
On K-Means Clustering with IVIF Datasets for Post-COVID-19 Recovery Efforts

 ,
,  , ,
, , 
Abstract
:1. Introduction
2. Literature Review
3. Preliminaries
3.1. Fuzzy Set Theory
3.2. Intuitionistic Fuzzy Set Theory
- (i)
- If, then
- (ii)
- If, then:
- If, then
- If, then
3.3. K-Means Clustering
4. Proposed Procedure: The Application of K-Means Clustering Based on IVIF Datasets
4.1. Case Study 1: Clustering Tourist Sites for Perceived COVID-19 Exposure
4.2. Case Study 2: Clustering Restaurants for Perceived COVID-19 Exposure
5. Comparative and Sensitivity Analysis
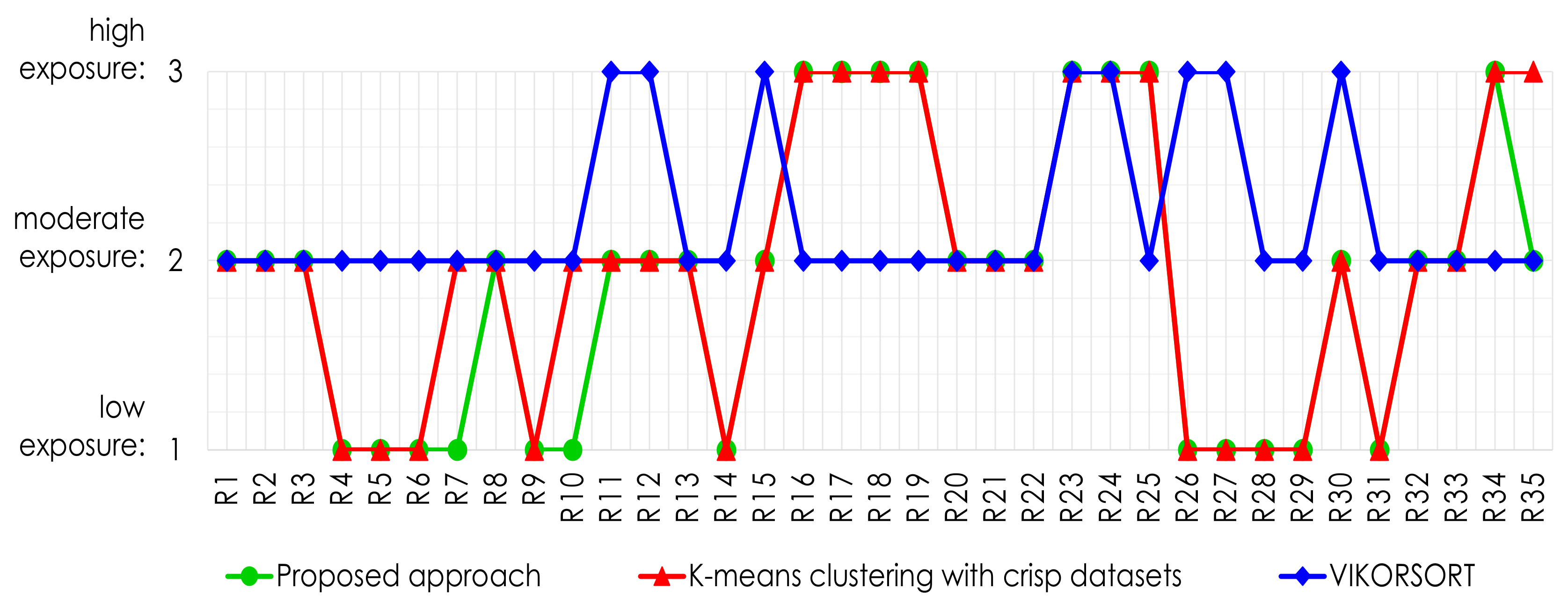
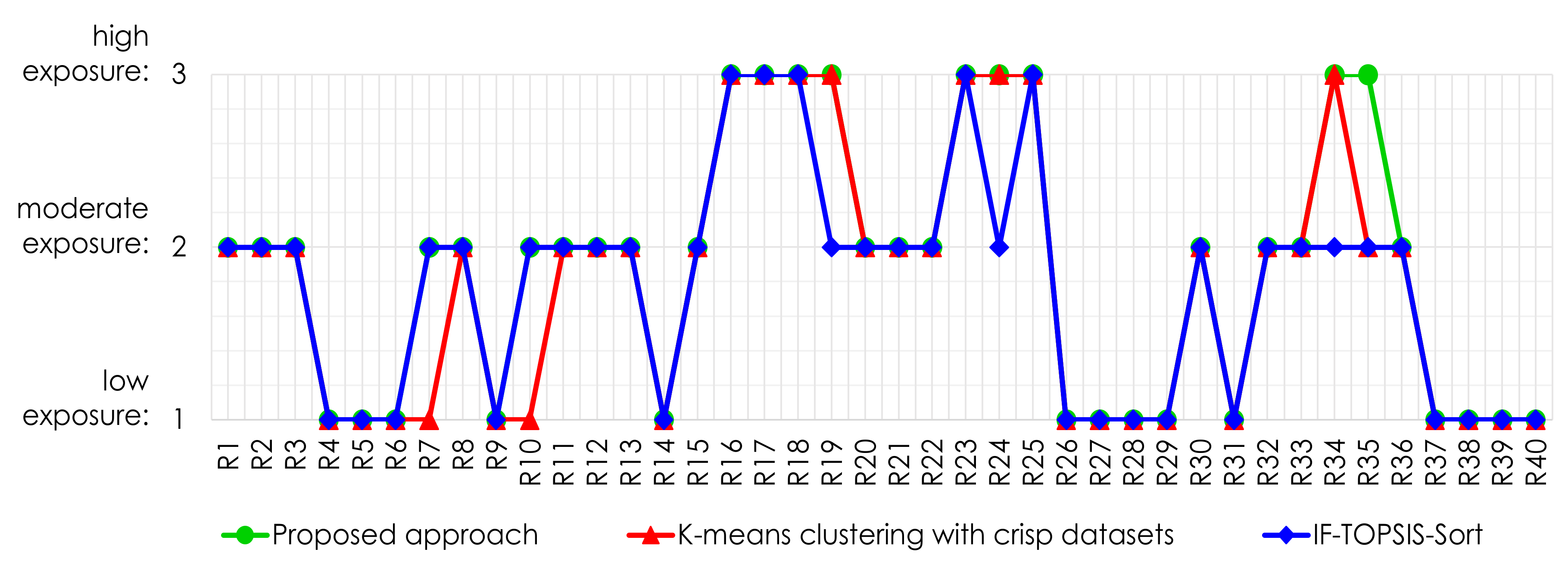
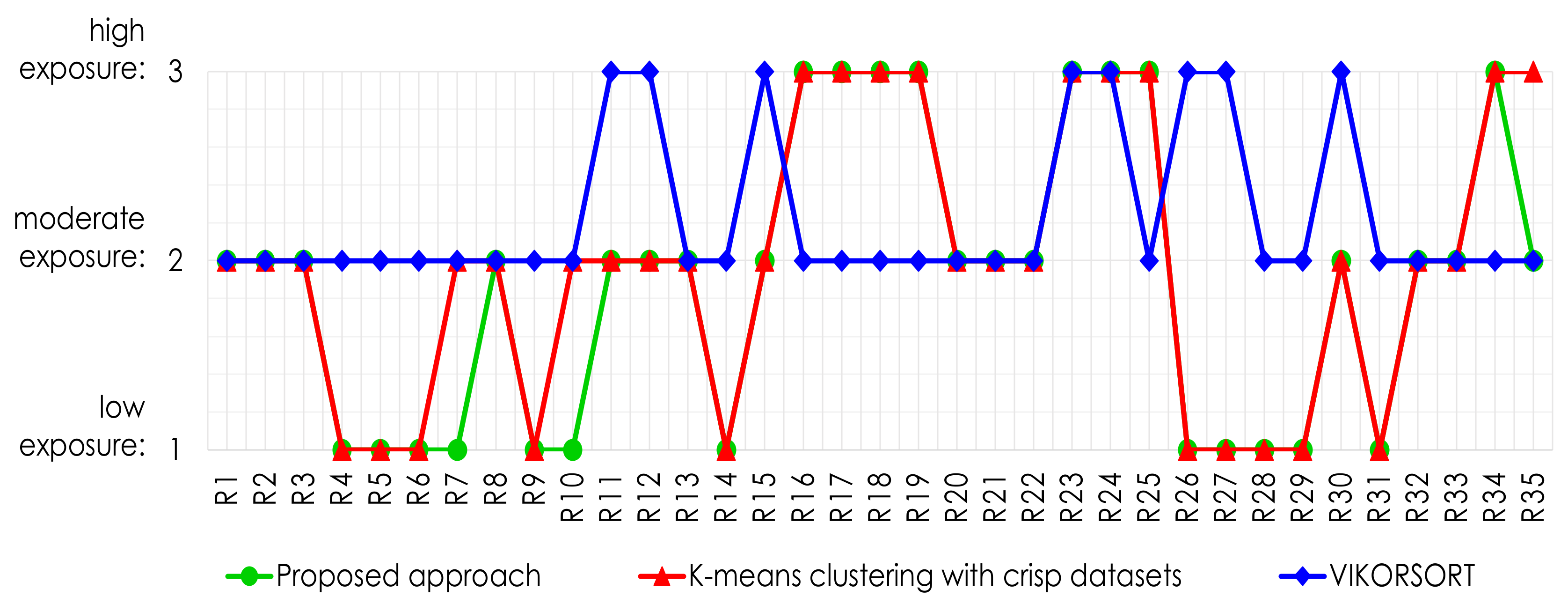
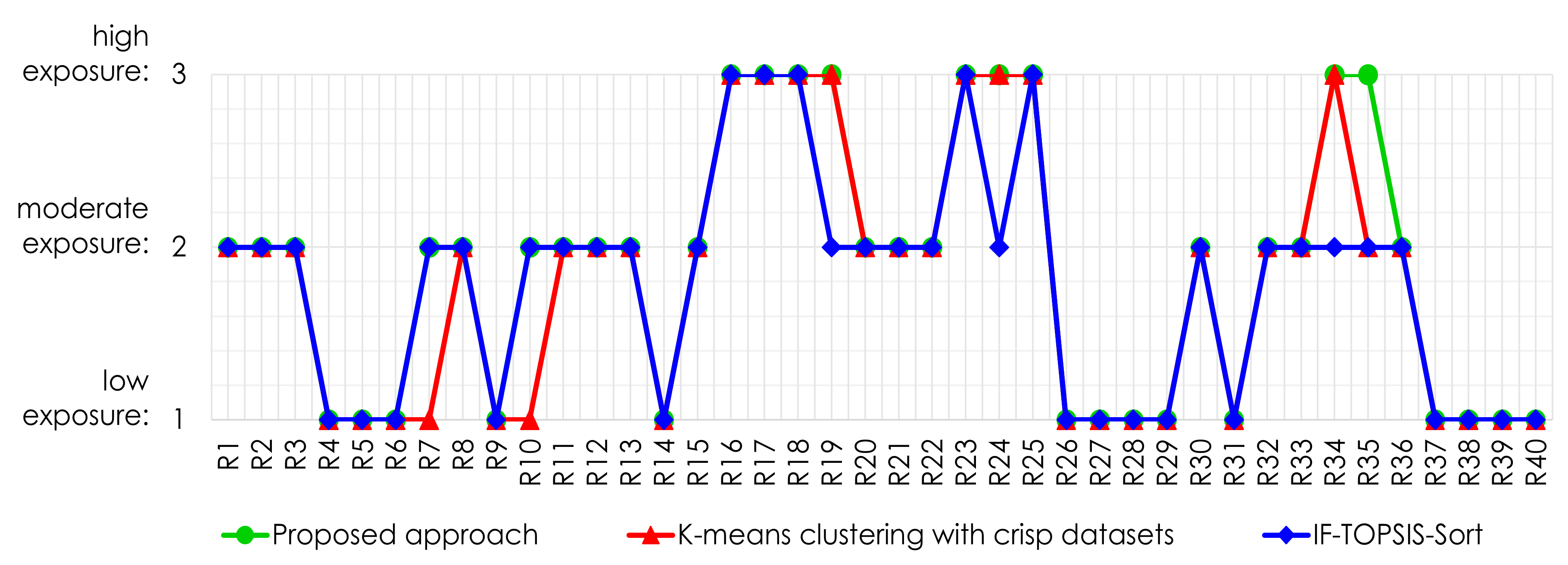
5.1. Comparative Analysis
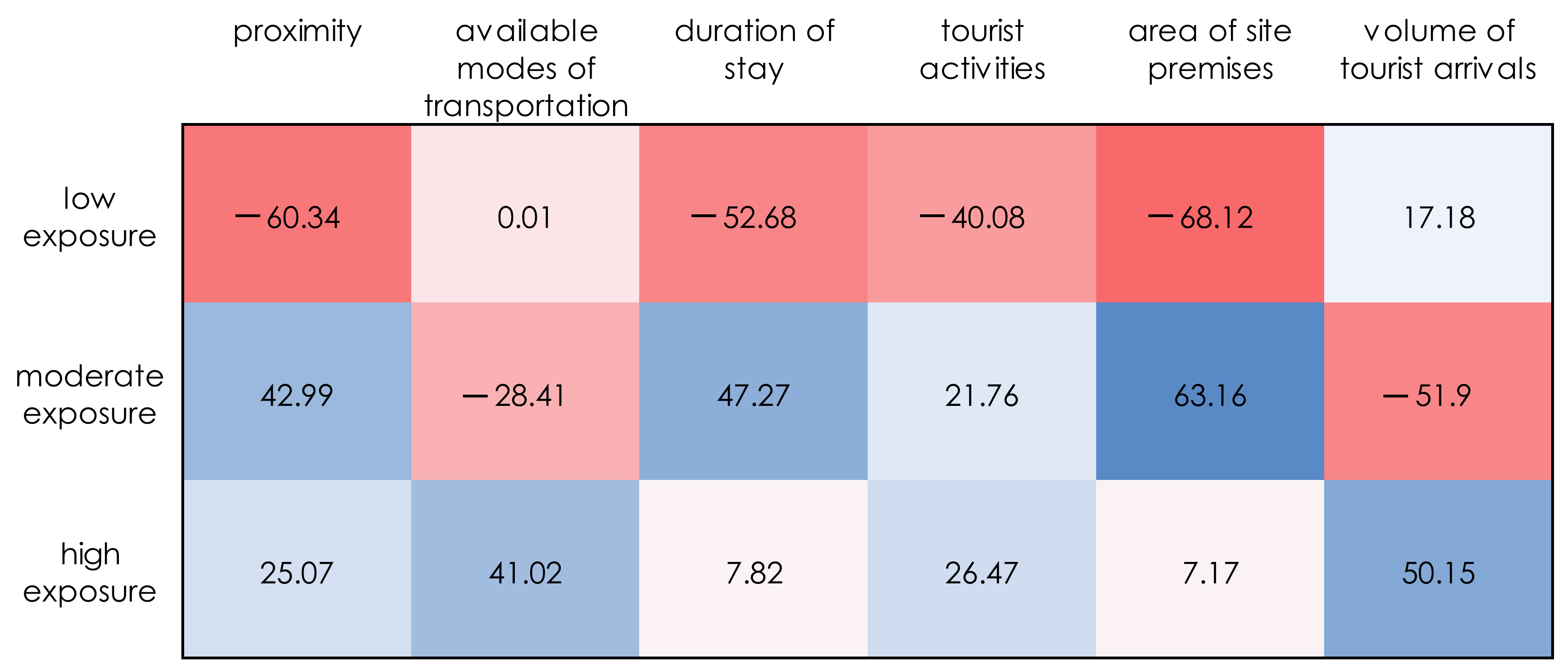
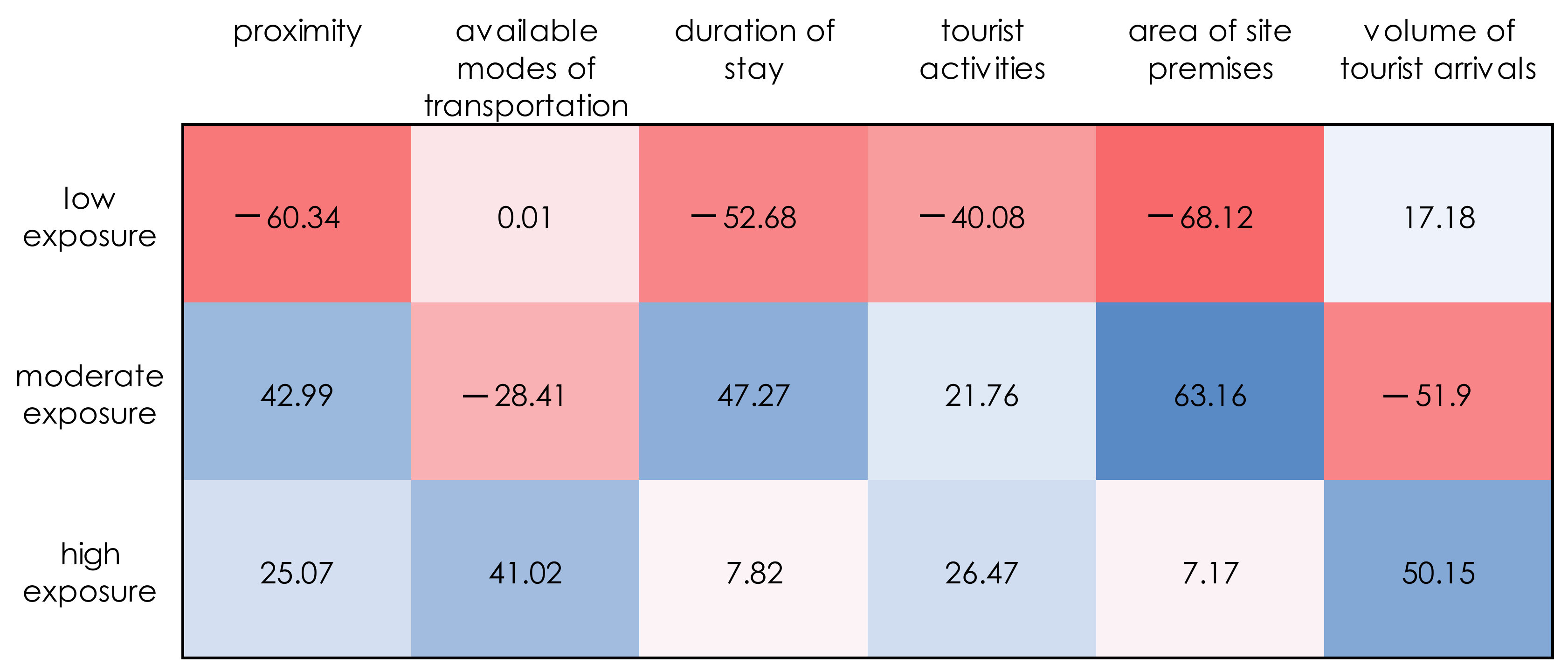
Case Study 1: Tourist Sites
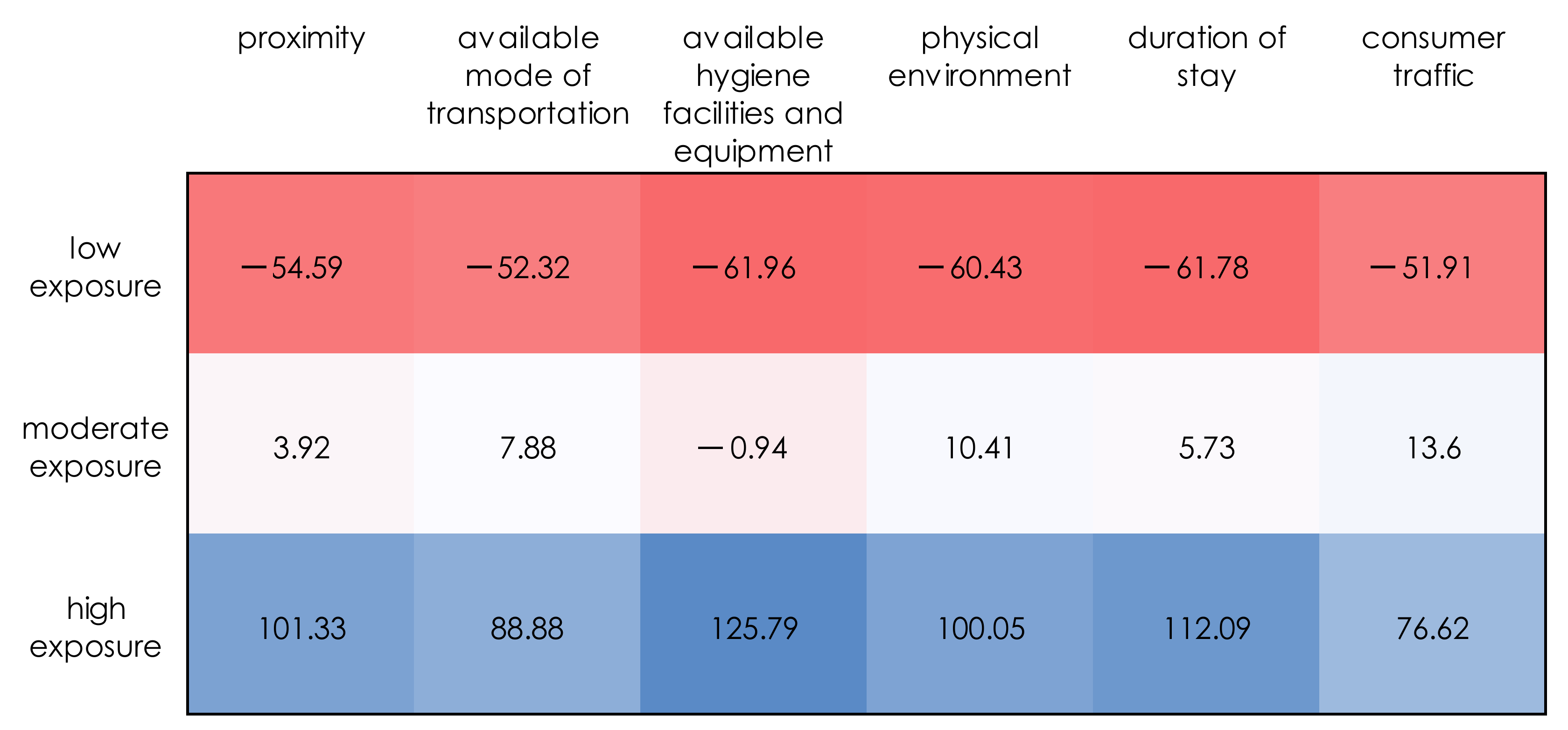
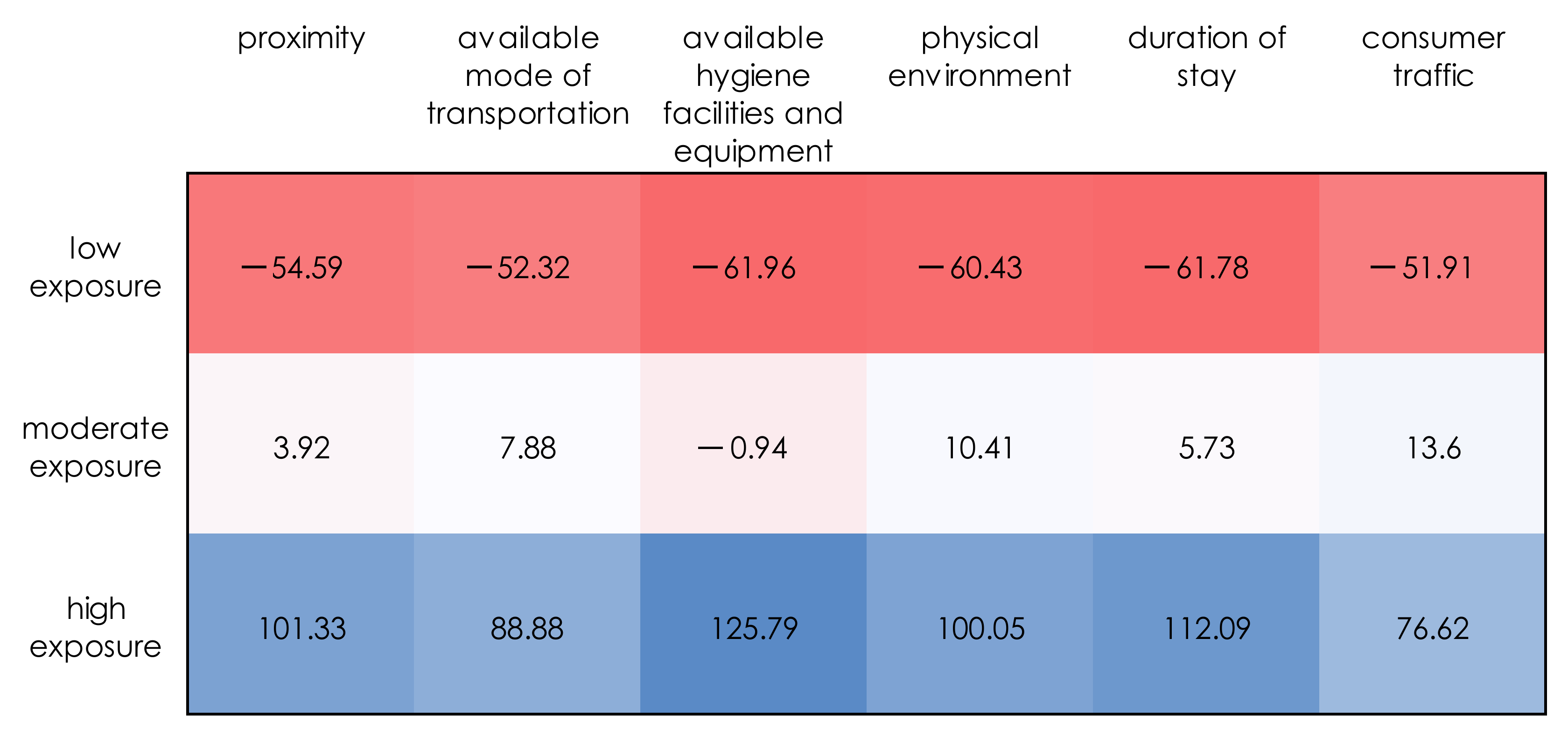
Case Study 2: Restaurants
5.2. Sensitivity Analysis
6. Discussion
7. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dryhurst, S.; Schneider, C.R.; Kerr, J.; Freeman, A.L.J.; Recchia, G.; van der Bles, A.M.; Spiegelhalter, D.; van der Linden, S. Risk perceptions of COVID-19 around the world. J. Risk Res. 2020, 23, 994–1006. [Google Scholar] [CrossRef]
- Yamagishi, K.; Ocampo, L. Utilizing TOPSIS-Sort for sorting tourist sites for perceived COVID-19 exposure. Curr. Issues Tour. 2021, 1–11. [Google Scholar] [CrossRef]
- Ocampo, L.; Yamagishi, K. Multiple criteria sorting of tourist sites for perceived COVID-19 exposure: The use of VIKORSORT. Kybernetes 2021. [Google Scholar] [CrossRef]
- Ocampo, L.; Tanaid, R.A.; Tiu, A.M.; Selerio, E., Jr.; Yamagishi, K. Classifying the degree of exposure of customers to COVID-19 in the restaurant industry: A novel intuitionistic fuzzy set extension of the TOPSIS-Sort. Appl. Soft Comput. 2021, 113, 107906. [Google Scholar] [CrossRef]
- Cong, L.; Ding, S.; Wang, L.; Zhang, A.; Jia, W. Image segmentation algorithm based on superpixel clustering. IET Image Process. 2018, 12, 2030–2035. [Google Scholar] [CrossRef]
- Hossain, Z.; Akhtar, N.; Ahmad, R.; Rahman, M. A dynamic K-means clustering for data mining. Indones. J. Electr. Eng. Comput. Sci. 2019, 13, 521–526. [Google Scholar] [CrossRef]
- Wen, L.; Zhou, K.; Yang, S. A shape-based clustering method for pattern recognition of residential electricity consumption. J. Clean. Prod. 2019, 212, 475–488. [Google Scholar] [CrossRef]
- Shi, W.; Zeng, W. Application of k-means clustering to environmental risk zoning of the chemical industrial area. Front. Environ. Sci. Eng. 2014, 8, 117–127. [Google Scholar] [CrossRef]
- Kuswandi, D.; Surahman, E.; Thaariq, Z.Z.A.; Muthmainnah, M. K-Means Clustering of Student Perceptions on Project-Based Learning Model Application. In Proceedings of the 2018 4th International Conference on Education and Technology (ICET), Malang, Indonesia, 26–28 October 2018; IEEE: Manhattan, NY, USA, 2018; pp. 9–12. [Google Scholar]
- Khanmohammadi, S.; Adibeig, N.; Shanehbandy, S. An improved overlapping k-means clustering method for medical applications. Expert Syst. Appl. 2017, 67, 12–18. [Google Scholar] [CrossRef]
- Pustokhina, I.V.; Pustokhin, D.A.; Rodrigues, J.J.P.C.; Gupta, D.; Khanna, A.; Shankar, K.; Seo, C.; Joshi, G.P. Automatic Vehicle License Plate Recognition Using Optimal K-Means with Convolutional Neural Network for Intelligent Transportation Systems. IEEE Access 2020, 8, 92907–92917. [Google Scholar] [CrossRef]
- Rani, S.; Kholidah, K.N.; Huda, S.N. A Development of Travel Itinerary Planning Application using Traveling Salesman Problem and K-Means Clustering Approach. In Proceedings of the 2018 7th International Conference on Software and Computer Applications, Kuantan, Malaysia, 8–10 February 2018; ACM: New York, NY, USA, 2018; pp. 327–331. [Google Scholar]
- Monica, S.; Natalia, F.; Sudirman, S. Clustering Tourism Object in Bali Province Using K-Means and X-Means Clustering Algorithm. In 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS); IEEE: Manhattan, NY, USA, 2018; pp. 1462–1467. [Google Scholar]
- Yang, H.; Luo, J.-D.; Fan, Y.; Zhu, L. Using weighted k-means to identify Chinese leading venture capital firms incorporating with centrality measures. Inf. Process. Manag. 2020, 57, 102083. [Google Scholar] [CrossRef]
- Mahmoudi, A.; Deng, X.; Javed, S.A.; Yuan, J. Large-scale multiple criteria decision-making with missing values: Project selection through TOPSIS-OPA. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9341–9362. [Google Scholar] [CrossRef]
- Park, J.H.; Park, I.Y.; Kwun, Y.C.; Tan, X. Extension of the TOPSIS method for decision making problems under interval-valued intuitionistic fuzzy environment. Appl. Math. Model. 2011, 35, 2544–2556. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 3, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Ngan, R.T.; Son, L.H.; Ali, M.; Tamir, D.E.; Rishe, N.D.; Kandel, A. Representing complex intuitionistic fuzzy set by quaternion numbers and applications to decision making. Appl. Soft Comput. 2020, 87, 105961. [Google Scholar] [CrossRef]
