Abstract
The nonhomogeneous Poisson process model with power law intensity, also known as the Army Materiel Systems Analysis Activity (AMSAA) model, is commonly used to model the reliability growth process of many repairable systems. In practice, it is necessary to test the reliability of the product under different operational environments. In this paper we introduce an AMSAA-based model considering the covariate effects to measure the influence of the time-varying environmental condition. The parameter estimation of the model is typically performed using maximum likelihood on the failure data. The statistical properties of the estimation in the model are comprehensively derived by the martingale theory. Further inferences including confidence interval estimation and hypothesis tests are designed for the model. The performance and properties of the method are verified in a simulation study, compared with the classical AMSAA model. A case study is used to illustrate the practical use of the model. The proposed approach can be adapted for a wide class of nonhomogeneous Poisson process based models.
1. Introduction
A repairable system is a system that can undergo reparation by mending or replacing some system components rather than re-establishing the entire system after failing. Most of the contemporary complex systems are repairable—for instance, communication systems, software systems, automobile engines, helicopters, and aircraft generators all belong to the repairable category. The reliability of some repairable systems can be improved by a test, analyze, and fix process, where system failures are identified and corrective actions are implemented until the reliability reaches a prespecified level. This procedure of improvement is called the reliability growth process, or the reliability growth test.
The reliability growth test is a powerful tool to improve repairable system’s reliability by identifying and repairing failure units, which has been widely used in many industries [1]. In the testing, data of failure times are collected to assess the changing trend of the product’s reliability growth. A variety of reliability models have been developed to study these testing data. Duane [2] first introduced the reliability growth model for aircraft engines by using the learning curve to describe the relationship between the cumulative failure rate and the cumulative testing time. Crow [3] further delved into the stochastic extension of Duane’s model, where failures can be represented as a nonhomogeneous Poisson process (NHPP) with Weibull intensity, which is also called a power law process [4]. The developed model is now known as the Army Materiel Systems Analysis Activity (AMSAA) model and has been popular, with multiple applications in industrial areas including automobiles [5], health care [6], power systems [7], and coal mining [8]. Subsequently, more forms of the NHPP model have been introduced to characterize the time-varying rates, such as the log-linear intensity model [9] and the exponential-trigonometric intensity model [10]. The statistical theory of the classical AMSAA model has been intensively studied as well. Some of these efforts focused on confidence interval estimation [11,12], future reliability estimation [13], first passage time problem [14], model selection [15] and goodness-of-fit test [16].
More recently, an increasing number of extensions of the AMSAA model have been proposed to foster product development. For instance, Somboonsavatdee et al. [17] investigated the statistical inference of the AMSAA model under competing risks; Peng et al. [18] proposed a novel method to evaluate and predict the dynamic reliability of a repairable system subjected to the interval-censoring problem based on the AMSAA model; Hu et al. [19] designed a robust decision method for the planning of reliability growth testing by integrating information gap decision theory and the AMSAA model. A compelling improvement to the AMSAA model is the incorporation of heterogeneity—an inclusion of individual-specific factors or covariates that may affect the reliability growth process. To measure the impact of operational and environmental factors, it is essential to take covariate effects into consideration, and several studies have already displayed this awareness. Van Dyck and Verdonck [20] extended the AMSAA model by introducing a multiplicative covariate factor with the interpretation of a known scaling of the system’s failure character. Similarly, Slimacek and Lindqvist [21] introduced a novel approach for the statistical modeling of failures where nonparametric frailty and covariates were considered in the NHPP model. In addition to the NHPP-based models, proportional hazard models are also able to delineate the covariate effects; however, they make no distributional assumptions about the failure process [22].
Among all the contemporary analyses of repairable systems with covariates or environmental effects, the majority are conducted over reliability growth tests for multiple experimental individuals, machines, or systems. However, with the present rising reliability requirements and the increasing product useful life, the cost of conducting reliability growth tests often becomes exorbitant. Because test costs and the availability of test subjects can sometimes be a barrier to the progression of reliability growth tests, it is more practical and economical to conduct tests with a single test subject under different experimental conditions; in other words, it would be more desirable if the covariates were time-dependent and the data were collected from one sample path. These time-varying covariates can include local climatic conditions like temperature and humidity or operational factors like current intensity and rotating speed, which can all be dynamically monitored during the test. To our best knowledge, there have been few comprehensive investigations on the AMSAA model with such test settings. In this paper, we model the data of a reliability growth test in a time-varying environment through an extended AMSAA model.
