
A New Quantile Regression Model and Its Diagnostic Analytics for a Weibull Distributed Response with Applications





Abstract
:1. Introduction, Motivations, and Outline
1.1. Bibliographical Review
1.2. Limitations of the Usual Regression Model
1.3. Objective and Outline
2. A New Weibull Quantile Regression Model
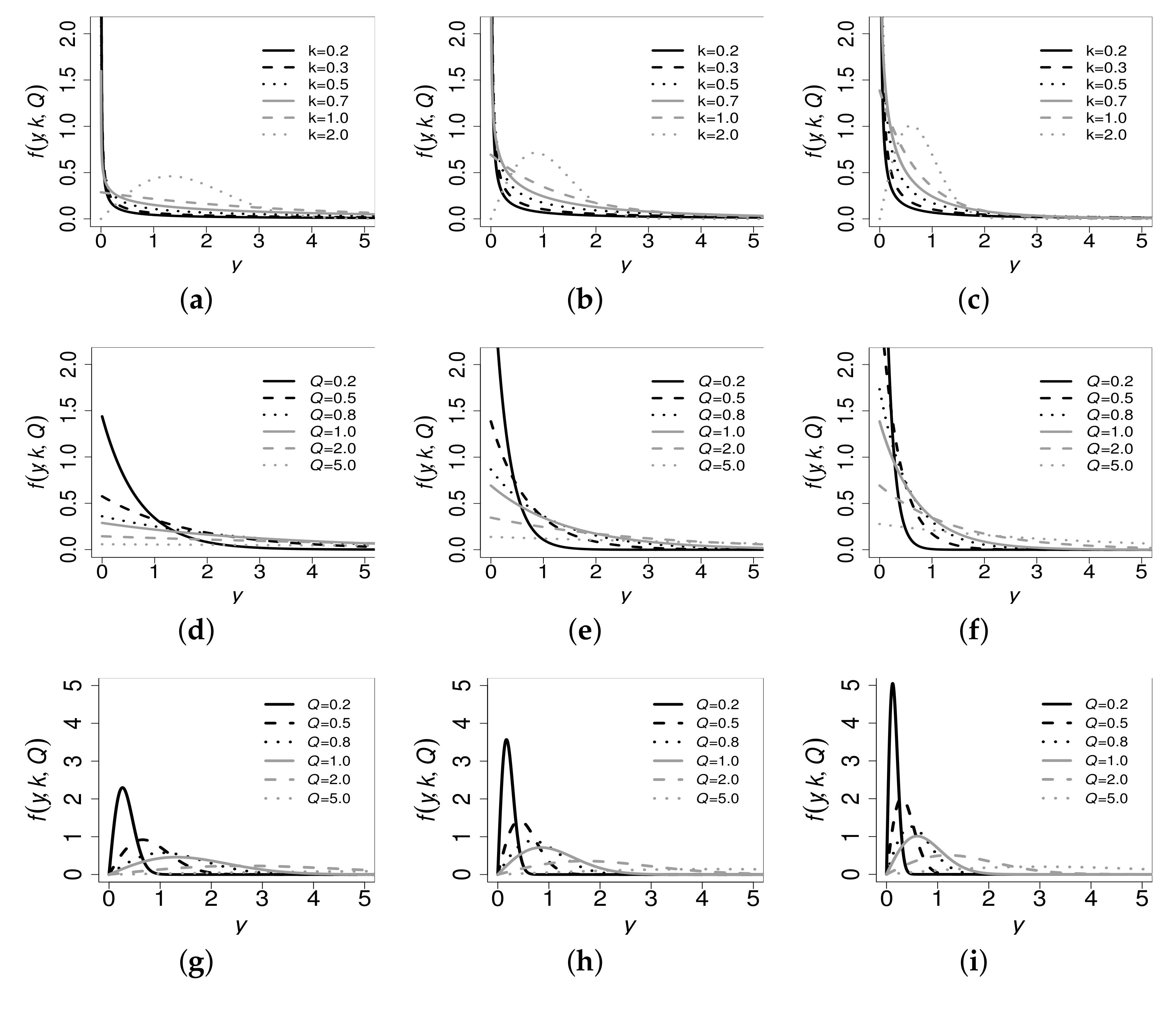
2.1. A Reparameterized Weibull Distribution
2.2. Shape Analysis
2.3. The Weibull Quantile Regression Model
3. Estimation, Inference and Goodness of Fit
3.1. Parameter Estimation
3.2. Inference and Hypothesis Testing
3.3. Residuals
4. Monte Carlo Simulation
4.1. Setting
4.2. Scenario 1: Maximum Likelihood Estimation
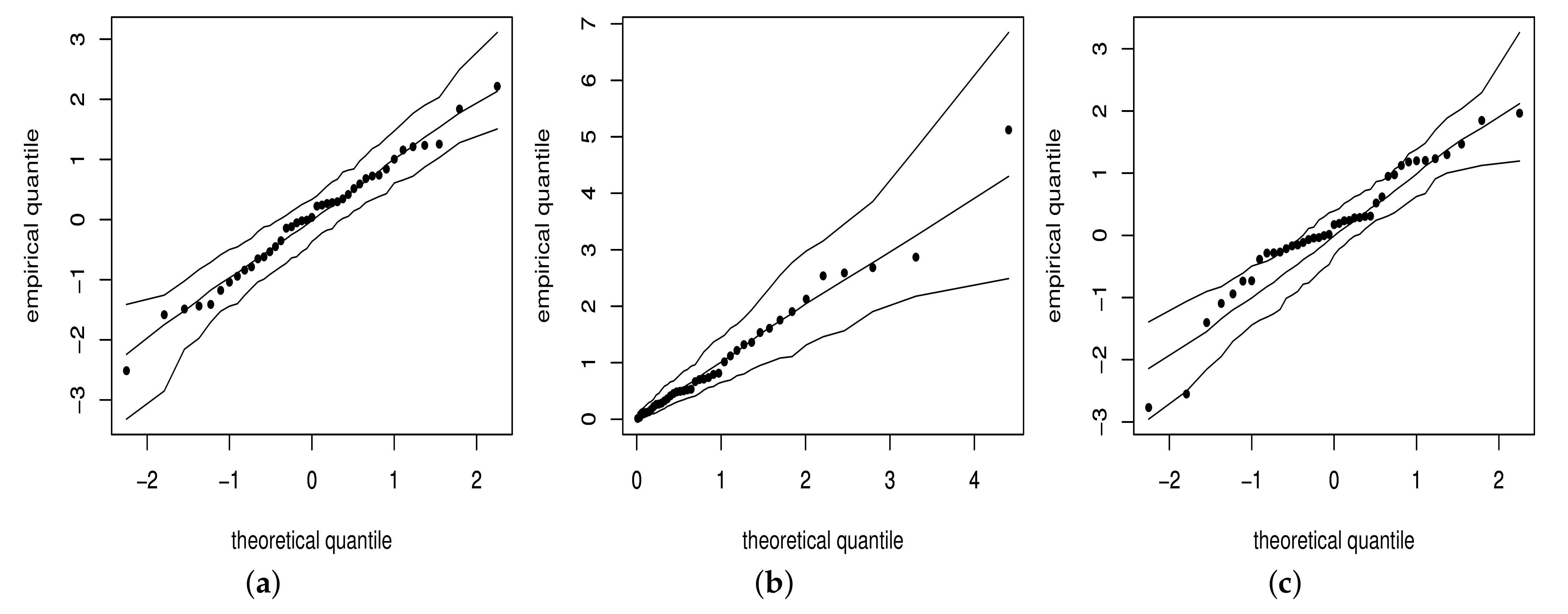
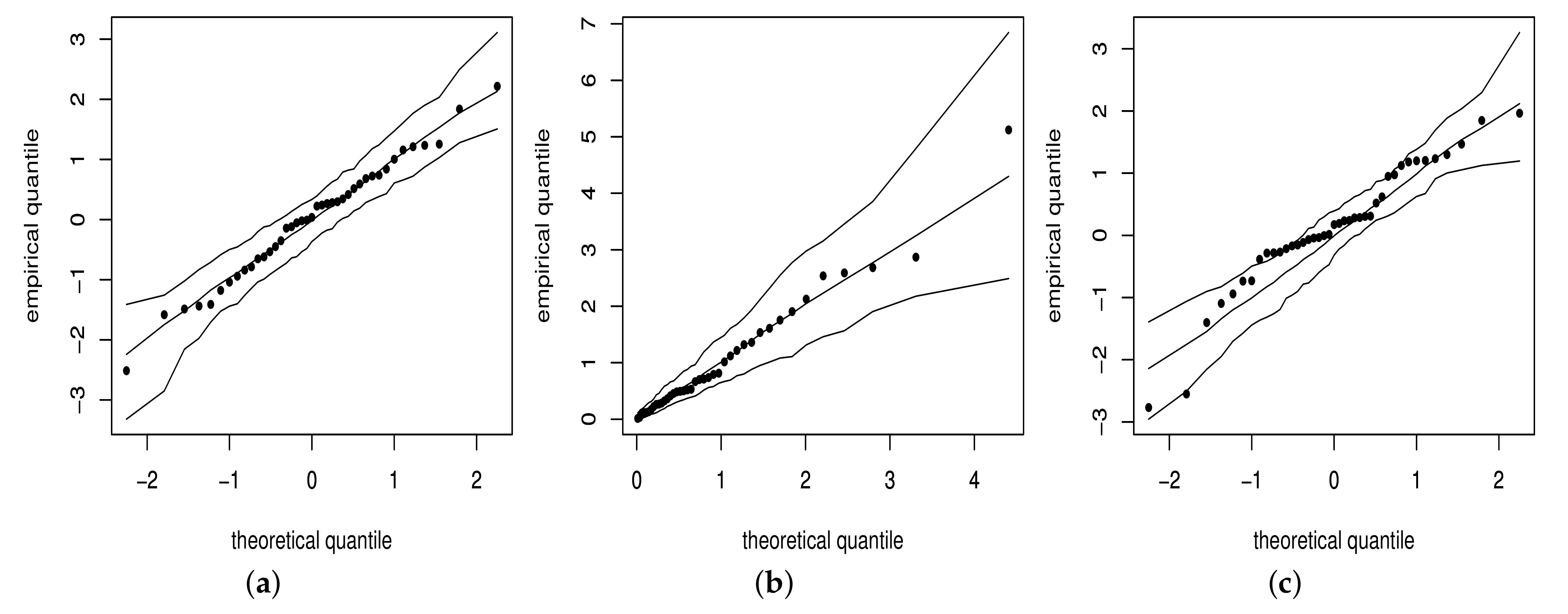
4.3. Scenario 2: Empirical Distribution of the Residuals
5. Local Influence
5.1. Perturbation Matrix and Potentially Influential Cases
5.2. Perturbation Schemes
5.2.1. Case-Weight Perturbation
5.2.2. Perturbation on the Response
5.2.3. Perturbation in the Continuous Covariate
5.2.4. Perturbation of the Parameter
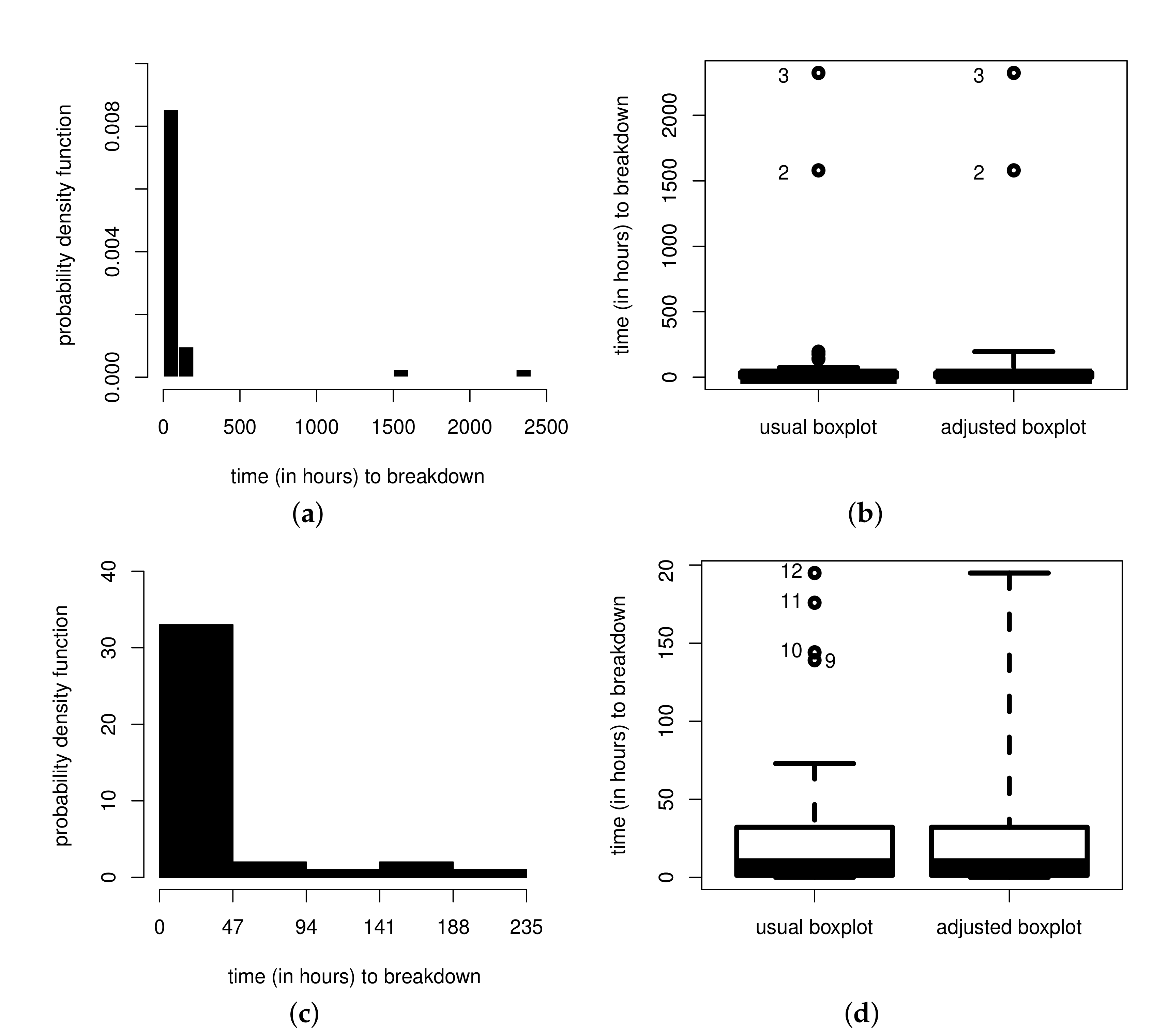
6. Illustrative Example
6.1. The Adjusted Weibull Quantile Regression
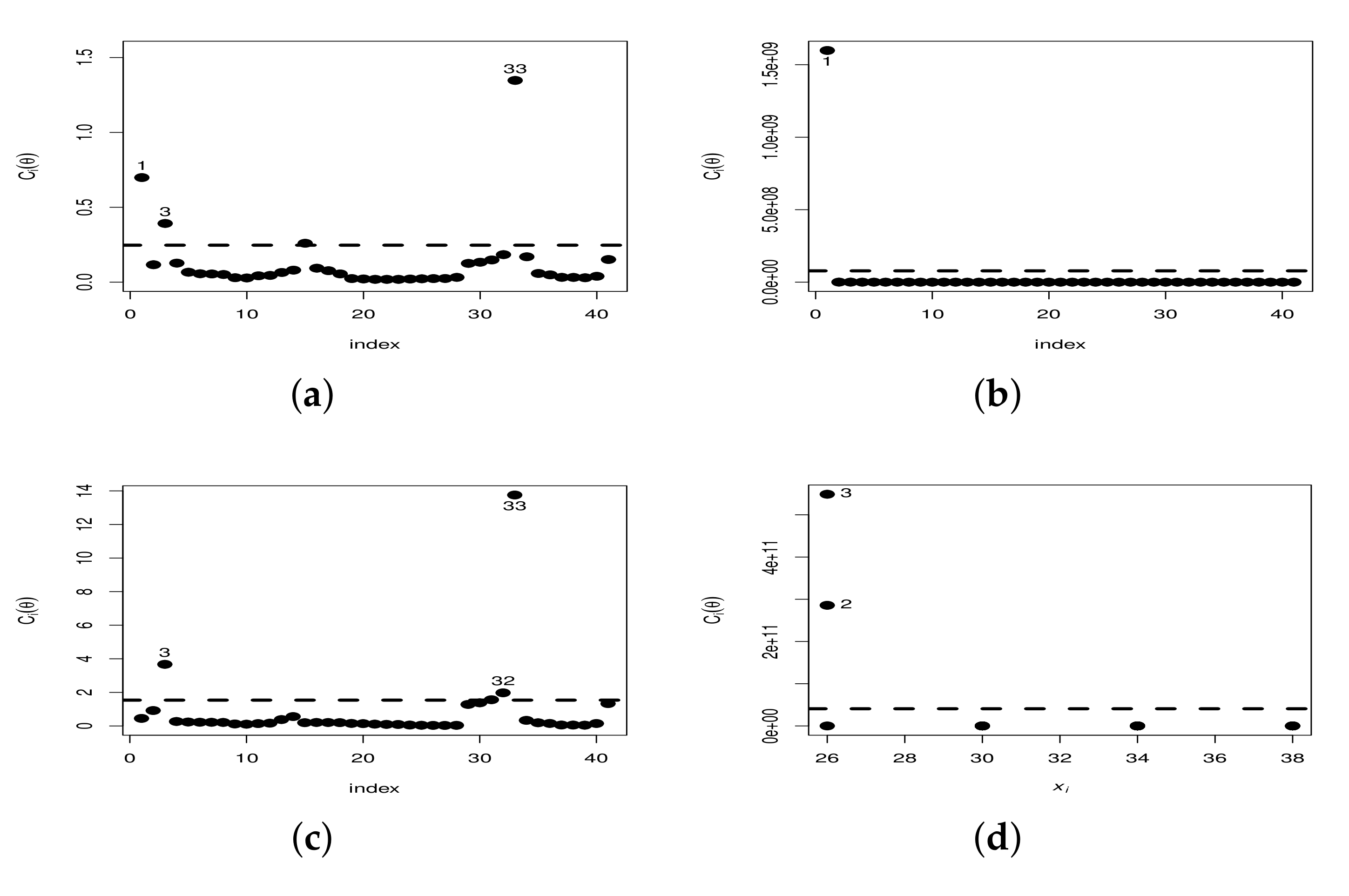
6.2. Local Influence Analysis
6.3. Coefficients across Quantiles
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ventura, M.; Saulo, H.; Leiva, V.; Monsueto, S. Log-symmetric regression models: Information criteria, application to movie business and industry data with economic implications. Appl. Stoch. Model. Bus. Ind. 2019, 35, 963–977. [Google Scholar] [CrossRef]
- Mazucheli, J.; Leiva, V.; Alves, B.; Menezes, A.F.B. A new quantile regression for modeling bounded data under a unit Birnbaum–Saunders distribution with applications in medicine and politics. Symmetry 2021, 13, 682. [Google Scholar] [CrossRef]
- Johnson, N.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Castillo, E.; Hadi, A.S.; Balakrishnan, N.; Sarabia, J.M. Extreme Value and Related Models with Applications in Engineering and Science; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Saraiva, E.F.; Suzuki, A.K. Bayesian computational methods for estimation of two-parameters Weibull distribution in presence of right-censored data. Chilean J. Stat. 2017, 8, 25–43. [Google Scholar]
- Weibull, W. A statistical distribution of wide applicability. J. Appl. Mech. 1951, 18, 293–297. [Google Scholar] [CrossRef]
- Arnold, B.C.; Castillo, E.; Sarabia, J.M. Modeling the fatigue life of longitudinal elements. Nav. Res. Logist. Q. 1996, 43, 885–895. [Google Scholar] [CrossRef]
- Rinne, H. The Weibull Distribution; Chapman and Hall: London, UK, 2009. [Google Scholar]
- Laplace, P. Theorie Analytique des Probabilites; Editions Jacques Gabayr: Paris, France, 1818. [Google Scholar]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Hao, L.; Naiman, D.Q. Quantile Regression. Sage Publications: Thousand Oaks, CA, USA, 2007. [Google Scholar]
- Davino, C.; Furno, M.; Vistocco, D. Quantile Regression: Theory and Applications; Wiley: London, UK, 2013. [Google Scholar]
