
Improved Multi-Scale Deep Integration Paradigm for Point and Interval Carbon Trading Price Forecasting

Abstract
:1. Introduction
- (A)
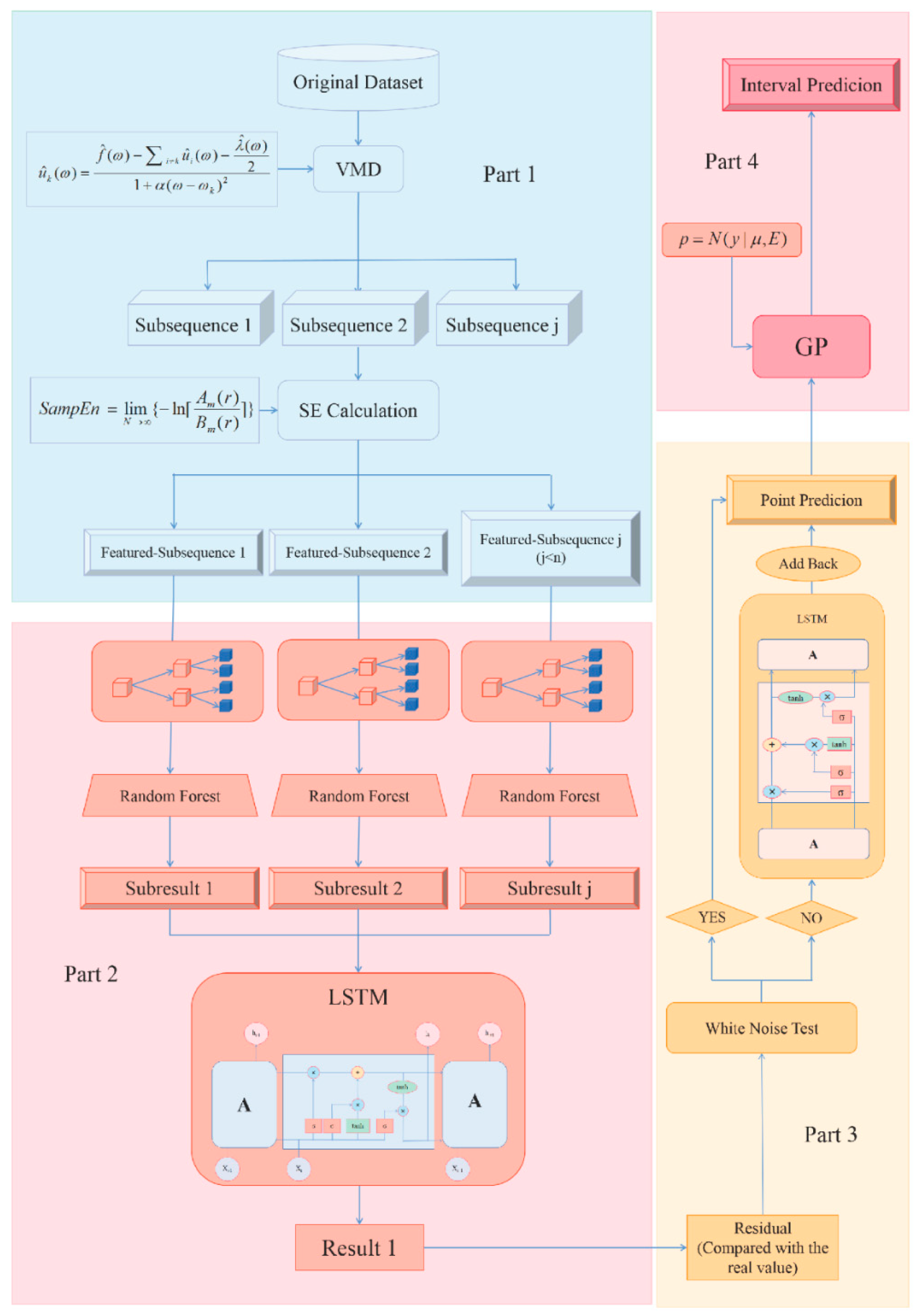
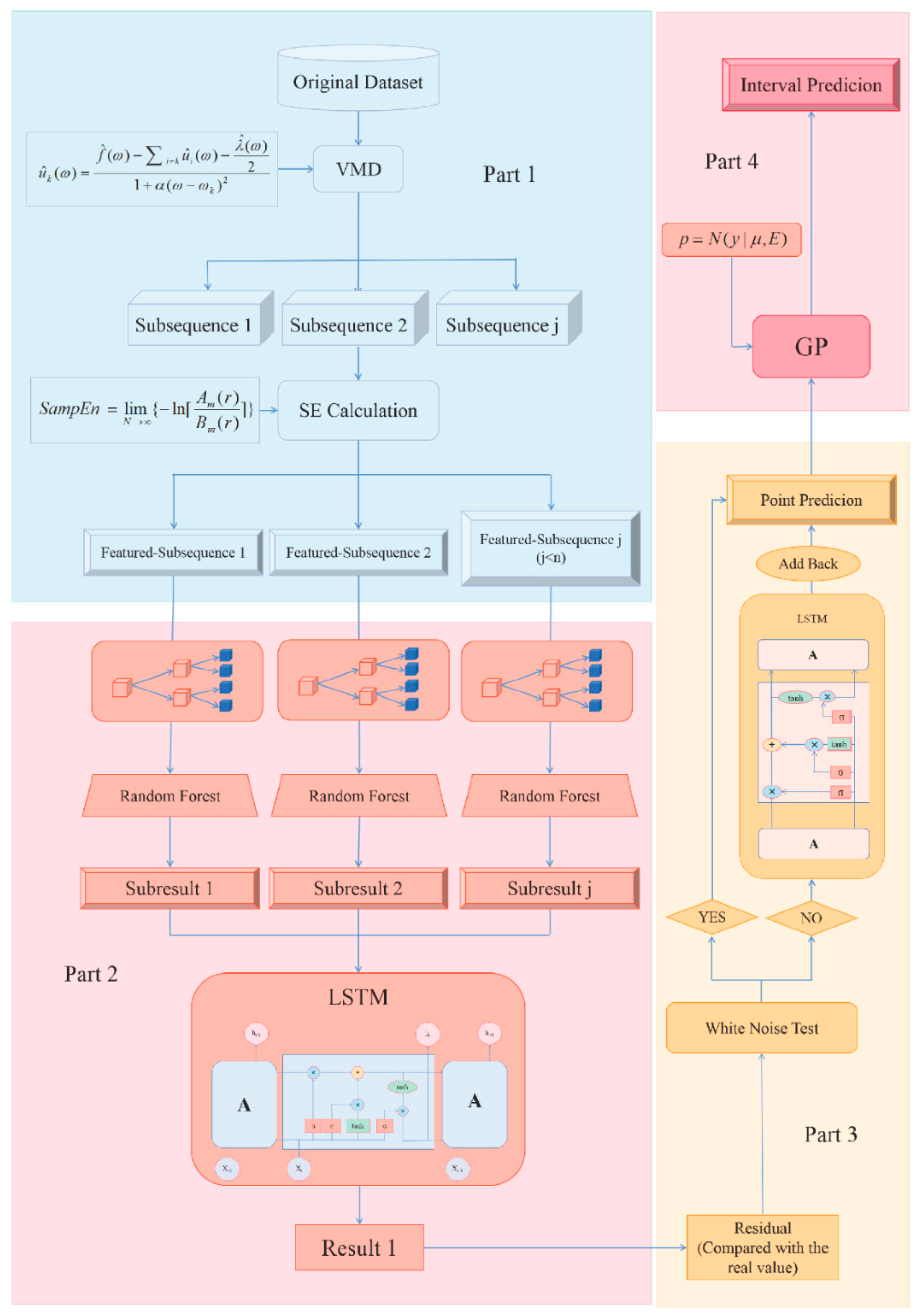
- Instead of carrying out research on the original data series, this paper decomposes the series first, in this way, the features of the series are separated, making the process that follows more targeted. Moreover, some sub-sequences can include similar features, there is no need to divide them too much, so the feature reconstruction process will also be included. In the proposed model, VMD combined with SE not only decomposes the series but also reconstructs the features. These methods can be seen as a system which performs the feature extraction and noise elimination work;
- (B)
- The proposed model applies the two-step learning process which includes random forest and LSTM rather than simple one-step learning or simple linear accumulation for they will usually leave the problem of messy learning or incomplete learning. The two-step nonlinear learning will make the learning process more targeted and also more complete;
- (C)
- The residual will also be seen as an important part of the whole process which goes through the LSTM to do the correction work. This means the residual will be added back after LSTM process to the first prediction result and in this way, the final prediction result will be obtained. Paying attention to the residual series will capture the useful information left, which shows the effort to grasp the important features as much as possible;
- (D)
- Many existing work will be satisfied merely with the point prediction result but this brings high uncertainty and low fault tolerance. As a result, this paper reflects the idea of interval estimate, which shows great improvement in the fault tolerance.
