Abstract
In this paper, an adaptive proximal bundle method is proposed for a class of nonconvex and nonsmooth composite problems with inexact information. The composite problems are the sum of a finite convex function with inexact information and a nonconvex function. For the nonconvex function, we design the convexification technique and ensure the linearization errors of its augment function to be nonnegative. Then, the sum of the convex function and the augment function is regarded as an approximate function to the primal problem. For the approximate function, we adopt a disaggregate strategy and regard the sum of cutting plane models of the convex function and the augment function as a cutting plane model for the approximate function. Then, we give the adaptive nonconvex proximal bundle method. Meanwhile, for the convex function with inexact information, we utilize the noise management strategy and update the proximal parameter to reduce the influence of inexact information. The method can obtain an approximate solution. Two polynomial functions and six DC problems are referred to in the numerical experiment. The preliminary numerical results show that our algorithm is effective and reliable.
1. Introduction
Consider the following optimization problem:
where is a finite convex function and function h is not necessarily convex. So the primal function (1) may be nonconvex and note that functions f and h are not necessarily smooth. In this paper, we consider the case that function h is easy to evaluate while the function f is much harder to evaluate and is time consuming.
The sum of two functions can be found in many optimization problems such as the Lasso problem in image problems and the optimization problems in machine leaning and so on. Meanwhile, the composite function (1) can be obtained from other problems such as by splitting technique and nonlinear programming and so on. Concretely, in some cases, the function considered is much complicated and difficult to evaluate, to speed up calculations, dividing the primal function into two functions f and h with relatively simple structure is a possible way. Besides that, another way is the penalty strategy which transfers the constraint problem into an unconstrained problem with the sum form.
Note that the splitting type methods (see [1,2]) and the alternating type methods (see [3,4]) are two classes of important methods for composite optimization. When functions f and h have some special structures, the above methods may be effective and own better convergent results. However, if the functions do not own special structures or the functions are much complex and difficult to evaluate, the above methods may not be suitable for Problem (1). Meanwhile, in the alternating direction type methods, at least two subproblems need to be solved at each iteration, if one of the subproblems is difficult or hard to solve, the algorithms’ effectiveness may be slowed down. Then, it is meaningful to seek other suitable methods to deal with Problem (1) without special structures.
In recent years, many scholars have devoted time to seeking effective methods for nonconvex and nonsmooth optimization problems, see [5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]. Usually, bundle methods are much effective for solving nonsmooth optimization problems [21,22,23,24,25,26]. Bundle methods use “black box” to compute the objective value and one of its subgradients (not special) at each iterations. Then, bundle techniques can be a class of possible effective ways to deal with the composite problem (1). At present, the proximal alternating linearization type methods (see [4,27,28,29]) are one effective kind of bundle methods for some composite problems. They need to solve two subproblems at each iteration and the data referred are usually exact. When inexact oracles are involved, the above methods may not be suitable and even be not convergent.
In this paper, we design a proximal bundle method for the inexact composite problem (1) and update the proximal parameter to reduce the effects of the inexact information. In the following, we first present some cases where inexact evaluations are generated.
Inexact evaluations are usually referred to in stochastic programming and Lagrangian relaxation [30,31]. It is at the very least impractical and is usually not even easy to solve those subproblems exactly. In bundle methods, inexact information are obtained from inexact oracles. There are different types of inexact oracles. In our work, we consider the Upper oracle (see (2a)–(2c) below). The Upper oracles may overestimate the corresponding function values and get negative linearization errors even if the primal function is convex.
In this paper, we focus on a class of nonconvex and nonsmooth composite problems with inexact data. The design and convergence analysis of bundle methods for nonconvex problems with inexact function and subgradient evaluations are quite involved and there are only a handful of papers for this topic, see [15,32,33,34,35].
In this paper, we present a proximal bundle method with a convexification technique and noise management strategy to solve composite problem (1). Concretely, we design “convexification” technique for the nonconvex function h to make sure the corresponding linearization error nonnegative and then we adopt the noise management strategy for inexact function f. If the error is “too ” large and the testing condition (22) is not satisfied, we decrease the value of the proximal parameter to obtain better iterative point. We summary our work as follows:
- Firstly, we design the convexification technique for the nonconvex function h to make sure the linearization errors of the augment function are nonnegative. Note that the the augment function may not be a convex function, the nonnegative linearization errors can be obtained by the choices of the parameter . Similar strategy can also be seen in [10,11,15,16].
- Then, the sum of functions f and is regarded as an approximate function for the composite function (1). We construct respectively the cutting plane models for functions f and and regard the sum of the two cutting plane models as the cutting plane model for the approximate function which may be a better cutting plane model. It should be noted that since inexact information are referred, the corresponding cutting plane model may not always be below function f.
- Although we design the cutting plane models for functions f and , respectively, only one quadratic programming (QP) subproblem needs to be solved at each iteration. By the construction of cutting plane models, we have that the QP subproblem is strictly convex and has unique solution which makes our algorithm more effective.
- In the method, we construct the noise management step to deal with the inexact data for function values and subgradient values where the errors are only bounded and need not to vanish. If the noise error is “too” large and the testing condition (22) is not satisfied, we decrease the value of to obtain a better iterative point.
- Two polynomial functions with twenty different dimensions and six DC (difference of convex) problems are referred to in the numerical experiment. In exact cases, our method is comparable with the method in [16] and has higher precision. In five different types of inexact oracles, we obtain that the exact case has the best performance and the performance of the vanishing error cases are generally better than that in the constant error cases. We also apply our method to six DC problems and the results show that our algorithm is effective and reliable.
The remainder of this paper is organized as follows. In Section 2, we review some variational analysis definitions and some preliminaries for proximal bundle method. Our proximal bundle method is given in Section 3. In Section 4, we present the convergent property of the algorithm. Some preliminary numerical testings are implemented in Section 5. In Section 6, we give some conclusions.
2. Preliminaries
In this section, we firstly review some concepts and definitions and then present some preliminaries for a proximal bundle method.
2.1. Preliminary
In this subsection, we recall concepts and results of variational analysis that will be used in the latter of the paper. The definition of lower- is given in Definition 10.29 in [36]. For completeness, we state it as follows:
Definition 1.
