
Experiments with Fuzzy Methods for Forecasting Time Series as Alternatives to Classical Methods


Abstract
:1. Introduction
2. Data and Methods
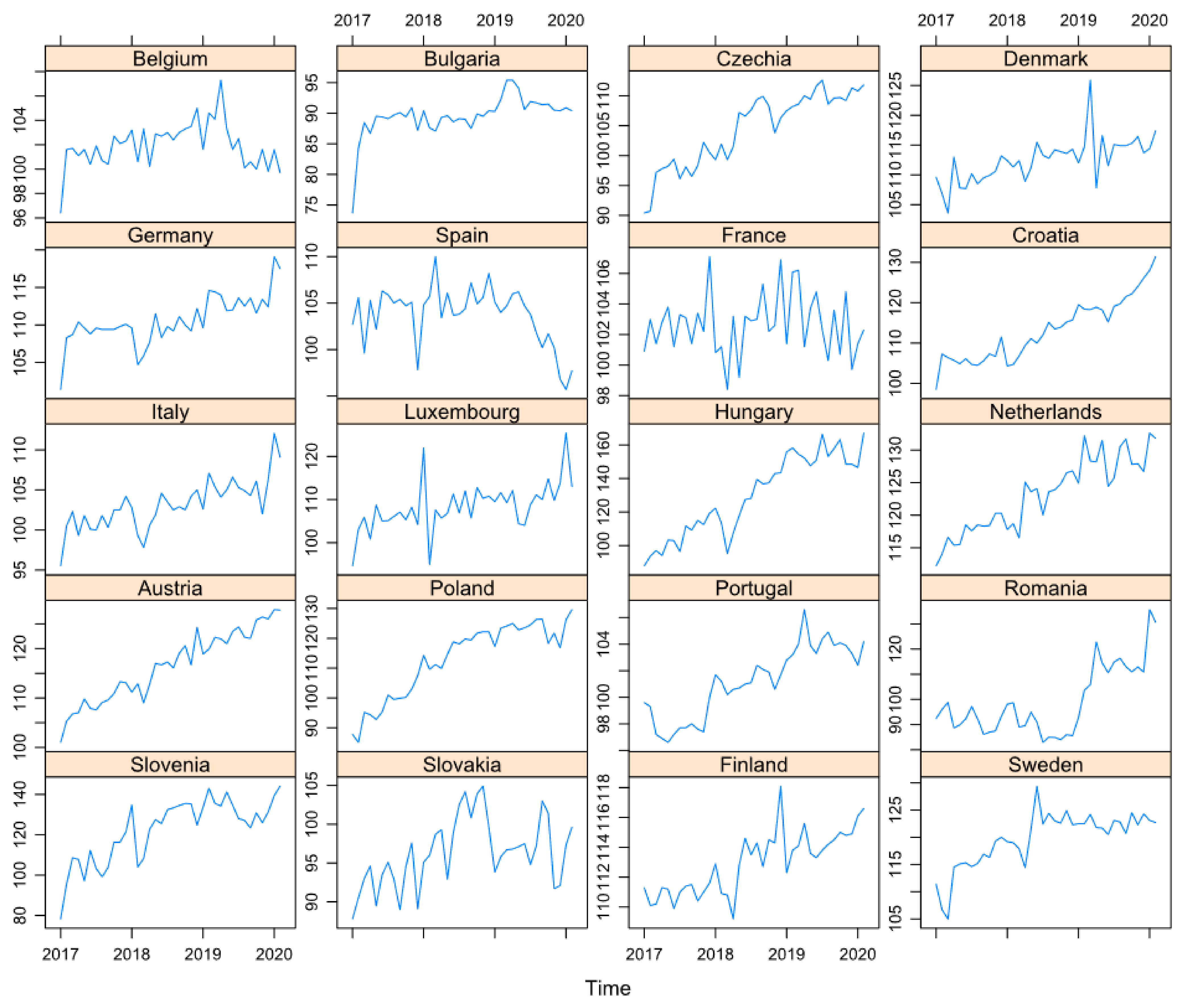
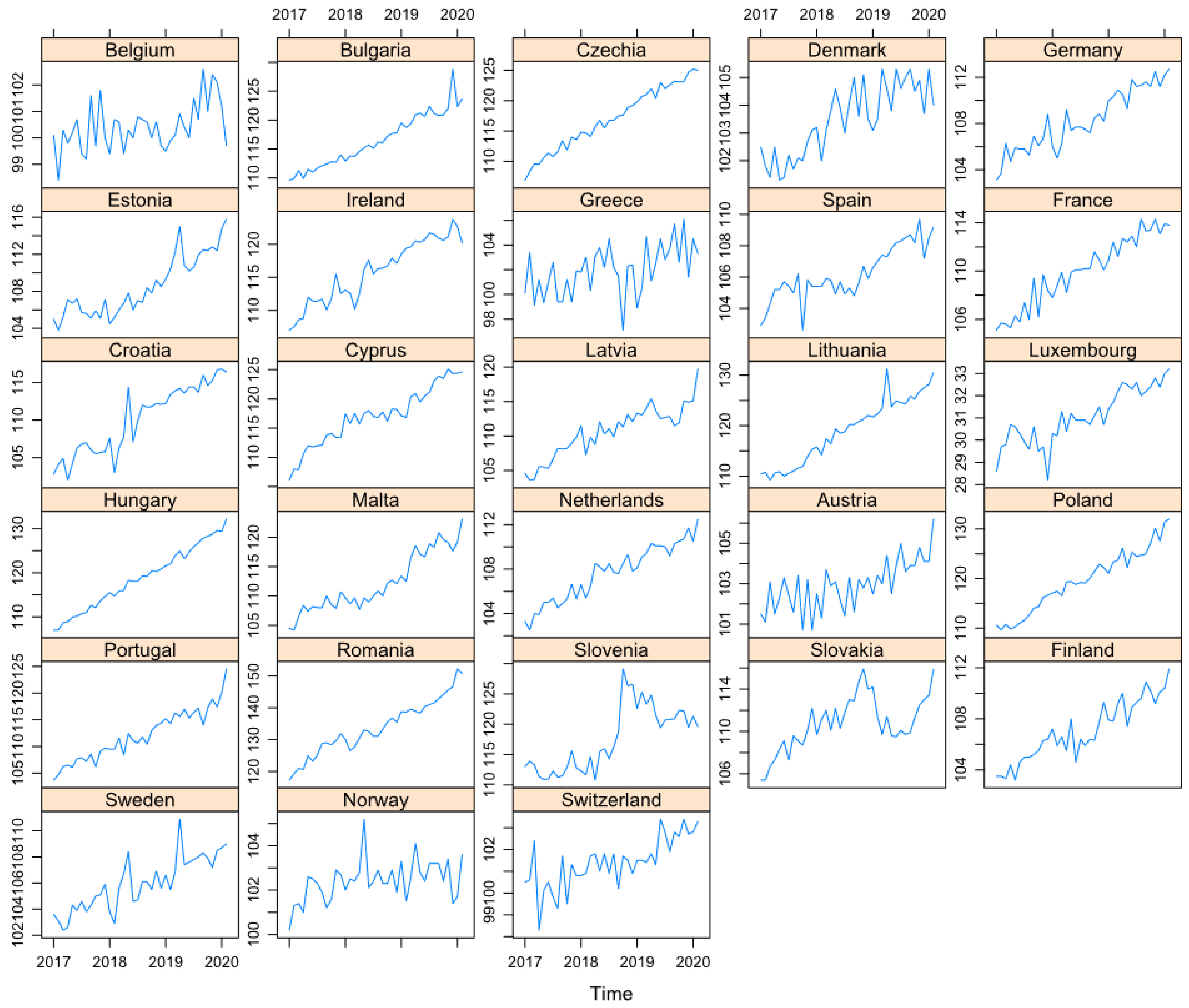
- The volume index of production in construction (2015 = 100), seasonally and calendar-adjusted, for 20 European countries;
