This section first describes the structure of the data used and how they were obtained. Secondly, it reviews the methodology employed, mainly relying on data panel models.
2.1. Data
The database used comprises deaths and populations of 26 European countries from the Human Mortality Database (HMD) [
19] for the period 1995–2012, an age range of 65–110+ and male (m) and female (f) sexes. The available European countries are Austria (AT), Belgium (BE), Belarus (BY), The Czech Republic (CZ), Denmark(DK), Estonia (EE), Finland (FI), France (FR), Germany (DE), Hungary (HU), Ireland (IE), Italy (IT), Latvia (LV), Lithuania (LT), Luxembourg (LU), The Netherlands (NL), Norway (NO), Poland (PL), Portugal (PT), Slovakia (SK), Slovenia (SI), Spain (ES), Sweden (SE), Switzerland (CH), The United Kingdom (UK), and Ukraine (UA). In previous studies, Carracedo et al. [
20] quantified the dynamics of mortality in Europe and detected two significant clusters for ages older than 64. In this paper, to explain the behavior of mortality as a function of socioeconomic variables, information about four variables for these 26 countries and 18 years was obtained from The World Bank Database [
21]. These variables are the Gross Domestic Product (GDP), public health expenditure, CO
2 emissions, and education expenditure based on a literature review of this area [
22,
23,
24] and data availability for European countries from [
21]. In addition, there are recent studies examining the impact of CO
2 emissions, health expenditure, and education on life expectancy [
24]. Furthermore, it is essential to point out that the new impacts of environmental degradation on human health affect today’s society both in terms of loss of quality of life and spending on health care. The definitions of the variables can be found below:
Gross Domestic Product per capita (current U.S. dollars) (GDP) is an economic variable used as a measure of income. It is defined as the sum of gross value added by all resident producers in the economy plus any product taxes and minus any subsidies not included in the products’ value. GDP has traditionally been used to show the economic and social development of countries [
25]. In recent years, there has been significant interest in the relationship between health, proxied by life expectancy, and income, as explained by [
26], preceded by [
27]. It has generally been well accepted that populations in countries with higher GDP levels have better health and longer life expectancy, as higher living standards lead to enhanced prevention and treatment of disease [
27]. It should be noted that all variables are expressed in per capita values.
Public health expenditure per capita (% of total health expenditure) (PHE) is a social variable that consists of recurrent and capital spending from government (central and local) budgets, external borrowings and grants (including donations from international agencies and nongovernmental organizations), and social (or compulsory) health insurance funds. In countries with high income per capita, the contributions to social security are essential and sustain, to a great extent, the financing of the health system. Consequently, the lower the mortality in a country, the healthier its population [
28]. Several studies, such as [
29,
30], among others, have shown that health expenditure has a significant negative impact on mortality rate and a positive impact on life expectancy. It should be noted that the health expenditure variable is reported until 2012; for this reason, the study is limited to that year.
CO
2 emissions per capita (metric tons) is an environmental variable that is used to indicate the effect of air pollution on mortality. Carbon dioxide emissions are those stemming from the burning of fossil fuels and the manufacture of cement. They include carbon dioxide produced during the consumption of solid, liquid, and gas fuels and gas flaring. Countries with higher carbon dioxide emissions levels are at higher risk of their citizens having health problems [
24,
31].
Education Expenditure per capita (% Gross National Income) (EE) refers to the current operating expenditure on education, including wages and salaries and excluding capital investments on buildings and equipment. This variable is an essential factor that determines health as a measure of educational level. People with higher educational levels have better jobs, higher incomes, and lower-risk behavior [
32].
Gavurova [
33] is the closest study to our analysis, but we should highlight three distinctive features in our study. First, we use a suitable statistic to compare mortality for each country by sex, the Comparative Mortality Figure. Second, our sample is contextualized in older European people. Hence, the reliability of our results is enhanced for retired people in Europe. In addition to studying the relationship between mortality and the covariates GDP and health expenditure, we consider the impact of CO
2 emissions and education expenditure per capita over mortality. Third, we consider the neighborhood relationships between countries over time. This point is vital since studies such as Carracedo et al. [
20] show that European mortality has a spatial dependence.
