
Predicting Adverse Drug Reactions from Social Media Posts: Data Balance, Feature Selection and Deep Learning

Abstract
:1. Introduction
2. Related Work
3. Data Description
4. Research Method: Data Balance, Feature Selection, and Deep Learning
4.1. Tackling the Data Imbalance Problem by Resampling and Ensemble Learning
4.2. Solving the High-Dimension Problem by Feature Selection
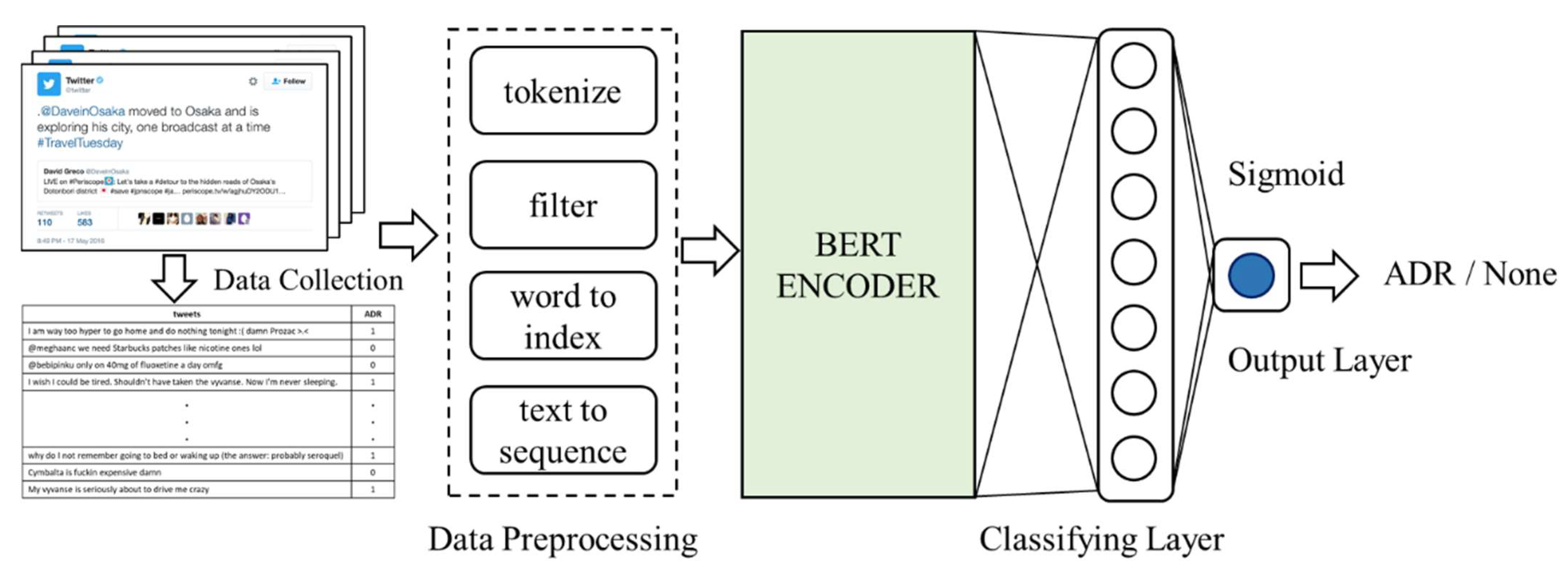
4.3. Enhanced Deep Learning for ADR Recognition
5. Experiments and Results
5.1. Results of Data Balance by Resampling Techniques
5.2. Evaluation of Ensemble Learning Methods
5.3. Results of Classification with Feature Selection
5.4. Evaluation of Deep Learning Methods
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benton, A.; Ungar, L.; Hill, S.; Hennessy, S.; Mao, J.; Chung, A.; Leonard, C.E.; Holmes, J.H. Identifying Potential Adverse Effects Using the Web: A New Approach to Medical Hypothesis Generation. J. Biomed. Inform. 2011, 44, 989–996. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mao, J.J.; Chung, A.; Benton, A.; Hill, S.; Ungar, L.; Leonard, C.E.; Hennessy, S.; Holmes, J.H. Online Discussion of Drug Side Effects and Discontinuation among Breast Cancer Survivors. Pharmacoepidemiol. Drug Saf. 2013, 22, 256–262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Freifeld, C.C.; Brownstein, J.S.; Menone, C.M.; Bao, W.J.; Filice, R.; Kass-Hout, T.; Dasgupta, N. Digital Drug Safety Surveillance: Monitoring Pharmaceutical Products in Twitter. Drug Saf. 2014, 37, 343–350. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Zhao, S.; Zhang, X. An Ensemble Method for Extracting Adverse Drug Events from Social Media. Artif. Intell. Med. 2016, 70, 62–76. [Google Scholar] [CrossRef] [PubMed]
- Pierce, C.E.; Bouri, K.; Pamer, C.; Proestel, S.; Rodriguez, H.W.; Le, H.V.; Freifeld, C.C.; Brownstein, J.S.; Walderhaug, M.; Edwards, I.R.; et al. Evaluation of Facebook and Twitter Monitoring to Detect Safety Signals for Medical Products: An Analysis of Recent Fda Safety Alerts. Drug Saf. 2017, 40, 317–331. [Google Scholar] [CrossRef] [Green Version]
- Sarker, A.; Gonzalez, G. Portable Automatic Text Classification for Adverse Drug Reaction Detection via Multi-corpus Training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zhao, S.; Wang, G. SSEL-ADE: A Semi-supervised Ensemble Learning Framework for Extracting Adverse Drug Events from Social Media. Artif. Intell. Med. 2018, 84, 34–49. [Google Scholar] [CrossRef]