In a classical AMSAA model, the parameters can be estimated by using maximum likelihood estimation (MLE) with analytic forms, whose exact distributions can be derived as chi-square distributions [3]. However, since there is no analytic form for MLE in the extension, it is challenging to discuss the properties of MLE. Moreover, most NHPP-based works on repairable systems develop estimations and inferences from the classical MLE theory, which is not readily applicable to small sample data with dependence. With these previous limitations in mind, the statistical properties of MLE and further inferences of the model are derived comprehensively from the martingale theory in the present study. The rest of this paper is organized as follows. In Section 2, we establish the AMSAA model with time-varying covariates of environmental effects. The method and property of the parameter estimation are discussed in Section 3. More statistical inference paradigms are developed in Section 4. A comprehensive simulation study and a case study are described in Section 5 and Section 6. A final discussion and an overview of the study are presented in Section 7.
2. AMSAA Model with Time-Varying Covariates
When evaluating the reliability of complex repairable systems with counting process models, each event in the process represents one instance of a failure of the system. The counting process is said to be a nonhomogeneous Poisson process with intensity function , if it satisfies:
- ;
- has independent increments;
- ;
- .
Under the conditions in the definition of NHPP, the distribution of the number of events that occurred in , , can be obtained from:
where . Let denote the number of events that occurred before time t. If we observe n events in the interval and the events occurred at times , the desired joint probability density function with takes the form,
Several forms of the intensity function have been used in modeling the process of reliability growth. In the present study, we considered the celebrated power law intensity adopted in AMSAA model, that is, . The expected event number up to time t is .
When operating the testing machine in environmental or operational conditions that are dynamic, external factors (e.g., temperature and stress) and internal factors (e.g., speed) will influence the reliability growth process of the machine. Now suppose that for the system there is a d-dimensional time-dependent covariate vector that affects the intensity of events’ occurrence. Note that may be deterministic or random, continuous or discrete about testing time. A deterministic and discrete situation is the most common due to the multi-stage experiment design, where the experimental conditions are changed in each stage. To quantify the reliability growth process with time-dependent covariate effects, some assumptions are made for the model.
Assumption 1.
is right-continuous with limits from the left and bounded almost surely.
Assumption 2.
The base reliability growth process under a standard condition evolves as a power law process.
Assumption 3.
impacts the failure intensity by a multiplicative factor , where is a d-dimensional constant vector.
Assumption 1 is satisfied in most cases in reality. Usually, is the monitoring data, which can be observed up to time t. The bounding condition restricts the covariate effect within a reasonable range so that the expected failure will tend to infinity as the operational time tends to infinity. Assumption 2 is also a common assumption that characterizes evolving pattern of a product’s reliability with normal use. In Assumption 3, the model we consider for the inclusion of is of the Cox type. This gives us the intensity and the expectation function with covariate effects respectively:
In the model, , , and are unknown parameters, with and being positive. As a well-known property of the counting process, we have the following martingale property for the model.
Property 1.
is a square integrable martingale with respect to the filtration , and its predictable variation process is .
Further properties and theories of the counting process and martingale can be found in [23].
3. Maximum Likelihood Estimation
The maximum likelihood method is considered for estimating the unknown parameters , and . The log-likelihood of (2) is given by
Then, the estimation values can be obtained by the optimization problem,
The first-order partial derivatives of the log-likelihood are
The parameter estimation can be computed by setting the partial derivatives equal to zero and solving the equations. However, there is one key problem that requires discussion before the computation—the existence and uniqueness of the solution. We will prove the property by constructing conditional likelihood.
Consider the conditional distribution of given . The conditional distribution is given by the distribution of the order statistics of the random variable t whose density function is . Note that the distribution function does not contain the parameter . As a result, the conditional log-likelihood function is given by
We have the following lemma for the conditional log-likelihood.
Lemma 1.
The maximum likelihood estimator for the log-likelihood (9) exists and is unique with probability 1 as the time tends to infinity. Moreover, the estimator is strongly consistent.
