
The Impact of Candidates’ Profile and Campaign Decisions in Electoral Results: A Data Analytics Approach

 ,
,  ,
,
Abstract
1. Introduction and Motivation
2. Data and Methods
2.1. Parliamentary Elections in Chile in 2017
2.2. Data and Variables
- Personal information: The gender variable is used, with the objective of detecting, on the one hand, the significant differences in access to resources by the candidates and, on the other hand, the effect of incorporating gender quotas (see [23,24], for details). Thus, if women have access to a lower campaign budget than men and this difference in resources explains the different electoral strategies, then it is likely that gender has an impact on electoral performance.
- Political orientation: Since 1990, the party system in Chile has been built on the basis of two large coalitions [25]. Therefore, it is expected that the change to the electoral system-implemented by the center-left coalition-will favor the electivity of the most institutionalized parties. For this, the party or political conglomerate of the candidate is identified with the attribute coalition.
- Political experience: The incumbency attribute is introduced to represent whether the candidate has held the same position to which he or she is running in the period prior to the elections under study, an idea that is based on his systematic superiority in electoral outcomes [26]. Additionally, the attribute of years in office is incorporated to study the impact of the time spent in the position for which he or she is running and an elected official by popular vote attribute to analyze the impact of candidates who have held positions of local representation (city councilors, mayors, governors, etc.) prior to the elections. The values of all the variables of this dimension were extracted from the Library of the National Congress of Chile [27].
- Percentage of communes visited, which corresponds to the fraction of communes in the district visited by the candidate.
- Percentage of individual visits, which corresponds to the fraction of visits that the candidate makes without other candidates of his or her coalition.
- 3.
- Percentage of visits to new communes, which corresponds to the fraction of visits made by the candidate to new communes in his district.
- 4.
- Percentage of new communes visited, which corresponds to the fraction of new communes in the district that are visited by the candidate.
2.3. Data Analytics Algorithms
2.4. Method Outline and Implementation
- Compile information on the candidates for deputies in the 2017 elections in Chile from their official Facebook accounts, the library of the National Congress, and the SERVEL website.
- Refine and pre-process data obtained from Facebook using text extraction, examination, and data visualization techniques. This step is carried out following the methodology proposed in [50]:
- Preprocessing the files by term extraction.
- Structuring and storage of the contents as intermediate representation, through lists of communes associated with the district to which each candidate runs.
- Application of analysis techniques on the intermediate representation through distribution analysis.
- Visualization of the results.
Additionally, in this step, all the data are accumulated and sorted to generate a sample where each candidate is represented by a class and a set of attributes. - Train the methods described in Section 2.3 with a subsample extracted from Step 2.
- Apply the classification methods trained in Step 3 to the candidates of the prediction sample (in the case of the variables associated with territorial deployment, for each candidate the mean values of these variables observed in the candidates from the training list are imputed).
- Compare the accuracy of the classification methods on the prediction sample. Select the method with the best accuracy value.