- Dai, H.J.; Wang, C.K. Classifying Adverse Drug Reactions from Imbalanced Twitter Data. Int. J. Med. Inform. 2019, 129, 122–132. [Google Scholar] [CrossRef]
- Sarker, A.; Ginn, R.; Nikfarjam, A.; O’Connor, K.; Smith, K.; Jayaraman, S.; Upadhaya, T.; Gonzalez, G. Utilizing Social Media Data for Pharmacovigilance: A Review. J. Biomed. Inform. 2015, 54, 202–212. [Google Scholar] [CrossRef] [Green Version]
- Pappa, D.; Stergioulas, L.K. Harnessing Social Media Data for Pharmacovigilance: A Review of Current State of the Art, Challenges and Future Directions. Int. J. Data Sci 2019, 8, 113–135. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process Syst. 2017, 30, 5998–6008. [Google Scholar]
- BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. Available online: https://aclanthology.org/N19-1423 (accessed on 20 December 2020).
- Predicting Adverse Drug Events from Personal Health Messages. Available online: https://www.ncbi.nlm.nih.gov/pmc/articlws/PMC3243174/ (accessed on 18 December 2020).
- Quantifying Self-Reported Adverse Drug Events on Twitter: Signal and Topic Analysis. Available online: https://dl.acm.org/doi/pdf/10.1145/2930971.2930977 (accessed on 18 December 2020).
- Sampathkumar, H.; Chen, X.W.; Luo, B. Mining Adverse Drug Reactions From Online Healthcare Forums Using Hidden Markov Model. BMC Medical Inform. Decis. Mak. 2014, 14, 91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nikfarjam, A.; Sarker, A.; O’Connor, K.; Ginn, R. Pharmacovigilance from Social Media: Mining Adverse Drug Reaction Mentions Using Sequence Labeling with Word Embedding Cluster Features. J. Am. Med. Inform. Assoc. 2015, 22, 671–681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mining Adverse Drug Reaction Signals from Social Media: Going beyond Extraction. Available online: https://www.researchgate.net/publication/280446645 (accessed on 18 December 2020).
- Shabani-Mashcool, S.; Marashi, S.-A.; Gharaghani, S. NDDSA: A Network- and- domain-based Method for Predicting Drug-side Effect Associations. Inf. Process Manag. 2020, 57, 102357. [Google Scholar] [CrossRef]
- Ding, Y.; Tang, J.; Guo, F. Identification of Drug-Side Effect Association via Multiple Information Integration with Centered Kernel Alignment. Neurocomputing 2019, 325, 211–224. [Google Scholar] [CrossRef]
- One Size Does Not Fit All: An Ensemble Approach towards Information Extraction from Adverse Drug Event Narratives. Available online: https://researchr.org/publication/biostec-2019hi (accessed on 18 December 2020).
