Abstract
In an increasingly globalized market, the relationship between the customer and the brand goes beyond the purchasing process. It is very important to understand the customer, to know their needs and to propose actions to increase the value of the brand for them. In the literature, there are several models capable of determining and segmenting customers according to variables dependent on the purchasing process. However, we have not found any study that applies to the business case of classifying customers according to their relationship with the contact centre. In this paper, we establish a working model that allows us to define the value of the customer in the process of interaction with the contact centre, so that we can propose actions both in the sales phase and during the post-sales service, so that the value and perception of the brand is increased. In this model, we propose using the value of recency, frequency, importance and duration of customer interactions with the post-sales service, thus obtaining a ranking, and grouping of customers to help establish personalized communication strategies. We have verified this model by presenting a business case applied to the telecom sector.
1. Introduction
The last decade has witnessed what is known as the Fourth Industrial Revolution. Factors that have contributed to this change include information storage and processing capacity, as well as speed of communication []. We live in a hyper-connected society, with more than half of the world’s population connected to the Internet. Almost 52% of web traffic originates from a mobile device. The total number of active users on social networks is 3725 million. In one minute more than 87,500 people use Twitter, there are 2.1 million snaps on Snapchat, 46,200 photos on Instagram, and 4.5 million plays on YouTube. In addition, Google exceeds 3.8 million requests, and App Store and Google Play generate 390,000 app downloads [].
From a consumer perspective, this digital disruption is transforming the way in which users relate to brands []. Further, in this sense, each population segment, each customer defines their own customer journey of their relationship with the brand [], thus creating a greater understanding of the customer experience and their journey through their different interactions through any channel. On the other hand, attracting customers is important, but even more important is being able to retain them—thus, marketing strategies are focused on this process of retaining the most profitable customers [].
There are various models that try to make the customer management process profitable from a marketing and sales point of view, trying to build customer loyalty. In this sense, one of the most widely used models based on the following sales parameters—recency, frequency and monetary (RFM). This model was introduced by Hughes in 1994, Strategic database marketing []. This model has been used to categorize the customer in such a way that marketing actions can be focused on them (cross-selling, upselling, etc.) according to the category to which they belong [].
Another important use of the RFM model is to measure customer lifetime value (CLV) [,]. This value will also determine the strategy and the et of marketing actions that should be carried out with that customer. An extension of the RFM model to improve its linguistic interpretability and accuracy is based on using the fuzzy two-tuple linguistic model [,].
A crucial aspect of the customer centric philosophy is to consider that communications between the company and the customer are bidirectional, and that the customer wants to be served consistently and through any channel. The importance of technology in addition to strategy is fundamental and customer relationship management (CRM) based systems allow for multi-channel integration and therefore have, a deeper knowledge of the customer [,,], for better customer management. Therefore, a crucial aspect for any Customer Centric strategy is the proper implementation of customer support processes integrated in the CRM and carried out by the contact centre.
Despite the proven and validated utility of the RFM model, it does not consider the interactions that occur between the company and the customer after the sale process and which, in many cases, are as or more important than the sale itself, to establish a true customer centric strategy. Everyday examples in relation to these post-sales interactions could be, a delay in the delivery of an order, a defective delivery, a deficient quality in the support service, etc.
After a detailed review of the literature related to customer service measurement, the focus in these reviews is set on the evaluation of customer satisfaction in one direction only, the customer’s opinion of the service provided by the contact centre, using a set of metrics linked to the customer satisfaction score (CSAT). The aim of this paper is to evaluate and establish a customer centric strategy in the processes of customer relations with the after-sales service, for which we propose a new model, which we have called RFID, based on RFM, and extended with the two-tuple model for the reasons mentioned above, so that it allows customer service experts to establish customer relationship strategies based on their interaction with the contact centre. This provides a 360° view of the relationship between the customer and the brand.
The proposed model is based on four parameters that have a direct impact on quality of service [,] and are present in the data model of any CRM, see Figures 4 and 6, which are crucial in case management during customer support processes: , when the client last opened a case; , how often the customer interacts with the contact centre; , what is the importance of customer interactions; and , how long it has taken to resolve issues. A crucial aspect such as establishing the importance of each of the variables in the model will be solved by using the analytical hierarchy process (AHP).
The RFID model developed in this article has been applied to the telecommunications sector, mainly because the contact centre is a vital element in the management process of the relationship between customer and brand. Although with the RFM model, the contact centre staff has adequate metrics for the personalisation of the interaction with the customer, we believe that the data provided is incomplete, as this model only considers the evaluation of the customer based on their purchases. Therefore, we consider that the RFID model complements and provides additional value to customer-brand loyalty processes.
In the remainder of this paper we will develop and apply the RFID model, according to the following structure: in Section 2, we will review the current state of the customer service metrics, and the use of the RFM methodology and its application scenarios, contrasting the existing GAP between the models developed and the one proposed in this article; in Section 3, we will address the model we will use in the definition of the RFID model; in Section 4, we will detail the proposed model; in Section 5, we will apply the RFID model using the CRM applied to a company in the telecom sector as a technological base; and finally in Section 6 and Section 7, we will set out the conclusions and future work.
2. Related Work
The studies reviewed in relation to after-sales service are based on the customer’s assessment of the brand or service provided through satisfaction surveys. For this reason, we believe it is of interest to have a 360° evaluation of the customer service process, as is performed with the RFM model in which the customer is evaluated on the basis of their purchases, in this case we propose to evaluate the customer through the history of their relationship with the after-sales service. We, therefore, believe that the RFM model, which has been so successful in obtaining customer value CLV in purchasing processes, can be applied intuitively to obtain customer value in customer service processes.
Next, in Section 2.1, we will review the literature related to studies on the valuation of after-sales service; in Section 2.2, we will review the studies and uses of the RFM model; and in Section 2.3, we will summarise the methodologies used and the need for the use of the proposed RFID model.
2.1. Customer Service Metrics
Customer satisfaction is an important metric in marketing science, and there are countless studies that refer to the need to properly manage the relationship between customer and brand. The following study covers the five key dimensions of service quality measurement: reliability, assurance, tangibility, empathy and responsiveness []. An extension of the previous study adapted to the particularities of contact centre [] identifies the following dimensions as fundamental in the customer–brand relationship process: reliability, empathy, customer knowledge, customer focus, waiting time, user-friendliness and accessibility.