A function , where is an open subset of , is said to be lower- on , if on some neighborhood V of each , there is a representation:
in which the function are of class on V and the index set T is a compact space such that and all its partial derivatives through order k depend continuously not just on x but on .
If , F is a lower- function. lower- function has a special relationship with convexity, see Theorem 10.33 in [36]. We state its equivalent statement as follow: A function F is lower- on an open set if F is finite on and for any , there exists a threshold such that is convex on an open neighborhood V of x for all . Specifically, if the function F is convex and finite-valued, then F is lower- with threshold .
For nonconvex function h, in the following, we consider that h is a lower- function. Since functions f and h are all not necessarily smooth, then the composite function (1) is also not necessarily smooth. For proper convex function f, the common subdifferential in convex analysis is used, which is denoted by at the point (see in [37]). For proper and regular function h, we utilize the limiting subdifferential and also denote it by at point x (see in [36]). The definition of the limiting subdifferential is as follows:
In nonsmooth analysis for convex function f, at point is usually used, which is defined:
where . In the following, we present the inexact data for function f and give some preliminaries for proximal bundle method.
2.2. Inexact Information and Bundle Construction
Bundle methods are much effective for nonsmooth problems and always utilize “black box” to compute function value and one subgradient at each iterative point. It should be noted that the obtained subgradient is not special. Along the iterative progress, the generated points are divided into two styles: null points, used essentially to increase the model’s accuracy; serious points, significantly decreasing the objective function (and also improve the approximate model’s accuracy). The corresponding iterations are respectively called null steps and serious steps. In the literature, serious points are sometimes called as prox-center or stability center, denoted by . Then, the sequence is a subsequence of the sequence . For notation simplification, we write .
For function f, the oracle can only provide inexact function value and one subgradient value at each iteration, , with unknown but bounded inaccuracy. That is, for , we have
Meanwhile
According to (2a)–(2c), we have the following relationships
Note that we only require the relationship holds for each index l. The bundle for function f can be noted as
Now we present the cutting plane model of function f by the inexact information:
where , is the current stability center with index corresponding to its candidate point index and is linearization errors, which measures the difference between cutting planes and the function value computed in the oracle for the current serious point, that is
Especially, note that the relation does not necessarily hold. So the linearization error may be negative. In fact, by (2a), (2b) and (6), satisfies that
Meanwhile, cutting plane model may overestimate f at some points. By (2b), the following inequality holds
For nonconvex function h, linearization errors may be nonnegative. In bundle methods, nonnegative linearization errors are much important for the convergence. For that we present a local “convexification” technique, similar techniques can also be seen in [15,16,38]. For the convexification parameter , its choice is as follows
where denotes an index set, i.e., and is the linearization error of h, which is defined as follows with
The bundle for function h can be noted as
Next, we introduce the augment function of f, it is defined by
where holds. Note that by the definition of , we have . By the calculation of subgradient, we have there exists satisfying
Meanwhile, the linearization error of function is
By the choice of the convexification parameter , we have holds for all .
In the following, we regard the sum of functions f and as an approximate function for composite function (1):
For (13), we utilize the sum of cutting plane models of functions f and as the cutting plane model. The cutting plane model of the augment function is defined as follows
Its equivalent form is
Then, the cutting plane model for the approximate function is
The new iterative point is given by the following QP (quadratic programming) subproblem
where is the proximal parameter. Note that is the unique solution to (15) by strong convexity. The following lemma shows the relation between the current stationary center and the new generated point. Similar conclusion can also be seen in Lemma 10.8 in [39] which is for convex function. Here we omit the proof.
Lemma 1.
Let be the unique solution to the QP subproblem (15) and proximal parameter . Then, we have
where
Meanwhile and is the solution to
In addition, the following relations hold:
- (i)
- ;
- (ii)
- .
In the following, we present the concepts of the predict descent. Concretely, the predict descent for functions are stated as follows
Note that the predict descent is much important for the convergence of bundle methods. By the definitions of functions and , we have . Since inexact data are referred to in the computation of function f, the nonnegativity of can not be guaranteed. Hence the nonnegativity of can not be guaranteed too.
Next we give the aggregate linearization error which is defined by
By the term (ii) in Lemma 1 and the definition of in (18), the following relationship holds
where . Next we define the aggregate linearization for approximate model :
Then, the aggregate linearization error can be also expressed as the difference between the value of the oracle at the current serious point and the value of aggregate linearization at that point, that is,
Indeed, by the definition of , we have
By the convexity of function , the inequality holds. So for any , we have
By (8), the following inequality holds under the condition :
Note that the condition may not be hold if the convexification parameter is less that the threshold parameter (the function may not be convex), but the choice of ensures the nonnegativity of for all .
By the nonnegativity of and (7), the aggregate linearization error satisfies
Using the fact that is the solution of the QP problem (15) and the definition of predict descent in (18), we have that
where the second inequality follows from the nonnegativity of . By (5) and , we have holds, Note that if only “small” errors have been introduced into the model , then it holds
Then, by (20) and (16), (22) has the following equivalent forms:
Next, we present a optimality measure. Concretely, it is that
By the above discussions, we have
From the above inequalities, the smaller may lead to higher probability to make inequality (22) hold. Based on that, we will update the parameter to reduce the effects of errors. In the next section, we will give our proximal bundle algorithm for the primal composite problem (1) with inexact information.