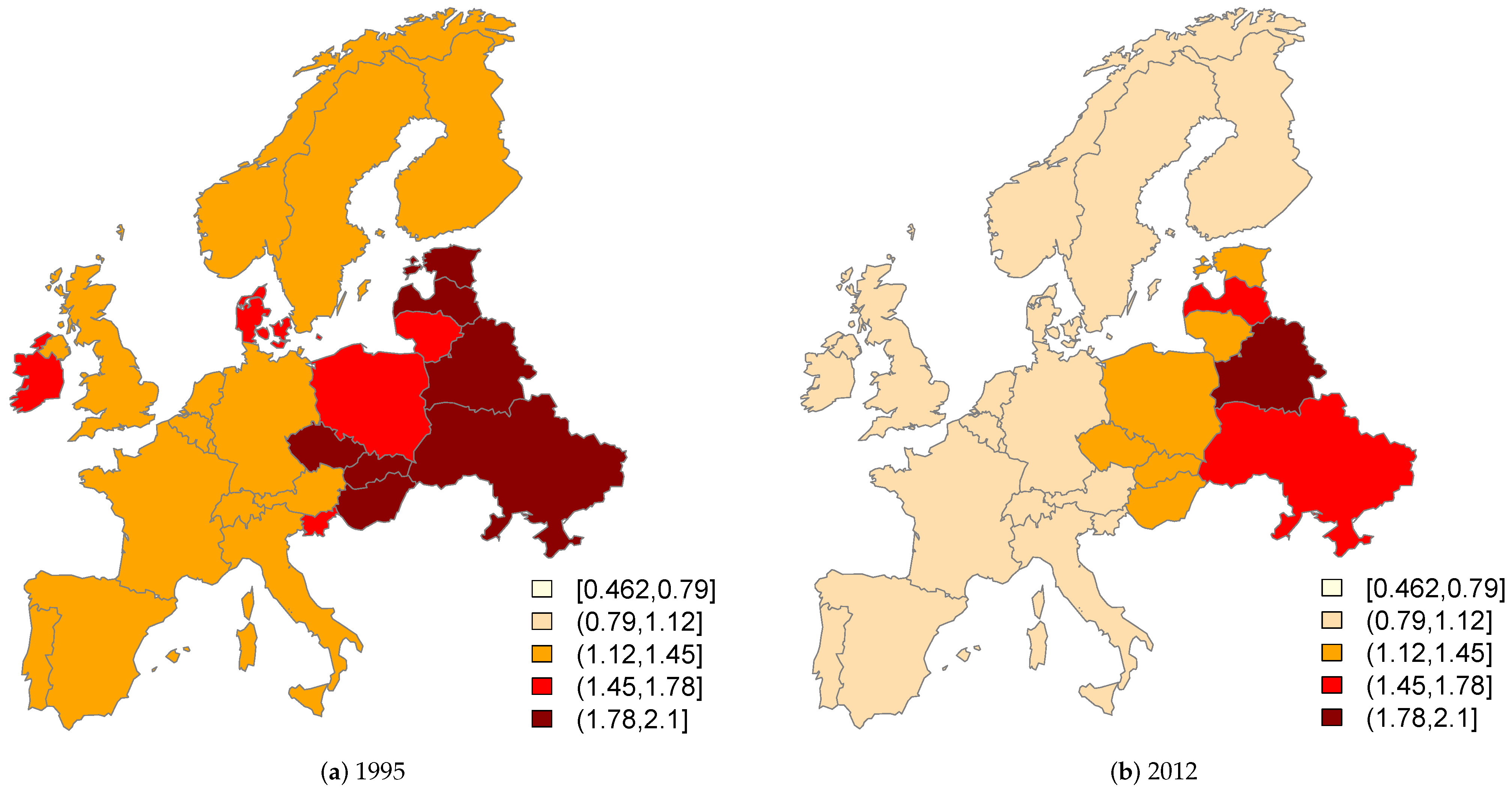
2.2. Comparative Mortality Figure
The Comparative Mortality Figure (CMF) was used in this study to compare the mortality experience over time by sex and country. There are two principal standardization methods—direct and indirect—which produce Comparative Mortality Figure (CMF) and Standardized Mortality Ratio (SMR), respectively. To compare the mortality experience over time by sex and country, the CMF was used in this study for two reasons. First, the same denominator applies in the calculations for each country, which permits comparison of the mortality experience by sex for different places, and second, the age-specific mortality rates are available for each country [
17] required in the expression of CMF but not in the expression of SMR.
