
Rockburst Interpretation by a Data-Driven Approach: A Comparative Study




Abstract
:1. Introduction
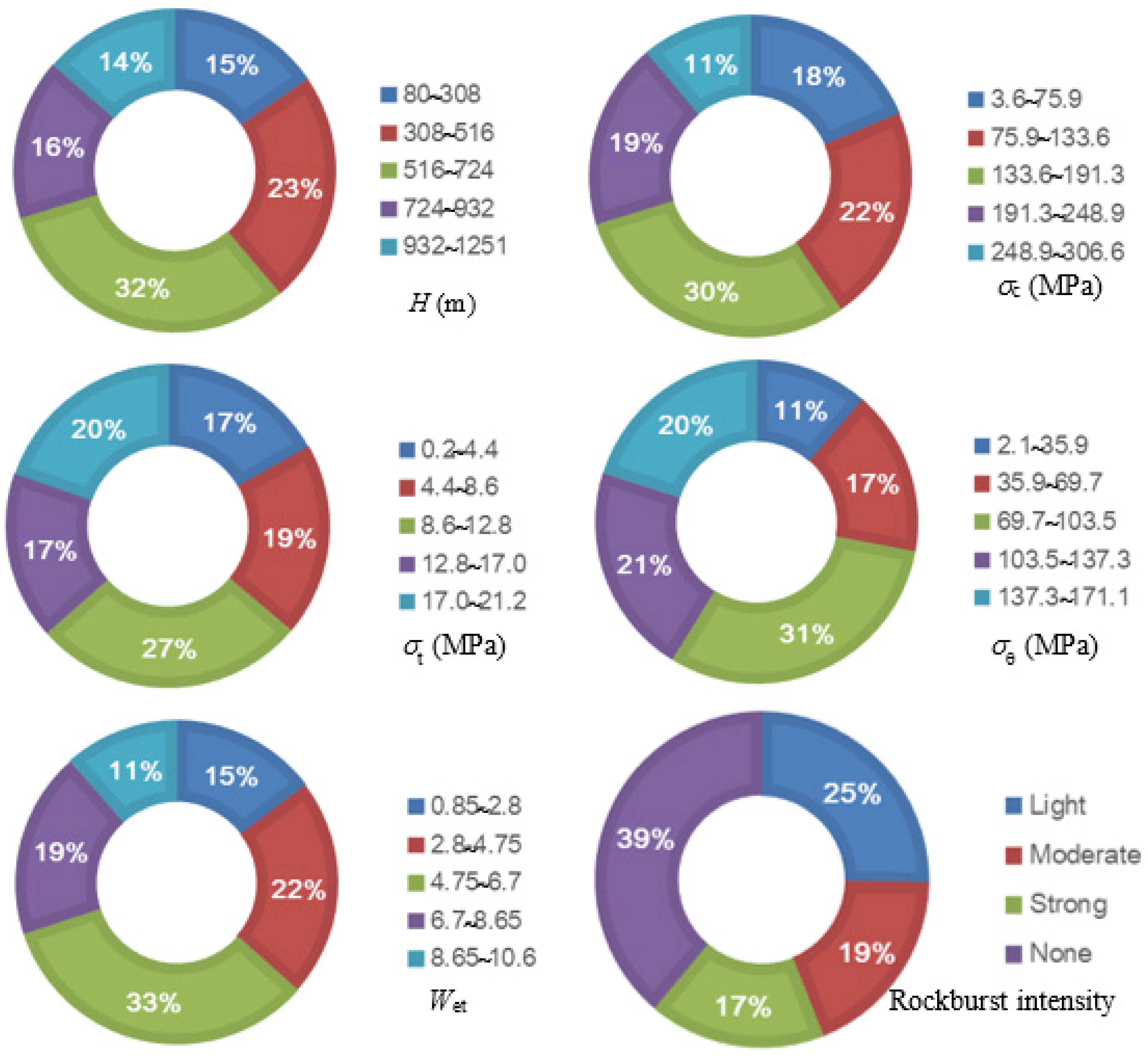
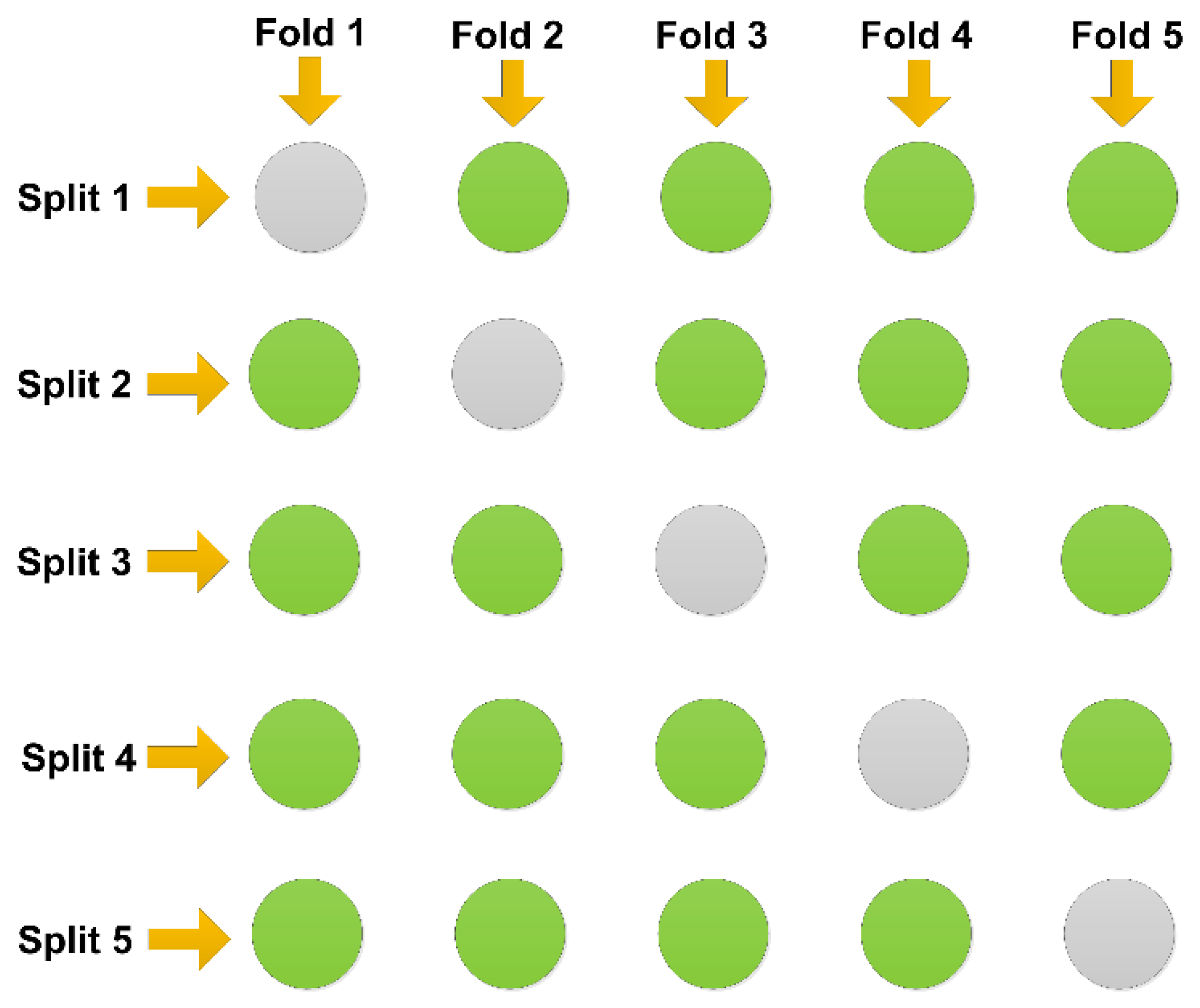
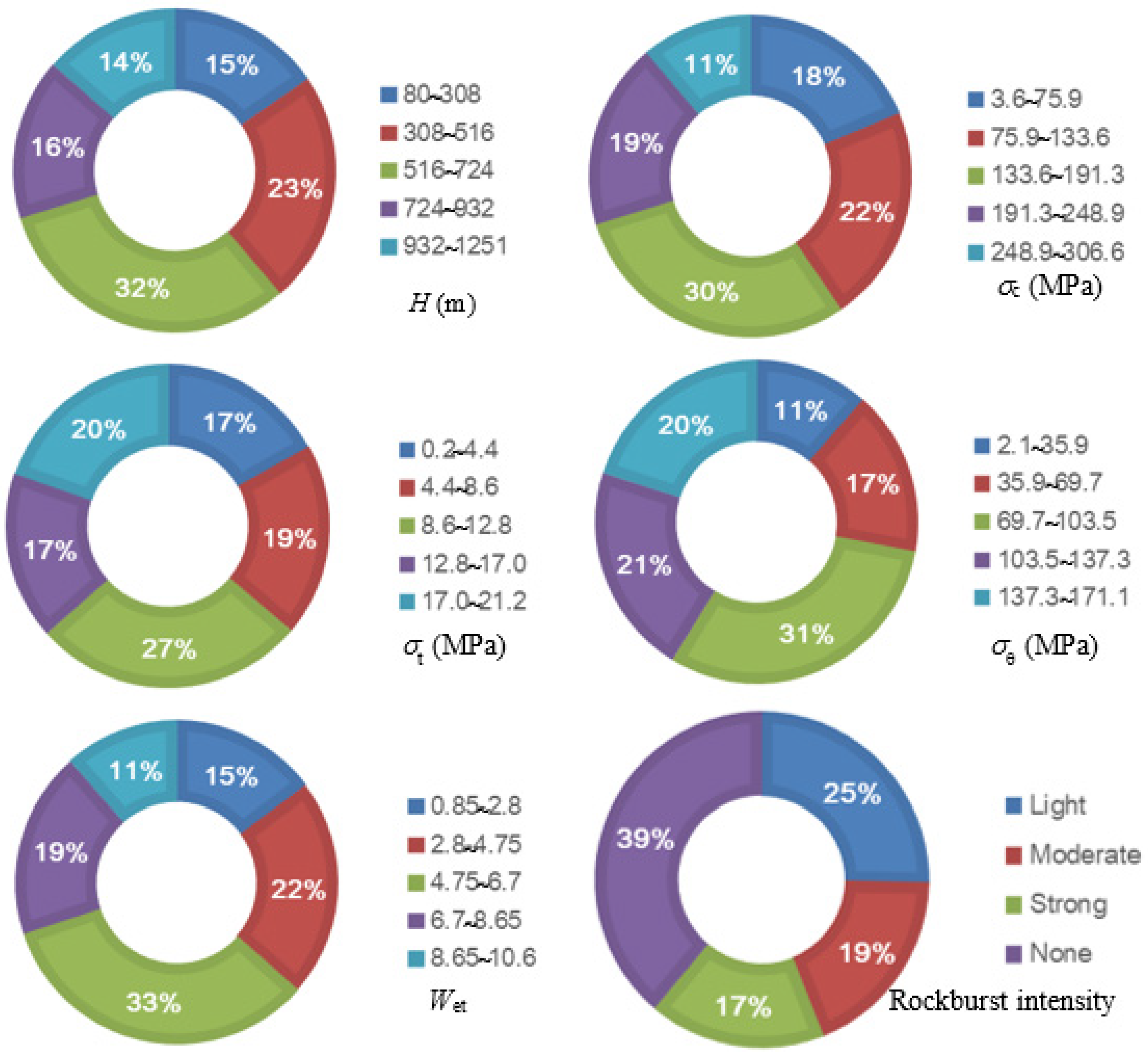
2. Dataset Preparation
3. Algorithm Background and Ensemble Model
3.1. Algorithms Description