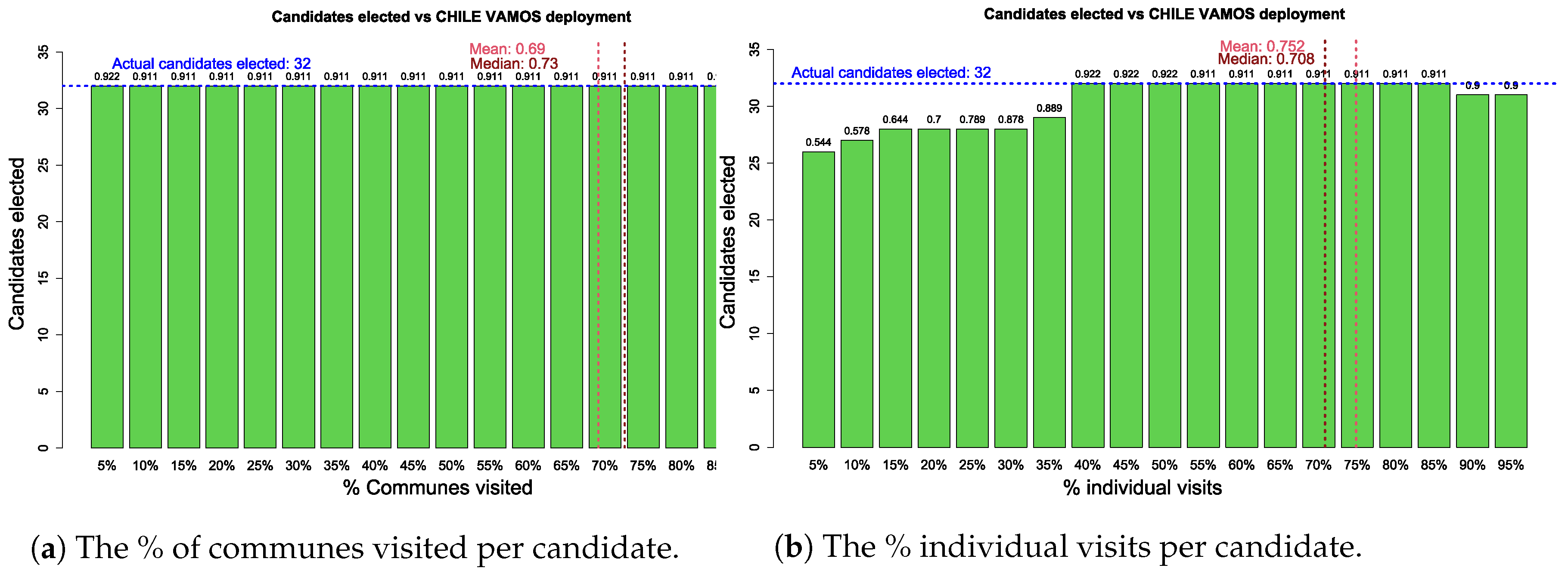
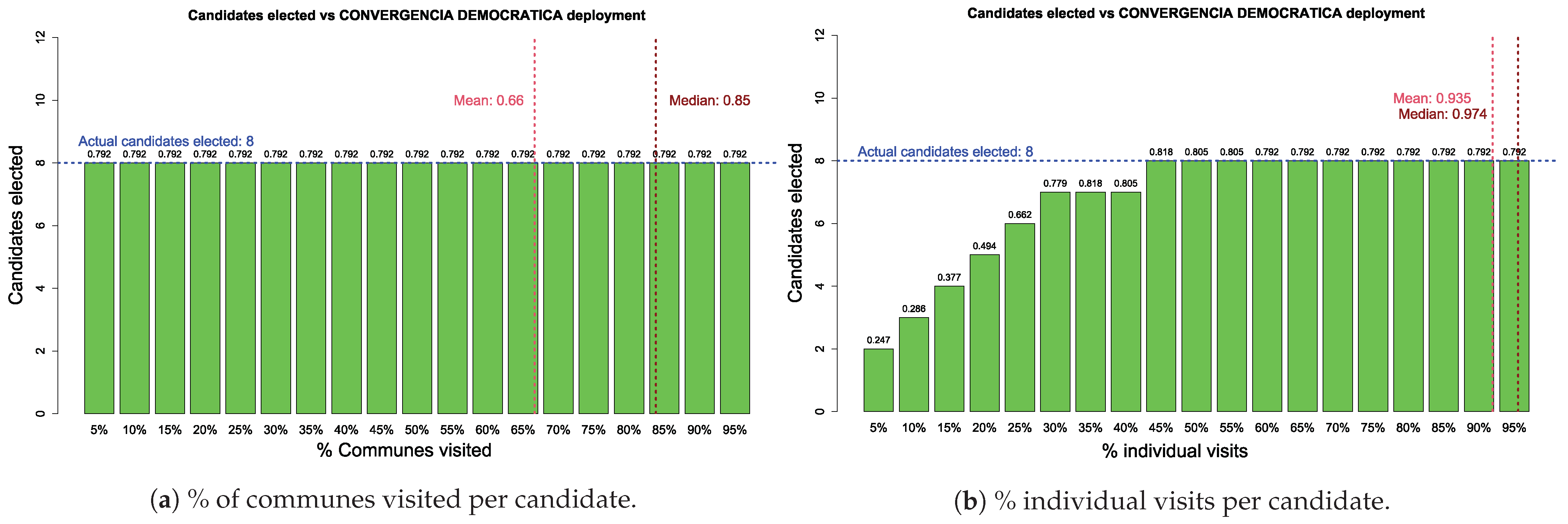
- Simulate different scenarios of territorial deployment by coalition, to analyze the impact of campaign strategies in the outcomes of the electoral process.