- Koenker, R.; Chernozhukov, V.; He, X.; Peng, L. Handbook of Quantile Regression; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Davison, A. Statistical Models; Cambridge University Press: Cambrigde, UK, 2003. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Chapman and Hall: London, UK, 1983. [Google Scholar]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Appl. Stoch. Model. Bus. Ind. 2021, 37, 53–73. [Google Scholar] [CrossRef]
- Saulo, H.; Dasilva, A.; Leiva, V.; Sánchez, L.; de la Fuente-Mella, H. Log-symmetric quantile regression models. Stat. Neerl. 2021, in press. [Google Scholar] [CrossRef]
- Cook, R.D.; Weisberg, S. Residuals and Influence in Regression; Chapman and Hall: London, UK, 1982. [Google Scholar]
- Maddala, G.S. Limited-Dependent and Qualitative Variables in Econometrics; Cambridge University Press: Cambridge, UK, 1983. [Google Scholar]
- Dunn, P.; Smyth, G. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Saulo, H.; Leão, J.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders autoregressive conditional duration models applied to high-frequency financial data. Stat. Pap. 2019, 60, 1605–1629. [Google Scholar] [CrossRef] [Green Version]
- Cook, R.D. Assessment of local influence. J. R. Stat. Soc. B 1986, 48, 133–169. [Google Scholar] [CrossRef]
- Santos-Neto, M.; Cysneiros, F.J.A.; Leiva, V.; Barros, M. Reparameterized Birnbaum-Saunders regression models with varying precision. Electron. J. Stat. 2016, 10, 2825–2855. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Uribe-Opazo, M.A.; Aykroyd, R.G. Birnbaum-Saunders spatial regression models: Diagnostics and application to chemical data. Chemom. Intell. Lab. Syst. 2018, 177, 114–128. [Google Scholar] [CrossRef] [Green Version]
- Leiva, V.; Sanchez, L.; Galea, M.; Saulo, H. Global and local diagnostic analytics for a geostatistical model based on a new approach to quantile regression. Stoch. Environ. Res. Risk Assess. 2020, 34, 1457–1471. [Google Scholar] [CrossRef]
- Meeker, W.; Escobar, L. Statistical Methods for Reliability Data; Wiley: New York, NY, USA, 1998. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Therneau, T. A Package for Survival Analysis in R; R Package Version 3.2-10. 2021. Available online: https://CRAN.R-project.org/package=survival (accessed on 18 October 2021).
- Maechler, M.; Rousseeuw, P.; Croux, C.; Todorov, V.; Ruckstuhl, A.; Salibian-Barrera, M.; Verbeke, T.; Koller, M.; Conceicao, E.L.; di Palma, M.A. Package ‘robustbase’. Basic Robust Statistics. 2021. Available online: https://cran.r-project.org/web/packages/robustbase/robustbase.pdf (accessed on 18 October 2021).
- Noufaily, A.; Jones, M. Parametric quantile regression based on the generalized gamma distribution. J. R. Stat. Soc. C 2013, 62, 723–740. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.; Fernandes, L.; Puziol, R.; Ghitany, M. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2019, 47, 954–974. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wald, A. Sequential Analysis; Wiley: New York, NY, USA, 1947. [Google Scholar]
