
Techniques to Improve B2B Data Governance Using FAIR Principles



Abstract
1. Cross-Sector B2B Data Sharing and Its Impact on the Companies Ecosystem
- Data monetization—companies are willing to share part of their data in order to increase their business revenues; according to a Gartner report on “Magic Quadrant for Analytics and Business Intelligence Platforms” [7], several corporations consider data sharing for profit an important part of their business strategy, amongst which Microsoft and Tableau are leaders, Oracle and Salesforce are visionaries, while IBM and Alibaba Cloud can be considered niche players; there are also business such as MicroStrategy and Looker who constantly challenge the consecrated techniques for B2B, which leads to improvements and new discoveries;
- Public data marketplaces—rely on public trusted entities that connect both data sellers and data buyers in one environment; usually, a transaction fee is perceived for all exchanges in order to keep the platform alive;
- Industrial data platforms—a secure and private environment which is restricted to group of companies exchanging data for free voluntarily in order to facilitate new product and services development;
- Technical enablers—businesses which specialize in creating data sharing flows custom for companies;
- Open data policy—companies sharing part of their data in a completely open manner;
2. Data Modelling in B2B Processes
2.1. FAIR Principles Overview
2.2. Open Data Debates Approached in the FAIR Data Model
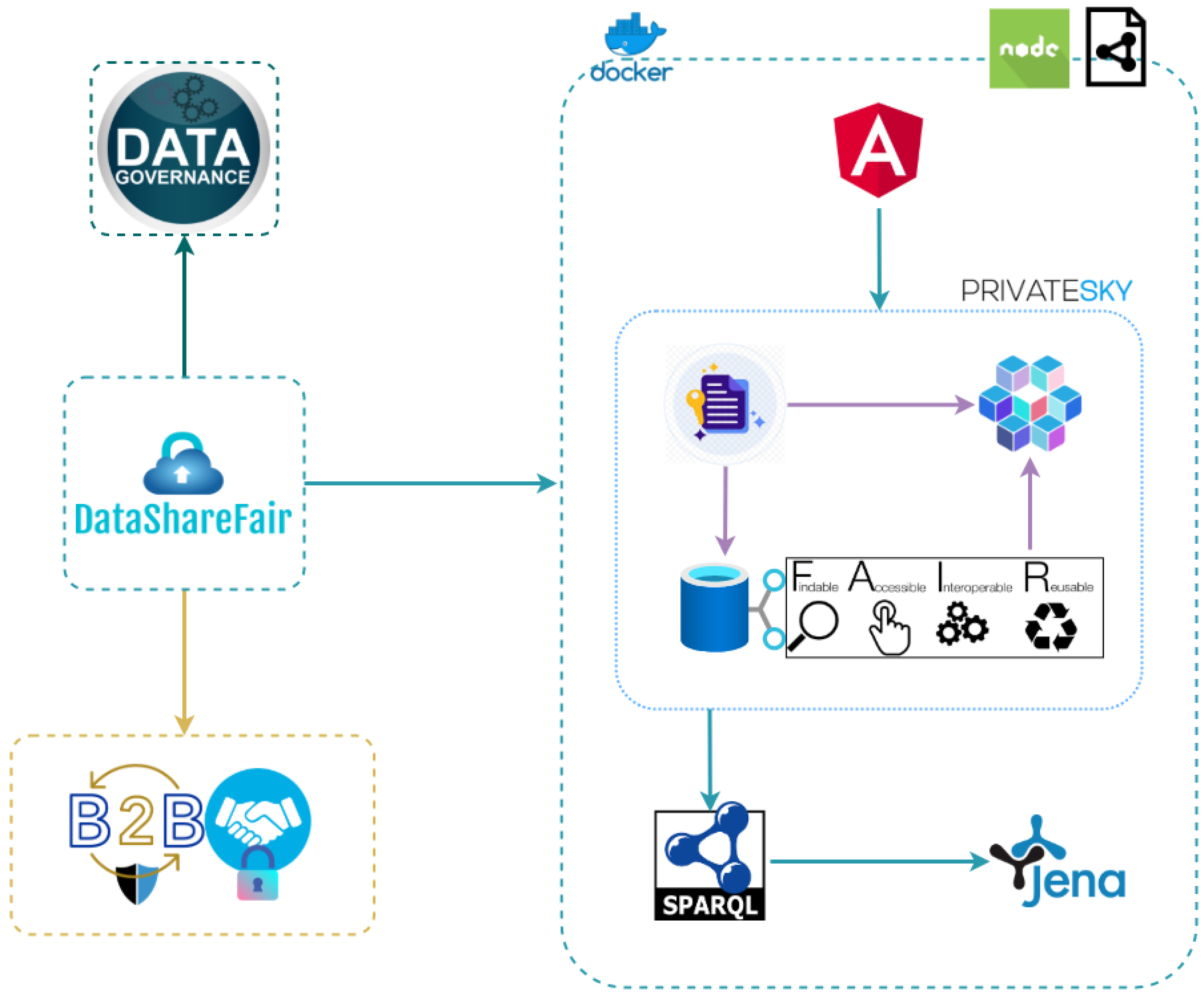
3. DataShareFair Proposal
3.1. FAIR Data Modelling in DataShareFair
3.2. DataShareFair Technical Approach
3.2.1. Underlying Concepts and Technologies
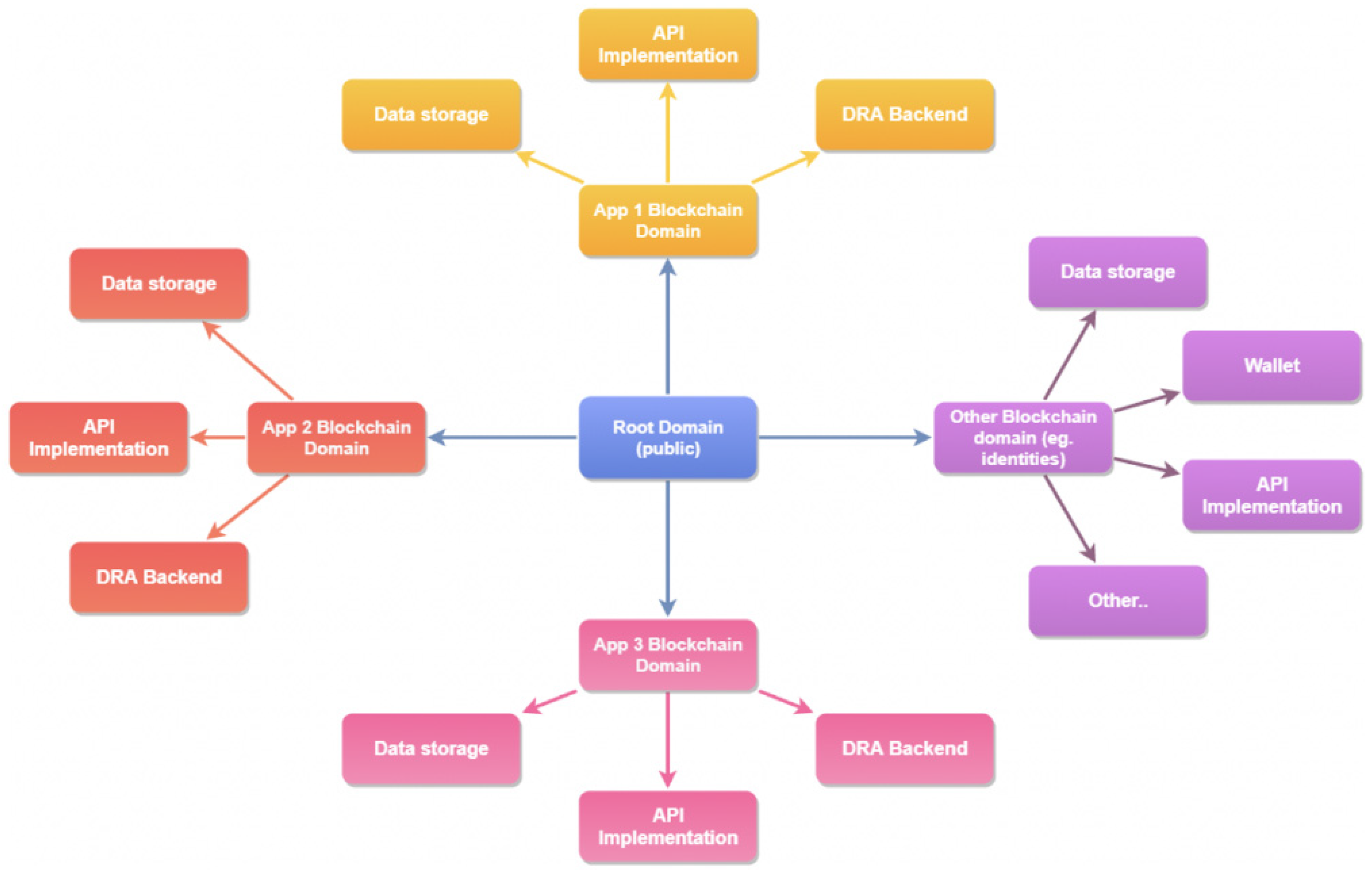
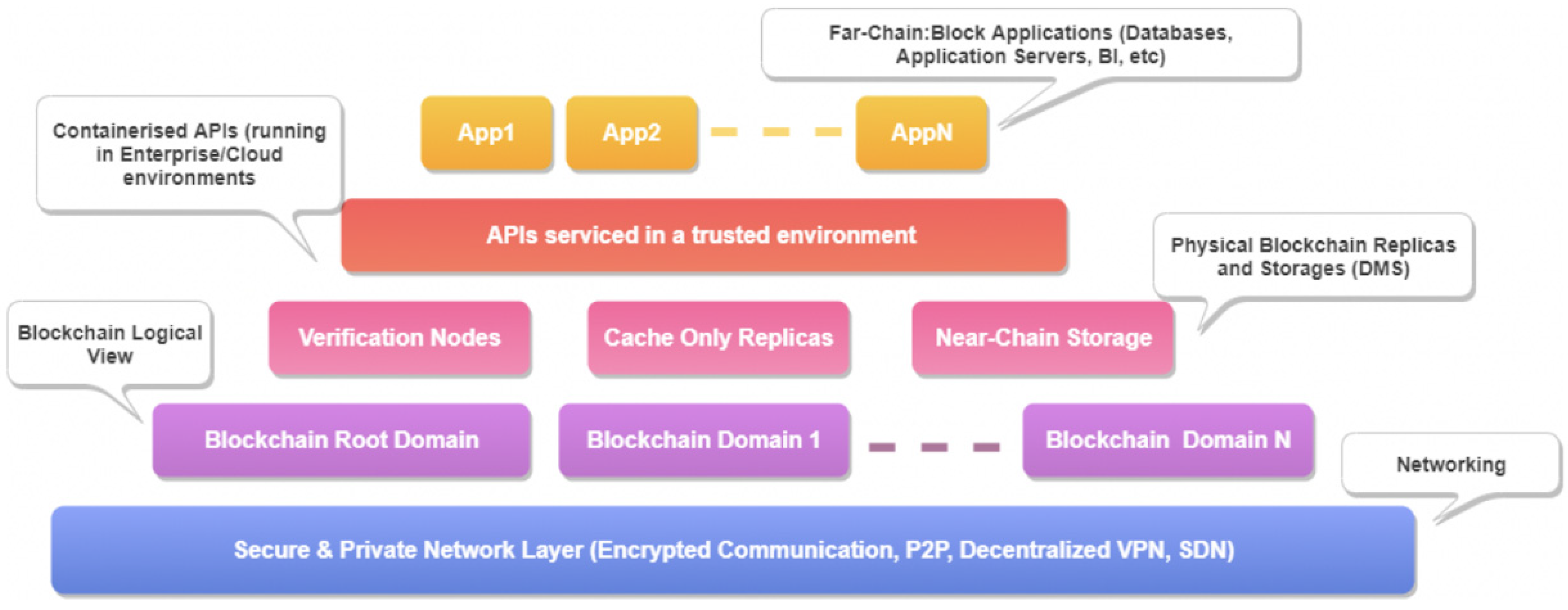
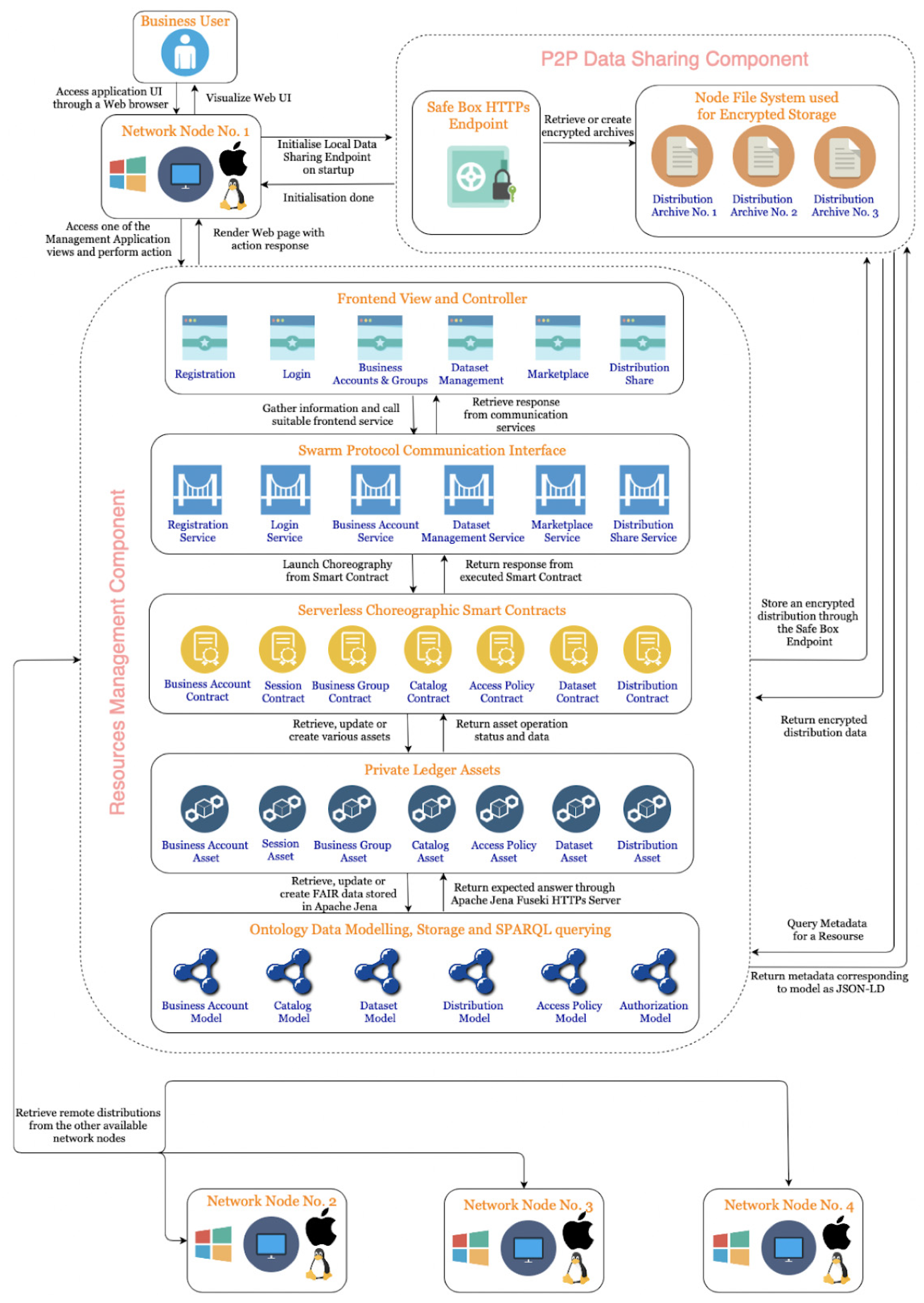
3.2.2. Proposed Architecture
- Registration and Login
- 2.