- Analyze the results obtained from two perspectives: first, from fitting the algorithms on the sample considered and, then, from the impact of the campaign strategies of the main coalitions in the outcomes of the electoral process.
3. Results and Discussion
Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Territorial Deployment Simulations


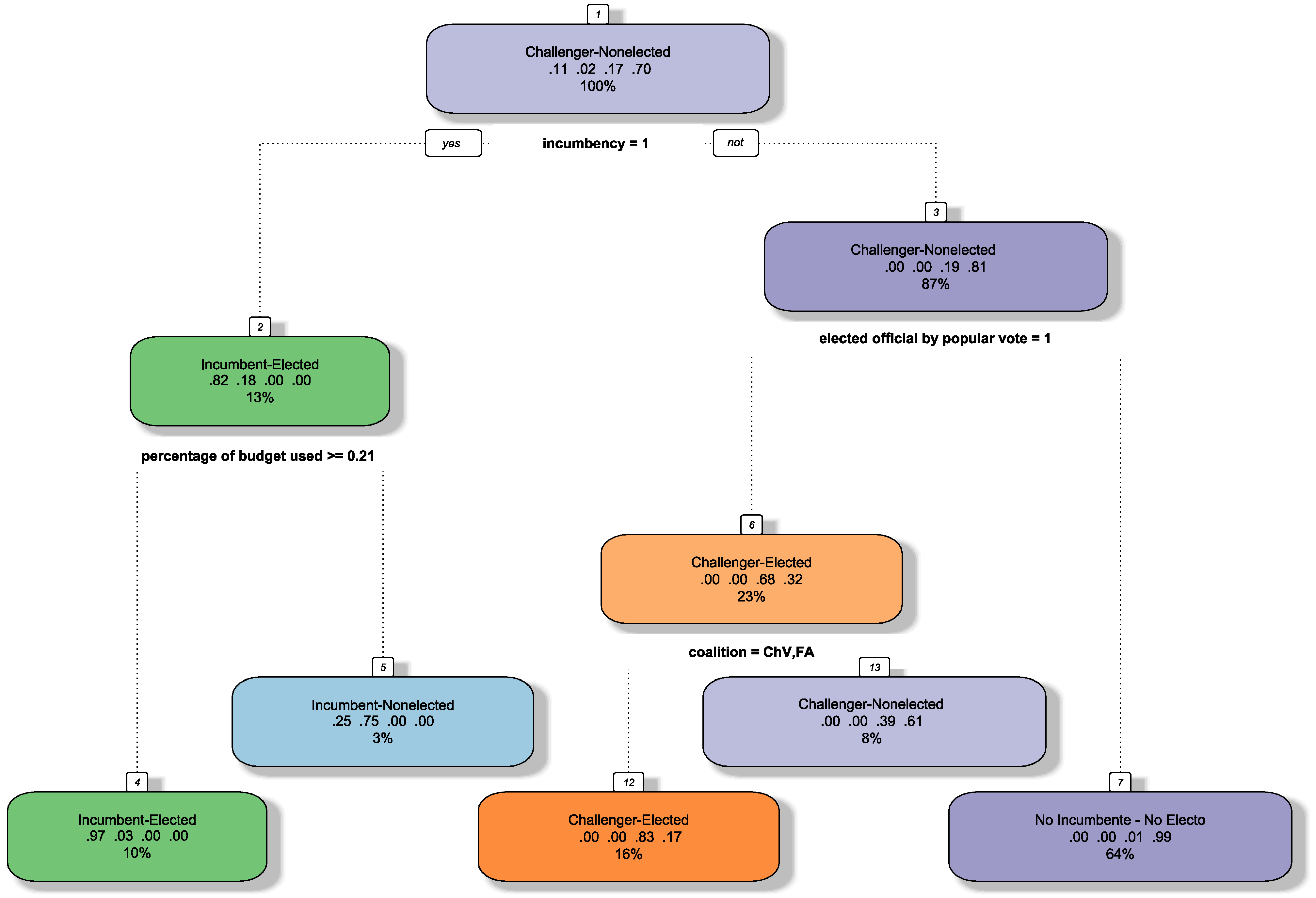
Appendix B. Classification Tree

References
- Benoit, K. Models of electoral system change. Elect. Stud. 2004, 23, 363–389. [Google Scholar] [CrossRef]
- Livne, A.; Simmons, M.; Adar, E.; Adamic, L. The party is over here: Structure and content in the 2010 election. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Rodríguez, S.; Allende-Cid, H.; Palma, W.; Alfaro, R.; Gonzalez, C.; Elortegui, C.; Santander, P. Forecasting the Chilean electoral year: Using twitter to predict the presidential elections of 2017. In Proceedings of the International Conference on Social Computing and Social Media, Las Vegas, NV, USA, 15–20 July 2018. [Google Scholar]
- Burnap, P.; Gibson, R.; Sloan, L.; Southern, R.; Williams, M. 140 characters to victory? Using Twitter to predict the UK 2015 General Election. Elect. Stud. 2016, 100, 230–233. [Google Scholar] [CrossRef]
- DiGrazia, J.; McKelvey, K.; Bollen, J.; Rojas, F. More tweets, more votes: Social media as a quantitative indicator of Political behavior. PLoS ONE 2013, 8, e79449. [Google Scholar] [CrossRef] [PubMed]
- Ganser, C.; Riordan, P. Vote expectations at the next level. Trying to predict vote shares in the 2013 German federal election by polling expectations. Elect. Stud. 2015, 100, 115–126. [Google Scholar] [CrossRef]
- Tumasjan, A.; Sprenger, T.; Sandner, P.; Welpe, I. Predicting elections with twitter: What 140 characters reveal about Political sentiment. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Kruikemeier, S. How Political candidates use Twitter and the impact on votes. Comput. Hum. Behav. 2014, 34, 131–139. [Google Scholar] [CrossRef]
