1. Introduction
Let the following be a Fredholm Integral Equation (FIE) of the second kind:
where
is a Jacobi weight,
g and
k are known functions defined in
and
, respectively,
is a non zero real parameter and
f is the unknown function we want to look for. The kernel function
k is also allowed to be weakly singular along the diagonal
, or it could show some other pathologies such as high oscillating behaviour or a “nearly singular” factor. The nature of the kernel, with the presence of the Jacobi weight inside the integral, implies that the solution
f can have a singular behaviour at the endpoints of the definition interval (see for instance [
1,
2]); therefore, the natural choice is to study Equation (
1) in suitable spaces of weighted functions.
A high number of papers on the numerical methods for FIEs is disposable in the literature, and in the last two decades a deep attention was devoted, in the case under consideration, to the so-called “global approximation methods”. They are essentially based on polynomial approximation and use zeros of orthogonal polynomials (see for instance [
3,
4] and the references therein). There are also examples of global approximation methods based on equispaced points [
5], which are especially convenient when the data are available in discrete form but are limited to the unweighted case (see [
5,
6]). Global methods, more or less, behave as the best polynomial approximation of the solution in suitable spaces of weighted functions; consequently, this approximation strategy provides a powerful performance in the case of very smooth functions. On the other hand, these methods can converge slowly if the functions are not smooth or if the kernel has pathologies as described above.
Recently in [
4], a new method based on the collocation approach using the so-called Extended Interpolation was proposed in order to reduce the computational effort in the cases where the solution is not so smooth [
7]. Moreover the method delays the computation of high degree polynomial zeros that becomes progressively unstable as the degree increases.
Following a similar idea, we propose here a Mixed Nyström scheme based on product quadrature rules of the “extended” type, i.e., based on the zeros of the polynomial
, where
denotes the orthonormal sequence with respect to a suitable fixed Jacobi weight
w [
8]. The advantages of using a Nyström scheme with respect to a collocation one include several benefits. Indeed, first of all, we will use here only one sequence of orthonormal polynomials, while in the collocation method in [
4] two different sequences (
and
, where
) were required to obtain optimal Lebesgue constants of the interpolating operators. Secondly, due to its nature, the Nyström strategy with a fixed kernel provides a faster convergence with respect to the collocation approach if the right-hand side
g in (
1) is not so smooth. Third, a Nyström method based on a product rule allows treating kernel functions having different pathologies.
The idea of the proposed scheme is the following. Consider two sequences of Nyström interpolants and : The first is based on the product rule using the zeros of , and the second one is based on the extended product rule using the zeros of . Each step of the procedure consists in solving, for a fixed m, the first Nyström method and in using the coefficients defining the corresponding Nyström interpolant in order to “reduce” about one half of the computation of the coefficients of the Extended Nyström interpolant . In other words, we will assume that the two interpolants “coincide” on the zeros of . This assumption results in solving only a linear system of order instead of one of dimension in order to obtain an approximating function that is comparable with from the convergence point of view.
The outline of the paper is the following.
Section 2 contains preliminary notations and a collection of tools needed to introduce the main results stated in
Section 3. Here, we present an extended Nyström method, and the combined algorithm that allows us to solve Equation (
1) faster based on this. In
Section 4, we provide some computational details for the effective construction of the linear systems.
Section 5 concerns the numerical tests, while
Section 6 contains the proofs.
2. Notation and Preliminary Results
Throughout the paper, we use in order to denote a positive constant, which may have different values at different occurrences, and we write to mean that is independent of .
2.1. Function Spaces
Let
u be the Jacobi weight defined as follows:
We denote by
the Banach space of the locally continuous functions
f on
such that the following limit conditions are satisfied:
is equipped with the following norm:
The limit conditions (
2) are necessary in order to assure that the following is the case (see for instance [
9]):
where, denoted by
the space of all algebraic polynomials having degree at most
m, it is
the error of best polynomial approximation of
.
For smoother functions, we consider the following Sobolev-type subspaces of
of order
, defined as the following:
where
denotes the space of all the functions that are absolutely continuous on every closed subset of
, and
.
is equipped with the following norm:
Finally, by
, we denote the set of all measurable function
f defined in
such that the following is the case:
For any bivariate function , we will write (or ) in order to regard k as the univariate function in the only variable x (or y).
2.2. Solvability of the Equation (1) in
Let us set the following:
Equation (
1) can be rewritten in the following form:
where
I denotes the identity operator.