3. Algorithm
In this section, we present our adaptive bundle algorithm to composite problem (1) with inexact information. To handle inexact information, similar to [17], we introduce the noise management step. Concretely, when the condition (22) does not hold, is reduced in order to make and increase the probability of condition (22).
| Algorithm 1 (Nonconvex Nonsmooth Adaptive Proximal Bundle Method with Inexact Information for a class of composite optimization) |
| Step 0 (Input and Initialization): Choose initial point , constants , an unacceptable increase parameter , and a stopping tolerance . Set noise management parameter NMP = 0 and . Set . Call the black box to compute . Set . |
| Step 1 (Model generation and QP subproblem): Having the current proximal center , the current bundles and with index set , and the current proximal parameter and the convexification parameter . Having the current approximate models and . Compute the QP problem (15) to get the next iterative point and simplex multipliers . Then, compute and . |
| Step 2 (Stopping criterion): If , then stop. Otherwise, go to Step 3. |
| Step 3 (Noise Management): If relationship (22) does not hold, set , , , go to Step 1; otherwise, set and we call the noise is acceptable and go to Step 4. |
| Step 4 (Descent testing): Call the black box to compute and . Check the descent condition |
| Step 5 (Update parameter): Apply the rule to compute |
| Step 6 (Restart step): If holds, then the objective increase is unacceptable; Restart the algorithm by setting |
Remark 1.
Note that in Algorithm 1, the update of elements in bundles are not stated clearly. For null step and serious step, the updating strategies are different. When a serious step occurs, the new generated point is regarded as a new proximal center and the corresponding linearization errors in the bundles all should be updated. When a null step emerges, the proximal center keeps unchanged and only the new generated information are added into the bundles to improve the model’s accuracy. As the iterations proceed, the elements in the bundles may be too large that reduces the efficiency of the algorithm. Then, the active technology (only the active element and are kept in the bundles) and the compression strategy can be adopted. For the compression strategy, the number of elements in the bundles can be at least two, the aggregate information and the new generated information. It should be noted that although the compression strategy does not impair the convergence of the algorithm, it may affect the model’s effectiveness if the number of elements in the bundles is too small.
In the following, we will focus on the analysis of Algorithm 1 which indicates the algorithm is well defined. If the algorithm loops forever, three situations may occur (the number of restart steps are finite, which can be see in Lemma 3 ):
- an very large loop of noise management between Step 1 and Step 3, driving ;
- a finite number of serious steps, followed by an very large number of null steps;
- an very large number of serious steps.
Next, we firstly give the case of very large loop of noise management.
Lemma 2.
If an very large loop between Step 1 and Step 3 in Algorithm 1 occurs, then the optimal measure .
Proof.
Suppose an very large loop between Step 1 and Step 3 begins at iterative index . According to the algorithm, this means that for all , neither the proximal center nor the approximate models change. Hence, when solving sequentially the QP optimization problem (15), only parameter is updated. By the strategy for , we have , then it holds as by . Using (24), we have
Then, the proof is completed. □
Note that if very large noise management steps happen, there is finite number of update for the convexification parameter . Then, eventually is bounded. Before the last two cases, we show that there is only finite number of restart steps in Algorithm 1. For that, we make an assumption, which can also be founded in [16].
Assumption 1.
The following level set is nonempty and compact.
By the definition of lower-, the compactness of set and the finite covering theorem, there exists a threshold such that for all , the augmented function is convex for .
The compactness of allows us to find Lipschitz constants for functions f and h, named and respectively (by lower- function’s local lipschitz property and the finite covering theorem). The following lemma indicates that the restart step in Algorithm 1 is finite.
Lemma 3.
Suppose only finite number of the noise management steps occur, Assumption 1 holds and consider the sequence of iterative points generated by Algorithm 1. The index denotes the current proximal center index, then there can be only a finite number of restart steps in Algorithm 1. Hence, eventually the sequence is entirely in .
Proof.
Firstly, new iterative point is well defined by the strong convexity of QP subproblems (15). As functions f and h are lipschitz continuous on the level set and their lipschitz constants are respective and , is also lipschitz continuous in the compact set and one of its lipschitz constants is . By the lipschitz continuity of , there exists such that for any , the open set is contained in compact set (indeed, the choice of suffices). Note that:
where , and . It also holds , then . In Algorithm 1, increases when the restart steps and the null steps with happen, eventually proximal parameter becomes large enough that the relationship holds. Noting that for any new serious point generated in Algorithm 1 completes the proof. □
Next, we focus on the update of convexification parameter . The following lemma shows eventually keeps unchanged.
Lemma 4.
Suppose there is a finite number of the noise management steps and Assumption 1 holds. Then, there exists an iteration index such that for all , the convexification parameter stabilizes, i.e., . Moreover, if holds, then for all , the augmented function is convex on the compact set .
Proof.
By the update of the convexification parameter in Algorithm 1, we have is nondecreasing: either or . Suppose the sequence does not stabilize, there must exist an very large number iterations such that the convexification parameter is increased by a factor of at least , but that is difficult and can lead to a contradiction. Since there exists an index such that and is convex on the compact set . For this iteration, we have for all (the linearization error for a convex is always nonnegative). Hence, holds. Then, from the iteration onward, the convexification parameter will keep unchanged, i.e., for all . Then, the sequence stabilizes. Specially, we choose . For , if holds, then the augmented function in is convex. □
The optimality measure in Algorithm 1 for inexact information is different with that in exact case. The following lemma justifies the choice of as optimality measure and indicates the accumulate point is an approximate solution of primal problem (1).
Lemma 5.
Suppose there is a finite number of the noise management steps and Assumption 1 holds. Suppose that for an very large subset of iterations , the sequence as . Let be the corresponding subsequence of serious points and let be an accumulation point. If holds, then is an approximate solution to the problem (13) with
where is the optimal value of function .
Proof.
Taking large enough and by the definition of , we have . Passing to the limit in inequality (21) and by , we have that
Moreover, for any cluster point of , passing to the limit to (2a), we obtain that
Rewriting the two inequalities above, the conclusion holds. □
Note that by the definition of function and large enough index n, we have and . By the above discussions, we have where and are local optimal solution and optimal value respectively. Then, is an approximate solution to the primal problem (1). There are some corollaries from Lemma 5, which are much important for convergent analysis. We state it here but omit its proof.
Corollary 1.
(i) if for some iteration index λ, holds and the optimality measure satisfies , then the serious point is an approximate solution to problem (13) with
(ii) Suppose that the serious point sequence finally stabilizes, i.e., there exists a constant m such that for all , we have . If holds, then is an approximate solution to the problem (13) with
Note that if an very large loop of noise management happens after some iteration and , then the proximal center keeps unchanged. According to (29), the last serious point is an approximate solution to problem (13). From above lemmas and corollary, we have Algorithm 1 is well defined. In the next section, we will study separately the last two cases.