2. Related Methodology
2.1. Variational Mode Decomposition
2.2. Random Forest
- (1)
- If the size of the training set is , for each tree, training samples are taken from the training randomly and with replacement. As the training set of the tree, it is repeated K times to generate sets of training sample sets.
- (2)
- If the sample dimension of each feature is , specify a constant which is smaller than , and randomly select features from the features.
- (3)
- Use features to maximize the growth of each tree with no pruning process.
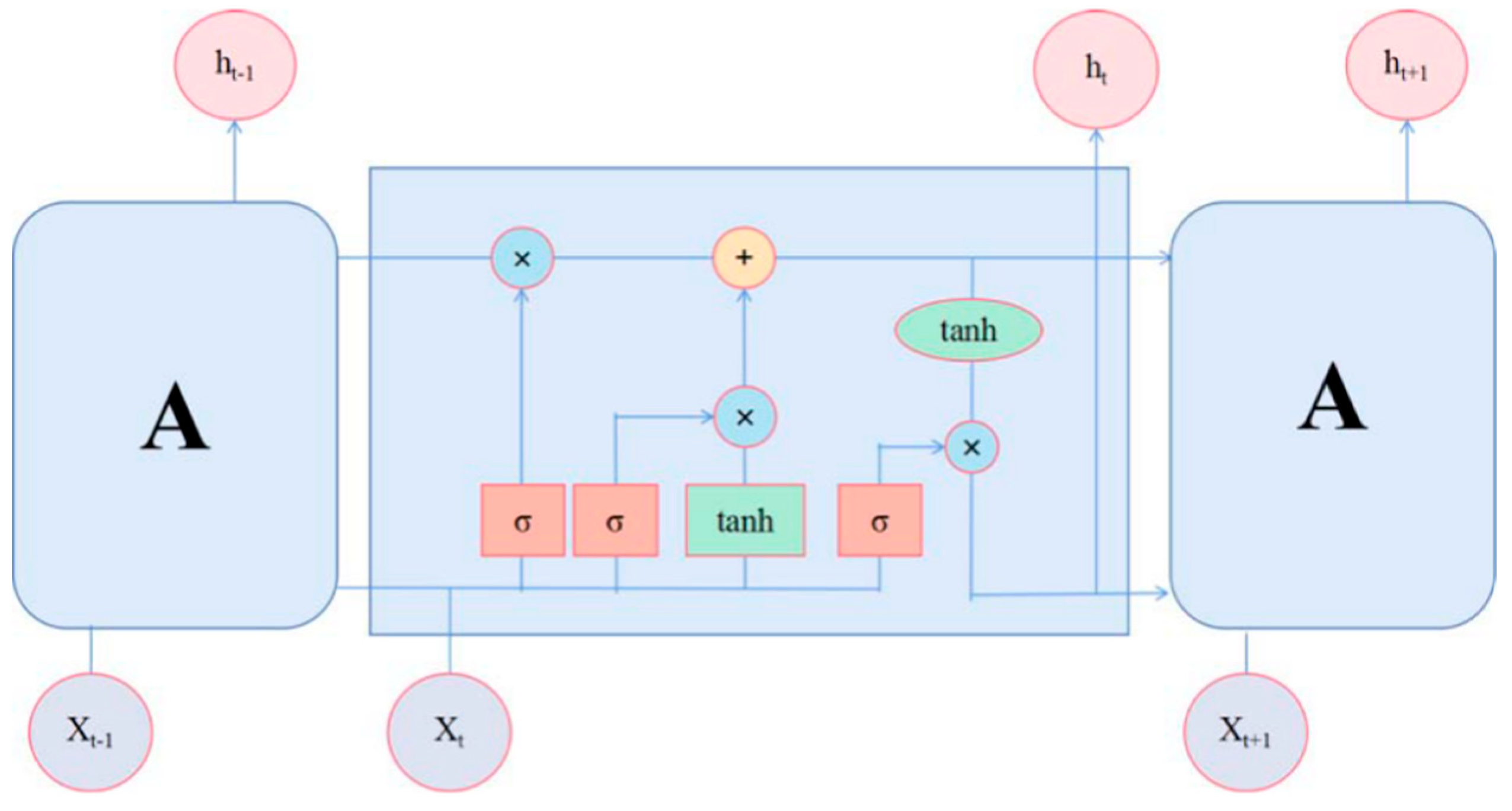
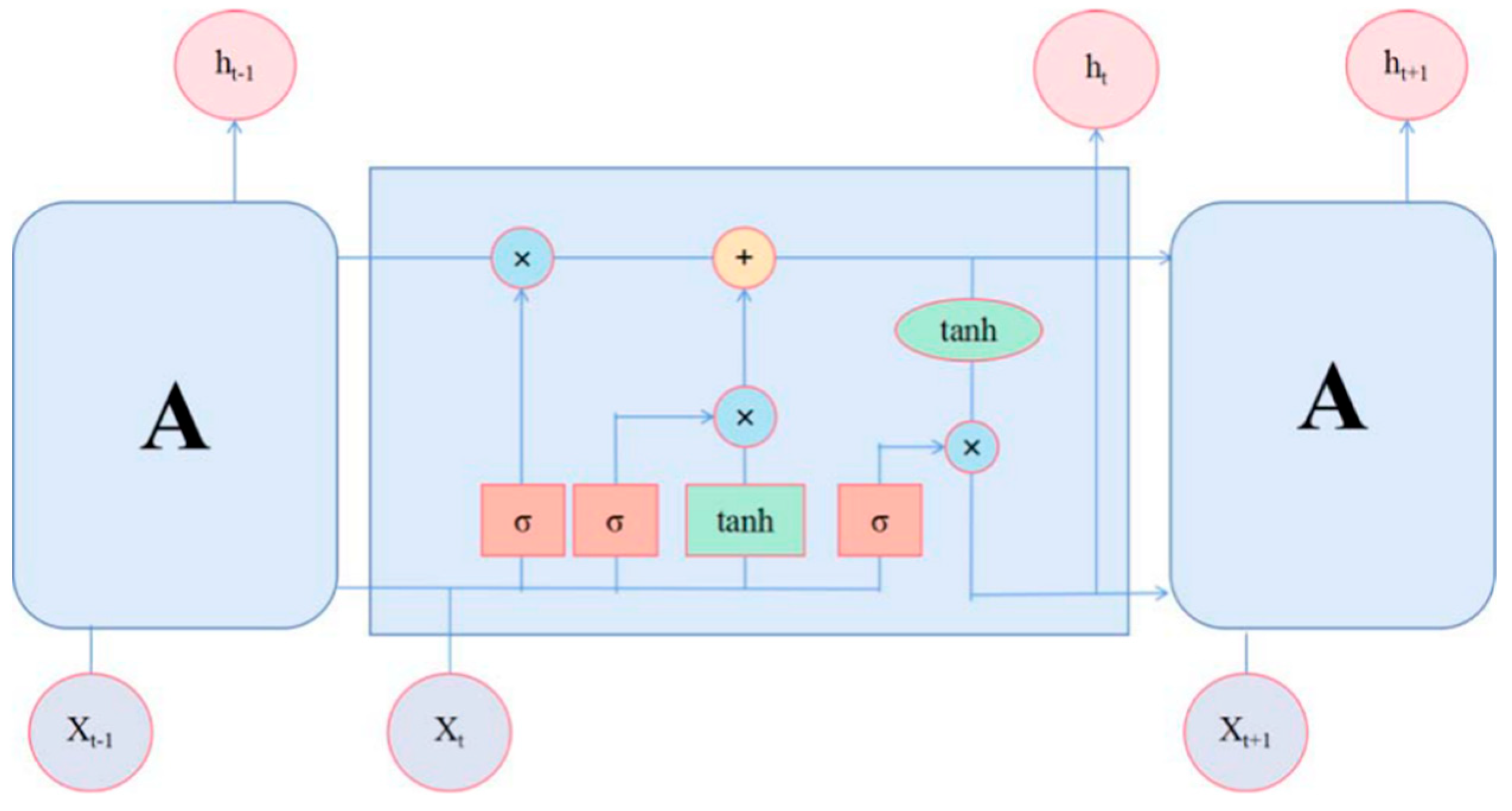
2.3. Long-Short Term Memory
- (1)
- First, assume as the value of the candidate memory cell at time ; are the corresponding weight matrix and the corresponding bias to the cell, then there is:
