
Gender Classification Using Proposed CNN-Based Model and Ant Colony Optimization

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- •
- A new architecture based on 64 layers named 4-BSMAB is proposed to obtain features from images. Due to the non-availability of larger datasets, the training of proposed model is carried out on CIFAR-100 dataset, and then the trained model is utilized to extract features from the testing datasets.
- •
- The feature optimization approach (ACS) is applied to obtain features for dimension reduction of extracted features.
- •
- Various classifiers are tested for PGC, and then the most successful classifier is benchmarked. The classification accuracy achieved with the proposed model shows that the proposed framework is acceptable.
2. Related Work
2.1. Traditional/Hand-Crafted Feature-Based Approaches
2.2. Deep Learning-Based Approaches
3. Material and Methods
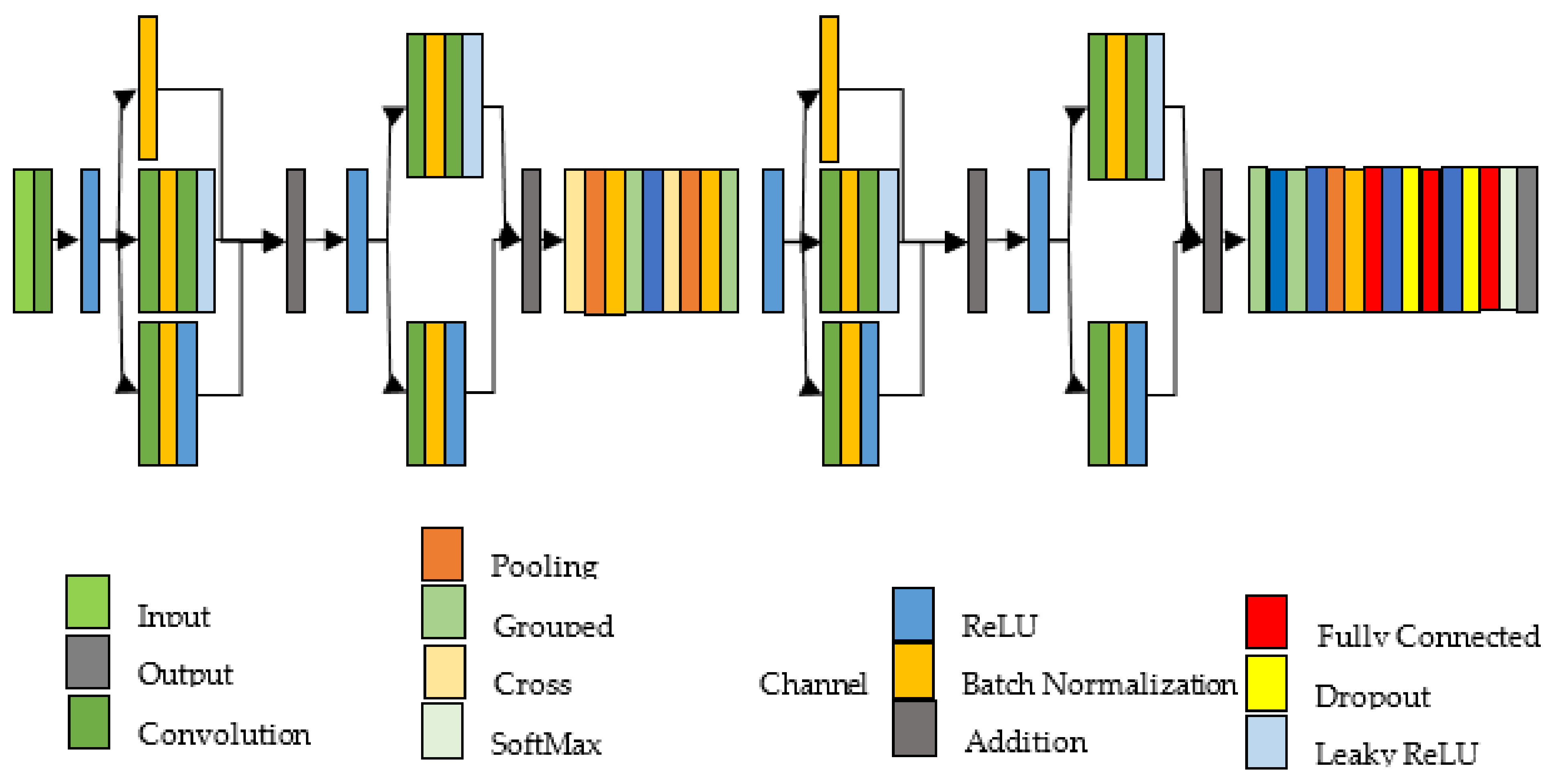
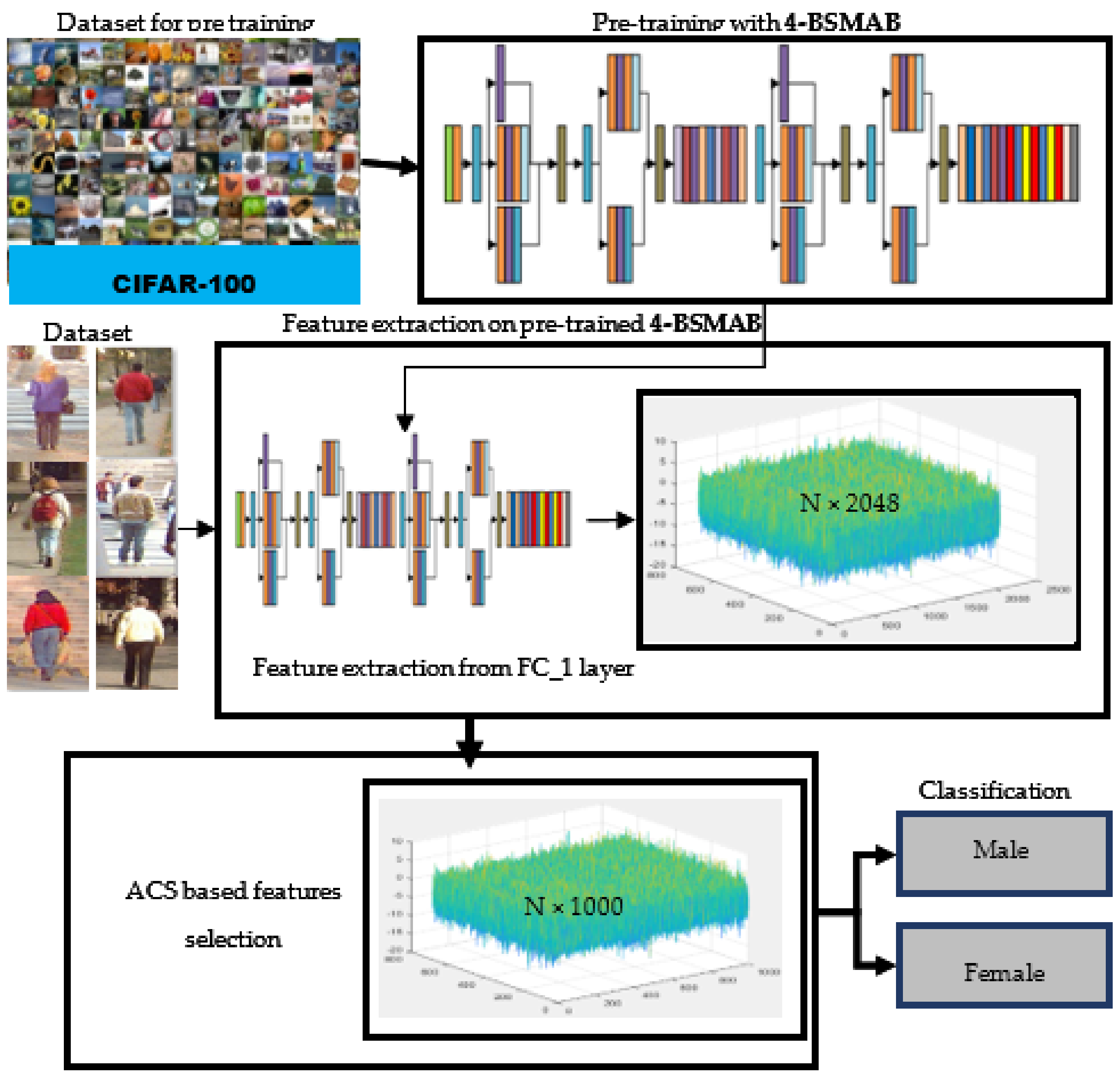
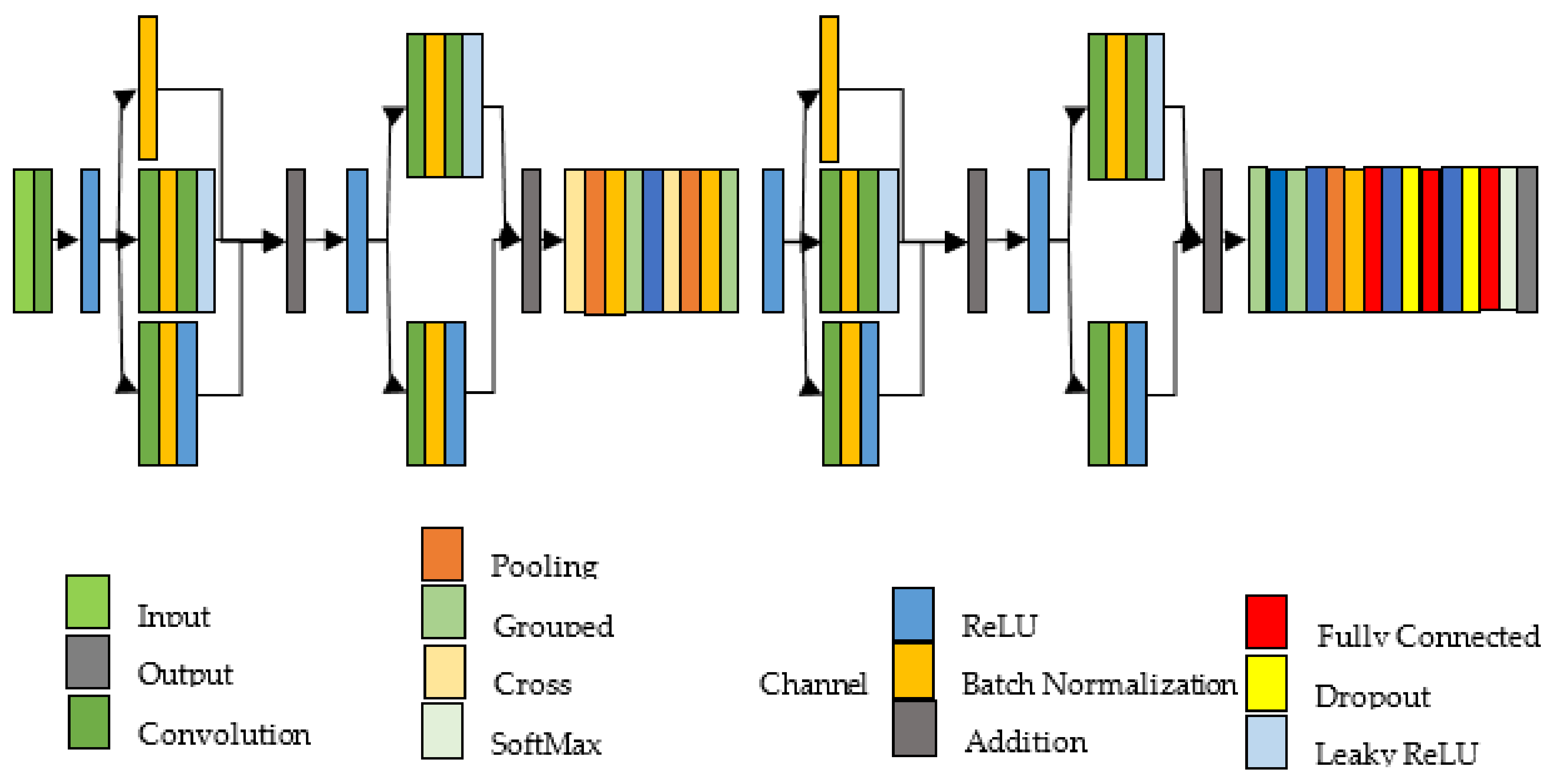
3.1. 4-BSMAB
3.2. Pre-Training of Proposed Model and Feature Extraction
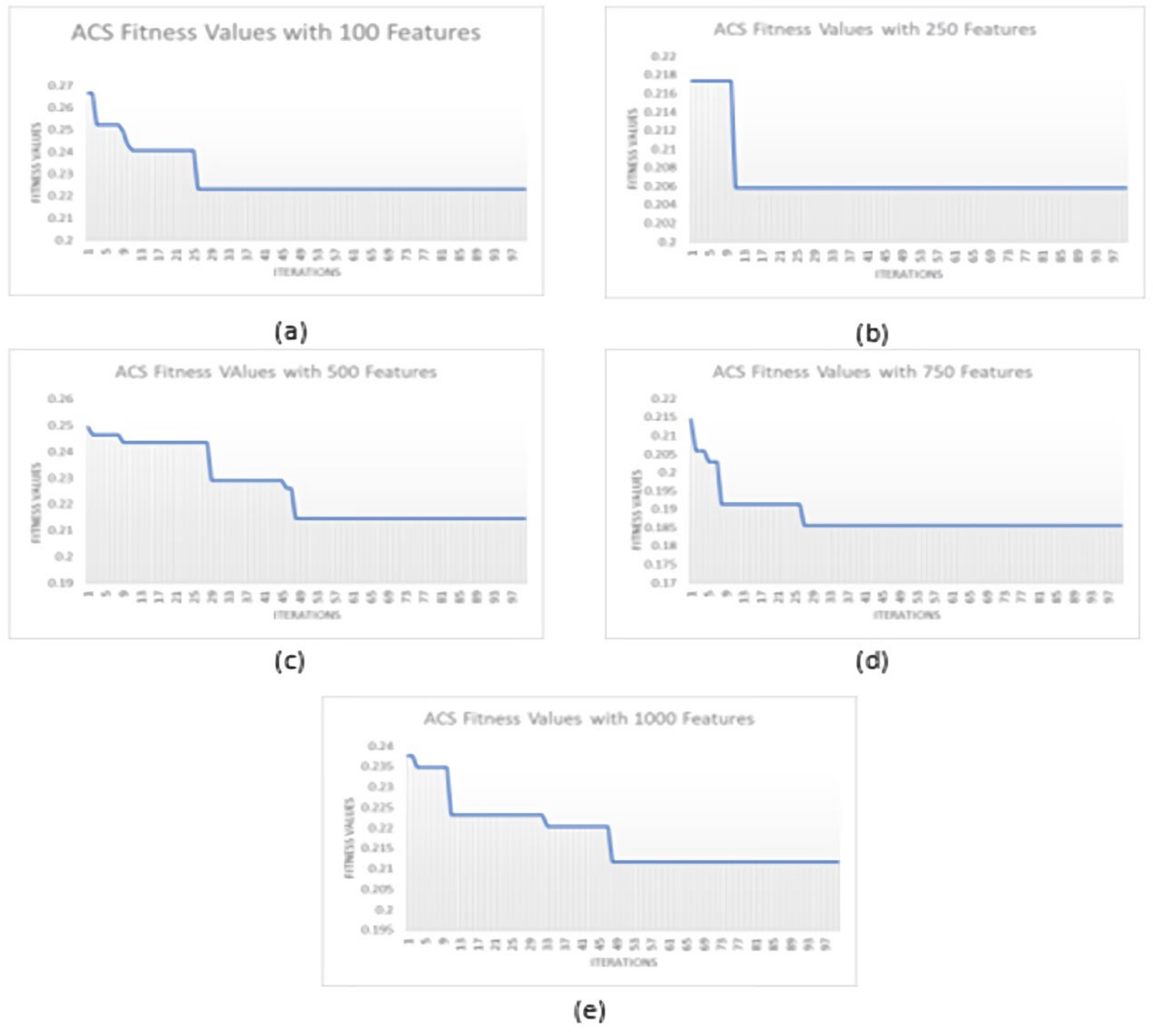
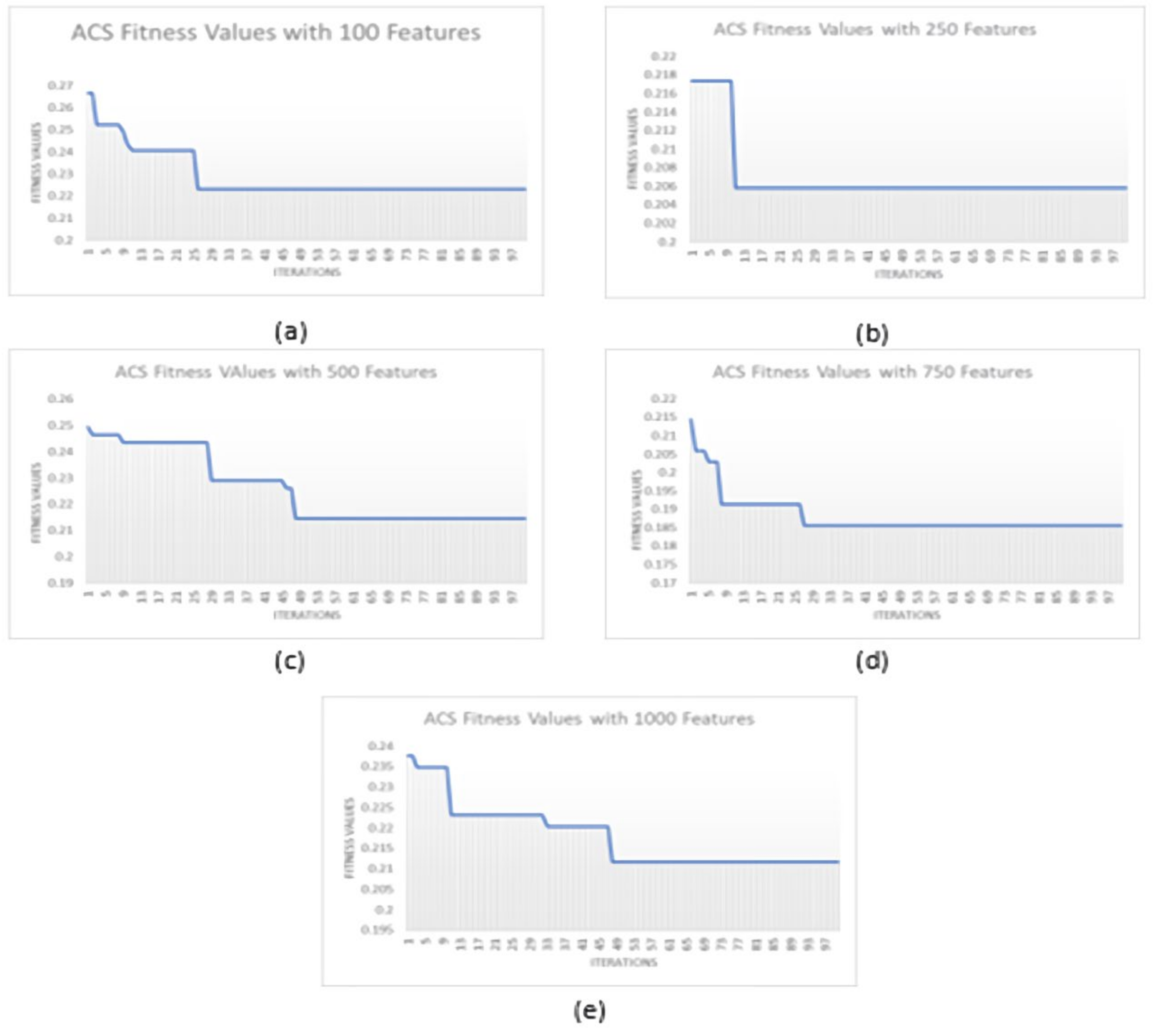
3.3. Feature Selection Based on ACS Optimization
3.4. Dataset Balancing
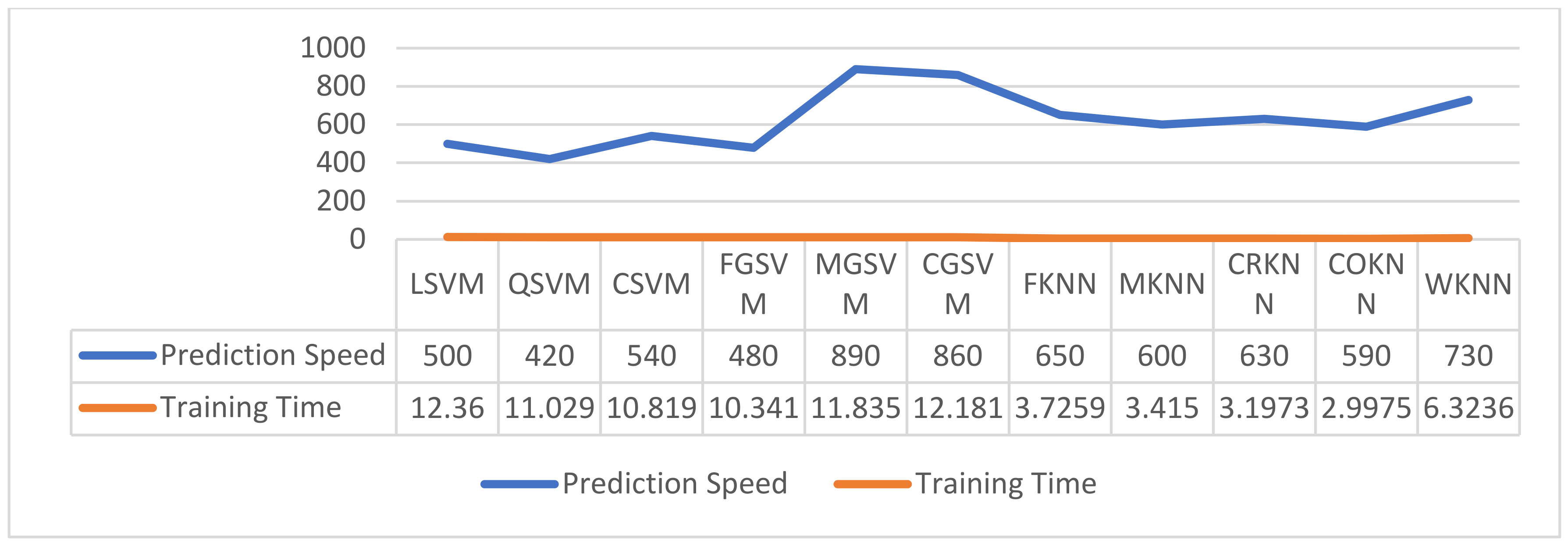
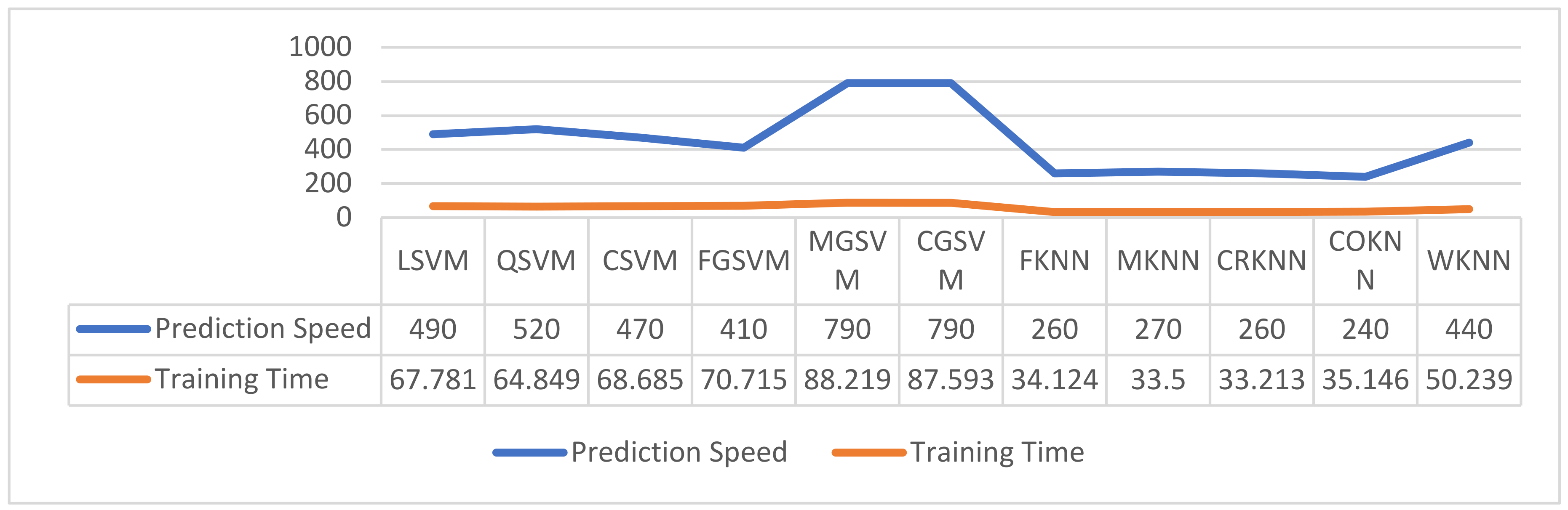
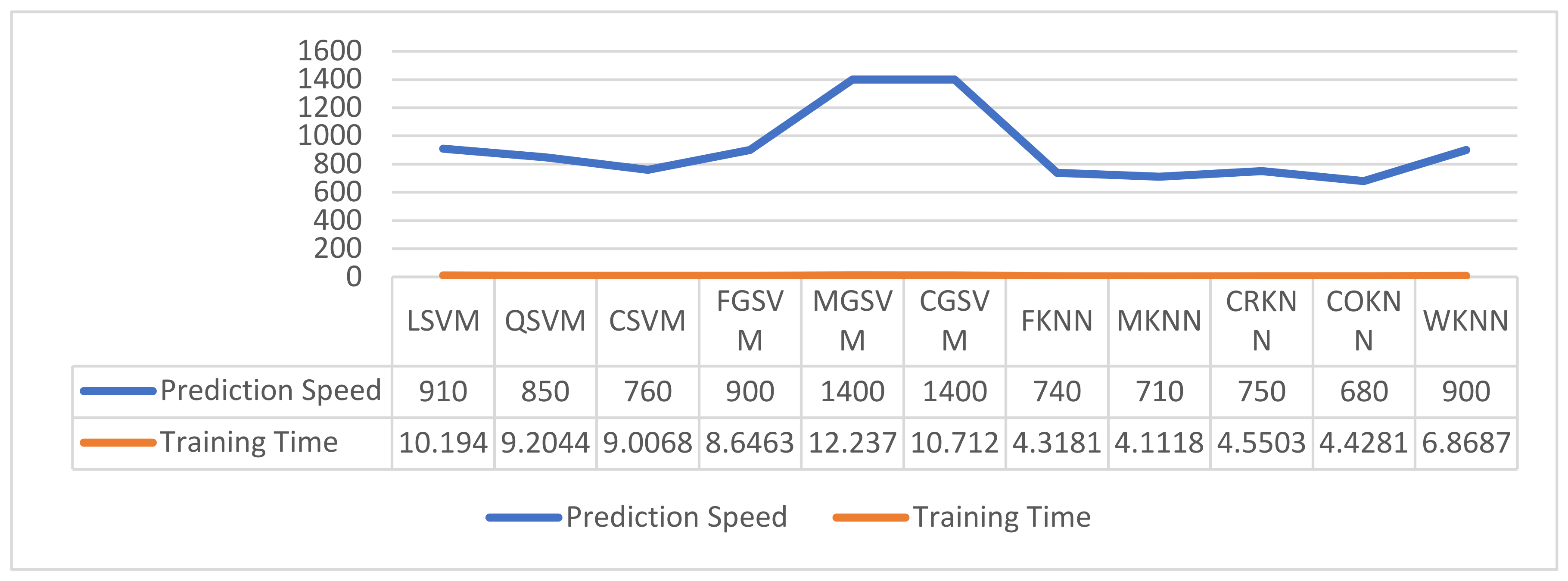
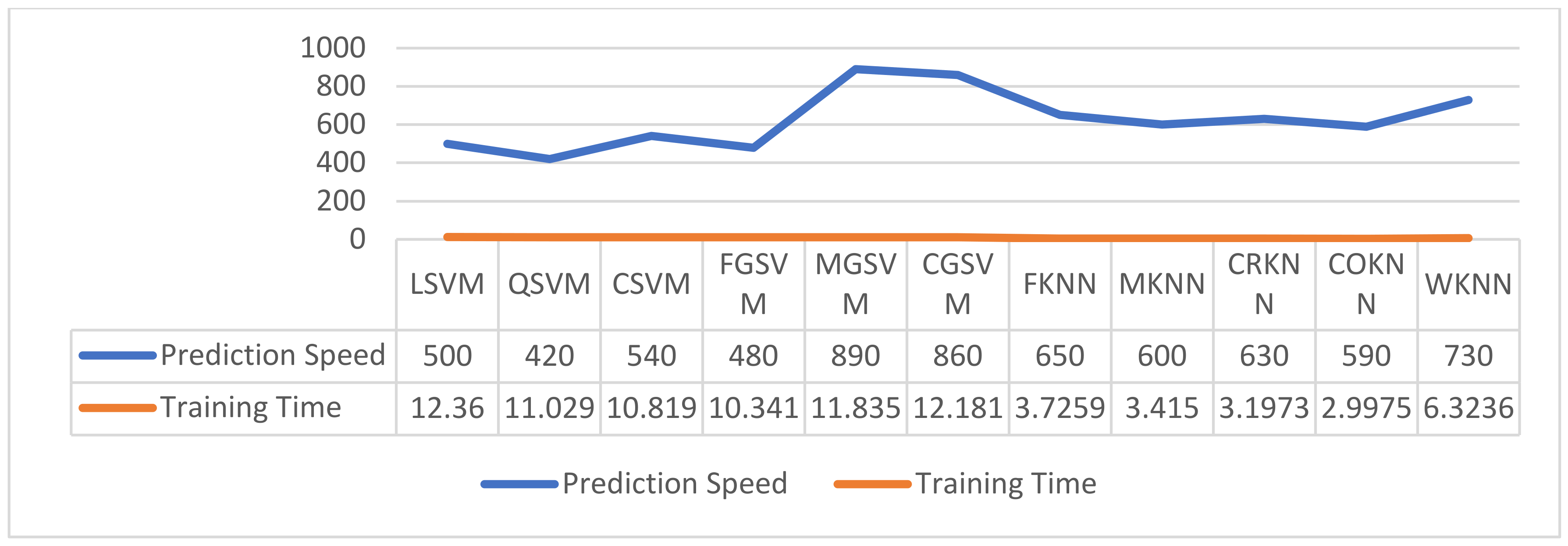
3.5. Classification
4. Results and Discussion
4.1. Datasets
4.2. Performance Evaluation Protocols
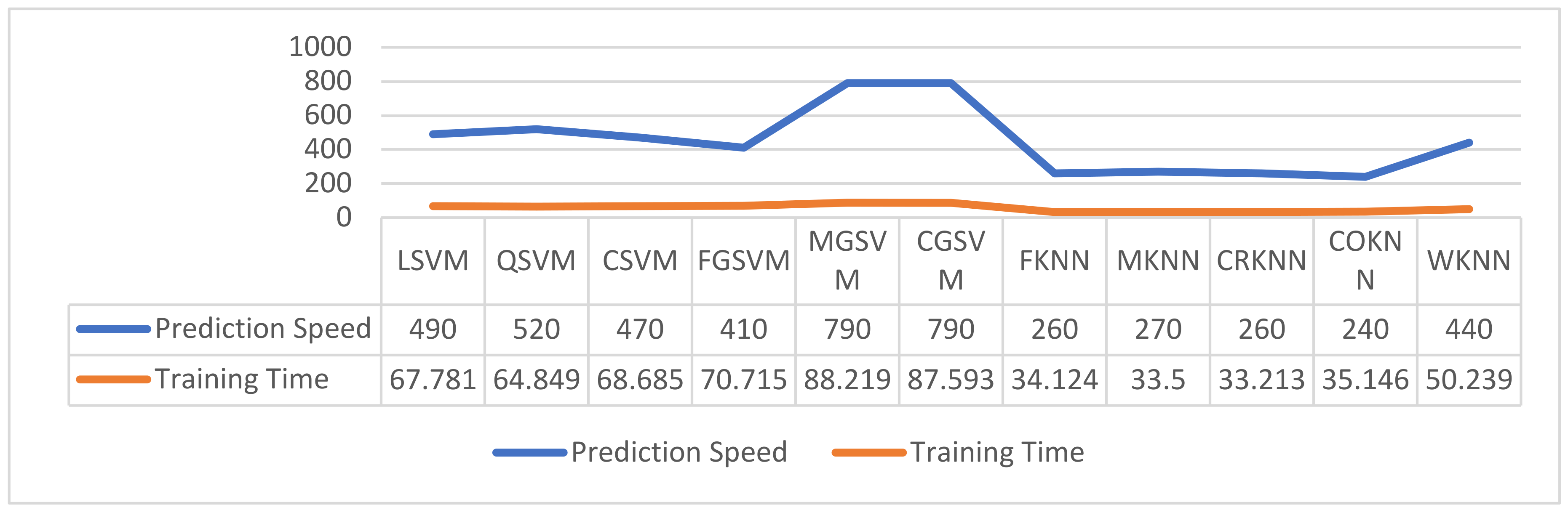
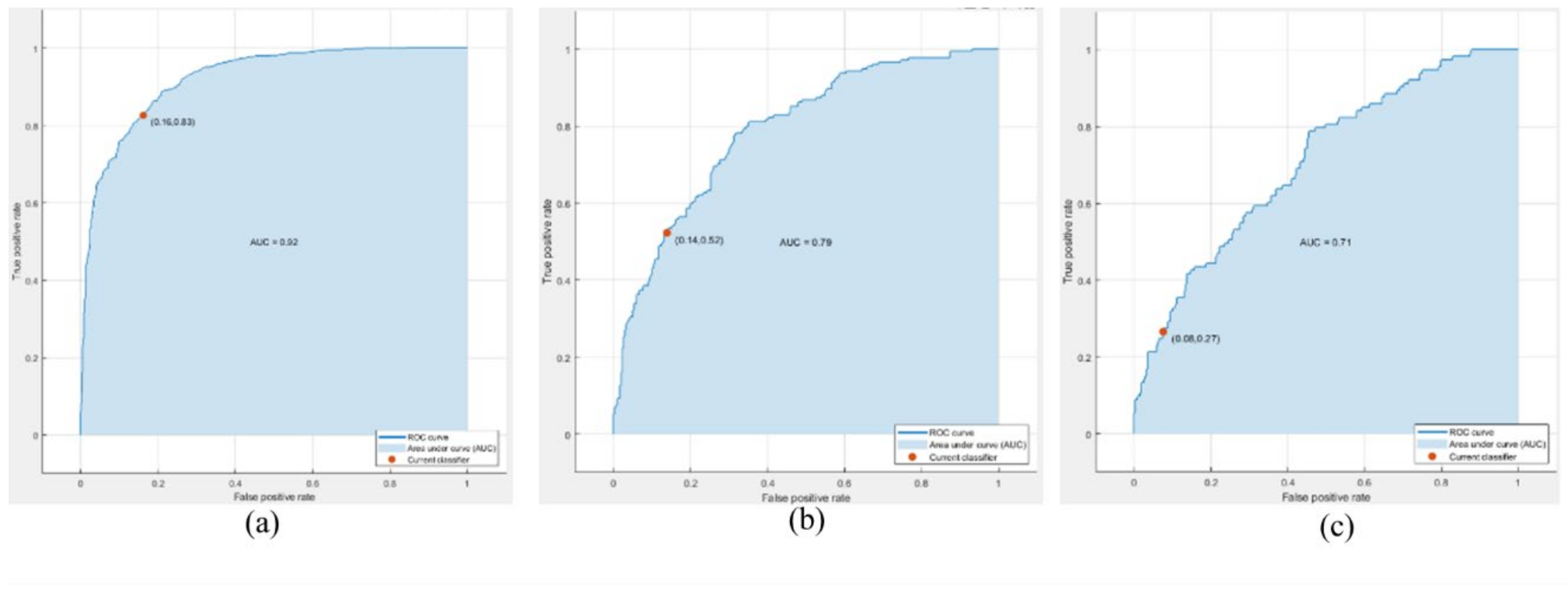
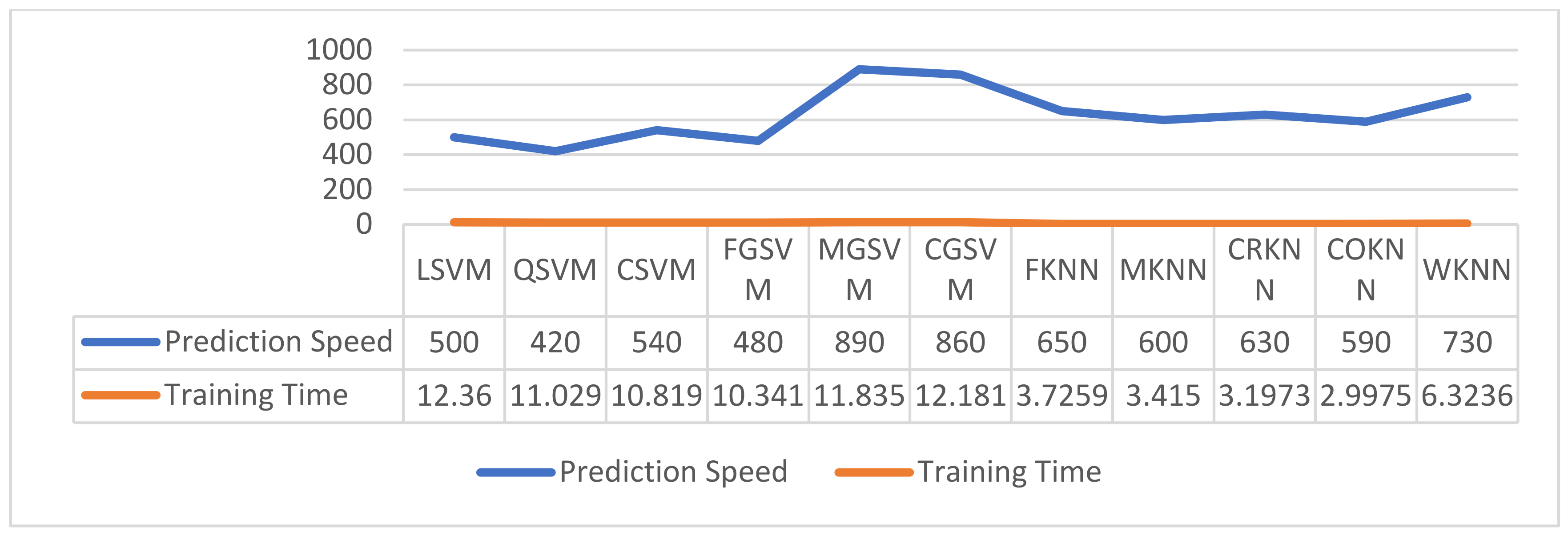
4.3. Performance Evaluation of Proposed Framework
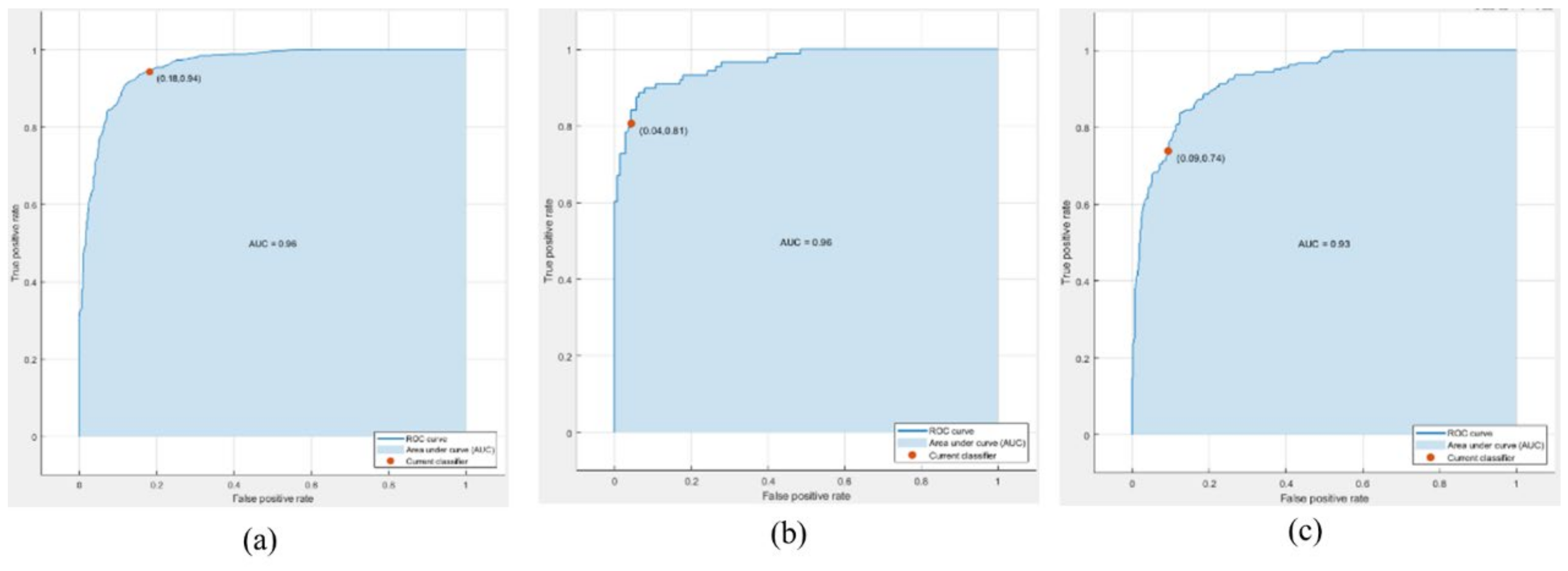
4.3.1. Performance Evaluation of MIT Dataset
4.3.2. Performance Evaluation of VIPeR Dataset
4.3.3. Performance Evaluation of PKU-Reid Dataset
4.4. Performance Comparison between Proposed Approach and Existing Studies
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sivabalakrishnan, M.; Menaka, R.; Jeeva, S. Smart video surveillance systems and identification of human behavior analysis. In Countering Cyber Attacks and Preserving the Integrity and Availability of Critical Systems; IGI Global: Philadelphia, PA, USA, 2019; pp. 64–97. [Google Scholar]
- Filonenko, A.; Jo, K.-H. Unattended object identification for intelligent surveillance systems using sequence of dual background difference. IEEE Trans. Ind. Inform. 2016, 12, 2247–2255. [Google Scholar]
- Zhu, H.; Wei, H.; Li, B.; Yuan, X.; Kehtarnavaz, N. A Review of Video Object Detection: Datasets, Metrics and Methods. Appl. Sci. 2020, 10, 7834. [Google Scholar] [CrossRef]
- Jang, D.-H.; Kwon, K.-S.; Kim, J.-K.; Yang, K.-Y.; Kim, J.-B. Dog Identification Method Based on Muzzle Pattern Image. Appl. Sci. 2020, 10, 8994. [Google Scholar] [CrossRef]
- Rybak, Ł.; Dudczyk, J. A geometrical divide of data particle in gravitational classification of moons and circles data sets. Entropy 2020, 22, 1088. [Google Scholar] [CrossRef]
- Rybak, Ł.; Dudczyk, J. Variant of Data Particle Geometrical Divide for Imbalanced Data Sets Classification by the Example of Occupancy Detection. Appl. Sci. 2021, 11, 4970. [Google Scholar] [CrossRef]
- Feng, Q.; Yuan, C.; Pan, J.-S.; Yang, J.-F.; Chou, Y.-T.; Zhou, Y.; Li, W. Superimposed sparse parameter classifiers for face recognition. IEEE Trans. Cybern. 2016, 47, 378–390. [Google Scholar] [CrossRef]
- Neff, C.; Mendieta, M.; Mohan, S.; Baharani, M.; Rogers, S.; Tabkhi, H. REVAMP 2 T: Real-Time Edge Video Analytics for Multicamera Privacy-Aware Pedestrian Tracking. IEEE Internet Things J. 2019, 7, 2591–2602. [Google Scholar] [CrossRef] [Green Version]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1249–1258. [Google Scholar]