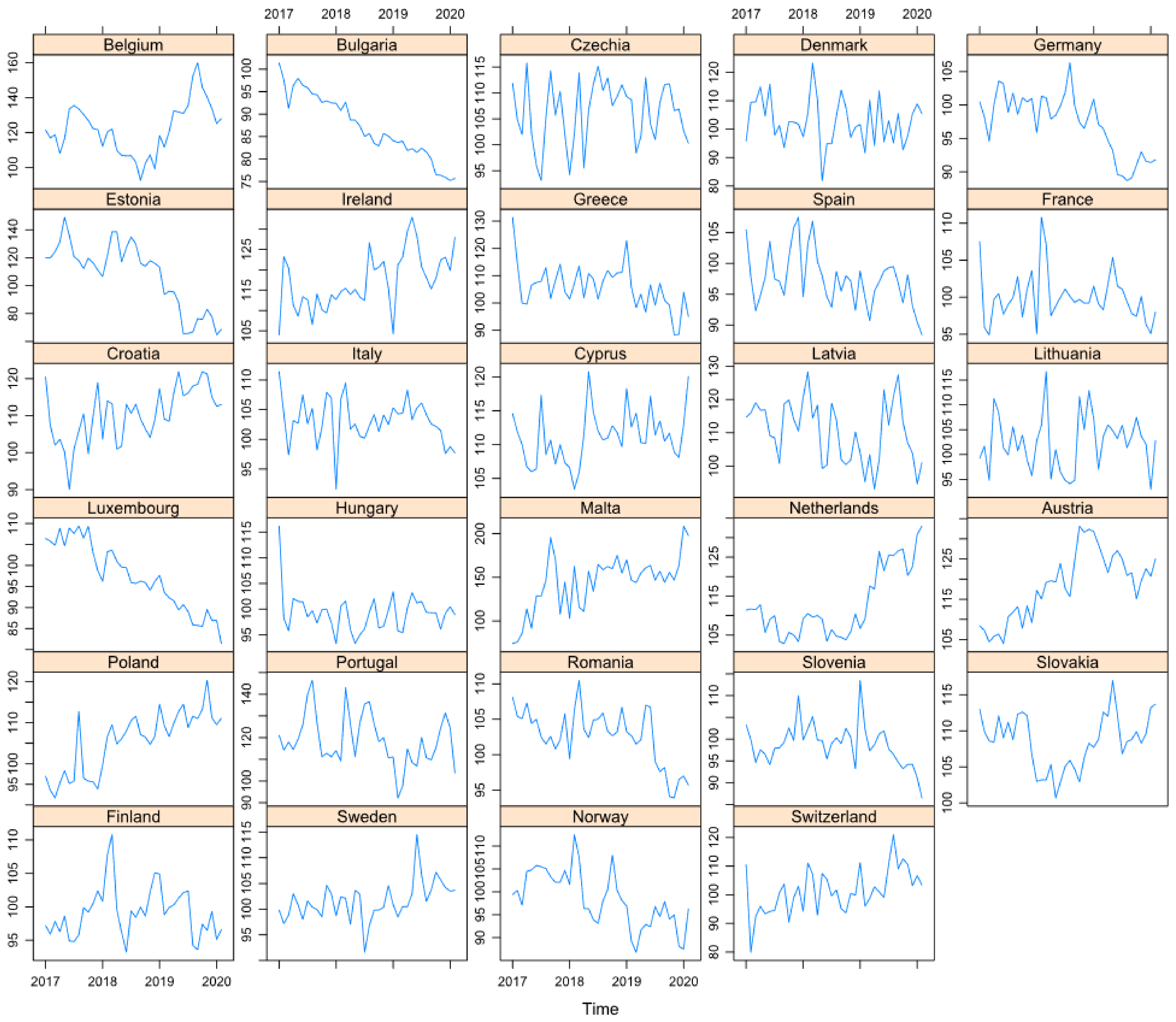
- The volume index of production in the industry for electricity, gas, steam and air conditioning supply (2015 = 100), seasonally and calendar-adjusted, for 29 European countries;
- The index of deflated turnover in retail trade, except for motor vehicles and motorcycles (2015 = 100), seasonally and calendar-adjusted, for 28 European countries.