- Atanassov, K.; Gargov, G. Interval valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 1989, 31, 343–349. [Google Scholar] [CrossRef]
- Hu, K.; Tan, Q.; Zhang, T.; Wang, S. Assessing technology portfolios of clean energy-driven desalination-irrigation systems with interval-valued intuitionistic fuzzy sets. Renew. Sustain. Energy Rev. 2020, 132, 109950. [Google Scholar] [CrossRef]
- Luo, M.; Liang, J. A Novel Similarity Measure for Interval-Valued Intuitionistic Fuzzy Sets and Its Applications. Symmetry 2018, 10, 441. [Google Scholar] [CrossRef] [Green Version]
- Ananthi, V.; Balasubramaniam, P. A new image denoising method using interval-valued intuitionistic fuzzy sets for the removal of impulse noise. Signal. Process. 2016, 121, 81–93. [Google Scholar] [CrossRef]
- Oztaysi, B.; Onar, S.C.; Kahraman, C.; Yavuz, M. Multi-criteria alternative-fuel technology selection using interval-valued intuitionistic fuzzy sets. Transp. Res. Part D Transp. Environ. 2017, 53, 128–148. [Google Scholar] [CrossRef]
- Wu, L.; Wei, G.; Gao, H.; Wei, Y. Some Interval-Valued Intuitionistic Fuzzy Dombi Hamy Mean Operators and Their Application for Evaluating the Elderly Tourism Service Quality in Tourism Destination. Mathematics 2018, 6, 294. [Google Scholar] [CrossRef] [Green Version]
- Cheng, S.-H. Autocratic multiattribute group decision making for hotel location selection based on interval-valued intuitionistic fuzzy sets. Inf. Sci. 2018, 427, 77–87. [Google Scholar] [CrossRef]
- Kaur, S.P.; Gupta, V. COVID-19 Vaccine: A comprehensive status report. Virus Res. 2020, 288, 198114. [Google Scholar] [CrossRef]
- Abu Bakar, N.; Rosbi, S. Effect of Coronavirus disease (COVID-19) to tourism industry. Int. J. Adv. Eng. Res. Sci. 2020, 7, 189–193. [Google Scholar] [CrossRef] [Green Version]
- John Hopkins Coronavirus Resource Center. COVID-19 Dashboard by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU). Available online: https://coronavirus.jhu.edu/map.html (accessed on 31 July 2021).
- Davahli, M.R.; Karwowski, W.; Sonmez, S.; Apostolopoulos, Y. The Hospitality Industry in the Face of the COVID-19 Pandemic: Current Topics and Research Methods. Int. J. Environ. Res. Public Health 2020, 17, 7366. [Google Scholar] [CrossRef]
- Organization for Economic Co-Operation and Development. Tourism Policy Responses to Coronavirus (COVID-19). 2020. Available online: https://www.oecd.org/coronavirus/policy-responses/tourism-policy-responses-to-the-coronavirus-covid-19-6466aa20/ (accessed on 2 August 2021).
- World Travel & Tourism Council (WTTC). Economic Impact Reports. World Travel & Tourism Council. 2021. Available online: https://wttc.org/Research/Economic-Impact (accessed on 30 July 2021).
- Zhang, H.; Cho, T.; Wang, H. The Impact of a Terminal High Altitude Area Defense Incident on Tourism Risk Perception and Attitude Change of Chinese Tourists Traveling to South Korea. Sustainability 2020, 12, 7. [Google Scholar] [CrossRef] [Green Version]
- Philippine Statistics Authority. Share of Tourism to GDP is 5.4 Percent in 2020. 2021. Available online: https://psa.gov.ph/tourism/satellite-accounts/id/164617 (accessed on 27 July 2021).
- Asian Development Bank. The COVID-19 Impact on Philippine Business. June 2020. Available online: https://www.adb.org/sites/default/files/publication/622161/covid-19-impact-philippine-business-enterprise-survey.pdf (accessed on 25 July 2021).
- Philippine Statistics Authority. Philippine GDP Posts -8.3 Percent in the Fourth Quarter 2020; -9.5 Percent for Full-Year 2020. Available online: https://psa.gov.ph/content/philippine-gdp-posts-83-percent-fourth-quarter-2020-95-percent-full-year-2020 (accessed on 28 January 2021).
- Philippine Statistics Authority. Employed Persons by Sector, Subsector, and Hours Worked, Philippines. 2021. Available online: https://psa.gov.ph/system/files/Table%202-Employed%20Persons%20by%20Sector%2C%20Sub-sector%20and%20Hours%20Worked%2C%20Philippines%2C%20February%202021%2C%20March%202021%2C%20April%202021%20and%20May%202021_0.xlsx (accessed on 26 July 2021).
- Kaushal, V.; Srivastava, S. Hospitality and tourism industry amid COVID-19 pandemic: Perspectives on challenges and learnings from India. Int. J. Hosp. Manag. 2021, 92, 102707. [Google Scholar] [CrossRef] [PubMed]
- Dube, K.; Nhamo, G.; Chikodzi, D. COVID-19 cripples global restaurant and hospitality industry. Curr. Issues Tour. 2021, 24, 1487–1490. [Google Scholar] [CrossRef]
- United Nations World Tourism Organization (UNWTO). UNWTO Launches a Call for Action for Tourism’s COVID-19 Mitigation and Recovery. 2020. Available online: https://www.unwto.org/news/unwto-launches-a-call-for-action-for-tourisms-covid-19-mitigation-and-recovery (accessed on 30 July 2021).