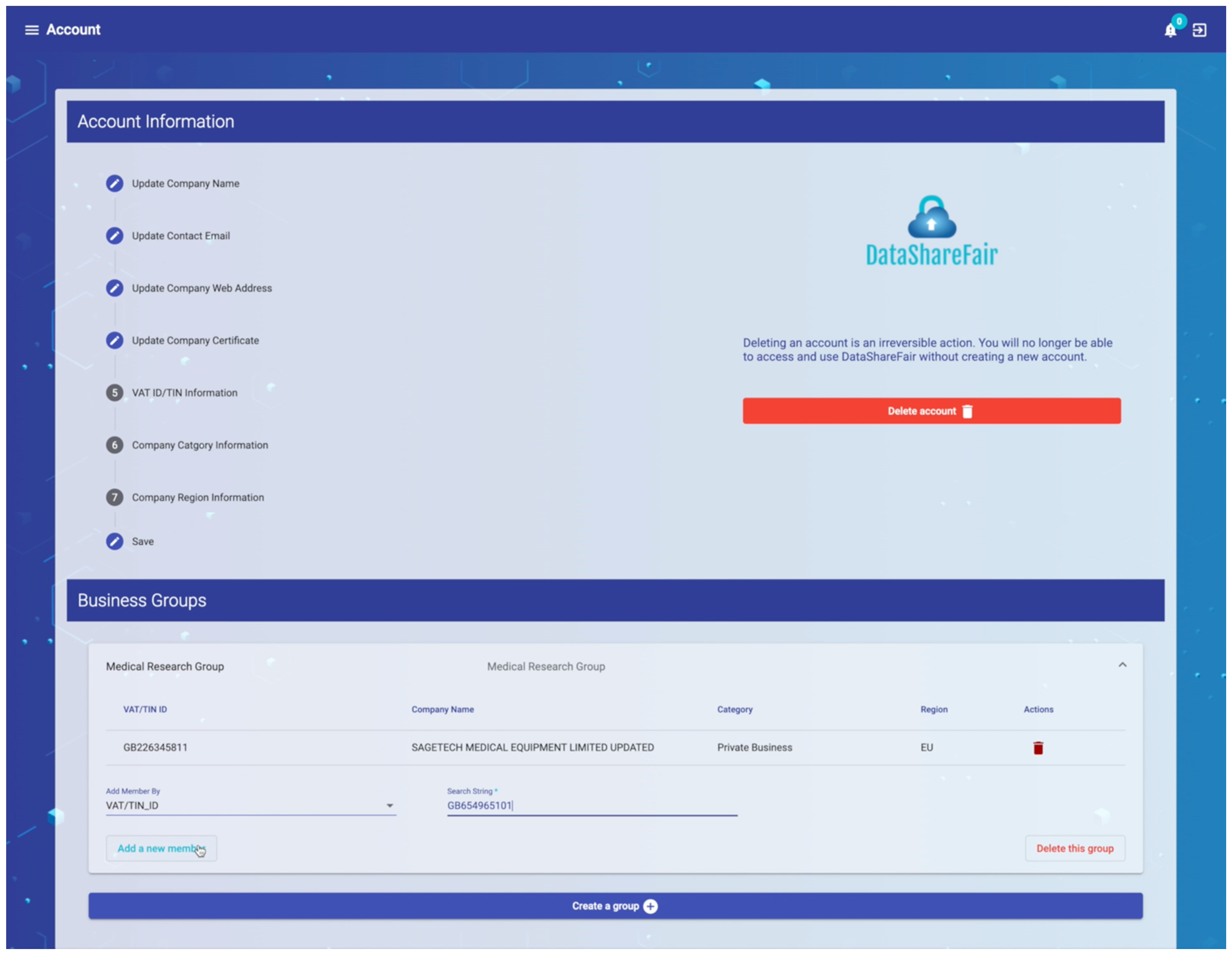
- Business Accounts and Groups Management
- 3.
