Simulation experiments were carried out to study the type I errors and the powers of the four methods proposed to simultaneously compare the predictive values: the global hypothesis test based on the chi-square distribution (Equation (5)), the individual hypothesis tests each one to an error (Equation (6)), the individual hypothesis tests (Equation (6)) applying the Bonferroni method and the individual hypothesis tests (Equation (6)) applying the Holm method. We have also studied the effect of a misspecification of the prevalence on the asymptotic behavior of these methods and on the estimators of the PVs.
The experiments were designed setting the values of the PVs. For each BDT, we took as PVs the values 0.60, 0.65, …, 0.90, 0.95, and as disease prevalence we took the values 10%, 25% and 50%. Based on the PVs and the prevalence,
Se and
Sp of each BDT were calculated from the Equation (1), only considering those cases in which the solutions are between 0 and 1. As values of the correlation coefficients
and
we took low values (25% of the maximum value), intermediate (50% of the maximum value) and high (75% of the maximum value), where the maximum value of each correlation coefficient is:
and
respectively. As sample sizes, we took the values
. The simulation experiments were carried out with R [
14], using the “bindata” package [
15] to generate the samples of each type I bivariate binomial distribution.
Regarding the random samples, these were generated in the following way. Firstly, once the values of the PVs and of the prevalence were set, we calculated the sensitivities, the specificities and the maximum values of the coefficients and . We then generated 10,000 random samples from a type I bivariate binomial distribution with a sample size , probabilities and , and correlation coefficient . Similarly, we generated another 10,000 random samples from a type I bivariate binomial distribution with a sample size , probabilities and , and correlation coefficient . In this way, we obtained the marginal frequencies and ( and ) of each one of the 10,000 case (control) samples. The rest of the marginal frequencies were easily calculated: , , and . In order to construct the table of each case sample, we generated a random value from a doubly truncated binomial distribution of parameters and , with . This is necessary so that the sum of the frequencies leads to the marginal totals randomly generated through the type I bivariate binomial distribution. In the same way, in order to construct the table of each control sample, we generated a random value from a doubly truncated binomial distribution of parameters and , with . For each one of the 10,000 case (control) samples, once we have generated the values , and (, and ) it is easy to construct the complete table. Thus, , and for the case samples, and , and for the control samples. For the experiments was set. Moreover, all of the samples were generated in such a way that in all of them the parameters and the variances-covariances can be estimated. If in a random sample it is obtained that , with , then and , and therefore the test statistic cannot be calculated since is a non-singular matrix. This problem occurs mainly when the sample size is small or moderate. In this situation, the sample has been discarded and another is generated in its place until the 10,000 samples are obtained.
3.1. Type I Errors and Powers
In
Table 2 and
Table 3, we can see some results obtained for the type I errors of the global test and of the alternative methods proposed in
Section 2. In these tables, we can only see the results for the global test, the individual comparisons with
and with the Bonferroni method. The results obtained with the Holm method are not shown as they are practically the same as those obtained with the Bonferroni method. From the results obtained we can draw the following conclusions. In general terms, the type I error of the global hypothesis test fluctuates around the nominal error, especially in the case of samples sized
, depending on the prevalence and the correlations between the two BDTs. For samples with smaller sizes
, the type I error of the global test is lower than
. The correlations between the two BDTs have an important effect on the type I error of the global test, with a decrease in the type I error when there is an increase in the correlation coefficients.
Regarding the method based on the individual hypothesis tests and to an error each one of them, the type I error may clearly overwhelm the nominal error (a situation that we have considered when the type I error is greater than 7%), especially when the correlations are not high. Consequently, this method may lead to erroneous results (false significances) and, therefore, should not be used. As for solving the global test from the individual tests applying the Bonferroni (Holm) method, the type I error has a very similar behavior to that of the global hypothesis test.
Regarding the powers of the hypothesis tests, in
Table 4 and
Table 5 we can see some of the results obtained for the global test and other alternative methods. The results obtained with the Holm method are not shown as they are practically the same as those obtained with the Bonferroni method. The power of the global hypothesis test is calculated as the proportion of samples in which it is accepted that
or
(being true that
or
). From the results, the following conclusions are obtained. The disease prevalence has an important effect on the power of each one of the methods to solve the global test, and the power increases with an increase in the prevalence. Regarding the correlations
and
, these do not have a clear effect on the power, and the power increases sometimes and decreases other times when the correlations increase. In general terms, when the prevalence is small
we need large samples
so that the power of the global hypothesis test is greater than 80%; for a prevalence of 25% with sample sizes
we obtain a power greater than 80%; and for a very large prevalence
with sample sizes
we obtain a very higher power, greater than 80%–90%, depending on the difference between the PVs.