Based on the quality and customer satisfaction model, we can highlight the following metric as one of the most widely used, net promoter score (NPS) proposed by F. Reichheld [] which uses the value of the customer’s recommendation of the brand as a measure of loyalty. Similar studies to this one includes the customer effort score (CES) [] which is based on the idea of reinforcing the value of customer interaction in a simple way, prioritising solutions over speed. In the following study [], the authors highlight that although these metrics have some intuitive power, they lack solid theoretical development, they focus on a specific CES domain or they focus on ad-hoc NPS transactions, underlining that multiple customer feedback metrics predict customer behaviour better than a single metric. Table 1 lists the main studies based on customer experience rating metrics:

Table 1.
Customer Services Metrics.
2.2. Studies and Uses of the RFM Model
In a customer-oriented RFM process, the objective is to classify customers according to their purchasing behavior. In this way, we can segment the group of customers and initiate marketing actions according to their profile (buyer persona) using CRM as a technological tool and customer journey as a design tool []. Therefore, we can discover, for example, the most valuable customers, those we have to incentivize, those who are in danger of abandoning the relationship with the brand, etc. [].
In recent years, data mining techniques have been used to carry out customer segmentation processes, such as Chi-squared automatic interaction detection (CHAID), logistic regression, and neural networks, etc. However, the trend in marketing environments is to use the RFM model in combination with other models, mainly because of the easy interpretability of the model and the possibility of making explainable decisions [].
Down below, a review of the different uses and applications of the RFM model in different business settings and other types of organisations will be displayed.
The traditional use of the RFM model helps us to classify customers, either by obtaining the CLV or by acting as a predictor for future customer behaviour. The main studies in this direction can be found in Table 2.
Table 2.
CLV-Related Studies.
Next, we elaborate on the literature related to the RFM model considering the sector and business case.
The following study [] proposes an integrated model for the management of bank credit card customers. A neural network was used to segment customers based on repayment behaviour and the RFM model, thus classifying customers into groups from most to least profitable.
In this other study [], the RFM model was used to segment the customers of a bank so that the CLV of each customer could be calculated by applying k-means clustering.
Outside the business environment, [] suggested as a key element in the relationship between citizens and public administrations the main objective of getting to know the citizen, encouraging them to participate in public decisions on the services they can consume.
In the following study [], it was proposed to distinguish customer value based on pre-purchase motivations. The results predict that frequency is the best indicator of customer value, above recency and monetary value.
In a different framework [], a model to evaluate the power of influence of brand prescribers was exhibited, adapting the RFM model by using a neural network to identify the most active recommenders and evaluating the effectiveness of the model by contrasting it with a product review website.
In another study, [] presented an approach for the possible detection of fraudulent credit card transactions in online transactions, using RFM to perform the analysis of the customer’s purchase history.
In the healthcare sector, [] proposed a customer tracking methodology to obtain special clusters and trends, the aim being to detect “potentially loyal” and “potentially disposable” customers, so that loyalty campaigns could be optimised. The proposed model is based on the traditional RFM model, but incorporating an additional variable, L, which defines patient loyalty.
On the other hand, and applied to the world of mobile games, [] suggested to work on a model for detecting customers with a high predisposition to abandon, using logistic regression analysis within the framework of the RFM model.
A model focused on extending customer loyalty via additional services to the products sold is detailed in the following publication [], in which the RFM model extended into four specific product-support-service variants is used.
Aimed at the hotel sector, the work carried out by [] is oriented towards the use of the RFM model, but adapting it and incorporating another criterion to replace the Monetary variable, which they have called Helpfulness (RFH), aggregating the information that users enter in social media by means of a two-tuple.
Hwang and Lee [] have presented a model focused on the perspective of launching a new product on the market so that we could use the RFM model, but only with the recency and frequency variables of customers website access data. Thus, allowing marketers to find target customers with no purchase history.
As can be seen, the RFM model can be applied to different business and government sectors, where it is necessary to classify the customer, patient or citizen, with the ultimate goal of personalising actions on population segments, identifying customers and analysing their profitability [].
Table 3 provides an overview of the annotated use cases classified by sectors/policy frameworks.
Table 3.
CLV Studies and Application to Sectors and Business Models.
2.2.1. Advantages and Limitations of the RFM Model
The main advantage of the RFM model is its ease of application, as customer sales data are almost always available. From these transactions, and with the use of the quantifiable variables already mentioned, it is possible to easily explain the groupings in profiles by similar behaviour, to identify the most valuable customers, and to establish individual or group actions []. On the other hand, the collection of information is performed through corporate tools such as CRM [] so that we do not have to carry out large information aggregation processes to obtain results that are understandable to decision-makers [].
RFM-based approaches have limitations, one of which is the lack of precision. Scores are expressed by n-scales , where n represents the highest contributing coefficient and 1 the lowest. Typically, , i.e., quintiles are often used. Furthermore, the importance of each RFM measure depends on the type of company [] and even on the seasonality of the service. Furthermore, and finally, the model may have biases in the case of customers who have a short lifetime in their relationship with the brand [].
In the literature review we have not found any study that applies to the business case of classifying customers according to their relationship with the contact centre. As we have seen in Section 2.1, the studies collect customer feedback through satisfaction surveys (CSAT, NPS, CES). That is why we consider RFID modelling to be a fundamental complement to the customer segmentation and evaluation process.
2.2.2. An Extension of the RFM Model
Given the limitations of RFM models, some authors have considered including extensions to the model using the fuzzy two-tuple linguistic model to solve the aforementioned lack of precision []. A frequent problem in the application of the model is to determine the weight of each of the variables, which obviously depends on business criteria. Some authors solve this problem by using AHP [] which allows this type of decision to be made easily by means of pairwise comparisons and consistency checks. Frequently, authors propose the use of clustering algorithms such as k-means after the application of the RFM model [], k-means is one of the most widely used algorithms in clustering processes [] providing in our model a segmentation and classification of customers so that a strategy can be defined for each grouping. In the model proposed in this article, these improvements to the original model will be used.
2.3. Summary
As we have seen in the previous sections, the RFM model is applied in several studies to obtain the CLV in sales processes, see Table 2 and Table 3. However, if we want to know the degree of customer satisfaction, we will use survey-based metrics such as NPS and CES, see Table 1. Models based on customer satisfaction are simple to implement but lack a solid theoretical development and focus on a specific area CES or ad-hoc transactions NPS [], they are based on collecting the customer’s opinion after the service has been provided.
The novelty of the RFID model lies in analysing customer value from the point of view of the contact centre, thus providing a 360° view between customer and brand. In this way, traditional service evaluation models (NPS, CES) can be complemented with the customer value provided by the RFID model through the history of customer interactions with the contact centre, in the same way that the RFM model obtains customer value from the purchases they make.
3. Methodology
The proposed model is based on three important models that will be explained in this section: the two-tuple fuzzy linguistic model, the RFM model and the AHP.