- Wilks, S.S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 1938, 9, 60–62. [Google Scholar] [CrossRef]
- Lesaffre, E.; Verbeke, G. Local influence in linear mixed models. Biometrics 1998, 54, 570–582. [Google Scholar] [CrossRef]
- Weisberg, S. Applied Linear Regression; Wiley: New York, NY, USA, 2014. [Google Scholar]
- Huerta, M.; Leiva, V.; Liu, S.; Rodriguez, M.; Villegas, D. On a partial least squares regression model for asymmetric data with a chemical application in mining. Chemom. Intell. Lab. Syst. 2019, 190, 55–68. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression models with application to spatial data. Mathematics 2020, 8, 1000. [Google Scholar] [CrossRef]
- Calle-Saldarriaga, A.; Laniado, H.; Zuluaga, F.; Leiva, V. Homogeneity tests for functional data based on depth-depth plots with chemical applications. Chemom. Intell. Lab. Syst. 2021, in press. [Google Scholar] [CrossRef]
- Leiva, V.; Saulo, H.; Souza, R.; Aykroyd, R.G.; Vila, R. A new BISARMA time series model for forecasting mortality using weather and particulate matter data. J. Forecast. 2021, 40, 346–364. [Google Scholar] [CrossRef]
- Figueroa-Zúñiga, J.I.; Bayes, C.L.; Leiva, V.; Liu, S. Robust Beta Regression Modeling with Errors-in-Variables: A Bayesian Approach and Numerical Applications. Stat. Pap. 2022, in press. [Google Scholar] [CrossRef]
- He, F.; Wang, H.J.; Tong, T. Extremal linear quantile regression with Weibull-type tails. Stat. Sin. 2020, 30, 1357–1377. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Median | Mean | SD | CV | CS | CK | n | ||
|---|---|---|---|---|---|---|---|---|
| 7.7400 | 122.51 | 430.24 | 3.51 | 4.36 | 20.93 | 0.09 | 2323.70 | 41 |
| Statistic | |||||||||||
| True value | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | ||
| Mean | 0.6011 | 0.5491 | 0.5138 | 0.5506 | 0.5244 | 0.5069 | 0.5253 | 0.5122 | 0.5034 | ||
| Bias | 0.1011 | 0.0491 | 0.0138 | 0.0506 | 0.0244 | 0.0069 | 0.0253 | 0.0122 | 0.0034 | ||
| Variance | 0.6747 | 0.1746 | 0.0537 | 0.1687 | 0.0437 | 0.0134 | 0.0422 | 0.0109 | 0.0034 | ||
| RMSE | 0.8276 | 0.4207 | 0.2322 | 0.4138 | 0.2104 | 0.1161 | 0.2069 | 0.1052 | 0.0581 | ||
| CS | −0.1288 | −0.1332 | −0.1183 | −0.1287 | −0.1331 | −0.1179 | −0.1286 | −0.1327 | −0.1180 | ||
| CK | 3.1481 | 3.0124 | 2.9364 | 3.1475 | 3.0105 | 2.9359 | 3.1476 | 3.0094 | 2.9360 | ||
| True value | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| Mean | 1.0193 | 0.9831 | 0.9954 | 1.0097 | 0.9915 | 0.9977 | 1.0048 | 0.9958 | 0.9988 | ||
| Bias | 0.0193 | −0.0169 | −0.0046 | 0.0097 | −0.0085 | −0.0023 | 0.0048 | −0.0042 | −0.0012 | ||
| Variance | 0.8966 | 0.2356 | 0.0745 | 0.2241 | 0.0589 | 0.0186 | 0.0560 | 0.0147 | 0.0047 | ||
| RMSE | 0.9471 | 0.4856 | 0.2730 | 0.4735 | 0.2428 | 0.1365 | 0.2368 | 0.1214 | 0.0682 | ||
| CS | 0.0619 | −0.0344 | 0.1067 | 0.0621 | −0.0347 | 0.1068 | 0.0621 | −0.0348 | 0.1067 | ||
| CK | 2.8443 | 3.0606 | 3.0311 | 2.8454 | 3.0607 | 3.0311 | 2.8440 | 3.0633 | 3.0311 | ||