The power of the method based on the individual hypothesis tests to an error is greater than that of the global test based on the chi-square distribution due to the fact that its type I error is also greater. Regarding the hypothesis test based on the individual tests with the Bonferroni method, in general terms, its power is very similar to that of the global test when the sample sizes are large. When the sample sizes are small or moderate, in general terms and depending on prevalence and correlations, the power of the global test is slightly greater than that of the individual tests with the Bonferroni method. The same conclusions are obtained when the Holm method is applied (whose results are almost identical to those of the Bonferroni method).
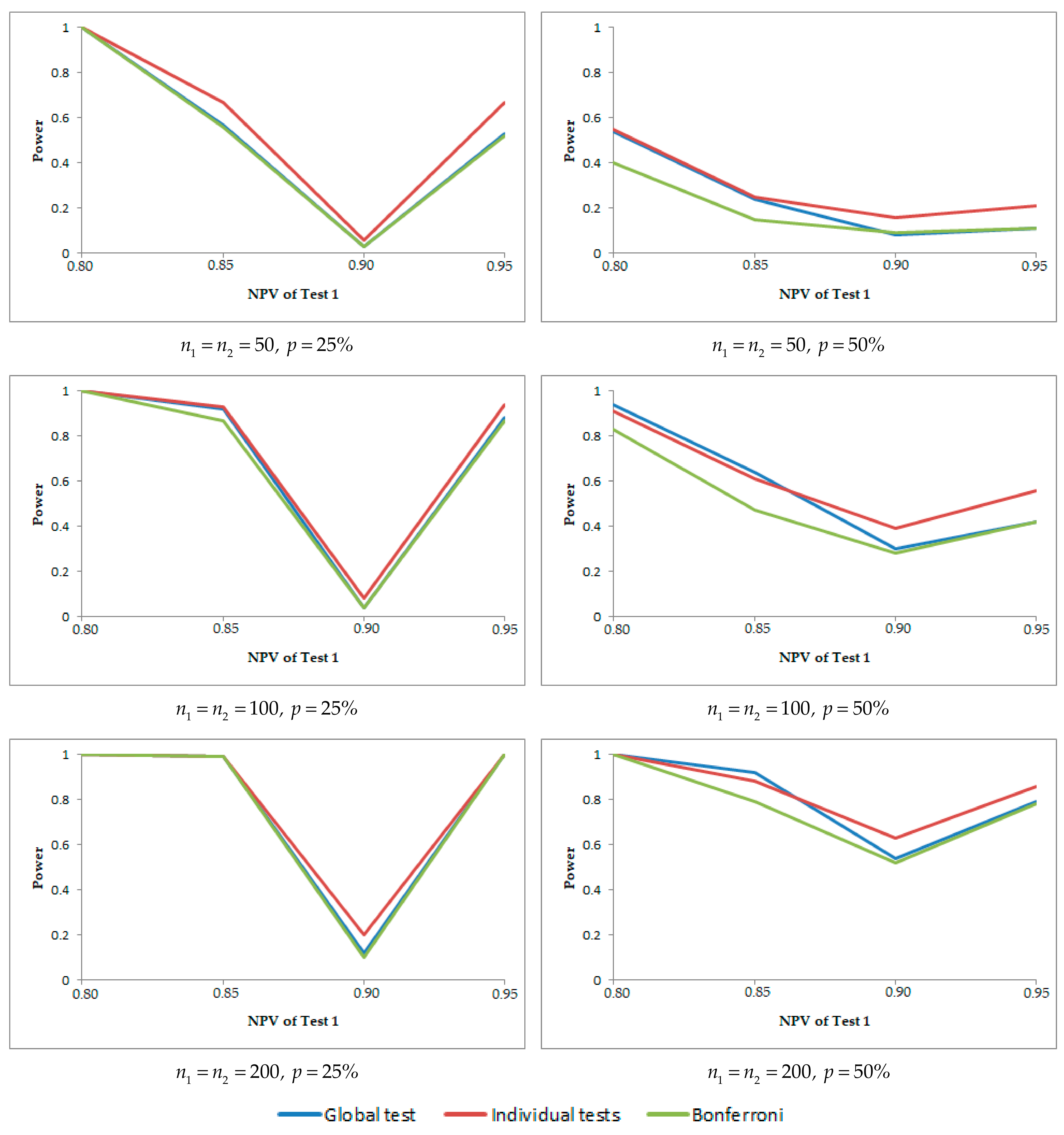
The graphs in
Figure 1 show the powers of the three methods when
,
,
and
, for different sample sizes
,