- Wu, S.; Chen, Y.-C.; Li, X.; Wu, A.-C.; You, J.-J.; Zheng, W.-S. An enhanced deep feature representation for person re-identification. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV 2016), Lake Placid, NY, USA, 7–10 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [Green Version]
- Kong, Y.; Ding, Z.; Li, J.; Fu, Y. Deeply learned view-invariant features for cross-view action recognition. IEEE Trans. Image Process. 2017, 26, 3028–3037. [Google Scholar] [CrossRef]
- Khan, M.A.; Akram, T.; Sharif, M.; Javed, M.Y.; Muhammad, N.; Yasmin, M. An implementation of optimized framework for action classification using multilayers neural network on selected fused features. Pattern Anal. Appl. 2019, 22, 1377–1397. [Google Scholar] [CrossRef]
- Ng, C.B.; Tay, Y.H.; Goi, B.-M. Recognizing human gender in computer vision: A survey. In Pacific Rim International Conference on Artificial Intelligence, Kuching, Malaysia, 3–7 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 335–346. [Google Scholar]
- Bhatnagar, G.; Wu, Q.J. A fractal dimension based framework for night vision fusion. IEEE/CAA J. Autom. Sin. 2018, 6, 220–227. [Google Scholar] [CrossRef]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. A convolutional neural network for pedestrian gender recognition. In International Symposium on Neural Networks, Dalian, China, 4–6 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 558–564. [Google Scholar]
- Antipov, G.; Berrani, S.-A.; Ruchaud, N.; Dugelay, J.-L. Learned vs. hand-crafted features for pedestrian gender recognition. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015; pp. 1263–1266. [Google Scholar]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. Comparing image representations for training a convolutional neural network to classify gender. In Proceedings of the 1st International Conference on Artificial Intelligence, Modelling and Simulation, Kota Kinabalu, Malaysia, 3–5 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 29–33. [Google Scholar]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. Training strategy for convolutional neural networks in pedestrian gender classification. In Second International Workshop on Pattern Recognition; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10443, p. 104431A. [Google Scholar]
- Raza, M.; Zonghai, C.; Rehman, S.U.; Zhenhua, G.; Jikai, W.; Peng, B. Part-wise pedestrian gender recognition via deep convolutional neural networks. In Proceedings of the 2nd IET International Conference on Biomedical Image and Signal Processing (ICBISP 2017), Wuhan, China, 13–14 May 2017. [Google Scholar]
- Sun, Y.; Zhang, M.; Sun, Z.; Tan, T. Demographic analysis from biometric data: Achievements, challenges, and new frontiers. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 332–351. [Google Scholar] [CrossRef]
- Azzopardi, G.; Greco, A.; Saggese, A.; Vento, M. Fusion of domain-specific and trainable features for gender recognition from face images. IEEE Access 2018, 6, 24171–24183. [Google Scholar] [CrossRef]
- Mane, S.; Shah, G. Facial recognition, expression recognition, and gender identification. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2019; pp. 275–290. [Google Scholar]
- Cheng, J.; Li, Y.; Wang, J.; Yu, L.; Wang, S. Exploiting effective facial patches for robust gender recognition. Tsinghua Sci. Technol. 2019, 24, 333–345. [Google Scholar] [CrossRef]
- Geetha, A.; Sundaram, M.; Vijayakumari, B. Gender classification from face images by mixing the classifier outcome of prime, distinct descriptors. Soft Comput. 2019, 23, 2525–2535. [Google Scholar] [CrossRef]