- LaMarre, H.; Suzuki-Lambrecht, Y. Tweeting democracy? Examining Twitter as an online public relations strategy for congressional campaigns. Public Relat. Rev. 2013, 39, 360–368. [Google Scholar] [CrossRef]
- Singh, P.; Dwivedi, Y.; Kahlon, K.; Pathania, A.; Sawhney, R. Can twitter analytics predict election outcome? An insight from 2017 Punjab assembly elections. Gov. Inf. Q. 2020, 37, 101444. [Google Scholar] [CrossRef]
- Baldwin-Philippi, J. Data ops, objectivity, and outsiders: Journalistic coverage of data campaigning. Political Commun. 2020, 37, 468–487. [Google Scholar] [CrossRef]
- Simon, F. “We power democracy”: Exploring the promises of the Political data analytics industry. Inf. Soc. 2019, 35, 158–169. [Google Scholar] [CrossRef]
- Ansolabehere, S.; Snyder, J.; Stewart, C. Old voters, new voters, and the personal vote: Using redistricting to measure the incumbency advantage. Am. J. Political Sci. 2000, 45, 17–34. [Google Scholar] [CrossRef]
- Shotts, K. The effect of majority-minority mandates on partisan gerrymandering. Am. J. Political Sci. 2001, 2001, 120–135. [Google Scholar] [CrossRef]
- Shotts, K. Gerrymandering, legislative composition, and national policy outcomes. Am. J. Political Sci. 2002, 2002, 398–414. [Google Scholar] [CrossRef]
- Ferejohn, J. On the decline of competition in congressional elections. Am. Political Sci. Rev. 1977, 71, 166–176. [Google Scholar] [CrossRef]
- Ansolabehere, S.; Snyder, J. The effects of redistricting on incumbents. Elect. Law J. 2012, 11, 490–502. [Google Scholar] [CrossRef]
- Servel. Nuevo Sistema Electoral Chileno: Método D’Hondt. 2017. Available online: https://www.servel.cl/nuevo-sistema-electoral-chileno-metodo-dhont-2/ (accessed on 3 November 2019).
