1. Introduction
The supercomputer infrastructure is a complex system in terms of its total power consumption. It is a system whose behavior depends on many factors, which may nonlinearly depend on each other, and where the number of such factors is so great that it is computationally impossible to model. The individual user tasks can cause consumption with aregular pattern, but, in combination, they generate a consumption pattern that is much less regular and, in some places, can seem almost chaotic.
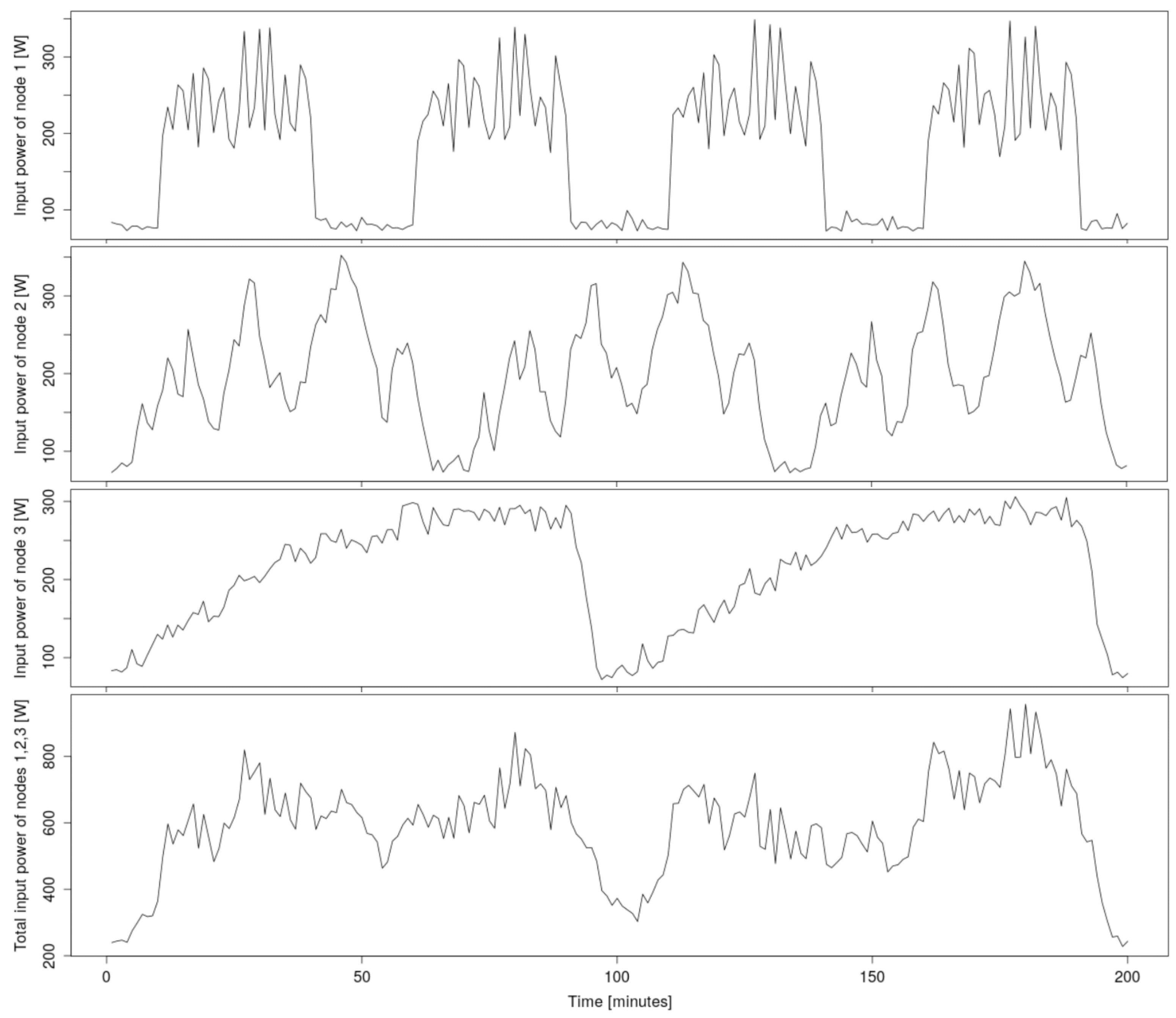
A simplified example of such a pattern-merging is shown in
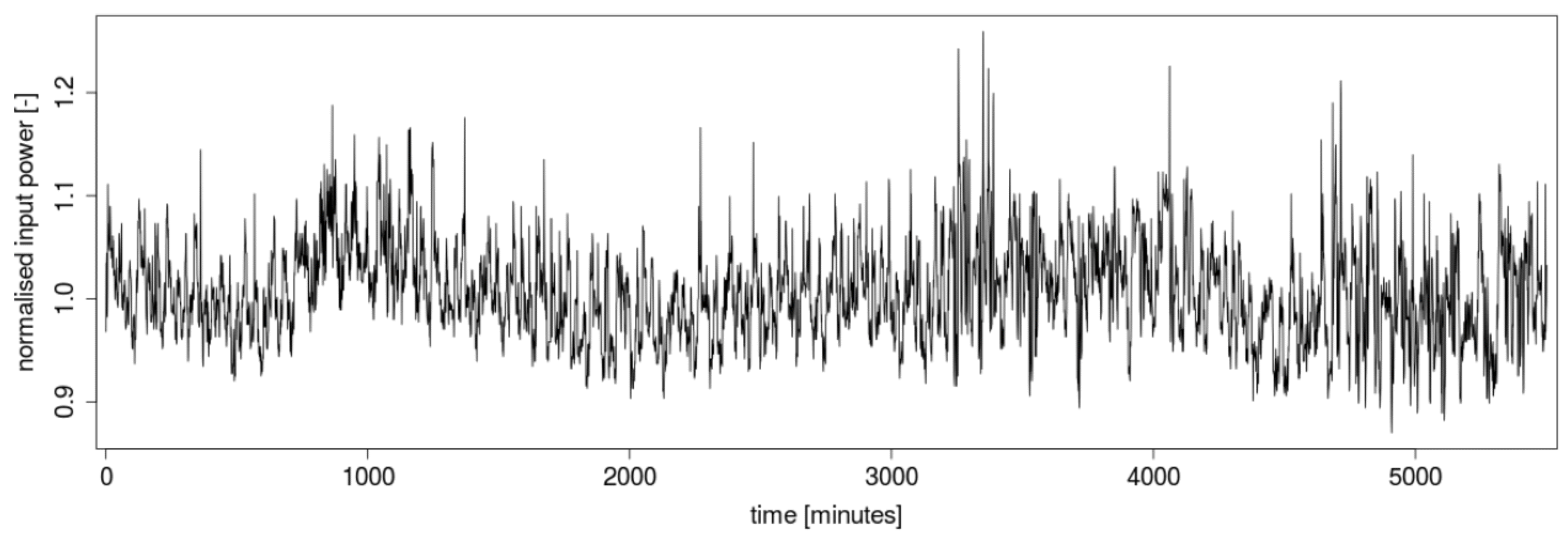
Figure 1. In real traffic, more users are working on the supercomputer at the same time, so the total consumption is then the result of the combination of many such patterns. An example of the total power consumption of a real supercomputer infrastructure, measured over several days, is shown in
Figure 2.
Since this is not a completely chaotic time series, its development can be partially predicted using appropriate forecasting methods. However, its complexity is so high that not all samples of this time series can successfully be used to predict its future evolution. Using all past values in the prediction of such a complex time series inevitably leads to overfitting. Of course, if too few values are used, the opposite (underfitting) will be the case, so the crucial task of any successful prediction method is to find the parts of the previous evolution of the predicted time series that most determine its character. Every prediction method has to deal with this problem.
Machine learning methods [
1] handle this by creating a mathematical model, but this takes some time to build, so these methods may be too slow for fast real-time predictions. It is possible to reuse a mathematical model built on older data to save time, but this can lead to larger prediction errors. Statistical methods [
2], on the other hand, work with parameters that describe the time series globally and are not sensitive to the possible fluctuations that may occasionally occur during this power energy consumption.
This paper presents a new nonlinear forecasting method that was designed to find the most significant parts of the previous time series evolution, and thus to produce forecasts very quickly, even for a seemingly chaotic time series.