Proof.
The problem is equal to discussing the existence and uniqueness of the maximum likelihood estimation of the parameters for n independent and identically distributed random variables with density function . Furthermore, is an exponential distribution family with natural parameter α and . Note that with probability 1 as . Then, the property in the lemma is derived by the theory of classical repeated sampling from an exponential family [24]. □
The estimator in the lemma gives the same solution with that of (5) for and . We will prove the existence, uniqueness and consistency for the estimator of full log-likelihood in the following theorem.
Theorem 1.
The maximum likelihood estimator from (5) exists and is unique with probability 1 as the time tends to infinity. Moreover, the estimator is strongly consistent.
Proof.
The estimation for and in optimization (5) is equal to maximizing the conditional likelihood (9), which derives from the direct calculations shown in Appendix A. Due to the analytic form of with and given by (10), the existence and uniqueness are held for (5). The strong consistency of and is given by Lemma 1.
As shown in Property 1, is a square integrable martingale, whose predictable variation process is . By Liptser’s law of large numbers for martingales [25], we have
almost surely on . With the discussion on Assumption 1, we know that holds almost surely. Then, with the consistency of and ,
almost surely, where denotes the expectation function with parameters , and . Hence, is strongly consistent. □
With all the proofs above, the full log-likelihood function of the observations can be factorized as follows:
where, is given by (9) and
Then, the optimization (5) can be factorized as follows, which may help to simplify the numerical calculation in practice.
4. Statistical Inference
In this section, we will discuss the distribution of the maximum likelihood estimation, which is expected to be asymptotically normal in most cases, as well as some inferences for the proposed model.
4.1. Asymptotic Normality of the Parameter Estimation
Before discussing normality, we present the martingale property of the score function.
Property 2.
Denote by θ. The score function denoted by is a square integrable martingale with mean zero with respect to the filtration .
The property follows from the fact that can be formulated as . The specific form of can be extracted from (6), (7), and (8). With this property, the asymptotic normality of the maximum likelihood estimator can now be deduced by standard arguments.
Theorem 2.
Suppose is the maximum likelihood estimator given by (5). Then,
as , where and is the identity matrix.
Proof.
On series expansion, we see that
where and is a convex combination of and . Therefore,
where
It follows from the central limit theorem for martingales [26] that
Because and are asymptotically equivalent and the consistency of , A tends to zero in probability as . Therefore, we get the asymptotic normality of . □
Remark 1.
and are well known as the expected information matrix and observed information matrix, respectively. The concrete forms are displayed in Appendix B. Due to the asymptotic equivalence of these two information matrices, in the theorem can be replaced by .
4.2. Inference of MTBF
The mean time between failures (MTBF) describes the expected time between two failures for a repairable system, and is a very important indicator in the process of reliability growth. Under the setting of NHPP, the mean time between failures at time t, , is . With the parameters estimated, the estimation of can be given by
is a continuous and differentiable function of . The distribution of can be given by the delta method as:
where
Then, the confidence interval estimation of can be computed in the form by plugging in ,
where is the th percentile of the standard normal distribution.
Note that the is a transient index computed under the time dimension of the accelerated reliability growth test, where the accelerated factor is decided by the covariate effects. In practice, we also want to know what the reliability of the machine would be like if there have been faults fixed in normal use; such a reliability can be inferred from the MTBF at in a standard condition test, where the expected cumulative number of failures at t under covariate effects is equal to the expected cumulative number of failures at under the standard conditions.
To distinguish between the two MTBF types, we will use to denote the latter. There exists a measurable map from the test time t with covariate effects to the equivalent time in the standard condition so that the transformed process denoted by is an NHPP with intensity function and expectation function . The aforementioned setup yields:
Subsequently, the estimated for the testing time t in the test with covariate effects is
The confidence interval is given by
where .
