
Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm and Its Application in Judicial Practice


Abstract
1. Introduction
2. Distance and Similarity Measure and Integration Operation of Hesitant Fuzzy Linguistic Decision Information
2.1. Hesitant Fuzzy Linguistic Term Sets
- (1)
- For any, if;
- (2)
- The negation operator is defined by, and especially.
- Lower bound:if, ;
- Upper bound: if, ;
- ;
- ;
- ;
- ;
- ;
- ;
- .
- ,
- , ,
- ;
- ;
- ;
- ;
- ;
- .
2.2. Distance and Similarity Measures of Hesitant Fuzzy Linguistic Decision Information
- ;
- , if and only if;
- .
- ;
- if and only if;
- .
2.3. Hesitant Fuzzy Linguistic Bonferroni Mean Operator
3. Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm
3.1. Agglomerative Hierarchical Clustering Algorithm
- Step 1: Take a sample as the initial set of clusters . Then, calculate the distance between each pair of clusters;
- Step 2: Find the minimum distance , merge clusters and into a new cluster and generate a new set of clusters: ;
- Step 3: Calculate the distance between the new cluster and the other clusters. Repeat Step 2 until all samples cluster to the target category number.
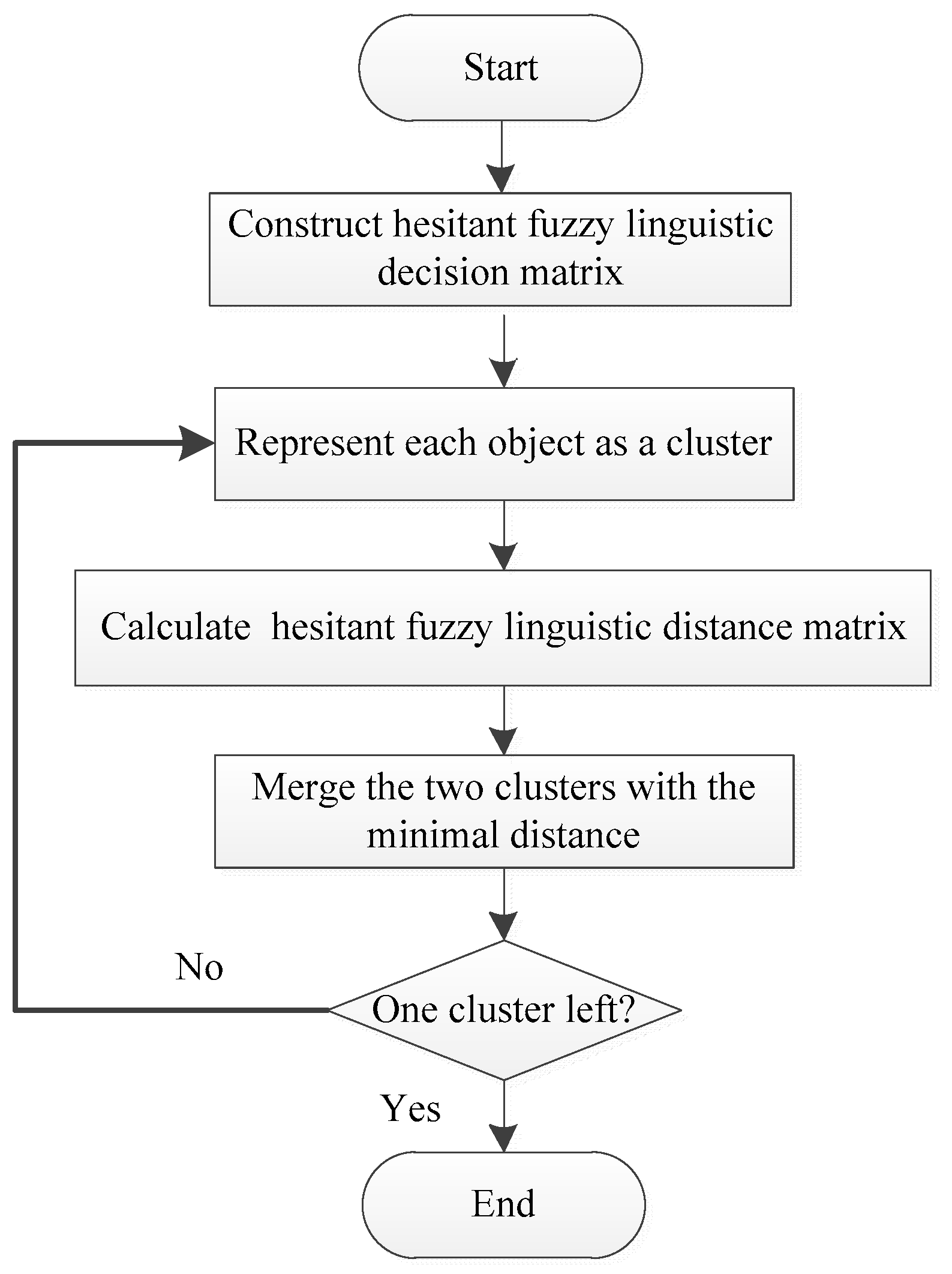
3.2. Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm
- Step 1: Supposing that the scheme set of a certain multi-attribute problem is , then the attribute set is , and the attribute weight vector is , satisfying and . The decision-maker uses linguistic expressions or statements to evaluate the series of decision schemes under each attribute . According to context-free grammar rules, the transformation function is used to transform the linguistic decision information into the HFLNs , and the hesitant fuzzy linguistic decision matrix is obtained;
- Step 2: Take each object as a class, and use Equations (11) or (12) to calculate the distance between the classes. Then, get the hesitant fuzzy linguistic distance matrix ;
- Step 3: Find the minimum distance in the hesitant fuzzy linguistic distance matrix , merge and into a new class and calculate the center of class using Equation (20);
- Step 4: Calculate the distance between the new class and the other classes to obtain a new hesitant fuzzy linguistic distance matrix;
- Step 5: Repeat Steps 3 and 4 until all classes are grouped into one class.
4. Cluster Analysis of the Person Subjected to Execution Based on Hesitant Fuzzy Linguistic Decision Information
4.1. Screening the Path of Concealment of Property by the Person Subjected to Execution
- Step 1: Suppose that the executive judge needs to judge the possibility of concealing property for persons subjected to execution , respectively. is the sample of representative persons subjected to execution extracted by the executive judge from the case database of court enforcement, among which the sample number of persons subjected to execution (laolai) who have concealed property behavior is ;