2. Zeroth Algorithm
The reason the zeroth algorithm method is briefly introduced here is that the new prediction method is partly based on this simple method. This method uses the zeroth-order approximation of the time series dynamics [
4]. Therefore, it is very fast but inaccurate. In the previous course of the predicted time series, this method looks for subsequences that are similar to the last subsequence. The forecast is then the arithmetic mean of the values that followed these similar subsequences in the past:
where
is the last subsequence,
is a subsequence in the past,
m is their length,
is the delay time,
is the radius of
, and
is number of similar subsequences in the past (they belong to the neighborhood
of the last subsequence).
The principle of this method can be shown by a simple example. Suppose the predicted time series is
and its members have values:
1.046794
1.049179
1.039641
1.046794
1.049179 | | 1.042025
1.030103
1.061101
1.046794
1.056332 |
For this example, the length of the searched similar subsequences and the time delay will be chosen. Thus, if a prediction of the value is sought, the last subsequence will be . For simplicity, the Manhattan norm will be used to measure the distance between subsequences. Then, the distances of the previous subsequences , , , and from the last subsequence will be 0.014307, 0.021460, 0.045305, and 0.028614. If the radius of is chosen to be , then and will be considered as similar subsequences. The prediction of is then calculated as the arithmetic mean of the values of the predicted time series following these similar subsequences, which, in this case, are the values of and . The result is therefore .
3. New Method
In brief, this new method attempts to find time delay patterns that, if used in the zeroth algorithm method on previous data, would result in the most accurate prediction. The structures of these patterns are randomly assembled, and the algorithm selects the most successful ones, which are used in the final calculation of the current prediction.
The principle of the new method is, therefore, partly based on the zeroth algorithm, but the subsequences
and
are defined using the random time-delay pattern (
). The randomly generated
s are then used to generate a multitude of estimated continuations of the predicted time series
. For one particular
, the partial prediction value
y and its estimated error rate
are calculated as follows:
where
y is the partial prediction (created by this particular
), which is equal to the value of the predicted time series
following subsequence
which is the subsequence that is most similar to
among all
subsequences in the past,
is the estimated error rate of this partial prediction,
is the distance norm between the last subsequence and the most similar subsequence,
is a random time-delays pattern,
m is the length of
s,
are random time delays,
are random time intervals.
The above procedure is repeated for
(number of patterns)
s, and the final prediction is then calculated as the arithmetic mean of the
(number of the most successful patterns) best partial predictions. Mathematically, it can be expressed as follows:
where
is the final prediction of the value of the predicted time series
at time
t,
is the number of the most successful
s,
is the total number of
s,
is the set of pairs
created by all
s, which are sorted in ascending order of the size of estimated error rates
.
It is worth mentioning that the values of , , m, and must be determined in advance. These are the parameters of this new method and fundamentally affect its accuracy and computational demand.
This new method will hereafter be referred to as the RTDP method and, for better illustration, it is written in pseudocode in Algorithm 1.
| Algorithm 1 The RTDP method in pseudocode. |
| Require: |
| Ensure: |
| |
| for i = 1 to do | ▹ tries s |
| random vector of length m containing random integer numbers from 1 to |
| |
| | ▹ is actually a cumulative sum of |
| for k = 1 to do | ▹ goes through all possible subsequencies in |
| | ▹ each distance between and is stored |
| end for |
| | ▹ finds the k for which is closest to |
| | ▹ assumed best prediction made by this |
| | ▹ distance of the closest subsequence |
| | ▹ adds results from this to the overall result set |
| end for |
| | ▹ ranking all s predictions by assumed accuracy |
| | ▹ averaging the best predictions |
For a better understanding of this method, it is also useful to demonstrate its principle with a simple example. Suppose the predicted time series is
and its members have values:
1.046794
1.049179
1.039641
1.046794
1.049179 | | 1.042025
1.030103
1.061101
1.046794
1.056332 | | 1.022949
1.022949
1.027718
1.027718
1.020565 | | 0.999104
1.011027
1.008642
1.013411
1.025334 |
For this simple example, the following parameters will be chosen: , , , .