and values intermediate of the correlation coefficients. These graphs show that when
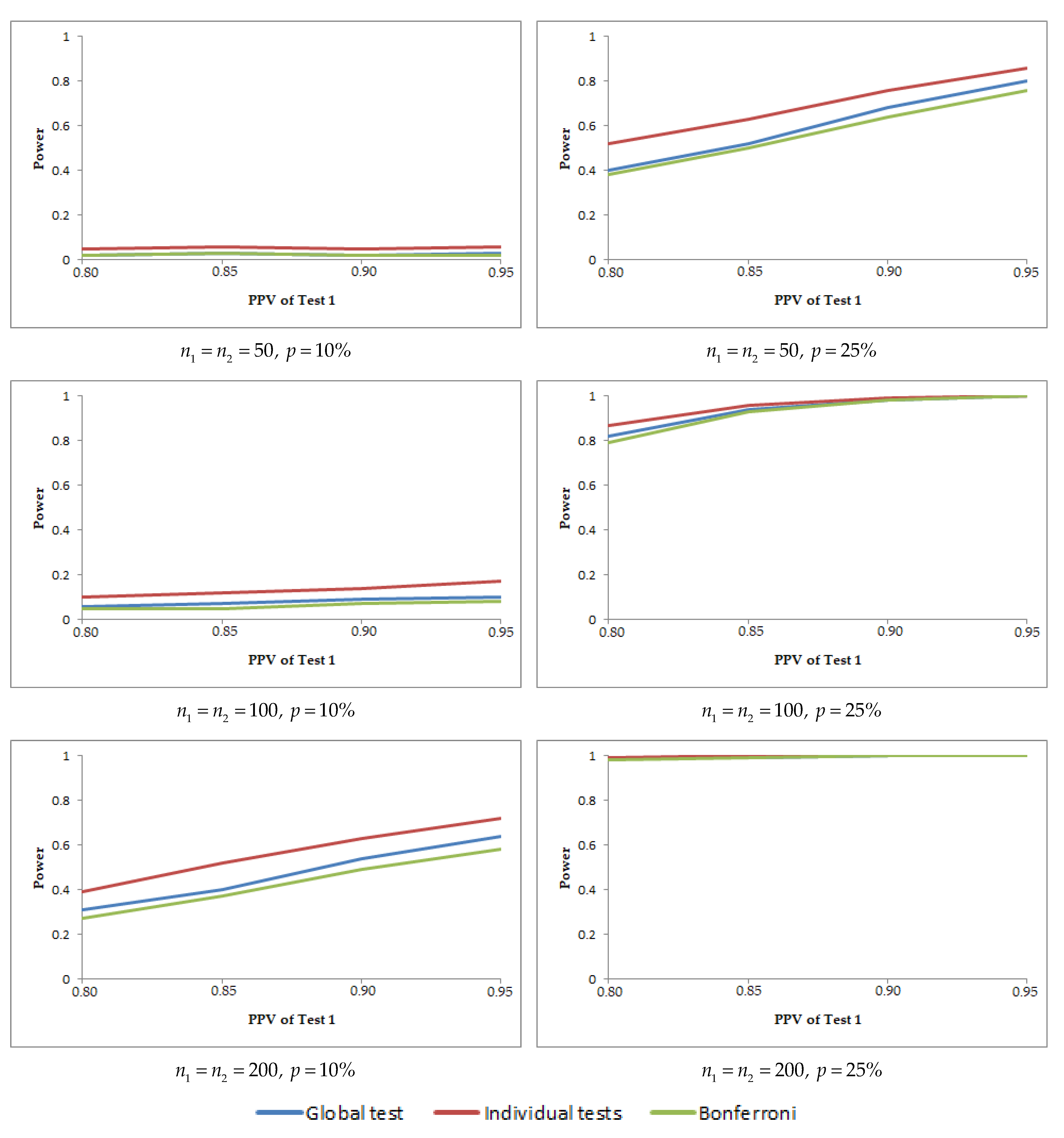
varies and the rest of the PVs are constant, the powers decrease when the prevalence increases. Similarly, the graphs in
Figure 2 show the powers of the three methods when
,
,
and
, for different sample sizes
,
and values intermediate of the correlation coefficients. These graphs show that when the
varies and the rest of the PVs are constant, the power of each method increases when the prevalence increases.
As conclusions of the results obtained in the simulation experiments, the global hypothesis test based on the chi-square distribution behaves well in terms of the type I error (it does not overwhelm the nominal error of 5%), the same as the individual tests along with the Bonferroni (Holm) method. The method based on the individual tests to a global error should not be used as it may clearly overwhelm the nominal error.