- Tapia, J.E.; Perez, C.A. Gender classification based on fusion of different spatial scale features selected by mutual information from histogram of LBP, intensity, and shape. IEEE Trans. Inf. Forensics Secur. 2013, 8, 488–499. [Google Scholar] [CrossRef]
- Tapia, J.E.; Perez, C.A.; Bowyer, K.W. Gender classification from the same iris code used for recognition. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1760–1770. [Google Scholar] [CrossRef]
- Shan, C. Learning local binary patterns for gender classification on real-world face images. Pattern Recognit. Lett. 2012, 33, 431–437. [Google Scholar] [CrossRef]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Deep Learning for Consumer Devices and Services: Pushing the limits for machine learning, artificial intelligence, and computer vision. IEEE Consum. Electron. Mag. 2017, 6, 48–56. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, K.; Sohail, A.; Conci, N.; de Natale, F. A comparative study of global and deep features for the analysis of user-generated natural disaster related images. In Proceedings of the IEEE 13th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Aristi Village, Greece, 10–12 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Tang, Y.; Yang, X.; Wang, N.; Song, B.; Gao, X. CGAN-TM: A novel domain-to-domain transferring method for person re-identification. IEEE Trans. Image Process. 2020, 29, 5641–5651. [Google Scholar] [CrossRef]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Ren, C.-X.; Liang, B.; Ge, P.; Zhai, Y.; Lei, Z. Domain adaptive person re-identification via camera style generation and label propagation. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1290–1302. [Google Scholar] [CrossRef] [Green Version]
- Karanam, S.; Li, Y.; Radke, R.J. Person re-identification with discriminatively trained viewpoint invariant dictionaries. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4516–4524. [Google Scholar]
- Li, S.; Shao, M.; Fu, Y. Person re-identification by cross-view multi-level dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2963–2977. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Chen, J.; Liang, C.; Wang, Z.; Hu, R. Cross-view identical part area alignment for person re-identification. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2462–2466. [Google Scholar]
- Chen, Y.-C.; Zhu, X.; Zheng, W.-S.; Lai, J.-H. Person re-identification by camera correlation aware feature augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 392–408. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Zeng, H.; Zhu, J.; Cao, J.; Wang, Y.; Ma, K.-K. Cascading Scene and Viewpoint Feature Learning for Pedestrian Gender Recognition. IEEE Internet Things J. 2020, 8, 3014–3026. [Google Scholar] [CrossRef]
- Cai, L.; Zhu, J.; Zeng, H.; Chen, J.; Cai, C.; Ma, K.-K. Hog-assisted deep feature learning for pedestrian gender recognition. J. Frankl. Inst. 2018, 355, 1991–2008. [Google Scholar] [CrossRef]
- Fayyaz, M.; Yasmin, M.; Sharif, M.; Raza, M. J-LDFR: Joint low-level and deep neural network feature representations for pedestrian gender classification. Neural Comput. Appl. 2021, 33, 361–391. [Google Scholar] [CrossRef]
- Cao, L.; Dikmen, M.; Fu, Y.; Huang, T.S. Gender recognition from body. In Proceedings of the 16th ACM International Conference on Multimedia, Vancouver, BC, Canada, 26–31 October 2008; ACM: New York, NY, USA, 2008; pp. 725–728. [Google Scholar]
- Guo, G.; Mu, G.; Fu, Y. Gender from body: A biologically-inspired approach with manifold learning. In Proceedings of the Asian Conference on Computer Vision, Xi’an, China, 23–27 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 236–245. [Google Scholar]