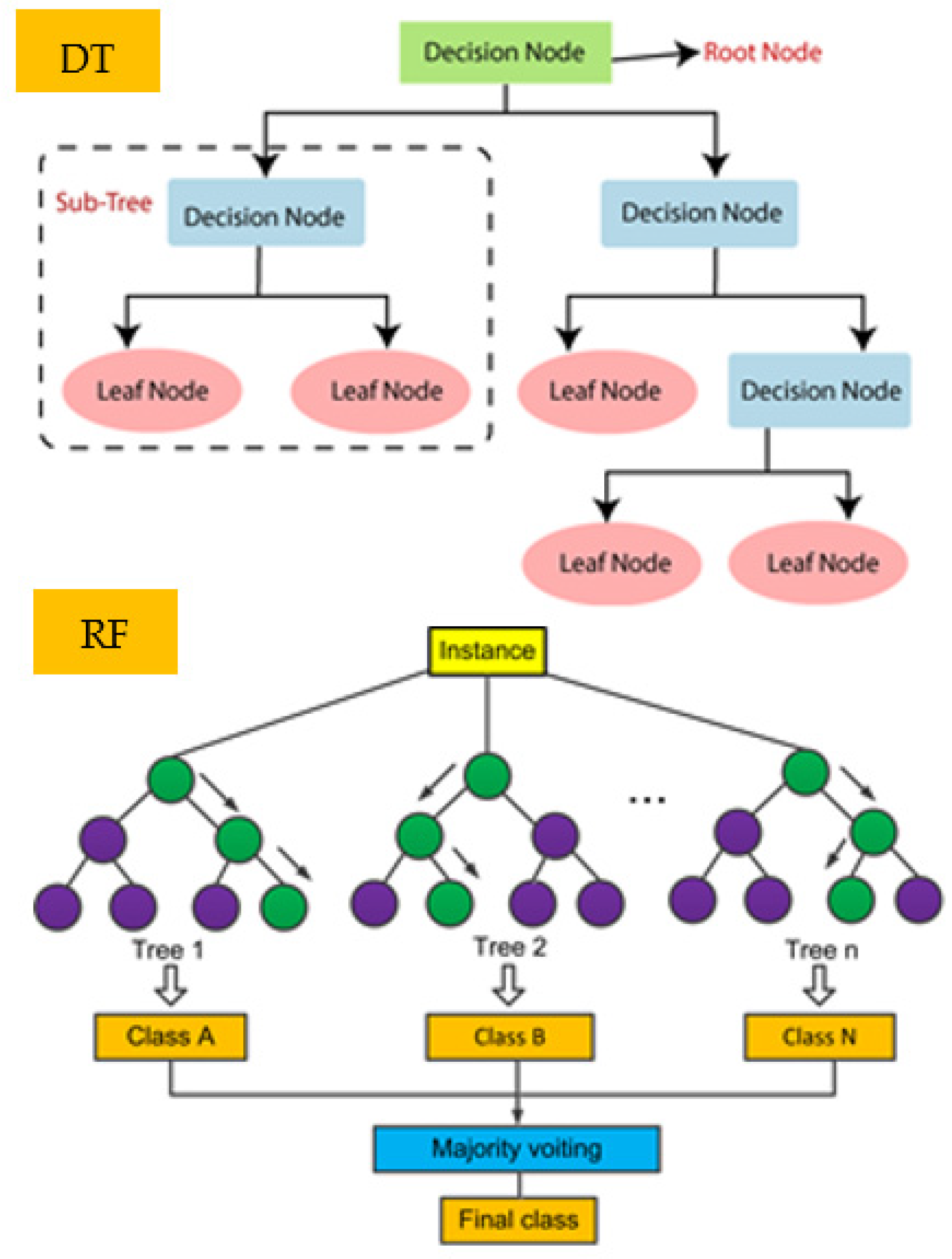
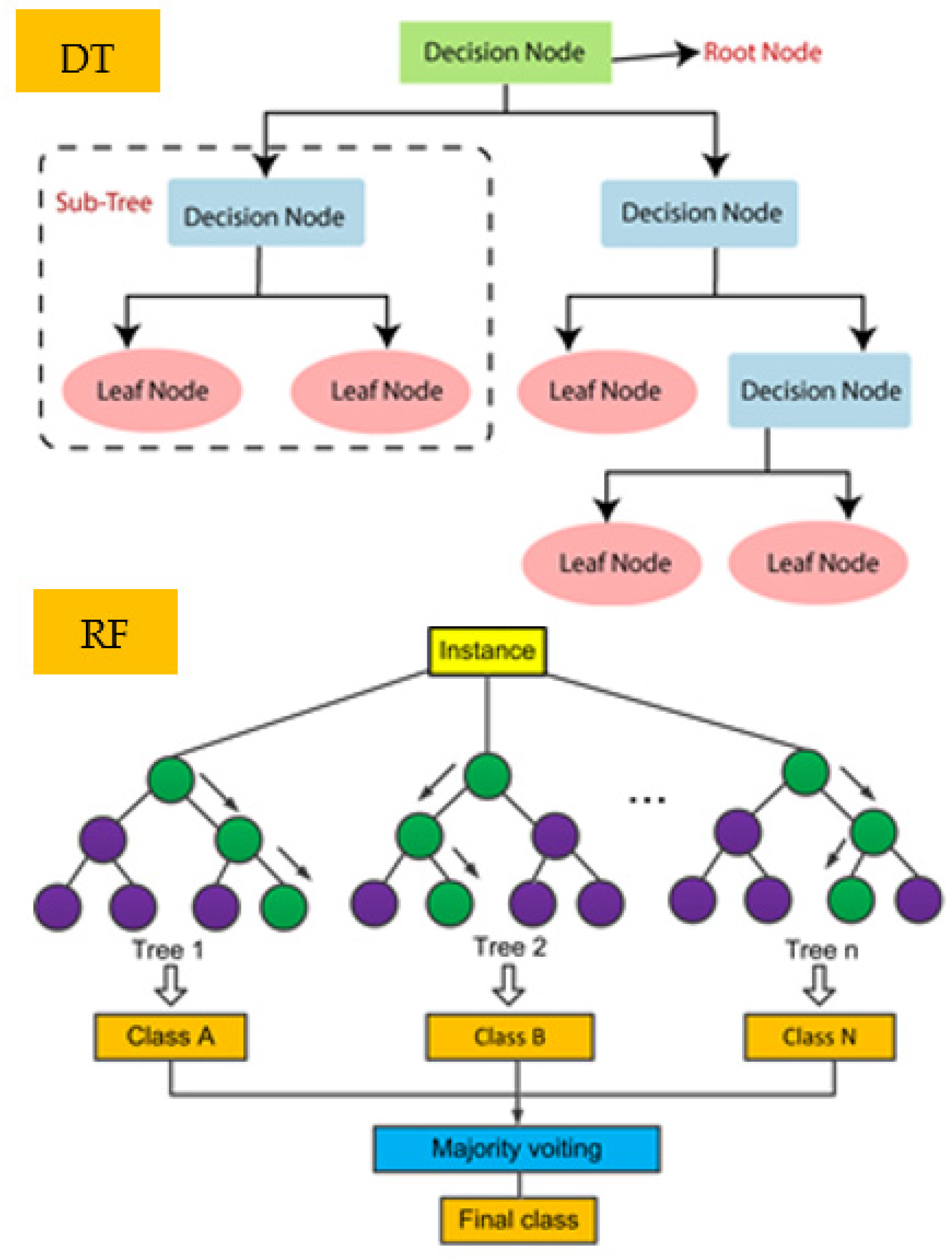
3.1.1. Decision Tree and Random Forest
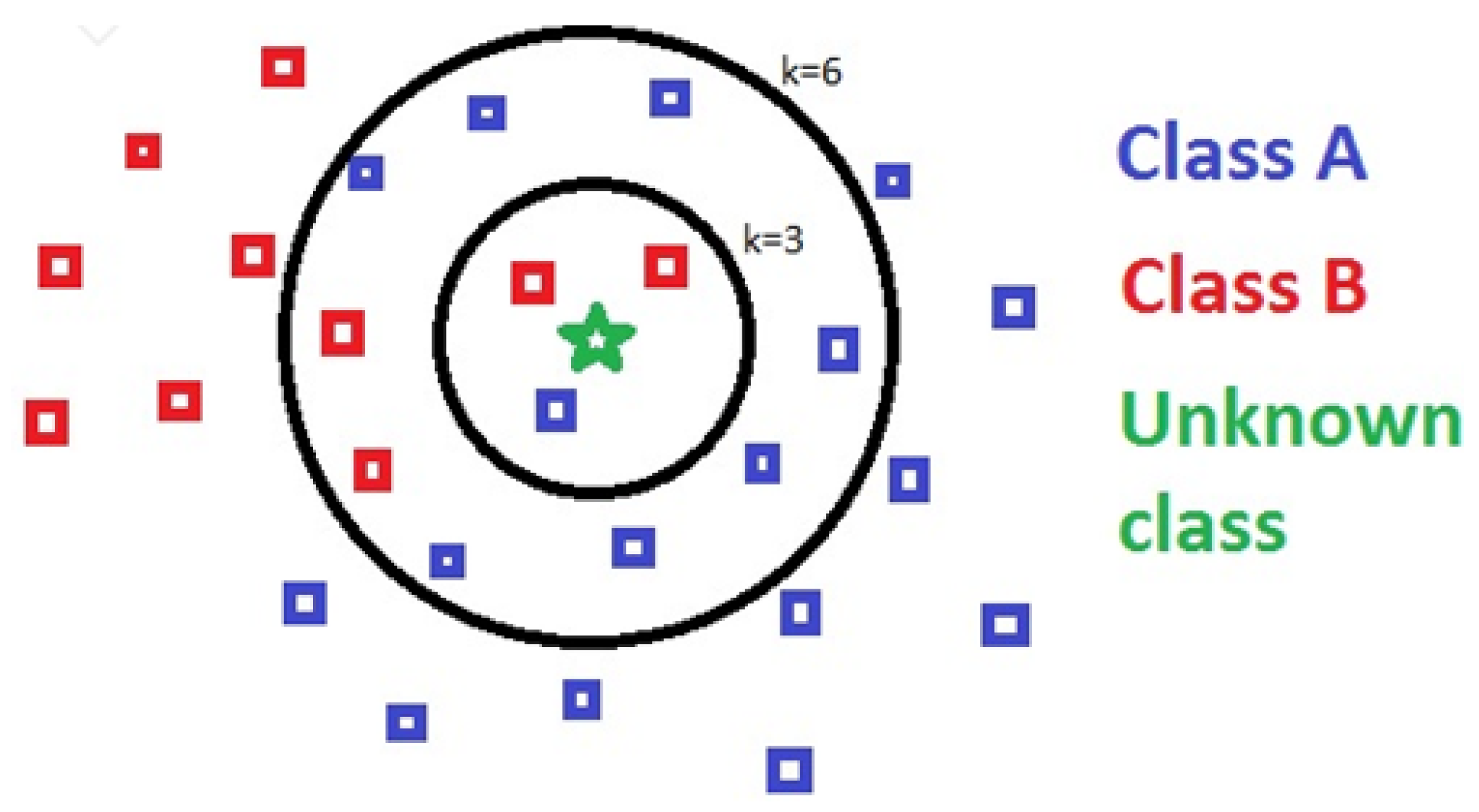
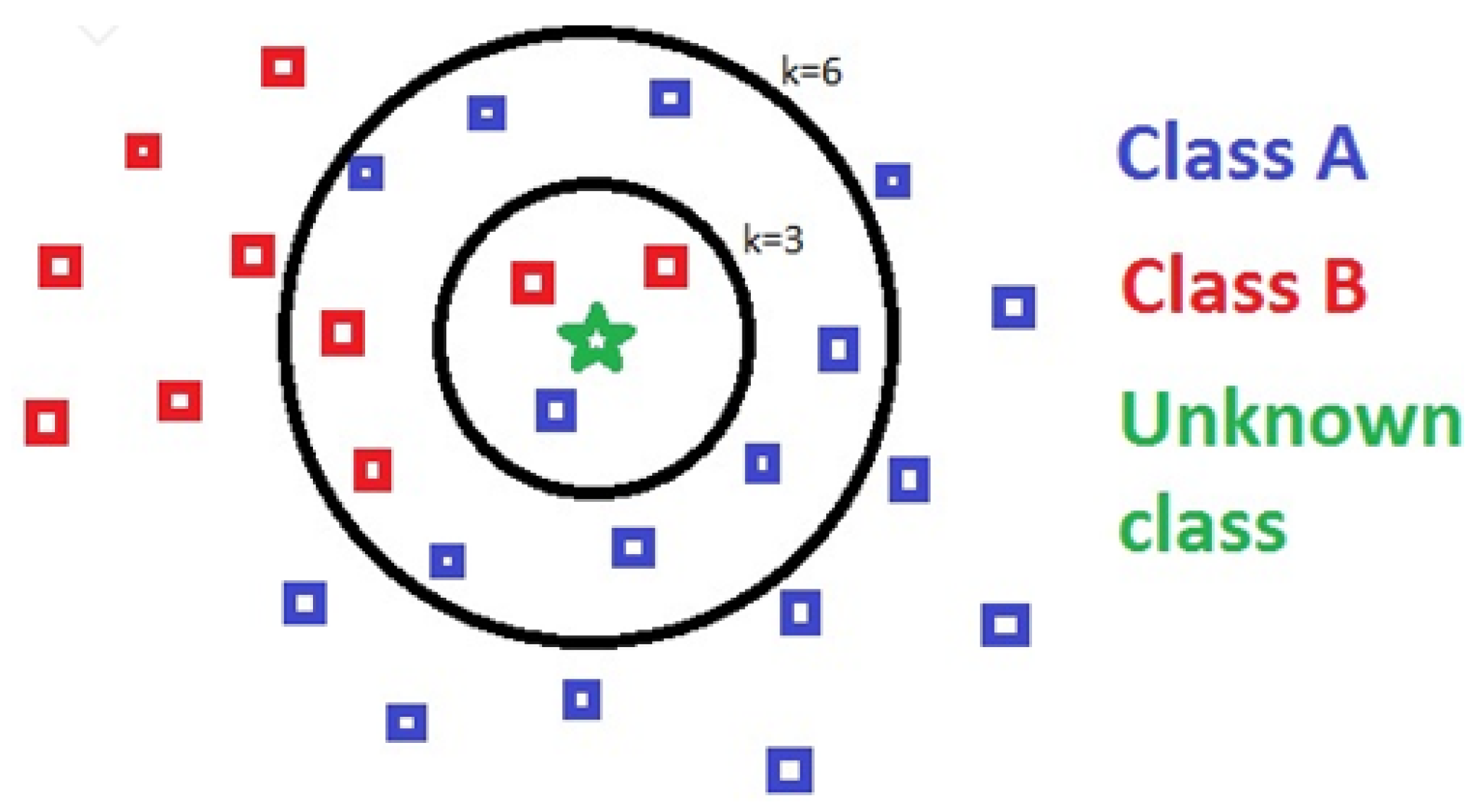
3.1.2. K-Nearest Neighbor
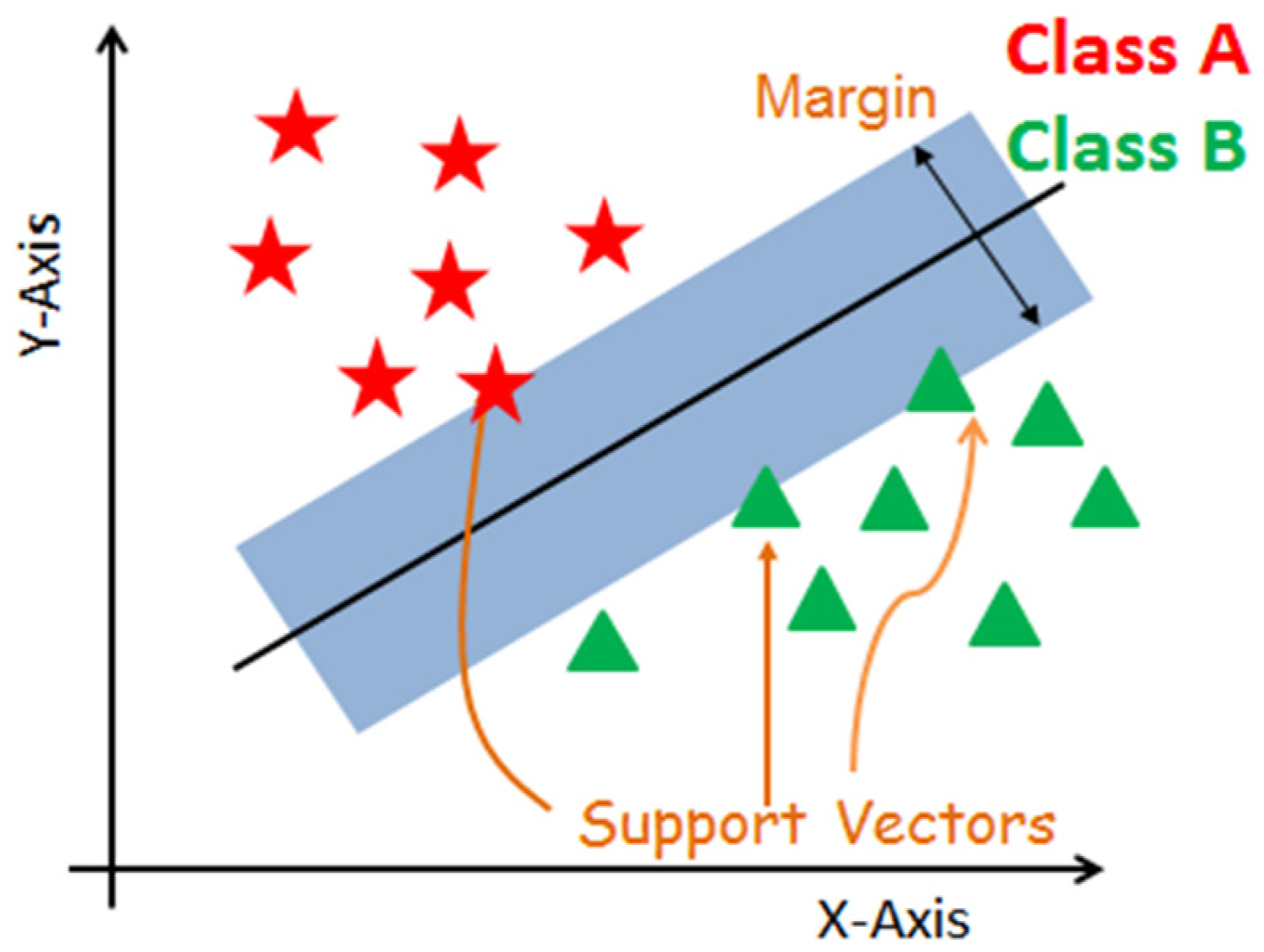
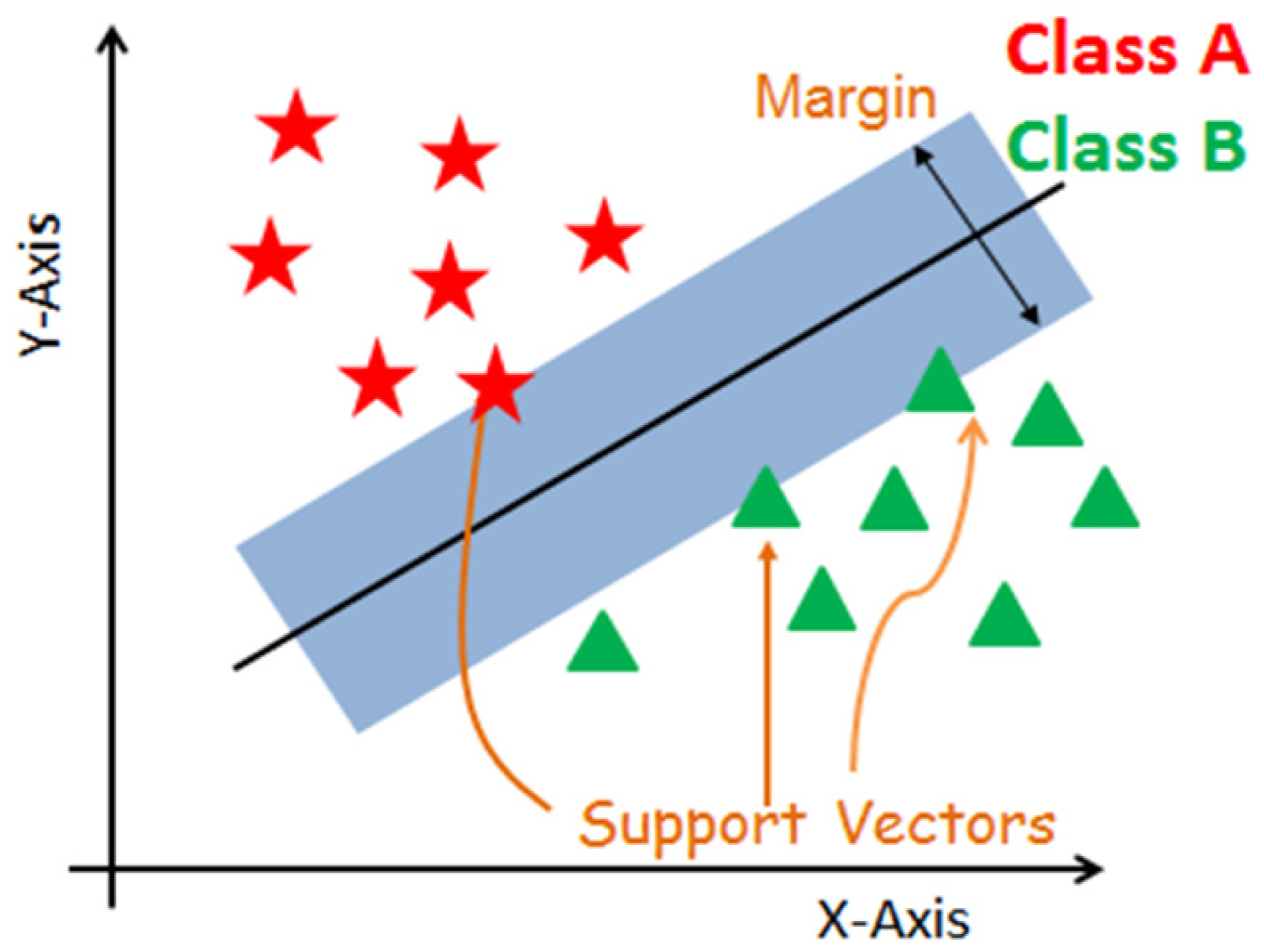