- World Health Organization. WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 28 July 2021).
- Gursoy, D.; Can, A.S.; Williams, N.; Ekinci, Y. Evolving impacts of COVID-19 vaccination intentions on travel intentions. Serv. Ind. J. 2021, 41, 719–733. [Google Scholar] [CrossRef]
- Buhat, C.A.H.; Duero, J.C.C.; Felix, F.O.; Rabajante, J.F.; Mamplata, J.B. Optimal Allocation of COVID-19 Test Kits Among Accredited Testing Centers in the Philippines. J. Heal. Inform. Res. 2021, 5, 54–69. [Google Scholar] [CrossRef]
- Gursoy, D.; Chi, C.G.; Chi, O.H. Effects of COVID 19 pandemic on restaurant and hotel customers’ sentiments towards dining out, traveling to a destination and staying at hotels. J. Hosp. 2021, 3, 1–17. [Google Scholar]
- Hafeez, S.; Din, M.; Zia, F.; Ali, M.; Shinwari, Z.K. Emerging concerns regarding COVID-19; second wave and new variant. J. Med. Virol. 2021, 93, 4108. [Google Scholar] [CrossRef] [PubMed]
- Padhi, A.K.; Tripathi, T. Can SARS-CoV-2 accumulate mutations in the S-protein to increase pathogenicity? ACS Pharmacol. Transl. Sci. 2020, 3, 1023–1026. [Google Scholar] [CrossRef] [PubMed]
- Šostaks, A. Mathematics in the context of fuzzy sets: Basic ideas, concepts, and some remarks on the history and recent trends of development. Math. Model. Anal. 2011, 16, 173–198. [Google Scholar] [CrossRef]
- Atanassov, K.T. Interval valued intuitionistic fuzzy sets. In Intuitionistic Fuzzy Sets; Physical: Heidelberg, Germany, 1999; pp. 139–177. [Google Scholar]
- Xu, Z. Methods for aggregating interval-valued intuitionistic fuzzy information and their application to decision making. Control. Decis. 2007, 22, 215–219. [Google Scholar]
- Xu, Z. A method based on distance measure for interval-valued intuitionistic fuzzy group decision making. Inf. Sci. 2010, 180, 181–190. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, J. Approach to group decision making based on interval-valued intuitionistic judgment matrices. Syst. Eng. Theory Pract. 2007, 27, 126–133. [Google Scholar] [CrossRef]
- Ye, J. Multicriteria fuzzy decision-making method based on a novel accuracy function under interval-valued intuitionistic fuzzy environment. Expert Syst. Appl. 2009, 36, 6899–6902. [Google Scholar] [CrossRef]
- Nayagam, V.L.G.; Muralikrishnan, S.; Sivaraman, G. Multi-criteria decision-making method based on interval-valued intuitionistic fuzzy sets. Expert Syst. Appl. 2011, 38, 1464–1467. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. Hybrid clustering analysis using improved krill herd algorithm. Appl. Intell. 2018, 48, 4047–4071. [Google Scholar] [CrossRef]
- Janani, R.; Vijayarani, S. Text document clustering using Spectral Clustering algorithm with Particle Swarm Optimization. Expert Syst. Appl. 2019, 134, 192–200. [Google Scholar] [CrossRef]
- Ramirez, A.; Himang, C.; Selerio, E.; Manalastas, R.; Himang, M.; Giango, W.; Tenerife, P.; Ocampo, L. Exploring the Hedonic and Eudaimonic Motivations of Teachers for Pursuing Graduate Studies. Asia-Pac. Educ. Res. 2020. [Google Scholar] [CrossRef]
- Selerio, E.F.; Arcadio, R.D.; Medio, G.J.; Natad, J.R.P.; Pedregosa, G.A. On the complex causal relationship of barriers to sustainable urban water management: A fuzzy multi-criteria analysis. Urban. Water J. 2021, 18, 12–24. [Google Scholar] [CrossRef]
- Anitha, P.; Patil, M.M. RFM model for customer purchase behavior using K-Means algorithm. J. King Saud Univ. Comput. Inf. Sci. 2019, in press. [Google Scholar] [CrossRef]
- Taheri, H.; Koester, L.W.; Bigelow, T.A.; Faierson, E.J.; Bond, L.J. In Situ Additive Manufacturing Process Monitoring with an Acoustic Technique: Clustering Performance Evaluation Using K-Means Algorithm. J. Manuf. Sci. Eng. 2019, 141, 1–27. [Google Scholar] [CrossRef]
- Galvis, I.S.; Villa, Y.; Duarte, C.; Sierra, D.; Agudelo, W. Seismic attribute selection and clustering to detect and classify surface waves in multicomponent seismic data by using k-means algorithm. Lead. Edge 2017, 36, 239–248. [Google Scholar] [CrossRef]
- Ramalingam, M.; Thangarajan, R. Mutated k-means algorithm for dynamic clustering to perform effective and intelligent broadcasting in medical surveillance using selective reliable broadcast protocol in VANET. Comput. Commun. 2020, 150, 563–568. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Forgy, E. Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Ocampo, L.; Yamagishi, K. Modeling the lockdown relaxation protocols of the Philippine government in response to the COVID-19 pandemic: An intuitionistic fuzzy DEMATEL analysis. Socio-Econ. Plan. Sci. 2020, 72, 100911. [Google Scholar] [CrossRef] [PubMed]
- Department of Tourism DOT Pushes Stringent Guidelines for Stakeholders across the Nation. 2020. Available online: http://tourism.gov.ph/news_features/GuidelinesForStakeholders.aspx (accessed on 20 July 2021).