4. Convergence Theory
In this section, we study separately the last two cases above. The similar proof process can be found in [13,16,17,38,40]. In the following lemma, the second case, i.e., finite serious step with very large null steps, is considered.
Lemma 6.
Assumption 1 holds and suppose that, after some iteration , holds and there is no serious step declared in Algorithm 1. Then, there exists a subsequence , such that as .
Proof.
After some iteration , no serious step is declared. Hence either noise management steps or null steps are done for . The serious point does not change, i.e., for all , . For notational simplicity, we denote .
If the number of noise management steps is very large, we have that as . The previous proof indicates that there exists a subsequence such that as .
Suppose there is only a finite number of noise management steps. Since the number of the restart steps is finite, there exists some iterative index , such that (22) holds and only null steps occur for all . Consequently, is a nondecreasing sequence since for all . Meanwhile as . In the following, we show . Let be the partial linearization of the the QP model (15), that is,
By Lemma 10.10 in [39], we know that the rules to apply selection on the bundles guarantee that holds. By the inequality (8), we have
Similarly, evaluating at , and using the fact that , we have
Furthermore, is the unique solution to (15), then . By Taylor’s expansion, we get
Hence the following two equalities hold
Using the relationship above, the fact and (30), we obtain
Then, the sequence is nondecreasing and bounded. Hence the limit exists:
Then, the sequence of null steps is bounded. By (16) and is bounded, we have is bounded (see [39]). Since for , the serious steps test is not satisfied, so by the definition of , we have
Since holds, then by the definition of partial linearization and , we have
By (32), Theorem 1 in [16] and , we have the right side of the above inequality vanishes as . So holds as . Hence
Then, holds as . By (24), holds as . □
Theorem 1.
Suppose Algorithm 1 loops forever and Assumption 1 holds. Assume there are finite number of serious steps and holds. Then, the last serious point is an approximate solution of problem (13) with
Proof.
(i) If very large noise management steps happens, Algorithm 1 finally stops and the conclusion holds. (ii) If very large null steps happen in Algorithm 1, by Lemma 6 and the second term of Corollary 1, the conclusion holds. □
The case of very large serious points generated in Algorithm 1 is considered in the next lemma. For notational convenience, we denote by the subset of iterations which are chosen as serious points. Let and be two successive serious points.
Lemma 7.
Suppose an very large sequence of serious steps is generated in Algorithm 1, Assumption 1 and hold. Then, the as .
Proof.
Since the serious points satisfy the descent condition (25), for two successive serious points and , applying the descent condition inequality, we have
Rewriting the above inequality, we have
Then, we have the sequence is strictly decreasing. By summing up this inequality for all serious steps, we deduce that
Hence, the above inequality deduces . Since (22) holds, then by (24), we have as . □
Theorem 2.
Suppose Algorithm 1 loops forever, there are very large number of serious steps and holds. Then, any accumulation point of serious points sequence is an approximate solution of the problem (13) with
Proof.
The conclusion follows from Lemma 5 and Lemma 7. □
5. Numerical Results
In this section, we consider two Ferrier polynomial functions (see [10,15,16]) and some DC (difference of convex) functions (see [41,42,43,44]). The section is divided into three parts. We code Algorithm 1 in MATLAB R2016 and run it on a PC with 2.10 GHZ CPU. Meanwhile, the Quadratic programming solver for Algorithm 1 in this paper is the Quadprog.m, which is available in the Optimization Toolbox in MATLAB. Note that the quadratic programming solver is not special and any solver for quadratic programming is accepted.
5.1. Two Polynomial Functions
In this subsection, we first present two polynomial functions which are in the form of the objective function (1). The two polynomial functions have the following forms:
where is defined by , where ∀ and for each . It is clear that the above functions are nonconvex, nonsmooth, lower- and have as their global minimizer. If we denote and or , the above functions are clear in the form (1). In the following, we adopt initial points and consider the case . The parameters in this subsection are set as follows: , , , , , , and . We also stop the algorithm when the iterative number is over 1000. First, we present the numerical results in Table 1 and Table 2 for the case and , that is the exact case, and compare them with the results in [16]. We call the algorithm in [16] as the RedistProx algorithm. Meanwhile, we adopt . Note that in the exact case, we stop the progress when occurs, which is the same in [16]. In exact case, the linearization error and are nonnegative, so the noise attenuation steps never happen. Then, in the numerical results for exact cases, the NNA is always zero, and we omit the NNA in the Table 1 and Table 2. The columns of Tables have the following meanings: Dim: the the tested problem dimension, NS: the number of serious steps, NNA: the number of noise attenuation steps, NF: the number of oracle function evaluations used, fk: the minimal function value found, : the value of at the final iteration, : the optimal function found, : the value of at the final iteration, RN: the number of restart steps, Nu: the number of null steps.

Table 1.
The numerical results of Algorithm 1 and RedistProx for .
Table 2.
The numerical results of Algorithm 1 and RedistProx for .
From Table 1 and Table 2, in most cases, our algorithm has a higher accuracy and compares with the RedistProx algorithm in [16]. For , we adopt a larger initial model prox-parameter (a smaller steplength), . Meanwhile, the and other parameters keep unchanged. For , We take , and keep other parameters unchanged. The numerical results for and are reported in Table 3.
Table 3.
The numerical results of Algorithm 1 for and .
From Table 3, Algorithm 1 can solve the two Ferrier polynomial functions in higher dimension successfully and have a reasonable and higher accuracy. The parameters and eventually keep unchanged in exact case, which is illustrated by Figure 1.
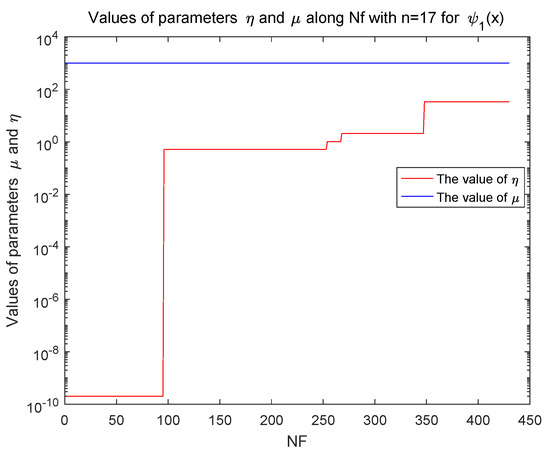
Figure 1.