- Nic, N.; Fletcher, R.; Kalogeropoulos, A.; Levy, D.; Nielsen, R. Reuters Institute Digital News Report 2018; Reuters Institute for the Study of Journalism: Oxford, UK, 2018. [Google Scholar]
- CADEM. El Chile Que Viene: Uso de Redes Sociales; Technical Report; CADEM: Región Metropolitana, Chile, 2019. [Google Scholar]
- Biblioteca del Congreso Nacional de Chile. Nuevo Sistema Electoral Para Elecciones Parlamentarias (Fin del Sistema Binominal). 2015. Available online: https://www.bcn.cl/leyfacil/recurso/nuevo-sistema-electoral-para-elecciones-parlamentarias-(fin-delsistema-binominal) (accessed on 1 October 2020).
- Loosemore, J.; Hanby, V. The theoretical limits of maximum distortion: Some analytic expressions for electoral systems. Br. J. Political Sci. 1971, 1, 467–477. [Google Scholar] [CrossRef]
- Jenkins, S. A woman’s work is never done? Fund-raising perception and effort among female state legislative candidates. Political Res. Q. 2007, 60, 230–239. [Google Scholar] [CrossRef]
- Krook, M.; Norris, P. Beyond quotas: Strategies to promote gender equality in elected office. Political Stud. 2014, 62, 2–20. [Google Scholar] [CrossRef]
- Siavelis, P. Electoral system, coalitional disintegration, and the future of Chile’s Concertación. Lat. Am. Res. Rev. 2005, 2005, 56–82. [Google Scholar] [CrossRef]
- Benoit, K.; Marsh, M. Incumbent and challenger campaign spending effects in proportional electoral systems: The Irish elections of 2002. Political Res. Q. 2010, 63, 159–173. [Google Scholar] [CrossRef]
- Biblioteca del Congreso Nacional de Chile. Reseñas biográficas Parlamentarias de Parlamentarios en Ejercicio). 2020. Available online: https://www.bcn.cl/historiapolitica/resenas_parlamentarias/index.html?categ=en_ejercicio&filtros=2) (accessed on 30 December 2020).
- Lago, I.; Bermúdez, S.; Guinjoan, M.; Rowe, K.; Simón, P. Party mobilization and electoral systems. Gov. Oppos. 2019, 54, 1–24. [Google Scholar] [CrossRef]
- Jacobson, G. The effects of campaign spending in congressional elections. Am. Political Sci. Rev. 1978, 72, 469–491. [Google Scholar] [CrossRef]
- Jacobson, G. Incumbents’ advantages in the 1978 US congressional elections. Legis. Stud. Q. 1981, 6, 183–200. [Google Scholar] [CrossRef]
- Jacobson, G. The effects of campaign spending in House elections: New evidence for old arguments. Am. J. Political Sci. 1990, 34, 334–362. [Google Scholar] [CrossRef]
- Morales Quiroga, M.; Piñeiro Rodríguez, R. Gasto en campaña y éxito electoral de los candidatos a diputados en Chile 2005. Rev. Cienc. Political (Santiago) 2010, 30, 645–667. [Google Scholar] [CrossRef]
- Servel. Ingresos y Gastos de Candidatos. 2018. Available online: https://www.servel.cl/ingresos-y-gastos-de-candidatos/ (accessed on 30 December 2020).