- Department of Tourism DOT Statement on Uniform Travel Protocols. 2021. Available online: http://www.tourism.gov.ph/news_features/UniformTravelProtocols.aspx (accessed on 20 July 2021).
- Rocamora, J.A.; Vaccination Key to Tourism Recovery. Philippine News Agency. 2021. Available online: https://www.pna.gov.ph/articles/1144200 (accessed on 31 July 2021).
- Prosser, L.A.; Lavelle, T.A.; Fiore, A.E.; Bridges, C.B.; Reed, C.; Jain, S.; Dunham, K.M.; Meltzer, M.I. Cost-Effectiveness of 2009 Pandemic Influenza A(H1N1) Vaccination in the United States. PLoS ONE 2011, 6, e22308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Asian Development Bank. (28 April 2021). Philippine Economy Seen Recovering in 2021, with Stronger Growth in 2022—ADB. Available online: https://www.adb.org/news/philippine-economy-seen-recovering-2021-stronger-growth-2022-adb (accessed on 29 July 2021).
- Markowitz, A. State-by-State Guide to Face Mask Requirements. AARP. Available online: https://www.aarp.org/health/healthy-living/info-2020/states-mask-mandates-coronavirus.html (accessed on 10 February 2021).
- Ghorabaee, M.K.; Zavadskas, E.K.; Olfat, L.; Turskis, Z. Multi-Criteria Inventory Classification Using a New Method of Evaluation Based on Distance from Average Solution (EDAS). Informatica 2015, 26, 435–451. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Code | Tourist Site | Type | Code | Tourist Site |
|---|---|---|---|---|---|
| Sun, sea, sand | S1 | Sumilon island | Ecotourism | S18 | Bojo river |
| S2 | Panagsama beach | S19 | Sanctuaries in Olango | ||
| S3 | Sardine run | S20 | Omagieca mangrove garden | ||
| S4 | Basdaku | Farm tourism | S21 | AO farm gardens | |
| S5 | Virgin island | S22 | Eskapo Verde ecotourism | ||
| S6 | Malapascua island | Water-based tourism | S23 | Oslob whale watching | |
| S7 | Orongan beach resort | S24 | Kawasan falls | ||
| S8 | Lambug beach | S25 | Pescador island | ||
| S9 | Tingko beach | S26 | Canyoneering | ||
| S10 | Camotes beach | S27 | Cebu Ocean Park | ||
| Heritage and culture | S11 | Fort San Pedro | Adventure tourism | S28 | Danasan eco adventure park |
| S12 | Casa Gorordo | S29 | Cebu safari | ||
| S13 | Yap-Sandiego museum | S30 | Anjo World | ||
| S14 | Museo sa Sugbo | Park tourism | S31 | Sirao flower garden | |
| S15 | Parian museum | S32 | Tops lookout | ||
| S16 | Sugbo Chinese heritage museum | S33 | D’Family park | ||
| S17 | Mactan shrine | S34 | Baluarte park | ||
| S35 | Lake Danao |
| Rating | Linguistic Variable | Equivalent IVIFS Value |
|---|---|---|
| 1 | Extremely irrelevant | ([0,0.1],[0.8,0.9]) |
| 2 | Very irrelevant | ([0.2,0.2],[0.7,0.7]) |
| 3 | Irrelevant | ([0.3,0.4],[0.5,0.6]) |
| 4 | Slightly irrelevant | ([0.4,0.5],[0.5,0.5]) |
| 5 | Fairly relevant | ([0.5,0.5],[0.4,0.5]) |
| 6 | Slightly relevant | ([0.6,0.7],[0.2,0.3]) |
| 7 | Relevant | ([0.7,0.8],[0.2,0.2]) |
| 8 | Very relevant | ([0.8,0.8],[0.1,0.1]) |
| 9 | Extremely relevant | ([0.9,1],[0,0]) |
| Codes | Criteria | IVIF Weights | Rank | |
|---|---|---|---|---|
| C1 | Proximity | ([0.9,1],[0,0]) | 0.950 | 1 |
| C2 | Available modes of transportation | ([0.78,1],[0,0]) | 0.891 | 3 |
| C3 | Duration of stay | ([0.75,1],[0,0]) | 0.875 | 6 |
| C4 | Tourist activities | ([0.76,1],[0,0]) | 0.879 | 5 |
| C5 | Area of site premises | ([0.76,1],[0,0]) | 0.880 | 4 |
| C6 | Volume of tourist arrivals | ([0.82,1],[0,0]) | 0.912 | 2 |
| Tourist Sites | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| S1 | ([0.4,0.5],[0.5,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.4,0.5],[0.5,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S2 | ([0.4,0.5],[0.5,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S3 | ([0.7,0.8],[0.2,0.2]) | ([0.8,0.8],[0.1,0.1]) | ([0.9,1],[0,0]) | ([0.9,1],[0,0]) | ([0.8,0.8],[0.1,0.1]) | ([0.9,1],[0,0]) |
| S4 | ([0.5,0.5],[0.5,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.5,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S5 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S6 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S7 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) |
| S8 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) |
| S9 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S10 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) |
| S11 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S12 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S13 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S14 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S15 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S16 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S17 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) |
| S18 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S19 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S20 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S21 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.6,0.7],[0.2,0.3]) |
| S22 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.7,0.8],[0.2,0.2]) |
| S23 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.6,0.7],[0.2,0.3]) |
| S24 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.5,0.5],[0.4,0.5]) |
| S25 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.6,0.7],[0.2,0.3]) |
| S26 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.7,0.8],[0.2,0.2]) |
| S27 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.6,0.7],[0.2,0.3]) |
| S28 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.5,0.5],[0.4,0.5]) |
| S29 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.7,0.8],[0.2,0.2]) |
| S30 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.6,0.7],[0.2,0.3]) |
| S31 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) |
| S32 | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.6,0.7],[0.2,0.3]) | ([0.7,0.8],[0.2,0.2]) |
| S33 | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.7,0.8],[0.2,0.2]) | ([0.6,0.7],[0.2,0.3]) | ([0.7,0.8],[0.2,0.2]) | ([0.5,0.5],[0.4,0.5]) |
| S34 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| S35 | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) | ([0.5,0.5],[0.4,0.5]) |
| Tourist Sites | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| S1 | ([0.63,1],[0,0]) | ([0.73,1],[0,0]) | ([0.66,1],[0,0]) | ([0.69,1],[0,0]) | ([0.67,1],[0,0]) | ([0.77,1],[0,0]) |
| S2 | ([0.68,1],[0,0]) | ([0.73,1],[0,0]) | ([0.7,1],[0,0]) | ([0.72,1],[0,0]) | ([0.71,1],[0,0]) | ([0.78,1],[0,0]) |
| S3 | ([0.65,1],[0,0]) | ([0.71,1],[0,0]) | ([0.67,1],[0,0]) | ([0.68,1],[0,0]) | ([0.68,1],[0,0]) | ([0.75,1],[0,0]) |
| S4 | ([0.68,1],[0,0]) | ([0.74,1],[0,0]) | ([0.7,1],[0,0]) | ([0.72,1],[0,0]) | ([0.71,1],[0,0]) | ([0.78,1],[0,0]) |
| S5 | ([0.64,1],[0,0]) | ([0.71,1],[0,0]) | ([0.66,1],[0,0]) | ([0.69,1],[0,0]) | ([0.69,1],[0,0]) | ([0.75,1],[0,0]) |
| S6 | ([0.67,1],[0,0]) | ([0.72,1],[0,0]) | ([0.68,1],[0,0]) | ([0.7,1],[0,0]) | ([0.7,1],[0,0]) | ([0.76,1],[0,0]) |
| S7 | ([0.63,1],[0,0]) | ([0.69,1],[0,0]) | ([0.66,1],[0,0]) | ([0.67,1],[0,0]) | ([0.67,1],[0,0]) | ([0.74,1],[0,0]) |
| S8 | ([0.68,1],[0,0]) | ([0.72,1],[0,0]) | ([0.68,1],[0,0]) | ([0.7,1],[0,0]) | ([0.7,1],[0,0]) | ([0.77,1],[0,0]) |
| S9 | ([0.66,1],[0,0]) | ([0.72,1],[0,0]) | ([0.67,1],[0,0]) | ([0.7,1],[0,0]) | ([0.71,1],[0,0]) | ([0.77,1],[0,0]) |
| S10 | ([0.67,1],[0,0]) | ([0.72,1],[0,0]) | ([0.67,1],[0,0]) | ([0.7,1],[0,0]) | ([0.69,1],[0,0]) | ([0.77,1],[0,0]) |
| S11 | ([0.74,1],[0,0]) | ([0.74,1],[0,0]) | ([0.71,1],[0,0]) | ([0.72,1],[0,0]) | ([0.76,1],[0,0]) | ([0.8,1],[0,0]) |
| S12 | ([0.72,1],[0,0]) | ([0.74,1],[0,0]) | ([0.7,1],[0,0]) | ([0.72,1],[0,0]) | ([0.75,1],[0,0]) | ([0.79,1],[0,0]) |
| S13 | ([0.7,1],[0,0]) | ([0.72,1],[0,0]) | ([0.69,1],[0,0]) | ([0.71,1],[0,0]) | ([0.74,1],[0,0]) | ([0.78,1],[0,0]) |
| S14 | ([0.71,1],[0,0]) | ([0.73,1],[0,0]) | ([0.7,1],[0,0]) | ([0.72,1],[0,0]) | ([0.75,1],[0,0]) | ([0.78,1],[0,0]) |
| S15 | ([0.73,1],[0,0]) | ([0.73,1],[0,0]) | ([0.7,1],[0,0]) | ([0.73,1],[0,0]) | ([0.75,1],[0,0]) | ([0.78,1],[0,0]) |