- Kim, Y.; Meystre, S.M. Ensemble Method–Based Extraction of Medication and Related Information from Clinical Texts. J. Am. Med. Inform. Assoc. 2020, 27, 31–38. [Google Scholar] [CrossRef]
- El-allaly, E.; Sarrouti, M.; En-Nahnahi, N.; El Alaoui, S.O. MTTLADE: A Multi-Task Transfer Learning-Based Method for Adverse Drug Events Extraction. Inf. Process Manag. 2021, 58, 102473. [Google Scholar] [CrossRef]
- Magge, A.; Sarker, A.; Nikfarjam, A.; Gonzalez-Hernandez, G. Deep Learning for Pharmacovigilance: Recurrent Neural Network Architectures for Labeling Adverse Drug Reactions in Twitter posts. J. Am. Med. Inform. Assoc. 2019, 26, 577–579. [Google Scholar] [CrossRef]
- A Deep Learning Approach to Extracting Adverse Drug Reactions. Available online: https://computer.org/csdl/proceedings/aiccsa/2019/1ifhrWozXb2 (accessed on 20 December 2020).
- Cocos, A.; Fiks, A.G.; Masino, A.J. Deep Learning for Pharmacovigilance: Recurrent Neural Network Architectures for Labeling Adverse Drug Reactions in Twitter Posts. J. Am. Med. Inform. Assoc. 2017, 24, 813–821. [Google Scholar] [CrossRef]
- Wang, C.S.; Lin, P.J.; Cheng, C.L.; Tai, S.H. Detecting Potential Adverse Drug Reactions Using a Deep Neural Network Model. J. Medical Internet Res. 2019, 21, e11016. [Google Scholar] [CrossRef] [Green Version]
- El-allaly, E.D.; Sarrouti, M.; En-Nahnahi, N.; El Alaoui, S.O. A LSTM-Based Method with Attention Mechanism for Adverse Drug Reaction Sentences Detection. In Proceedings of the International Conference on Advanced Intelligent Systems for Sustainable Development, Marrakech, Morocco, 8–11 July 2019; Springer Nature Switzerland AG: Cham, Switzerland, 2019; pp. 17–26. [Google Scholar]
- BioReddit: Word Embeddings for User-Generated Biomedical NLP. Available online: https://aclanthology.org/D19-6205/ (accessed on 20 December 2020).
- KFU NLP Team at SMM4H 2019 Tasks: Want to Extract Adverse Drugs Reactions from Tweets? BERT to the Rescue. Available online: https://www.aclanthology.org/W19-3207/ (accessed on 20 December 2020).
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. Biobert: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Fan, B.; Fan, W.; Smith, C. Adverse Drug Event Detection and Extraction from Open Data: A Deep Learning Approach. Inf. Process Manag. 2020, 57, 102131. [Google Scholar] [CrossRef]
- ADR Classification. Available online: https://diego.asu.edu/Publications/ADRClassify.html (accessed on 15 October 2020).
- High-Dimensional Data Analysis: The Curses and Blessings of Dimensionality. Available online: https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.3391 (accessed on 12 November 2020).
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-Learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- The Machine Learning Tool Sciki-Learn. Available online: https://scikit-learn.org/ (accessed on 15 October 2020).
- Borderline Over-Sampling for Imbalanced Data Classification. Available online: https://ousar.lib.okayama-u.ac.jp/en/19617 (accessed on 18 December 2020).
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. Available online: https://arxiv.org/abs/1702.05659 (accessed on 20 December 2020).
- Laurikkala, J. Improving Identification of Difficult Small Classes by Balancing Class Distribution. In Proceedings of the Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, 1–4 July 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 63–66. [Google Scholar]
- Wilson, D.L. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Trans. Syst. Man Cybern. Syst. 1972, 2, 408–421. [Google Scholar] [CrossRef] [Green Version]
- Tomek, I. An Experiment with the Edited Nearest-neighbor Rule. IEEE Trans. Syst. Man Cybern. Syst. 1976, 6, 448–452. [Google Scholar]
- KNN Approach to Unbalanced Data Distributions: A Case Study Involving Information Extraction. Available online: https://www.site.uottawa.ca/~nat/Workshop2003/jzhang.pdf (accessed on 15 December 2020).