Furthermore, we generalize the MTBF to the situation where faults have been fixed for the machine under the covariate effects of , with parameter being known. A new map for the testing time is constructed in a similar manner to that of (28),
where . Note that the map is one-to-one due to the monotonically increasing property of . Therefore, the estimation for is
4.3. Hypothesis Test for Covariate Effects
The inference of the covariate effects can be accomplished by using likelihood ratio tests. Consider the hypothesis test problem,
where . The test aims to check whether the covariates in the subset S influence the reliability growth process significantly. The likelihood ratio test is designed to achieve this purpose. The likelihood ratio statistic can be given by
where represents the vector excluding . By Wilks’ theorem, under , has an asymptotic distribution of , where is the cardinal number of the set S. Then, the null hypothesis will be rejected at a significance level of if is greater than the 95th percentile of , indicating that the covariate effects of are significant.
5. Simulation Study
The functionalities of the proposed model and estimation method are validated in the simulation study. Data of time points when failures happen are simulated by a non-homogeneous Poisson process whose intensity function is defined as (3). The time-dependent covariate effect is considered as a step function which occurs when the environmental factor (e.g., temperature) is changed as designed at some points during the test. The values of the step function are defined in Table 1.

Table 1.
Step covariate function.
The parameters in the model are set as, , , and . The failure points of the process are generated by the thinning approach [27], which applies thinning to the points generated from a homogeneous Poisson process with a rate parameter equal to the maximum of the intensity function. MLE is done for the simulated data and the procedure is repeated 1000 times. The estimation results are summarized in Table 2.
Table 2.
Simulation results.
From the results, we can conclude that the MLE results are close to the true values, with relatively small mean square errors (MSEs). The standard deviations of the estimates almost perfectly match the theoretical standard deviations computed from the square root of the inverse of the expected information matrix. As a means of comparison, the classical AMSAA model without considering the covariate effects is fitted as well. This model has a mean of 0.66 and a standard deviation of 0.1991 for ; the mean of is 0.5728 with a standard deviation of 0.0263. The deviation between the estimation of the classical AMSAA model and the true parameters in the base intensity is perceptibly large. In order to further compare the performance in fitting the reliability growth trend, the fitted intensity functions are plotted with the means of MLEs in Figure 1. The curve of the intensity estimated by the AMSAA model with covariate effects is within the confidence band, while the curve of the classical AMSAA model deviates considerably large from the true curve. The comparison result again tellingly emphasizes the indispensability of considering covariate effects.
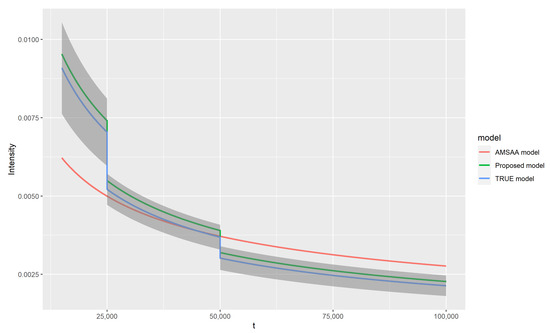
Figure 1.
Intensity functions on in different models. The grey area is the confidence band constructed by the true parameters. For the sake of comparison and neatness, the confidence band is constructed around the true curve rather than the two estimated curves. The band width is the same as that of the proposed model, which is computed with the delta method by plugging in the true parameter values.
Another aspect in the simulation study that calls for verification is the normality of the estimators. The quantile-quantile (Q-Q) plot method is employed to show the distributions of , , and , which are presented in Figure 2. As expected, the scattered points are distributed around the line except for the most extreme values, and this pattern indicates a good fit. Therefore, it is plausible to conclude that the estimator is approximately normally distributed in practice.
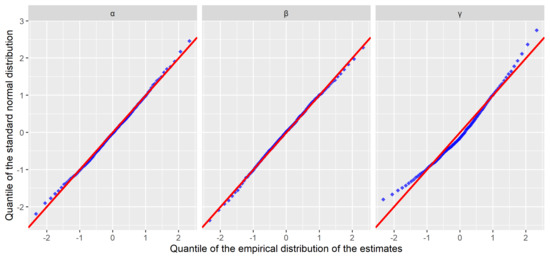
Figure 2.
Quantile-quantile plot. The quantiles of the the empirical distributions are calculated with the normalized estimation results.
The relationship between MSE, which is computed by the mean square norm of , and testing time is studied as well. The maximum testing time is increased from to with a step size of . The testing time of each phase is increased proportionally. For each testing time, the procedure of simulation and estimation is repeated 1000 times. As seen in Figure 3, MSE decreases with the increase of testing time, which illustrates the consistency of the estimates.