| True value | 0.5000 | 0.5000 | 0.5000 | 1.0000 | 1.0000 | 1.0000 | 2.0000 | 2.0000 | 2.0000 | ||
| Mean | 0.5210 | 0.5061 | 0.5021 | 1.0419 | 1.0122 | 1.0043 | 2.0838 | 2.0244 | 2.0086 | ||
| Bias | 0.0210 | 0.0061 | 0.0021 | 0.0419 | 0.0122 | 0.0043 | 0.0838 | 0.0244 | 0.0086 | ||
| Variance | 0.0036 | 0.0008 | 0.0003 | 0.0144 | 0.0033 | 0.0010 | 0.0576 | 0.0130 | 0.0041 | ||
| RMSE | 0.0636 | 0.0292 | 0.0162 | 0.1271 | 0.0584 | 0.0324 | 0.2543 | 0.1168 | 0.0648 | ||
| CS | 0.5824 | 0.2446 | 0.0840 | 0.5826 | 0.2450 | 0.0840 | 0.5831 | 0.2447 | 0.0841 | ||
| CK | 3.7567 | 2.9277 | 2.6255 | 3.7563 | 2.9247 | 2.6253 | 3.7577 | 2.9246 | 2.6250 | ||
| Statistic | |||||||||||
| True value | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | ||
| Mean | 0.4963 | 0.5152 | 0.5015 | 0.4982 | 0.5076 | 0.5008 | 0.4991 | 0.5038 | 0.5004 | ||
| Bias | −0.0037 | 0.0152 | 0.0015 | −0.0018 | 0.0076 | 0.0008 | −0.0009 | 0.0038 | 0.0004 | ||
| Variance | 0.3423 | 0.0885 | 0.0261 | 0.0856 | 0.0221 | 0.0065 | 0.0214 | 0.0055 | 0.0016 | ||
| RMSE | 0.5851 | 0.2978 | 0.1615 | 0.2925 | 0.1489 | 0.0808 | 0.1463 | 0.0745 | 0.0404 | ||
| CS | −0.2084 | −0.1717 | −0.1039 | −0.2085 | −0.1716 | −0.1039 | −0.2084 | −0.1715 | −0.1038 | ||
| CK | 3.0076 | 3.1321 | 2.9602 | 3.0078 | 3.1320 | 2.9601 | 3.0075 | 3.1319 | 2.9600 | ||
| True value | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| Mean | 1.0194 | 0.9831 | 0.9954 | 1.0097 | 0.9916 | 0.9977 | 1.0049 | 0.9958 | 0.9988 | ||
| Bias | 0.0194 | −0.0169 | −0.0046 | 0.0097 | −0.0084 | −0.0023 | 0.0049 | −0.0042 | −0.0012 | ||
| Variance | 0.8965 | 0.2355 | 0.0745 | 0.2241 | 0.0589 | 0.0186 | 0.0560 | 0.0147 | 0.0047 | ||
| RMSE | 0.9470 | 0.4856 | 0.2730 | 0.4735 | 0.2428 | 0.1365 | 0.2368 | 0.1214 | 0.0683 | ||
| CS | 0.0619 | −0.0343 | 0.1067 | 0.0619 | −0.0343 | 0.1068 | 0.0620 | −0.0344 | 0.1067 | ||
| CK | 2.8447 | 3.0612 | 3.0311 | 2.8448 | 3.0612 | 3.0309 | 2.8450 | 3.0609 | 3.0310 | ||
| True value | 0.5000 | 0.5000 | 0.5000 | 1.0000 | 1.0000 | 1.0000 | 2.0000 | 2.0000 | 2.0000 | ||
| Mean | 0.5210 | 0.5061 | 0.5021 | 1.0419 | 1.0122 | 1.0043 | 2.0838 | 2.0243 | 2.0086 | ||
| Bias | 0.0210 | 0.0061 | 0.0021 | 0.0419 | 0.0122 | 0.0043 | 0.0838 | 0.0243 | 0.0086 | ||
| Variance | 0.0036 | 0.0008 | 0.0003 | 0.0144 | 0.0033 | 0.0010 | 0.0576 | 0.0130 | 0.0041 | ||
| RMSE | 0.0636 | 0.0292 | 0.0162 | 0.1271 | 0.0584 | 0.0324 | 0.2543 | 0.1168 | 0.0648 | ||
| CS | 0.5826 | 0.2448 | 0.0841 | 0.5825 | 0.2448 | 0.0840 | 0.5824 | 0.2448 | 0.0840 | ||
| CK | 3.7568 | 2.9256 | 2.6256 | 3.7565 | 2.9256 | 2.6254 | 3.7559 | 2.9256 | 2.6255 | ||
| Statistic | |||||||||||
| True value | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | ||
| Mean | 0.4295 | 0.4939 | 0.4937 | 0.4648 | 0.4969 | 0.4969 | 0.4824 | 0.4985 | 0.4984 | ||
| Bias | −0.0705 | −0.0061 | −0.0063 | −0.0352 | −0.0031 | −0.0031 | −0.0176 | −0.0015 | −0.0016 | ||
| Variance | 0.3075 | 0.0794 | 0.0235 | 0.0769 | 0.0198 | 0.0059 | 0.0192 | 0.0050 | 0.0015 | ||