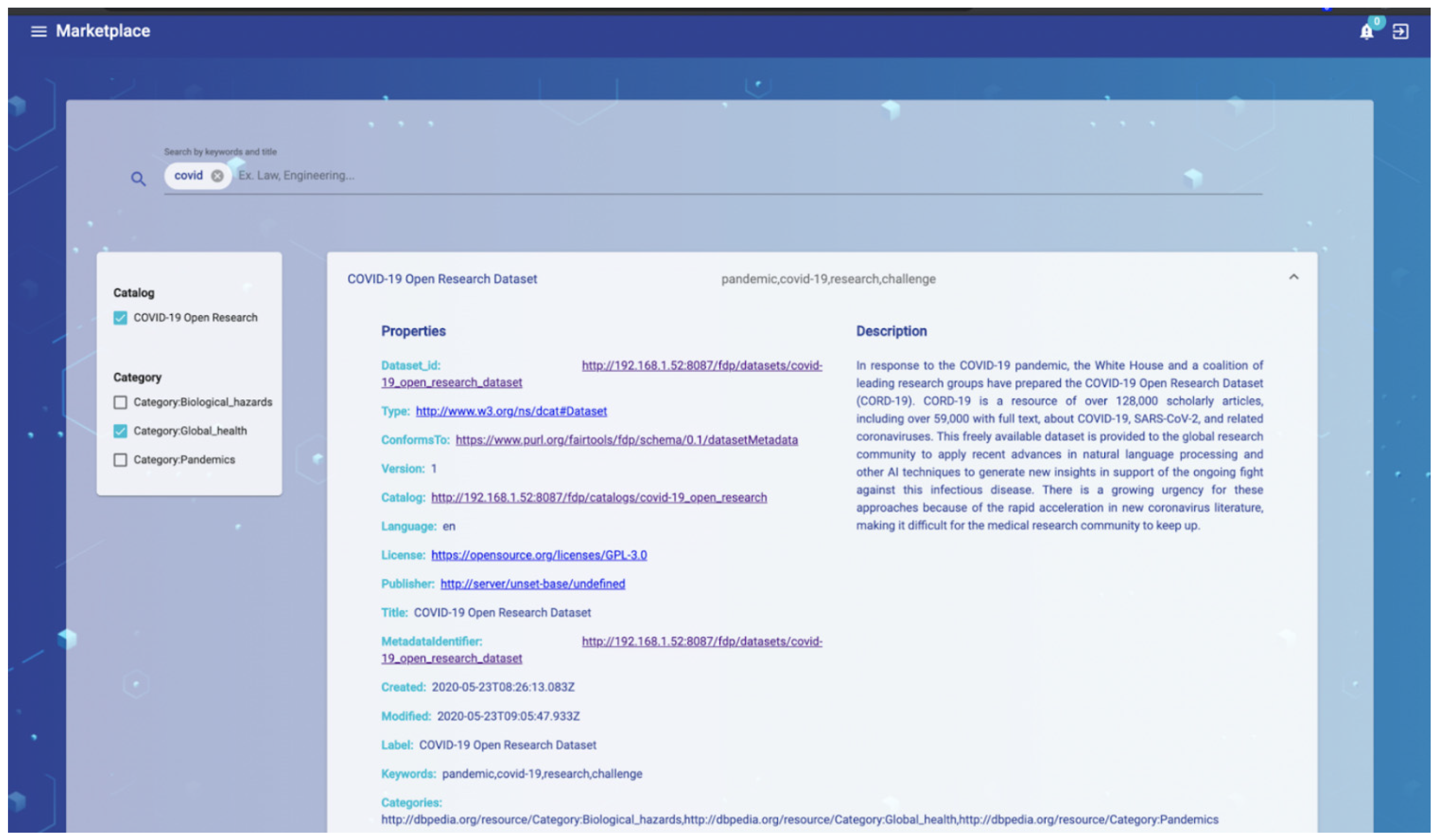
- B2B FAIR Data Marketplace
- 4.
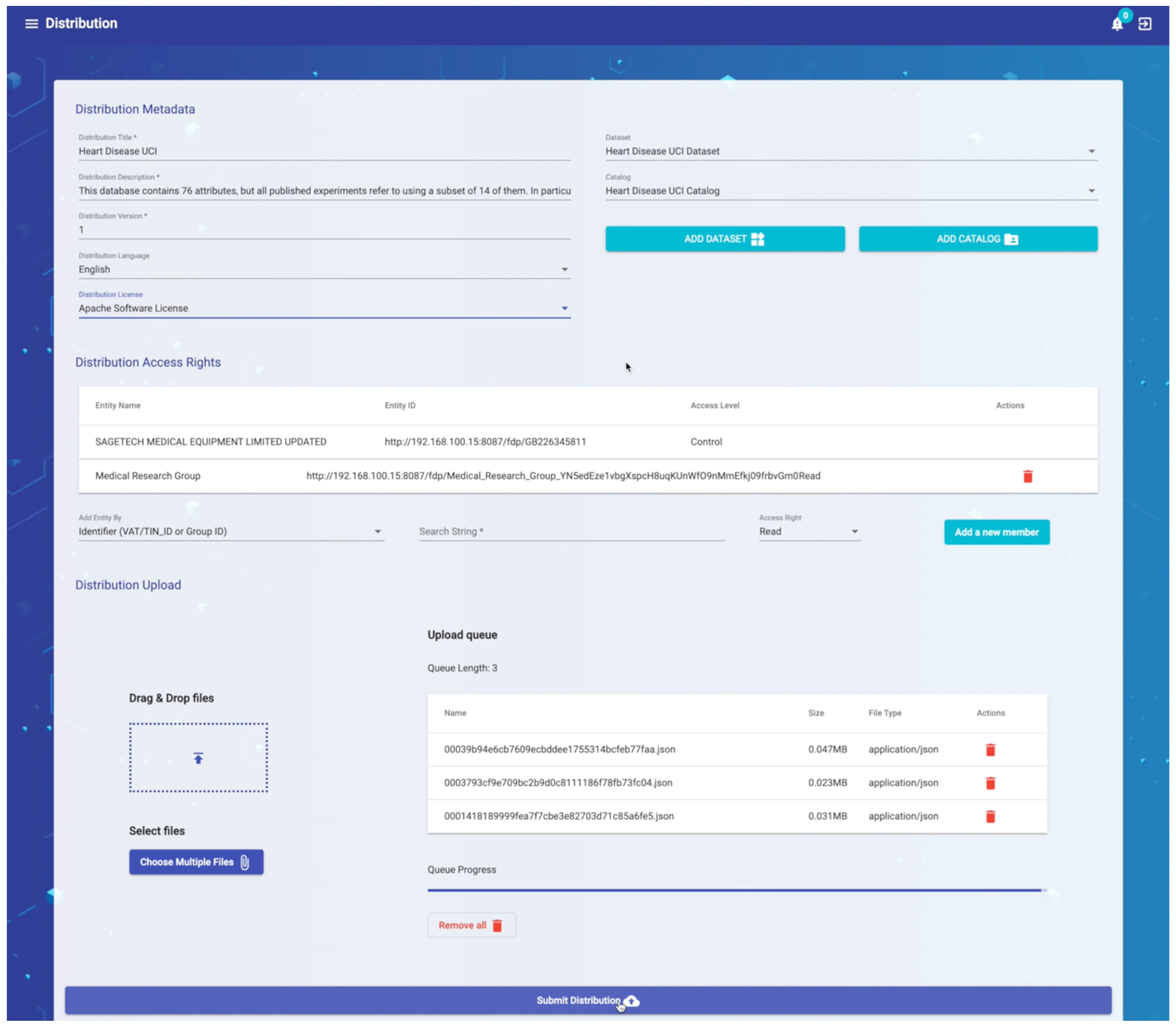
- FAIRification Process for B2B Data Sharing
- 5.