In the simulation experiments, the proportion of times that
and that
are correctly concluded has also been studied. This issue is of special interest when the alternative hypothesis of the global test is true, as it can be a valid method to investigate the causes of significance. The study was carried out by applying the individual hypothesis tests together with the Bonferroni (Holm) method. Individual tests to an
error have not been considered as they have a type I error that can exceed the nominal error. If it is verified that
, then this study is equivalent to studying the power of the individual test
to an
error (since the Bonferroni method has been applied), where
is
or
. If it is verified that
then this study is equivalent to studying the type I error of the individual test
to an
error. In the scenarios considered in
Table 4 and
Table 5 it is verified that
and that
. Therefore, for these two scenarios, the power of the test
and the type I error of the test
have been studied, each with an error equal to
.
Table 6 and
Table 7 show the results obtained applying the Bonferroni method. The results obtained with the Holm method are not shown as they are practically the same as those obtained with the Bonferroni method.
In general terms, the hypothesis test has a high power when the sample sizes are moderate or high, depending on the prevalence and the correlation coefficients. Its behavior is very similar to that of the global hypothesis test. With respect to the test , its type I error fluctuates around the nominal error (2.5%) when the sample sizes are moderate or large, depending on the prevalence of the correlation coefficients. In general terms, the hypothesis tests and have a good asymptotic behavior, both in terms of power and type I error.
From the results obtained in the simulation experiments, we propose the following method to compare the PVs of two BDTs subject to a case-control design: (1) Applying the global hypothesis test based on the chi-square distribution (Equation (5)) to an error; (2) If the global hypothesis test is not significant, the equality hypothesis of the PVs is not rejected; if the global hypothesis test is significant to an error, the investigation of the causes of the significance is made by testing the individual tests (Equation (6)) and applying the Bonferroni method or the Holm method to an error. Therefore, if the global test is significant, the investigation of the significance consists in solving the individual hypothesis tests and , each of them to an error (Bonferroni method) or applying Holm method.
This method to simultaneously compare the PVs is very similar to other methods used in other statistical models, such as the analysis of variance: first the global test is resolved to an error, and if it is significant then the causes of significance are investigated from pairwise comparisons and the application of a multiple comparison method.
3.2. Effect of the Prevalence
The estimation and comparison of the PVs of two BDTs subject to a case-control design requires knowledge of the disease prevalence. To study the effect of a misspecification of the prevalence on the comparison of the PVs and on the estimators of the PVs, we carried out simulation experiments similar to those made to study the type I errors and the powers. For this purpose, we took as the prevalence for the inference a misspecification equal to 10% and to 20% of the value of the prevalence set, and we have studied the type I errors and the powers of the global test and of the Bonferroni and Holm methods, and the relative root mean square error (
RRMSE) of the estimator of each PVs. Thus, for each estimator we calculated the relative root mean square error (
RRMSE), i.e.,
where
is the
PPV or the
NPV of the
ith BDT
and
is its estimator calculated from the
kth sample
, and
. For the values of the parameters we took as prevalence
respectively, and to estimate the PVs we took as prevalence
with
. A value
can be considered as a small (moderate) value of the relative deviation.
Table 8 shows some of the results obtained for the type I errors and the powers of the global test and the Bonferroni method (the results of the Holms method are not shown as they are practically identically to those obtained with the Bonferroni method). In this Table we show the results when there is no misspecification of the prevalence
and when there is a misspecification of the prevalence (
or
). From the results of these experiments, it is verified that the type I errors of the methods studied do not overwhelm the nominal error (
). In general terms there are no important differences between the type I errors when there is a misspecification of the prevalence and when there is not. Regarding the powers, the conclusions are also very similar, there are no important differences between the powers when there is a misspecification of the prevalence and when there is not.
Regarding the estimators,
Table 8 shows some of the results obtained for the
RRMSEs (in %) of the estimators of the PVs of Test 1 (the results for Test 2 are identical). In general terms, the difference between the
RRMSEs is small (around 5% or less, in absolute value) when the two sample sizes are moderate
or large
and the relative deviation is small (10%) or moderate (20%). Therefore, a small or moderate misspecification of the prevalence (
or
) does not have an important effect on the estimators of the PVs when the samples are moderate or large. Additionally, there is not an important difference between the
RRMSEs when the sample sizes are small
and the relative deviation is small. However, the difference between the
RRMSEs is larger when the sample sizes are small and the relative deviation is moderate. In this situation, a misspecification of the prevalence has an important effect on the estimators of the PVs.







{kind=link}
{kind=link}