| S16 | ([0.71,1],[0,0]) | ([0.72,1],[0,0]) | ([0.69,1],[0,0]) | ([0.71,1],[0,0]) | ([0.73,1],[0,0]) | ([0.77,1],[0,0]) |
| S17 | ([0.71,1],[0,0]) | ([0.73,1],[0,0]) | ([0.68,1],[0,0]) | ([0.7,1],[0,0]) | ([0.72,1],[0,0]) | ([0.77,1],[0,0]) |
| S18 | ([0.66,1],[0,0]) | ([0.7,1],[0,0]) | ([0.65,1],[0,0]) | ([0.69,1],[0,0]) | ([0.67,1],[0,0]) | ([0.74,1],[0,0]) |
| S19 | ([0.67,1],[0,0]) | ([0.72,1],[0,0]) | ([0.67,1],[0,0]) | ([0.7,1],[0,0]) | ([0.69,1],[0,0]) | ([0.76,1],[0,0]) |
| S20 | ([0.65,1],[0,0]) | ([0.7,1],[0,0]) | ([0.65,1],[0,0]) | ([0.67,1],[0,0]) | ([0.67,1],[0,0]) | ([0.74,1],[0,0]) |
| S21 | ([0.71,1],[0,0]) | ([0.67,1],[0,0]) | ([0.69,1],[0,0]) | ([0.7,1],[0,0]) | ([0.75,1],[0,0]) | ([0.65,1],[0,0]) |
| S22 | ([0.7,1],[0,0]) | ([0.65,1],[0,0]) | ([0.68,1],[0,0]) | ([0.67,1],[0,0]) | ([0.74,1],[0,0]) | ([0.7,1],[0,0]) |
| S23 | ([0.73,1],[0,0]) | ([0.7,1],[0,0]) | ([0.74,1],[0,0]) | ([0.73,1],[0,0]) | ([0.8,1],[0,0]) | ([0.7,1],[0,0]) |
| S24 | ([0.74,1],[0,0]) | ([0.71,1],[0,0]) | ([0.74,1],[0,0]) | ([0.73,1],[0,0]) | ([0.8,1],[0,0]) | ([0.67,1],[0,0]) |
| S25 | ([0.71,1],[0,0]) | ([0.68,1],[0,0]) | ([0.71,1],[0,0]) | ([0.69,1],[0,0]) | ([0.77,1],[0,0]) | ([0.69,1],[0,0]) |
| S26 | ([0.73,1],[0,0]) | ([0.71,1],[0,0]) | ([0.74,1],[0,0]) | ([0.72,1],[0,0]) | ([0.78,1],[0,0]) | ([0.74,1],[0,0]) |
| S27 | ([0.76,1],[0,0]) | ([0.75,1],[0,0]) | ([0.76,1],[0,0]) | ([0.78,1],[0,0]) | ([0.81,1],[0,0]) | ([0.68,1],[0,0]) |
| S28 | ([0.71,1],[0,0]) | ([0.67,1],[0,0]) | ([0.71,1],[0,0]) | ([0.69,1],[0,0]) | ([0.75,1],[0,0]) | ([0.67,1],[0,0]) |
| S29 | ([0.72,1],[0,0]) | ([0.68,1],[0,0]) | ([0.7,1],[0,0]) | ([0.7,1],[0,0]) | ([0.76,1],[0,0]) | ([0.73,1],[0,0]) |
| S30 | ([0.74,1],[0,0]) | ([0.74,1],[0,0]) | ([0.77,1],[0,0]) | ([0.77,1],[0,0]) | ([0.81,1],[0,0]) | ([0.69,1],[0,0]) |
| S31 | ([0.7,1],[0,0]) | ([0.67,1],[0,0]) | ([0.69,1],[0,0]) | ([0.71,1],[0,0]) | ([0.77,1],[0,0]) | ([0.69,1],[0,0]) |
| S32 | ([0.71,1],[0,0]) | ([0.69,1],[0,0]) | ([0.69,1],[0,0]) | ([0.71,1],[0,0]) | ([0.77,1],[0,0]) | ([0.69,1],[0,0]) |
| S33 | ([0.71,1],[0,0]) | ([0.68,1],[0,0]) | ([0.7,1],[0,0]) | ([0.7,1],[0,0]) | ([0.74,1],[0,0]) | ([0.65,1],[0,0]) |
| S34 | ([0.65,1],[0,0]) | ([0.68,1],[0,0]) | ([0.64,1],[0,0]) | ([0.66,1],[0,0]) | ([0.66,1],[0,0]) | ([0.73,1],[0,0]) |
| S35 | ([0.65,1],[0,0]) | ([0.7,1],[0,0]) | ([0.66,1],[0,0]) | ([0.67,1],[0,0]) | ([0.66,1],[0,0]) | ([0.74,1],[0,0]) |
| Tourist Sites | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| S1 | ([0.57,1],[0,0]) | ([0.57,1],[0,0]) | ([0.5,1],[0,0]) | ([0.53,1],[0,0]) | ([0.51,1],[0,0]) | ([0.63,1],[0,0]) |
| S2 | ([0.61,1],[0,0]) | ([0.57,1],[0,0]) | ([0.52,1],[0,0]) | ([0.55,1],[0,0]) | ([0.54,1],[0,0]) | ([0.64,1],[0,0]) |
| S3 | ([0.58,1],[0,0]) | ([0.56,1],[0,0]) | ([0.5,1],[0,0]) | ([0.52,1],[0,0]) | ([0.52,1],[0,0]) | ([0.62,1],[0,0]) |
| S4 | ([0.61,1],[0,0]) | ([0.58,1],[0,0]) | ([0.53,1],[0,0]) | ([0.55,1],[0,0]) | ([0.54,1],[0,0]) | ([0.64,1],[0,0]) |
| S5 | ([0.58,1],[0,0]) | ([0.55,1],[0,0]) | ([0.5,1],[0,0]) | ([0.53,1],[0,0]) | ([0.52,1],[0,0]) | ([0.62,1],[0,0]) |
| S6 | ([0.61,1],[0,0]) | ([0.56,1],[0,0]) | ([0.51,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.63,1],[0,0]) |
| S7 | ([0.57,1],[0,0]) | ([0.54,1],[0,0]) | ([0.49,1],[0,0]) | ([0.51,1],[0,0]) | ([0.51,1],[0,0]) | ([0.61,1],[0,0]) |
| S8 | ([0.61,1],[0,0]) | ([0.57,1],[0,0]) | ([0.51,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.63,1],[0,0]) |
| S9 | ([0.6,1],[0,0]) | ([0.56,1],[0,0]) | ([0.51,1],[0,0]) | ([0.53,1],[0,0]) | ([0.54,1],[0,0]) | ([0.63,1],[0,0]) |
| S10 | ([0.61,1],[0,0]) | ([0.56,1],[0,0]) | ([0.5,1],[0,0]) | ([0.53,1],[0,0]) | ([0.52,1],[0,0]) | ([0.63,1],[0,0]) |
| S11 | ([0.66,1],[0,0]) | ([0.58,1],[0,0]) | ([0.53,1],[0,0]) | ([0.55,1],[0,0]) | ([0.58,1],[0,0]) | ([0.66,1],[0,0]) |
| S12 | ([0.65,1],[0,0]) | ([0.58,1],[0,0]) | ([0.53,1],[0,0]) | ([0.55,1],[0,0]) | ([0.57,1],[0,0]) | ([0.65,1],[0,0]) |
| S13 | ([0.63,1],[0,0]) | ([0.56,1],[0,0]) | ([0.52,1],[0,0]) | ([0.54,1],[0,0]) | ([0.56,1],[0,0]) | ([0.64,1],[0,0]) |
| S14 | ([0.64,1],[0,0]) | ([0.57,1],[0,0]) | ([0.53,1],[0,0]) | ([0.55,1],[0,0]) | ([0.57,1],[0,0]) | ([0.64,1],[0,0]) |
| S15 | ([0.66,1],[0,0]) | ([0.57,1],[0,0]) | ([0.53,1],[0,0]) | ([0.55,1],[0,0]) | ([0.57,1],[0,0]) | ([0.64,1],[0,0]) |
| S16 | ([0.64,1],[0,0]) | ([0.56,1],[0,0]) | ([0.52,1],[0,0]) | ([0.54,1],[0,0]) | ([0.55,1],[0,0]) | ([0.63,1],[0,0]) |
| S17 | ([0.64,1],[0,0]) | ([0.57,1],[0,0]) | ([0.51,1],[0,0]) | ([0.53,1],[0,0]) | ([0.55,1],[0,0]) | ([0.64,1],[0,0]) |
| S18 | ([0.59,1],[0,0]) | ([0.55,1],[0,0]) | ([0.49,1],[0,0]) | ([0.52,1],[0,0]) | ([0.51,1],[0,0]) | ([0.61,1],[0,0]) |
| S19 | ([0.6,1],[0,0]) | ([0.56,1],[0,0]) | ([0.51,1],[0,0]) | ([0.53,1],[0,0]) | ([0.52,1],[0,0]) | ([0.62,1],[0,0]) |
| S20 | ([0.58,1],[0,0]) | ([0.55,1],[0,0]) | ([0.49,1],[0,0]) | ([0.51,1],[0,0]) | ([0.51,1],[0,0]) | ([0.61,1],[0,0]) |
| S21 | ([0.64,1],[0,0]) | ([0.52,1],[0,0]) | ([0.52,1],[0,0]) | ([0.53,1],[0,0]) | ([0.57,1],[0,0]) | ([0.54,1],[0,0]) |
| S22 | ([0.63,1],[0,0]) | ([0.51,1],[0,0]) | ([0.51,1],[0,0]) | ([0.51,1],[0,0]) | ([0.56,1],[0,0]) | ([0.58,1],[0,0]) |
| S23 | ([0.66,1],[0,0]) | ([0.55,1],[0,0]) | ([0.56,1],[0,0]) | ([0.55,1],[0,0]) | ([0.61,1],[0,0]) | ([0.58,1],[0,0]) |
| S24 | ([0.66,1],[0,0]) | ([0.56,1],[0,0]) | ([0.55,1],[0,0]) | ([0.55,1],[0,0]) | ([0.61,1],[0,0]) | ([0.56,1],[0,0]) |
| S25 | ([0.64,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.59,1],[0,0]) | ([0.57,1],[0,0]) |
| S26 | ([0.66,1],[0,0]) | ([0.55,1],[0,0]) | ([0.56,1],[0,0]) | ([0.54,1],[0,0]) | ([0.59,1],[0,0]) | ([0.61,1],[0,0]) |
| S27 | ([0.68,1],[0,0]) | ([0.59,1],[0,0]) | ([0.57,1],[0,0]) | ([0.59,1],[0,0]) | ([0.62,1],[0,0]) | ([0.56,1],[0,0]) |
| S28 | ([0.64,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.52,1],[0,0]) | ([0.57,1],[0,0]) | ([0.55,1],[0,0]) |
| S29 | ([0.64,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.53,1],[0,0]) | ([0.58,1],[0,0]) | ([0.6,1],[0,0]) |
| S30 | ([0.67,1],[0,0]) | ([0.58,1],[0,0]) | ([0.58,1],[0,0]) | ([0.58,1],[0,0]) | ([0.61,1],[0,0]) | ([0.57,1],[0,0]) |
| S31 | ([0.63,1],[0,0]) | ([0.53,1],[0,0]) | ([0.52,1],[0,0]) | ([0.54,1],[0,0]) | ([0.59,1],[0,0]) | ([0.57,1],[0,0]) |
| S32 | ([0.64,1],[0,0]) | ([0.54,1],[0,0]) | ([0.51,1],[0,0]) | ([0.54,1],[0,0]) | ([0.58,1],[0,0]) | ([0.57,1],[0,0]) |
| S33 | ([0.64,1],[0,0]) | ([0.53,1],[0,0]) | ([0.52,1],[0,0]) | ([0.53,1],[0,0]) | ([0.56,1],[0,0]) | ([0.53,1],[0,0]) |
| S34 | ([0.58,1],[0,0]) | ([0.53,1],[0,0]) | ([0.48,1],[0,0]) | ([0.5,1],[0,0]) | ([0.5,1],[0,0]) | ([0.6,1],[0,0]) |
| S35 | ([0.59,1],[0,0]) | ([0.54,1],[0,0]) | ([0.49,1],[0,0]) | ([0.51,1],[0,0]) | ([0.5,1],[0,0]) | ([0.61,1],[0,0]) |
| Tourist Sites | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| S1 | 0.78323 | 0.78492 | 0.74933 | 0.76333 | 0.75612 | 0.81525 |
| S2 | 0.80713 | 0.78431 | 0.76150 | 0.77316 | 0.76840 | 0.82021 |
| S3 | 0.79093 | 0.77899 | 0.75061 | 0.75938 | 0.75996 | 0.80885 |
| S4 | 0.80545 | 0.78977 | 0.76442 | 0.77340 | 0.76996 | 0.82098 |
| S5 | 0.78830 | 0.77595 | 0.74900 | 0.76261 | 0.76114 | 0.80988 |
| S6 | 0.80264 | 0.78132 | 0.75637 | 0.76497 | 0.76472 | 0.81299 |
| S7 | 0.78320 | 0.77128 | 0.74641 | 0.75577 | 0.75377 | 0.80389 |
| S8 | 0.80601 | 0.78339 | 0.75655 | 0.76601 | 0.76406 | 0.81671 |
| S9 | 0.79785 | 0.78110 | 0.75267 | 0.76486 | 0.76867 | 0.81712 |
| S10 | 0.80315 | 0.78109 | 0.75235 | 0.76542 | 0.76043 | 0.81606 |
| S11 | 0.83107 | 0.79146 | 0.76452 | 0.77348 | 0.78758 | 0.83039 |
| S12 | 0.82326 | 0.78809 | 0.76338 | 0.77440 | 0.78349 | 0.82513 |
| S13 | 0.81550 | 0.78215 | 0.75780 | 0.77034 | 0.78125 | 0.81919 |
| S14 | 0.82142 | 0.78600 | 0.76384 | 0.77319 | 0.78347 | 0.82014 |
| S15 | 0.82897 | 0.78705 | 0.76419 | 0.77517 | 0.78501 | 0.82091 |
| S16 | 0.81853 | 0.78197 | 0.75818 | 0.76888 | 0.77580 | 0.81657 |
| S17 | 0.81827 | 0.78435 | 0.75329 | 0.76520 | 0.77274 | 0.81898 |
| S18 | 0.79556 | 0.77468 | 0.74541 | 0.76045 | 0.75354 | 0.80476 |
| S19 | 0.80030 | 0.78088 | 0.75282 | 0.76620 | 0.76229 | 0.81158 |