In Algorithm 1, the
s are (for illustrative purposes) generated sequentially, one after the other; however, as will now be seen, they can also be generated in parallel. Based on the value of
and
, five random vectors
are generated:
and from them, five
s are calculated as their cumulative sums:
Suppose a prediction of
is sought, then the last subsequences based on these
s is:
By iterating the values of
k from 1 to 5 (
), the distances
between all
s and
are now calculated for each
. For simplicity, the Manhattan norm can be used again, obtaining the following results for
:
| 1 | 2 | 3 | 4 | 5 |
| 1.025334 | 1.013411 | 1.008642 | 1.011027 | 0.999104 |
| 0.052459 | 0.050074 | 0.114456 | 0.081073 | 0.090611 |
These results show that the minimum distance for this
is
, so
and the assumed best prediction is
. This procedure is repeated for all
s, and the best results from each are stored in
, which, in this example, would look like this:
| (2,4,5,8,11) | (1,2,4,5,6) | (3,4,7,8,10) | (3,6,9,12,13) | (2,4,7,10,13) |
| y | 1.013411 | 1.025334 | 1.025334 | 1.008642 | 1.013411 |
| 0.050074 | 0.057228 | 0.052459 | 0.054843 | 0.059612 |
Finally, the of the potential best results y (with the smallest ) is taken and the arithmetic mean is calculated, so, in this example, the final resulting prediction is .