- Kotsiantis, S.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 3rd IEEE International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016. [Google Scholar]
- Saad, S.; Yang, J. Twitter Sentiment Analysis Based on Ordinal Regression. IEEE Access 2019, 7, 163677–163685. [Google Scholar] [CrossRef]
- Díaz, J.; Morales, J. Comparación entre árboles de regresión CART y regresión lineal. Comun. Estadística 2013, 6, 175–195. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Morgan, S.; Teachman, J. Logistic regression: Description, examples, and comparisons. J. Marriage Fam. 1988, 50, 929–936. [Google Scholar] [CrossRef]
- Hedeker, D. A mixed-effects multinomial logistic regression model. Stat. Med. 2003, 22, 1433–1446. [Google Scholar] [CrossRef]
- Nerlove, M.; Press, S. Univariate and Multivariate Log-Linear and Logistic Models; RAND: Santa Monica, CA, USA, 1973; Volume 1306. [Google Scholar]
- Wang, Y. A multinomial logistic regression modeling approach for anomaly intrusion detection. Comput. Secur. 2005, 24, 662–674. [Google Scholar] [CrossRef]
- Therneau, T.; Atkinson, E. An Introduction to Recursive Partitioning Using the RPART Routines; Technical Report; Mayo Foundation: Rochester, NY, USA, 1997. [Google Scholar]
- Therneau, T.; Atkinson, E. Rpart: Recursive Partitioning and Regression Trees; R Package Version 4.1-15; The R Foundation: Vienna, Austria, 2019. [Google Scholar]
- Liaw, A.; Wiener, M. RandomForest: Breiman and Cutler’s Random Forests for Classification and Regression; R Package Version 4.6-14; The R Foundation: Vienna, Austria, 2018. [Google Scholar]
- Venables, W.; Ripley, B. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Ripley, B.; Venables, W. Feed-Forward Neural Networks and Multinomial Log-Linear Models; R Package Version 7.3-15; The R Foundation: Vienna, Austria, 2018. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Feldman, R.; Sanger, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Genolini, C.; Jacqmin-Gadda, H. Copy mean: A new method to impute intermittent missing values in longitudinal studies. Open J. Stat. 2013, 3, 26. [Google Scholar] [CrossRef]
- Guan, N.; Yusoff, M. Missing values in data analysis: Ignore or impute? Educ. Med. J. 2011, 3, e6–e11. [Google Scholar]
- Von Hippel, P. How to impute interactions, squares, and other transformed variables. Sociol. Methodol. 2009, 39, 265–291. [Google Scholar] [CrossRef]
- Mellon, J.; Fieldhouse, E. The British Election Study 2015 general election constituency forecast. Elect. Stud. 2016, 41, 250–254. [Google Scholar] [CrossRef]
- Whiteley, P.; Clarke, H.; Sanders, D.; Stewart, M. Forecasting the 2015 British general election: The Seats-Votes model. Elect. Stud. 2016, 41, 269–273. [Google Scholar] [CrossRef][Green Version]
- Prosser, C. Do local elections predict the outcome of the next general election? Forecasting British general elections from local election national vote share estimates. Elect. Stud. 2016, 41, 274–278. [Google Scholar] [CrossRef][Green Version]
- Stegmaier, M.; Williams, L. Forecasting the 2015 British election through party popularity functions. Elect. Stud. 2016, 41, 260–263. [Google Scholar] [CrossRef]
- König, P. Why Digital-Era Political Marketing is Not the Death Knell for Democracy: On the Importance of Placing Political Microtargeting in the Context of Party Competition. Stat. Political Policy 2020, 11, 87–110. [Google Scholar] [CrossRef]
- Grover, P.; Kar, A.; Dwivedi, Y.; Janssen, M. Polarization and acculturation in US Election 2016 outcomes—Can twitter analytics predict changes in voting preferences. Technol. Forecast. Soc. Chang. 2019, 145, 438–460. [Google Scholar] [CrossRef]