In order to provide the sufficient conditions assuring the compactness of the operator
, we need to recall the following definition. For any
and with
, in [
10], it was defined the following modulus of smoothness:
where
and the following is the case:
For any
, the modulus
is estimated by means of the following inequality (see for instance [
11], p. 314):
We are now able to state a theorem that guarantees the solvability of the Equation (
1) in the space
and for which its proof is given in
Section 6.
Theorem 1. Under the following assumptions, with and ,the operator is compact. Therefore, if , for any , Equation (1) admits a unique solution in . Remark 1. We observe that (4) is satisfied also when the kernel in (3) is weakly singular. For instance fulfils the assumption with (see ([11], Lemma 4.1, p. 322) and ([3], pp. 3–4)). 2.3. Product Integration Rules
Denoted by
, the system of the orthonormal polynomials with respect to the Jacobi weight
, the polynomial
is so defined:
Let
be the zeros of
and let the following:
be the Christoffel numbers with respect to
w.
For the following integral:
consider the following product integration rule:
where
According to a consolidated terminology, we will refer to the product integration rule in (
5) as
Ordinary Product Rule only to distinguish it from the extended product integration rule introduced below. Moreover, we recall that
are known as
Modified Moments [
12] (see, e.g., [
13]).
With respect to the stability and the convergence of the previous rule, the following result, useful for our aim, can be deduced by ([
9], p. 348) (see also [
14]).
Theorem 2. Under the following assumptions:for any we obtain the following bounds:andwith . In addition to the previous well-known product rule, we recall the following
Extended Product Rule (see [
8]) based on the zeros of
. Denoted by
the zeros of
, the extended formula is as follows: -4.6cm0cm
where
and
are known as the
Generalized Modified Moments (GMMs).
With respect to the stability and convergence of the extended quadrature rule (
8), we recall the following.
Theorem 3 ([
8], Theorem 3.2).
Under the following assumptions:for any , we obtain the following bounds:andwith . 2.4. A Nyström Method
In order to approximate the solution of (
1), we recall the following weighted Nyström method based on the product quadrature rule (
5). Introducing the sequence
where the following is the case:
we proceed to solve in
the following
finite dimensional equation in the unknown
:
By multiplying both sides of the previous equation by the weight function
u and collocating at the nodes
, we reach the following linear system of order
m in the unknowns
:
where
is defined in (
6).
By setting the following:
the system (
15) can be rewritten in the following matrix form:
Details on the matrix
will be given in
Section 4.
Once the solution
of the system (
16) has been determined, the
Ordinary Nyström interpolant takes the form:
About the convergence of this method, the following theorem can be obtained by using weighted arguments in [
15]:
Theorem 4. Under the assumptions of Theorems 1 and 2, for any , the finite dimensional Equation (14) admits a unique solution such that we have the following:with and . In what follows, we will refer to this Nyström method as the Ordinary Nyström Method (ONM).
3. Main Results
3.1. The Extended Nyström Method
Now, we introduce a Nyström method based on the extended product quadrature rule (
8), calling it the
Extended Nyström Method (ENM). Proceeding in analogy to the ONM, we begin by constructing the following sequence
:
Moreover, we solve in
the following
extended finite dimensional equation in the unknown
:
By multiplying both sides of (
19) by the weight function
u and collocating at the quadrature nodes
, we obtain the following linear system:
where the following is the case:
The coefficients
and
are defined in (
9)–(
10). The linear system of order
can be rewritten in the following more convenient block-matrix form:
with
and
. Details on the effective construction of the system will be provided in
Section 4.
Denoted by
, the vector solution of (
21), the
extended Nyström interpolant takes the following form:
With respect to the convergence, we are able to prove the following:
Theorem 5. Under the assumption of Theorems 1 and 3, for any , the finite dimensional Equation (19) admits a unique solution such that the following error estimate holds: 3.2. The Mixed Nyström Method
We observe that, under suitable assumptions, both sequences
and
uniformly converge to the solution
f of (
1). Thus, it makes sense to consider a mixed scheme that combines the two methods previously introduced.