- Collins, M.; Zhang, J.; Miller, P.; Wang, H. Full body image feature representations for gender profiling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1235–1242. [Google Scholar]
- Geelen, C.D.; Wijnhoven, R.G.; Dubbelman, G. Gender classification in low-resolution surveillance video: In-depth comparison of random forests and SVMs. In Video Surveillance and Transportation Imaging Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9407, p. 94070M. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. Lightennet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Rashid, M.; Khan, M.A.; Sharif, M.; Raza, M.; Sarfraz, M.M.; Afza, F. Object detection and classification: A joint selection and fusion strategy of deep convolutional neural network and SIFT point features. Multimed. Tools Appl. 2019, 78, 15751–15777. [Google Scholar] [CrossRef]
- Khan, M.A.; Akram, T.; Sharif, M.; Awais, M.; Javed, K.; Ali, H.; Saba, T. CCDF: Automatic system for segmentation and recognition of fruit crops diseases based on correlation coefficient and deep CNN features. Comput. Electron. Agric. 2018, 155, 220–236. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Rashid, M.; Yasmin, M.; Afza, F.; Tanik, U.J. Deep CNN and geometric features-based gastrointestinal tract diseases detection and classification from wireless capsule endoscopy images. J. Exp. Theor. Artif. Intell. 2019, 33, 1–23. [Google Scholar] [CrossRef]
- Raza, M.; Sharif, M.; Yasmin, M.; Khan, M.A.; Saba, T.; Fernandes, S.L. Appearance based pedestrians’ gender recognition by employing stacked auto encoders in deep learning. Future Gener. Comput. Syst. 2018, 88, 28–39. [Google Scholar] [CrossRef]
- Cai, L.; Zhu, J.; Zeng, H.; Chen, J.; Cai, C. Deep-learned and hand-crafted features fusion network for pedestrian gender recognition. In Proceedings of the ELM-2016, Singapore, 13–15 December 2016; Springer: Berlin/Heidelberg, Germany, 2018; pp. 207–215. [Google Scholar]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. Pedestrian gender classification using combined global and local parts-based convolutional neural networks. Pattern Anal. Appl. 2018, 22, 1469–1480. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Balocco, S.; González, M.; Ñanculef, R.; Radeva, P.; Thomas, G. Calcified plaque detection in IVUS sequences: Preliminary results using convolutional nets. In Proceedings of the International Workshop on Artificial Intelligence and Pattern Recognition, Havana, Cuba, 24–26 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 34–42. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Liu, Y.; Wang, X.; Wang, L.; Liu, D. A modified leaky ReLU scheme (MLRS) for topology optimization with multiple materials. Appl. Math. Comput. 2019, 352, 188–204. [Google Scholar] [CrossRef]
- Bouvrie, J. Notes on convolutional neural networks; MIT CBCL Technical Report. Neural Nets 2006, 5869, 47–60. [Google Scholar]
- Li, Y.; Hao, Z.; Lei, H. Survey of convolutional neural network. J. Comput. Appl. 2016, 36, 2508–2515. [Google Scholar]
- Wu, J. Introduction to convolutional neural networks. In National Key Lab for Novel Software Technology; Nanjing University: Nanjing, China, 2017; Volume 5, p. 23. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features From Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Dash, M.; Liu, H. Feature selection for clustering. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2000; pp. 110–121. [Google Scholar]
- Rashno, A.; Nazari, B.; Sadri, S.; Saraee, M. Effective pixel classification of mars images based on ant colony optimization feature selection and extreme learning machine. Neurocomputing 2017, 226, 66–79. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Chang, Y.-W.; Lin, C.-J. Feature ranking using linear SVM. In Proceedings of the Workshop on the Causation and Prediction Challenge at WCCI 2008, Hong Kong, China, 3–4 June 2008; pp. 53–64. [Google Scholar]