- Step 2: According to the behavior characteristics of the concealment of property by the person subjected to execution, the executive judges use linguistic expressions or statements to conduct a multidimensional evaluation of persons subjected to execution and give corresponding hesitant fuzzy linguistic decision information;
- Step 3: samples to be identified are added to the known sample of m subjects to perform fuzzy clustering on subjects . To improve the accuracy of clustering and discrimination, it is assumed that one sample of the subject to be identified is added to m known samples at a time, and then fuzzy clustering is carried out for these subjects ;
- Step 4: According to the clustering results, is divided into classes . If the subject belongs to class , the sample number of laolai individuals in is , and the sample number of non-Laolai individuals is . Then, the quantified probability of the subject concealing property can be expressed as ;
- Step 5: Repeat Steps 3 and 4 until the quantified probability value of the concealed property of the subject to be identified is obtained in turn. The greater the probability value is, the greater the concealed property’s possibility, and the greater the corresponding control force is. According to the reasonable allocation of execution resources, complete the classification of the person under execution.
4.2. Numerical Example
- Step 1: According to the conversion function , the following hesitant fuzzy linguistic evaluation matrix can be generated:To calculate the distance between two HFLTSs more accurately, the HFLTSs with fewer elements add linguistic terms by Equation (3). The following standardized hesitant fuzzy linguistic evaluation matrix can be obtained:
- Step 2: Take each executed person as classes , , , and , and calculate the distance between the classes by using Equation (12) to get the hesitant fuzzy linguistic distance matrix :
- Step 3: In the hesitant fuzzy linguistic distance matrix , the minimum distance is . Therefore, and are merged into a new class, and the subjects are divided into four classes: , , and . Use Equation (20) to calculate the center of each new class:By adding linguistic terms to the HFLTSs with fewer elements, a standardized hesitant fuzzy linguistic evaluation matrix can be obtained:
- Step 4: Calculate the distance between class and classes , and , respectively, and get , and . The updated hesitant fuzzy linguistic distance matrix is :
- Step 5: In the hesitant fuzzy linguistic distance matrix , the minimum distance is . Therefore, and are merged into a new class, , and the subjects are divided into the following three categories: , and . Use Equation (14) to calculate the center of each new class:
4.3. Contrastive Analysis
- for all;
- if and only if;
- for all.
- is reflexive (i.e.,);
- is symmetric (i.e.,);
- is transitive (i.e.,).