- Hart, P. The Condensed Nearest Neighbor Rule. IEEE Trans. on Information Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-sided Selection. In Proceedings of the International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; pp. 179–186. [Google Scholar]
- Smith, M.R.; Martinez, T.; Giraud-Carrier, C. An Instance Level Analysis of Data Complexity. Mach. Learn. 2014, 95, 225–256. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1322–1328. [Google Scholar]
- Balancing Training Data for Automated Annotation of Keywords: A Case Study. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.10.2192 (accessed on 18 December 2020).
- Batista, G.E.; Prati, R.C.; Monard, M.C. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. ACM Trans. Knowl. Discov. Data 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Louppe, G.; Geurts, P. Ensembles on Random Patches. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bristol, UK, 23–27 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 346–361. [Google Scholar]
- Using Random Forest to Learn Imbalanced Data. Available online: https://statistics.berkeley.edu/sites/default/files/tech-reports/666.pdf (accessed on 15 October 2020).
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory Undersampling for Class-imbalance Learning. IEEE Trans. Syst. Man Cybern. Syst. 2008, 39, 539–550. [Google Scholar]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. RUSBoost: A Hybrid Approach to Alleviating Class Imbalance. IEEE Trans. Syst. Man Cybern. Syst. 2009, 40, 185–197. [Google Scholar] [CrossRef]
- Adverse Drug Reaction Classification with Deep Neural Networks. Available online: https://aclanthology.org/C16-1084/ (accessed on 15 December 2020).


{kind=link}
{kind=link}
| Feature Name | Dim | Description |
|---|---|---|
| text | 5000 | N-grams, N = 1~3 |
| synset vector | 2000 | the tf.idf measure for each derived synonym |
| cluster vector | 981 | cluster terms tf |
| topic vector | 500 | the topic terms that appear in the instance |
| sentiments | 5 | the sum of all the individual term-POS (part-of-speech) sentiment scores divided by the length of the sentence in words |
| good/bad | 4 | four features: MORE-GOOD, MORE-BAD, LESS-GOOD, and LESS-BAD |
| structural features | 3 | length: lengths of the text segments in words presence of comparatives and superlatives: these are binary features and these items are identified from the Stanford parses of the text segments presence of modals |
| ADRs lexicon | 2 | The first feature is a binary feature indicating the presence/absence of ADR mentions. The second feature is a numeric feature computed by counting the number of ADR mentions in a text segment and dividing it by the number of words in the text segment. |
| topics | 1 | sums of all the relevance scores of the terms in each instance |
| Methods | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|
| SVM | 0.90 | 0.54 | 0.51 | 0.52 | 0.73 |
| LR | 0.90 | 0.51 | 0.56 | 0.53 | 0.75 |
| Methods | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|
| Without balance | 0.90 | 0.58 | 0.41 | 0.48 | 0.69 |
| Random under-sampling | 0.74 | 0.28 | 0.78 | 0.41 | 0.76 |
| TomekLinks [40] | 0.90 | 0.59 | 0.41 | 0.48 | 0.69 |
| NearMiss [41] | 0.37 | 0.15 | 0.95 | 0.26 | 0.62 |
| CondensedNearestNeighbour [42] | 0.85 | 0.39 | 0.58 | 0.47 | 0.73 |
| OneSidedSelection [43] | 0.90 | 0.59 | 0.41 | 0.48 | 0.69 |