3.1.3. Support Vector Machines
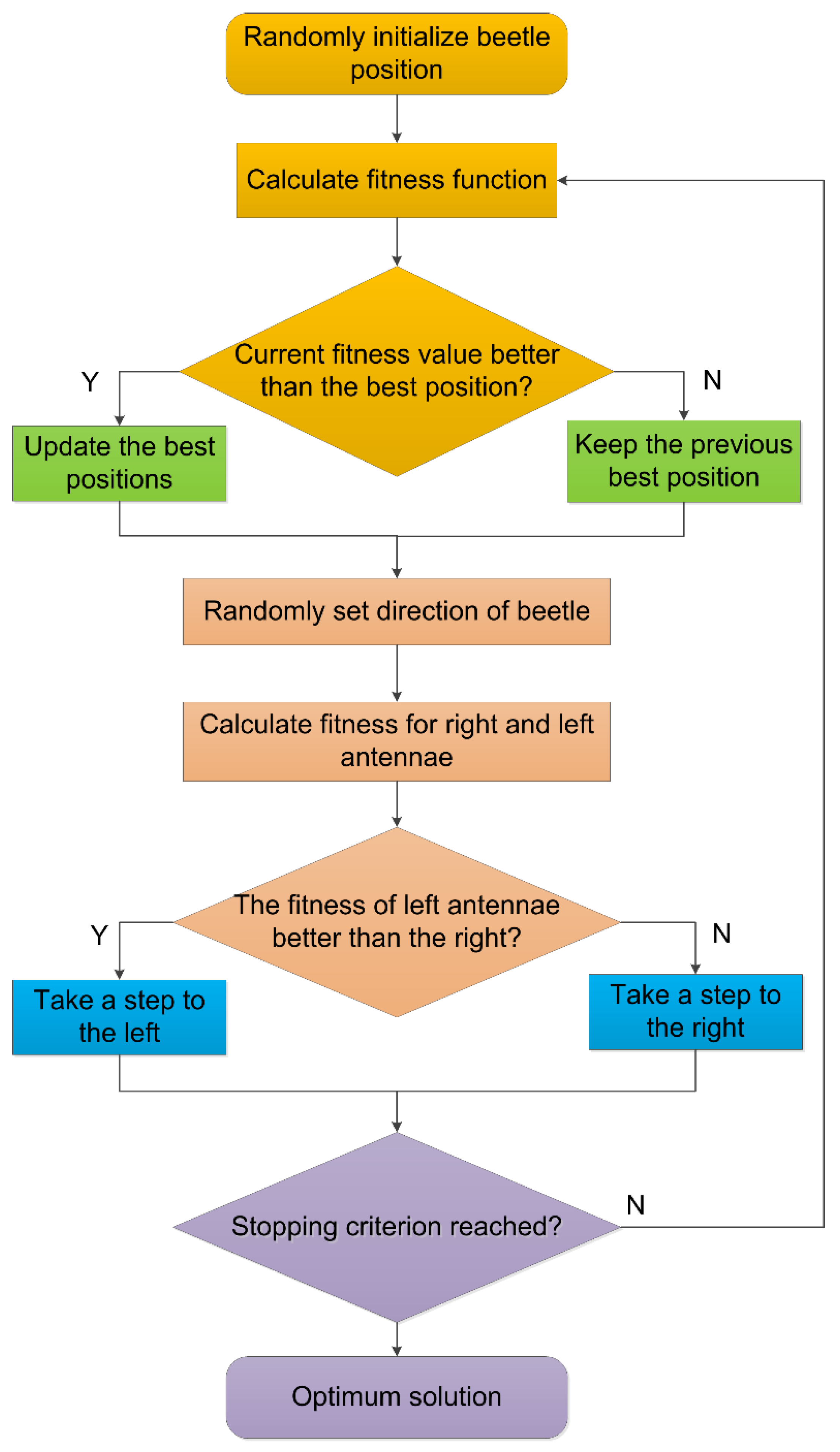
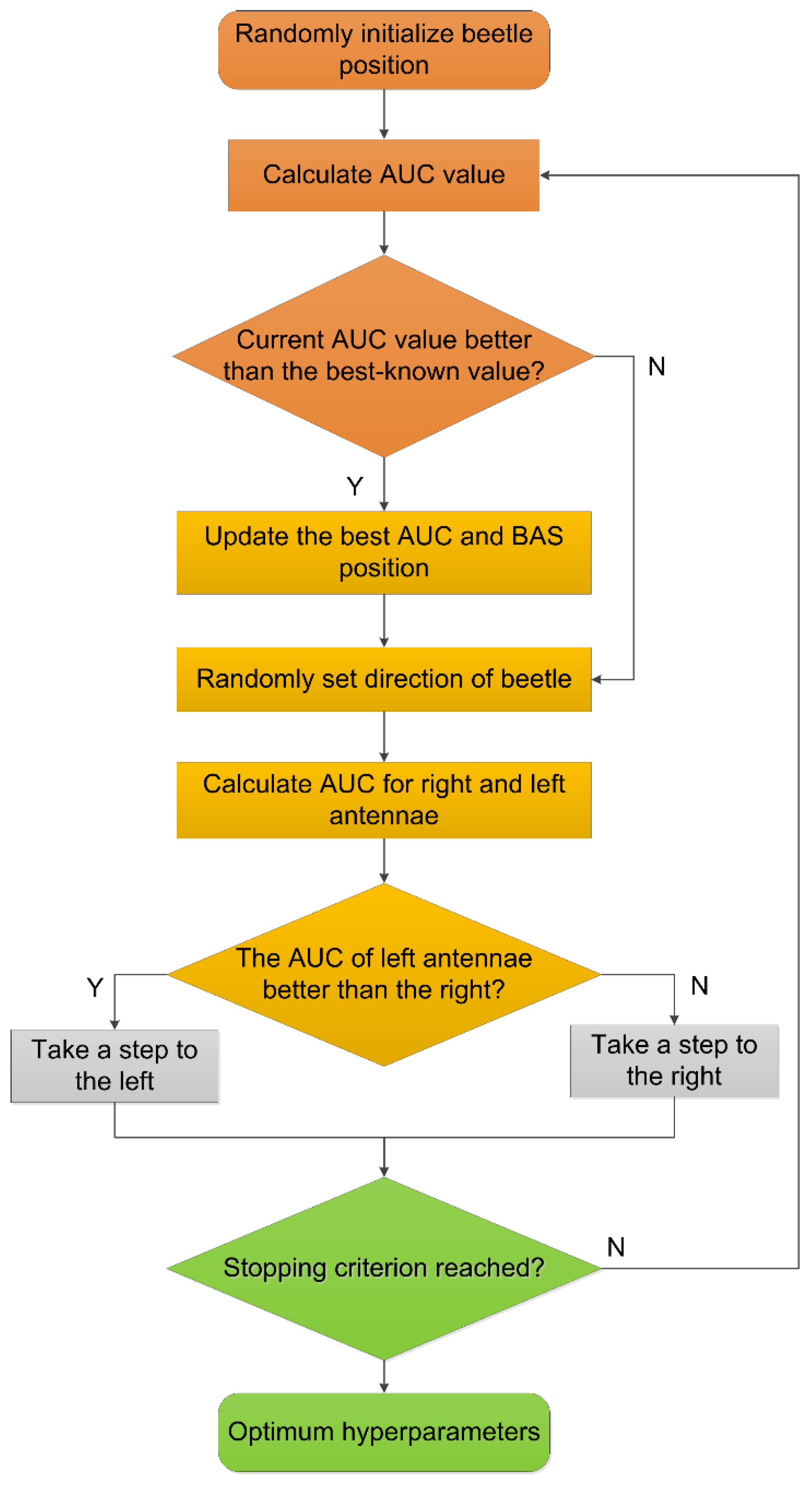
3.1.4. Beetle Antennae Search Algorithm
3.2. The Methodology of Ensemble RF-BAS Model
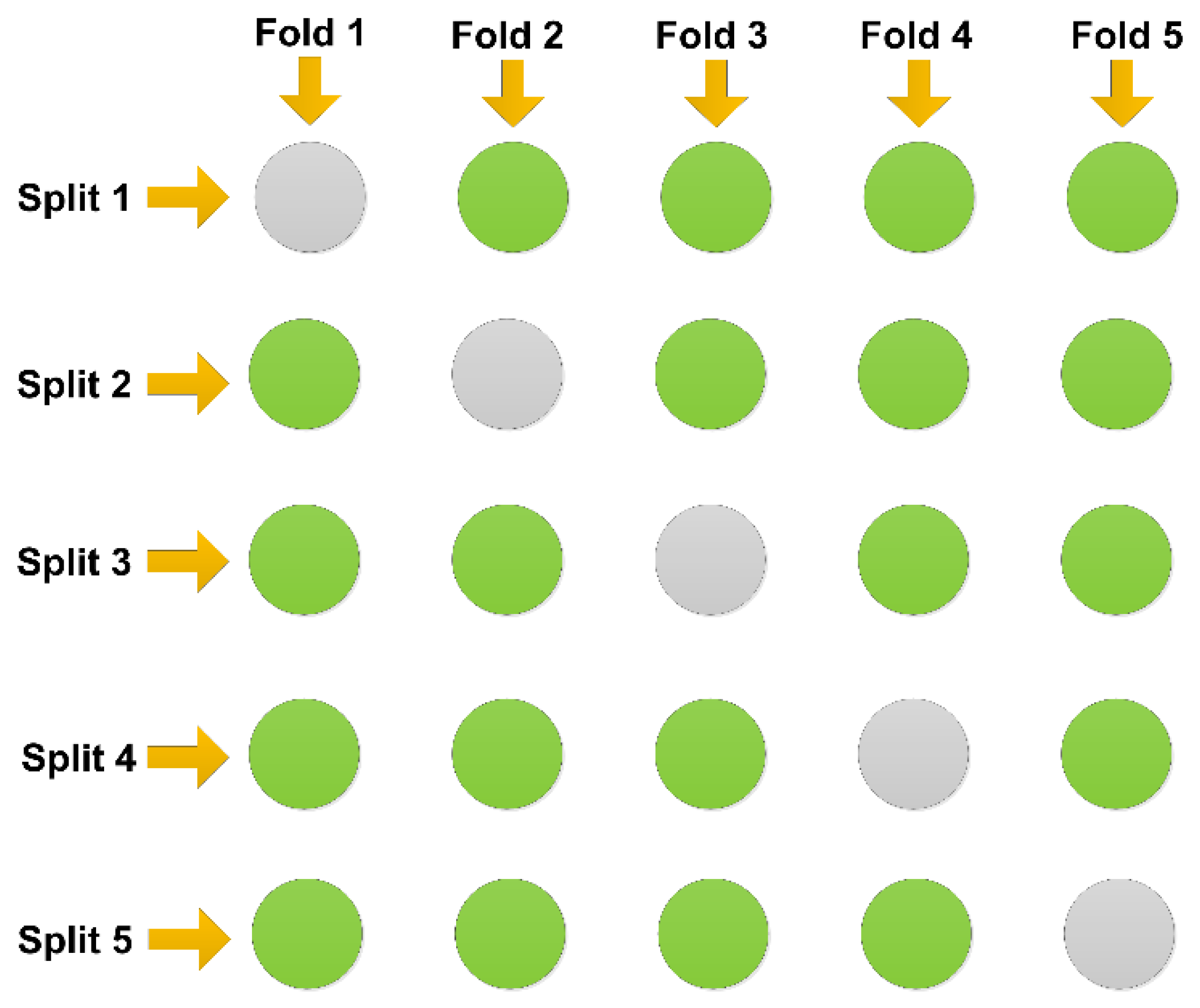
3.3. Performance Evaluation Methods
4. Results