- McKelvey, K.; DiGrazia, J.; Rojas, F. Twitter publics: How online Political communities signaled electoral outcomes in the 2010 US house election. Inform. Commun. Soc. 2014, 17, 436–450. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Id | Variable | Type |
|---|---|---|---|
| Profile of the candidate | 1 | gender | Categorical |
| 2 | incumbency | Categorical | |
| 3 | years in office | Quantitative | |
| 4 | elected official by popular vote | Categorical | |
| 5 | coalition | Categorical | |
| Campaign effort | 6 | percentage of visits to new communes | Quantitative |
| 7 | percentage of new communes visited | Quantitative | |
| 8 | percentage of communes visited | Quantitative | |
| 9 | percentage of individual visits | Quantitative | |
| 10 | percentage of budget used | Quantitative |
| Coalition | Training | Prediction | ||||
|---|---|---|---|---|---|---|
| Elected | Not elected | Total | Elected | Not elected | Total | |
| Chile Vamos (ChV) | 41 | 50 | 91 | 32 | 58 | 90 |
| Coalición Regionalista Verde (CRV) | 1 | 0 | 1 | 3 | 29 | 32 |
| Convergencia Democrática (CD) | 5 | 31 | 36 | 8 | 69 | 77 |
| Frente Amplio (FA) | 14 | 48 | 62 | 6 | 87 | 93 |
| La Fuerza de la Mayoría (LFM) | 19 | 41 | 60 | 24 | 90 | 114 |
| Por Todo Chile (PTCh) | 0 | 28 | 28 | 1 | 91 | 92 |
| Sumemos (SUM) | 0 | 16 | 16 | 0 | 53 | 53 |
| Partido de Trab. Rev. (PTR) | NA | NA | NA | 0 | 4 | 4 |
| U. Patriótica (UP) | NA | NA | NA | 0 | 56 | 56 |
| Independientes (IND) | NA | NA | NA | 1 | 9 | 10 |
| Total | 294 | 551 | ||||
| Prediction | Results | ||||
|---|---|---|---|---|---|
| IE | INE | CE | CNE | ||
| IE′ | 31 / 29 / 31 | 0 / 1 / 0 | 0 / 0 / 0 | 0 / 0 / 0 | |
| INE′ | 0 / 2 / 0 | 7 / 6 / 7 | 0 / 0 / 0 | 0 / 0 / 0 | |
| CE′ | 0 / 0 / 0 | 0 / 0 / 0 | 38 / 38 / 47 | 11 / 8 / 3 | |
| CNE′ | 0 / 0 / 0 | 0 / 0 / 0 | 11 / 11 / 2 | 196 / 199 / 204 | |
| a Training sample. | |||||
| Prediction | Results | ||||
| IE | INE | CE | CNE | ||
| IE′ | 27 / 26 / 28 | 8 / 7 / 8 | 0 / 0 / 0 | 0 / 0 / 0 | |
| INE′ | 4 / 5 / 3 | 6 / 7 / 6 | 0 / 0 / 0 | 0 / 0 / 0 | |
| CE′ | 0 / 0 / 0 | 0 / 0 / 0 | 36 / 25 / 35 | 13 / 11 / 13 | |
| CNE′ | 0 / 0 / 0 | 0 / 0 / 0 | 7 / 18 / 8 | 450 / 452 / 451 | |
| b Prediction sample. | |||||
| Accuracy | |
|---|---|
| mLogit | 0.9419 |
| CART | 0.9256 |
| RF | [0.8748–0.9419] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Campos-Valdés, C.; Álvarez-Miranda, E.; Morales Quiroga, M.; Pereira, J.; Liberona Durán, F. The Impact of Candidates’ Profile and Campaign Decisions in Electoral Results: A Data Analytics Approach. Mathematics 2021, 9, 902. https://doi.org/10.3390/math9080902
Campos-Valdés C, Álvarez-Miranda E, Morales Quiroga M, Pereira J, Liberona Durán F. The Impact of Candidates’ Profile and Campaign Decisions in Electoral Results: A Data Analytics Approach. Mathematics. 2021; 9(8):902. https://doi.org/10.3390/math9080902
Chicago/Turabian StyleCampos-Valdés, Camilo, Eduardo Álvarez-Miranda, Mauricio Morales Quiroga, Jordi Pereira, and Félix Liberona Durán. 2021. "The Impact of Candidates’ Profile and Campaign Decisions in Electoral Results: A Data Analytics Approach" Mathematics 9, no. 8: 902. https://doi.org/10.3390/math9080902
APA StyleCampos-Valdés, C., Álvarez-Miranda, E., Morales Quiroga, M., Pereira, J., & Liberona Durán, F. (2021). The Impact of Candidates’ Profile and Campaign Decisions in Electoral Results: A Data Analytics Approach. Mathematics, 9(8), 902. https://doi.org/10.3390/math9080902