- Step 1: Assume that is the set of clustering objects. Use Equations (14) or (15) to calculate the similarity between classes, and the hesitant fuzzy linguistic similarity matrix is obtained;
- Step 2: Given the confidence level , the -cutting matrix is constructed by Equation (31);
- Step 3: Judge whether is an equivalent Boole matrix. If is an equivalent Boole matrix, skip to Step 4. If not, then exists as a special submatrix in Definition 1 under a particular arrangement. In this case, as long as the 0 of the special submatrices is changed to 1, until no unique form of the submatrices is produced, then a new equivalent Boole matrix can be obtained;
- Step 4: If all the elements in row (column) and row (column) in are the same, then the cluster objects and can be combined into one class. According to the principle, the objects are classified.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ghosh, A.; Mishra, N.S.; Ghosh, S. Fuzzy clustering algorithms for unsupervised change detection in remote sensing images. Inf. Sci. 2011, 181, 699–715. [Google Scholar] [CrossRef]
- Chen, N.; Xu, Z.; Xia, M. Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis. Appl. Math. Model. 2013, 37, 2197–2211. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Z. Hesitant fuzzy agglomerative hierarchical clustering algorithms. Int. J. Syst. Sci. 2013, 46, 562–576. [Google Scholar] [CrossRef]
- Ruspini, E.H. A new approach to clustering. Inf. Control. 1969, 15, 22–32. [Google Scholar] [CrossRef]
- Liang, G.-S.; Chou, T.-Y.; Han, T.-C. Cluster analysis based on fuzzy equivalence relation. Eur. J. Oper. Res. 2005, 166, 160–171. [Google Scholar] [CrossRef]
- Wang, Y.-J. A clustering method based on fuzzy equivalence relation for customer relationship management. Expert Syst. Appl. 2010, 37, 6421–6428. [Google Scholar] [CrossRef]
- Bai, C.; Dhavale, D.; Sarkis, J. Complex investment decisions using rough set and fuzzy c-means: An example of investment in green supply chains. Eur. J. Oper. Res. 2016, 248, 507–521. [Google Scholar] [CrossRef]
- Oner, S.C.; Oztaysi, B. An interval type 2 hesitant fuzzy mcdm approach and a fuzzy c means clustering for retailer clustering. Soft Comput. 2018, 22, 4971–4987. [Google Scholar] [CrossRef]
- Eke, S.; Clerc, G.; Aka-Ngnui, T.; Fofana, I. Transformer condition assessment using fuzzy C-means clustering techniques. IEEE Electr. Insul. Mag. 2019, 35, 47–55. [Google Scholar] [CrossRef]
- Murtagh, F.; Legendre, P. Ward’s hierarchical clustering method: Clustering criterion and agglomerative algorithm. Comput. Sci. 2014, 31, 274–295. [Google Scholar]
- Bordogna, G.; Pagani, M.; Pasi, G. A dynamic hierarchical fuzzy clustering algorithm for information filtering. In Soft Computing in Web Information Retrieval; Springer: Berlin, Germany, 2006. [Google Scholar]
- Zhao, H.; Xu, Z.; Liu, S.; Wang, Z. Intuitionistic fuzzy MST clustering algorithms. Comput. Ind. Eng. 2012, 62, 1130–1140. [Google Scholar] [CrossRef]
- Xu, D.; Xu, Z.; Liu, S.; Zhao, H. A spectral clustering algorithm based on intuitionistic fuzzy information. Knowledge-Based Syst. 2013, 53, 20–26. [Google Scholar] [CrossRef]
- Yang, M.-S.; Lin, D.-C. On similarity and inclusion measures between type-2 fuzzy sets with an application to clustering. Comput. Math. Appl. 2009, 57, 896–907. [Google Scholar] [CrossRef]
- Qiu, C.; Xiao, J.; Han, L.; Iqbal, M.N. Enhanced interval type-2 fuzzy c-means algorithm with improved initial center. Pattern Recognit. Lett. 2014, 38, 86–92. [Google Scholar] [CrossRef]
- Li, C.; Zhao, H.; Xu, Z. Kernel C-Means Clustering Algorithms for Hesitant Fuzzy Information in Decision Making. Int. J. Fuzzy Syst. 2017, 20, 141–154. [Google Scholar] [CrossRef]
- Song, C.; Xu, Z.; Zhao, H. New correlation coefficients between probabilistic hesitant fuzzy sets and their appli-cations in cluster analysis. Int. J. Fuzzy Syst. 2019, 21, 355–368. [Google Scholar] [CrossRef]
- Riaz, M.; Çagman, N.; Wali, N.; Mushtaq, A. Certain properties of soft multi-set topology with applications in multi-criteria decision making. Decis. Making: Appl. Manag. Eng. 2020, 3, 70–96. [Google Scholar] [CrossRef]