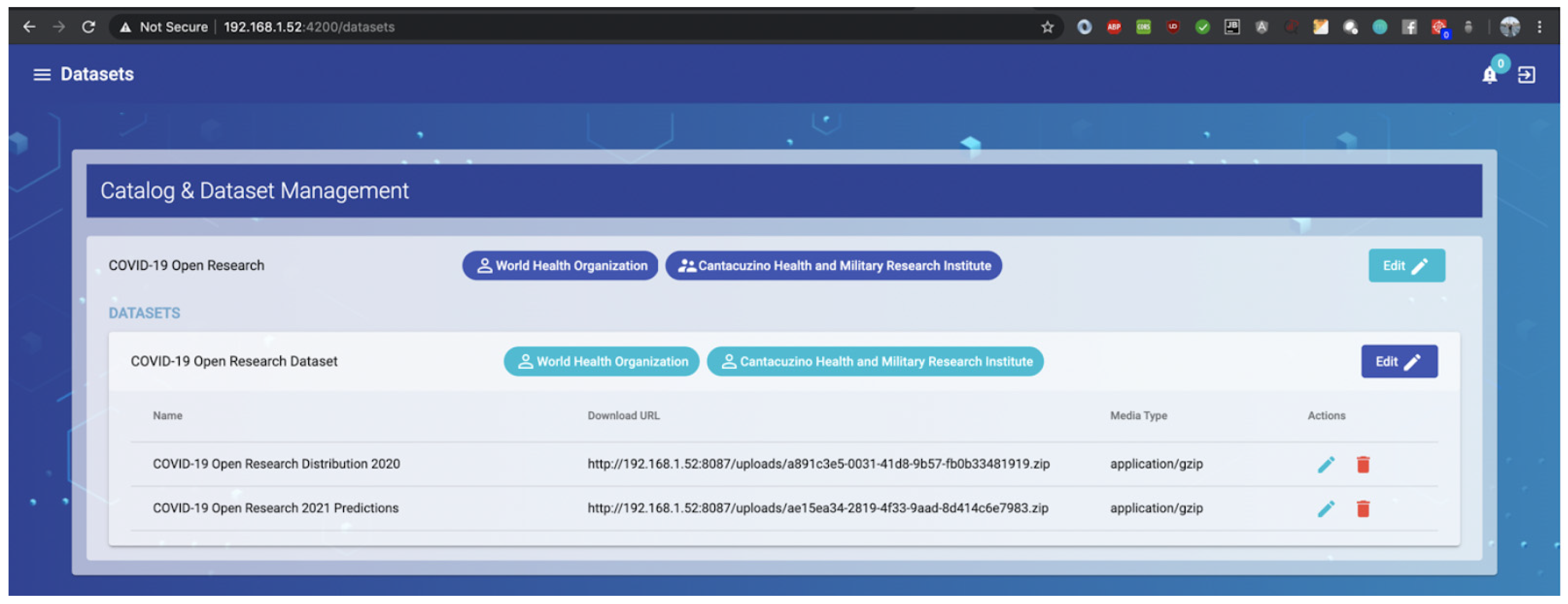
- FAIR Resources Management
- 6.
- P2P FAIR Data Points
4. Impact of DataShareFair in B2B Data Exchange Use Cases
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gartner. New B2B Buying Journey & Its Implication for Sales. Available online: https://www.gartner.com/en/sales/insights/b2b-buying-journey (accessed on 18 April 2021).
- Gunnar, S. Business-to-business data sharing: A source for integration of supply chains. Int. J. Prod. Econ. 2002, 75, 135–146. [Google Scholar] [CrossRef]
- Directorate-General for Communications Networks, Content and Technology. Study on Data Sharing between Companies in Europe (2018). Available online: https://op.europa.eu/en/publication-detail/-/publication/8b8776ff-4834-11e8-be1d-01aa75ed71a1/language-en (accessed on 20 April 2021).
- Myler, L. Forbes. Available online: https://www.forbes.com/sites/larrymyler/2017/09/11/data-sharing-can-be-a-catalyst-for-b2b-innovation/ (accessed on 13 September 2020).
- Informatica. B2B Data Exchange—Streamline Multi-Enterprise Data Integration 2020. Available online: https://www.informatica.com/content/dam/informatica-com/en/collateral/brochure/b2b-data-exchange_brochure_6828.pdf (accessed on 23 April 2021).
- Euro Banking Association. B2B Data Sharing: Digital Consent Management as a Driver for Data Opportunities. 2018. Available online: https://eba-cms-prod.azurewebsites.net/media/azure/production/1815/eba_2018_obwg_b2b_data_sharing.pdf (accessed on 20 April 2020).
- Gartner. Magic Quadrant for Analytics and Business Intelligence Platforms. Available online: https://www.gartner.com/en/documents/3980852/magic-quadrant-for-analytics-and-business-intelligence-p (accessed on 11 February 2020).
- Datapace. 2021. Available online: https://datapace.io (accessed on 18 April 2021).
- Epimorphics. Epimorphics. 2021. Available online: https://www.epimorphics.com/services/ (accessed on 18 April 2021).
- iGrant.io. iGrant.io. 2021. Available online: https://igrant.io/ (accessed on 18 April 2021).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Fair, R.T. FAIR Principles. 2020. Available online: FAIR Principles (accessed on 16 May 2020).
- Association of European Research Libraries (A. o. E. R. Libraries). Implementing FAIR Data Principles: The Role of Libraries. 2017. Available online: https://libereurope.eu/wp-content/uploads/2017/12/LIBER-FAIR-Data.pdf (accessed on 20 April 2020).
- Commission, E. Guidelines on FAIR Data Management in Horizon 2020. Available online: http://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf (accessed on 22 April 2020).
- Gartner. Data Governance. 2021. Available online: https://www.gartner.com/en/information-technology/glossary/data-governance (accessed on 18 April 2021).
- Talend. What is Data Governance. 2021. Available online: https://www.talend.com/resources/what-is-data-governance/ (accessed on 19 March 2021).
- European Data Portal. 2020. Available online: https://www.europeandataportal.eu/en/training/what-open-data (accessed on 22 April 2020).
- European Legislation on Open Data and the Re-use of Public. 2020. Available online: https://ec.europa.eu/digital-single-market/en/european-legislation-reuse-public-sector-information (accessed on 15 April 2020).
- Link, G.J.; Lumbard, K.; Conboy, K.; Feldman, M.; Feller, J.; George, J.; Germonprez, M.; Goggins, S.; Jeske, D.; Kiely, G.; et al. Contemporary Issues of Open Data in Information Systems Research: Considerations and Recommendations. Commun. Assoc. Inf. Syst. 2017, 41. [Google Scholar] [CrossRef]
- Mohan, S. Building a Comprehensive Data Governance Program. Available online: https://www.gartner.com/en/documents/3956689/building-a-comprehensive-data-governance-program (accessed on 27 August 2019).
- Calancea, C.G.; Alboaie, L.; Panu, A.; Swarm, A. ESB Based Architecture for an European Healthcare Insurance System in Compliance with GDPR. In International Conference on Parallel and Distributed Computing: Applications and Technologies; PDCAT 2018. In Communications in Computer and Information Science; Springer: Singapore, 2018; p. 931. [Google Scholar] [CrossRef]
- Cowan, D.; Alencar, P.; McGarry, F. Perspectives on Open Data: Issues and Opportunities. In Proceedings of the 2014 IEEE International Conference on Software Science, Technology and Engineering, Ramat Gan, Israel, 11–12 June 2014. [Google Scholar] [CrossRef]
- Fair, R.T. FAIR Data Point Specification. 2020. Available online: https://github.com/FAIRDataTeam/FAIRDataPoint-Spec (accessed on 18 May 2020).