3.1. The Two-Tuple Fuzzy Linguistic Model
The two-tuple model proposed by [], has the objective of improving the problems of information loss present in the computational processes with linguistic labels. The following is a brief review of the linguistic model of two-tuple representation and its computational model. This model has as its basis of representation a pair of values (, where i and .
Definition 1.
Leta set of linguistic terms, anda value in the granularity interval of S. The symbolic translation of a linguistic term if its values are a number valued in the intervalwhich expresses the difference in information between a quantity of information expressed by the valueobtained in a symbolic operation and the nearest integer value,, which indicates the index of the nearest linguistic label () nearest in S.
This representation model defines a pair of functions to perform transformations between numerical values defined in the granularity interval and two-tuple linguistic values to perform the computational processes on two-tuple linguistic values.
Definition 2.
Leta set of linguistic terms,anda value representing the result of a symbolic operation then the linguistic two-tuple expressing information equivalent tois obtained using the following function:
whereis the visual rounding operator,is the label with index closest toandis the value of the symbolic translation.
Thus, a value in the interval is always identified with a two-tuple linguistic value in .
Definition 3.
Leta set of linguistic terms andthe numerical value in the granularity intervalrepresenting the linguistic value two-tupleis obtained using the function:
Along with the representation model seen above, we can analyse the associated computational model, for which the following operators are defined:
Two-tuple linguistic value comparison operator. Given two two-tuple linguistic values and representing quantities of information:
- If , then is less than .
- If , then
- (a)
- If , then and represent the same information.
- (b)
- If , then is less than .
- (c)
- If , then is greater than .
Negation operator of a two-tuple linguistic value. It is defined as:
where g +1 is the cardinality of the set of linguistic labels S.
Aggregation operators for two-tuple linguistic values. Information aggregation consists of obtaining a two-tuple linguistic value that summarises a set of two-tuple values. We describe the aggregation operators that we will use in our model:
Definition 4.
Leta vector two-tuple linguistic values in, the linguistic value two-tuple symbolising the arithmetic mean,, is given by the functiondefined as:
Definition 5.
Leta vector two-tuple linguistic values in, andwherea vector of weights such that, then the linguistic value two-tuple symbolising the weighted mean associated with omega is given by the functiondefined as:
3.2. Two-Tuple RFM Model
The RFM model follows a methodology that allows us to segment customers according to similar characteristics. It is used to measure recency, frequency and monetary value in customer transactions with the brand.
The idea, therefore, is to categorise each customer by scores based on these three variables [], typically using quintiles (5 represents the top 20% of customers on that variable and 1 represents the bottom 20%), from which a single score is calculated representing the customer’s value. However, these scores are not very accurate, so in the work by [] an improvement of the RFM is proposed, which consists of representing these scores using the two-tuple model. The stages of this proposal are explained below:
- Data collect. Let be the set of customers who have made at least one purchase over a pre-established analysis period. Let bet the details of transactions or purchases made by such customers in that period, where the U, identifies the customer of such a purchase on the date di for the amount of ai.
- Customer aggregation. In this phase, T is aggregated, at customer level, obtaining the set , where re would be the days since the last purchase of such customer ue (using a later fixed reference date for all customer purchases), re is the number of times the customer has purchased, and me contains the total amount of those purchases.
- Score’s computation. Set with the two-tuple RFM scores is obtained. First, a symmetric and uniformly distributed domain S using five linguistic labels is defined. These labels have a semantic meaning for the variables of the RFM model referred:
Let be with , with the definition showed in Figure 1.
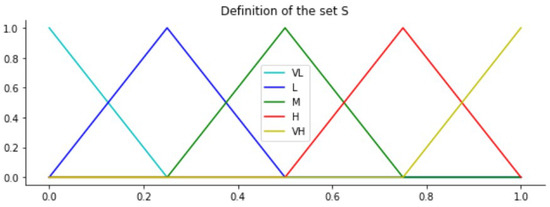
Figure 1.
Definition of the set S.
Therefore, we have the variables to calculate: . For each customer , we obtain with . Firstly, customers are sorted in ascending order according to each of the individual components with , contained in TU. Now, we define as the ranking of each client respect to each of these variables:
with and . The final two-tuple score is obtained as following:
where and have been defined in Section 3.1 (Equations (1) and (3)). We use the negation function on recency because the larger scores represent the most recent buyers.
- RFM Overall Score computation. In this step, the two-tuple , which characterizes together the Re, Fe and Me scores, is calculated for each customer using the Equation (5) as , with the user-defined weights previously defined by the marketing experts.
3.3. Analytical Hierarchical Process (AHP)
Among the multi-criteria decision marking models (MCDM) is the method called analytical hierarchical process, AHP []. Based on mathematics and psychology, it is designed to solve complex multi-criteria problems.
The main characteristic of the AHP is that the decision problem is modelled by means of a hierarchy in whose upper vertex is the main objective of the problem, the goal to be achieved, and at the base are the possible alternatives to be evaluated. The intermediate levels represent the criteria (which in turn can also be structured in hierarchies) since which the decision is made. The second feature of the method is that, at each level of the hierarchy, comparisons are made between pairs of elements at that level, based on the importance or contribution of each to the higher-level element to which they are linked. Finally, once the contribution of each element to the elements at the next higher level of the hierarchy has been assessed, the overall contribution of each alternative to the main objective or goal is calculated by means of an additive aggregation [,].
In our model, we will use the AHP method to establish the weights of each of the criteria that will determine the total score of each customer, after the aggregation and ranking process using the RFM two-tuple model.
A review of the AHP method and its applications can be found in the following references [,]. This whole process is detailed in the following sub-sections.
3.3.1. Structuring of the Decision Problem into a Hierarchical Model
The first step of the AHP method is to model the decision problem to be solved as a hierarchy. This fact is one of the main characteristics of the method, hence the term “hierarchical” appears in its name.
It consists of the decomposition of the decision problem into elements, according to their common characteristics, constructing in a visual way a hierarchical model of different interrelated criteria, facilitating their understanding and evaluation. The first level always contains the goal of the problem, G, the second level is constituted by the criteria, this level can be subdivided into sub-criteria, and the last level contains the different alternatives. Thus, in this step we define de alternatives set and the hierarchical criteria for assessing them C. , each of these criteria can, in turn, be subdivided into sub-criteria, in several levels, and so recursively, Figure 2.
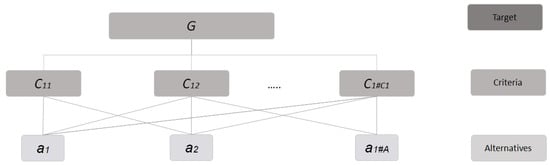
Figure 2.