Values of and in function with in exact case.
Next, inexact data are referred and we consider the cases of random noises for function value and subgradient. We introduce two kinds of random noises in matlab codes. The first case is , and . The code generates random numbers from the normal distribution with mean value 0, standard deviation 0.1 and scalars and 1 are the row and column dimensions. We take , , , , and in this random error case. The algorithm stops when holds or the number of function evaluated is over 1000. The numerical results for this case are report in Table 4.
Table 4.
The numerical results of Algorithm 1 for and in normal case.
From Table 4, we have Algorithm 1 can solve and successfully for random errors in a reasonable accuracy. We also focus on the parameters and in the implementation of Algorithm 1. Although the convexification parameter eventually keeps unchanged, the update strategy of the proximal parameter is complicated. When the noise management step occurs, parameter is decreasing to reduce the ’noise’ errors’ impact. When the unacceptable condition happens, we increase the parameter to get a smaller step length. Figure 2 shows the variation of parameters and along NF for with in normal random error case.
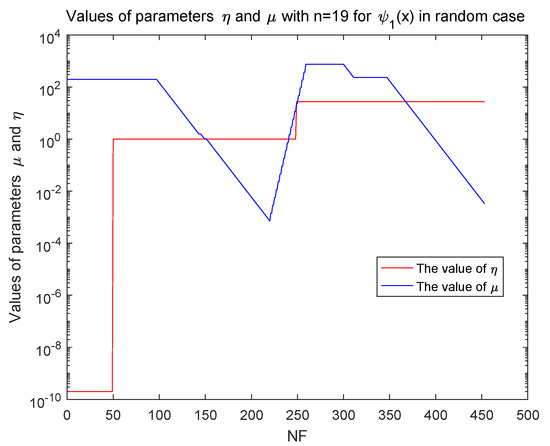
Figure 2.
The values of and in function with in inexact case.
In the following, we introduce the error case of and . The code gives a similar case with the ‘normrd’ case. In this case, we adopt two values and two initial proximal parameter values for different dimension of the variables. Concretely, we take , , , , and , for . For , we take , and the other parameters keep unchanged. We also take 1000 as the upper limit of function evaluated. The algorithm stops when holds or the number of function evaluated is over 1000. The numerical results for this error case are reported in Table 5.
Table 5.
The numerical results of Algorithm 1 for and in unifrnd error case.
From Table 5, Algorithm 1 can solve and in a reasonable accuracy for the ‘unifrnd’ random error case. In this inexact case, we also illustrate the vary of and in Figure 3 and Figure 4. The parameter is eventually stable. Although the vary of the proximal parameter is complicate for inexact case, the hypothesis about the upper limits for in the numerical experiment is reasonable, which are illustrated in the numerical testing.
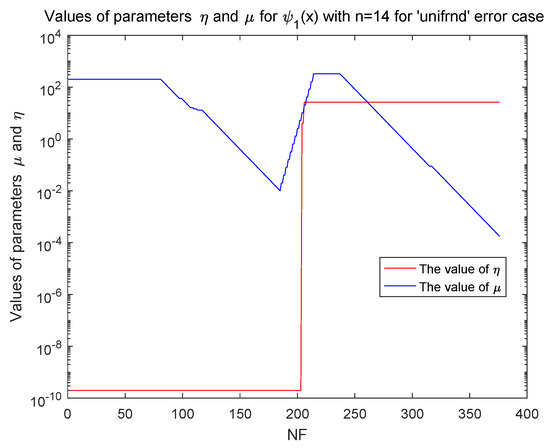
Figure 3.
Values of and in function with in unifrnd error case.
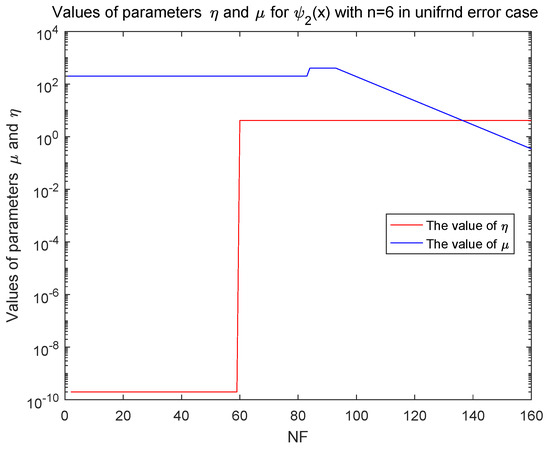
Figure 4.
Values of and in function with in unifrnd error case.
5.2. Noise’s Impact on Solution Accturacy
The error have different types. To analysis the impact of different noise types, we test five different types of inexact oracles:
- NNE (no noise error): in this case, and for all i in iterative process;
- CNE (constant noise error): in this case, , for all i in iterative process;
- VNE (vanishing noise error): in this case, and for all i in iterative process;
- CGNE (constant subgradient noise error): in this case, and for all i in iterative process;
- VGNE (vanishing subgradient noise error): in this case, we set and , for all i in iterative process;
In the numerical experiment, the parameters involved are the same with that in the ‘unifrnd’ error case. We present the numerical results of no noise error case (exact values case) in Table 6. In the test, for , we take . In exact case, the number of is always 0, then we omit the columns of in Table 6.
Table 6.
The numerical results of Algorithm 1 for and in NNE case.
In the following, we present the numerical results of constant noise error case in Table 7. The parameters are same with that in the NNE case except that for with . For the case of with , we take , and the other parameters keep unchanged. For the case of with , we take , and the other parameters keep unchanged.
Table 7.
The numerical results of Algorithm 1 for and in CNE case.