- Fair, R.T. FAIR Data Point Metadata Specification. 2020. Available online: https://github.com/FAIRDataTeam/FAIRDataPoint-Spec/blob/master/spec.md (accessed on 18 May 2020).
- W3C. “WebAccessControl”. 2016. Available online: https://www.w3.org/wiki/WebAccessControl (accessed on 19 March 2021).
- PrivateSky Project. 2020. Available online: https://profs.info.uaic.ro/~ads/PrivateSky/ (accessed on 18 April 2021).
- Alboaie, S.; Ursache, N.C.; Alboaie, L. Self-Sovereign Applications: Return control of data back to people. In Proceedings of the 24th International Conference on Knowledge-Based and Intelligent Information & Engineering Systems, Verona, Italy, 16–18 September 2020. [Google Scholar]
- Alboaie, S.; Alboaie, L.; Zeev, P.; Adrian, I. Secret Smart Contracts in Hierarchical Blockchains. In Proceedings of the 28th International Conference on Information Systems Development (ISD2019), Toulon, France, 28–30 August 2019. [Google Scholar]
- Angular. 2020. Available online: https://angular.io (accessed on 15 May 2020).
- Apache Jena. 2020. Available online: https://jena.apache.org (accessed on 16 May 2020).
- Apache Jena Fuseki. 2020. Available online: https://jena.apache.org/documentation/fuseki2/index.html (accessed on 16 May 2020).
- Docker. 2020. Available online: https://www.docker.com/ (accessed on 20 May 2020).
- Alboaie, L.; Alboaie, S.; Panu, A. Swarm Communication—A Messaging Pattern Proposal for Dynamic Scalability in Cloud. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013. [Google Scholar]
- Alboaie, L. Towards a Smart Society through Personal Assistants Employing Executable Choreographies. In Proceedings of the Information Systems Development: Advances in Methods, Tools and Management (ISD2017 Proceedings), Larnaca, Cyprus, 6–8 September 2017. [Google Scholar]
- Voshmgir, S. Token Economy: How Blockchains and Smart Contracts Revolutionize the Economy; BlockchainHub: Berlin, Germany, 27 June 2019; ISBN/EAN: 9783982103822. [Google Scholar]
- PrivateSky. PrivateSky EDFS Explained. 2020. Available online: https://privatesky.xyz/?API/edfs/overview (accessed on 18 April 2021).
- PrivateSky. What is Swarm Communication? 2020. Available online: https://privatesky.xyz/?Overview/swarms-explained (accessed on 18 April 2021).
- PrivateSky. PrivateSky Secret Smart Contracts. 2020. Available online: https://privatesky.xyz/?Overview/Blockchain/secret-smart-contracts (accessed on 18 April 2021).
- PrivateSky. PrivateSky Architecture. 2020. Available online: https://privatesky.xyz/?Overview/architecture (accessed on 18 April 2021).
- PrivateSky. PrivateSky Interactions. 2020. Available online: https://privatesky.xyz/?API/interactions (accessed on 18 April 2021).
- Calancea, C.; Miluț, C.; Alboaie, L.; Iftene, A. iAssistMe—Adaptable Assistant for Persons with Eye Disabilities. In Proceedings of the Knowledge-Based and Intelligent Information & Engineering Systems: Proceedings of the 23rd International Conference KES2019, Budapest, Hungary, 4–6 September 2019. [Google Scholar]
- DataShareFair Source Code. 2020. Available online: https://bitbucket.org/meoweh/datasharefair/src/master/ (accessed on 15 July 2020).
- VAT. Identification Numbers. 2020. Available online: https://ec.europa.eu/taxation_customs/business/vat/eu-vat-rules-topic/vat-identification-numbers_en (accessed on 10 April 2020).
- DBpedia. 2020. Available online: https://wiki.dbpedia.org (accessed on 15 July 2020).
- Wikidata. 2020. Available online: https://www.wikidata.org/wiki/Wikidata:Main_Page (accessed on 15 July 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| <http://192.168.1.52:8087/fdp/catalogs/biohazard_catalog> a <http://www.w3.org/ns/dcat#Catalog>; <http://www.w3.org/2000/01/rdf-schema#label> “Biohazard catalog”; <http://purl.org/dc/terms/accessRights> <http://192.168.1.52:8087/fdp/catalogs/biohazard_catalog#accessRights>; <http://purl.org/dc/terms/conformsTo> <https://www.purl.org/fairtools/fdp/schema/0.1/catalogMetadata>; <http://purl.org/dc/terms/description> “A catalog that should contain datasets about artificial produced disasters in nature; data can be used to predict future disasters.”; <http://purl.org/dc/terms/hasVersion> “1”; <http://purl.org/dc/terms/identifier> “biohazard_catalog”; <http://purl.org/dc/terms/isPartOf> <http://192.168.1.52:8087/fdp/>; <http://purl.org/dc/terms/language> <http://id.loc.gov/vocabulary/iso639-1/cy>; <http://purl.org/dc/terms/license> <https://www.gnu.org/licenses/fdl-1.2.html>; <http://purl.org/dc/terms/publisher> <http://192.167.1.53:8087/fdp/organizations/CC28732>; <http://purl.org/dc/terms/title> “A new bright catalog”; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataIdentifier> <http://192.168.1.52:8087/fdp/catalogs/biohazard_catalog>; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataIssued> “1586882492976”^^<http://www.w3.org/2001/XMLSchema#dateTime>; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataModified> “1586882492976”^^<http://www.w3.org/2001/XMLSchema#dateTime>; <http://www.w3.org/ns/dcat#dataset> <http://192.168.1.52:8087/fdp/datasets/biohazard_dataset>, <http://192.168.1.54:8087/fdp/datasets/natural_disasters>; <http://www.w3.org/ns/dcat#themeTaxonomy> <http://dbpedia.org/resource/Category:Natural>, <http://dbpedia.org/resource/Category:Biohazard>. |
| <http://192.168.1.52:8087/fdp/datasets/biohazard_dataset> a <http://www.w3.org/ns/dcat#Dataset>; <http://www.w3.org/2000/01/rdf-schema#label> “Biohazards Dataset”; <http://purl.org/dc/terms/accessRights> <http://192.168.1.52:8087/fdp/datasets/pretty_dataset#accessRights>; <http://purl.org/dc/terms/conformsTo> <https://www.purl.org/fairtools/fdp/schema/0.1/datasetMetadata>; <http://purl.org/dc/terms/description> “Dataset that contains data about different kind of biohazards”; <http://purl.org/dc/terms/hasVersion> “1”; <http://purl.org/dc/terms/isPartOf> <http://192.168.1.52:8087/fdp/catalogs/biohazard_catalog>; <http://purl.org/dc/terms/language> <http://id.loc.gov/vocabulary/iso639-1/da>; <http://purl.org/dc/terms/license> <https://creativecommons.org/licenses/by/3.0/>; <http://purl.org/dc/terms/publisher> <http://192.167.1.53:8087/fdp/organizations/CC28732>; <http://purl.org/dc/terms/title> “Biohazards Dataset”; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataIdentifier> <http://192.168.1.52:8087/fdp/datasets/biohazard_dataset>; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataIssued> “2020-04-14T18:23:28.668Z”^^<http://www.w3.org/2001/XMLSchema#dateTime>; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataModified> “2020-04-14T18:23:28.668Z”^^<http://www.w3.org/2001/XMLSchema#dateTime>; <http://www.w3.org/ns/dcat#distribution> <http://192.168.1.52:8087/fdp/distributions/biohazard_danger_statistics>; <http://www.w3.org/ns/dcat#keyword> “hazard”, “biology”, “nature”; <http://www.w3.org/ns/dcat#theme> <http://dbpedia.org/resource/Category:Hazard>, <http://dbpedia.org/resource/Category:Nature>. |