Therefore, the Mixed Nyström Method (MNM) consists of two steps:
The mixed sequence of Nyström interpolants is obtained by iterating a couple of steps of the types (
24)–(
26), allowing us to obtain the following mixed sequence of Nyström interpolants:
Denoting by
the infinity norm of the matrix
, the uniform convergence of
to the solution
of (
1) is stated in the following:
Theorem 6. Under the assumptions of Theorems 1, 4, 5 and supposing that the matrix in (25) is invertible, with , for any , the sequence uniformly converges to , and the following error estimate holds: Remark 2. By comparing (23) with (28), both the sequences obtained by the extended and the mixed Nyström methods uniformly converge to with the same rate of convergence. By implementing the Mixed Nyström Method, we gain different advantages, specifically the reduction in the sizes of the involved linear systems.
More precisely, at each step of the mixed scheme, setting , we solve two systems of order m and . By doing so, the obtained error is comparable with that performed by solving the two systems of order m and by the Ordinary Nyström Method.
Therefore, the computational cost of the global procedure is strongly reduced. Indeed, if we compute the solution of the linear systems by Gaussian Elimination, we save 77.8% off long operations and 33.2% off function evaluations.
Furthermore, the difficulties in the evaluation of the modified moments for “large” degree are delayed, as well as the instability in the construction of Jacobi polynomial zeros of high degrees by the Golub–Welsh algorithm.
4. Computational Details
Given two integers
, in this section, we use the short notation
to denote the set
Denoting by
the identity matrix of order
m, the matrix of the linear system (
16) takes the following form:
with
It is well known that the system (
16) and the finite dimensional Equation (
14) are equivalent (see for instance ([
16], Theorem 12.7, p. 202)).
About the block-matrix of the system (
21), according to the previously introduced matrices, we have the following:
where
and the matrices
,
,
and
are as follows:
Remark 3. The entries of the matrices in (29) require the computation of the GMMs. As usual, the ordinary Modified Moments (MMs), which depend on the specific kernel we considered, are often derived by suitable recurrence relations (see, e.g., [13]). In [8] a general scheme for deriving GMMs starting from MMs was proposed. Alternatively, for very smooth kernels, Gaussian rules can be also used. In any case, the global algorithm can be organized in such a manner that the matrices in (29), requiring the most expensive computation effort, can be performed once for a given couple . 5. Numerical Experiments
Now we propose some tests showing the numerical results that were obtained by approximating the solution of equations of the type (
1) by the mixed sequence
in (
27). We will compare the results with those attained by the corresponding ordinary sequence used in the standard method and in Example 2 also with those achieved by the mixed collocation method proposed in [
4]. Indeed, in this test, the kernel is moderately smooth, and the convergence conditions of both methods are satisfied.
We have selected g possessing different regularities and kernels k presenting some kinds of drawback such as a contemporary high oscillating behaviour with a “near” singular fixed point or being weakly singular. In each test, we will report either the common weight w used in the construction of the quadrature formulae and the weight u defining the space to which f belongs.
For effective comparison between the ordinary and the extended sequences on the same number of nodes, we have considered the following sequences:
Since the solution
f is unknown, we retain the exact values attained by the approximating function
, for sufficiently large
N. We remark that
turns out to be a suitable choice for the functions under consideration. In the tables, for increasing
n, we will report the weighted maximum error attained by
and
at the set
,
of equally spaced points of
by setting
In each table, first and third columns contain the size of the ordinary system (o.l.s.) and its condition number
related to the ordinary sequence. In the fourth and sixth columns, the sizes of the couple of linear systems of the mixed scheme (m.l.s.) and the condition number
of the “reduced” system (
25) are reported. All the condition numbers have been computed with respect to the infinity norm.
Finally, in order to contain possible moderate loss of accuracy in computing GMMs, we have carried out their construction by using the software Wolfram Mathematica 12.1 in quadruple precision. All the other computations have been performed in double-machine precision 2.220446049250313e-16.
Example 1. Let us consider the following equation:In this case and according to Theorem 6, which holds since all the assumptions are satisfied, the errors are , and the numerical results reported in Table 1 are even better. All the linear systems are well conditioned, the ordinary condition numbers being slightly smaller than the mixed ones. The weighted absolute errors by ONM and MNM are displayed in Figure 1. Example 2. Let us consider the following equation:In Table 2 and Table 3 we report the results achieved by the mixed and ordinary Nyström methods and those obtained by the mixed and ordinary collocation methods in [4]. Indeed, the assumptions assuring stability and convergence for all the methods are satisfied; hence, the comparison makes sense. We denote by and the weighted maximum error attained by the Ordinary Collocation Method (OCM) and the Mixed Collocation Method (MCM) in [4] at the set , of equally spaced points of , respectively. The results show that both the Nyström methods behave better than the collocation ones, and this is quite common in cases such as the one under consideration. Indeed, even if the solution (since ), the rate of convergence of the collocation approach depends on both the approximations of the integral operator and the right-hand side. On the contrary, the order of convergence of the Nyström method depends essentially on the smoothness of the kernel. This is one of the reasons why in these cases the Nyström approach produces better results than the collocation one, as also announced in the Introduction.