Next, Table 8 presents the results for the vanishing noise error case. The parameters keep unchanged except that for with and with . In the case of with , we take and the other parameters keep unchanged. For the with case, we take and other parameters keep unchanged. It also should note the results for the case of with .
Table 8.
The numerical results of Algorithm 1 for and in VNE case.
In the following, Table 9 presents the results for the constant subgradient noise error case (CGNE). The parameters keep unchanged except the case of with . In this case, we take and . Table 10 presents the results for the vanishing subgradient noise error case (VGNE). The parameters keep unchanged except the cases of with . In these cases, we take and other parameters keep unchanged.
Table 9.
The numerical results of Algorithm 1 for and in CGNE case.
Table 10.
The numerical results of Algorithm 1 for and in VGNE case.
Next, we compare the numerical performance of different noise type. For comparing the performances, we adopt the formula Precision and regard the NNE case as a benchmark for comparison. The cases of constant noise (CNE and CGNE) and exact form (NNE) are referred to in Figure 5. It is clear that the exact case has the best performance and Algorithm 1 can achieve a reasonable accuracy for the constant case. Meanwhile, the performance of CGNE case is better that than of CNE case. Similarly, Figure 6 reports the numerical performance for the vanishing cases (VNE and VGNE) and the exact form (NNE). From Figure 6, the performance of the VGNE case is comparable with that of the exact (NNE) case. Meanwhile, the performance of the vanishing error cases are generally better than that in the constant error cases.
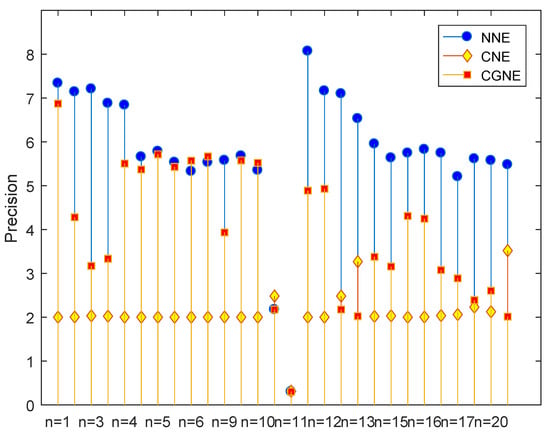
Figure 5.
Performance of Algorithm 1 for the NNE, CNE and CGNE cases.
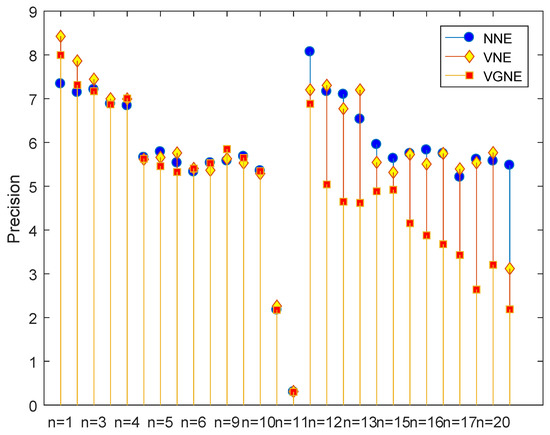
Figure 6.
Performance of Algorithm 1 for the NNE, VNE and VGNE cases.
5.3. Application to Some DC Problems
In this subsection, we test some unconstrained DC examples to illustrate the effectiveness of Algorithm 1. These examples come from [42,43,44]. Usually, the DC function has the form: . If we take , the problems are in the form of (1).
Problem 1.
Dimension: ,
Component functions: ; ,
Relevant information: , , .
Problem 2.
Dimension: ,
Component functions: ; ,
Relevant information: , , .
Problem 3.
Dimension: ,
Component functions: , ,
Relevant information: , , or , , , .
Problem 4.
Dimension: ,
Component functions: ;
Relevant information: , , ;
Problem 5.
Dimension: ,
Component functions: ,
Relevant information: , , .
Problem 6.
Dimension: ,
Component functions:
Relevant information: , , .
For the effectiveness of Algorithm 1, we compare it with the TCM algorithm, NCVX algorithm and penalty NCVX algorithm in [42]. The values of parameters in Algorithm 1 are that: , , , , , and . The results can be seen in Table 11. Meanwhile the ∗ in Table 11 means the obtained value is not optimal. From Table 11, we have that Algorithm 1 can successfully solve these DC problems, however the TCM algorithm cannot solve Problem 4, NCVX algorithm cannot solve Problems 1 and 4 and the penalty NCVX algorithm can not solve Problem 1. Then, Algorithm 1 is reliable. From the obtained function value and the number of function evaluations, Algorithm 1 is also effective.
Table 11.
The numerical results for Algorithm 1, TCM, NCVX and PNCVX algorithms in Problems 1–5.
For the above DC problems, we consider the vanishing noise error (VNE) case and the exact (NNE case. We also take 1000 as the upper limit of function evaluated. The algorithm stops when holds or the number of function evaluated is over 1000. For the vanishing noise case, we set and except Problem 3. In Problem 3, the optimal solutions vary with the dimensions, then we set and . Table 12 presents the results for the vanishing noise error case (VNE) and the exact case (NNE). The column in Table 12 denotes the index of problems. We also compute the Precision. However it is not suitable since the optimal value is not 0. To deal with that, we take and Precision . The numerical results are reported as follows.
Table 12.
The numerical results of Algorithm 1 for these DC problems in VNE and NNE cases.
From Table 12, Algorithm 1 can successfully solve the above DC problems in a higher precision and is effective to the VNE case in a reasonable accuracy. Then, Algorithm 1 is effective and reliable to the above DC problems. During the numerical experiment, we also focus on the variation of parameters and , which are both bounded and the parameter eventually keeps unchanged, which can be illustrated in Figure 7 and Figure 8.