| <http://192.168.1.52:8087/fdp/distributions/biohazard_danger_statistics> a <http://www.w3.org/ns/dcat#Distribution>; <http://www.w3.org/2000/01/rdf-schema#label> “Biohazard Dangers Statistics”; <http://purl.org/dc/terms/accessRights> <http://192.168.1.52:8087/fdp/distributions/biohazard_danger_statistics#accessRights>; <http://purl.org/dc/terms/conformsTo> <https://www.purl.org/fairtools/fdp/schema/0.1/distributionMetadata>; <http://purl.org/dc/terms/description> “This distribution aims to offer data about existing biohazardous substances that can be found and in which quantities”; <http://purl.org/dc/terms/hasVersion> “1”; <http://purl.org/dc/terms/isPartOf> <http://192.168.1.52:8087/fdp/datasets/biohazard_dataset>; <http://purl.org/dc/terms/language> <http://id.loc.gov/vocabulary/iso639-1/ch>; <http://purl.org/dc/terms/license> <https://www.apache.org/licenses/LICENSE-1.0>; <http://purl.org/dc/terms/publisher> <http://192.167.1.53:8087/fdp/organizations/CC28732>; <http://purl.org/dc/terms/title> “Biohazard Dangers Statistics”; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataIdentifier> <http://192.168.1.52:8087/fdp/distributions/biohazard_danger_statistics>; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataIssued> “2020-04-14T18:26:35.097Z”^^<http://www.w3.org/2001/XMLSchema#dateTime>; <http://rdf.biosemantics.org/ontologies/fdp-o#metadataModified> “2020-04-14T18:26:35.097Z”^^<http://www.w3.org/2001/XMLSchema#dateTime>; <http://www.w3.org/ns/dcat#downloadURL> <http://192.168.1.52:8087/uploads/b4db06ef-ce6e-4005-976a-e93385dad18a.zip>; <http://www.w3.org/ns/dcat#mediaType> “application/gzip”. |
| <http://192.168.1.52:8087/fdp/distributions/cat_sweet_dist#accessRights> a <http://purl.org/dc/terms/RightsStatement>; <http://purl.org/dc/terms/description> “This resource has access restriction”; <http://purl.org/dc/terms/isPartOf> <http://192.168.1.52:8087/fdp/authorizations/9f4603eb-120b-45be-9fbf-c2f533d7b2bb>, <http://192.168.1.52:8087/fdp/authorizations/1f3b1276-2d10-436f-8b38-55655b1c73c3>. <http://192.168.1.52:8087/fdp/authorizations/9f4603eb-120b-45be-9fbf-c2f533d7b2bb> a <http://www.w3.org/ns/auth/acl#Authorization>; <http://www.w3.org/ns/auth/acl#agent> <http://192.165.1.54:8087/fdp/organizations/CC29751>; <http://www.w3.org/ns/auth/acl#mode> <http://www.w3.org/ns/auth/acl#Read>. <http://192.168.1.52:8087/fdp/authorizations/1f3b1276-2d10-436f-8b38-55655b1c73c3> a <http://www.w3.org/ns/auth/acl#Authorization>; <http://www.w3.org/ns/auth/acl#agent> <http://192.167.1.53:8087/fdp/organizations/CC28732>; <http://www.w3.org/ns/auth/acl#mode> <http://www.w3.org/ns/auth/acl#Control>. |
| //Business Organization URI type specification <http://192.165.1.54:8087/fdp/organizations/CC29751> a <http://xmlns.com/foaf/0.1#Organization>; //property which specifies the unique identifier of the current resource <http://schema.org/Thing#identifier> “http://192.165.1.54:8087/fdp/organizations/CC29751”; //property which specifies the official web address of a business—for additional information <http://schema.org/Thing#url> “https://bio-research.com”; //property which specifies the popular/known name of the business <http://xmlns.com/foaf/0.1#name> “Biohazard Research Group”; //property which specifies an email contact address of the business <https://schema.org/Organization#email> “contact@biohazard-research.com” //property which specifies the legal and official name of the business <https://schema.org/Organization#legalName> “Biohazard Research Group”; //property which specifies the fiscal identifier for a business—also used to compose the unique identifier of the business <https://schema.org/Organization#vatID> “CC29751”; //property which specifies the official residence for a business—either the full address or just the global region <https://schema.org/Organization#address> “Europe”. |
| Category | Main Principle | Subprinciples | DataShareFair Data Modelling Applicability |
|---|---|---|---|
| Findable | F1. (Meta)data are assigned a globally unique and persistent identifier | − | Each dataset, catalog, distribution and organization resource has a uniquely generated identifier (fdp:metadataIdentifier property in Table 1, Table 2 and Table 3 and thing:identifier property in Table 5) |
| F2. Data are described with rich metadata (defined by R1 below) | − | Each distribution resource contains information about the issued and last update dates, keywords and intrinsic metadata that can be extracted from the uploaded distributions (fdp:metadataIssued and fdp:metadataModified from Table 3); this allows easy data discovery by automated processes or human filtering | |
| F3. Metadata clearly and explicitly include the identifier of the data they describe | Each Dataset contains a list of IRIs for all the available distributions (dcat:distribution from Table 2); distribution metadata is linked to the dataset metadata through the dcat:dataset property from Table 3; dataset metadata is linked to the catalog metadata through the dct:isPartOf property from Table 2 | ||
| F4. (Meta)data are registered or indexed in a searchable resource | − | The existing dataset metadata and its distribution’s metadata is indexed for human search in the DataShareFair Management Platform; for automated search, data will be available at FAIR data points in the network; this process in presented in Section 3.2 | |
| Accessible | A1. (Meta)data are retrievable by their identifier using a standardized communications protocol | A1.1 The protocol is open, free, and universally implementable | The used protocol for exchanging metadata in DataShareFair is swarm communication [26], which is open, free and universally implementable; exchanging data through the distributed fair data points can be achieved through the HTTPs communication; communication protocols are detailed in Section 3.2. |
| A1.2 The protocol allows for an authentication and authorization procedure, where necessary | Each business representative is authenticated with its own credentials to access shared data; for each request an authorization token is provided to validate the requestor’s identity | ||
| A2. Metadata are accessible, even when the data are no longer available | − | Stale data deletion is allowed; metadata remains intact and cannot be deleted; A catalog of datasets can never be deleted, even though the requester is one of the owners; this restriction is controlled from our FAIR data management platform, presented in Section 3.2. | |
| Interoperable | I1. (Meta)data uses a formal, accessible, shared, and broadly applicable language for knowledge representation | − | Catalogs, datasets, distributions and other resources will be stored in a graph-oriented database (Apache Jena) and they will be available in several interoperable and machine-readable formats such as: JSON-LD, OWL, XML; additional details are provided in Section 3.2.1 |
| I2. (Meta)data use vocabularies that follow FAIR principles | − | The vocabularies used to describe the datasets, catalogs, distributions are standardized and have external IRIs open for access to anyone interested; examples of such vocabularies: DCTERMS, FDP, RDF, XSD, DCAT—used in Table 1, Table 2, Table 3, Table 4 and Table 5 | |
| I3. (Meta)data include qualified references to other (meta)data | − | Each dataset resource contains a list of IRIs for all the available distributions using DCAT ontology (dcat:distribution property in Table 2) | |
| Reusable | R1. Meta(data) are richly described with a plurality of accurate and relevant attributes | R1.1. (Meta)data are released with a clear and accessible data usage licens | The type of license under which the data are distributed is mentioned in each Catalog, Dataset and Distribution resource (dcterms:license property in Table 1, Table 2 and Table 3) |
| R1.2. (Meta)data are associated with detailed provenance | This principle is covered by the dcterms:license and the dcterms:publisher properties in the distribution modelling from Table 3; Each distribution instance is connected to several access rights instances–in Table 4; they describe the limits of usage for a dataset reported to organizations—described in Table 5 | ||