- Set the universe of discourse
- Divide the universe of discourse into several intervals
- Fuzzify the datasets
- Setting the fuzzy logical relationship and group
- Defuzzification.
- Define U as the universe of discourse starting from the range of time series data, setting , with D1 and D2 being two convenient positive numbers
- Divide U into equal length intervals u1, u2, … uk. The number of intervals should be equal to the number of linguistic variables A1, A2, … Ak
- Build the fuzzy sets Ai according to the previously set intervals and apply triangular membership rule to each one
- Fuzzify the available data and set the fuzzy logical relations where Ai corresponds to the fuzzified value at time step n and Aj to the time step n + 1.
- Define the universe of discourse (U) starting from the range of time series data;
- Divide the set U into equal-length intervals
- Determine the respective values of linguistic variable
- Fuzzify the input data
- Select the parameter W > 1, and compute the fuzzy relationships matrix
- Defuzzify the obtained results.
3. Results
4. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Allen, P.G.; Fildes, R. Econometric forecasting strategies and techniques. In Principles of Forecasting: A Handbook for Researchers and Practitioners; Armstrong, J.S., Ed.; Kluwer Academic Press: Norwell, MA, USA, 2001; pp. 1–45. [Google Scholar]
- Diebold, F.X. Elements of Forecasting; South-Western College Publishing: La Jolla, CA, USA, 1998. [Google Scholar]
- Coyle, D. Making sense of published economic forecasts. In Understanding Economic Forecasts; Hendry, D.F., Ericsson, N.R., Eds.; MIT Press: Cambridge, MA, USA, 2001; pp. 54–67. [Google Scholar]
- Granger, C.W.J.; Newbold, P. Forecasting Economic Time Series, 2nd ed.; Academic Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Whitley, J.D. A Course in Macroeconomic Modeling and Forecasting; Harvester Wheatsheaf: London, UK, 1994. [Google Scholar]
- Ghosal, V.; Loungani, P. The Differential Impact of Uncertainty on Investment in Small and Large Businesses. Rev. Econ. Stat. 2000, 82, 338–343. [Google Scholar] [CrossRef]
- Liberto, D. Strategic analysis for investors. Invest. Chron. 2019, 127, 169–188. [Google Scholar]
- Enders, W. Applied Econometric Time Series; Wiley: New York, NY, USA, 1995. [Google Scholar]
- Hamilton, J. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Song, Q.; Chissom, B.S. Forecasting enrollments with fuzzy time series—Part I. Fuzzy Sets Syst. 1993, 54, 1–9. [Google Scholar] [CrossRef]
- Chen, S.-M. Forecasting enrollments based on fuzzy time series. Fuzzy Sets Syst. 1996, 81, 311–319. [Google Scholar] [CrossRef]
- Chen, S.M. Forecasting enrollments based on high-order fuzzy time series. Cybern. Syst. Int. J. 2002, 33, 1–16. [Google Scholar] [CrossRef]
- Singh, S.R. A computational method of forecasting based on fuzzy time series. Math. Comput. Simul. 2008, 79, 539–554. [Google Scholar] [CrossRef]
- Bose, M.; Mali, K. Designing fuzzy time series forecasting models: A survey. Int. J. Approx. Reason. 2019, 111, 78–99. [Google Scholar] [CrossRef]
- Singh, S.R. A simple method of forecasting based on fuzzy time series. Appl. Math. Comput. 2007, 186, 330–339. [Google Scholar] [CrossRef]
- Huarng, K. Heuristic models of fuzzy time series for forecasting. Fuzzy Sets Syst. 2001, 123, 369–386. [Google Scholar] [CrossRef]
- Chen, S.M.; Hsu, C.C. A New method to forecast enrollments using fuzzy time series. Int. J. Appl. Sci. Eng. 2004, 12, 234–244. [Google Scholar]
- Liu, F.; Li, R.; Dreglea, A. Wind Speed and Power Ultra Short-Term Robust Forecasting Based on Takagi–Sugeno Fuzzy Model. Energies 2019, 12, 3551. [Google Scholar] [CrossRef] [Green Version]
- Ollech, D.; Webel, K. A Random Forest-Based Approach to Identifying the Most Informative Seasonality Tests; Bundesbank Discussion Paper 55/2020; Deutsche Bundesbank: Frankfurt am Main, Germany, 2020. [Google Scholar]
- Armstrong, J.S. Selecting Forecasting Methods. 2009. Available online: https://ssrn.com/abstract=1941247 (accessed on 5 May 2021). [CrossRef] [Green Version]
- Brown, R.G. Exponential Smoothing for Predicting Demand; Arthur D. Little Inc.: Cambridge, MA, USA, 1956; p. 15. [Google Scholar]
- Brown, R.G. Statistical Forecasting for Inventory Control; McGraw-Hill: New York, NY, USA, 1959. [Google Scholar]
- Ord, J.K.; Koehler, A.B.; Snyder, R.D. Estimation and Prediction for a Class of Dynamic Nonlinear Statistical Models. J. Am. Stat. Assoc. 1997, 92, 1621–1629. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Prediction Intervals for Exponential Smoothing Using Two New Classes of State Space Models. J. Forecast. 2005, 24, 17–37. [Google Scholar] [CrossRef]
- Pegels, C.C. Exponential Forecasting: Some New Variations. Manag. Sci. 1969, 15, 311–315. [Google Scholar]
- Gardner, E.S., Jr. Exponential smoothing: The state of the art. J. Forecast. 1985, 4, 1–28. [Google Scholar] [CrossRef]
- Taylor, J.W. Exponential smoothing with a damped multiplicative trend. Int. J. Forecast. 2003, 19, 715–725. [Google Scholar] [CrossRef] [Green Version]
- Holt, C.C. Forecasting Seasonals and Trends by Exponentially Weighted Averages, O.N.R. Memorandum No. 52; Carnegie Institute of Technology: Pittsburgh, PA, USA, 1957. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day Inc.: San Francisco, CA, USA, 1970. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljyng, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Abbasov, A.M.; Mamedova, M.H. Application of fuzzy time series to population forecasting. In Proceedings of the 8th Symposion on Information Technology in Urban and Spatial Planning, Vienna University of Technology, Vienna, Austria, 25 February–1 March 2003; pp. 545–552. [Google Scholar]
- Vovan, T.; Ledai, N. A New Fuzzy Time Series Model Based on Cluster Analysis Problem. Int. J. Fuzzy Syst. 2019, 21, 852–864. [Google Scholar] [CrossRef]
- Han, T.T.N.; Nghi, D.H.; Diem, M.T.H.; My, N.T.D.; Minh, H.V.; Vo, V.T.; Truc, P.M. AnalyzeTS: Analyze Fuzzy Time Series, 2019, R Package Version 2.3. Available online: https://CRAN.R-project.org/package=AnalyzeTS (accessed on 1 June 2021).