| S20 | 0.79118 | 0.77262 | 0.74358 | 0.75327 | 0.75486 | 0.80261 |
| S21 | 0.81867 | 0.76183 | 0.76006 | 0.76641 | 0.78332 | 0.76904 |
| S22 | 0.81489 | 0.75569 | 0.75490 | 0.75303 | 0.77981 | 0.78954 |
| S23 | 0.82957 | 0.77583 | 0.77793 | 0.77620 | 0.80465 | 0.79000 |
| S24 | 0.83176 | 0.77919 | 0.77591 | 0.77668 | 0.80263 | 0.77760 |
| S25 | 0.82023 | 0.76669 | 0.76566 | 0.76310 | 0.79335 | 0.78538 |
| S26 | 0.82782 | 0.77636 | 0.77867 | 0.77239 | 0.79678 | 0.80661 |
| S27 | 0.83988 | 0.79451 | 0.78582 | 0.79535 | 0.80863 | 0.78058 |
| S28 | 0.81842 | 0.76274 | 0.76696 | 0.76085 | 0.78307 | 0.77720 |
| S29 | 0.82199 | 0.76510 | 0.76313 | 0.76452 | 0.79026 | 0.80083 |
| S30 | 0.83274 | 0.78772 | 0.79064 | 0.79179 | 0.80711 | 0.78267 |
| S31 | 0.81716 | 0.76361 | 0.75818 | 0.76894 | 0.79302 | 0.78527 |
| S32 | 0.81887 | 0.76965 | 0.75728 | 0.76980 | 0.79152 | 0.78389 |
| S33 | 0.81937 | 0.76594 | 0.76148 | 0.76545 | 0.78200 | 0.76676 |
| S34 | 0.79157 | 0.76621 | 0.74010 | 0.75053 | 0.75179 | 0.79921 |
| S35 | 0.79458 | 0.77215 | 0.74666 | 0.75576 | 0.75008 | 0.80319 |
| Low Exposure Cluster | Moderate Exposure Cluster | High Exposure Cluster |
|---|---|---|
| S1, S3, S5, S6, S7, S8, S9, S10, S18, S19, S20, S34, S35 | S21, S22, S23, S24, S25, S26, S27, S28, S29, S30, S31, S32, S33 | S2, S4, S11, S12, S13, S14, S15, S16, S17 |
| Code | Restaurants | Code | Restaurants |
|---|---|---|---|
| R1 | Vikings Luxury Buffet, SM City Cebu | R21 | Entoy’s Bakasihan, Cordova |
| R2 | Buffet 101, City Time Square Mandaue City | R22 | Matias BBQ, Mandaue City |
| R3 | Cabalen Restaurant, SM City Cebu | R23 | Pungko pungko sa Fuente, Cebu City |
| R4 | Tinderbox Wine and Deli Shop, Banilad Cebu City | R24 | Chinese Ngohiong, Downtown Cebu City |
| R5 | Acacia Steakhouse, Capitol Cebu City | R25 | Larangan sa Pasil - the original, Pasil Cebu City |
| R6 | Top of Cebu, Busay, Cebu City | R26 | Nonki Japanese Restaurant, SM City Cebu |
| R7 | Rico’s Lechon, Mandaue City | R27 | La Vie Parisienne, Gorordo Cebu City |
| R8 | Hukad, SM City Cebu | R28 | Casa Verde Main Cebu City |
| R9 | Lantaw Floating Restaurant, Cordova Cebu | R29 | Lemon Grass, Ayala Center Cebu |
| R10 | Choobi-choobi, Mabolo Cebu City | R30 | Samguypsalamat Unli-Korean Meat, Cabahug St, Cebu City |
| R11 | Starbucks, Ayala Cebu | R31 | Maya Mexican, Cebu City |
| R12 | Bo’s Coffee, BTC Banilad Cebu City | R32 | Jollibee, Highway Mandaue City |
| R13 | Macau Imperial Tea, SM City Cebu | R33 | McDonald’s, Jones Avenue Cebu City |
| R14 | KM 21, Cantipla Cebu City | R34 | Chowking, Sto. Nino Cebu City |
| R15 | Chatime, SM City Cebu | R35 | Mang Inasal, Parkmall Mandaue City |
| R16 | Sugbo Mercado, IT Park Cebu City | R36 | Orange Brutus, Fuente Cebu City |
| R17 | Larsian Barbecue Food Park | R37 | Cafe Bai, Bai Hotel Mandaue City |
| R18 | Tambayan Food Park, Consolacion | R38 | Cafe Marco, Marco Polo Cebu City |
| R19 | SM Food Court, SM City Cebu | R39 | Feria, Radisson Blue Cebu City |
| R20 | Sutukil Seafood Market, Mactan | R40 | Pusô Bistro & Bar, Quest Hotel Cebu City |
| Rating | Linguistic Variable | Equivalent IVIFS Value |
|---|---|---|
| 1 | very irrelevant | ([0.05,0.25],[0.65,0.75]) |
| 2 | irrelevant | ([0.30,0.45],[0.40,0.55]) |
| 3 | slightly irrelevant | ([0.45,0.55],[0.30,0.45]) |
| 4 | slightly relevant | ([0.55,0.75],[0.10,0.25]) |
| 5 | relevant | ([0.75,0.85],[0.05,0.10]) |
| 6 | very relevant | ([0.85,0.95],[0,0.05]) |
| Codes | Criteria | IVIF Weights | Rank | |
|---|---|---|---|---|
| C1 | proximity | ([0.66,1],[0,0]) | 0.831 | 6 |
| C2 | available mode of transportation | ([0.70,1],[0,0]) | 0.850 | 4 |
| C3 | available hygiene facilities and equipment | ([0.75,1],[0,0]) | 0.874 | 1 |
| C4 | physical environment | ([0.74,1],[0,0]) | 0.868 | 2 |
| C5 | duration of stay | ([0.69,1],[0,0]) | 0.843 | 5 |
| C6 | consumer traffic | ([0.70,1],[0,0]) | 0.851 | 3 |
| Restaurants | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| R1 | ([0.59,0.74],[0,0.24]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) | ([0.63,0.78],[0,0.2]) | ([0.61,0.76],[0,0.21]) | ([0.63,0.78],[0,0.2]) |
| R2 | ([0.59,0.74],[0,0.24]) | ([0.61,0.76],[0,0.22]) | ([0.6,0.76],[0,0.22]) | ([0.63,0.78],[0,0.2]) | ([0.6,0.75],[0,0.22]) | ([0.62,0.77],[0,0.21]) |
| R3 | ([0.59,0.74],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) | ([0.61,0.76],[0,0.22]) | ([0.63,0.78],[0,0.2]) |
| R4 | ([0.58,0.73],[0,0.25]) | ([0.59,0.75],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) | ([0.59,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) |
| R5 | ([0.57,0.73],[0,0.25]) | ([0.59,0.74],[0,0.24]) | ([0.6,0.76],[0,0.22]) | ([0.62,0.76],[0,0.21]) | ([0.59,0.74],[0,0.23]) | ([0.61,0.76],[0,0.22]) |
| R6 | ([0.57,0.73],[0,0.26]) | ([0.6,0.75],[0,0.23]) | ([0.6,0.75],[0,0.23]) | ([0.58,0.74],[0,0.24]) | ([0.58,0.73],[0,0.25]) | ([0.58,0.74],[0,0.24]) |
| R7 | ([0.6,0.75],[0,0.23]) | ([0.59,0.74],[0,0.24]) | ([0.61,0.77],[0,0.22]) | ([0.61,0.76],[0,0.22]) | ([0.59,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) |
| R8 | ([0.6,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) | ([0.6,0.75],[0,0.23]) | ([0.62,0.77],[0,0.2]) |
| R9 | ([0.59,0.75],[0,0.24]) | ([0.6,0.76],[0,0.23]) | ([0.61,0.77],[0,0.22]) | ([0.6,0.75],[0,0.23]) | ([0.59,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) |
| R10 | ([0.59,0.74],[0,0.24]) | ([0.59,0.74],[0,0.24]) | ([0.62,0.77],[0,0.21]) | ([0.62,0.77],[0,0.21]) | ([0.59,0.74],[0,0.24]) | ([0.61,0.76],[0,0.22]) |
| R11 | ([0.6,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) | ([0.62,0.77],[0,0.21]) | ([0.6,0.75],[0,0.23]) | ([0.64,0.79],[0,0.19]) |
| R12 | ([0.6,0.75],[0,0.23]) | ([0.6,0.76],[0,0.23]) | ([0.61,0.77],[0,0.22]) | ([0.63,0.77],[0,0.2]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) |
| R13 | ([0.6,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) | ([0.63,0.78],[0,0.2]) | ([0.59,0.74],[0,0.23]) | ([0.63,0.78],[0,0.2]) |
| R14 | ([0.56,0.72],[0,0.26]) | ([0.58,0.74],[0,0.25]) | ([0.6,0.75],[0,0.23]) | ([0.58,0.73],[0,0.25]) | ([0.58,0.73],[0,0.25]) | ([0.58,0.74],[0,0.24]) |
| R15 | ([0.59,0.75],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.62,0.77],[0,0.21]) | ([0.63,0.78],[0,0.2]) | ([0.6,0.76],[0,0.23]) | ([0.63,0.78],[0,0.2]) |
| R16 | ([0.65,0.79],[0,0.19]) | ([0.64,0.79],[0,0.19]) | ([0.67,0.81],[0,0.17]) | ([0.68,0.82],[0,0.16]) | ([0.65,0.8],[0,0.18]) | ([0.68,0.82],[0,0.16]) |
| R17 | ([0.65,0.8],[0,0.19]) | ([0.64,0.79],[0,0.19]) | ([0.67,0.82],[0,0.17]) | ([0.68,0.83],[0,0.16]) | ([0.66,0.81],[0,0.18]) | ([0.67,0.82],[0,0.17]) |
| R18 | ([0.65,0.8],[0,0.18]) | ([0.64,0.79],[0,0.19]) | ([0.66,0.81],[0,0.17]) | ([0.67,0.82],[0,0.17]) | ([0.65,0.8],[0,0.18]) | ([0.67,0.81],[0,0.17]) |
| R19 | ([0.62,0.77],[0,0.21]) | ([0.63,0.78],[0,0.2]) | ([0.65,0.8],[0,0.18]) | ([0.66,0.81],[0,0.17]) | ([0.64,0.79],[0,0.19]) | ([0.66,0.81],[0,0.18]) |
| R20 | ([0.62,0.77],[0,0.21]) | ([0.63,0.78],[0,0.21]) | ([0.65,0.8],[0,0.19]) | ([0.65,0.8],[0,0.18]) | ([0.62,0.77],[0,0.21]) | ([0.64,0.78],[0,0.19]) |
| R21 | ([0.61,0.76],[0,0.22]) | ([0.61,0.76],[0,0.22]) | ([0.63,0.78],[0,0.2]) | ([0.63,0.78],[0,0.2]) | ([0.6,0.75],[0,0.23]) | ([0.63,0.78],[0,0.2]) |
| R22 | ([0.6,0.75],[0,0.23]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.78],[0,0.21]) | ([0.63,0.78],[0,0.2]) | ([0.62,0.77],[0,0.21]) | ([0.63,0.78],[0,0.2]) |
| R23 | ([0.66,0.81],[0,0.18]) | ([0.64,0.79],[0,0.19]) | ([0.7,0.84],[0,0.15]) | ([0.7,0.84],[0,0.15]) | ([0.68,0.83],[0,0.16]) | ([0.69,0.84],[0,0.15]) |
| R24 | ([0.63,0.78],[0,0.2]) | ([0.63,0.78],[0,0.2]) | ([0.67,0.82],[0,0.17]) | ([0.67,0.81],[0,0.17]) | ([0.65,0.8],[0,0.19]) | ([0.66,0.81],[0,0.18]) |
| R25 | ([0.65,0.8],[0,0.18]) | ([0.65,0.8],[0,0.19]) | ([0.69,0.83],[0,0.16]) | ([0.7,0.85],[0,0.14]) | ([0.67,0.82],[0,0.17]) | ([0.68,0.83],[0,0.16]) |
| R26 | ([0.59,0.74],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.59,0.75],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.59,0.74],[0,0.24]) | ([0.6,0.74],[0,0.23]) |