| RMSE | 0.5590 | 0.2818 | 0.1534 | 0.2795 | 0.1409 | 0.0767 | 0.1397 | 0.0704 | 0.0384 | ||
| CS | −0.1501 | −0.1109 | −0.1234 | −0.1505 | −0.1108 | −0.1234 | −0.1504 | −0.1109 | −0.1234 | ||
| CK | 2.9205 | 3.1507 | 2.9856 | 2.9191 | 3.1504 | 2.9857 | 2.9190 | 3.1504 | 2.9857 | ||
| True value | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| Mean | 1.0194 | 0.9831 | 0.9953 | 1.0097 | 0.9915 | 0.9977 | 1.0048 | 0.9958 | 0.9988 | ||
| Bias | 0.0194 | −0.0169 | −0.0047 | 0.0097 | −0.0085 | −0.0023 | 0.0048 | −0.0042 | −0.0012 | ||
| Variance | 0.8965 | 0.2355 | 0.0745 | 0.2241 | 0.0589 | 0.0186 | 0.0560 | 0.0147 | 0.0047 | ||
| RMSE | 0.9470 | 0.4856 | 0.2730 | 0.4735 | 0.2428 | 0.1365 | 0.2368 | 0.1214 | 0.0682 | ||
| CS | 0.0617 | −0.0343 | 0.1067 | 0.0620 | −0.0343 | 0.1067 | 0.0619 | −0.0342 | 0.1067 | ||
| CK | 2.8453 | 3.0612 | 3.0310 | 2.8448 | 3.0612 | 3.0311 | 2.8447 | 3.0609 | 3.0311 | ||
| True value | 0.5000 | 0.5000 | 0.5000 | 1.0000 | 1.0000 | 1.0000 | 2.0000 | 2.0000 | 2.0000 | ||
| Mean | 0.5210 | 0.5061 | 0.5021 | 1.0419 | 1.0122 | 1.0043 | 2.0838 | 2.0243 | 2.0086 | ||
| Bias | 0.0210 | 0.0061 | 0.0021 | 0.0419 | 0.0122 | 0.0043 | 0.0838 | 0.0243 | 0.0086 | ||
| Variance | 0.0036 | 0.0008 | 0.0003 | 0.0144 | 0.0033 | 0.0010 | 0.0576 | 0.0130 | 0.0041 | ||
| RMSE | 0.0636 | 0.0292 | 0.0162 | 0.1271 | 0.0584 | 0.0324 | 0.2543 | 0.1168 | 0.0648 | ||
| CS | 0.5825 | 0.2448 | 0.0840 | 0.5825 | 0.2449 | 0.0840 | 0.5825 | 0.2447 | 0.0840 | ||
| CK | 3.7567 | 2.9257 | 2.6254 | 3.7567 | 2.9258 | 2.6255 | 3.7566 | 2.9257 | 2.6254 | ||
| Statistic | |||||||||||
| True value | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| Mean | 1.1013 | 1.0493 | 1.0138 | 1.0506 | 1.0244 | 1.0069 | 1.0253 | 1.0122 | 1.0034 | ||
| Bias | 0.1013 | 0.0493 | 0.0138 | 0.0506 | 0.0244 | 0.0069 | 0.0253 | 0.0122 | 0.0034 | ||
| Variance | 0.6747 | 0.1747 | 0.0537 | 0.1687 | 0.0437 | 0.0134 | 0.0422 | 0.0109 | 0.0034 | ||
| RMSE | 0.8276 | 0.4208 | 0.2322 | 0.4138 | 0.2104 | 0.1161 | 0.2069 | 0.1052 | 0.0581 | ||
| CS | −0.1295 | −0.1353 | −0.1183 | −0.1290 | −0.1330 | −0.1180 | −0.1292 | −0.1332 | −0.1185 | ||
| CK | 3.1489 | 3.0134 | 2.9364 | 3.1480 | 3.0104 | 2.9358 | 3.1485 | 3.0116 | 2.9364 | ||
| True value | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | ||
| Mean | 2.5193 | 2.4830 | 2.4954 | 2.5097 | 2.4915 | 2.4977 | 2.5048 | 2.4958 | 2.4989 | ||
| Bias | 0.0193 | −0.0170 | −0.0046 | 0.0097 | −0.0085 | −0.0023 | 0.0048 | −0.0042 | −0.0011 | ||
| Variance | 0.8962 | 0.2358 | 0.0745 | 0.2241 | 0.0589 | 0.0186 | 0.0560 | 0.0147 | 0.0047 | ||
| RMSE | 0.9469 | 0.4859 | 0.2730 | 0.4735 | 0.2428 | 0.13657 | 0.2368 | 0.1214 | 0.0682 | ||
| CS | 0.0622 | −0.0376 | 0.1068 | 0.0619 | −0.0346 | 0.1066 | 0.0621 | −0.0336 | 0.1070 | ||
| CK | 2.8454 | 3.0685 | 3.0310 | 2.8447 | 3.0617 | 3.0290 | 2.8452 | 3.0608 | 3.0310 | ||
| True value | 0.5000 | 0.5000 | 0.5000 | 1.0000 | 1.0000 | 1.0000 | 2.0000 | 2.0000 | 2.0000 | ||
| Mean | 0.5210 | 0.5061 | 0.5021 | 1.0419 | 1.0122 | 1.0043 | 2.0838 | 2.0243 | 2.0086 | ||