- Dagher, I. Quadratic kernel-free non-linear support vector machine. J. Glob. Optim. 2008, 41, 15–30. [Google Scholar] [CrossRef]
- Virdi, P.; Narayan, Y.; Kumari, P.; Mathew, L. Discrete wavelet packet based elbow movement classification using fine Gaussian SVM. In Proceedings of the IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India, 4–6 July 2016; pp. 1–5. [Google Scholar]
- Liu, Z.; Zuo, M.J.; Zhao, X.; Xu, H. An Analytical Approach to Fast Parameter Selection of Gaussian RBF Kernel for Support Vector Machine. J. Inf. Sci. Eng. 2015, 31, 691–710. [Google Scholar]
- Rüping, S. SVM Kernels for Time Series Analysis; Technical Report; TU Dortmund: Dortmund, Germany, 2001; pp. 1–13. [Google Scholar] [CrossRef]
- Ayat, N.-E.; Cheriet, M.; Suen, C.Y. Automatic model selection for the optimization of SVM kernels. Pattern Recognit. 2005, 38, 1733–1745. [Google Scholar] [CrossRef]
- Haasdonk, B. Feature space interpretation of SVMs with indefinite kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 482–492. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Zhu, Q.; Fan, Z.; Qiu, M.; Chen, Y.; Liu, H. Coarse to fine K nearest neighbor classifier. Pattern Recognit. Lett. 2013, 34, 980–986. [Google Scholar] [CrossRef]
- Singh, A.P. Analysis of variants of KNN algorithm based on preprocessing techniques. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; pp. 186–191. [Google Scholar]
- Lamba, A.; Kumar, D. Survey on KNN and its variants. Int. J. Adv. Res. Comput. Commun. Eng. 2016, 5, 430–435. [Google Scholar]
- Jiang, L.; Zhang, H.; Su, J. Learning k-nearest neighbor naive bayes for ranking. In Proceedings of the International Conference on Advanced Data Mining and Applications, Guilin, China, 19–21 December 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 175–185. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In Proceedings of the Computer Vision–ECCV 2008, Marseille, France, 12–18 August 2008; ACM: New York, NY, USA, 2008; pp. 262–275. [Google Scholar]
- Deng, Y.; Luo, P.; Loy, C.C.; Tang, X. Pedestrian attribute recognition at far distance. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 789–792. [Google Scholar]
- Ma, L.; Liu, H.; Hu, L.; Wang, C.; Sun, Q. Orientation driven bag of appearances for person re-identification. arXiv 2016, arXiv:1605.02464. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer # | Layer Name | Feature Maps | Filter Depth | Stride | Padding | Pooling Window Size/Other Values |
|---|---|---|---|---|---|---|
| 1 | Data | |||||
| 2 | C_1 | [4 4] | [0 0 0 0] | |||
| 3 | R1_1 | |||||
| 4 | C4_1 | [1 1] | Same | |||
| 5 | C2 _1 | [1 1] | Same | |||
| 6 | BN1_1 | |||||
| 7 | BN2 | |||||
| 8 | BN3_1 | |||||
| 9 | LR2_1 | Scaling value 0.01 | ||||
| 10 | C3_1 | [1 1] | Same | |||
| 11 | LR1_1 | Scaling value 0.01 | ||||
| 12 | ADD1_1 | |||||
| 13 | R1_2 | |||||
| 14 | C4_2 | [1 1] | Same | |||
| 15 | BN3_2 | |||||
| 16 | LR2_2 | Scaling value 0.01 | ||||
| 17 | C2_2 | [1 1] | Same | |||
| 18 | BN1_2 | |||||
| 19 | C3_2 | [1 1] | Same | |||
| 20 | LR1_2 | Scaling value 0.01 | ||||
| 21 | ADD1_2 | |||||
| 22 | norm1 | |||||
| 23 | P1 | [2 2] | [0 0 0 0] | Maximum pooling | ||
| 24 | BN4 | |||||
| 25 | GC1(c5) | Two groups of | [1 1] | [2 2 2 2] | ||
| 26 | R2 | |||||
| 27 | norm2 | |||||
| 28 | P2 | [2 2] | [0 0 0 0] | Maximum pooling | ||
| 29 | BN5 | |||||
| 30 | GC2(c6) | [1 1] | [1 1 1 1] | |||
| 31 | R3_1 | |||||
| 32 | BN7 | |||||
| 33 | C7_1 | [1 1] | Same | |||