| R27 | ([0.58,0.73],[0,0.24]) | ([0.58,0.73],[0,0.25]) | ([0.59,0.75],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.58,0.73],[0,0.25]) | ([0.59,0.74],[0,0.24]) |
| R28 | ([0.58,0.74],[0,0.24]) | ([0.59,0.74],[0,0.24]) | ([0.6,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) | ([0.59,0.75],[0,0.23]) | ([0.6,0.75],[0,0.23]) |
| R29 | ([0.58,0.73],[0,0.25]) | ([0.57,0.73],[0,0.26]) | ([0.6,0.75],[0,0.23]) | ([0.6,0.75],[0,0.23]) | ([0.57,0.73],[0,0.25]) | ([0.58,0.74],[0,0.24]) |
| R30 | ([0.61,0.76],[0,0.22]) | ([0.6,0.75],[0,0.23]) | ([0.62,0.78],[0,0.21]) | ([0.63,0.78],[0,0.2]) | ([0.62,0.78],[0,0.21]) | ([0.63,0.78],[0,0.2]) |
| R31 | ([0.58,0.73],[0,0.25]) | ([0.58,0.73],[0,0.25]) | ([0.6,0.75],[0,0.23]) | ([0.59,0.74],[0,0.24]) | ([0.57,0.73],[0,0.25]) | ([0.58,0.73],[0,0.25]) |
| R32 | ([0.62,0.77],[0,0.21]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.78],[0,0.21]) | ([0.63,0.79],[0,0.2]) | ([0.62,0.77],[0,0.21]) | ([0.64,0.79],[0,0.19]) |
| R33 | ([0.63,0.78],[0,0.2]) | ([0.62,0.77],[0,0.21]) | ([0.62,0.78],[0,0.21]) | ([0.65,0.8],[0,0.18]) | ([0.63,0.78],[0,0.2]) | ([0.65,0.79],[0,0.19]) |
| R34 | ([0.63,0.78],[0,0.2]) | ([0.63,0.78],[0,0.21]) | ([0.64,0.8],[0,0.19]) | ([0.66,0.81],[0,0.17]) | ([0.65,0.8],[0,0.18]) | ([0.66,0.81],[0,0.18]) |
| R35 | ([0.62,0.77],[0,0.21]) | ([0.62,0.77],[0,0.21]) | ([0.64,0.79],[0,0.2]) | ([0.65,0.79],[0,0.19]) | ([0.64,0.78],[0,0.2]) | ([0.64,0.79],[0,0.19]) |
| R36 | ([0.61,0.76],[0,0.22]) | ([0.61,0.75],[0,0.22]) | ([0.63,0.77],[0,0.2]) | ([0.64,0.78],[0,0.2]) | ([0.61,0.76],[0,0.22]) | ([0.62,0.77],[0,0.21]) |
| R37 | ([0.6,0.75],[0,0.23]) | ([0.6,0.75],[0,0.23]) | ([0.59,0.75],[0,0.24]) | ([0.6,0.75],[0,0.23]) | ([0.59,0.74],[0,0.24]) | ([0.6,0.75],[0,0.23]) |
| R38 | ([0.58,0.74],[0,0.25]) | ([0.59,0.74],[0,0.24]) | ([0.59,0.75],[0,0.24]) | ([0.59,0.75],[0,0.24]) | ([0.58,0.73],[0,0.25]) | ([0.57,0.73],[0,0.25]) |
| R39 | ([0.58,0.73],[0,0.25]) | ([0.58,0.74],[0,0.25]) | ([0.58,0.75],[0,0.24]) | ([0.58,0.73],[0,0.25]) | ([0.57,0.72],[0,0.26]) | ([0.56,0.72],[0,0.26]) |
| R40 | ([0.58,0.74],[0,0.25]) | ([0.58,0.74],[0,0.25]) | ([0.58,0.74],[0,0.24]) | ([0.59,0.75],[0,0.24]) | ([0.58,0.73],[0,0.25]) | ([0.57,0.73],[0,0.25]) |
| Restaurants | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| R1 | ([0.39,0.74],[0,0.24]) | ([0.42,0.76],[0,0.22]) | ([0.46,0.77],[0,0.21]) | ([0.47,0.78],[0,0.2]) | ([0.42,0.76],[0,0.21]) | ([0.44,0.78],[0,0.2]) |
| R2 | ([0.39,0.74],[0,0.24]) | ([0.42,0.76],[0,0.22]) | ([0.45,0.76],[0,0.22]) | ([0.46,0.78],[0,0.2]) | ([0.41,0.75],[0,0.22]) | ([0.43,0.77],[0,0.21]) |
| R3 | ([0.39,0.74],[0,0.24]) | ([0.42,0.75],[0,0.23]) | ([0.46,0.76],[0,0.22]) | ([0.46,0.77],[0,0.21]) | ([0.42,0.76],[0,0.22]) | ([0.44,0.78],[0,0.2]) |
| R4 | ([0.38,0.73],[0,0.25]) | ([0.41,0.75],[0,0.24]) | ([0.45,0.75],[0,0.23]) | ([0.45,0.76],[0,0.22]) | ([0.41,0.75],[0,0.23]) | ([0.43,0.76],[0,0.22]) |
| R5 | ([0.38,0.73],[0,0.25]) | ([0.41,0.74],[0,0.24]) | ([0.45,0.76],[0,0.22]) | ([0.45,0.76],[0,0.21]) | ([0.4,0.74],[0,0.23]) | ([0.43,0.76],[0,0.22]) |
| R6 | ([0.38,0.73],[0,0.26]) | ([0.42,0.75],[0,0.23]) | ([0.45,0.75],[0,0.23]) | ([0.43,0.74],[0,0.24]) | ([0.4,0.73],[0,0.25]) | ([0.41,0.74],[0,0.24]) |
| R7 | ([0.39,0.75],[0,0.23]) | ([0.41,0.74],[0,0.24]) | ([0.46,0.77],[0,0.22]) | ([0.45,0.76],[0,0.22]) | ([0.41,0.75],[0,0.23]) | ([0.43,0.76],[0,0.22]) |
| R8 | ([0.39,0.75],[0,0.23]) | ([0.43,0.76],[0,0.22]) | ([0.46,0.76],[0,0.22]) | ([0.46,0.77],[0,0.21]) | ([0.41,0.75],[0,0.23]) | ([0.44,0.77],[0,0.2]) |
| R9 | ([0.39,0.75],[0,0.24]) | ([0.42,0.76],[0,0.23]) | ([0.46,0.77],[0,0.22]) | ([0.44,0.75],[0,0.23]) | ([0.41,0.75],[0,0.23]) | ([0.43,0.76],[0,0.22]) |
| R10 | ([0.39,0.74],[0,0.24]) | ([0.41,0.74],[0,0.24]) | ([0.46,0.77],[0,0.21]) | ([0.45,0.77],[0,0.21]) | ([0.41,0.74],[0,0.24]) | ([0.43,0.76],[0,0.22]) |
| R11 | ([0.4,0.75],[0,0.23]) | ([0.43,0.76],[0,0.22]) | ([0.46,0.77],[0,0.21]) | ([0.45,0.77],[0,0.21]) | ([0.41,0.75],[0,0.23]) | ([0.45,0.79],[0,0.19]) |
| R12 | ([0.4,0.75],[0,0.23]) | ([0.42,0.76],[0,0.23]) | ([0.46,0.77],[0,0.22]) | ([0.46,0.77],[0,0.2]) | ([0.42,0.76],[0,0.22]) | ([0.44,0.77],[0,0.21]) |
| R13 | ([0.39,0.75],[0,0.23]) | ([0.43,0.76],[0,0.22]) | ([0.46,0.77],[0,0.21]) | ([0.46,0.78],[0,0.2]) | ([0.41,0.74],[0,0.23]) | ([0.44,0.78],[0,0.2]) |
| R14 | ([0.37,0.72],[0,0.26]) | ([0.4,0.74],[0,0.25]) | ([0.45,0.75],[0,0.23]) | ([0.43,0.73],[0,0.25]) | ([0.4,0.73],[0,0.25]) | ([0.41,0.74],[0,0.24]) |
| R15 | ([0.39,0.75],[0,0.24]) | ([0.42,0.75],[0,0.23]) | ([0.46,0.77],[0,0.21]) | ([0.46,0.78],[0,0.2]) | ([0.41,0.76],[0,0.23]) | ([0.44,0.78],[0,0.2]) |
| R16 | ([0.43,0.79],[0,0.19]) | ([0.45,0.79],[0,0.19]) | ([0.5,0.81],[0,0.17]) | ([0.5,0.82],[0,0.16]) | ([0.45,0.8],[0,0.18]) | ([0.48,0.82],[0,0.16]) |
| R17 | ([0.43,0.8],[0,0.19]) | ([0.45,0.79],[0,0.19]) | ([0.5,0.82],[0,0.17]) | ([0.5,0.83],[0,0.16]) | ([0.45,0.81],[0,0.18]) | ([0.47,0.82],[0,0.17]) |
| R18 | ([0.43,0.8],[0,0.18]) | ([0.45,0.79],[0,0.19]) | ([0.5,0.81],[0,0.17]) | ([0.5,0.82],[0,0.17]) | ([0.45,0.8],[0,0.18]) | ([0.47,0.81],[0,0.17]) |
| R19 | ([0.41,0.77],[0,0.21]) | ([0.44,0.78],[0,0.2]) | ([0.49,0.8],[0,0.18]) | ([0.49,0.81],[0,0.17]) | ([0.44,0.79],[0,0.19]) | ([0.46,0.81],[0,0.18]) |
| R20 | ([0.41,0.77],[0,0.21]) | ([0.44,0.78],[0,0.21]) | ([0.48,0.8],[0,0.19]) | ([0.48,0.8],[0,0.18]) | ([0.43,0.77],[0,0.21]) | ([0.45,0.78],[0,0.19]) |
| R21 | ([0.4,0.76],[0,0.22]) | ([0.42,0.76],[0,0.22]) | ([0.47,0.78],[0,0.2]) | ([0.46,0.78],[0,0.2]) | ([0.41,0.75],[0,0.23]) | ([0.44,0.78],[0,0.2]) |
| R22 | ([0.4,0.75],[0,0.23]) | ([0.42,0.76],[0,0.22]) | ([0.47,0.78],[0,0.21]) | ([0.46,0.78],[0,0.2]) | ([0.42,0.77],[0,0.21]) | ([0.45,0.78],[0,0.2]) |
| R23 | ([0.43,0.81],[0,0.18]) | ([0.45,0.79],[0,0.19]) | ([0.52,0.84],[0,0.15]) | ([0.51,0.84],[0,0.15]) | ([0.47,0.83],[0,0.16]) | ([0.49,0.84],[0,0.15]) |
| R24 | ([0.41,0.78],[0,0.2]) | ([0.44,0.78],[0,0.2]) | ([0.5,0.82],[0,0.17]) | ([0.49,0.81],[0,0.17]) | ([0.44,0.8],[0,0.19]) | ([0.46,0.81],[0,0.18]) |
| R25 | ([0.43,0.8],[0,0.18]) | ([0.45,0.8],[0,0.19]) | ([0.52,0.83],[0,0.16]) | ([0.52,0.85],[0,0.14]) | ([0.46,0.82],[0,0.17]) | ([0.48,0.83],[0,0.16]) |
| R26 | ([0.39,0.74],[0,0.24]) | ([0.42,0.75],[0,0.23]) | ([0.44,0.75],[0,0.24]) | ([0.44,0.75],[0,0.23]) | ([0.4,0.74],[0,0.24]) | ([0.42,0.74],[0,0.23]) |
| R27 | ([0.39,0.73],[0,0.24]) | ([0.4,0.73],[0,0.25]) | ([0.44,0.75],[0,0.24]) | ([0.44,0.75],[0,0.23]) | ([0.4,0.73],[0,0.25]) | ([0.41,0.74],[0,0.24]) |
| R28 | ([0.39,0.74],[0,0.24]) | ([0.41,0.74],[0,0.24]) | ([0.45,0.76],[0,0.22]) | ([0.46,0.77],[0,0.21]) | ([0.41,0.75],[0,0.23]) | ([0.42,0.75],[0,0.23]) |
| R29 | ([0.38,0.73],[0,0.25]) | ([0.4,0.73],[0,0.26]) | ([0.45,0.75],[0,0.23]) | ([0.44,0.75],[0,0.23]) | ([0.39,0.73],[0,0.25]) | ([0.41,0.74],[0,0.24]) |
| R30 | ([0.4,0.76],[0,0.22]) | ([0.42,0.75],[0,0.23]) | ([0.46,0.78],[0,0.21]) | ([0.47,0.78],[0,0.2]) | ([0.43,0.78],[0,0.21]) | ([0.44,0.78],[0,0.2]) |
| R31 | ([0.39,0.73],[0,0.25]) | ([0.41,0.73],[0,0.25]) | ([0.45,0.75],[0,0.23]) | ([0.43,0.74],[0,0.24]) | ([0.39,0.73],[0,0.25]) | ([0.4,0.73],[0,0.25]) |
| R32 | ([0.41,0.77],[0,0.21]) | ([0.43,0.76],[0,0.22]) | ([0.47,0.78],[0,0.21]) | ([0.47,0.79],[0,0.2]) | ([0.43,0.77],[0,0.21]) | ([0.45,0.79],[0,0.19]) |
| R33 | ([0.41,0.78],[0,0.2]) | ([0.43,0.77],[0,0.21]) | ([0.47,0.78],[0,0.21]) | ([0.48,0.8],[0,0.18]) | ([0.43,0.78],[0,0.2]) | ([0.45,0.79],[0,0.19]) |
| R34 | ([0.42,0.78],[0,0.2]) | ([0.44,0.78],[0,0.21]) | ([0.48,0.8],[0,0.19]) | ([0.49,0.81],[0,0.17]) | ([0.45,0.8],[0,0.18]) | ([0.46,0.81],[0,0.18]) |
| R35 | ([0.41,0.77],[0,0.21]) | ([0.44,0.77],[0,0.21]) | ([0.48,0.79],[0,0.2]) | ([0.48,0.79],[0,0.19]) | ([0.44,0.78],[0,0.2]) | ([0.45,0.79],[0,0.19]) |
| R36 | ([0.4,0.76],[0,0.22]) | ([0.42,0.75],[0,0.22]) | ([0.47,0.77],[0,0.2]) | ([0.47,0.78],[0,0.2]) | ([0.42,0.76],[0,0.22]) | ([0.43,0.77],[0,0.21]) |
| R37 | ([0.4,0.75],[0,0.23]) | ([0.42,0.75],[0,0.23]) | ([0.44,0.75],[0,0.24]) | ([0.44,0.75],[0,0.23]) | ([0.41,0.74],[0,0.24]) | ([0.42,0.75],[0,0.23]) |