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 1 June 2021).
- Oancea, B.; Pospisil, R.; Jula, M.; Imbrișcă, C.-I. Data Sets and R Code for Experimentation of Forecasting Methods, 2021. Figshare, Dataset, 2021. Available online: https://figshare.com/articles/dataset/Data_sets_and_R_code_for_experimentation_of_forecasting_methods/14971707/1 (accessed on 13 July 2021). [CrossRef]
- Efendi, R.; Ismail, Z.; Deris, M.M. A new linguistic out-sample approach of fuzzy time series for daily forecasting of Malaysian electricity load demand. Appl. Soft Comput. 2015, 28, 422–430. [Google Scholar] [CrossRef]
- Hyndman, R.; Athanasopoulos, G.; Bergmeir, C.; Caceres, G.; Chhay, L.; O’Hara-Wild, M.; Petropoulos, F.; Razbash, S.; Wang, E.; Yasmeen, F. Forecast: Forecasting Functions for Time Series and Linear Models. R Package Version 8.13. 2020. Available online: https://pkg.robjhyndman.com/forecast (accessed on 1 June 2021).
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, F.; Makridakis, S.; Assimakopoulos, V.; Nikolopoulos, K. ‘Horses for Courses’ in demand forecasting. Eur. J. Oper. Res. 2014, 237, 152–163. [Google Scholar] [CrossRef] [Green Version]
- Dadabada, P.; Ravi, V. Soft computing hybrids for FOREX rate prediction: A comprehensive review. Comput. Oper. Res. 2018, 99, 262–284. [Google Scholar] [CrossRef]
- William, R.; O’Connor, M. Neural Networks for Time-Series Forecasting. In Principles of Forecasting: A Handbook for Researchers and Practitioners; Armstrong Scott, J., Ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2001. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Min | 1sq QU | Median | Mean | 3rd QU | Max | VAR | SD | SE | Order of Integration |
|---|---|---|---|---|---|---|---|---|---|---|
| Belgium | 96.4 | 100.62 | 101.8 | 101.95 | 103 | 107.3 | 3.41 | 1.84 | 0.29 | 1 |
| Bulgaria | 73.7 | 89.02 | 89.8 | 89.55 | 90.82 | 95.4 | 11.68 | 3.41 | 0.55 | 1 |
| Czechia | 90.4 | 99.3 | 106.9 | 104.35 | 109.4 | 112.6 | 37.59 | 6.13 | 0.99 | 1 |
| Denmark | 103.6 | 109.97 | 112.9 | 112.49 | 114.62 | 125.9 | 14.47 | 3.8 | 0.61 | 1 |
| Germany | 101.4 | 109.25 | 109.9 | 110.63 | 112.35 | 119.1 | 10.38 | 3.22 | 0.52 | 1 |
| Spain | 95.7 | 102.32 | 104.7 | 103.73 | 105.6 | 110 | 9.84 | 3.13 | 0.5 | 1 |
| France | 98.4 | 101.25 | 102.7 | 102.65 | 103.55 | 107.1 | 4.1 | 2.02 | 0.32 | 2 |