The CMF allows for the direct standardization method of mortality rates across age groups to permit comparison of the free effects of differences in the size of subgroups of the populations [
17]. In this study, we used males (m) in the set of European countries in the year 2012 as the standard population. Therefore, the CMF is defined as follows,
where
represents the expected deaths in country
i, in year
t, and sex
s and
is the number of observed deaths in the set of European countries in year 2012 for males. As we have
the number of observed deaths for the age
x,
Then
are obtained by using the age-specific death rate of each country
i for the age
x, year
t, and sex
s,
,
where
is the population in the set of European countries at age
x in year 2012 for
sex, which can be obtained by adding all
the population of each country
i with the following expression
The death rate of the study population (
) are obtained as
where
and
are the number of deaths and the study population, respectively. If the CMF is greater than 1, there is a higher expected number of deaths than observed; in this case, there are “excess deaths” in the studied countries. On the contrary, a CMF value below 1 indicates a lower expected number of deaths than observed relative to the standard population. According to [
17,
34], the numbers of observed deaths in the countries is a random variable that follows a Poisson distribution; in the case of CMF that distribution can be used for modelization.
2.3. Spatial Dependence of CMF
Global Moran’s Index (GM) is widely used to test for the presence of spatial dependence between adjacent locations [
35,
36]. In this study, it is a summary measure that shows the intensity of spatial dependence of all countries’ CMF considered.
where
is the mean of the CMF of all countries for each year
t and sex
s and
is the neighborhood or spatial weights matrix. The definition of proximity is given by
, which is an
(
) positive matrix that provides a weight
to each pair of spatial units
[
37]. In this study, the weights matrix is used in row standardized form. In addition, two countries are considered neighbors when they have a common border (first order of neighborhood [
38]), and therefore, if a country is not a neighbor of itself, it takes the following values,
where
is the number of neighbors of country
i and
the set of neighbors of the country
i. The interpretation for
is the following:
—Positive spatial autocorrelation between countries. The CMF of countries and their neighbors goes in the same direction.
—Negative spatial autocorrelation between countries. The CMF of countries and their neighbors varies in a different direction.
—Absence of spatial autocorrelation between the 26 European countries, meaning a random spatial pattern.
Moran’s test for spatial autocorrelation was calculated to test the significance of the GM index. The null hypothesis establishes that the
is randomly distributed among the spatial units of the study area
[
39].
2.4. Spatiotemporal Panel Data Models
The analysis of data from the spatiotemporal panel is currently a field of econometrics undergoing significant methodological advances [
12]. Panel data consist of a cross-section of observations (individuals, countries, regions) followed through time. Specifically, the data from this study are panel data that combine a spatial dimension
N (26 countries) and temporal dimension
T (18 years). In a spatiotemporal panel, there may be dependency or correlation between the close observations (spatial units) over time (temporal units).
Econometrics panel data models offer advantages over cross-section regression or time series as they control for unobserved heterogeneity produced by both spatial and temporal units. As a result, these models reduce the issues related to multicollinearity problems between the variables by building more efficient estimates in the parameters of the panel data models [
40]. Panel data usually contain more degrees of freedom and more sample variability, combining both cross-sectional and time-series data, hence, improving the efficiency of econometric estimates [
41]. The spatiotemporal panel data models are used as the regression models that employ the panel structure’s temporal and spatial heterogeneity to estimate parameters of interest [
42].