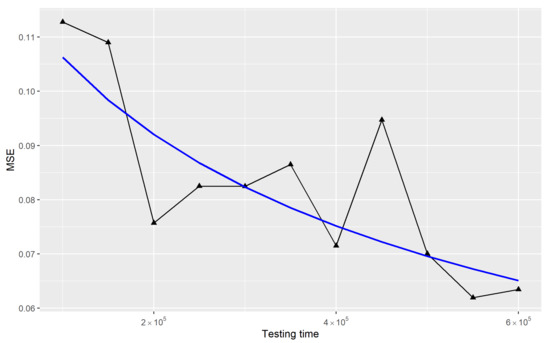
Figure 3.
The relationship between mean square error (MSE) and testing time. The blue curve is the trend line fitted by the formula .
6. Case Study
The data used in the case study is obtained from a real dataset collected in a reliability growth test during the development phase of an engine. In the test, the engine was tested in four phases with different operational conditions, and the failure times were recorded. Some summary statistics are provided in Table 3.
Table 3.
Description of the dataset.
In this particular case, it is impossible to monitor all aspects of the environment. So, the covariate in table is generated from scoring by experts, and is the evaluation for the stress intensity of the environment. More specially, the testers rate the stress intensity of the experimental environment as based on the sensitive parameters of the engine, such as gas pressure, temperature, and rotation speed.
We estimate the parameters by maximizing the log-likelihood. The estimation results are shown in Table 4. The value is less than 1, which suggests that the reliability of the machine is improved in the testing procedure. The positive implies that the increase in the stress intensity of the environment accelerates the process of the fault exposure.
Table 4.
Estimation results.
With the estimated parameters, we estimate and its confidence interval at the failure points. The estimation results are plotted in Figure 4. As shown in the figure, grows as testing time increases in each phase, and the growth rate is attenuating. The MTBFs for other operational conditions at the end of the test are also calculated through (32). The estimations and their confidence intervals are presented in Table 5. The first row of the table presents the reliability computed in the experiment condition; the other three rows are the transformation results estimated for the testing machine put in each of the remaining operational conditions, respectively. However, due to the short test duration in the present study, the variance of the estimation is relatively large. This limitation can be addressed in the future by incorporating a longer testing time so that a more accurate set of data can be obtained.
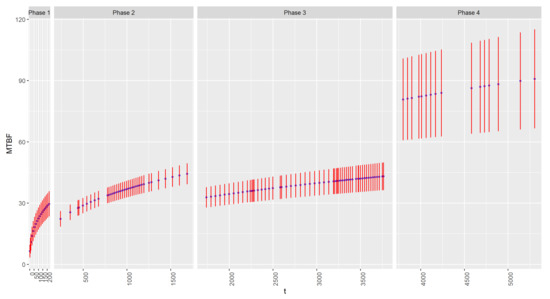
Figure 4.
and confidence intervals at the failure points. Red lines represent the range of the confidence intervals.
Table 5.
Estimations for MTBF and their confidence intervals.
In the model, the stress intensity of the experimental environment is reflected by the covariate scored by experts. An alternative method is to treat the stress intensity as a latent variable and incorporate it into . In this case, we can set as a 2-dimensional dummy variable, that is,
With the set of , the values of and in the coefficient vector represent the environmental stress intensity of Phases 2 and 3 during the test, respectively. The estimation results for the alternative model are shown in Table 6. It is shown that the stress intensity of Phase 3, , is the highest, which is in line with the expert score. Note that is close to 0; we use the likelihood ratio test (33) to check whether . The test statistic takes the value , which is less than the 95th percentile of . So, the null hypothesis of cannot be rejected. The hypothesis test result fails to correspond to the actual setting of the test, where the environmental stress of Phase 2 is significantly stronger than that of the normal case. The increase in the number of parameters and the absence of experimental information render the model more susceptible to data fluctuations, which leads to greater estimation variance and insignificant estimation results. In future tests, this can be improved by increasing the length of testing time and collecting more monitoring information on the sensitive parameters of the tested engine.
Table 6.
Estimation results.