| Croatia | 98.5 | 106.47 | 112.75 | 113.19 | 118.77 | 131.4 | 59.73 | 7.72 | 1.25 | 1 |
| Italy | 95.5 | 101.8 | 102.7 | 103.13 | 104.97 | 112.1 | 9.59 | 3.09 | 0.5 | 0 |
| Luxembourg | 94.6 | 105.4 | 108.45 | 108.38 | 111.25 | 125.4 | 33.24 | 5.76 | 0.93 | 0 |
| Hungary | 87.8 | 109.82 | 132.5 | 129.62 | 150.3 | 167.1 | 584.79 | 24.18 | 3.92 | 1 |
| Netherlands | 112.2 | 118.42 | 124 | 123.18 | 127.55 | 132.6 | 32.42 | 5.69 | 0.92 | 1 |
| Austria | 101 | 110.07 | 116.85 | 116.45 | 122.25 | 127.9 | 51.63 | 7.18 | 1.16 | 1 |
| Poland | 85.1 | 101.5 | 117.65 | 112.87 | 122.65 | 129.6 | 153.12 | 12.37 | 2 | 1 |
| Portugal | 96.6 | 99.37 | 101.45 | 101.19 | 103.3 | 106.6 | 7.12 | 2.66 | 0.43 | 0 |
| Romania | 82.9 | 88.7 | 94.1 | 99.12 | 110.82 | 135.7 | 187.49 | 13.69 | 2.22 | 2 |
| Slovenia | 78.3 | 109.5 | 126.55 | 122.38 | 134.42 | 144.1 | 240.89 | 15.52 | 2.51 | 1 |
| Slovakia | 87.8 | 93.12 | 96.35 | 96.28 | 99.2 | 104.9 | 19.69 | 4.43 | 0.71 | 2 |
| Finland | 109.2 | 111.22 | 113.1 | 112.95 | 114.45 | 118.1 | 4.37 | 2.09 | 0.33 | 1 |
| Sweden | 105 | 116.45 | 121.6 | 119.68 | 122.77 | 129.4 | 25.35 | 5.03 | 0.81 | 1 |
| Country | Min | 1sq QU | Median | Mean | 3rd QU | Max | VAR | SD | SE | Order of Integration |
|---|---|---|---|---|---|---|---|---|---|---|
| Belgium | 92.6 | 110.35 | 121.65 | 122.2 | 132.4 | 159.9 | 219.59 | 14.81 | 2.4 | 2 |
| Bulgaria | 75.2 | 82.32 | 85.7 | 87.2 | 92.67 | 101.4 | 50.36 | 7.09 | 1.15 | 2 |
| Czechia | 93.1 | 102.02 | 106.8 | 106.27 | 111.6 | 115.8 | 37.19 | 6.09 | 0.98 | 1 |
| Denmark | 81.9 | 96.12 | 102.55 | 102.68 | 108.6 | 123.3 | 67.67 | 8.22 | 1.33 | 0 |
| Germany | 88.7 | 93.55 | 98.35 | 97.24 | 100.8 | 106.3 | 20.83 | 4.56 | 0.74 | 1 |
| Estonia | 64.7 | 89.55 | 115.95 | 107.56 | 121.15 | 149 | 573.3 | 23.94 | 3.88 | 2 |
| Ireland | 104 | 112.85 | 115.5 | 117.23 | 121.87 | 132.9 | 47.79 | 6.91 | 1.12 | 0 |
| Greece | 88.3 | 101.02 | 106.65 | 105.8 | 110.45 | 131.4 | 67.52 | 8.21 | 1.33 | 1 |
| Spain | 88.4 | 94.6 | 97.35 | 97.43 | 99.17 | 107.5 | 20.54 | 4.53 | 0.73 | 1 |
| France | 94.9 | 97.85 | 99.55 | 100.01 | 101.1 | 110.8 | 11.68 | 3.41 | 0.55 | 1 |
| Croatia | 90.1 | 104.52 | 110.55 | 110.34 | 115.92 | 121.9 | 54.83 | 7.4 | 1.2 | 1 |
| Italy | 91.6 | 101.55 | 102.95 | 103.11 | 105.27 | 111.4 | 14.4 | 3.79 | 0.61 | 1 |
| Cyprus | 103.4 | 108.6 | 110.85 | 111.25 | 112.95 | 120.8 | 15.9 | 3.98 | 0.64 | 0 |