| Bias | 0.0210 | 0.0061 | 0.0021 | 0.0419 | 0.0122 | 0.0043 | 0.0838 | 0.0243 | 0.0086 | ||
| Variance | 0.0036 | 0.0008 | 0.0003 | 0.0144 | 0.0033 | 0.0010 | 0.0576 | 0.0130 | 0.0041 | ||
| RMSE | 0.0636 | 0.0292 | 0.0162 | 0.1271 | 0.0584 | 0.0324 | 0.2543 | 0.1168 | 0.0648 | ||
| CS | 0.5824 | 0.2461 | 0.0840 | 0.5826 | 0.2453 | 0.0829 | 0.5824 | 0.2456 | 0.0836 | ||
| CK | 3.7574 | 2.9265 | 2.6256 | 3.7571 | 2.9272 | 2.6223 | 3.7563 | 2.9261 | 2.6256 | ||
| Statistic | |||||||||||
| True value | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| Mean | 0.9963 | 1.0152 | 1.0015 | 0.9982 | 1.0076 | 1.0008 | 0.9991 | 1.0038 | 1.0004 | ||
| Bias | −0.0037 | 0.0152 | 0.0015 | −0.0018 | 0.0076 | 0.0008 | −0.0009 | 0.0038 | 0.0004 | ||
| Variance | 0.3423 | 0.0885 | 0.0261 | 0.0856 | 0.0221 | 0.0065 | 0.0214 | 0.0055 | 0.0016 | ||
| RMSE | 0.5851 | 0.2978 | 0.1615 | 0.2925 | 0.1489 | 0.0807 | 0.1463 | 0.0745 | 0.0404 | ||
| CS | −0.2084 | −0.1718 | −0.1039 | −0.2083 | −0.1716 | −0.1038 | −0.2084 | −0.1715 | −0.1044 | ||
| CK | 3.0076 | 3.1324 | 2.9603 | 3.0073 | 3.1323 | 2.9601 | 3.0069 | 3.1312 | 2.9588 | ||
| True value | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | ||
| Mean | 2.5194 | 2.4831 | 2.4954 | 2.5097 | 2.4916 | 2.4977 | 2.5049 | 2.4958 | 2.4989 | ||
| Bias | 0.0194 | −0.0169 | −0.0046 | 0.0097 | −0.0084 | −0.0023 | 0.0049 | −0.0042 | −0.0011 | ||
| Variance | 0.8964 | 0.2355 | 0.0745 | 0.2241 | 0.0589 | 0.0186 | 0.0560 | 0.0147 | 0.0047 | ||
| RMSE | 0.9470 | 0.4856 | 0.2730 | 0.4735 | 0.2428 | 0.1365 | 0.2368 | 0.1214 | 0.0682 | ||
| CS | 0.0619 | −0.0343 | 0.1067 | 0.0618 | −0.0343 | 0.1066 | 0.0618 | −0.0342 | 0.1060 | ||
| CK | 2.8447 | 3.0612 | 3.0310 | 2.8448 | 3.0615 | 3.0307 | 2.8453 | 3.0600 | 3.0309 | ||
| True value | 0.5000 | 0.5000 | 0.5000 | 1.0000 | 1.0000 | 1.0000 | 2.0000 | 2.0000 | 2.0000 | ||
| Mean | 0.5210 | 0.5061 | 0.5021 | 1.0419 | 1.0122 | 1.0043 | 2.0838 | 2.0243 | 2.0087 | ||
| Bias | 0.0210 | 0.0061 | 0.0021 | 0.0419 | 0.0122 | 0.0043 | 0.0838 | 0.0243 | 0.0087 | ||
| Variance | 0.0036 | 0.0008 | 0.0003 | 0.0144 | 0.0033 | 0.0010 | 0.0576 | 0.0130 | 0.0041 | ||
| RMSE | 0.0636 | 0.0292 | 0.0162 | 0.1271 | 0.0584 | 0.0324 | 0.2543 | 0.1168 | 0.0648 | ||
| CS | 0.5825 | 0.2447 | 0.0838 | 0.5824 | 0.2446 | 0.0838 | 0.5825 | 0.2446 | 0.0820 | ||
| CK | 3.7565 | 2.9255 | 2.6254 | 3.7563 | 2.9257 | 2.6253 | 3.7571 | 2.9255 | 2.6247 | ||
| Statistic | |||||||||||
| True value | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| Mean | 0.9295 | 0.9938 | 0.9937 | 0.9648 | 0.9969 | 0.9969 | 0.9824 | 0.9985 | 0.9984 | ||
| Bias | −0.0705 | −0.0062 | −0.0063 | −0.0352 | −0.0031 | −0.0031 | −0.0176 | −0.0015 | −0.0016 | ||
| Variance | 0.3074 | 0.0794 | 0.0235 | 0.0769 | 0.0198 | 0.0059 | 0.0192 | 0.0050 | 0.0015 | ||
| RMSE | 0.5589 | 0.2818 | 0.1534 | 0.2795 | 0.1409 | 0.0767 | 0.1397 | 0.0705 | 0.0384 | ||
| CS | −0.1500 | −0.1104 | −0.1234 | −0.1505 | −0.1111 | −0.1234 | −0.1504 | −0.1107 | −0.1230 | ||