| 34 | BN6_1 | |||||
| 35 | C8_1 | [1 1] | Same | |||
| 36 | LR3_1 | Scaling value 0.01 | ||||
| 37 | C9_1 | [1 1] | Same | |||
| 38 | BN8_1 | |||||
| 39 | LR4_1 | Scaling value 0.01 | ||||
| 40 | ADD2_1 | |||||
| 41 | R3_2 | |||||
| 42 | C7_2 | [1 1] | Same | |||
| 43 | C9_2 | [1 1] | Same | |||
| 44 | BN8_2 | |||||
| 45 | BN6_2 | |||||
| 46 | C8_2 | [1 1] | Same | |||
| 47 | LR3_2 | Scaling value 0.01 | ||||
| 48 | LR4_2 | Scaling value 0.01 | ||||
| 49 | ADD2_2 | |||||
| 50 | GC3(c10) | Two groups of | [1 1] | [1 1 1 1] | ||
| 51 | R4 | |||||
| 52 | GC4(c11) | Two groups of | [1 1] | [1 1 1 1] | ||
| 53 | R5 | |||||
| 54 | P3 | [2 2] | [0 0 0 0] | Max pooling | ||
| 55 | BN9 | |||||
| 56 | Fc_1 | |||||
| 57 | R6 | |||||
| 58 | D1 | 50% Dropout | ||||
| 59 | Fc_2 | |||||
| 60 | R7 | |||||
| 61 | D2 | 50% Dropout | ||||
| 62 | Fc_3 | |||||
| 63 | prob | |||||
| 63 | Class output |
| Sr. No. | Datasets | Year | # Images/Videos | Views | Size | Applications |
|---|---|---|---|---|---|---|
| 1 | VIPeR | 2008 | 1264 | Side, Front, Back | 128 × 48 | Pedestrian re-identification and tracking across multi-camera network |
| 2 | MIT | 2014 | 888 | Front, Back | 128 × 48 | Pedestrian attribute analysis |
| 3 | PKU-Reid | 2016 | 1824 | Side, Front, Back | 128 × 48 | Pedestrian attribute analysis and re-identification |
| Type of Views for Testing | MIT | VIPeR | PKU-Reid | |||
|---|---|---|---|---|---|---|
| Male | Female | Male | Female | Male | Female | |
| Front | 305 | 113 | 339 | 251 | 420 | 264 |
| Back | 296 | 174 | 198 | 133 | 140 | 88 |
| Mixed | 864 | 864 | 721 | 543 | 1120 | 520 |
| Sr. No. | Performance Measures | Mathematical Representation |
|---|---|---|
| 1 | FPR | |
| 2 | Sensitivity (SE), TPR, Recall | |
| 3 | Specificity (SP), TNR | |
| 4 | Precision (PR) | |
| 5 | Accuracy (ACC) | |
| 6 | AUC | |
| 7 | F-Measure (FM) | |
| 8 | G-Measure (GM) |
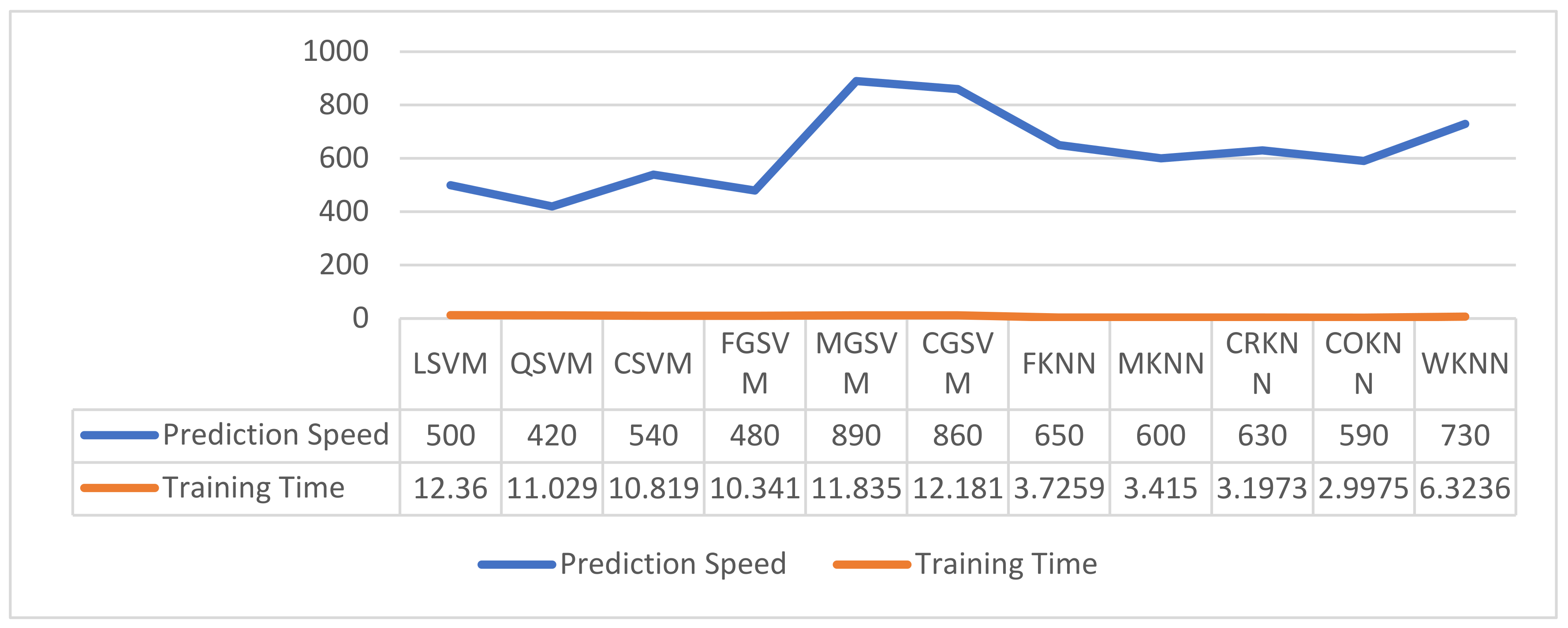
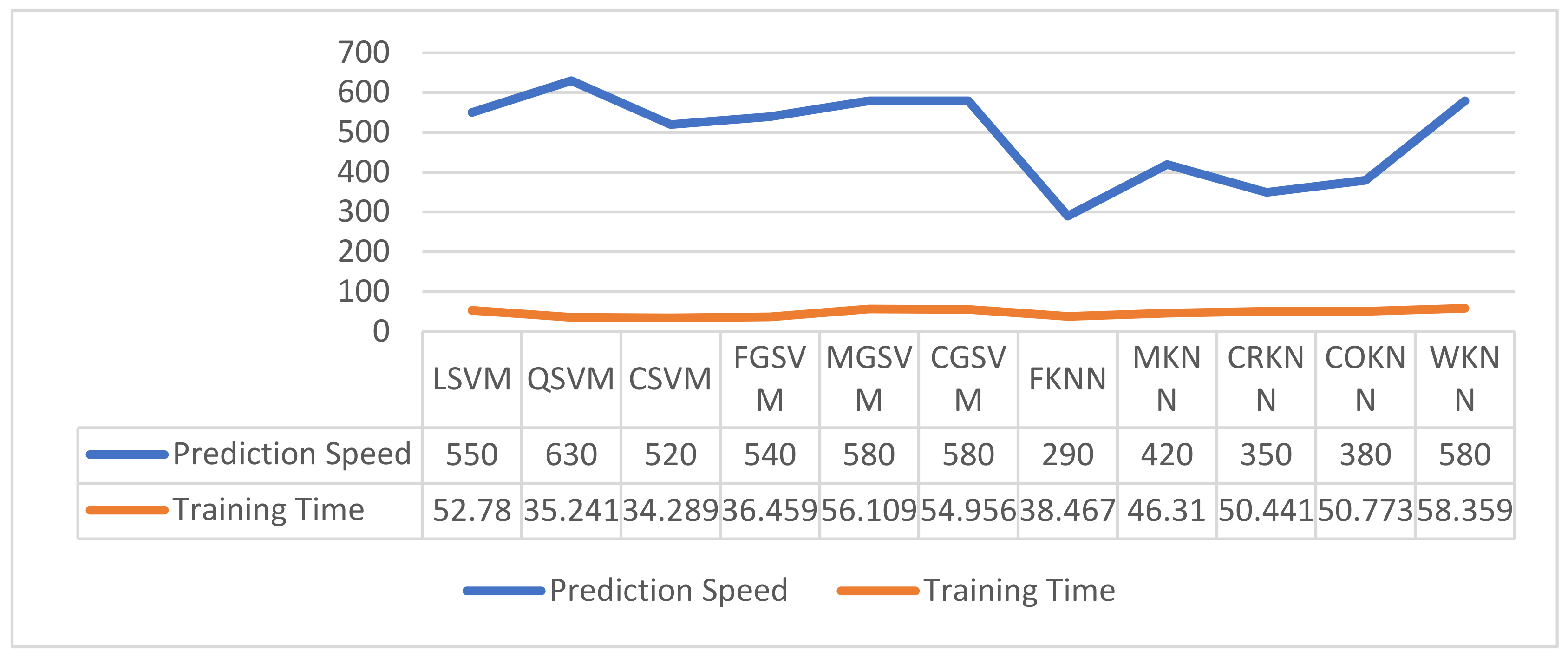
| Optimized Feature Subset No. | No. of Features | Best ACC (%) Achieved on MIT Dataset | Best ACC (%) Achieved on VIPeR Dataset | Best ACC (%) Achieved on PKU-Reid Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Front Views | Back Views | Mixed Views | Front Views | Back Views | Mixed Views | Front Views | Back Views | Mixed Views | ||
| 1 | 100 | 74.9 | 72.8 | 81.3 | 65.9 | 70.0 | 64.1 | 79.1 | 86.8 | 81.8 |
| 2 | 250 | 74.6 | 73.4 | 84.6 | 67.0 | 66.5 | 68.4 | 85.7 | 88.6 | 88.0 |
| 3 | 500 | 74.7 | 73.0 | 84.7 | 65.1 | 69.5 | 68.3 | 83.8 | 89.9 | 89.8 |
| 4 | 750 | 74.9 | 73.8 | 85.1 | 69.3 | 72.5 | 69.5 | 84.2 | 90.4 | 91.2 |
| 5 | 1000 | 74.9 | 73.8 | 85.4 | 72.9 | 70.7 | 70.3 | 85.5 | 93.0 | 91.2 |
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 74.9 | 0.70 | 99.3 | 08.9 | 74.6 | 85.2 | 29.7 | ||||
| CSVM | ✓ | 74.9 | 0.71 | 91.8 | 29.2 | 77.8 | 84.2 | 51.8 | ||||
| MGSVM | ✓ | 74.0 | 0.70 | 100.0 | 03.5 | 74.7 | 84.8 | 18.8 | ||||
| QSVM | ✓ | 74.9 | 0.71 | 92.5 | 27.4 | 77.5 | 84.3 | 50.4 | ||||
| QSVM | ✓ | 74.9 | 0.71 | 92.5 | 27.4 | 77.5 | 84.3 | 50.4 | ||||
| FGSVM | ✓ | 73.7 | 0.52 | 100.0 | 02.7 | 73.5 | 84.7 | 16.3 | ||||
| CGSVM | ✓ | 73.2 | 0.69 | 100.0 | 00.9 | 73.1 | 84.5 | 09.4 | ||||
| FKNN | ✓ | 68.9 | 0.54 | 82.3 | 32.7 | 76.8 | 79.4 | 52.0 | ||||
| COKNN | ✓ | 73.2 | 0.59 | 96.1 | 11.5 | 73.6 | 84.0 | 33.2 | ||||
| COKNN | ✓ | 73.2 | 0.59 | 95.7 | 12.4 | 74.7 | 84.0 | 34.4 | ||||
| CRKNN | ✓ | 73.0 | 0.65 | 100.0 | 00.0 | 73.0 | 84.4 | 00.0 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 73.0 | 0.77 | 91.2 | 42.0 | 72.8 | 81.0 | 61.9 | ||||
| CSVM | ✓ | 73.8 | 0.79 | 85.1 | 54.6 | 76.1 | 80.4 | 68.2 | ||||
| MGSVM | ✓ | 70.7 | 0.78 | 94.3 | 305 | 69.8 | 80.2 | 536 | ||||