| Latvia | 93 | 101.9 | 111.4 | 110.37 | 117.95 | 128.4 | 86.67 | 9.3 | 1.51 | 1 |
| Lithuania | 93 | 98.97 | 102.8 | 102.48 | 105.82 | 116.7 | 31.44 | 5.6 | 0.9 | 0 |
| Luxembourg | 81.4 | 90.92 | 96.25 | 97.29 | 104.42 | 109.4 | 63.53 | 7.97 | 1.29 | 2 |
| Hungary | 93.3 | 96.4 | 99.35 | 99.26 | 101.05 | 116.2 | 14.79 | 3.84 | 0.62 | 1 |
| Malta | 74.2 | 128.52 | 150.7 | 144.28 | 162.67 | 208.7 | 1012.44 | 31.81 | 5.16 | 1 |
| Netherlands | 102.8 | 105.72 | 110 | 112.86 | 119.62 | 133 | 77.63 | 8.81 | 1.42 | 2 |
| Austria | 104 | 112.15 | 119.45 | 118.47 | 124.87 | 133.2 | 69.5 | 8.33 | 1.35 | 2 |
| Poland | 91.7 | 97.32 | 106.9 | 105.45 | 111.07 | 120.3 | 54.89 | 7.4 | 1.2 | 1 |
| Portugal | 92.2 | 111.12 | 116.55 | 118.68 | 126.2 | 146.4 | 141.07 | 11.87 | 1.92 | 1 |
| Romania | 93.9 | 100.97 | 102.95 | 102.62 | 105.32 | 110.5 | 15.58 | 3.94 | 0.64 | 1 |
| Slovenia | 86.5 | 95.75 | 99 | 98.77 | 101.02 | 113.5 | 23.83 | 4.88 | 0.79 | 1 |
| Slovakia | 100.7 | 106 | 108.7 | 108.56 | 112.07 | 117 | 14.02 | 3.74 | 0.6 | 2 |
| Finland | 93.2 | 96.35 | 99 | 99.15 | 100.72 | 110.8 | 14.51 | 3.8 | 0.61 | 1 |
| Sweden | 91.6 | 99.8 | 101.2 | 101.56 | 103.65 | 114.5 | 14.08 | 3.75 | 0.6 | 1 |
| Norway | 86.8 | 94.15 | 97.95 | 98.44 | 103 | 112.5 | 37.45 | 6.12 | 0.99 | 0 |
| Switzerland | 79.9 | 95.32 | 100.8 | 101.37 | 107.07 | 121 | 61.67 | 7.85 | 1.27 | 1 |
| Country | Min | 1sq QU | Median | Mean | 3rd QU | Max | VAR | SD | SE | Order of Integration |
|---|---|---|---|---|---|---|---|---|---|---|
| Belgium | 98.4 | 99.82 | 100.3 | 100.42 | 100.77 | 102.6 | 0.82 | 0.9 | 0.14 | 1 |
| Bulgaria | 109.6 | 112.72 | 115.9 | 116.5 | 120.75 | 128.8 | 21.38 | 4.62 | 0.75 | 2 |
| Czechia | 106.9 | 113.45 | 116.8 | 116.99 | 121.75 | 125.2 | 26.74 | 5.17 | 0.83 | 1 |
| Denmark | 101.3 | 102.5 | 103.55 | 103.48 | 104.6 | 105.3 | 1.59 | 1.26 | 0.2 | 1 |
| Germany | 103.1 | 106.15 | 107.95 | 108.29 | 110.8 | 112.7 | 6.91 | 2.62 | 0.42 | 1 |
| Estonia | 103.8 | 105.92 | 107.5 | 108.53 | 110.75 | 115.8 | 10.58 | 3.25 | 0.52 | 1 |
| Ireland | 107 | 111.85 | 116.35 | 115.83 | 120.27 | 123.8 | 22.26 | 4.71 | 0.76 | 0 |
| Greece | 97.1 | 100.62 | 102.2 | 101.96 | 103.25 | 106.1 | 4.12 | 2.03 | 0.32 | 1 |
| Spain | 102.6 | 105.22 | 105.8 | 106.21 | 107.37 | 109.7 | 2.87 | 1.69 | 0.27 | 1 |
| France | 105.1 | 107.9 | 110.1 | 109.98 | 112.4 | 114.3 | 8.12 | 2.85 | 0.46 | 1 |