| CK | 2.9199 | 3.1514 | 2.9857 | 2.9190 | 3.1513 | 2.9857 | 2.9190 | 3.1501 | 2.9853 | ||
| True value | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | 2.5000 | ||
| Mean | 2.5194 | 2.4832 | 2.4954 | 2.5097 | 2.4916 | 2.4977 | 2.5048 | 2.4958 | 2.4988 | ||
| Bias | 0.0194 | −0.0168 | −0.0046 | 0.0097 | −0.0084 | −0.0023 | 0.0048 | −0.0042 | −0.0012 | ||
| Variance | 0.8963 | 0.2355 | 0.0745 | 0.2241 | 0.0589 | 0.0186 | 0.0560 | 0.0147 | 0.0047 | ||
| RMSE | 0.9469 | 0.4856 | 0.2730 | 0.4735 | 0.2428 | 0.1365 | 0.2368 | 0.1214 | 0.0683 | ||
| CS | 0.0615 | −0.0349 | 0.1067 | 0.0620 | −0.0343 | 0.1068 | 0.0619 | −0.0341 | 0.1064 | ||
| CK | 2.8454 | 3.0617 | 3.0310 | 2.8448 | 3.0610 | 3.0311 | 2.8448 | 3.0609 | 3.0310 | ||
| True value | 0.5000 | 0.5000 | 0.5000 | 1.0000 | 1.0000 | 1.0000 | 2.0000 | 2.0000 | 2.0000 | ||
| Mean | 0.5210 | 0.5061 | 0.5021 | 1.0419 | 1.0122 | 1.0043 | 2.0838 | 2.0243 | 2.0086 | ||
| Bias | 0.0210 | 0.0061 | 0.0021 | 0.0419 | 0.0122 | 0.0043 | 0.0838 | 0.0243 | 0.0086 | ||
| Variance | 0.0036 | 0.0008 | 0.0003 | 0.0144 | 0.0033 | 0.0010 | 0.0576 | 0.0130 | 0.0041 | ||
| RMSE | 0.0636 | 0.0292 | 0.0162 | 0.1271 | 0.0584 | 0.0324 | 0.2543 | 0.1168 | 0.0648 | ||
| CS | 0.5825 | 0.2448 | 0.0840 | 0.5825 | 0.2449 | 0.0840 | 0.5825 | 0.2448 | 0.0838 | ||
| CK | 3.7566 | 2.9255 | 2.6255 | 3.7567 | 2.9257 | 2.6254 | 3.7566 | 2.9256 | 2.6257 | ||
| Statistic | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| SD | 0.9882 | 0.9963 | 0.9986 | 0.9882 | 0.9963 | 0.9986 | 0.9882 | 0.9963 | 0.9986 | ||
| CS | 1.5711 | 1.8525 | 1.9394 | 1.5710 | 1.8524 | 1.9394 | 1.5711 | 1.8524 | 1.9394 | ||
| CK | 5.7186 | 7.6584 | 8.3894 | 5.7185 | 7.6578 | 8.3894 | 5.7187 | 7.6580 | 8.3895 | ||
| Mean | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| SD | 0.9882 | 0.9963 | 0.9986 | 0.9882 | 0.9963 | 0.9986 | 0.9882 | 0.9963 | 0.9986 | ||
| CS | 1.5711 | 1.8524 | 1.9394 | 1.5711 | 1.8524 | 1.9394 | 1.5711 | 1.8524 | 1.9394 | ||
| CK | 5.7189 | 7.6577 | 8.3894 | 5.7188 | 7.6577 | 8.3895 | 5.7188 | 7.6577 | 8.3895 | ||
| Mean | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| SD | 0.9882 | 0.9963 | 0.9986 | 0.9882 | 0.9963 | 0.9986 | 0.9882 | 0.9963 | 0.9986 | ||
| CS | 1.5711 | 1.8524 | 1.9394 | 1.5711 | 1.8524 | 1.9394 | 1.5711 | 1.8524 | 1.9394 | ||
| CK | 5.7189 | 7.6577 | 8.3895 | 5.7188 | 7.6577 | 8.3895 | 5.7189 | 7.6577 | 8.3895 | ||
| Statistic | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | 0.0012 | 0.0004 | 0.0001 | 0.0012 | 0.0004 | 0.0001 | 0.0012 | 0.0004 | 0.0001 | ||
| SD | 1.0134 | 1.0033 | 1.0011 | 1.0134 | 1.0033 | 1.0011 | 1.0133 | 1.0033 | 1.0011 | ||
| CS | 0.0142 | 0.0026 | 0.0009 | 0.0142 | 0.0027 | 0.0009 | 0.0142 | 0.0027 | 0.0009 | ||
| CK | 2.7487 | 2.9258 | 2.9774 | 2.7486 | 2.9258 | 2.9774 | 2.7487 | 2.9258 | 2.9774 | ||
| Mean | 0.0012 | 0.0003 | 0.0001 | 0.0012 | 0.0004 | 0.0001 | 0.0012 | 0.0003 | 0.0001 | ||
| SD | 1.0134 | 1.0033 | 1.0011 | 1.0134 | 1.0033 | 1.0011 | 1.0134 | 1.0033 | 1.0011 | ||