7. Discussion
In this paper, we investigate an extension of the AMSAA model where the influence of the environment is considered as a time-dependent covariate vector. The covariate effects are incorporated into the AMSAA model as a proportional factor in the intensity function. To estimate the parameters in the NHPP-based model, the maximum likelihood estimation method is adopted. The properties of MLE, including existence, uniqueness, consistency, and asymptotic normality, are proved with several martingale properties of the designed counting process. Based on the MLE properties, the confidence interval estimation of the reliability measurement, mean time between failures, is deduced by the delta method. Moreover, a likelihood ratio test is designed to test whether any covariates influence the reliability growth process significantly. We verify the property and the efficiency of the proposed model in the simulation study, where a comparison is made with the classical AMSAA model. The results of the simulation demonstrate the necessity of taking covariate effects into account. A case study is conducted on the data collected from a multi-phase reliability growth test. We illustrate the practical use of the model by estimating the parameters and the MTBFs for the testing machine.
The proposed model is formulated based on the AMSAA model, in which failures are modeled by an NHPP whose intensity function corresponds to the power law. Nevertheless, the modeling approach and the proofs of its properties can be applied to NHPP models with an exponential family intensity function, which enables our model to be readily extended to these models. Furthermore, the covariate effects can be incorporated into the reliability growth model in more generalized forms in future work. As for application, our model can play an essential role in the design and planning of future reliability growth experiments, especially multi-stage reliability experiments.
Author Contributions
Conceptualization, X.-Y.T. and X.-J.Y.; methodology, X.-Y.T., X.S., and X.-J.Y.; software, X.-Y.T., X.S., and C.P.; validation, X.S., C.P., and X.-Y.T.; formal analysis, X.-Y.T.; investigation, X.-Y.T. and X.-J.Y.; resources, X.-J.Y.; data curation, X.-J.Y. and X.-Y.T.; writing—original draft preparation, X.-Y.T.; writing—review and editing, X.-Y.T., X.S., and X.-J.Y.; visualization, X.-Y.T.; supervision, X.-J.Y.; project administration, X.-J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 71801196.
Data Availability Statement
Data sharing is not applicable to this article.
Acknowledgments
We would like to thank the editor and reviewers for their constructive comments and suggestions, which have considerably improved this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AMSAA | Army Materiel Systems Analysis Activity |
| MLE | Maximum likelihood estimation |
| MTBF | Mean time between failures |
| NHPP | Nonhomogeneous Poisson process |
Appendix A. Estimation in the Conditional Log-Likelihood
Appendix B. Information Matrix
References
- Li, M.; Xu, D.; Li, Z.S. A joint modeling approach for reliability growth planning considering product life cycle cost performance. Comput. Ind. Eng. 2020, 145, 106541. [Google Scholar] [CrossRef]
- Duane, J.T. Learning Curve Approach to Reliability Monitoring. IEEE Trans. Aerosp. 1964, 2, 563–566. [Google Scholar] [CrossRef]
- Crow, L.H. Reliability Analysis for Complex, Repairable Systems. In Reliability and Biometry; Proschan, F., Serfling, R.G., Eds.; SIAM: Philadelphia, PA, USA, 1974; pp. 379–410. [Google Scholar]
- Rigdon, S.E.; Basu, A.P. The Power Law Process: A Model for the Reliability of Repairable Systems. J. Qual. Technol. 1989, 21, 251–260. [Google Scholar] [CrossRef]
- Guo, H.; Zhao, W.W.; Mettas, A. Practical methods for modeling repairable systems with time trends and repair effects. RAMS ’06. Annu. Reliab. Maintainab. Symp. 2006, 2006, 182–188. [Google Scholar] [CrossRef]