| Croatia | 102 | 106.07 | 111.75 | 110.06 | 114.12 | 116.8 | 20.76 | 4.55 | 0.73 | 1 |
| Cyprus | 106.1 | 113.5 | 117.25 | 117.01 | 120.45 | 125.1 | 24.28 | 4.92 | 0.79 | 1 |
| Latvia | 103.6 | 108.2 | 111.4 | 110.61 | 112.95 | 119.7 | 13.3 | 3.64 | 0.59 | 1 |
| Lithuania | 109.2 | 112.4 | 119.8 | 118.98 | 124.15 | 131.2 | 41.51 | 6.44 | 1.04 | 1 |
| Luxembourg | 28.2 | 30.3 | 30.9 | 31.06 | 32.2 | 33.2 | 1.52 | 1.23 | 0.2 | 1 |
| Hungary | 107 | 112.87 | 118.75 | 118.75 | 124.5 | 132.2 | 50.62 | 7.11 | 1.15 | 1 |
| Malta | 104.2 | 108.42 | 110.35 | 112.26 | 117 | 123.1 | 24.77 | 4.97 | 0.8 | 1 |
| Netherlands | 102.5 | 105.32 | 107.95 | 107.64 | 109.85 | 112.5 | 6.46 | 2.54 | 0.41 | 1 |
| Austria | 100.7 | 102.22 | 103.1 | 102.93 | 103.67 | 106.2 | 1.51 | 1.23 | 0.19 | 1 |
| Poland | 109.6 | 114.77 | 119.35 | 119.6 | 124.3 | 132 | 39.71 | 6.3 | 1.02 | 1 |
| Portugal | 103.7 | 108.45 | 111.7 | 112.09 | 115.52 | 124.5 | 22.65 | 4.75 | 0.77 | 2 |
| Romania | 117.3 | 128.5 | 132.85 | 133.76 | 139.45 | 152.2 | 73.99 | 8.6 | 1.39 | 1 |
| Slovenia | 110.8 | 112.82 | 116.15 | 117.53 | 121.45 | 129.1 | 28.21 | 5.31 | 0.86 | 2 |
| Slovakia | 105.4 | 109.52 | 110.2 | 110.75 | 112.42 | 115.9 | 6.67 | 2.58 | 0.41 | 3 |
| Finland | 103.2 | 105.27 | 106.5 | 107.06 | 109.2 | 111.9 | 5.53 | 2.35 | 0.38 | 2 |
| Sweden | 102.4 | 104.37 | 105.75 | 105.93 | 107.55 | 110.9 | 4.13 | 2.03 | 0.32 | 0 |
| Norway | 100.2 | 101.9 | 102.4 | 102.42 | 102.9 | 105.2 | 0.84 | 0.91 | 0.14 | 0 |
| Switzerland | 98.3 | 100.8 | 101.5 | 101.39 | 101.87 | 103.4 | 1.35 | 1.16 | 0.18 | 1 |
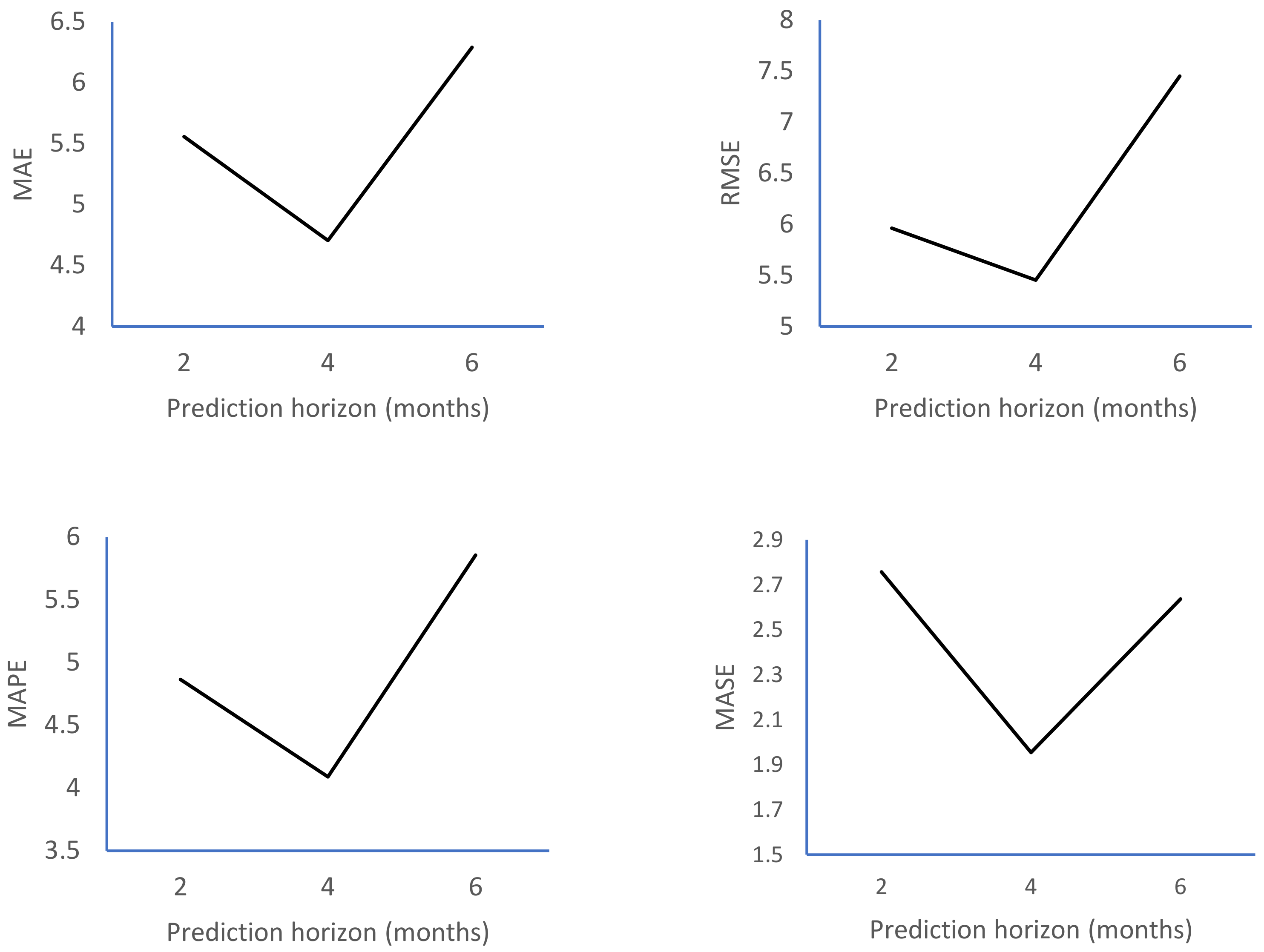
| Accuracy Indicator | Fuzzy Time Series Forecasting Method | Econometric Method | The Volume Index of Production in Construction (20 Time Series) | The Volume Index of Production in Industry for Electricity, Gas, Steam and Air Conditioning Supply (29 Time Series) | The Index of Deflated Turnover in Retail Trade, Except for Motor Vehicles and Motorcycles (28 Time Series) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| h = 2 | h = 4 | h = 6 | h = 2 | h = 4 | h = 6 | h = 2 | h = 4 | h = 6 | |||
| MAE | Abbasov–Mamedova | SES | 8 | 11 | 7 | 14 | 13 | 6 | 10 | 12 | 11 |
| Abbasov–Mamedova | Holt | 7 | 10 | 9 | 15 | 14 | 7 | 7 | 8 | 6 | |
| Abbasov–Mamedova | ARIMA | 7 | 8 | 7 | 14 | 15 | 7 | 6 | 7 | 8 | |