- (2)
- Calculate the value of input gate :
- (3)
- Calculate the value of forget gate :
- (4)
- Calculate the value of the current memory cell :
- (5)
- Calculate the value of output gate :
- (6)
- Then the general output of LSTM can be calculated:
2.4. Gaussian Process
3. Proposed Model
4. Case Study
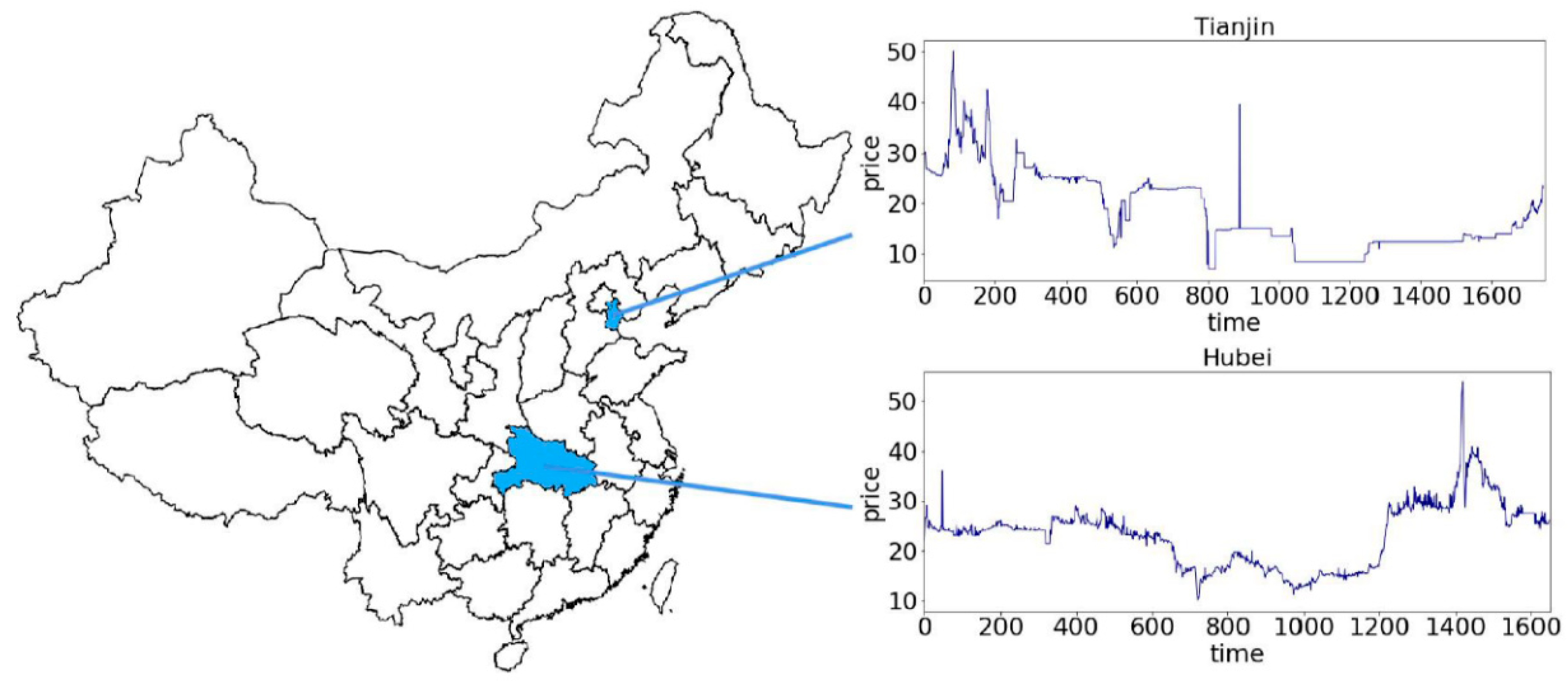
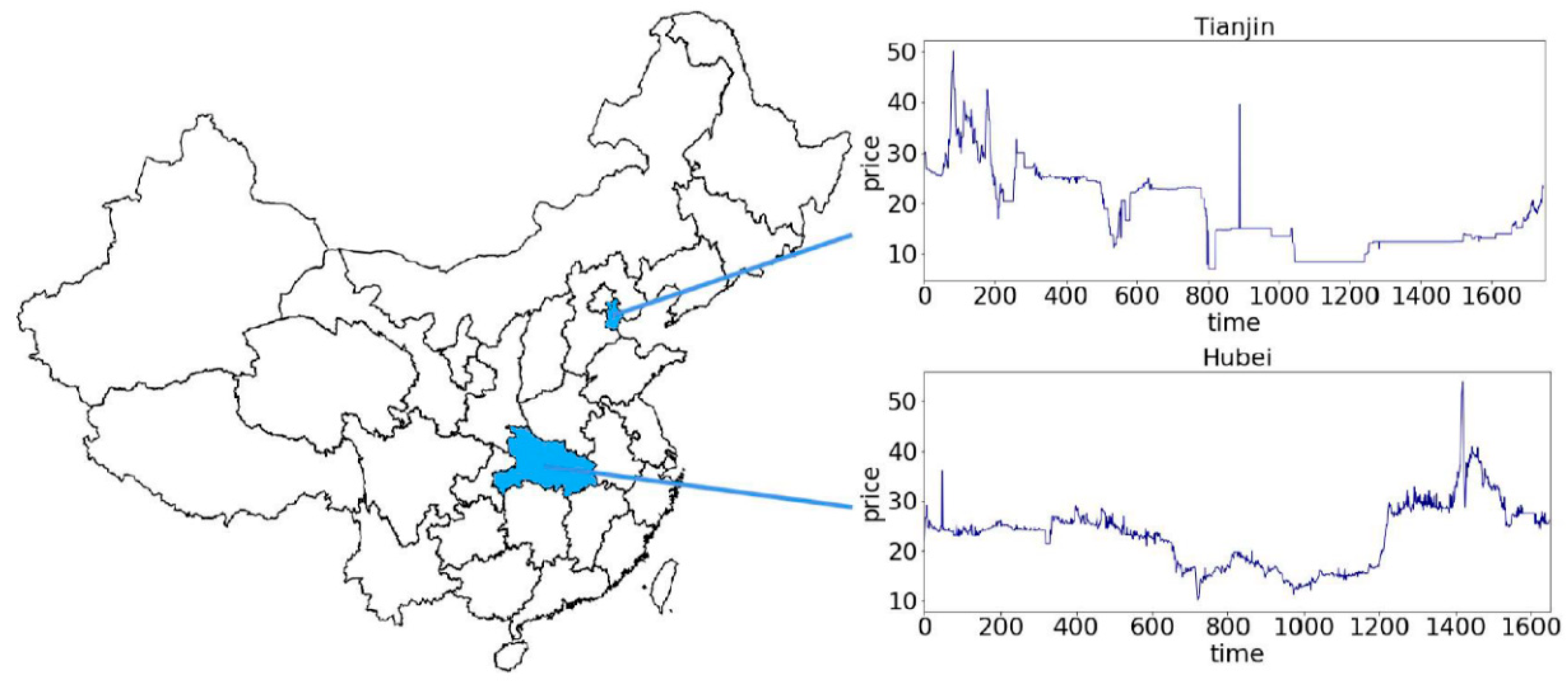
4.1. Data Collection
4.2. Evaluation Criteria
4.3. Point Prediction
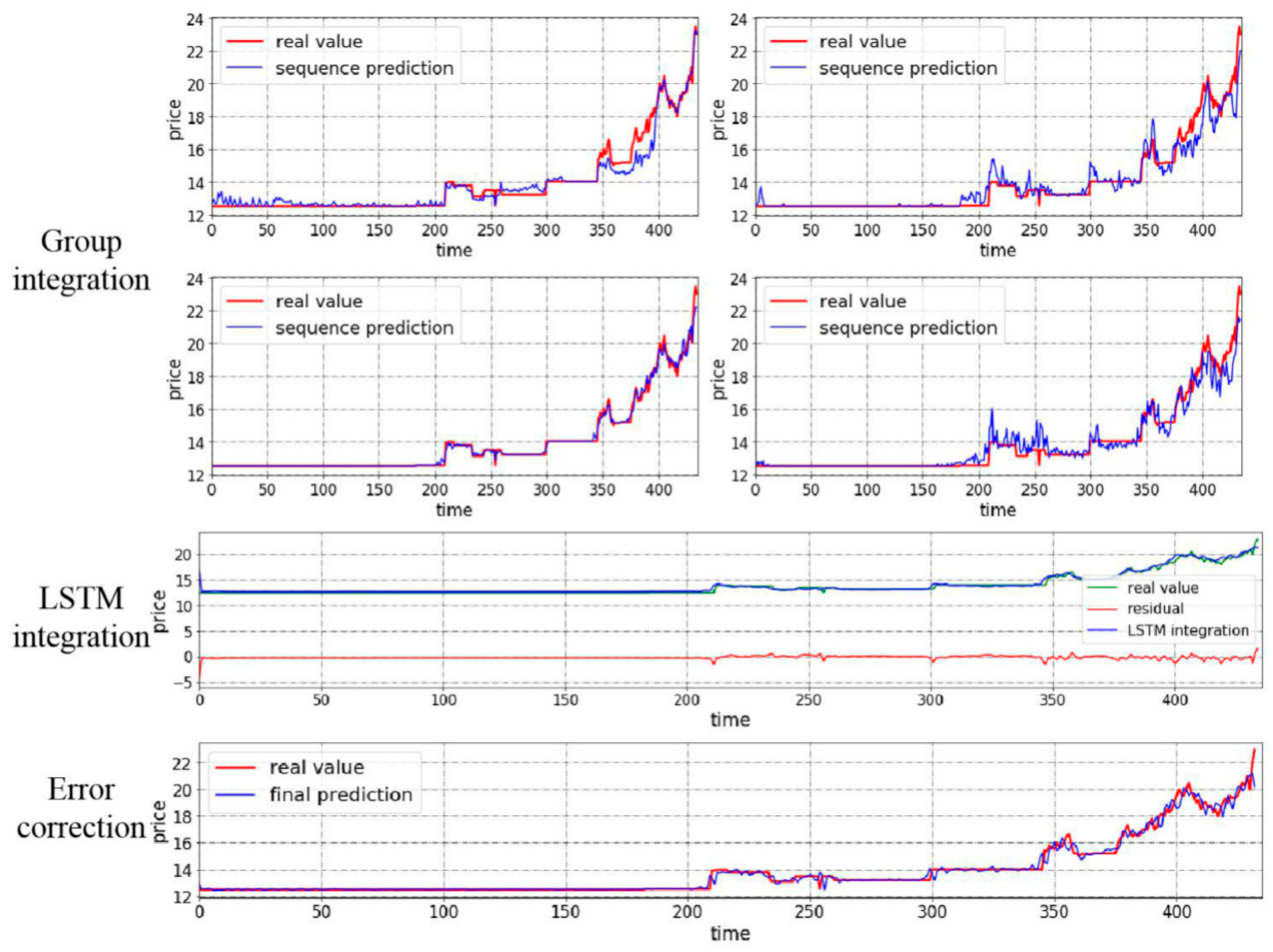
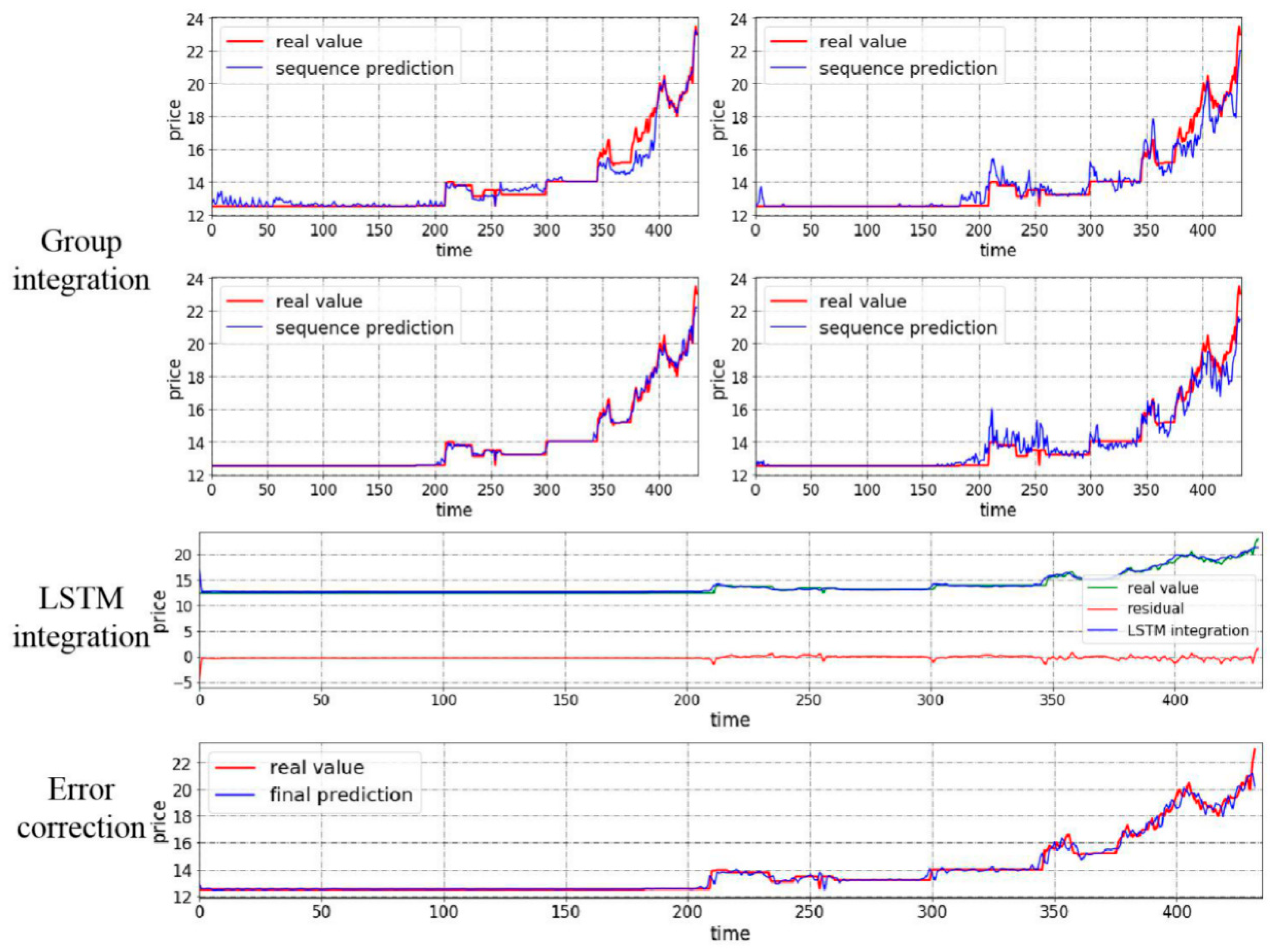
4.3.1. Case I: Test with Closing Price from Tianjin Market
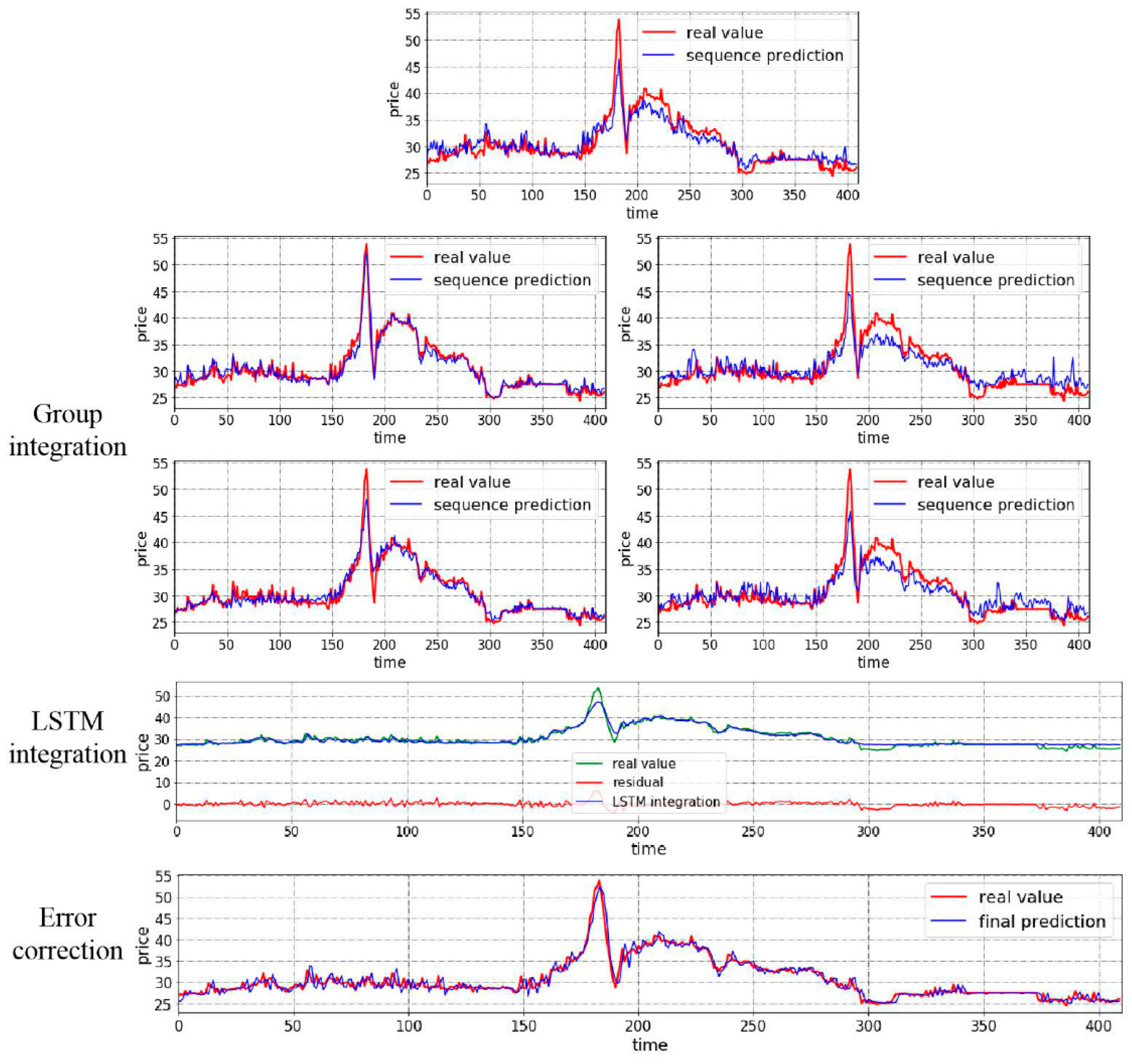
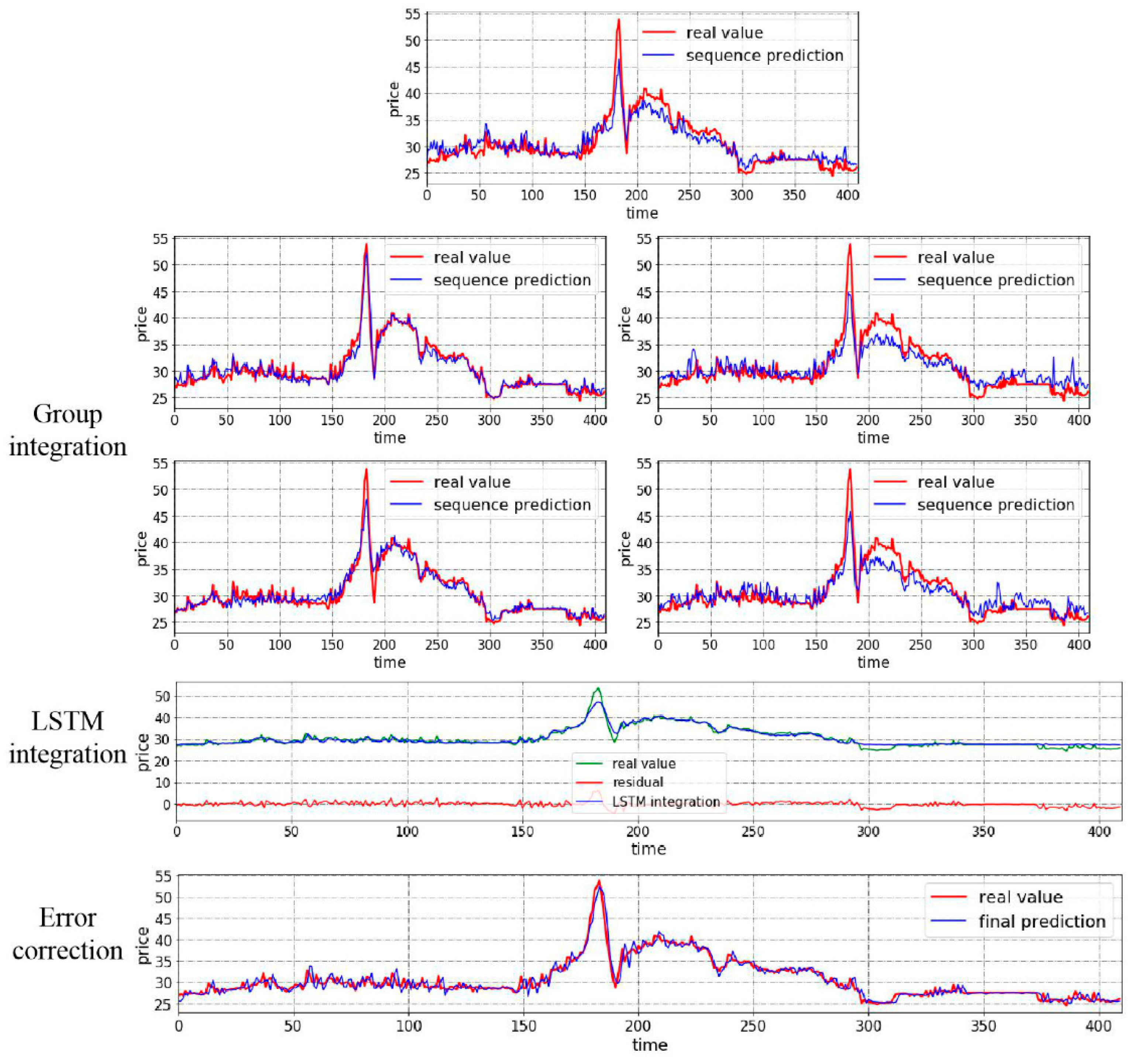