| NeighbourhoodCleaningRule [38] | 0.90 | 0.56 | 0.51 | 0.53 | 0.72 |
| EditedNearestNeighbours [39] | 0.89 | 0.55 | 0.54 | 0.54 | 0.74 |
| RepeatedEditedNearestNeighbours [40] | 0.88 | 0.48 | 0.56 | 0.52 | 0.74 |
| AllKNN [40] | 0.89 | 0.51 | 0.55 | 0.53 | 0.74 |
| InstanceHardnessThreshold [44] | 0.85 | 0.40 | 0.63 | 0.49 | 0.75 |
| Methods | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|
| Without balance | 0.90 | 0.58 | 0.41 | 0.48 | 0.69 |
| Random over-sampling | 0.87 | 0.47 | 0.55 | 0.51 | 0.73 |
| SMOTE [45] | 0.88 | 0.47 | 0.54 | 0.50 | 0.73 |
| Borderline-SMOTE type 1 [46] | 0.88 | 0.48 | 0.55 | 0.51 | 0.73 |
| Borderline-SMOTE type 2 [46] | 0.87 | 0.46 | 0.60 | 0.52 | 0.76 |
| Support Vectors SMOTE [36] | 0.89 | 0.53 | 0.50 | 0.51 | 0.72 |
| ADASYN [47] | 0.89 | 0.53 | 0.49 | 0.51 | 0.72 |
| SMOTE + Tomek [48] | 0.88 | 0.47 | 0.55 | 0.51 | 0.73 |
| SMOTE + ENN [49] | 0.88 | 0.47 | 0.54 | 0.50 | 0.73 |
| Methods | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|
| Balanced Bagging DT [50] | 0.81 | 0.32 | 0.67 | 0.43 | 0.75 |
| Balanced RandomForest [51] | 0.73 | 0.26 | 0.76 | 0.39 | 0.75 |
| EasyEnsemble [52] | 0.74 | 0.26 | 0.76 | 0.38 | 0.75 |
| RUSBoost [53] | 0.74 | 0.26 | 0.76 | 0.38 | 0.75 |
| Method | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|
| LR with DB | 0.90 | 0.51 | 0.56 | 0.53 | 0.75 |
| LR with DB and FS | 0.90 | 0.51 | 0.62 | 0.56 | 0.78 |
| 1000 best features removed | 0.84 | 0.29 | 0.30 | 0.29 | 0.60 |
| Feature Name | Selected | Original | Category (%) | Overall (%) |
|---|---|---|---|---|
| text | 332 | 5000 | 6.6 | 4.90 |
| synset vector | 471 | 2000 | 23.5 | 6.90 |
| sentiments | 3 | 5 | 60.0 | 0.04 |
| cluster vector | 123 | 981 | 12.5 | 1.80 |
| structural features | 2 | 3 | 66.7 | 0.03 |
| adrlexicon | 2 | 2 | 100.0 | 0.03 |
| topics | 1 | 1 | 100.0 | 0.01 |
| topic vector | 65 | 500 | 13.0 | 0.95 |
| goodbad | 1 | 4 | 25.0 | 0.01 |
| Methods | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|
| CNN [54] | 0.88 | 0.47 | 0.50 | 0.48 | 0.71 |
| CRNN [54] | 0.85 | 0.38 | 0.53 | 0.44 | 0.71 |
| RCNN [54] | 0.89 | 0.50 | 0.44 | 0.46 | 0.69 |
| BERT with BCE | 0.90 | 0.56 | 0.50 | 0.53 | 0.85 |
| BERT with MSE | 0.91 | 0.62 | 0.45 | 0.52 | 0.86 |
| BERT with fixed weights-1 | 0.90 | 0.58 | 0.49 | 0.51 | 0.82 |
| BERT with fixed weights-2 | 0.91 | 0.53 | 0.55 | 0.53 | 0.83 |
| BERT with BAW | 0.90 | 0.56 | 0.53 | 0.55 | 0.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.-Y.; Lee, W.-P.; Lee, K.-D. Predicting Adverse Drug Reactions from Social Media Posts: Data Balance, Feature Selection and Deep Learning. Healthcare 2022, 10, 618. https://doi.org/10.3390/healthcare10040618
Huang J-Y, Lee W-P, Lee K-D. Predicting Adverse Drug Reactions from Social Media Posts: Data Balance, Feature Selection and Deep Learning. Healthcare. 2022; 10(4):618. https://doi.org/10.3390/healthcare10040618
Chicago/Turabian StyleHuang, Jhih-Yuan, Wei-Po Lee, and King-Der Lee. 2022. "Predicting Adverse Drug Reactions from Social Media Posts: Data Balance, Feature Selection and Deep Learning" Healthcare 10, no. 4: 618. https://doi.org/10.3390/healthcare10040618
APA StyleHuang, J.-Y., Lee, W.-P., & Lee, K.-D. (2022). Predicting Adverse Drug Reactions from Social Media Posts: Data Balance, Feature Selection and Deep Learning. Healthcare, 10(4), 618. https://doi.org/10.3390/healthcare10040618