Hierarchic System of Problem.
3.3.2. Making Pair-Wise Comparisons and Obtaining the Judgmental Matrix
In this step, the opinion of the decision makers is used to compare in pairs, the elements of a particular level with respect to a specific element in the immediate superior level, let be a pairwise comparison matrix where elements represent the importance of criterion i over criterion j evaluated by the decision makers, where judgments about the relative importance of one criterion over another with respect to the goal, as well as about the relative importance of one sub-criterion over another with respect to the main dimension, which are represented from the predefined rating scale of numbers of Table 4. Each entry of the judgmental matrix are governed by the three rules: > 0; reciprocal property; and for all i.
Table 4.
Saaty’s Scale [].
3.3.3. Obtaining Local Weights and Consistency of Comparisons
The criteria weight vector, W, is built using the eigenvector method through the following equation:
where is the is the maximum eigenvalue of PW and is the normalized eigenvector associated to the main eigenvalue of PW []. This approach provides the best priority weights for each criterion or sub-criterion. The consistency of the AHP can be checked by the consistency ratio (CR) which is defined as:
that is, the division between the consistency index (CI), defined as and the random consistency index (RI) which represents the consistency of a randomly generated pairwise comparison matrix. If CR ≤ 0.1 the results of the individual hierarchical type are satisfied and coherence is guaranteed, otherwise it will be necessary to adjust the values of the elements of the pairwise comparison, and the judgments should be caused once again by the decision makers up to that are more consistent.
4. RFID Proposed Model
Based on the ticket information stored in a conventional operational CRM, our model obtains two types of recommendations for customers based on their customer service behaviour: individualised and group based. The model is parameterised with the information provided by the customer support experts. These same users are also in charge of determining and implementing the final treatment strategies for customers.
The process we are going is as follows: in Section 4.1, we retrieve the data from the CRM; in Section 4.2, we carry out a pre-processing of the information in which we define the period of analysis; in Section 4.3, we carry out the aggregation process by customer; in Section 4.4, we apply the two-tuple model on the data obtained in the previous step; in Section 4.5, we obtain the global valuation of each customer by applying the AHP model; in Section 4.6, we establish an individual recommendation strategy. If we want to establish a group strategy, starting from the results of Section 4.4, we group the customers according to the k-means model to finally obtain the recommendation strategy by groups.
The proposed model is showed in Figure 3 and each step is explained more detailed below:
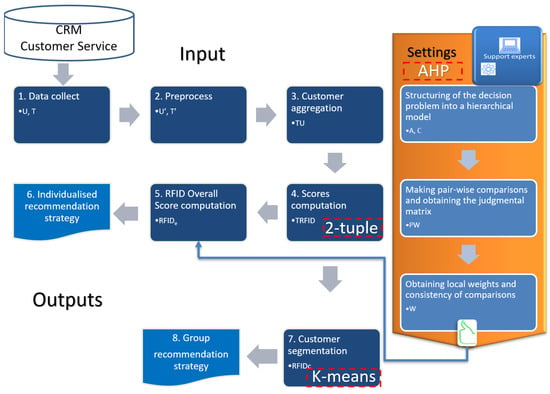
Figure 3.
RFID Proposed Model.
4.1. Data Collect
In the CRM terminology, trouble tickets or cases [] are any kind of customer service requests or complaints as they occur after sales.
Let be the details of these requests, where:
- : is a code that uniquely identifies each trouble ticket requested by the customer , with .
- : is the date on which the service was initially required.
- : is a code that identifies the status of the ticket with respect to its management, e.g., initiated, resolved, cancelled, etc.
- : the service required by the customer has a process by which the ticket goes through several states, in this variable the date corresponding to the last state in which the ticket is stored.
- : identifies the type of request, complaint or trouble the customer has.
- : relevance of the ticket which is a standard feature of most CRMs. It is usually expressed on an ordinal and/or linguistic scale of n-values such that the higher the value, the higher the relevance of the ticket. In this article we will consider that the scale has five values very low, low, moderate, high, very high. As it is a linguistic scale, we will consider modelling it with the set S.
In Figure 4, the details of a new ticket are presented in the Salesforce CRM tool, a correspondence between fields is established, .
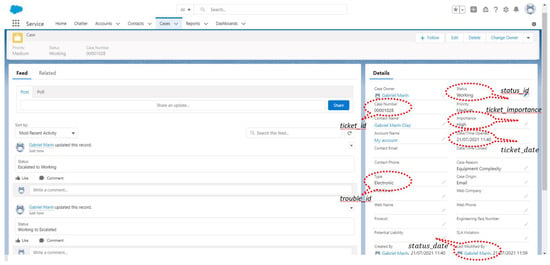
Figure 4.
Salesforce Case New.
4.2. Preprocess
Given a time period, t, for analysis enclosed by the dates and with , at this stage it is necessary to identify the actual service requests from customers to be analysed. Thus, we need to identify all tickets from the set T within the analysis period t, i.e., their status_datei belongs to that period t, that do not correspond to final contract cancellation requests as we consider them to be customers that can no longer be managed. This is easy because the tickets contain a field that categorizes its type, i.e., trouble_idi
We represent this set as bet the details of these requests made by such customers in that period t.
4.3. Customer Aggregation
We represent the set of customers as , such that each of them has made at least one service request over a pre-established analysis period t, in other words, they are the different customers contained in the set T′. In this phase, T′ is aggregated at this customer level , considering the different tickets ticket_idi for that customer in such set T′. Thus, we obtain the set where:
- re: it is the days since the last request for service of such customer ue (using as a reference the end date of the analysis period). Therefore , where diffdays is a function that returns the difference in days between two dates, and max is a function that return the last date of the different dates of entry.
- fe: it is the number of times the customer has made a service request, i.e., with different ticket codes ticket_idi.
- ie: it is the average importance. As it is a linguistic variable this value is calculated for each customer using the Equation (4) as ie = .
- de: contains the total duration in days of all customer’s tickets. Therefore, .
4.4. Scores Computation
In this step, the set with the two-tuple scores is obtained.
Therefore, we have the variables to calculate: . For each customer , we obtain with . Firstly, customers are sorted in ascending order according to each of the individual components , with contained in TU. With and , the final two-tuple score is obtained as following:
where and have been defined Equations (1) and (3) respectively and percent_rank in Equation (6). We use the negation function on recency because the larger scores represent customers with more recent requests.
4.5. RFID Overall Score Computation
In this step, the two-tuple , which characterizes together the scores, is calculated for each customer using the Equation (5) as , with the user-defined weights obtained from the information provided by the customer service experts.