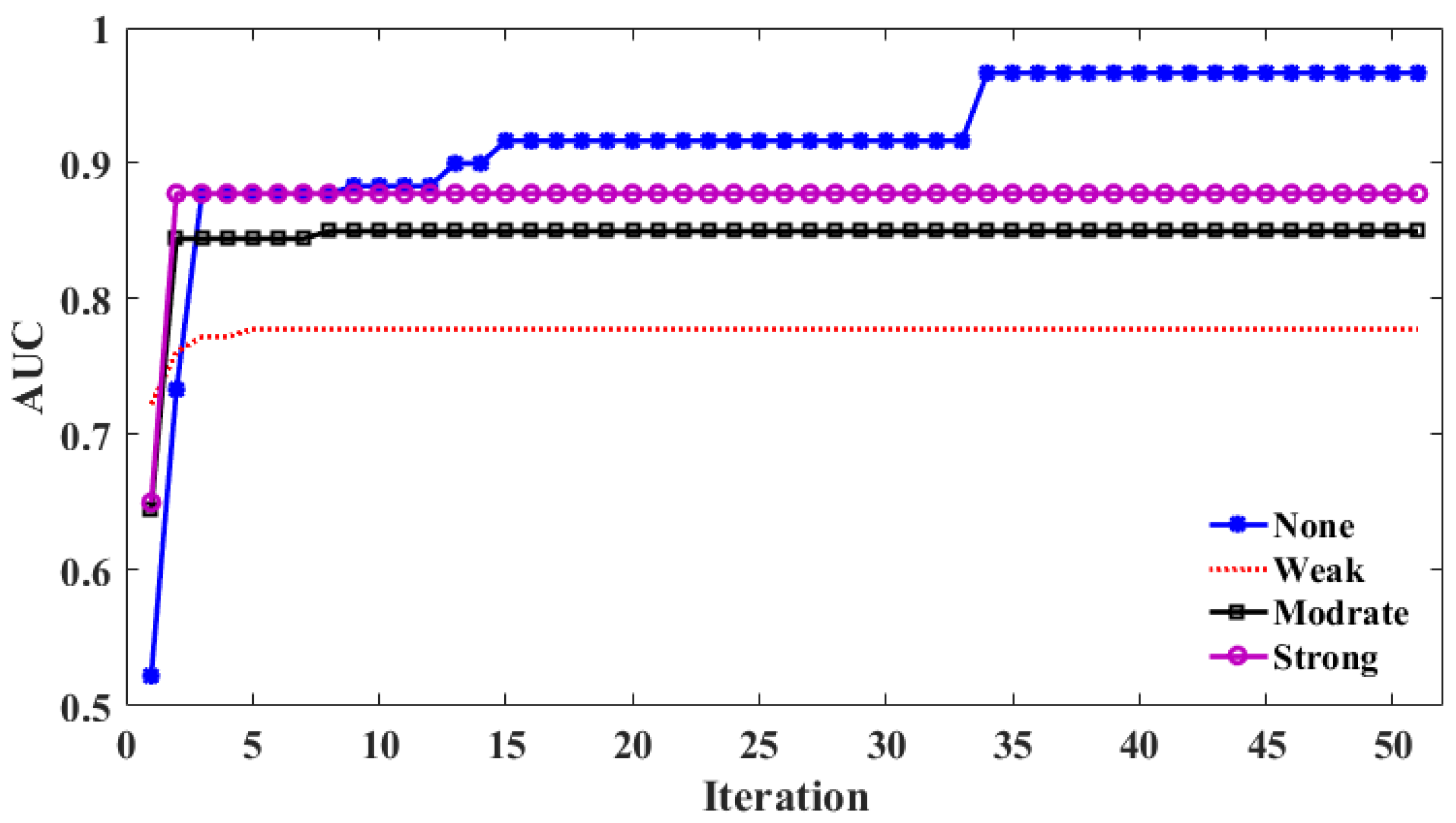
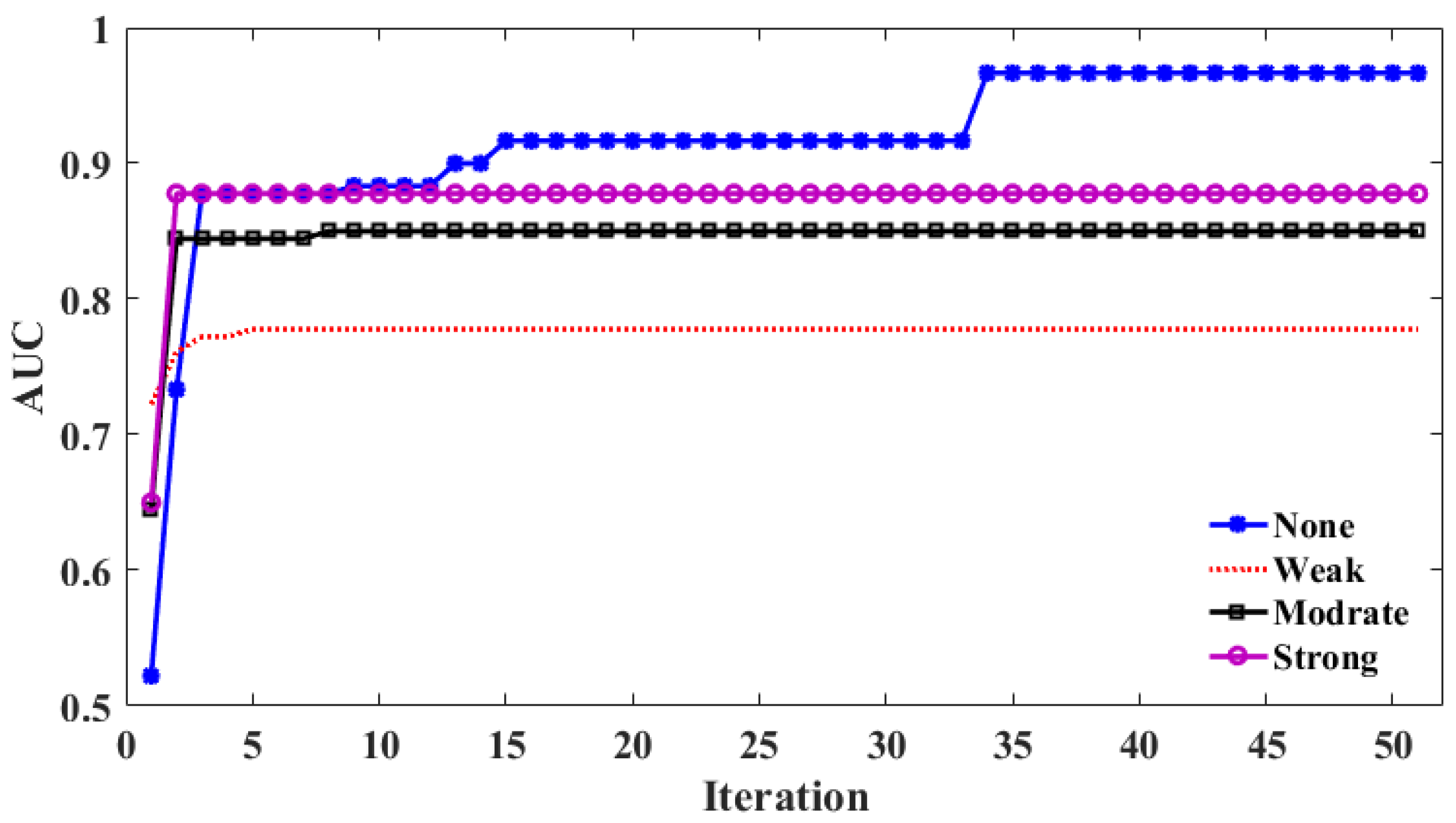
4.1. Hyper-Parameter Tuning
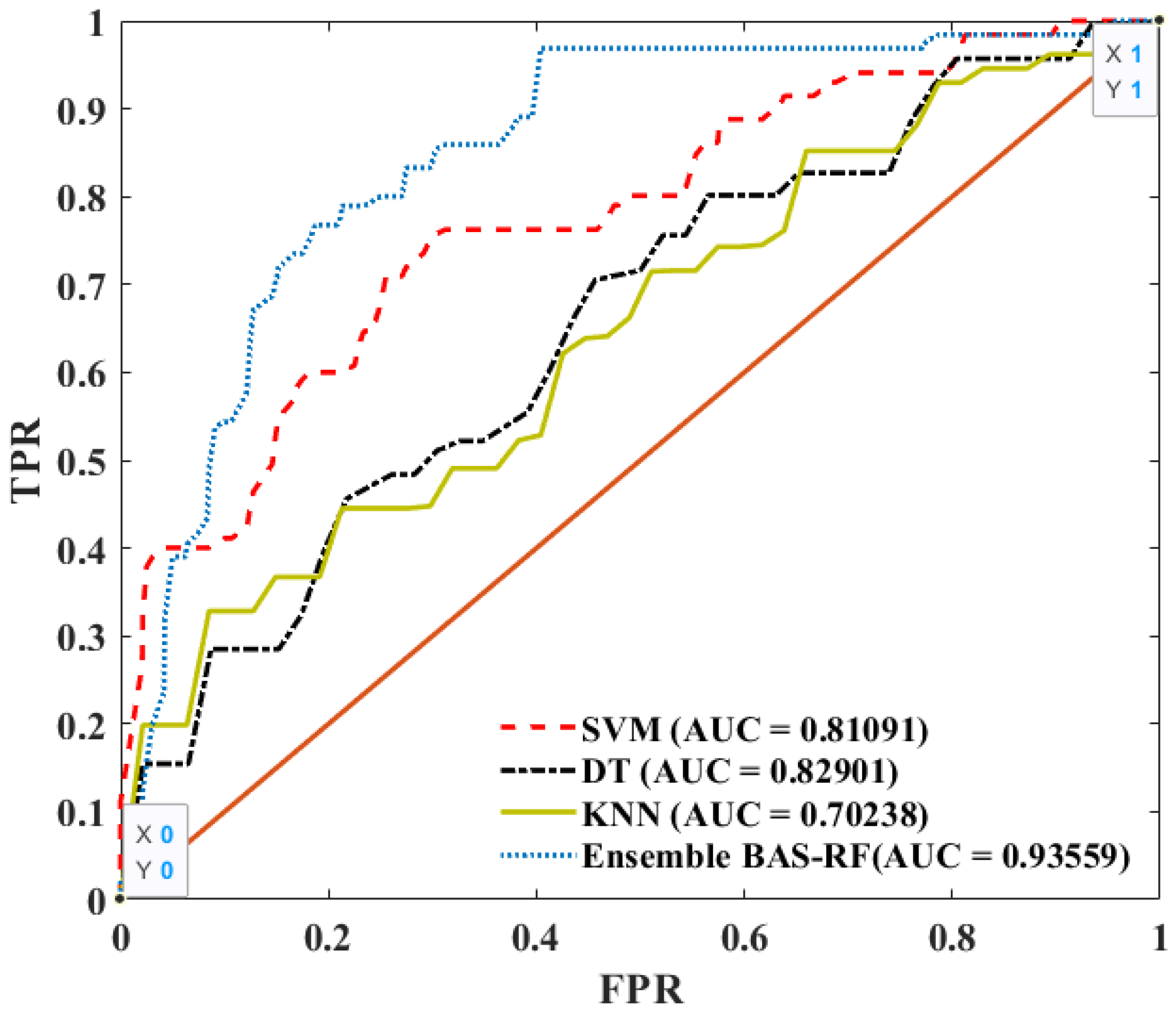
4.2. Validation of BAS-RF
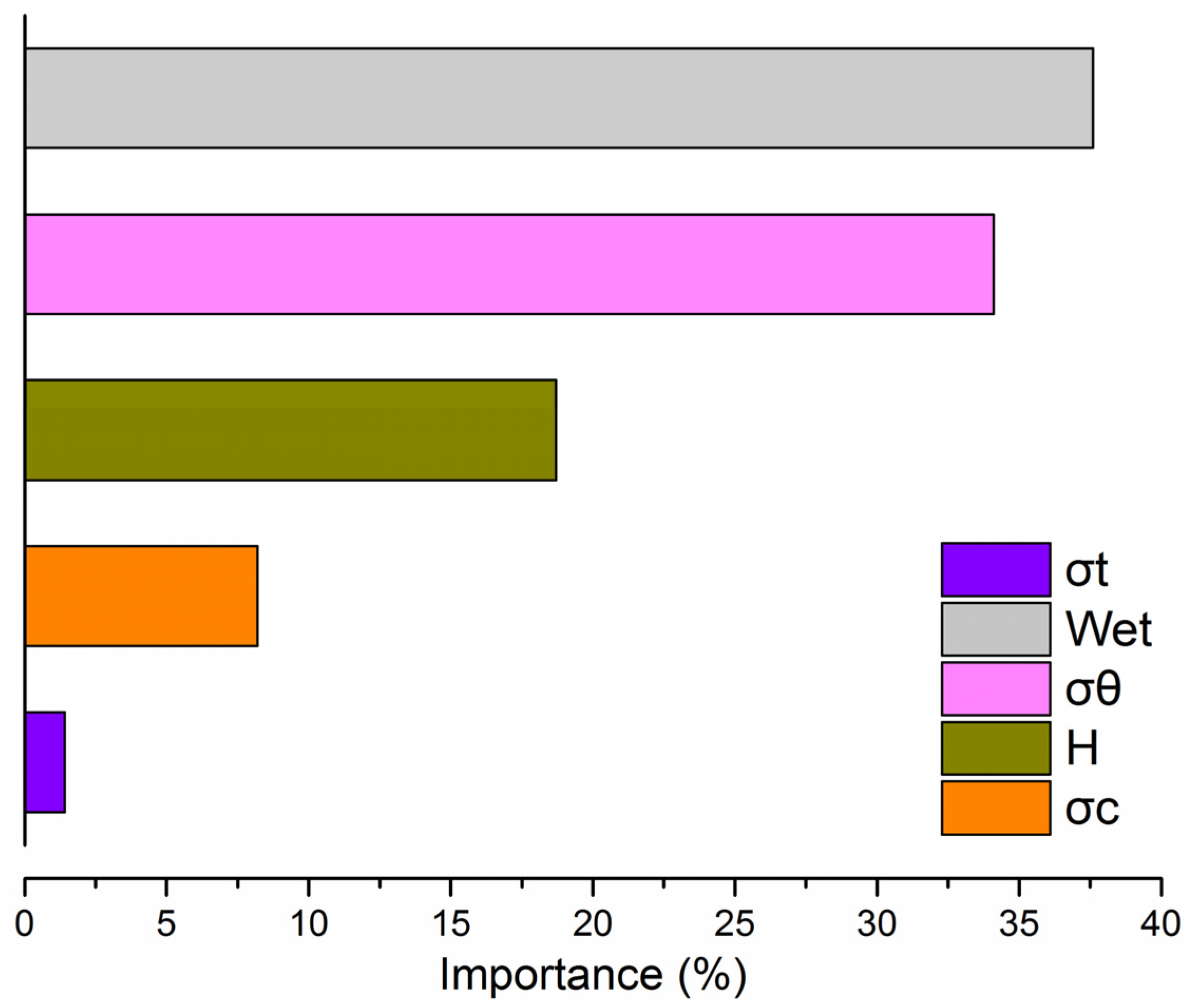
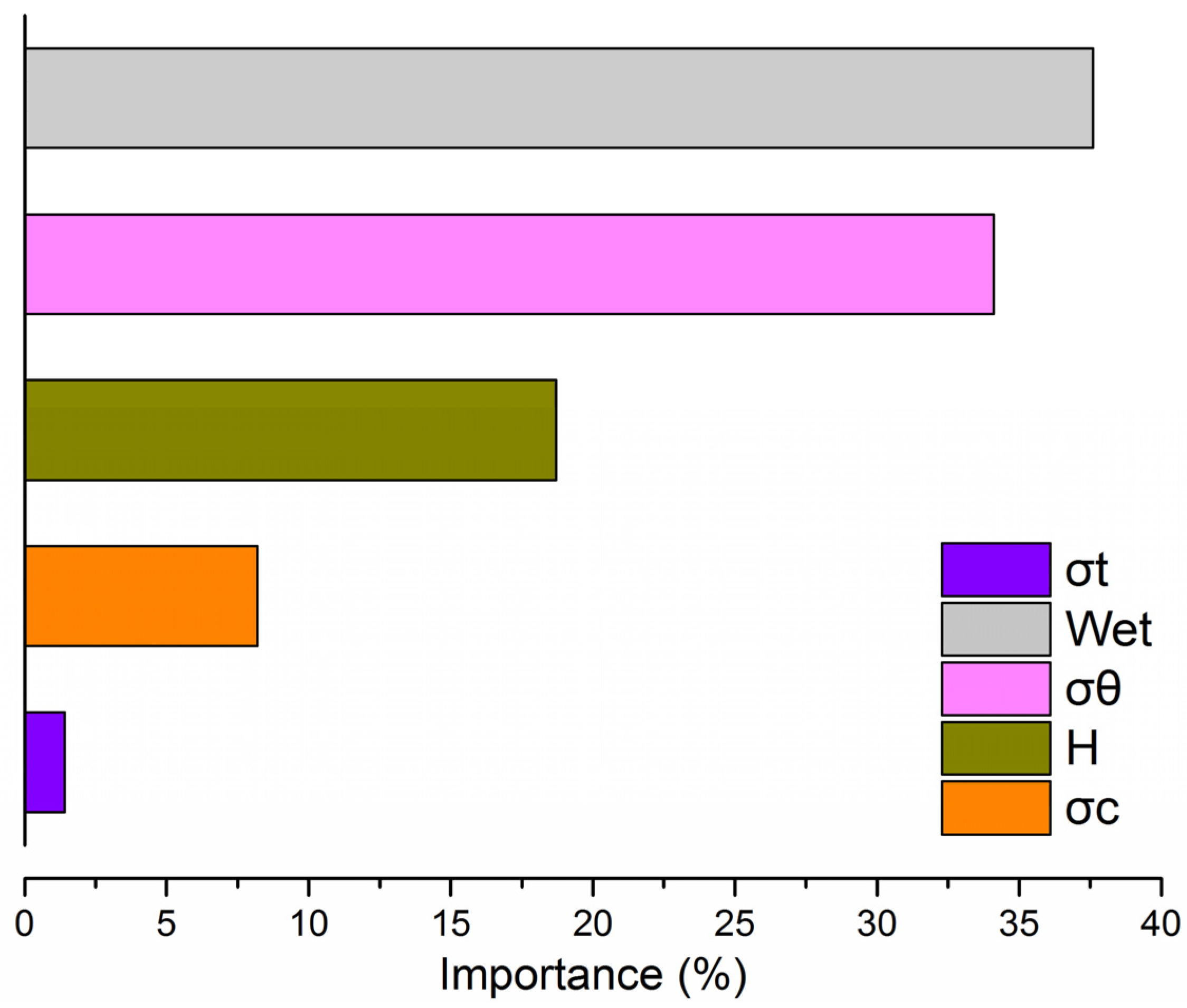
4.3. The Rank of Influencing Variables
5. Discussion
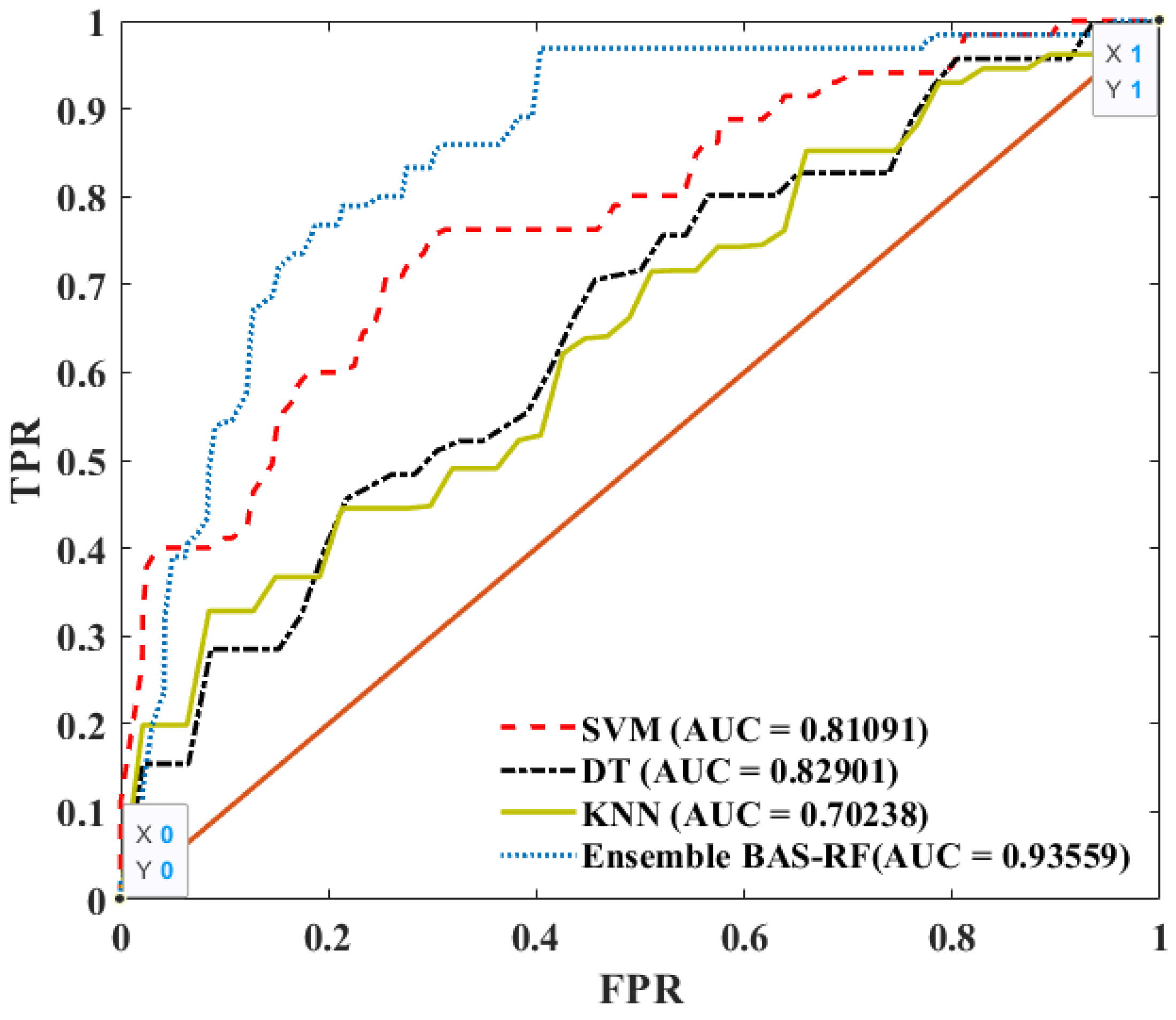
5.1. Comparison of the BAS-RF with Baseline Models
5.2. Cases Application
6. Summary and Conclusions
- The BAS algorithm could tune hyperparameters of the RF model effectively, leading to a satisfactory performance of the BAS-RF model in rockburst classifications.
- The BAS-RF model performed much better compared to the other classifier. The BAS-RF was the most accurate model, followed by DT, SVM, and KNN models.
- Analyzing the relative importance of input variables based on the BAS-RF model demonstrated that Wet has a substantial influence on rockburst.
- The BAS-RF model provided the most accurate classification as compared to the existing RF model as well as the empirical criteria.
- We successfully applied the BAS-RF model for predicting rockburst events in new projects. The proposed model had a high generalization ability, which facilitates its future application in rockburst intensity assessments.