- Riaz, M.; Davvaz, B.; Firdous, A.; Fakhar, A. Novel concepts of soft rough set topology with applications. J. Intell. Fuzzy Syst. 2019, 36, 3579–3590. [Google Scholar] [CrossRef]
- Riaz, M.; Hashmi, M.R. Soft rough Pythagorean m-polar fuzzy sets and Pythagorean m-polar fuzzy soft rough sets with application to decision-making. Comput. Appl. Math. 2020, 39, 16. [Google Scholar] [CrossRef]
- Wu, S.; Lin, J.; Zhang, Z. New distance measures of hesitant fuzzy linguistic term sets. Phys. Scr. 2020, 96, 015002. [Google Scholar] [CrossRef]
- Zhang, Z.; Lin, J.; Zhang, H.; Wu, S.; Jiang, D. Hybrid TODIM Method for Law Enforcement Possibility Evaluation of Judgment Debtor. Mathematics 2020, 8, 1806. [Google Scholar] [CrossRef]
- Zhang, Z.; Lin, J.; Miao, R.; Zhou, L. Novel distance and similarity measures on hesitant fuzzy linguistic term sets with application to pattern recognition. J. Intell. Fuzzy Syst. 2019, 37, 2981–2990. [Google Scholar] [CrossRef]
- Liao, H.; Xu, Z.; Zeng, X.-J.; Merigó, J.M. Qualitative decision making with correlation coefficients of hesitant fuzzy linguistic term sets. Knowl. Based Syst. 2015, 76, 127–138. [Google Scholar] [CrossRef]
- Xu, Z. Deviation measures of linguistic preference relations in group decision making. Omega 2005, 33, 249–254. [Google Scholar] [CrossRef]
- Rodriguez, R.M.; Martinez, L.; Herrera, F. Hesitant Fuzzy Linguistic Term Sets for Decision Making. IEEE Trans. Fuzzy Syst. 2011, 20, 109–119. [Google Scholar] [CrossRef]
- Xu, Z. Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf. Sci. 2004, 168, 171–184. [Google Scholar] [CrossRef]
- Zhu, B.; Xu, Z. Consistency Measures for Hesitant Fuzzy Linguistic Preference Relations. IEEE Trans. Fuzzy Syst. 2014, 22, 35–45. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, M. Distance and similarity measures for hesitant fuzzy sets. Inf. Sci. 2011, 181, 2128–2138. [Google Scholar] [CrossRef]
- Liao, H.; Xu, Z.; Zeng, X.-J. Distance and similarity measures for hesitant fuzzy linguistic term sets and their application in multi-criteria decision making. Inf. Sci. 2014, 271, 125–142. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z.; Liao, H. Multiple criteria decision making based on Bonferroni means with hesitant fuzzy linguistic information. Soft Comput. 2016, 21, 6515–6529. [Google Scholar] [CrossRef]
- Miyamoto, S. Fuzzy Sets in Information Retrieval and Cluster Analysis. Theory Decis. Lib. 1990, 16, 1–7. [Google Scholar] [CrossRef]
- Zhao, H.; Xu, Z.; Wang, Z. Intuitionistic fuzzy clustering algorithm based on boole matrix and association measure. Int. J. Inf. Technol. Decis. Mak. 2013, 12, 95–118. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Person Subjected to Execution | Attributes | ||
|---|---|---|---|
| Between very small and smaller | Greater than very large | Between smaller and medium | |
| At least very large | Between smaller and medium | Smaller | |
| Larger | At most very small | Very small | |
| Between smaller and medium | Lower than very small | Very large | |
| Very large | Between medium and larger | At least larger | |
| Clusters | HFLAH Clustering Algorithm | HFLBM Clustering Algorithm |
|---|---|---|
| 5 | ,,,, | ,,,, |
| 4 | ,,, | ,,, |
| 3 | ,, | ,, |
| 2 | , | , |
| 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Lin, J.; Zhang, Z.; Yang, Y. Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm and Its Application in Judicial Practice. Mathematics 2021, 9, 370. https://doi.org/10.3390/math9040370
Wu S, Lin J, Zhang Z, Yang Y. Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm and Its Application in Judicial Practice. Mathematics. 2021; 9(4):370. https://doi.org/10.3390/math9040370
Chicago/Turabian StyleWu, Shuangsheng, Jie Lin, Zhenyu Zhang, and Yushu Yang. 2021. "Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm and Its Application in Judicial Practice" Mathematics 9, no. 4: 370. https://doi.org/10.3390/math9040370
APA StyleWu, S., Lin, J., Zhang, Z., & Yang, Y. (2021). Hesitant Fuzzy Linguistic Agglomerative Hierarchical Clustering Algorithm and Its Application in Judicial Practice. Mathematics, 9(4), 370. https://doi.org/10.3390/math9040370