| QSVM | ✓ | 73.8 | 0.79 | 83.8 | 56.9 | 76.8 | 80.1 | 69.0 | ||||
| FGSVM | ✓ | 63.0 | 0.53 | 100.0 | 00.0 | 63.0 | 77.3 | 00.0 | ||||
| CGSVM | ✓ | 65.8 | 0.77 | 99.7 | 08.1 | 64.8 | 78.6 | 28.3 | ||||
| FKNN | ✓ | 65.1 | 0.58 | 74.7 | 48.9 | 71.3 | 73.0 | 60.4 | ||||
| COKNN | ✓ | 68.3 | 0.66 | 84.5 | 40.8 | 70.8 | 77.0 | 58.7 | ||||
| CRKNN | ✓ | 63.4 | 0.70 | 100.0 | 01.2 | 63.3 | 77.5 | 10.7 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | Acc | Auc | Se | Sp | PR | FM | GM | |
| LSVM | ✓ | 76.9 | 0.84 | 77.0 | 76.8 | 77.0 | 76.9 | 76.9 | ||||
| CSVM | ✓ | 83.9 | 0.92 | 82.6 | 85.1 | 84.7 | 83.7 | 83.9 | ||||
| MGSVM | ✓ | 81.9 | 0.89 | 88.5 | 75.1 | 78.1 | 83.0 | 81.6 | ||||
| QSVM | ✓ | 81.7 | 0.89 | 81.3 | 82.1 | 81.9 | 81.6 | 81.7 | ||||
| FGSVM | ✓ | 67.3 | 0.66 | 95.1 | 39.4 | 61.1 | 74.4 | 61.2 | ||||
| CGSVM | ✓ | 75.5 | 0.80 | 76.7 | 74.2 | 74.8 | 75.8 | 75.5 | ||||
| FKNN | ✓ | 85.4 | 0.89 | 79.9 | 90.7 | 89.6 | 84.5 | 85.1 | ||||
| COKNN | ✓ | 73.7 | 0.81 | 77.3 | 70.0 | 72.1 | 74.6 | 73.6 | ||||
| CRKNN | ✓ | 67.8 | 0.74 | 75.9 | 59.6 | 65.3 | 70.2 | 67.3 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 69.3 | 0.76 | 82.3 | 51.8 | 69.8 | 75.5 | 65.3 | ||||
| CSVM | ✓ | 70.7 | 0.75 | 78.8 | 59.8 | 72.6 | 75.5 | 68.6 | ||||
| MGSVM | ✓ | 67.0 | 0.76 | 81.7 | 47.0 | 67.6 | 74.0 | 62.0 | ||||
| QSVM | ✓ | 72.9 | 0.76 | 78.8 | 64.9 | 75.2 | 77.0 | 71.5 | ||||
| FGSVM | ✓ | 57.5 | 0.57 | 100.0 | 00.0 | 57.5 | 73.0 | 00.0 | ||||
| CGSVM | ✓ | 66.8 | 0.74 | 91.5 | 33.5 | 65.0 | 76.0 | 55.3 | ||||
| FKNN | ✓ | 60.3 | 0.61 | 69.6 | 47.8 | 64.3 | 66.9 | 57.7 | ||||
| COKNN | ✓ | 64.8 | 0.68 | 80.2 | 43.8 | 65.9 | 72.3 | 59.3 | ||||
| CRKNN | ✓ | 66.8 | 0.69 | 91.5 | 33.5 | 65.0 | 76.0 | 553 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 70.7 | 0.76 | 86.9 | 46.6 | 70.8 | 78.0 | 63.7 | ||||
| CSVM | ✓ | 70.0 | 0.78 | 80.3 | 54.1 | 72.3 | 76.1 | 65.9 | ||||
| MGSVM | ✓ | 68.9 | 0.76 | 92.9 | 33.1 | 67.4 | 78.1 | 55.5 | ||||
| QSVM | ✓ | 72.5 | 0.78 | 82.8 | 57.1 | 74.2 | 78.3 | 68.8 | ||||
| FGSVM | ✓ | 59.8 | 0.51 | 100.0 | 00.0 | 59.8 | 74.9 | 00.0 | ||||
| CGSVM | ✓ | 61.9 | 0.75 | 99.5 | 60.2 | 61.2 | 75.8 | 24.5 | ||||
| FKNN | ✓ | 58.3 | 0.75 | 68.2 | 43.6 | 64.3 | 66.2 | 54.5 | ||||
| FKNN | ✓ | 58.3 | 0.75 | 64.7 | 48.9 | 65.3 | 65.0 | 56.2 | ||||
| COKNN | ✓ | 65.0 | 0.65 | 79.3 | 43.6 | 67.7 | 73.0 | 58.8 | ||||
| CRKNN | ✓ | 61.3 | 0.71 | 99.5 | 04.5 | 60.8 | 75.5 | 21.2 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 69.5 | 0.74 | 80.2 | 55.4 | 70.5 | 75.0 | 66.7 | ||||
| CSVM | ✓ | 70.3 | 0.74 | 78.0 | 60.2 | 72.2 | 75.0 | 68.5 | ||||
| MGSVM | ✓ | 68.3 | 0.75 | 84.5 | 46.8 | 67.8 | 75.2 | 62.9 | ||||
| QSVM | ✓ | 69.1 | 0.74 | 78.0 | 57.3 | 70.8 | 74.2 | 66.9 | ||||
| FGSVM | ✓ | 57.0 | 0.53 | 1.00 | 0.00 | 57.4 | 72.7 | 0.00 | ||||
| CGSVM | ✓ | 68.4 | 0.73 | 88.0 | 42.5 | 67.0 | 76.1 | 61.2 | ||||
| CGSVM | ✓ | 68.4 | 0.73 | 83.0 | 49.2 | 68.4 | 75.0 | 63.9 | ||||
| FKNN | ✓ | 58.4 | 0.56 | 66.9 | 47.2 | 62.7 | 64.7 | 56.1 | ||||
| FKNN | ✓ | 58.4 | 0.56 | 66.9 | 47.2 | 62.7 | 64.7 | 56.0 | ||||
| COKNN | ✓ | 63.2 | 0.66 | 72.9 | 50.5 | 66.1 | 69.3 | 60.7 | ||||
| CRKNN | ✓ | 60.4 | 0.69 | 98.5 | 09.8 | 59.2 | 74.0 | 31.0 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
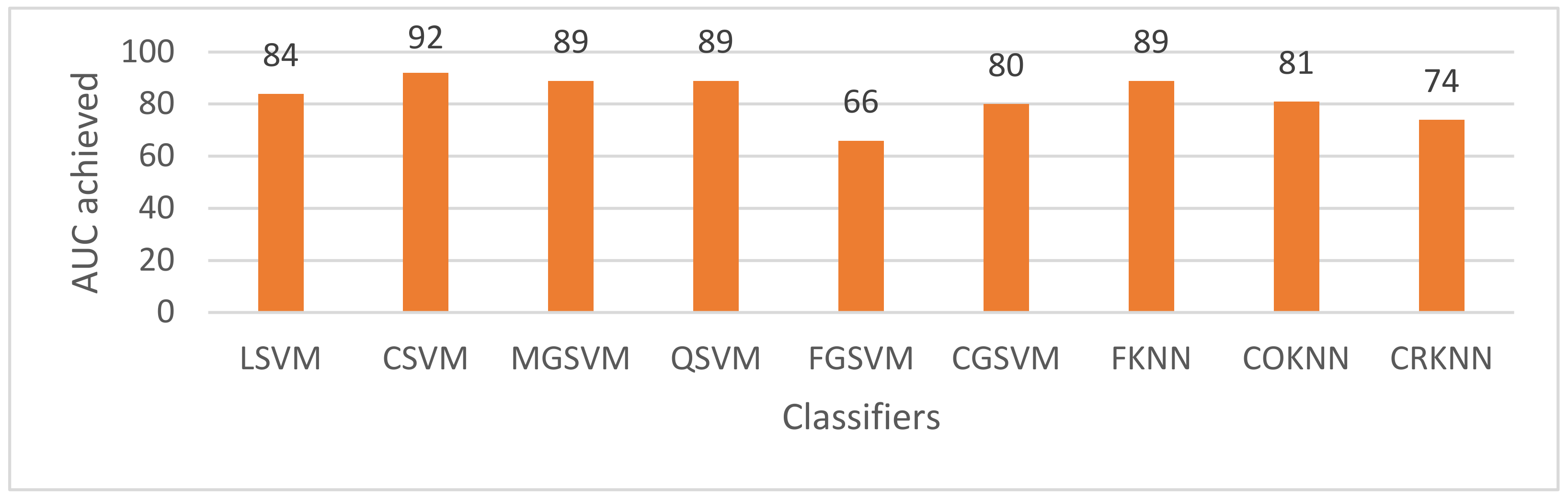
| LSVM | ✓ | 82.9 | 0.91 | 91.2 | 69.7 | 82.7 | 86.8 | 79.7 | ||||
| CSVM | ✓ | 85.7 | 0.93 | 91.2 | 76.9 | 86.3 | 88.7 | 83.7 | ||||
| MGSVM | ✓ | 82.2 | 0.92 | 92.9 | 65.2 | 80.9 | 86.5 | 77.8 | ||||
| QSVM | ✓ | 84.2 | 0.92 | 89.5 | 75.8 | 85.5 | 87.4 | 82.4 | ||||
| FGSVM | ✓ | 61.4 | 0.65 | 100.0 | 00.0 | 61.4 | 76.1 | 00.0 | ||||