| CS | 0.0142 | 0.0027 | 0.0009 | 0.0142 | 0.0027 | 0.0009 | 0.0142 | 0.0027 | 0.0009 | ||
| CK | 2.7487 | 2.9258 | 2.9774 | 2.7487 | 2.9258 | 2.9774 | 2.7487 | 2.9258 | 2.9774 | ||
| Mean | 0.0012 | 0.0004 | 0.0001 | 0.0012 | 0.0003 | 0.0001 | 0.0012 | 0.0003 | 0.0001 | ||
| SD | 1.0134 | 1.0033 | 1.0011 | 1.0134 | 1.0033 | 1.0011 | 1.0134 | 1.0033 | 1.0011 | ||
| CS | 0.0142 | 0.0027 | 0.0009 | 0.0142 | 0.0027 | 0.0009 | 0.0142 | 0.0027 | 0.0009 | ||
| CK | 2.7487 | 2.9258 | 2.9774 | 2.7487 | 2.9258 | 2.9774 | 2.7487 | 2.9258 | 2.9774 | ||
| Model | AIC | CAIC | BIC | Log-Likelihood | |
|---|---|---|---|---|---|
| L1 | 327.07 | 327.71 | 332.21 | 0.71 | −160.53 |
| L2 | 351.63 | 352.28 | 356.77 | 0.47 | −172.81 |
| Statistic | |||
|---|---|---|---|
| Estimate | 20.97 | −0.56 | 0.82 |
| SE | 1.86 | 0.06 | 0.10 |
| p-value | <0.01 | <0.01 | <0.01 |
| Parameter | ||||
|---|---|---|---|---|
| Removed Case(s) | ||||
| None | RC() | N/A | N/A | N/A |
| RC() | N/A | N/A | N/A | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 3.41 | 3.41 | 5.81 | |
| RC() | 2.52 | 2.78 | 5.38 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 4.87 | 5.23 | 0.77 | |
| RC() | 18.86 | 18.31 | 0.14 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 1.46 | 1.98 | 8.16 | |
| RC() | 13.23 | 13.26 | 12.43 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 0.45 | 0.71 | 4.74 | |
| RC() | 12.25 | 11.37 | 5.15 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 4.46 | 4.92 | 15.72 | |
| RC() | 15.21 | 15.50 | 20.27 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 3.28 | 3.11 | 7.54 | |
| RC() | 3.65 | 4.11 | 12.51 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| RC() | 0.56 | 0.76 | 14.77 | |
| RC() | 5.40 | 6.19 | 20.12 | |
| p-value | <0.01 | <0.01 | <0.01 | |
| Estimate | ||||||
|---|---|---|---|---|---|---|
| 18.97 | 21.80 | 20.97 | 20.19 | 21.02 | 20.50 | |
| −0.57 | −0.62 | −0.56 | −0.52 | −0.52 | −0.57 | |
| 0.84 | 0.81 | 0.82 | 0.84 | 0.84 | 0.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez, L.; Leiva, V.; Saulo, H.; Marchant, C.; Sarabia, J.M. A New Quantile Regression Model and Its Diagnostic Analytics for a Weibull Distributed Response with Applications. Mathematics 2021, 9, 2768. https://doi.org/10.3390/math9212768
Sánchez L, Leiva V, Saulo H, Marchant C, Sarabia JM. A New Quantile Regression Model and Its Diagnostic Analytics for a Weibull Distributed Response with Applications. Mathematics. 2021; 9(21):2768. https://doi.org/10.3390/math9212768
Chicago/Turabian StyleSánchez, Luis, Víctor Leiva, Helton Saulo, Carolina Marchant, and José M. Sarabia. 2021. "A New Quantile Regression Model and Its Diagnostic Analytics for a Weibull Distributed Response with Applications" Mathematics 9, no. 21: 2768. https://doi.org/10.3390/math9212768
APA StyleSánchez, L., Leiva, V., Saulo, H., Marchant, C., & Sarabia, J. M. (2021). A New Quantile Regression Model and Its Diagnostic Analytics for a Weibull Distributed Response with Applications. Mathematics, 9(21), 2768. https://doi.org/10.3390/math9212768