| R38 | ([0.38,0.74],[0,0.25]) | ([0.41,0.74],[0,0.24]) | ([0.44,0.75],[0,0.24]) | ([0.44,0.75],[0,0.24]) | ([0.39,0.73],[0,0.25]) | ([0.4,0.73],[0,0.25]) |
| R39 | ([0.38,0.73],[0,0.25]) | ([0.41,0.74],[0,0.25]) | ([0.44,0.75],[0,0.24]) | ([0.43,0.73],[0,0.25]) | ([0.39,0.72],[0,0.26]) | ([0.4,0.72],[0,0.26]) |
| R40 | ([0.38,0.74],[0,0.25]) | ([0.41,0.74],[0,0.25]) | ([0.44,0.74],[0,0.24]) | ([0.43,0.75],[0,0.24]) | ([0.4,0.73],[0,0.25]) | ([0.4,0.73],[0,0.25]) |
| Restaurants | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
| R1 | 0.53421 | 0.56409 | 0.59061 | 0.60444 | 0.56786 | 0.59290 |
| R2 | 0.53362 | 0.56410 | 0.57716 | 0.60098 | 0.55618 | 0.57810 |
| R3 | 0.53511 | 0.55534 | 0.58291 | 0.59113 | 0.56382 | 0.58536 |
| R4 | 0.52143 | 0.55008 | 0.57281 | 0.57704 | 0.54630 | 0.56536 |
| R5 | 0.51954 | 0.54784 | 0.57863 | 0.58246 | 0.54324 | 0.56927 |
| R6 | 0.51741 | 0.55765 | 0.57158 | 0.55017 | 0.53290 | 0.54025 |
| R7 | 0.54220 | 0.54890 | 0.58595 | 0.57845 | 0.54813 | 0.56753 |
| R8 | 0.54293 | 0.56549 | 0.58131 | 0.59176 | 0.54815 | 0.58268 |
| R9 | 0.53767 | 0.56389 | 0.58580 | 0.56693 | 0.54751 | 0.57026 |
| R10 | 0.53074 | 0.54837 | 0.59502 | 0.58507 | 0.54342 | 0.56732 |
| R11 | 0.54462 | 0.56724 | 0.59247 | 0.58825 | 0.55248 | 0.59765 |
| R12 | 0.54243 | 0.56125 | 0.58965 | 0.59448 | 0.56076 | 0.58112 |
| R13 | 0.54388 | 0.57041 | 0.59431 | 0.59821 | 0.54466 | 0.58675 |
| R14 | 0.50988 | 0.53809 | 0.56912 | 0.54742 | 0.53281 | 0.54043 |
| R15 | 0.54009 | 0.55795 | 0.59302 | 0.59668 | 0.55615 | 0.58586 |
| R16 | 0.59227 | 0.59576 | 0.64019 | 0.64741 | 0.60692 | 0.63773 |
| R17 | 0.59734 | 0.60137 | 0.64806 | 0.64962 | 0.61513 | 0.62845 |
| R18 | 0.59422 | 0.59936 | 0.63902 | 0.64258 | 0.60643 | 0.62362 |
| R19 | 0.56741 | 0.58410 | 0.62578 | 0.63197 | 0.59208 | 0.61719 |
| R20 | 0.56554 | 0.58363 | 0.62140 | 0.62281 | 0.57485 | 0.59438 |
| R21 | 0.55603 | 0.56765 | 0.60576 | 0.60195 | 0.55570 | 0.58618 |
| R22 | 0.54836 | 0.56350 | 0.59751 | 0.60073 | 0.57205 | 0.59179 |
| R23 | 0.60461 | 0.60160 | 0.67186 | 0.66636 | 0.63395 | 0.64827 |
| R24 | 0.57513 | 0.58726 | 0.64198 | 0.63540 | 0.60119 | 0.62022 |
| R25 | 0.60066 | 0.60786 | 0.66176 | 0.67201 | 0.62789 | 0.64021 |
| R26 | 0.53234 | 0.55240 | 0.56663 | 0.56672 | 0.53671 | 0.55193 |
| R27 | 0.52815 | 0.52963 | 0.56719 | 0.56717 | 0.53115 | 0.54879 |
| R28 | 0.53037 | 0.54644 | 0.58061 | 0.58911 | 0.54585 | 0.55911 |
| R29 | 0.52551 | 0.52872 | 0.57163 | 0.56874 | 0.52429 | 0.54145 |
| R30 | 0.55412 | 0.55894 | 0.59852 | 0.60132 | 0.57948 | 0.59142 |
| R31 | 0.52583 | 0.53378 | 0.56989 | 0.55628 | 0.52448 | 0.53097 |
| R32 | 0.56553 | 0.56814 | 0.59961 | 0.60552 | 0.57475 | 0.60100 |
| R33 | 0.57310 | 0.57768 | 0.59783 | 0.62193 | 0.58485 | 0.60464 |
| R34 | 0.57720 | 0.58520 | 0.61934 | 0.63428 | 0.60579 | 0.61668 |
| R35 | 0.57075 | 0.58152 | 0.61109 | 0.61624 | 0.58815 | 0.60309 |
| R36 | 0.55791 | 0.56115 | 0.59852 | 0.60560 | 0.56505 | 0.57784 |
| R37 | 0.54299 | 0.55936 | 0.56791 | 0.57141 | 0.54289 | 0.55592 |
| R38 | 0.52747 | 0.54540 | 0.56211 | 0.56284 | 0.52848 | 0.53357 |
| R39 | 0.52307 | 0.53953 | 0.56042 | 0.54760 | 0.51972 | 0.51974 |
| R40 | 0.52759 | 0.53839 | 0.55839 | 0.55786 | 0.53135 | 0.53015 |
| Low Exposure Cluster | Moderate Exposure Cluster | High Exposure Cluster |
|---|---|---|
| R4, R5, R6, R7, R9, R10, R14, R26, R27, R28, R29, R31, R37, R38, R39, R40 | R1, R2, R3, R8, R11, R12, R13, R15, R20, R21, R22, R30, R32, R33, R35, R36 | R16, R17, R18, R19, R23, R24, R25, R34 |
| Vikorsort | -Means Clustering with Crisp Datasets | Proposed Approach | |
|---|---|---|---|
| VIKORSORT | 1 | 0.400 | 0.371 |
| -means clustering with crisp datasets | - | 1 | 0.914 |
| Proposed approach | - | - | 1 |
| IF-TOPSIS-Sort | -Means Clustering with Crisp Datasets | Proposed Approach | |
|---|---|---|---|
| IF-TOPSIS-Sort | 1 | 0.875 | 0.9 |
| -means clustering with crisp datasets | - | 1 | 0.925 |
| Proposed approach | - | - | 1 |
| Rating | |||||
|---|---|---|---|---|---|
| 1 | [(0,0.15),(0.43,0.85)] | [(0,0.2),(0.4,0.8)] | [(0,0.25),(0.38,0.75)] | [(0,0.3),(0.35,0.7)] | [(0,0.35),(0.33,0.65)] |
| 2 | [(0.1,0.25),(0.38,0.75)] | [(0.09,0.29),(0.35,0.71)] | [(0.09,0.34),(0.33,0.66)] | [(0.08,0.38),(0.31,0.62)] | [(0.08,0.43),(0.29,0.58)] |
| 3 | [(0.2,0.35),(0.33,0.65)] | [(0.19,0.39),(0.31,0.61)] | [(0.18,0.43),(0.29,0.58)] | [(0.16,0.46),(0.27,0.54)] | [(0.15,0.5),(0.25,0.5)] |
| 4 | [(0.3,0.45),(0.28,0.55)] | [(0.28,0.48),(0.26,0.52)] | [(0.26,0.51),(0.24,0.49)] | [(0.24,0.54),(0.23,0.46)] | [(0.23,0.58),(0.21,0.43)] |
| 5 | [(0.4,0.55),(0.23,0.45)] | [(0.38,0.58),(0.21,0.43)] | [(0.35,0.6),(0.2,0.4)] | [(0.33,0.63),(0.19,0.38)] | [(0.3,0.65),(0.18,0.35)] |
| 6 | [(0.5,0.65),(0.18,0.35)] | [(0.47,0.67),(0.17,0.33)] | [(0.44,0.69),(0.16,0.31)] | [(0.41,0.71),(0.15,0.29)] | [(0.38,0.73),(0.14,0.28)] |
| 7 | [(0.6,0.75),(0.13,0.25)] | [(0.56,0.76),(0.12,0.24)] | [(0.53,0.78),(0.11,0.23)] | [(0.49,0.79),(0.11,0.21)] | [(0.45,0.8),(0.1,0.2)] |
| 8 | [(0.7,0.85),(0.08,0.15)] | [(0.66,0.86),(0.07,0.14)] | [(0.61,0.86),(0.07,0.14)] | [(0.57,0.87),(0.07,0.13)] | [(0.53,0.88),(0.06,0.13)] |
| 9 | [(0.8,0.95),(0.03,0.05)] | [(0.75,0.95),(0.03,0.05)] | [(0.7,0.95),(0.03,0.05)] | [(0.65,0.95),(0.03,0.05)] | [(0.6,0.95),(0.03,0.05)] |
| Rating | |||||
|---|---|---|---|---|---|
| 1 | [(0,0.15),(0.43,0.85)] | [(0,0.2),(0.4,0.8)] | [(0,0.25),(0.38,0.75)] | [(0,0.3),(0.35,0.7)] | [(0,0.35),(0.33,0.65)] |
| 2 | [(0.16,0.31),(0.35,0.69)] | [(0.15,0.35),(0.33,0.65)] | [(0.14,0.39),(0.31,0.61)] | [(0.13,0.43),(0.29,0.57)] | [(0.12,0.47),(0.27,0.53)] |
| 3 | [(0.32,0.47),(0.27,0.53)] | [(0.3,0.5),(0.25,0.5)] | [(0.28,0.53),(0.24,0.47)] | [(0.26,0.56),(0.22,0.44)] | [(0.24,0.59),(0.21,0.41)] |
| 4 | [(0.48,0.63),(0.19,0.37)] | [(0.45,0.65),(0.18,0.35)] | [(0.42,0.67),(0.17,0.33)] | [(0.39,0.69),(0.16,0.31)] | [(0.36,0.71),(0.15,0.29)] |
| 5 | [(0.64,0.79),(0.11,0.21)] | [(0.6,0.8),(0.1,0.2)] | [(0.56,0.81),(0.1,0.19)] | [(0.52,0.82),(0.09,0.18)] | [(0.48,0.83),(0.09,0.17)] |
| 6 | [(0.8,0.95),(0.03,0.05)] | [(0.75,0.95),(0.03,0.05)] | [(0.7,0.95),(0.03,0.05)] | [(0.65,0.95),(0.03,0.05)] | [(0.6,0.95),(0.03,0.05)] |
| 0.15 | 0.004 | 0.002 | 0.002 | 0.006 | 0.862 | 0.734 | 0.438 | 1.283 | 0.767 |
| 0.20 | 0.003 | 0.002 | 0.001 | 0.006 | 0.806 | 0.684 | 0.408 | 1.203 | 0.765 |
| 0.25 | 0.003 | 0.002 | 0.001 | 0.005 | 0.750 | 0.634 | 0.379 | 1.123 | 0.763 |
| 0.30 | 0.002 | 0.001 | 0.001 | 0.004 | 0.694 | 0.584 | 0.351 | 1.042 | 0.761 |
| 0.35 | 0.002 | 0.001 | 0.001 | 0.004 | 0.639 | 0.535 | 0.322 | 0.961 | 0.760 |
| 0.15 | 0.002 | 0.001 | 0.003 | 0.002 | 0.721 | 0.770 | 0.476 | 0.795 | 0.637 |
| 0.20 | 0.001 | 0.001 | 0.002 | 0.001 | 0.660 | 0.705 | 0.436 | 0.726 | 0.637 |
| 0.25 | 0.001 | 0.001 | 0.002 | 0.001 | 0.601 | 0.643 | 0.398 | 0.660 | 0.637 |
| 0.30 | 0.001 | 0.001 | 0.001 | 0.001 | 0.545 | 0.583 | 0.361 | 0.598 | 0.637 |
| 0.35 | 0.001 | 0.001 | 0.001 | 0.001 | 0.491 | 0.526 | 0.326 | 0.538 | 0.637 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ocampo, L.; Aro, J.L.; Evangelista, S.S.; Maturan, F.; Selerio, E., Jr.; Atibing, N.M.; Yamagishi, K. On K-Means Clustering with IVIF Datasets for Post-COVID-19 Recovery Efforts. Mathematics 2021, 9, 2639. https://doi.org/10.3390/math9202639
Ocampo L, Aro JL, Evangelista SS, Maturan F, Selerio E Jr., Atibing NM, Yamagishi K. On K-Means Clustering with IVIF Datasets for Post-COVID-19 Recovery Efforts. Mathematics. 2021; 9(20):2639. https://doi.org/10.3390/math9202639
Chicago/Turabian StyleOcampo, Lanndon, Joerabell Lourdes Aro, Samantha Shane Evangelista, Fatima Maturan, Egberto Selerio, Jr., Nadine May Atibing, and Kafferine Yamagishi. 2021. "On K-Means Clustering with IVIF Datasets for Post-COVID-19 Recovery Efforts" Mathematics 9, no. 20: 2639. https://doi.org/10.3390/math9202639
APA StyleOcampo, L., Aro, J. L., Evangelista, S. S., Maturan, F., Selerio, E., Jr., Atibing, N. M., & Yamagishi, K. (2021). On K-Means Clustering with IVIF Datasets for Post-COVID-19 Recovery Efforts. Mathematics, 9(20), 2639. https://doi.org/10.3390/math9202639