- It should be pointed out that the generalization could have been improved if we had used a large dataset to train the model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaiser, P.K.; McCreath, D.R.; Tannant, D.D. Rockburst Support Handbook; Geomechanics Research Centre, Laurentian University of Canada: Sudbury, ON, USA, 1996. [Google Scholar]
- Ortlepp, W. RaSiM Comes of Age—A Review of the contribution to the understanding and control of mine rockbursts. In Proceedings of the Sixth International Symposium on Rockburst and Seismicity in Mines, Perth, Australia, 9–11 March 2005; pp. 3–20. [Google Scholar]
- Cai, M. Principles of rock support in burst-prone ground. Tunn. Undergr. Space Technol. 2013, 36, 46–56. [Google Scholar] [CrossRef]
- Kie, T.T. Rockbursts, case records, theory and control. In Proceedings of the International Symposium on Engineering in Complex Rock Formations, Beijing, China, 3–7 November 1988; Elsevier BV: Cham, Switzerland, 1988; pp. 32–47. [Google Scholar]
- Zhou, J.; Li, X.; Mitri, H.S. Evaluation method of rockburst: State-of-the-art literature review. Tunn. Undergr. Space Technol. 2018, 81, 632–659. [Google Scholar] [CrossRef]
- He, M.; Ren, F.; Liu, D. Rockburst mechanism research and its control. Int. J. Min. Sci. Technol. 2018, 28, 829–837. [Google Scholar] [CrossRef]
- Dehghan, S.; Shahriar, K.; Maarefvand, P.; Goshtasbi, K. 3-D modeling of rock burst in pillar No. 19 of Fetr6 chromite mine. Int. J. Min. Sci. Technol. 2013, 23, 231–236. [Google Scholar] [CrossRef]
- Lu, C.-P.; Dou, L.-M.; Liu, B.; Xie, Y.-S.; Liu, H.-S. Microseismic low-frequency precursor effect of bursting failure of coal and rock. J. Appl. Geophys. 2012, 79, 55–63. [Google Scholar] [CrossRef]
- Wang, S.; Li, X.; Yao, J.; Gong, F.; Li, X.; Du, K.; Tao, M.; Huang, L.; Du, S. Experimental investigation of rock breakage by a conical pick and its application to non-explosive mechanized mining in deep hard rock. Int. J. Rock Mech. Min. Sci. 2019, 122, 104063. [Google Scholar] [CrossRef]
- Wang, S.; Sun, L.; Li, X.; Wang, S.; Du, K.; Li, X.; Feng, F. Experimental investigation of cuttability improvement for hard rock fragmentation using conical cutter. Int. J. Geomech. 2021, 21, 6020039. [Google Scholar] [CrossRef]
- Sun, Y.; Li, G.; Zhang, N.; Chang, Q.; Xu, J.; Zhang, J. Development of ensemble learning models to evaluate the strength of coal-grout materials. Int. J. Min. Sci. Technol. 2021, 31, 153–162. [Google Scholar] [CrossRef]
- Zhao, H.-B. Classification of rockburst using support vector machine. Rock Soil Mech. 2005, 26, 642–644. [Google Scholar]
- Zhu, Y.H.; Liu, X.R.; Zhou, J.P. Rockburst prediction analysis based on v-SVR algorithm. J. China Coal Soc. 2008, 33, 277–281. [Google Scholar]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of Rockburst in Underground Projects: Comparison of Ten Supervised Learning Methods. J. Comput. Civ. Eng. 2016, 30, 04016003. [Google Scholar] [CrossRef]
- Adoko, A.C.; Gokceoglu, C.; Wu, L.; Zuo, Q.J. Knowledge-based and data-driven fuzzy modeling for rockburst prediction. Int. J. Rock Mech. Min. Sci. 2013, 61, 86–95. [Google Scholar] [CrossRef]
- Haijun, L.C.; Dexin, S.N. Prediction of rockburst by artificial neural network. Chin. J. Rock Mech. Eng. 2003, 22, 762. [Google Scholar]
- Guo, L.; Li, X.; Yan, X.; Xiong, L. Rock Burst Prediction Methods Based on BP Network Theory. Ind. Saf. Dust Control 2005, 10. [Google Scholar]
- Faradonbeh, R.S.; Taheri, A. Long-term prediction of rockburst hazard in deep underground openings using three robust data mining techniques. Eng. Comput. 2019, 35, 659–675. [Google Scholar] [CrossRef]
- Liu, Z.; Shao, J.; Xu, W.; Meng, Y. Prediction of rock burst classification using the technique of cloud models with attribution weight. Nat. Hazards 2013, 68, 549–568. [Google Scholar] [CrossRef]
- Zhou, K.-P.; Lin, Y.; Deng, H.-W.; Li, J.; Liu, C.-J. Prediction of rock burst classification using cloud model with entropy weight. Trans. Nonferrous Met. Soc. China 2016, 26, 1995–2002. [Google Scholar] [CrossRef]
- Li, N.; Jimenez, R. A logistic regression classifier for long-term probabilistic prediction of rock burst hazard. Nat. Hazards 2017, 90, 197–215. [Google Scholar] [CrossRef]
- Afraei, S.; Shahriar, K.; Madani, S.H. Statistical assessment of rock burst potential and contributions of considered predictor variables in the task. Tunn. Undergr. Space Technol. 2018, 72, 250–271. [Google Scholar] [CrossRef]
- Li, N.; Feng, X.; Jimenez, R. Predicting rock burst hazard with incomplete data using Bayesian networks. Tunn. Undergr. Space Technol. 2017, 61, 61–70. [Google Scholar] [CrossRef]
- Sun, Y.; Li, G.; Zhang, J. Developing Hybrid Machine Learning Models for Estimating the Unconfined Compressive Strength of Jet Grouting Composite: A Comparative Study. Appl. Sci 2020, 10, 1612. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Lingga, B. Rockburst prediction in kimberlite using decision tree with incomplete data. J. Sustain. Min. 2018, 17, 158–165. [Google Scholar] [CrossRef]
- Sun, Y.; Li, G.; Zhang, J.; Huang, J. Rockburst intensity evaluation by a novel systematic and evolved approach: Machine learning booster and application. Bull. Eng. Geol. Environ. 2021, 80, 8385–8395. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Dong, L.-J.; Li, X.-B.; Peng, K. Prediction of rockburst classification using Random Forest. Trans. Nonferrous Met. Soc. China 2013, 23, 472–477. [Google Scholar] [CrossRef]
- Afraei, S.; Shahriar, K.; Madani, S.H. Developing intelligent classification models for rock burst prediction after recognizing significant predictor variables, Section 2: Designing classifiers. Tunn. Undergr. Space Technol. 2018, 84, 522–537. [Google Scholar] [CrossRef]
- Long, L.; Chen, J. Fuzzy Comprehensive Assessment Method Adopted to Predict Rock Burst in Daxiangling Tunne. Xiandai Suidao Jishu 2010, 47, 23–27. [Google Scholar]
- Li, N.; Jimenez, R.; Feng, X. The Influence of Bayesian Networks Structure on Rock Burst Hazard Prediction with Incomplete Data. Procedia Eng. 2017, 191, 206–214. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Shi, X. Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf. Sci. 2012, 50, 629–644. [Google Scholar] [CrossRef]
- Lee, P.; Tsui, Y.; Tham, L.; Wang, Y.; Li, W. Method of fuzzy comprehensive evaluations for rockburst prediction. Chin. J. Rock Mech. Eng. 1998, 17, 493–501. [Google Scholar]
- Kidybiński, A. Bursting liability indices of coal. Int. J. Rock Mech. Min. Sci. Géoméch. Abstr. 1981, 18, 295–304. [Google Scholar] [CrossRef]
- Russenes, B.F. Analysis of Rock Spalling for Tunnels in Steep Valley Sides; Norwegian Institute of Technology: Trondheim, Norway, 1974; Volume 247. [Google Scholar]
- Singh, S. Classification of mine workings according to their rockburst proneness. Min. Sci. Technol. 1989, 8, 253–262. [Google Scholar] [CrossRef]
- Jia, Y.; Lv, Q.; Shang, Y. Rockburst prediction using particle swarm optimization algorithm and general regression neural network. Chin. J. Rock Mech. Eng. 2013, 32, 343–348. [Google Scholar]
- Tang, Z.; Xu, Q. Rock burst prediction based on nine machine learning algorithms. Chin. J. Rock. Mech Eng. 2020, 161. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Accuracy (%) | Data | References |
|---|---|---|---|
| SVM | 100 | 16 | Zhao et al. [12] |
| 93.8 | 45 | Zhu et al. [13] | |
| 51.7–67.2 | 246 | Zhou et al. [14] | |
| ANFIS | 66.5–95.6 | 174 | Adoko et al. [15] |
| ANN | 72.2 | 18 | Chen et al. [16] |
| 100 | 19 | Xiao et al. [17] | |
| 100 | 10 | Feng et al. [10] | |
| 85.2 | 134 | Faradonbeh et al. [18] | |
| CM | 90–94.1 | 164 | Liu et al. [19] |
| 76.4–82 | 209 | Zhou et al. [20] | |
| 71–76 | 246 | Zhao et al. [14] | |
| LR | 80.2–90.9 | 135 | Li et al. [21] |
| 88.3 | 188 | Afraei et al. [22] | |
| BN | 91.7 | 135 | Li et al. [23] |
| 53.9–65.8 | 246 | Lin et al. [24] | |
| KNN | 53.2–67.2 | 246 | Zhou et al. [14] |
| 50–65.9 | 246 | Lin et al. [24] | |
| DT | 81.5 | 134 | Faradonbeh et al. [18] |
| 73–93 | 132 | Pu et al. [25] | |
| 89.2–90.2 | 174 | Ghasemi al. [26] |
| Parameters | Min | Max | Mean | Standard Deviation |
|---|---|---|---|---|
| H (m) | 80 | 1251 | 682.2 | 291.4 |
| (MPa) | 3.6 | 306.6 | 118.9 | 69.8 |
| (MPa) | 0.2 | 21.2 | 8.6 | 6.1 |
| (MPa) | 2.1 | 171.1 | 63.4 | 42.5 |
| Wet | 0.85 | 10.57 | 5.2 | 3.4 |
| Number of Input Variables | Hyperparameter | Definition | Scope | Class | |||
|---|---|---|---|---|---|---|---|
| None | Light | Moderate | Strong | ||||
| 5 | tree_num | The number of the trees | 2–100 | 42 | 29 | 34 | 17 |
| min_sample_leaf | The minimum required samples at a leaf node | 1–10 | 1 | 1 | 2 | 1 | |
| Rockburst | Actual | Predicted | Percentage Correct | Accuracy | |||
|---|---|---|---|---|---|---|---|
| None | Light | Moderate | Strong | ||||
| None | 35 | 32 | 1 | 1 | 1 | 0.91 | 0.92 |
| Light | 20 | 1 | 19 | 0 | 0 | 0.95 | |
| Moderate | 15 | 0 | 1 | 13 | 1 | 0.86 | |
| Strong | 14 | 0 | 1 | 0 | 13 | 0.92 | |
| ML Models | Empirical Models | |||||||
|---|---|---|---|---|---|---|---|---|
| BAS-RF | SVM | DT | KNN | Conventional RF | Rock Brittleness Coefficient Criterion | Elastic Energy Index | Russenes Criterion | Burst Proneness Index |
| 0.92 | 0.76 | 0.84 | 0.71 | 0.73, Zhou et al. (2016) [14]; 0.61, Lin et al. (2018) [24] | 0.32, Wang et al. (1998) [33] | 0.41, Kidybinski (1981) [34] | 0.36, Russenes (1974) [35] | 0.21, Singh (1989) [36] |
| No. | H (m) | σθ (MPa) | σc (MPa) | σt (MPa) | Wet | Actual | Predicted |
|---|---|---|---|---|---|---|---|
| 1 [37] | 768 | 32.8 | 160 | 6.6 | 4.6 | Light | Light |
| 2 [37] | 768 | 50.9 | 160 | 7.5 | 5.3 | Moderate | Moderate |
| 3 [37] | 730 | 105.5 | 190.3 | 17.1 | 4.0 | Moderate | Moderate |
| 4 [38] | 700 | 87.3 | 137.7 | 9.62 | 7.14 | Strong | Strong |
| 5 [38] | 700 | 87.3 | 94.4 | 9.16 | 3.57 | Light | Light |
| 6 [30] | 808 | 45.6 | 114 | 2.3 | 4.7 | Moderate | Moderate |
| 7 [30] | 362 | 25.6 | 59.7 | 1.3 | 1.7 | None | None |
| 8 [30] | 981 | 57.2 | 80.6 | 2.5 | 5.5 | Strong | Strong |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Li, G.; Yang, S. Rockburst Interpretation by a Data-Driven Approach: A Comparative Study. Mathematics 2021, 9, 2965. https://doi.org/10.3390/math9222965
Sun Y, Li G, Yang S. Rockburst Interpretation by a Data-Driven Approach: A Comparative Study. Mathematics. 2021; 9(22):2965. https://doi.org/10.3390/math9222965
Chicago/Turabian StyleSun, Yuantian, Guichen Li, and Sen Yang. 2021. "Rockburst Interpretation by a Data-Driven Approach: A Comparative Study" Mathematics 9, no. 22: 2965. https://doi.org/10.3390/math9222965
APA StyleSun, Y., Li, G., & Yang, S. (2021). Rockburst Interpretation by a Data-Driven Approach: A Comparative Study. Mathematics, 9(22), 2965. https://doi.org/10.3390/math9222965