| R1.3. (Meta)data meet domain-relevant community standards | Data shared by the businesses is organized in a standardized way by extracting and structuring the metadata according to the ontology specification; The storage of the distributions is done in a well-established and sustainable file format; Documentation (metadata) follows a common template and uses common vocabulary |
| Category of the Decisional Factor | Decisional Factor in B2B Data Exchange Fulfilment | DataShareFair Approach on B2B Challenges | Overall Contribution |
|---|---|---|---|
| Legal and Economical | Liability avoidance through clear license agreements | When creating any type of resource such as a catalog, dataset and distribution meant to structure data through metadata entries, a license agreement must be selected from a predefined list; this ensures any business is aware of the legal scope of usage when crawling the metadata; data providers are protected from any wrongful reuse of their data | + |
| Technical | Operational barriers caused by interoperability and standardization issues | DataShareFair proposes structured metadata to be extracted from the shared data; metadata is modelled hierarchically according to the FAIR data principles and proposed ontologies; this helps businesses create suitable automated data discovery and reuse mechanisms | + |
| Technical | Poor or insufficient quality of the data | Extracted metadata is well-structured, split in granular fields, each serving their own purpose; by addressing the standardization issue with a strict data model, high data quality standards are also ensured | + |
| Technical | Infrastructure costs regarding storage, security and curation of available data | Security of the data is covered by the encrypted data storage in ZIP archives, which are decrypted only for the authorized businesses; the delete option is also available for the distribution files referenced in a dataset; Data can be cleared in order to reduce storage costs, but extracted metadata is kept for historical traceback; Businesses are able to acknowledge the existence of deleted data and they can contact the provider (through the business information provided in metadata) for subsequent access if needed | + |
| Technical and Legal | Ownership rights assertion and definition of the legal extent to which data can be used | Claiming the rights of ownership over uniquely created data is possible through automatic extraction of the publishing company’s identity; the legal extent of data usage is specified by the owner throughout the attached agreement license, compulsory at the creation time of any dataset, catalog and distribution | + |
| Technical | Monitoring capabilities to control the extent of data usage | DataShareFair offers an integrated monitoring mechanism designed as an important feature of the PrivateSky platform; Each new transaction performed by an entity over data/metadata in the proposed marketplace is added to the blockchain log entries, where the business can obtain an overview over the means of usage for the provided data; | + |
| Economical | Costs associated to the skills development among employees within the company to analyze the available data | The proposed solution does not manage to fully cut the costs associated with training the personnel involved in the B2B data exchange process; It manages to slightly reduce the training time through a user-friendly designed tool which requires less training than going manually through unclassified TB of data; | − |
| Technical | Guidance, methodologies and systemic approaches for data sharing | The proposed B2B data exchange solution establishes a well-defined procedure for both data providers and data users; Both parties need to be authenticated with real fiscal information (VAT ID and digital certificate), data is hierarchically organized based on the provided metadata and stored as encrypted ZIP archives in order to enhance security; data can be filtered and found based on the metadata information; access can be gained either through access requests or through direct authorization provided by the owner; Data can be managed only by the owners and people with minimum write access level; | + |
| Technical and Legal | Establishing trust with partners when sharing data | The trust component between two or many business entities is facilitated in DataShareFair through the access rights semantic model, applied over the shared data and metadata; A data provider can choose from different access levels when allowing another business to work with their data; Businesses can receive group access to resources if a joint legal agreement was put in place; The access policies management allows a data owner to also remove existing authorizations in case conditions of the legally binding agreement are broken; | + |
| Technical and Legal | Ensuring compliance with regulations such as General Data Protection Regulation (GDPR) | DataShareFair manages to ensure compliance with the GDPR legislation by offering sensitive data storage in encrypted blocks over the blockchain; When a business account is deleted, all private information such as email and phone number are erased from the system; only the unique FAIR identifier of the company is kept to ensure the consistency of the metadata semantic model; Distribution data provided by a business is GDPR compliant at the FAIRification step, prior to sharing; | + |
| Technical and Economical | Addressing concerns that data sharing could result in a loss of business competitiveness or exposure of trade secrets | A step forward in this direction brought by DataShareFair is encapsulated in the PrivateSky underlying technology; PrivateSky offers a mechanism to detect faulty nodes in the network through the OBFT consensus algorithm used for transaction validation; When an illegitimate node is detected, the data flow through the network is interrupted to avoid delivering it to unauthorized entities; the risk to expose important information to untrusted entities is significantly reduced; | + |
| Technical | Denial or unforeseen termination of access to the datasets by the data supplier | Businesses are not guaranteed unlimited access to existing distributions because of infrastructure costs on the data providers side; nonetheless, datasets, catalogs and distributions metadata cannot be deleted or hidden from marketplace by the data owners; this allows the data user to retrieve and mine relevant metadata and request access to data from the owner directly through the DataShareFair platform; | + |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calancea, C.G.; Alboaie, L. Techniques to Improve B2B Data Governance Using FAIR Principles. Mathematics 2021, 9, 1059. https://doi.org/10.3390/math9091059
Calancea CG, Alboaie L. Techniques to Improve B2B Data Governance Using FAIR Principles. Mathematics. 2021; 9(9):1059. https://doi.org/10.3390/math9091059
Chicago/Turabian StyleCalancea, Cristina Georgiana, and Lenuța Alboaie. 2021. "Techniques to Improve B2B Data Governance Using FAIR Principles" Mathematics 9, no. 9: 1059. https://doi.org/10.3390/math9091059
APA StyleCalancea, C. G., & Alboaie, L. (2021). Techniques to Improve B2B Data Governance Using FAIR Principles. Mathematics, 9(9), 1059. https://doi.org/10.3390/math9091059