4.3.2. Case II: Test with Closing Price from Hubei Market
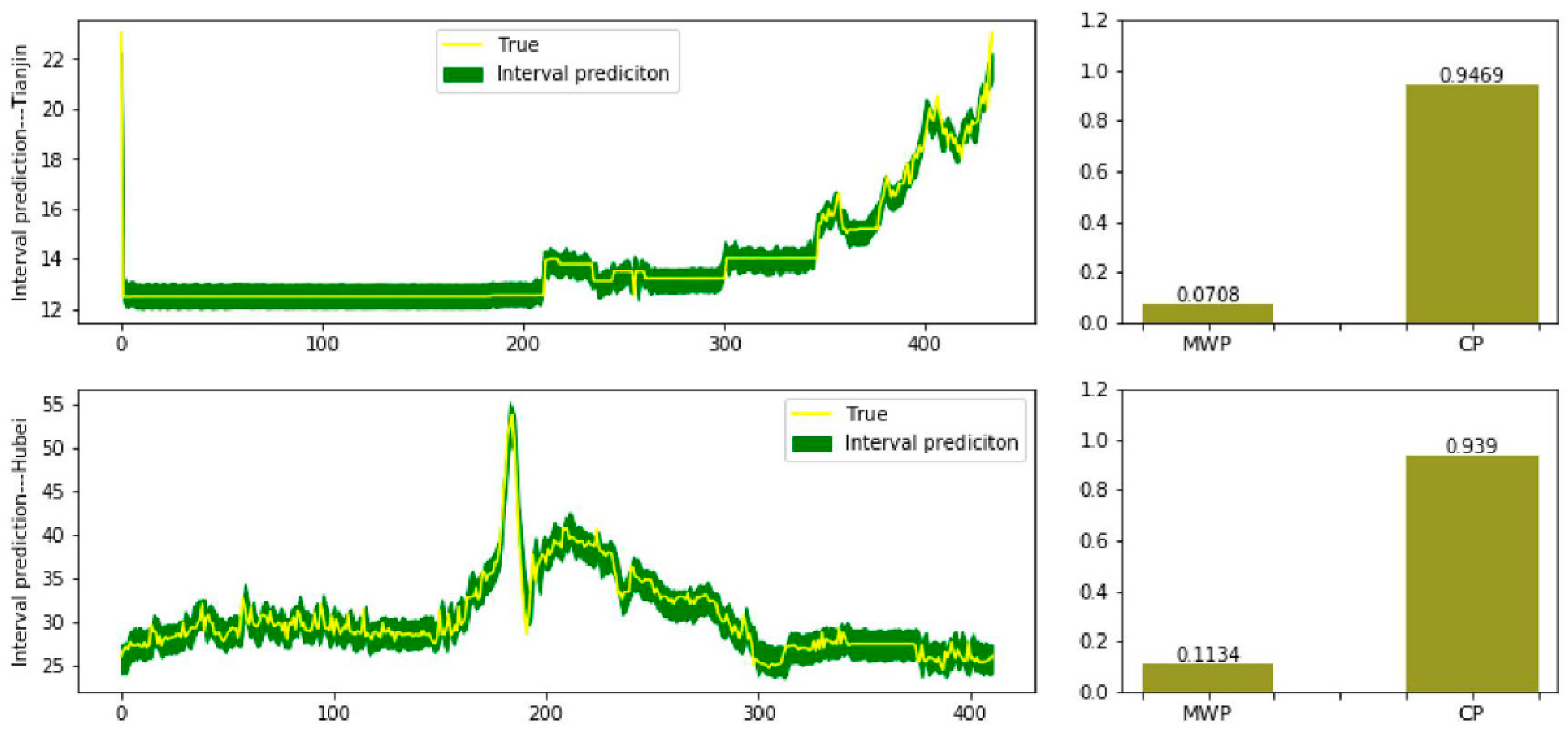
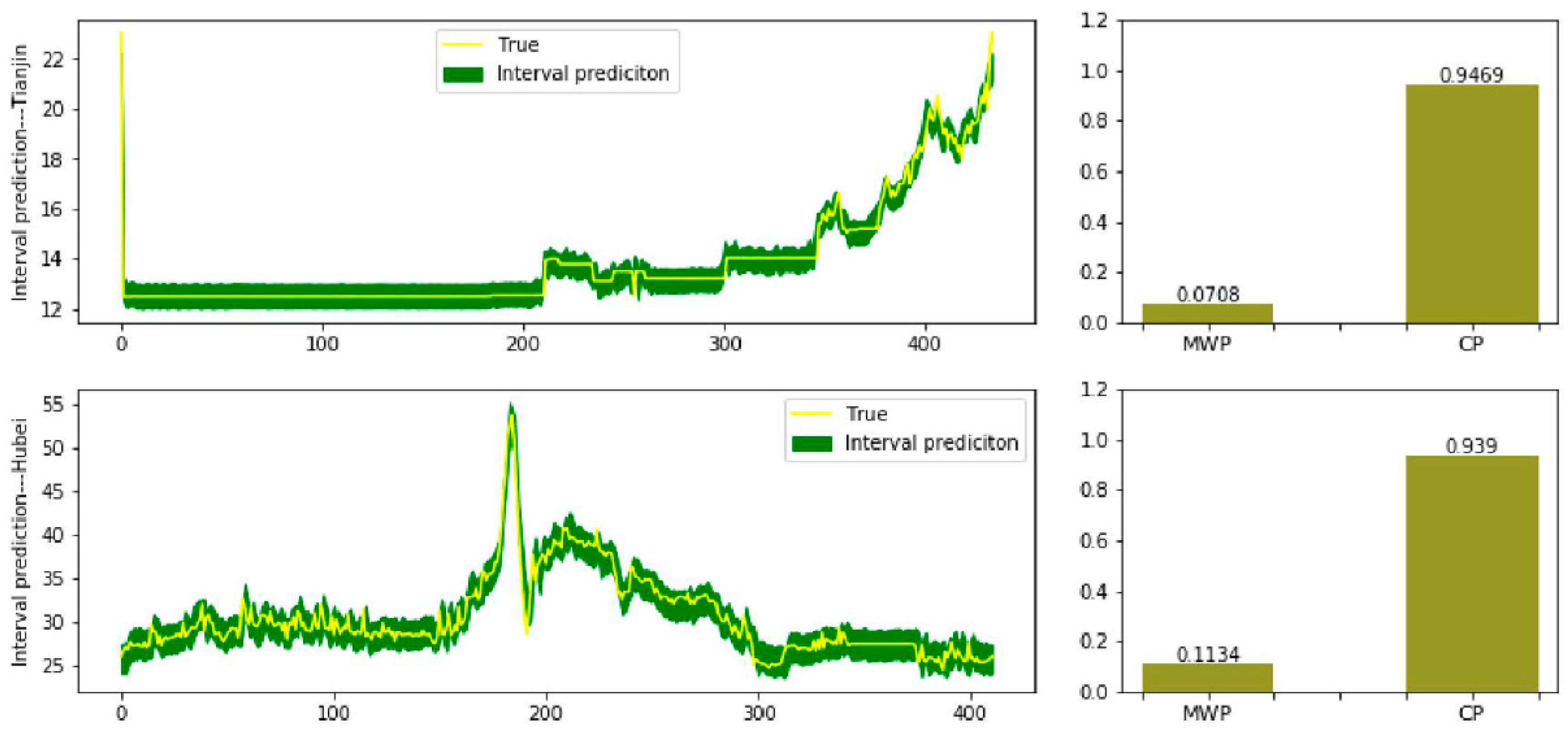
4.4. Interval Prediction
5. Comparison Model and Discussion
5.1. Comparison Model
5.2. Discussion
- (1)
- To start with, the prediction ability of three nonlinear integration tools: BP, random forest, and LSTM are compared together especially to demonstrate the accuracy in point prediction. Seen from the table, BP does have satisfying predicting ability in that though the MAE of two cases are 0.05, 0.09 separately, no larger than 0.1, other measures, RMSE and MAPE, are far from satisfaction. While for random forest and LSTM, not only are their RMSE values below 0.1, but their MAPE values are also controlled