As other authors have suggested [], we propose the use of the AHP model introduced in Section 3.3. We follow the typical phases of this process:
4.5.1. Structuring of the Decision Problem into a Hierarchical Model
In order to structure the MCDM it is necessary to define the available alternatives and the required criteria. The criteria (C) and alternatives (A) are the RFID score variables: A = {R, F, I, D}. Figure 5 shows the hierarchy of the proposed AHP model.
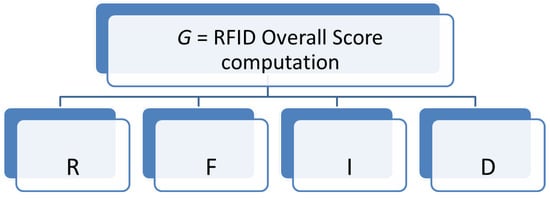
Figure 5.
AHP Hierarchy.
4.5.2. Making Pair-Wise Comparisons
The customer service experts fill in the pairwise matrix, PW, corresponding to the criteria of the hierarchical model—C, expressing the relative importance of each RFID variable over others in order to compute the overall score computation at customer level.
4.5.3. Obtaining Local Weights and Consistency of Comparisons
To ensure the coherence of the given matrix, their CR (Equation (8)), must be lower or equal than 0.1. If the CR is not good enough, it will be considered that the business specifications do not meet their quality criteria, that is, they may contradict each other. Once the consistency is checked, the weight of each criterion is calculated as we defined in Section 3.3.3 (Equation (7)). The weights for each of the RFID alternatives are expressed as follows: .
4.6. Individualized Recommendation Strategy
In a customer-centric management model, it is essential to take into account the after-sales support requested by customers [,].
Using , calculated in the previous stage, it is possible to characterize and manage each customer individually, based on all the services required by them. It should be noted that it is a two-tuple value that allows for easy interpretation, while allowing for high measurement precision. This high accuracy also allows us to rank customers in such a way that we can prioritize those with the highest value for management and monitoring.
4.7. Customer Segmentation
The objective of this phase is to obtain homogeneous groups of customers based on RFID variables that allow common strategies to be established for each of them. For this purpose, we will use the most commonly used clustering algorithm in machine learning, i.e., k-means. Some of its advantages are []: low complexity, computationally fast and ability to handle large data sets (has even been adapted for big data problems []). The use of this algorithm has the additional advantage that it has been adapted for the two-tuple model []. Some of the main disadvantages are []: sensitive to outliers and to scale of the data set. In our case, this will not be a problem since the scale is always expressed in the two-tuple model and also, since it is based on ranking (see Equation (9)), it will hardly generate outliers.
In this step, the set , where each identifies the cluster to which each customer belongs. The input variables to the segmentation algorithm are two-tuple values, this case has already been solved by other authors []. Based on this approach, the values of these centroids will be expressed using the two-tuple model, thus we get a better linguistic interpretability. In order to apply the algorithm, we use the Euclidean distance dec between a client and a cluster centroid following:
for each customer , for each cluster with the centroid , . In each step of the k-mean algorithm, we recalculate the new cluster centroid using the Equation (4): .
A typical problem when using k-means is the selection of the optimal number of groups [], #c. In this article we will use an eclectic approach, using several methods for this purpose, synthesized in [].
4.8. Group Recommendation Strategy
As the different clusters obtained are easily interpretable as they are described with the two-tuple linguistic model, customer service experts can establish different treatment strategies for customers belonging to these segments.
5. Proposed Model Applied to Telecom Industry
In this section, we present an example of an application of our RFID model, explained in the above section, using the CRM information of a multinational service company with regarding to the part of its business located in Spain.
5.1. Data Collect
Ticket information is managed by the company in an operational CRM developed by the company itself. Although in-depth details about such a CRM have not been provided to us, its structure is quite conventional and analogous in its data model to other CRMs such as the one presented in Figure 6. Therefore, to obtain the set T, the following specifications are used:
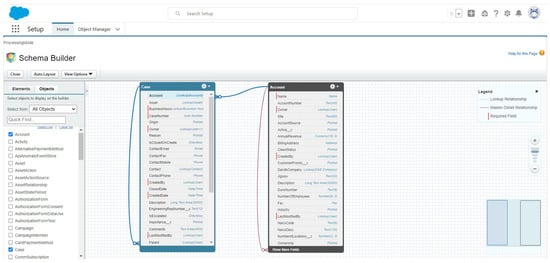
Figure 6.
Salesforce CRM. Data Model for Ticket Management.
5.2. Preprocess
The time period, t, for analysis is enclosed by the dates and . Based on information from the CRM contained in T, we obtain all the trouble tickets that have been managed during this period t, i.e., . As mentioned above, only tickets that do not correspond to customer cancellations are selected, using .
Under these conditions we obtain T′ with a total number of tickets of 13619, i.e., . An extract from this table is shown in Table 5 with several selected clients for whom we will follow the whole process.
Table 5.
Extract of T′.
5.3. Customer Aggregation
We group the different customers in T′, giving a total of 6789, i.e., . Thus, we obtain the set TU with the specifications mentioned above. An extract from this set is shown in Table 6.
Table 6.
Extract of TU.
5.4. Scores Computation
The set TU at this stage is used to obtain the TRFID set as explained in the previous section. RFID contains the basic variables of this new model. In Table 7, we present an extract from this set for the same customers as shown in Table 6.
Table 7.
Extract of TRFID.
5.5. RFID Overall Score Computation
At this stage, the importance of each of the variables in the RFID model must be obtained before calculating the RFID overall score of the customer. For this, as mentioned above, the AHP model will be used. The consulted expert has specified the following matrix using the Saaty’s scale (Table 4):
Only when CR ≤ 0.10 (see Equation (8)) the results of the individual hierarchical type are satisfied, and coherence is guaranteed. In this case, CR = 0.091 therefore the results are valid for the model.
The final weights calculated are . Therefore, the expert has attached the greatest importance to the recency of the tickets, followed by its frequency and relevance. The overall duration of its resolution is the least important.
As mentioned above, with this W we obtain the RFID overall score for each customer. In Table 8 we present the results for the same customers as shown in Table 5.
Table 8.
RFID overall score for some customers.
5.6. RFID Overall Score Computation
The RFID overall score allows to quantify how carefully the service to these customers should be managed. As an example, Table 9 shows the company’s most valuable RFID customers. As can be seen, those with a very high recency and frequency predominate, as these are the variables with the greatest weight in W. It should be noted that the use of the two-tuple model allows for high linguistic interpretability as well as high precision in the results.
Table 9.
RFID Overall Score for Some Customers.