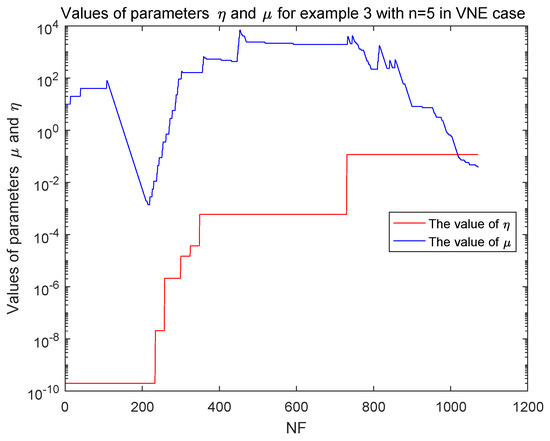
Figure 7.
The values of and in Problem 3 with in the VNE case.
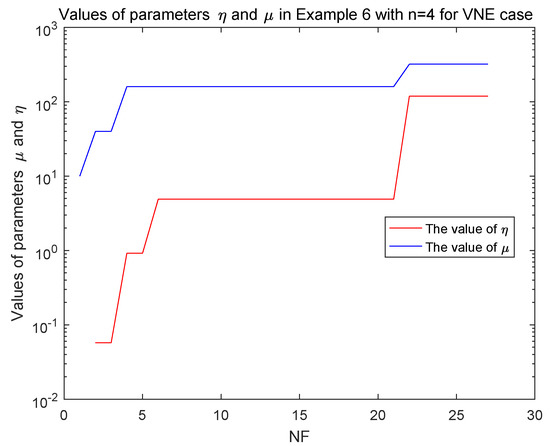
Figure 8.
The values of and in Problem 6 with in the VNE case.
6. Conclusions
In this paper, we consider a special class of nonconvex and nonsmooth composite problem. The problem is constituted by the sum of two functions, one is finite convex with inexact information and the other is a nonconvex function (lower-). For the nonconvex function, we utilize the convexification technique and adjust the parameter dynamically to make sure the linearization errors of the augment function nonnegative and construct the corresponding cutting plane models. Then, we regard the sum of the convex function and the augment function as an approximate function. For the convex function with inexact information, we construct the cutting plane model by its inexact information and notice that the cutting plane model may not be below the convex function. Then, the sum of the cutting plane models of the convex function with inexact information and the augment function is regarded as a cutting plane model of the approximate function. After that, we design an adaptive proximal bundle method. Meanwhile, for the convex function with inexact information, we utilize the noise management strategy and update adaptively the proximal parameter to reduce the influence of inexact information. Two polynomial functions including five different inexact types and six DC problems with different dimension are referred to in the numerical experiment. The preliminary numerical results show our algorithm is interesting and reliable. Meanwhile, our method can also be applied to some constraint problems and stochastic programming in the future.
Author Contributions
Conceptualization, X.W. and L.P.; methodology, X.W.; software, X.W., Q.W. and M.Z.; validation, X.W., L.P. and M.Z.; formal analysis, X.W. and Q.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data can be found in the manuscript.
Acknowledgments
We are greatly indebted to three anonymous referees for many helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Condat, L. A primal-dual splitting method for convex optimization involving Lipschitzian, proximable and linear composite terms. J. Optim. Theory Appl. 2013, 158, 460–479. [Google Scholar] [CrossRef]
- Li, G.Y.; Pong, T.K. Global convergence of splitting methods for nonconvex composite optimization. SIAM J. Optim. 2015, 25, 2434–2460. [Google Scholar] [CrossRef]
- Hong, M.; Luo, Z.Q. On the linear convergence of the alternating direction method of multipliers. Math. Program. 2017, 162, 165–199. [Google Scholar] [CrossRef]
- Li, D.; Pang, L.P.; Chen, S. A proximal alternating linearization method for nonconvex optimization problems. Optim. Method Softw. 2014, 29, 771–785. [Google Scholar] [CrossRef]
- Burke, J.V.; Lewis, A.S.; Overton, M.L. A robust gradient sampling algorithm for nonsmooth, nonconvex optimization. SIAM J. Optim. 2005, 15, 751–779. [Google Scholar] [CrossRef]
- Kiwiel, K.C. A method of centers with approximate subgradient linearizations for nonsmooth convex optimization. SIAM J. Optim. 2008, 18, 1467–1489. [Google Scholar] [CrossRef]
- Yuan, G.L.; Meng, Z.H.; Li, Y. A modified Hestenes and Stiefel conjugate gradient algorithm for large-scale nonsmooth minimizations and nonlinear equations. J. Optim. Theory Appl. 2016, 168, 129–152. [Google Scholar] [CrossRef]
- Yuan, G.L.; Sheng, Z. Nonsmooth Optimization Algorithms; Science Press: Beijing, China, 2017. [Google Scholar]
- Yuan, G.L.; Wei, Z.X.; Li, G. A modified Polak-Ribière-Polyak conjugate gradient algorithm for nonsmooth convex programs. J. Comput. Appl. Math. 2014, 255, 86–96. [Google Scholar] [CrossRef]
- Lv, J.; Pang, L.P.; Meng, F.F. A proximal bundle method for constrained nonsmooth nonconvex optimization with inexact information. J. Glob. Optim. 2018, 70, 517–549. [Google Scholar] [CrossRef]
- Yang, Y.; Pang, L.P.; Ma, X.F.; Shen, J. Constrained nonconvex nonsmooth optimization via proximal bundle method. J. Optim. Theory Appl. 2014, 163, 900–925. [Google Scholar] [CrossRef]
- Fuduli, A.; Gaudioso, M.; Giallombardo, G. Minimizing nonconvex nonsmooth functions via cutting planes and proximity control. SIAM J. Optim. 2004, 14, 743–756. [Google Scholar] [CrossRef]
- Sagastizábal, C. Composite proximal bundle method. Math. Program. 2013, 140, 189–233. [Google Scholar] [CrossRef]
- Mäkelä, M.M. Survey of bundle methods for nonsmooth optimization. Optim. Method Softw. 2002, 17, 1–29. [Google Scholar] [CrossRef]
- Hare, W.; Sagastizábal, C.; Solodov, M. A proximal bundle method for nonsmooth nonconvex functions with inexact information. Comput. Optim. Appl. 2016, 63, 1–28. [Google Scholar] [CrossRef]
- Sagastizábal, C.; Hare, W. A redistributed proximal bundle method for nonconvex optimization. SIAM J. Optim. 2010, 20, 2442–2473. [Google Scholar]
- Kiwiel, K.C. A proximal bundle method with approximate subgradient linearizations. SIAM J. Optim. 2006, 16, 1007–1023. [Google Scholar] [CrossRef]