4. Comparison
The time series of power energy consumption, shown in
Figure 2, was used to test the prediction using the RTDP method. To verify the competitiveness of this RTDP method, predictions of the same time series were also calculated using other common prediction methods.
Machine-learning methods such as extreme gradient boosting (XGB) [
5], k-nearest neighbor (KNN) [
6], random forest (RF) [
7], and artificial neural networks (ANN) [
8] were used. The latter was used with two parameter settings; one faster and one more accurate. Statistical methods are represented here by the probable best one: the auto-regressive integrated moving average (ARIMA) [
2] method, and in two parameter settings. For an interesting comparison, the zeroth algorithm method on which the RTDP prediction method is based was also added.
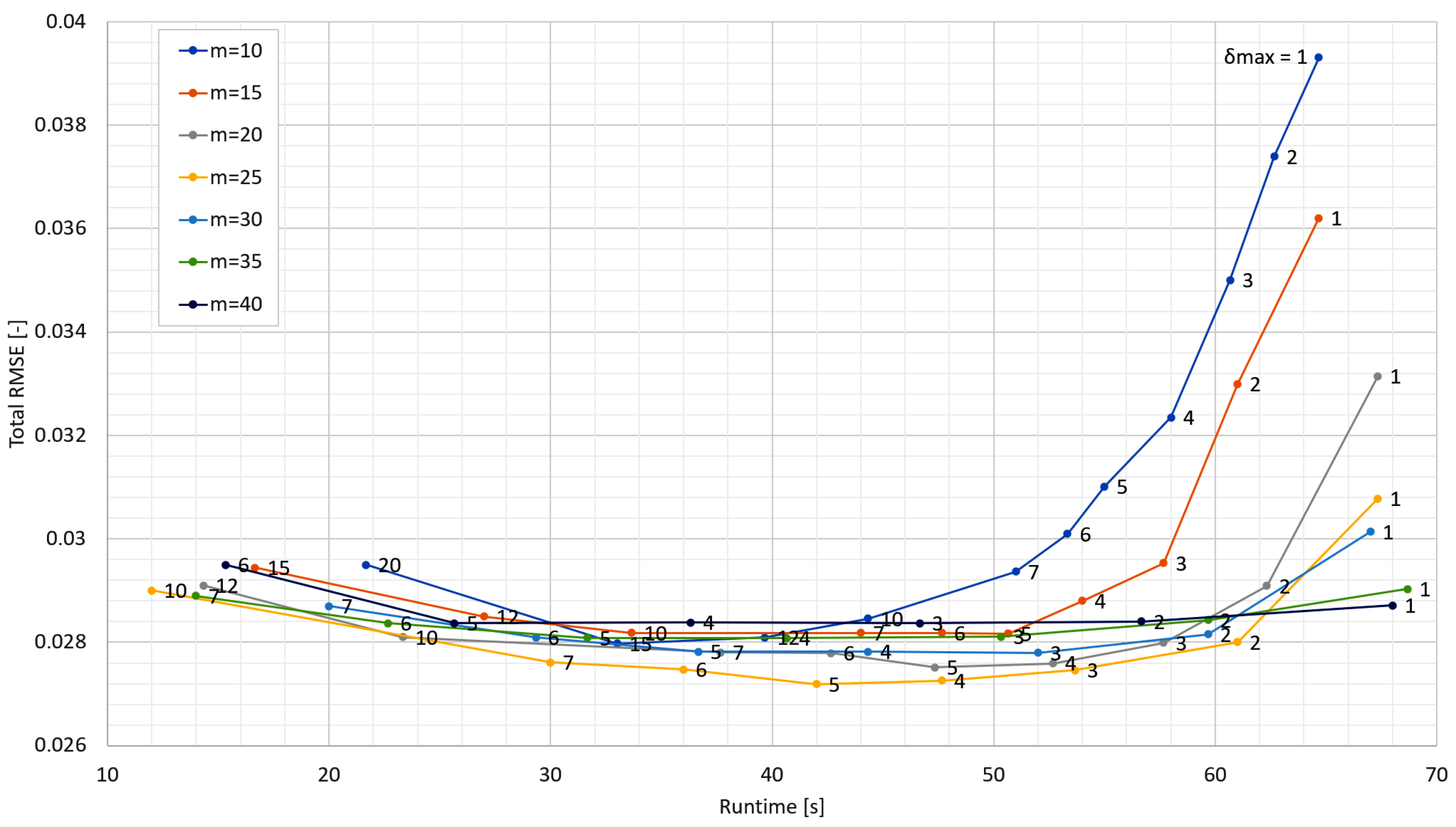
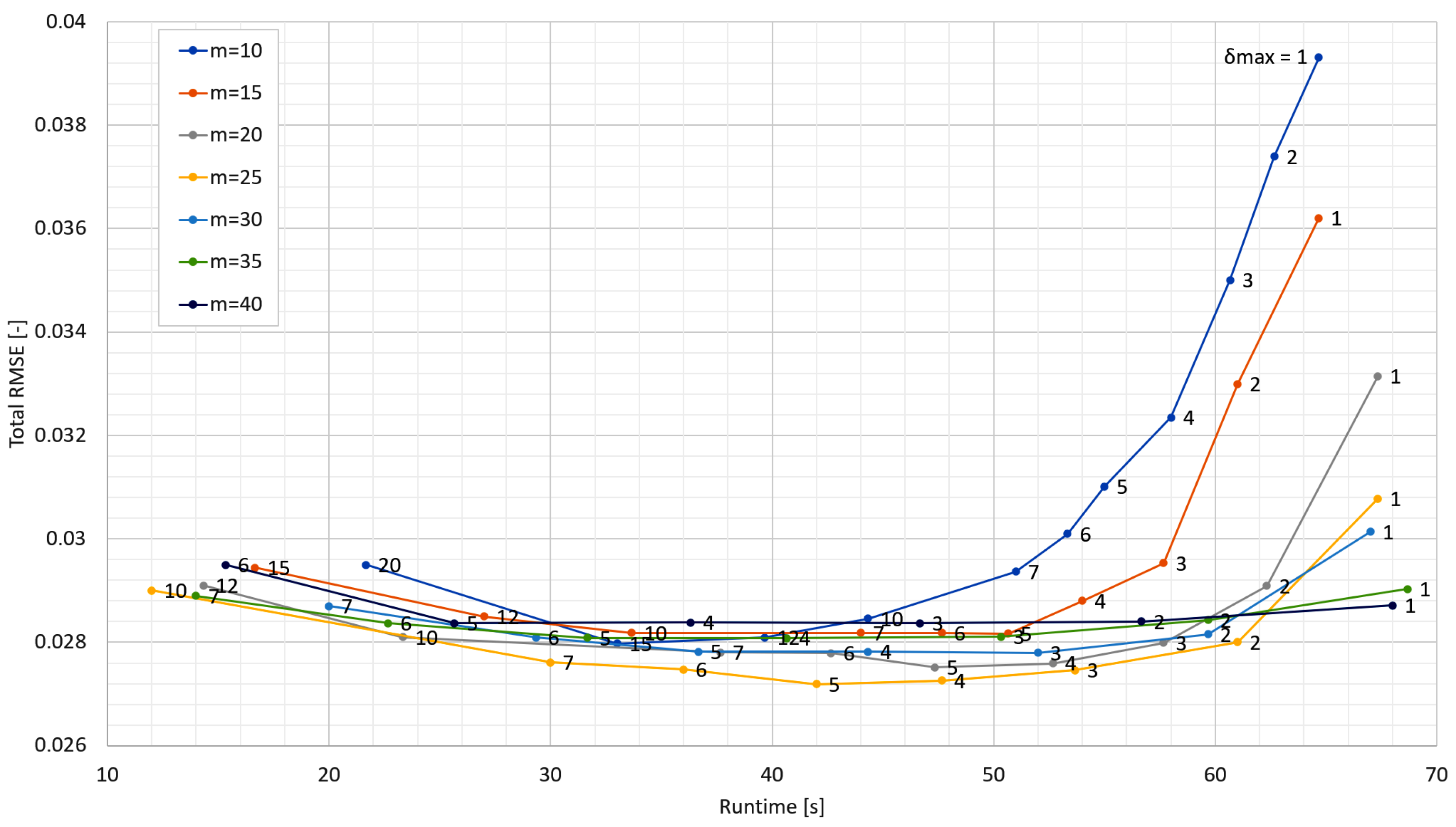
The parameters of the ARIMA(0,1,2) method were automatically determined by its auto.arima() function and the parameters of the ARIMA(8,1,6) method were determined by the recommended procedure using autocorrelation (ACF) and partial autocorrelation functions (PACF). The optimal parameter values used for all other methods were empirically located. For the RTDP method, this search is shown in