All these customers should be given special attention in their interaction with the contact centre, for example, Customer 23420561 has an overall score , which gives them a very high importance for the company, with very high recency and frequency values.
5.7. Customer Segmentation
As commented, the RFID variables are expressed in the two-tuple model, which allows for easy interpretation and can be computed without loss of information. However, in this phase, in order to follow the conventional segmentation process, we will work with these variables converted to a numerical scale using the function (Equation (2)).
Therefore, as all variables are on the same scale, no additional normalisation process is necessary. Nevertheless, a study of the correlations between variables is necessary, since a high correlation between them indicates the unsuitability of using a Euclidean distance, which is the one used by the k-means algorithm. Figure 7 shows the Pearson correlation matrix. The highest correlation is between recency and duration with 0.3, which can be considered non-significant.
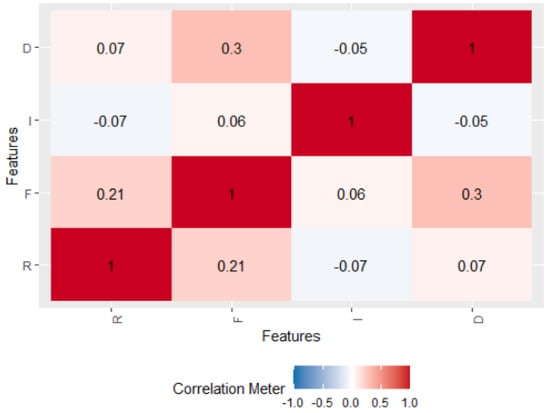
Figure 7.
Correlation Matrix of Variables.
As mentioned above, to solve the typical problem of obtaining the optimal number of segments, we will use the method proposed in []. This method offers the user the best clustering scheme (i.e., better k) among different results after using different indexes. The final number of clusters is proposed based on most indices. After application in R language (using the NbClust package to determine the optimal number of clusters between 6 and 12) the summary of the different algorithms for determining the optimal number of segments is showed in Table 10. As can be observed in Figure 8, most algorithms determine that the optimal number of clusters is 8. Therefore, in our case . Although we have applied an automatic method of terminating the number of clusters, it should be noted that it is common to also consider business criteria in the determination of the final clustering. In this way, we have also tried segmentation by changing the value of k and we were also satisfied with the one that obtained eight clusters.
Table 10.
Number of Clusters Proposed by the Different Indices.
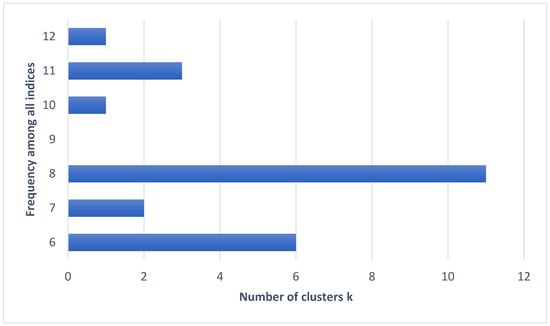
Figure 8.
Summary of the Different Indices for Determining the Optimal Number of Segments.
Once the k-means algorithm has been applied, using the Euclidean distance (see Equation (10)) the results are shown in Table 11.
Table 11.
Result of the k-Means Algorithm.
5.8. Group Recommendation Strategy
The clustering results, summarised in Table 11, are obtained after applying the function (Equation (2)) to each of the variables in the TRFID set. This has allowed for a more accurate process than is typically applied in traditional RFM models. However, to better understand clusters it is preferable to use the linguistic representation of them. This is achieved by applying the corresponding ∆ function (Equation (1)) to the centroids, see Table 12.
Table 12.
Result of the k-Means Algorithm Expressed in the Two-Tuple Model.
To support this information, Figure 9 shows the distribution of all segmented customers by each of the variables used in this segmentation.
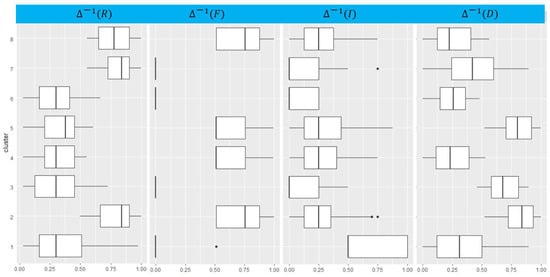
Figure 9.
Distribution of All Customers by Segment.
Table 13 depicts the recommendation strategies by customer profile, each grouping responding to a profile with the segment distribution observed in Figure 9. The recommendation metrics to be used in future two-way customer-brand interactions should be based on providing the highest quality of service with the objective of obtaining maximum customer satisfaction [,,,].
Table 13.
Recommendation Strategy by Each Cluster.
Based on the previous premise, the main objective of recommendation strategies by profile will be to personalise the customer’s interaction with the brand, analysing the level of personalisation in interactions with the contact centre and thus connecting better emotionally with customers [,].
We try to ensure that the customer groups that need personalised attention, that is, the groups that we consider critical (strongcustom, custom) receive this personalised attention in the next interaction with the contact centre. Further, the groups that we do not consider so critical (selfcustom, self) can manage themselves autonomously or through a bot.
Table 14 shows the final segment assigned to the customers shown in Table 5, Table 6, Table 7 and Table 8.
Table 14.
Extract of for Some Clients.
In Table 14, eight different customers are evaluated, explaining their belonging to the cluster profiles defined in Table 13. Based on their cluster, we can consider, among other actions to be taken in the interaction between customer and brand, measuring the degree of personalisation in subsequent interactions and defining marketing actions appropriate to the profile.
Customer profile—21046586 fits Cluster 5, as it is a customer with the following individual assessment, . Therefore, they are a customer with very high and frequent incidents, the recency is moderate and with a low importance value, see Table 7. The type of attention will be personalised.
The customer profile—21334657 fits Cluster 2, as it is a customer with the following individual assessment: . Therefore, they are a customer with very high duration and frequent incidents, the recency is very high and with a medium value of importance, see Table 7. This customer profile is considered of critical relevance for the brand and will be attended to in a personalised way.
The profile of Customer 2288774 fits Cluster 3, as it is a customer with the following individual assessment: . Thus, they are a customer with very infrequent incidents of very high duration, the recency is very low and with an average value of importance, see Table 7. This customer profile has not given the brand many problems, they are loyal customers who had initial problems linked to the implementation processes, in the following customer interactions with the contact centre, it is recommended to use self-help bot and in the case of requiring personalisation, they would switch to a free agent.