Due to the nature of our variables, we propose a log–log spatiotemporal panel data model that assumes the log transformation of the CMF and the explanatory variables to achieve approximate normality and symmetry about the distribution of CMF and provide straightforward interpretability of the results [
43]. In this model, the explanatory variables’ coefficients represent the elasticity of CMF for the explanatory variables [
44].
The spatial lag term considers that the value of the CMF in a country depends on the value of the CMF in its vicinity. This fact will be confirmed in
Section 3.2. In addition, the fixed effects model is generally more appropriate than the random effects model when the sample used is fixed, i.e., the countries have not been drawn randomly from a very large population [
37]. In our case, we would like to model the space-time data of adjacent spatial units (countries) or “located in an unbroken study area” [
45]. For these reasons, we fitted spatial lag models with fixed effects. This model fits the behavior of CMF by country and time as a function of explanatory variables assuming that the differences between spatial units, time units, or both are constant [
46]. For this reason, spatial and temporal dummy variables were created to account for the unobserved characteristics of cross-sectional units (not changing with time but affecting the dependent variable) and the unobserved characteristics of temporal units (not changing with countries but affecting the dependent variable). These models use the notation that has become usual in this context and adapted to explain the log transformation of CMF, namely,
Spatial Lag Model with spatial fixed effects (SLMSFE);
Spatial Lag Model with time fixed effects (SLMTFE);
Spatial Lag Model with spatial and time fixed effects (SLMSTFE);
where represents an ordered vector of dimension corresponding to observations of the dependent variable for each country i and year t, is the intercept, is the spatial parameter associated with the dependent variable, represents a matrix of dimension , the log transformation of the explanatory variables ordered by spatial units first and then by time period, which are related to the parameters of dimension . The fixed effects considered in the model are as follows:
is the spatial fixed effect (not spatially autocorrelated), which captures the unobservable characteristics that change across countries but remain constant over time.
is the temporal fixed effect (not temporally autocorrelated), which captures the unobservable characteristics that change over time but remain constant across countries.
denotes the spatial autoregressive parameter on the spatially lagged dependent variable to follow the econometrics literature [
47,
48]. SLMSTFE has the conditions that the sum of the spatial and temporal effects are zero [
49]. These conditions are achieved using 26 spatial dummies and 18 time dummies because 26 and 18 are the total number of countries and years considered in this study. Thus, the spatial effect represents the deviation of the spatial unit
i from the mean
, and the time effect represents the deviation of the time unit
t from the mean
.
On the other hand, GLMs are an extension of linear models for response variables with non-normal distributions and nonlinear transformations [
18]. GLM provides a method for estimating a function of the dependent variable’s mean, also called link function, as a linear combination of a set of explanatory variables. Poisson regression is a GLM model where the dependent variable is a count that follows a Poisson distribution. The canonical link results in a log-linear relationship between mean and linear predictor. The Poisson model variance is identical to the mean; thus, in the case the variance is larger than the mean, the data are over-dispersed.
A way of modeling over-dispersed count data is to use the quasi-Poisson model, which produces the same coefficient estimates as the standard Poisson model, but the inference is adjusted over-dispersion. Consequently, the quasi-Poisson family does not correspond to a model with fully specified likelihood, and therefore, statistical tests and goodness-of-fit measures such as AIC, BIC, likelihood-ratio are unavailable in the output of model [
16]. In
R, the quasi-Poisson model with estimated dispersion parameter can also be fitted with the
glm function and setting
family = quasipoisson.
We suggest adapting log–log SLMSTFE to GLM, the model proposed for
is,
In the next section, these models are estimated by maximum likelihood with splm and glm functions in R software and the sar_panel_FE function in MATLAB. In this way, the glm function takes into account the value of the quasiPoisson-likelihood and not the log-likelihood value.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}