under 20%. More specifically, the MAPE of BP in the two cases are 35.47% and 30.25%, random forest can reduce them to 11.68% and 7.9%. Even though the predicting ability of LSTM is relatively weaker than random forest, but compared to BP, LSTM can still reduce the MAPE values by 23.87% and 13.78%. Meanwhile, this experiment can still prove the accuracy of nonlinear integration methods. So, it is suitable for the proposed model to include random forest and LSTM.
- (2)
- Focusing on the first three experiments, when we have found out that BP shows the worst performance, it needs to be seen what differences do they have compared to the proposed model. The three single model applies the one-step nonlinear integration while the proposed model uses the two-step nonlinear integration. Seen from the results, clearly, the predicting ability shows great difference. In case 1, MAPE value goes up by 34.52%, 10.73%, and 10.65% in the one-step BP, one-step random forest, and one-step LSTM. This is the same in case 2, MAPE value inclines by 11.2 times, 2.93 times and 6.1 times separately. Meanwhile, RMSE and MAE values are affected. Only the proposed model can control them under 0.01 in case 1 and 0.015 in case 2. For certain, the accuracy of simple one-step nonlinear integration is not that bad (MAPE in case 2 of one-step random forest), however, we cannot be too careful when it comes to the precise prediction. That is why this paper applies the two-step nonlinear integration.