The customer profile 24583147 fits Cluster 6, as it is a customer with the following individual assessment: . Therefore, they are a customer with low duration and very infrequent incidents, the recency is low and with a very low value of importance, see Table 7. This customer profile, as in the previous case, has not given the brand many problems. In the following customer interactions with the contact centre, it is recommended to use the self-help bot, and to look for a self-response in the interaction with the customer.
Customer Profile 25860618 fits Cluster 4, as it is a customer with the following individual assessment: . Hence, this is a customer with very frequent incidents of low duration, the recency is medium, as is the importance, see Table 7. With this customer profile, although the recency and importance value are medium, special care must be taken in subsequent customer interactions with the contact centre to personalise communication by means of generalist and, if necessary, specialised agents.
Customer Profile 25864456 fits Cluster 1, as it is a customer with the following individual assessment: . Therefore, they are a customer with very low duration and moderate frequency incidents, the recency is very low, and the importance very high, see Table 7. This customer profile corresponds to customers with very important incidents in the past. In subsequent customer interactions with the contact centre, it is recommended to use self-help bot, and if customisation is required because the customer demands it, it could be changed from an automatic channel to a customised and even specialised one.
The customer profile—26053204 fits Cluster 7, as it is a customer with the following individual assessment: . Therefore, it is a customer with incidents of very low duration, importance and frequency, and the recency is very high, see Table 7. This customer profile corresponds to loyal customers with few, although recent, problems, which is why it is important that if the frequency value is increased, the customer is directed towards a personalised service.
The customer profile 26064419 fits with Cluster 8, as it is a customer with the following individual assessment, . Thus, it is a customer with incidents of low duration and importance, high frequency, and recency, see Table 7. This customer profile corresponds to loyal customers with frequent and recent problems, it is, therefore, important to direct the customer towards a personalised service.
6. Discussion
The data that we have worked on in the previous sections come from a company that implements telecommunications services. As a conclusion to this study, and applied to this company, by analysing the volume of data, we can see that the opening and closing times of tickets is high and is mainly due to the implementation processes of 4G technology in rural environments, where the periods of the implementation processes and reach optimal coverage levels are high.
The working model we have used allows us to have an individual classification of customers according to the criteria defined in the relationship between the customer and the contact centre, RFID. For this we have adapted the RFM model, widely used in marketing for its simplicity of use and ease of interpretation, into an environment other than the traditional one, in this case customer service. In addition, with the aim of improving the model and based on previous work [] in which the two-tuple model is applied to solve the problem of the RFM model’s lack of precision, we have also used the AHP methodology to give weight to each of the variables that make up the model and thus obtain an overall score for each customer. In parallel, we have provided the model with an additional argument, i.e., the possibility of classifying customers using k-means.
We have obtained two types of results, the first one helps us to establish an individual classification strategy with each customer according to the criteria defined in the RFID model, which will help us to quantify the care with which each customer’s attention must be managed individually according to their classification, see Table 9. In a typical operation, the agent in charge of managing that interaction recognises the customer and, therefore, recommendations can be established based on their history of relationship with the brand, not only by what they buy (RFM), but also by the history of the RFID service received.
Furthermore, on the other hand, we have proceeded to segment customers by applying k-means so that we are able to apply group actions by customer profile. In this case, we have focused on using these groupings to establish scenarios from lowest to highest cost in the process of customer interaction with the brand, i.e., we try to ensure that the customer groups that need personalised attention, that is, the groups that we consider critical (strongcustom, custom) receive this personalised attention in the next interaction with the contact centre. The brand image perceived by the user grows considerably with this type of interaction []. In addition, on the other hand, the groups that we do not consider so critical (selfcustom, self) can manage themselves autonomously or through a bot, thus, the cost of the interaction is lower, and the brand image does not suffer, see Table 13.
Finally, we have given some recommendations about the campaigns that could be more effective: considering customer segmentation, seeking loyalty between customer and brand for clusters susceptible to abandonment, rewarding the most loyal customers to contribute to generating brand image through content and, as always, using the leverage of offers and promotions.
For practical purposes, we have evaluated different customers in each cluster and analysed the actions that could be taken from a contact centre perspective, see Table 14. Basically, based on the value of the cluster, we have recommended personalisation actions and possible campaigns in an omnichannel environment.
It is at the discretion of the contact centre manager to use one model or the other, or both. With the aim of establishing strategies that help in the process of customer brand loyalty, since the evaluation that a customer makes of the brand not only depends on the product or service it provides, but also depends on additional factors such as personalisation, attention through multiple communication channels and excellence in the services provided [].
The developed model can be applied to different industries, in business to business (B2B) or business to customer (B2C) models where the contact centre becomes a fundamental element in the relationship between customer and brand. Sectors such as tourism, professional services, manufacturers, insurance companies, banks, retailers, public entities, hospitals, and health centres have CRM tools that are integrated with the contact centre. If in an interaction between customer and brand, the agent who handles the management has an adequate assessment of the customer, the agent can understand and personalise the communication. If we also equip the system with an artificial intelligence (AI) model, the system will be able to recommend the best actions for the profile of the customer the agent is dealing with. Furthermore, and finally, we use customer aggregated value for queue management in the contact centre.
7. Conclusions and Future Work
In conclusion, it should be noted that this work has developed a completely new model of customer evaluation through their relationship with the contact centre, RFID. This model can be added to the RFM model and thus obtain aggregated results of customer evaluation through the different points of interaction between customer and brand (sales and after-sales), with the advantage that all the information processed by the model can be found in the usual customer management systems of any company, CRM, and is therefore, applicable to any industry. This will help us to have a better knowledge of the customer, and therefore, to develop and implement actions that tend to contribute to the enrichment of the brand image.
The use of the two-tuple model has allowed us to calculate the score of the RFID model with greater precision, as well as to obtain a better linguistic interpretation of each customer’s score. The use of k-means has also permitted us to perform a clustering of customers, and to establish group strategies for both personalisation and campaign development. Finally, thanks to the use of AHP, it has been possible to determine the weight of each of the variables of the RFID model in a simple way and with a consistency check according to the business information.
As an example, we have applied the implemented model to a dataset from a company in the telecom sector, verifying the advantages of adding the new model to the traditional CLV calculation model, using RFM.
As future work, we propose to extend the model to any industry, focusing on retail, insurance, banking, service provision and software manufacturers. In addition, we propose to enrich the customer engagement value (CEV) model developed by [], incorporating RFID as another element to be taken into account. On the other hand, the model can help to elaborate user profiles (customer, patient, citizen), incorporating AI algorithms and contribute to personalise communication with the user. Further, and finally, a fundamental part is to consolidate the model with what customers think, i.e., to contrast the model with customer satisfaction, NPS.