| NFTS | SES | 8 | 10 | 7 | 13 | 12 | 6 | 10 | 8 | 11 | |
| NFTS | Holt | 8 | 9 | 9 | 14 | 13 | 9 | 6 | 10 | 4 | |
| NFTS | ARIMA | 8 | 8 | 7 | 14 | 12 | 9 | 4 | 12 | 7 | |
| MAPE | Abbasov–Mamedova | SES | 8 | 10 | 7 | 14 | 13 | 6 | 10 | 12 | 12 |
| Abbasov–Mamedova | Holt | 7 | 9 | 9 | 15 | 12 | 7 | 7 | 8 | 6 | |
| Abbasov–Mamedova | ARIMA | 7 | 8 | 7 | 15 | 13 | 7 | 6 | 7 | 8 | |
| NFTS | SES | 9 | 10 | 8 | 13 | 12 | 6 | 10 | 13 | 11 | |
| NFTS | Holt | 8 | 9 | 9 | 14 | 13 | 9 | 6 | 10 | 4 | |
| NFTS | ARIMA | 8 | 8 | 7 | 14 | 11 | 8 | 4 | 8 | 7 | |
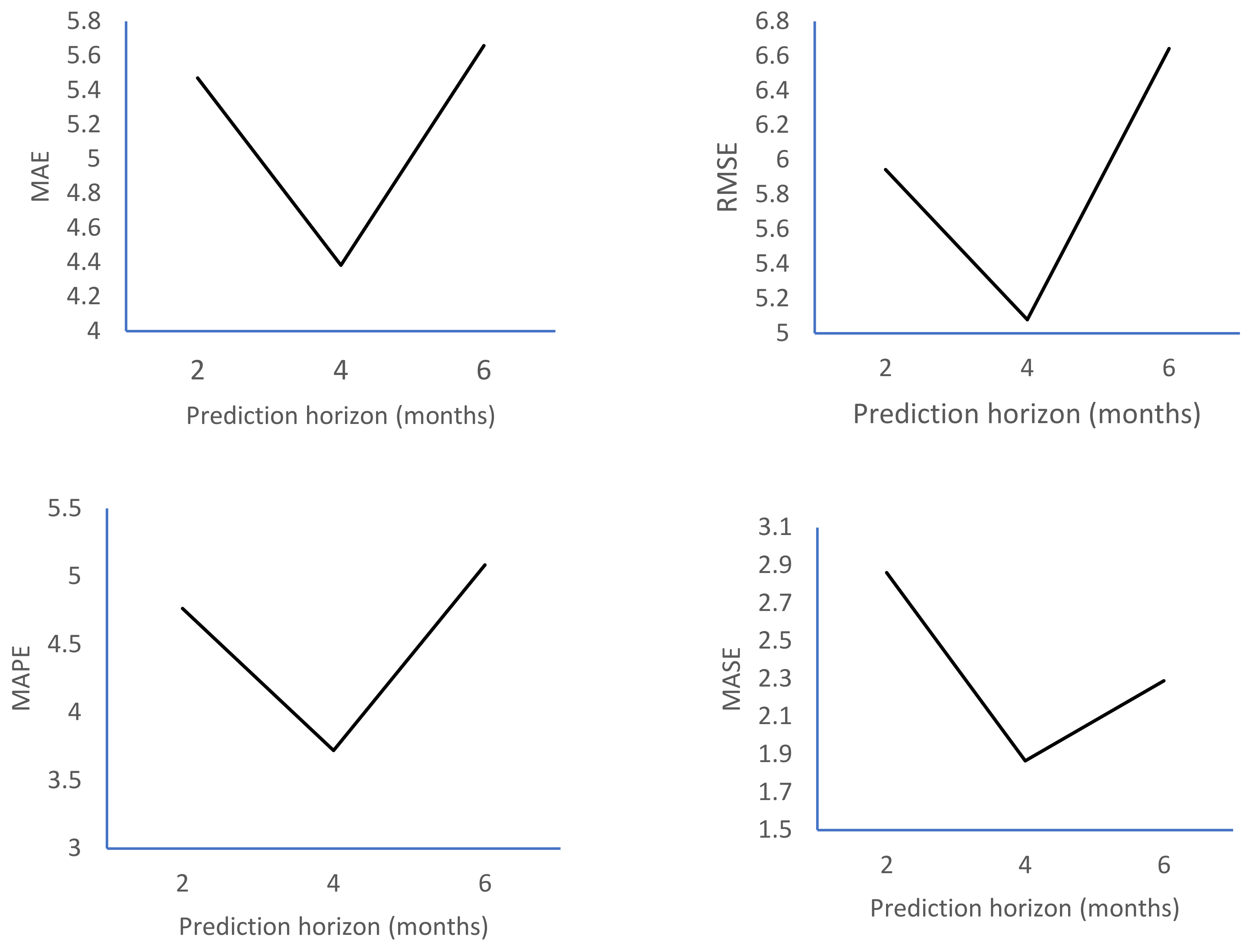
| RMSE | Abbasov–Mamedova | SES | 8 | 11 | 6 | 13 | 12 | 6 | 9 | 12 | 12 |
| Abbasov–Mamedova | Holt | 7 | 10 | 9 | 14 | 14 | 6 | 6 | 8 | 5 | |
| Abbasov–Mamedova | ARIMA | 7 | 8 | 7 | 14 | 13 | 6 | 6 | 7 | 7 | |
| NFTS | SES | 9 | 10 | 8 | 16 | 13 | 7 | 8 | 13 | 11 | |
| NFTS | Holt | 8 | 11 | 9 | 13 | 14 | 8 | 6 | 9 | 3 | |
| NFTS | ARIMA | 7 | 10 | 7 | 16 | 13 | 9 | 5 | 8 | 6 | |
| MASE | Abbasov–Mamedova | SES | 8 | 11 | 7 | 14 | 13 | 6 | 10 | 12 | 11 |
| Abbasov–Mamedova | Holt | 7 | 10 | 9 | 15 | 14 | 7 | 7 | 10 | 6 | |
| Abbasov–Mamedova | ARIMA | 7 | 8 | 7 | 14 | 15 | 7 | 6 | 8 | 8 | |
| NFTS | SES | 9 | 10 | 7 | 13 | 12 | 6 | 8 | 12 | 11 | |
| NFTS | Holt | 8 | 9 | 9 | 14 | 13 | 9 | 6 | 10 | 4 | |
| NFTS | ARIMA | 8 | 8 | 7 | 14 | 12 | 9 | 5 | 7 | 7 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oancea, B.; Pospíšil, R.; Jula, M.N.; Imbrișcă, C.-I. Experiments with Fuzzy Methods for Forecasting Time Series as Alternatives to Classical Methods. Mathematics 2021, 9, 2517. https://doi.org/10.3390/math9192517
Oancea B, Pospíšil R, Jula MN, Imbrișcă C-I. Experiments with Fuzzy Methods for Forecasting Time Series as Alternatives to Classical Methods. Mathematics. 2021; 9(19):2517. https://doi.org/10.3390/math9192517
Chicago/Turabian StyleOancea, Bogdan, Richard Pospíšil, Marius Nicolae Jula, and Cosmin-Ionuț Imbrișcă. 2021. "Experiments with Fuzzy Methods for Forecasting Time Series as Alternatives to Classical Methods" Mathematics 9, no. 19: 2517. https://doi.org/10.3390/math9192517
APA StyleOancea, B., Pospíšil, R., Jula, M. N., & Imbrișcă, C.-I. (2021). Experiments with Fuzzy Methods for Forecasting Time Series as Alternatives to Classical Methods. Mathematics, 9(19), 2517. https://doi.org/10.3390/math9192517