- Kiwiel, K.C. A linearization algorithm for nonsmooth minimization. Math. Oper. Res. 1985, 10, 185–194. [Google Scholar] [CrossRef]
- Tang, C.M.; Liu, S.; Jian, J.B.; Li, J.L. A feasible SQP-GS algorithm for nonconvex, nonsmooth constrained optimization. Numer. Algorithms 2014, 65, 1–22. [Google Scholar] [CrossRef]
- Tang, C.M.; Jian, J.B. Strongly sub-feasible direction method for constrained optimization problems with nonsmooth objective functions. Eur. J. Oper. Res. 2012, 218, 28–37. [Google Scholar] [CrossRef]
- Hintermüller, M. A proximal bundle method based on approximate subgradients. Comput. Optim. Appl. 2001, 20, 245–266. [Google Scholar] [CrossRef]
- Lukšan, L.; Vlček, J. A bundle-Newton method for nonsmooth unconstrained minimization. Math. Program. 1998, 83, 373–391. [Google Scholar] [CrossRef]
- Solodov, M.V. On approximations with finite precision in bundle methods for nonsmooth optimization. J. Optim. Theory Appl. 2003, 119, 151–165. [Google Scholar] [CrossRef]
- Kiwiel, K.C. Restricted step and Levenberg-Marquardt techniques in proximal bundle methods for nonconvex nondifferentiable optimization. SIAM J. Optim. 1996, 6, 227–249. [Google Scholar] [CrossRef]
- Borghetti, A.; Frangioni, A.; Lacalandra, F.; Nucci, C.A. Lagrangian heuristics based on disaggregated bundle methods for hydrothermal unit commitment. IEEE Trans Power Syst. 2003, 18, 313–323. [Google Scholar] [CrossRef]
- Zhang, Y.; Gatsis, N.; Giannakis, G.B. Disaggregated bundle methods for distributed market clearing in power networks. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 835–838. [Google Scholar]
- Gao, H.; Lv, J.; Wang, X.L.; Pang, L.P. An alternating linearization bundle method for a class of nonconvex optimization problem with inexact information. J. Ind. Manag. Optim. 2021, 17, 805–825. [Google Scholar] [CrossRef]
- Goldfarb, D.; Ma, S.; Scheinberg, K. Fast alternating linearization methods for minimizing the sum of two convex functions. Math. Program. 2013, 141, 349–382. [Google Scholar] [CrossRef]
- Bolte, J.; Sabach, S.; Teboulle, M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 2014, 146, 459–494. [Google Scholar] [CrossRef]
- De Oliveira, W.; Solodov, M. Bundle Methods for Inexact Data; Technical Report; 2018; Available online: http://pages.cs.wisc.edu/~solodov/wlomvs18iBundle.pdf (accessed on 1 April 2021).
- Fábián, C.I.; Wolf, C.; Koberstein, A.; Suhl, L. Risk-averse optimization in two-stage stochastic models: Computational aspects and a study. SIAM J. Optim. 2015, 25, 28–52. [Google Scholar] [CrossRef]
- Solodov, M.V.; Zavriev, S.K. Error stability properties of generalized gradient-type algorithms. J. Optim. Theory Appl. 1998, 98, 663–680. [Google Scholar] [CrossRef]
- De Oliveira, W.; Sagastizábal, C.; Lemaréchal, C. Convex proximal bundle methods in depth: A unified analysis for inexact oracles. Math. Program. 2014, 148, 241–277. [Google Scholar] [CrossRef]
- Hertlein, L.; Ulbrich, M. An inexact bundle algorithm for nonconvex nonsmooth minimization in Hilbert space. SIAM J. Optim. 2019, 57, 3137–3165. [Google Scholar] [CrossRef]
- Noll, D. Bundle Method for Non-Convex Minimization with Inexact Subgradients and Function Values. In Computational and Analytical Mathematics; Springer Proceedings in Mathematics; 2013; Volume 50, pp. 555–592. Available online: https://link.springer.com/chapter/10.1007/978-1-4614-7621-4_26 (accessed on 10 March 2021).
- Rockafellar, R.T.; Wets, R.J.B. Variational Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Hiriart-Urruty, J.B.; Lemaréchal, C. Convex Analysis and Minimization Algorithms; No. 305–306 in Grund. der math. Wiss; Springer: Berlin, Germany, 1993; Volume 2, Available online: https://core.ac.uk/display/44384992 (accessed on 10 March 2021).
- Hare, W.; Sagastizábal, C. Computing proximal points of nonconvex functions. Math. Program. 2009, 116, 221–258. [Google Scholar] [CrossRef]
- Bonnans, J.; Gilbert, J.; Lemaréchal, C.; Sagastizábal, C. Numerical Optimization: Theoretical and Practical Aspects, 2nd ed.; Springer: Berlin, Germany, 2006. [Google Scholar]
- Emiel, G.; Sagastizábal, C. Incremental-like bundle methods with application to energy planning. Comput. Optim. Appl. 2010, 46, 305–332. [Google Scholar] [CrossRef]
- Fuduli, A.; Gaudioso, M.; Giallombardo, G. A DC piecewise affine model and a bundling technique in nonconvex nonsmooth minimization. Optim. Method Softw. 2004, 19, 89–102. [Google Scholar] [CrossRef]
- Joki, K.; Bagirov, A.M.; Karmitsa, N.; Mäkelä, M.M. A proximal bundle method for nonsmooth DC optimization utilizing nonconvex cutting planes. J. Glob. Optim. 2017, 68, 501–535. [Google Scholar] [CrossRef]
- Bagirov, A. A method for minimization of quasidifferentiable functions. Optim. Method Softw. 2002, 17, 31–60. [Google Scholar] [CrossRef]
- Bagirov, A.M.; Ugon, J. Codifferential method for minimizing nonsmooth DC functions. J. Glob. Optim. 2011, 50, 3–22. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).