Figure 3.
Table 1 then summarizes the parameter values of all methods used in the comparison.
5. Results
For all methods, the same number of previous samples (341) was used to predict of the following value. A time window of 340 samples was created and each method attempted to predict the value of the 341st sample. By sliding this time window over the entire power energy consumption time series, the waveform of the prediction error for each method was obtained.
The sampling rate of the predicted time series used is one sample per minute, so 340 samples represent a timespan of more than 5 hours. Over such a long period of time, power consumption trends should already be sufficiently evident. Of course, by using a longer time window, the predictions could be more accurate, but for the purposes of this comparison, this level of accuracy is sufficient.
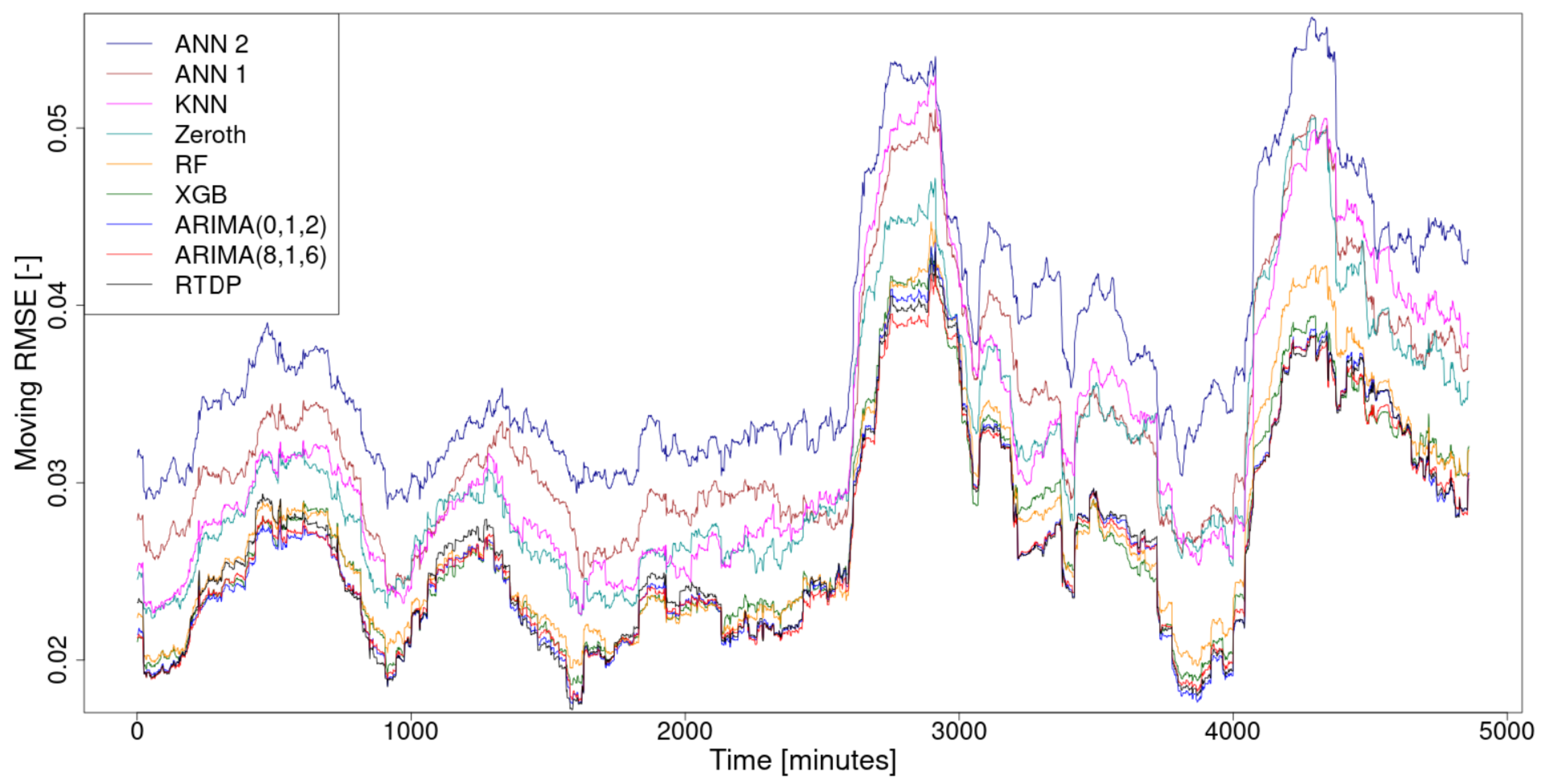
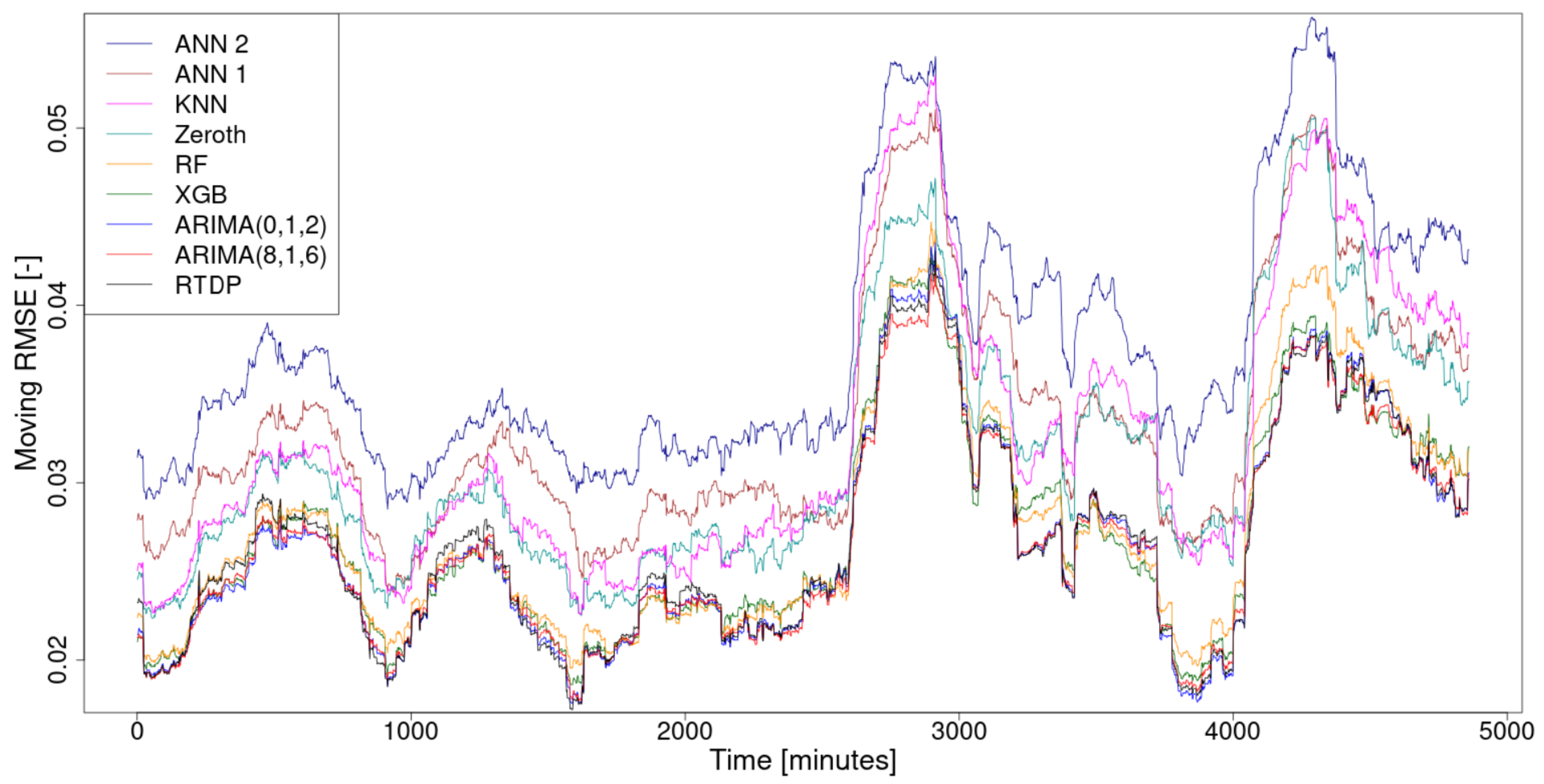
From the prediction error waveforms, the moving root mean square error (RMSE) waveforms, using a 300-sample-width moving window, were calculated for smoothing purposes and are shown in
Figure 4. For each method, the overall RMSE was also calculated from this prediction error waveform and a sorted summary of these total RMSEs is given in