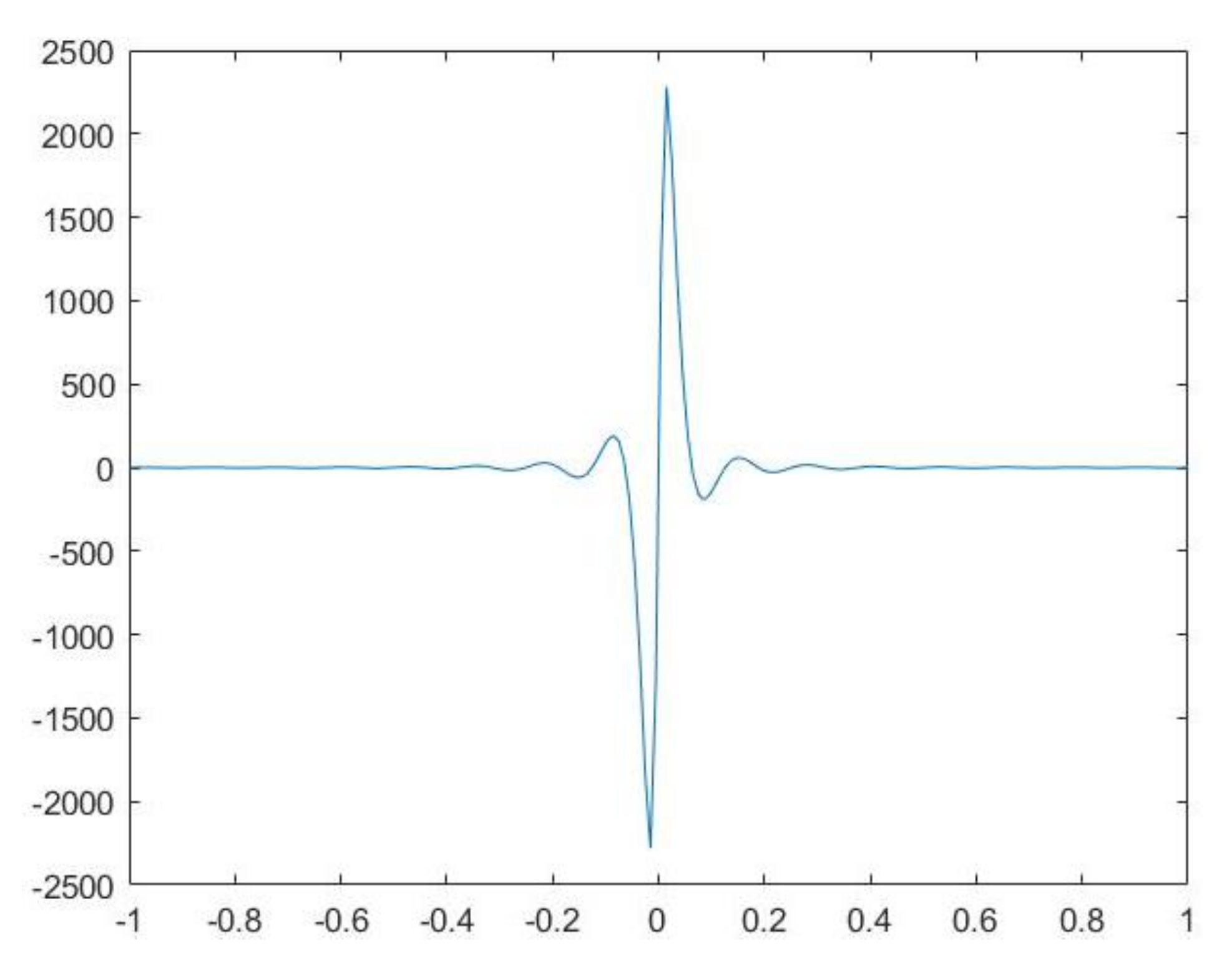
Example 3. Let us consider the following equation:In this test, the kernel presents a fast oscillating behaviour. Its graphic is reported in Figure 2. Hence, the product formula allows us to overcome the drawbacks deriving from the use of the Gauss–Jacobi rule. About the rate of convergence, since , we expect that the errors are . We have reported the values attained by ONM and MNM in three different points of the interval (Table 4) and the maximum errors on the entire interval (Table 5). In all the cases the theoretical estimates are attained. Moreover, in both methods the condition numbers of the linear systems are comparable. Example 4. Let us consider the following equation:In this case, ρ and u satisfy the assumptions for the convergence of the Nyström methods, while they do not satisfy those of the collocation methods [4]. We recall that for the convergence of both the collocation methods smoother kernels and more restrictive assumptions on the weights are required. About the rate of convergence, since , we expect that the errors are . Moreover, we have chosen this test to propose a comparison with the Nyström method obtained by approximating the coefficients in (5) by Gaussian rules. We will refer to this procedure as the Ordinary Nyström method by Gaussian rule
(shortly, ONG). We point out that the nature of the kernel k makes this comparison possible, since the computation of the coefficients by the Gauss–Jacobi rule can be performed. Thus, in Table 6, in addition to the results by the mixed and ordinary Nyström methods, in the last two columns, we will set the maximum weighted errors attained by the ONG at the same set of nodes , and the condition numbers of the corresponding linear systems. They will be shortly denoted as and , respectively. The results by ONM and MNM are slightly better than the expected accuracy, and the condition numbers of the mixed linear systems are a little bit lower than their ordinary counterparts. With respect to the ONG method, as we can observe, the errors result as stagnant. Example 5. Let us consider the following equation:This test deals with a kernel that is a product of a periodic function having high frequency and multiplied by a “nearly” singular function. Such kernels, treated in the bidimensional case in [17], appear for instance in the solution of problems of propagation in uniform wave-guides with non-perfect conductors [18]. The graphic of the kernel is given in Figure 3. With respect to the results of the equation, since , a very fast convergence is expected, and this is confirmed also by the numerical results reported in Table 7. The mixed condition numbers are significantly smaller than the ordinary ones. The graphic of the weighted solution is provided in Figure 4. 7. Conclusions