- Taghipour, S.; Banjevic, D. Trend analysis of the power law process using Expectation–Maximization algorithm for data censored by inspection intervals. Reliab. Eng. Syst. Saf. 2011, 96, 1340–1348. [Google Scholar] [CrossRef]
- Tang, Z.; Zhou, W.; Zhao, J.; Wang, D.; Zhang, L.; Liu, H.; Yang, Y.; Zhou, C. Comparison of the Weibull and the Crow-AMSAA Model in Prediction of Early Cable Joint Failures. IEEE Trans. Power Deliv. 2015, 30, 2410–2418. [Google Scholar] [CrossRef]
- Li, D.; Tao, Y. Reliability Analysis of Emulsion Pump Based on Fault Tree and AMSAA Model. In Proceedings of the 2019 International Conference on Quality, Reliability, Risk, Maintenance, and Safety Engineering (QR2MSE), Zhangjiajie, China, 6–9 August 2019; pp. 545–550. [Google Scholar] [CrossRef]
- Coetzee, J.L. The role of NHPP models in the practical analysis of maintenance failure data. Reliab. Eng. Syst. Saf. 1997, 56, 161–168. [Google Scholar] [CrossRef]
- Lee, S.; Wilson, J.R.; Crawford, M.M. Modeling and simulation of a nonhomogeneous poisson process having cyclic behavior. Commun. Stat. Simul. Comput. 1991, 20, 777–809. [Google Scholar] [CrossRef]
- Gaudoin, O.; Yang, B.; Xie, M. Confidence Intervals for the Scale Parameter of the Power-Law Process. Commun. Stat. Theory Methods 2006, 35, 1525–1538. [Google Scholar] [CrossRef]
- Wang, B.X.; Xie, M.; Zhou, J.X. Generalized Confidence Interval for the Scale Parameter of the Power-Law Process. Commun. Stat. Theory Methods 2013, 42, 898–906. [Google Scholar] [CrossRef]
- Muralidharan, K.; Shah, R.; Dhandhukia, D.H. Future Reliability Estimation Based on Predictive Distribution in Power Law Process. Qual. Technol. Quant. M. 2008, 5, 193–201. [Google Scholar] [CrossRef]
- Di Crescenzo, A.; Martinucci, B. On a First-Passage-Time Problem for the Compound Power-Law Process. Stoch. Models 2009, 25, 420–435. [Google Scholar] [CrossRef]
- Oliveira, M.D.D.; Colosimo, E.A.; Gilardoni, G.L. Power Law Selection Model for Repairable Systems. Commun. Stat. Theory Methods 2013, 42, 570–578. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, J. A New Goodness-of-Fit Test Based on the Laplace Statistic for a Large Class of NHPP Models. Commun. Stat. Simul. Comput. 2005, 34, 725–736. [Google Scholar] [CrossRef]
- Somboonsavatdee, A.; Sen, A. Statistical Inference for Power-Law Process with Competing Risks. Technometrics 2015, 57, 112–122. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y.; Zi, Y.; Tsui, K.L.; Zhang, C. Dynamic reliability assessment and prediction for repairable systems with interval-censored data. Reliab. Eng. Syst. Saf. 2017, 159, 301–309. [Google Scholar] [CrossRef]
- Hu, J.M.; Huang, H.Z.; Li, Y.F. Reliability growth planning based on information gap decision theory. Mech. Syst. Signal Process. 2019, 133, 106274. [Google Scholar] [CrossRef]
- Van Dyck, J.; Verdonck, T. Precision of power-law NHPP estimates for multiple systems with known failure rate scaling. Reliab. Eng. Syst. Saf. 2014, 126, 143–152. [Google Scholar] [CrossRef]
- Slimacek, V.; Lindqvist, B.H. Nonhomogeneous Poisson process with nonparametric frailty and covariates. Reliab. Eng. Syst. Saf. 2017, 167, 75–83. [Google Scholar] [CrossRef]
- Barabadi, A.; Barabady, J.; Markeset, T. Application of reliability models with covariates in spare part prediction and optimization–A case study. Reliab. Eng. Syst. Saf. 2014, 123, 1–7. [Google Scholar] [CrossRef]
- Fleming, T.R.; Harrington, D.P. Counting Processes and Survival Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 169. [Google Scholar]
- Wei, B.C. Exponential Family Nonlinear Models; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1. [Google Scholar]
- Liptser, R. A strong law of large numbers for local martingales. Stochastics 1980, 3, 217–228. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.E.; Sørensen, M. A review of some aspects of asymptotic likelihood theory for stochastic processes. Int. Stat. Rev. Int. Stat. 1994, 133–165. [Google Scholar] [CrossRef]
- Lewis, P.A.W.; Shedler, G.S. Simulation of nonhomogeneous poisson processes by thinning. Nav. Res. Logist. Q. 1979, 26, 403–413. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).