| CGSVM | ✓ | 82.3 | 0.89 | 94.8 | 62.5 | 80.1 | 86.8 | 77.0 | ||||
| FKNN | ✓ | 74.3 | 0.71 | 85.2 | 56.8 | 75.9 | 80.3 | 69.6 | ||||
| COKNN | ✓ | 78.1 | 0.84 | 89.3 | 60.2 | 78.1 | 83.3 | 73.3 | ||||
| CRKNN | ✓ | 66.1 | 0.84 | 99.5 | 12.9 | 64.5 | 78.3 | 35.8 | ||||
| CRKNN | ✓ | 66.1 | 0.84 | 98.8 | 14.0 | 64.6 | 78.2 | 37.2 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 90.4 | 0.96 | 97.1 | 79.6 | 88.3 | 92.5 | 87.9 | ||||
| CSVM | ✓ | 93.0 | 0.96 | 97.9 | 85.2 | 91.3 | 94.5 | 91.3 | ||||
| MGSVM | ✓ | 86.0 | 0.95 | 96.4 | 69.3 | 83.3 | 89.4 | 81.8 | ||||
| QSVM | ✓ | 92.5 | 0.96 | 97.1 | 85.2 | 91.3 | 94.1 | 91.0 | ||||
| FGSVM | ✓ | 61.4 | 0.59 | 100.0 | 00.0 | 61.4 | 76.1 | 00.0 | ||||
| CGSVM | ✓ | 87.7 | 0.94 | 99.3 | 69.3 | 83.7 | 90.9 | 83.0 | ||||
| FKNN | ✓ | 75.4 | 0.72 | 90.7 | 51.1 | 74.7 | 82.0 | 68.1 | ||||
| COKNN | ✓ | 80.7 | 0.89 | 92.1 | 62.5 | 79.6 | 85.4 | 75.9 | ||||
| CRKNN | ✓ | 61.4 | 0.85 | 100.0 | 00.0 | 61.4 | 76.1 | 00.0 | ||||
| Classification Methods | Optimized Feature Subsets | Evaluation Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 250 | 500 | 750 | 1000 | ACC | AUC | SE | SP | PR | FM | GM | |
| LSVM | ✓ | 87.4 | 0.93 | 88.7 | 86.0 | 86.4 | 87.5 | 87.3 | ||||
| CSVM | ✓ | 91.2 | 0.96 | 91.4 | 91.0 | 91.0 | 91.2 | 91.2 | ||||
| CSVM | ✓ | 91.2 | 0.96 | 91.2 | 91.2 | 91.2 | 91.2 | 91.2 | ||||
| MGSVM | ✓ | 88.5 | 0.95 | 90.5 | 87.0 | 87.4 | 88.7 | 88.5 | ||||
| QSVM | ✓ | 90.4 | 0.95 | 91.1 | 89.8 | 89.9 | 90.5 | 90.4 | ||||
| FGSVM | ✓ | 56.7 | 0.59 | 97.9 | 15.5 | 53.7 | 69.4 | 39.0 | ||||
| FGSVM | ✓ | 56.7 | 0.59 | 97.9 | 15.5 | 53.7 | 69.4 | 39.0 | ||||
| CGSVM | ✓ | 87.1 | 0.91 | 89.1 | 85.1 | 85.7 | 87.3 | 87.1 | ||||
| FKNN | ✓ | 82.0 | 0.71 | 84.0 | 80.1 | 80.8 | 82.4 | 82.0 | ||||
| COKNN | ✓ | 81.8 | 0.87 | 89.7 | 73.9 | 77.4 | 83.1 | 81.4 | ||||
| CRKNN | ✓ | 79.1 | 0.87 | 86.5 | 71.7 | 75.4 | 80.6 | 78.8 | ||||
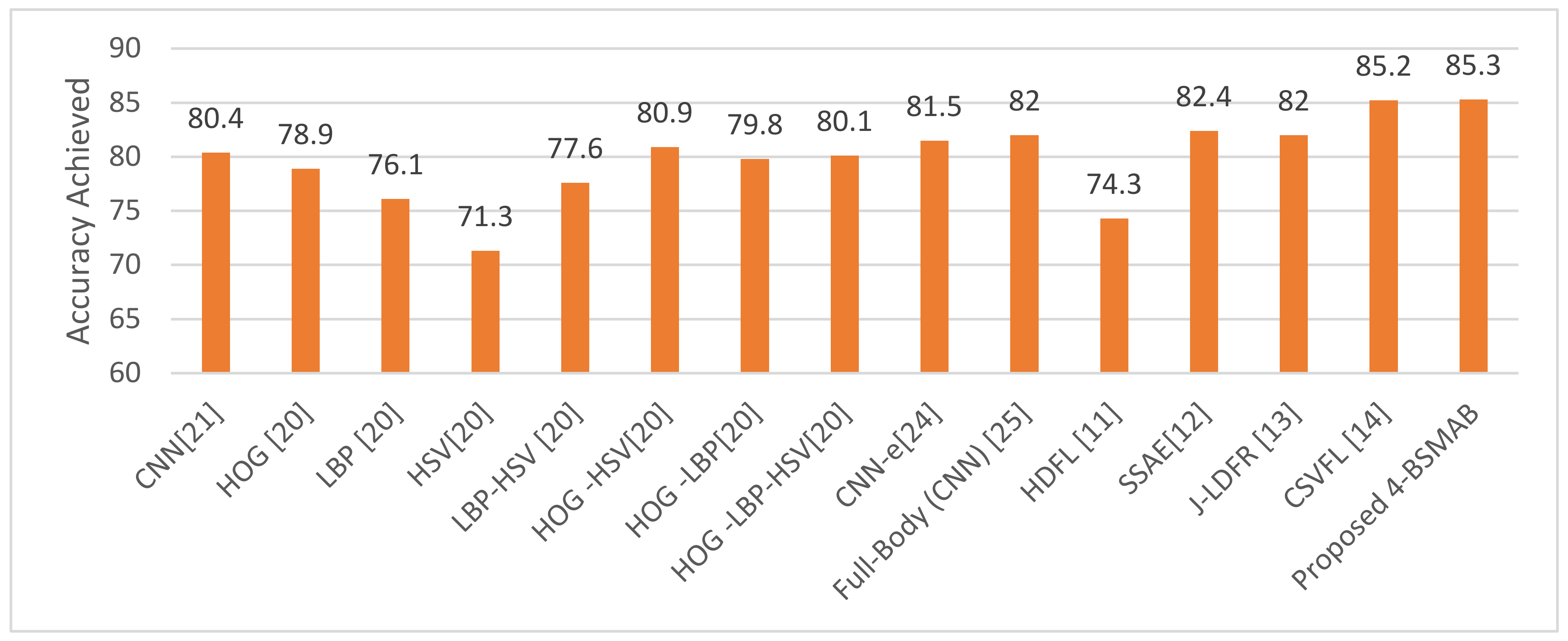
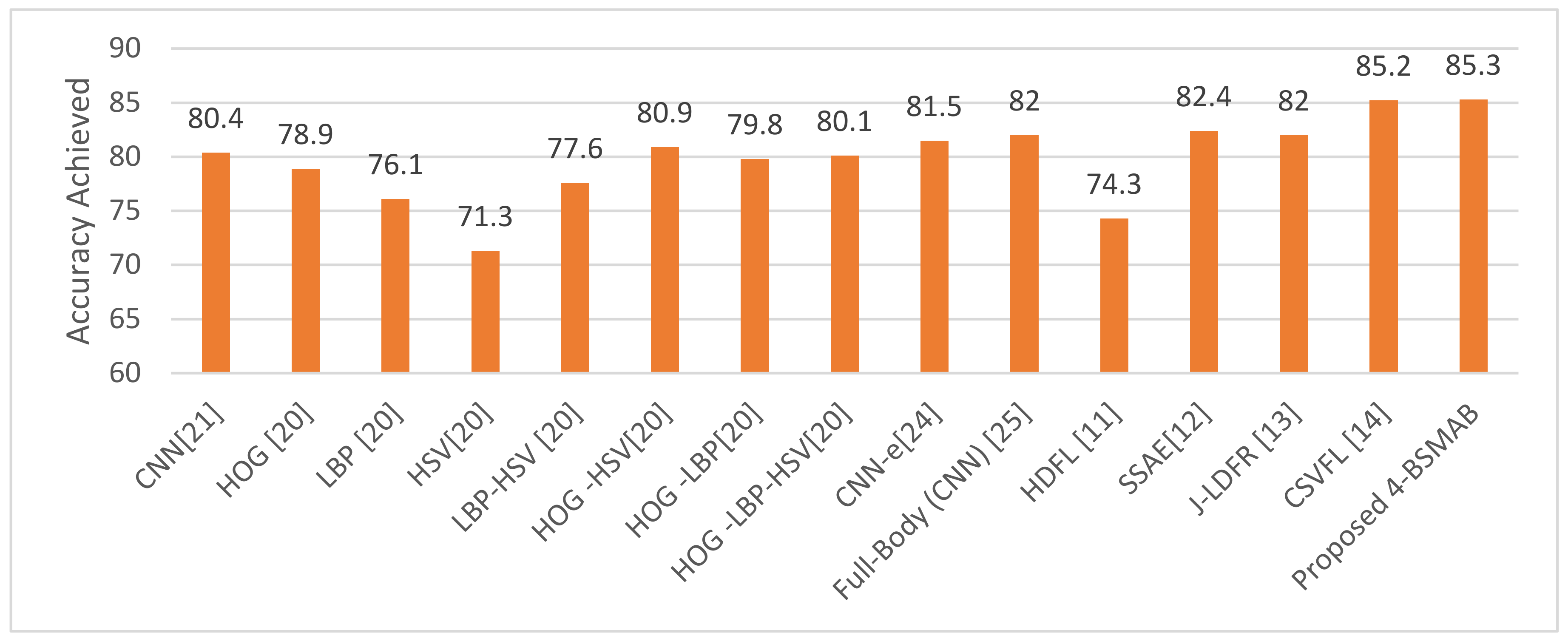
| Methods | Year | ACC (%) Using Mixed Views |
|---|---|---|
| CNN [16] | 2013 | 80.4 |
| HOG [45] | 2015 | 78.9 |
| LBP [45] | 2015 | 76.1 |
| HSV [45] | 2015 | 71.3 |
| LBP-HSV [45] | 2015 | 77.6 |
| HOG -HSV [45] | 2015 | 80.9 |
| HOG -LBP [45] | 2015 | 79.8 |
| HOG -LBP-HSV [45] | 2015 | 80.1 |
| CNN-e [19] | 2017 | 81.5 |
| Full-Body (CNN) [20] | 2017 | 82.0 |
| HDFL [40] | 2018 | 74.3 |
| SSAE [51] | 2018 | 82.4 |
| J-LDFR [41] | 2021 | 82.0 |
| CSVFL [39] | 2021 | 85.2 |
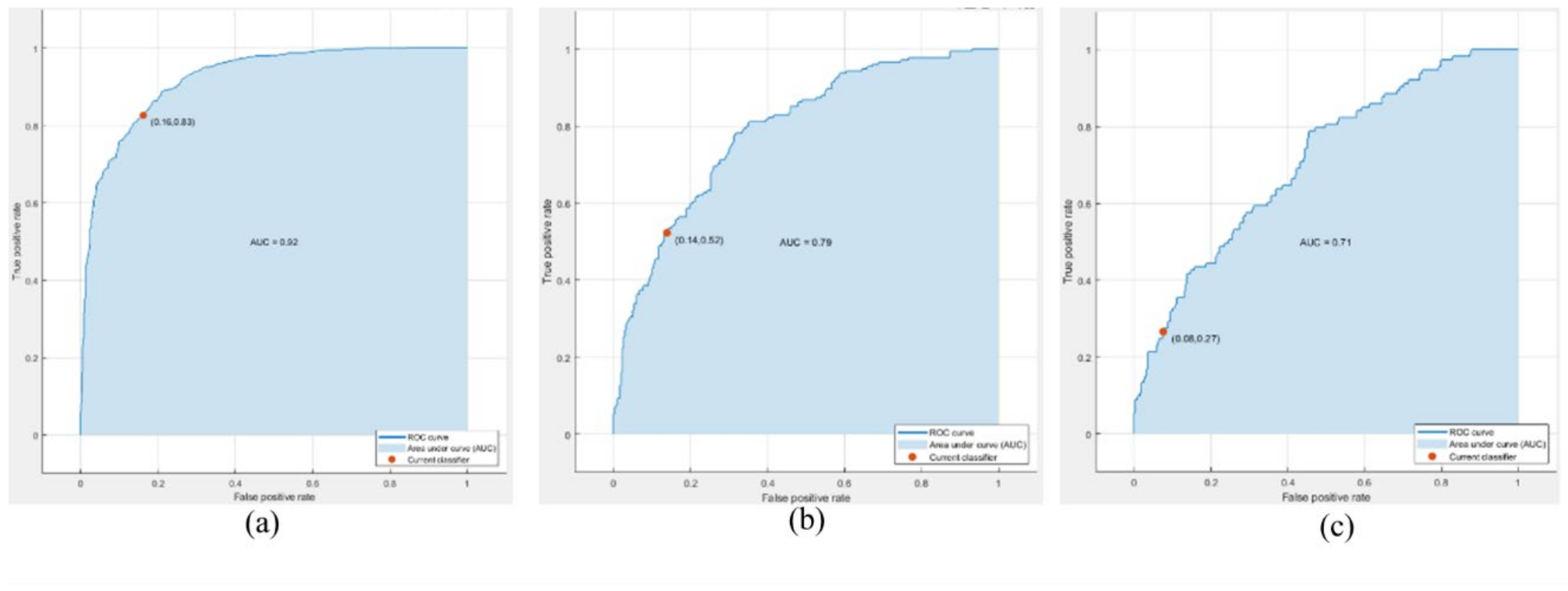
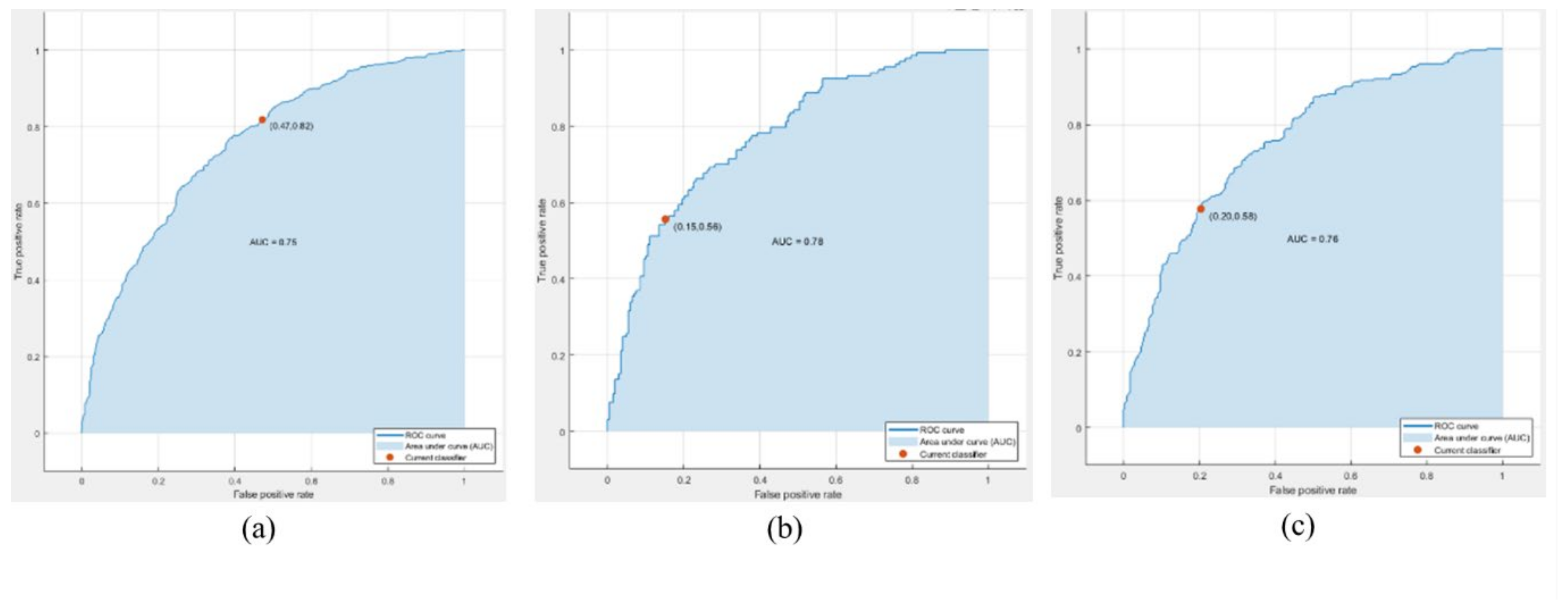
| Proposed 4-BSMAB | Proposed | 85.4 |
| Methods | Year | AUC (%) Using Mixed Views |
|---|---|---|
| J-LDFR [41] | 2021 | 86.0 |
| Proposed 4-BSMAB | Proposed | 92.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, F.; Yasmin, M.; Fayyaz, M.; Abd Elaziz, M.; Lu, S.; El-Latif, A.A.A. Gender Classification Using Proposed CNN-Based Model and Ant Colony Optimization. Mathematics 2021, 9, 2499. https://doi.org/10.3390/math9192499
Abbas F, Yasmin M, Fayyaz M, Abd Elaziz M, Lu S, El-Latif AAA. Gender Classification Using Proposed CNN-Based Model and Ant Colony Optimization. Mathematics. 2021; 9(19):2499. https://doi.org/10.3390/math9192499
Chicago/Turabian StyleAbbas, Farhat, Mussarat Yasmin, Muhammad Fayyaz, Mohamed Abd Elaziz, Songfeng Lu, and Ahmed A. Abd El-Latif. 2021. "Gender Classification Using Proposed CNN-Based Model and Ant Colony Optimization" Mathematics 9, no. 19: 2499. https://doi.org/10.3390/math9192499
APA StyleAbbas, F., Yasmin, M., Fayyaz, M., Abd Elaziz, M., Lu, S., & El-Latif, A. A. A. (2021). Gender Classification Using Proposed CNN-Based Model and Ant Colony Optimization. Mathematics, 9(19), 2499. https://doi.org/10.3390/math9192499