In this research, we have proposed a global Nyström method involving ordinary and extended product integration rules, both based on Jacobi zeros. For the nature of the method, we can handle FIE with kernels presenting some kind of pathological behaviours since the coefficients of the rules are exactly computed via recurrence relations. The method employs two different discrete sequences, namely the ordinary and the extended sequences, that are suitably mixed to strongly reduce the computational effort required by the ordinary Nyström method. Advantages are achieved with respect to the mixed collocation method in [
4] from different points of view that can be summarised as follows: we can treat FIEs as having less regular kernels and under wider assumptions in order to obtain a better rate of convergence. Such improvements have been shown by means of some numerical tests. In particular, Example 2 evidences how the mixed Nyström method provides a better performance than the mixed collocation one in [
4]. Furthermore, Example 4 shows how the assumptions of the mixed Nyström method are wider than those of the above mentioned mixed collocation one. Both methods allow us to reduce the sizes of the involved linear systems but require the computation of Modified and Generalized Modified Moments. In any case, once the kernel
k and the order
m are given, the algorithm can be organized pre-computing the matrix of the system. Moreover, once Modified Moments are given, Generalized Modified Moments can be always deduced by a suitable recurrence relation (see, e.g., [
8]). Therefore, the global process has a general applicability and only requires the assumptions of convergence to be satisfied. With respect to the Modified Moments, they can be computed through recurrence relations (see, e.g., [
13]). However, when these relations are unstable, Modified Moments can be accurately computed by suitable numerical methods. For instance, in the case of high oscillating or nearly singular kernels, this approach has been successfully tried by implementing “dilation” techniques [
20,
21]. The major cost represents a well known limit of the classical Nyström methods based on product integration rules. They are more expensive since the coefficients of the rule possessing many and different pathological kernels have to be “exactly” computed. On the other hand, this major effort is amply repaid by the better performance with respect to other cheaper procedures. Finally, establishing that the convergence conditions are also necessary is still an open problem. This will be a subject for further investigations.










{kind=link}
{kind=link}
{kind=link}
{kind=link}