- (3)
- Then, many existing studies usually carry out research on the original dataset without decomposition or feature reconstruction. In the proposed model, these two jobs are realized by the VMD-SE process; so, the second experiment eliminates VMD-SE process to prove the significance of decomposition and feature reconstruction. Drawn from the table, RMSE, MAE, and MAPE values show increases, the RMSE value in case 2 is four times and more, MAE value in case 1 is 20 times the value of the proposed model’s; for MAPE values, they increase by 12.76% and 12.08% separately which means the predicting ability is affected; for the interval prediction, even CP value increases in case 1, but for the MWP value of it, the value is 58 times larger, which means the interval contains more uncertainty; while in case 2, CP value shows a great decrease even if MWP value is satisfying, this means even the interval is reliable in some way, the sample point is not in the interval which is meaningless to study the interval. Thus, it is beyond argument that the decomposition or feature reconstruction process can obviously raise the predicting accuracy which means the arrangement of the proposed model is more reliable.
- (4)
- In the meantime, the third experiment is carried out to demonstrate the significance of residual correction. In the VMD-SE-random forest-LSTM model, the residual correction process is eliminated. RMSE and MAE values in the two cases show no great differences but, apparently, MAPE value goes higher in case 1, increased by 0.84%. This means the residual contains much unextracted information. For the interval prediction, CP values even though show a slight increase in case 1, however, what needs to be emphasized is the MWP value. It has been stressed above that MWP stands for the width of the interval, larger MWP value means the interval is bigger which is not the best interval estimate, that is, the gap is too wide to lower the fault tolerance to show the decline of uncertainty. The MWP value is 59 more times larger than that in the proposed model in case 1. Then, it may seem to be performing well in the point prediction of case 2, but like in the last experiment, CP value is disappointing, which goes down by 0.86, losing the significance of interval prediction. Many existing works will usually tend to ignore the residual series, however, doing this means even there is valuable information in the residual series, the information will not be paid attention to. That is why this paper focuses on the residual as well, showing effort to grasp the information as much as possible, making the whole process of the proposed model more persuasive.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Sample Entropy
Appendix A.2. White Noise Test
References
- Fan, J.; Todorova, N. Dynamics of China’s carbon prices in the pilot trading phase. Appl. Energy 2017, 208, 1452–1467. [Google Scholar] [CrossRef] [Green Version]
- Ivanovski, K.; Churchill, S. Convergence and determinants of greenhouse gas emissions in Australia: A regional analysis. Energy Econ. 2020, 92, 104971. [Google Scholar] [CrossRef]
- Chao, Q.; Yongrok, C. A study on the CO2 marginal abatement cost of coal-fueled power plants: Is the current price of China pilot carbon emission trading market rational? Carbon Manag. 2020, 11, 303–314. [Google Scholar]
- Fang, C.; Ma, T. Stylized agent-based modeling on linking emission trading systems and its implications for China’s practice. Energy Econ. 2020, 92, 104916. [Google Scholar] [CrossRef]
- Yu, X.; Dong, Z.; Zhou, D.; Sang, X.; Chang, C.; Huang, X. Integration of tradable green certificates trading and carbon emissions trading: How will Chinese power industry do? J. Clean. Prod. 2021, 279, 123485. [Google Scholar] [CrossRef]
- Liu, H.; Shen, L. Forecasting carbon price using empirical wavelet transform and gated recurrent unit neural network. Carbon Manag. 2019, 11, 25–37. [Google Scholar] [CrossRef]
- Zhu, B.; Han, D.; Wang, P.; Wu, Z.; Zhang, T.; Wei, Y. Forecasting carbon price using empirical mode decomposition and evolutionary least squares support vector regression. Appl. Energy 2017, 191, 521–530. [Google Scholar] [CrossRef] [Green Version]
- Qin, Q.; He, H.; Li, L.; He, L. A Novel Decomposition-Ensemble Based Carbon Price Forecasting Model Integrated with Local Polynomial Prediction. Comput. Econ. 2020, 55, 1249–1273. [Google Scholar] [CrossRef]
- Tian, C.; Hao, Y. Point and interval forecasting for carbon price based on an improved analysis-forecast system. Appl. Math. Model. 2020, 79, 126–144. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, C.; Sun, C. Carbon pricing prediction based on wavelet transform and K-ELM optimized by bat optimization algorithm in China ETS: The case of Shanghai and Hubei carbon markets. Carbon Manag. 2018, 9, 605–617. [Google Scholar]
- Wu, Q.; Liu, Z. Forecasting the carbon price sequence in the Hubei emissions exchange using a hybrid model based on ensemble empirical mode decomposition. Energy Sci. Eng. 2020, 8, 2708–2721. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Sun, C.; Li, Z. A Hybrid Carbon Price Forecasting Model with External and Internal Influencing Factors Considered Comprehensively: A Case Study from China. Pol. J. Environ. Stud. 2020, 29, 3305–3316. [Google Scholar] [CrossRef]
- Huang, Y.; He, Z. Carbon price forecasting with optimization prediction method based on unstructured combination. Sci. Total Environ. 2020, 725, 138350. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, G.; Li, M.; Yin, H. Variational mode decomposition denoising combined the detrended fluctuation analysis. Signal Process 2016, 125, 349–364. [Google Scholar] [CrossRef]
- Sun, W.; Huang, C. A carbon price prediction model based on secondary decomposition algorithm and optimized back propagation neural network. J. Clean. Prod. 2020, 243, 118671. [Google Scholar] [CrossRef]
- Zhu, J.; Wu, P.; Chen, H.; Liu, J.; Zhou, L. Carbon price forecasting with variational mode decomposition and optimal combined model. Phys. A 2019, 519, 140–158. [Google Scholar] [CrossRef]
- Singh, S.N.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar]
- Mbah, T.J.; Ye, H.W.; Zhang, J.H.; Long, M. Using LSTM and ARIMA to Simulate and Predict Limestone Price Variations. Min. Met. Explor. 2021, 38, 913–926. [Google Scholar]
- Zhang, J.; Li, D.; Hao, Y.; Tan, Z. A hybrid model using signal processing technology, econometric models and neural network for carbon spot price forecasting. J. Clean. Prod. 2018, 204, 958–964. [Google Scholar] [CrossRef]
- Dutta, A. Modeling and forecasting the volatility of carbon emission market: The role of outliers, time-varying jumps and oil price risk. J. Clean. Prod. 2018, 172, 2773–2781. [Google Scholar] [CrossRef]
- Sanin, M.E.; Violante, F.; Mansanet-Bataller, M. Understanding volatility dynamics in the EU-ETS market. Energy Policy 2018, 82, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Zeitlberger, A.; Brauneis, A. Modeling carbon spot and futures price returns with GARCH and Markov switching GARCH models: Evidence from the first commitment period (2008–2012). Cent. Eur. J. Oper. Res. 2016, 1, 149–176. [Google Scholar] [CrossRef]
- Zainuddin, N.; Lola, M.; Djauhari, M.; Yusof, F.; Ramlee, M.; Deraman, A.; Ibrahim, Y.; Abdullah, M. Improvement of time forecasting models using a novel hybridization of bootstrap and double bootstrap artificial neural networks. Appl. Soft Comput. 2019, 84, 105676. [Google Scholar] [CrossRef]