Table 2.
The prediction calculations of the machine-learning methods were conducted using the software R [
9] package caret [
10] and the calculation of the statistical method predictions was conducted using R package forecast [
11].
In the case of the machine learning methods used (XGB, ANN, RF, KNN), the default resampling method of the caret software package was used to split the data into training and test sets. This is a bootstrapping method that builds a test set from 25% of the input data. Nonlinear and statistical methods (Zeroth, RTDP, ARIMA) do not use this partitioning in the training and test sets because they do not create a mathematical model that needs to be trained and then tested.
All calculations were performed on the same personal computer with an Intel Core i7-1065G7 processor (1.30–3.90 GHz) and 16 GB DDR4 RAM.
6. Conclusions and Future Work
In this paper, a new prediction method, named RTDP, was proposed. Using random time-delays patterns, this method tries to find important parts of the previous evolution of the time series and predicts its future evolution on this basis.
Its competitiveness was proved by comparing the accuracy of its prediction of the supercomputer infrastructure consumption time series with the accuracy of the prediction of the same time series when calculated with other commonly used prediction methods. The new RTDP method is based on the old and simple zeroth algorithm method and, thanks to the modifications, has gained in accuracy and lost a little in speed compared to the original method.
The comparison results, shown in
Figure 4 and summarized in
Table 2, show that the new RTDP method, when used to predict the evolution of supercomputer infrastructure consumption, was the most accurate and the second fastest. This is an excellent result, but to more comprehensively test this method, it will be necessary to perform this comparison on various types time series.
The development of the software package in which this method will be effectively implemented is another appropriate future work. The advantage of this method is its easy parallelizability, since calculations with individual s are independent of each other and can, therefore, run on different processor cores at the same time. It is reasonable to assume that the use of this feature will further speed up the method, which may also have an impact on its accuracy, as more s can be tried in the same amount of time.




{kind=link}
{kind=link}
{kind=link}
{kind=link}