- Jamous, R.; ALRahhal, H.; El-Darieby, M. A New ANN-Particle Swarm Optimization with Center of Gravity (ANN-PSOCoG) Prediction Model for the Stock Market under the Effect of COVID-19. Sci. Program. 2021, 2021, 6656150. [Google Scholar]
- Liu, W.P.; Wang, C.Z.; Li, Y.G.; Liu, Y.S.; Huang, K.K. Ensemble forecasting for product futures prices using variational mode decomposition and artificial neural networks. Chaos Soliton Fractals 2021, 146, 110822. [Google Scholar] [CrossRef]
- Wen, L.; Liu, Y. A Research about Beijing’s Carbon Emissions Based on the IPSO-BP Model. Environ. Prog. Sustain. Energy 2017, 36, 428–434. [Google Scholar] [CrossRef]
- Yu, R.; Gao, J.; Yu, M.; Lu, W.; Xu, T.; Zhao, M.; Zhang, J.; Zhang, R.; Zhang, Z. LSTM-EFG for wind power forecasting based on sequential correlation features. Futur. Gener. Comp. Syst. 2019, 93, 33–42. [Google Scholar] [CrossRef]
- Han, M.; Ding, L.; Zhao, X.; Kang, W. Forecasting carbon prices in the Shenzhen market, China: The role of mixed-frequency factors. Energy 2019, 171, 69–76. [Google Scholar] [CrossRef]
- Wei, S.; Wang, T.; Li, Y. Influencing factors and prediction of carbon dioxide emissions using factor analysis and optimized least squares support vector machine. Environ. Eng. 2017, 22, 175–185. [Google Scholar] [CrossRef]
- Qiao, W.; Lu, H.; Zhou, G.; Azimi, M.; Yang, Q.; Tian, W. A hybrid algorithm for carbon dioxide emissions forecasting based on improved lion swarm optimizer. J. Clean. Prod. 2020, 244, 118612. [Google Scholar] [CrossRef]
- Zhu, B.; Ye, S.; Wang, P.; He, K.; Zhang, T.; Wei, Y. A novel multiscale nonlinear ensemble leaning paradigm for carbon price forecasting. Energy Econ. 2018, 70, 143–157. [Google Scholar] [CrossRef]
- Wen, L.; Cao, Y. Influencing factors analysis and forecasting of residential energy-related CO2 emissions utilizing optimized support vector machine. J. Clean. Prod. 2020, 250, 119492. [Google Scholar] [CrossRef]
- Fan, Y.Q.; Sun, Z.H. CPI Big Data Prediction Based on Wavelet Twin Support Vector Machine. Int. J. Pattern Recogn. 2021, 35, 2159013. [Google Scholar] [CrossRef]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized Random Forests. Ann. Stat. 2019, 47, 1148–1178. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Ma, X.; Huang, K.; Azimi, M. Carbon trading volume and price forecasting in China using multiple machine learning models. J. Clean. Prod. 2020, 249, 119386. [Google Scholar] [CrossRef]
- Sun, Q. Research on the driving factors of energy carbon footprint in Liaoning province using Random Forest algorithm. Appl. Ecol. Environ. Res. 2019, 17, 8381–8394. [Google Scholar] [CrossRef]
- Wen, L.; Yuan, X. Forecasting CO2 emissions in Chinas commercial department, through BP neural network based on random forest and PSO. Sci. Total Environ. 2020, 718, 137194. [Google Scholar] [CrossRef]
- Sharaf, M.; Hemdan, E.E.; El-Sayed, A.; El-Bahnasawy, N.A. StockPred: A framework for stock Price prediction. Multimed. Tools Appl. 2021, 80, 17923–17954. [Google Scholar] [CrossRef]
- Huang, Y.; Shen, L.; Liu, H. Grey relational analysis, principal component analysis and forecasting of carbon emissions based on long short-term memory in China. J. Clean. Prod. 2019, 209, 415–423. [Google Scholar] [CrossRef]
- Yang, S.; Chen, D.; Li, S.; Wang, W. Carbon price forecasting based on modified ensemble empirical mode decomposition and long short-term memory optimized by improved whale optimization algorithm. Sci. Total Environ. 2020, 716, 137117. [Google Scholar] [CrossRef]
- Yan, L. Forecasting Chinese carbon emissions based on a novel time series prediction method. Energy Sci. Eng. 2020, 8, 2274–2285. [Google Scholar]
- Karmiani, R.; Kazi, A.; Nambisan, A.; Shah, A.; Kamble, V. Comparison of Predictive Algorithms: Backpropagation, SVM, LSTM and Kalman Filter for Stock Market. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; Volume 2, pp. 228–234. [Google Scholar]
- Oliver Muncharaz, J. Comparing classic time series models and the LSTM recurrent neural network: An application to S&P 500 stocks. Financ. Mark. Valuat. 2020, 6, 137–148. [Google Scholar]
- Pan, S. Coal Price Prediction based on LSTM. J. Phys. Conf. Ser. 2021, 1802, 042055. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Criteria | Definition | Equation |
|---|---|---|
| MAE | Mean absolute error | |
| RMSE | Root mean square error | |
| MAPE | Mean absolute percentage error | |
| MWP | Mean width percentage | |
| CP | Coverage probability |
| Lag Order | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q-value | 53.77 | 69.83 | 89.75 | 109.92 | 124.32 | 133.41 | 143.91 | 153.78 | 162.8 | 168.49 | 172.72 | 177.45 |
| 0.004 | 0.10 | 0.35 | 0.71 | 1.15 | 1.64 | 2.17 | 2.73 | 3.33 | 3.94 | 4.58 | 5.23 |
| Random Forest | LSTM Integration | LSTM Residual Correction | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Min Samples Split | Batch Size | Neure | Look Back | Dropout | Seed | Batch Size | Neure | Look Back | Dropout | Seed |
| 2 | 30 | 5 | 2 | 0.001 | 5 | 30 | 10 | 2 | 0.1 | 8 |
| Lag Order | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q-value | 119.80 | 214.40 | 282.29 | 331.73 | 345.77 | 349.61 | 351.19 | 356.08 | 364.69 | 369.37 | 378.43 | 388.16 |
| 0.004 | 0.10 | 0.35 | 0.71 | 1.15 | 1.64 | 2.17 | 2.73 | 3.33 | 3.94 | 4.58 | 5.23 |
| Random Forest | LSTM Integration | LSTM Residual Correction | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Min Samples Split | Batch Size | Neure | Look Back | Dropout | Seed | Batch Size | Neure | Look Back | Dropout | Seed |
| 2 | 60 | 3 | 2 | 0.001 | 2 | 30 | 5 | 2 | 0.1 | 2 |
| Case Name | GP Parameters | ||
|---|---|---|---|
| Mean | Cov | Lik | |
| Case 1 | 1 | 3,1,2 | −1 |
| Case 2 | 1 | 3,2,1 | −2 |
| Model | Case | Measure | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | CP | MWP | ||
| Proposed Model | Tianjin | 0.003 | 0.001 | 0.95% | 0.95 | 0.07 |
| Hubei | 0.012 | 0.01 | 2.70% | 0.94 | 0.11 | |
| One-step BP | Tianjin | 0.05 | 0.05 | 35.47% | / | / |
| Hubei | 0.10 | 0.09 | 30.25% | / | / | |
| One-step random forest | Tianjin | 0.03 | 0.02 | 11.68% | / | / |
| Hubei | 0.02 | 0.02 | 7.90% | / | / | |
| One-step LSTM | Tianjin | 0.05 | 0.03 | 11.60% | / | / |
| Hubei | 0.06 | 0.04 | 16.47% | / | / | |
| Random forest -two-stage LSTM-GP | Tianjin | 0.02 | 0.02 | 13.71% | 1 | 4.07 |
| Hubei | 0.05 | 0.04 | 14.78% | 0.30 | 0.01 | |
| VMD-SE-random forest -one-stage LSTM-GP | Tianjin | 0.003 | 0.002 | 1.79% | 1 | 4.18 |
| Hubei | 0.01 | 0.01 | 2.74% | 0.08 | 0.01 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Qiu, S. Improved Multi-Scale Deep Integration Paradigm for Point and Interval Carbon Trading Price Forecasting. Mathematics 2021, 9, 2595. https://doi.org/10.3390/math9202595
Wang J, Qiu S. Improved Multi-Scale Deep Integration Paradigm for Point and Interval Carbon Trading Price Forecasting. Mathematics. 2021; 9(20):2595. https://doi.org/10.3390/math9202595
Chicago/Turabian StyleWang, Jujie, and Shiyao Qiu. 2021. "Improved Multi-Scale Deep Integration Paradigm for Point and Interval Carbon Trading Price Forecasting" Mathematics 9, no. 20: 2595. https://doi.org/10.3390/math9202595
APA StyleWang, J., & Qiu, S. (2021). Improved Multi-Scale Deep Integration Paradigm for Point and Interval Carbon Trading Price Forecasting. Mathematics, 9(20), 2595. https://doi.org/10.3390/math9202595