Author Contributions
Conceptualization, G.M.D. and R.A.C.; methodology, G.M.D. and R.A.C.; software, G.M.D. and R.A.C.; validation, G.M.D., R.A.C. and D.G.; formal analysis, G.M.D. and R.A.C.; investigation, G.M.D.; resources, G.M.D., R.A.C. and D.G.; data curation, G.M.D. and R.A.C.; writing—original draft preparation, G.M.D.; writing—review and editing, G.M.D., R.A.C. and D.G.; visualization, G.M.D.; supervision, D.G. and R.A.C.; project administration, G.M.D. and R.A.C.; funding acquisition, Not applicable. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been partially supported by the Government of Spain, Grant Plan Nacional de I+D+i, MTM2015-70550-P, PGC2018096509-B-I00.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Oztemel, E.; Gursev, S. Literature review of Industry 4.0 and related technologies. J. Intell. Manuf. 2020, 31, 127–182. [Google Scholar] [CrossRef]
- Ali, A. Here’s What Happens Every Minute on the Internet in 2020. 2020. Available online: https://www.visualcapitalist.com/every-minute-internet-2020/ (accessed on 23 July 2021).
- Kumar, V.; Rajan, B.; Gupta, S.; Pozza, I.D. Customer engagement in service. J. Acad. Mark. Sci. 2019, 47, 138–160. [Google Scholar] [CrossRef]
- Lemon, K.N.; Verhoef, P.C. Understanding Customer Experience Throughout the Customer Journey. J. Mark. 2016, 80, 69–96. [Google Scholar] [CrossRef]
- Wei, J.; Lin, S.; Wu, H. A review of the application of RFM model. Afr. J. Bus. Manag. 2010, 4, 4199–4206. [Google Scholar]
- Hughes, A.M. Strategic Database Marketing; Probus Publishing: Chicago, IL, USA, 1994. [Google Scholar]
- Shih, Y.-Y.; Liu, C.-Y. A method for customer lifetime value ranking—Combining the analytic hierarchy process and clustering analysis. J. Database Mark. Cust. Strat. Manag. 2003, 11, 159–172. [Google Scholar] [CrossRef][Green Version]
- Sohrabi, B.; Khanlari, A. Customer Lifetime Value (CLV) Measurement Based on RFM Model. Iran. Account. Audit. Rev. 2007, 14, 7–20. [Google Scholar]
- Khajvand, M.; Zolfaghar, K.; Ashoori, S.; Alizadeh, S. Estimating customer lifetime value based on RFM analysis of customer purchase behavior: Case study. Procedia Comput. Sci. 2011, 3, 57–63. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, M.F.; García-Madariaga, J.; Herrera-Viedma, E. A Fuzzy Linguistic RFM Model Applied to Campaign Management. Int. J. Interact. Multimed. Artif. Intell. 2019, 5, 21. [Google Scholar] [CrossRef]
- Bueno, I.; Carrasco, R.A.; Porcel, C.; Kou, G.; Herrera-Viedma, E. A linguistic multi-criteria decision making methodology for the evaluation of tourist services considering customer opinion value. Appl. Soft Comput. 2021, 101, 107045. [Google Scholar] [CrossRef]
- Payne, A.; Frow, P. The role of multichannel integration in customer relationship management. Ind. Mark. Manag. 2004, 33, 527–538. [Google Scholar] [CrossRef]
- Kumar, V.; Reinartz, W. Customer Relationship Management: Concept, Strategy, and Tools LK, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2018; 411p, Available online: https://ucm.on.worldcat.org/oclc/1050446648 (accessed on 2 July 2021).
- Verhoef, P.C. Understanding the Effect of Customer Relationship Management Efforts on Customer Retention and Customer Share Development. J. Mark. 2003, 67, 30–45. [Google Scholar] [CrossRef]
- Van Dun, Z.; Bloemer, J.; Henseler, J. Perceived customer contact centre quality: Conceptual foundation and scale development. Serv. Ind. J. 2011, 31, 1347–1363. [Google Scholar] [CrossRef]
- Abdullateef, A.O.; Sanuri, S.; Mokhtar, M.; Yusoff, R.Z. The impact of CRM Dimensions on Call Center Performance. OR Spectr. 2010, 10, 184–194. Available online: http://proquest.umi.com/pqdweb?did=669649341&Fmt=7&clientId=65345&RQT=309&VName=PQD (accessed on 23 July 2021).
- Parasuraman, A.; Zeithaml, V.A.; Berry, L.L. A Conceptual Model of Service Quality and Its Implications for Future Research. J. Mark. 1985, 49, 41. [Google Scholar] [CrossRef]
- Reichheld, F.F. The one number you need to grow. Harv. Bus. Rev. 2003, 81, 46–54. Available online: www.hbr.org (accessed on 15 June 2021). [PubMed]
- Dixon, M.; Freeman, K.; Toman, N. Stop trying to delight your customers. Harv. Bus. Rev. 2019, 88, 7–8. [Google Scholar]
- Gupta, S.; Zeithaml, V. Customer Metrics and Their Impact on Financial Performance. Mark. Sci. 2006, 25, 718–739. [Google Scholar] [CrossRef]
- An Doorn, J.; Leeflang, P.S.; Tijs, M. Satisfaction as a predictor of future performance: A replication. Int. J. Res. Mark. 2013, 30, 314–318. [Google Scholar] [CrossRef]
- De Haan, E.; Kannan, P.K.; Verhoef, P.C.; Wiesel, T. The Role of Mobile Devices in the Online Customer Journey; Marketing Science Institute Report No. 15–124; 2015; pp. 1–56. Available online: https://www.msi.org/working-papers/the-role-of-mobile-devices-in-the-online-customer-journey/ (accessed on 16 June 2021).
- De Keyser, A.; Lemon, K.N.; Klaus, P.; Keiningham, T.L. A Framework for Understanding and Managing the CX. Work. Pap. Ser. 2015, 15, 1–47. [Google Scholar]
- Grewal, D.; Levy, M.; Kumar, V. Customer Experience Management in Retailing: An Organizing Framework. J. Retail. 2009, 85, 1–14. [Google Scholar] [CrossRef]
- Morgan, N.A.; Rego, L.L. The Value of Different Customer Satisfaction and Loyalty Metrics in Predicting Business Performance. Mark. Sci. 2006, 25, 426–439. [Google Scholar] [CrossRef]
- Korneta, P. Net promoter score, growth, and profitability of transportation companies. Int. J. Manag. Econ. 2018, 54, 136–148. [Google Scholar] [CrossRef]
- Rocks, B. Interval Estimation for the “Net Promoter Score”. Am. Stat. 2016, 70, 365–372. [Google Scholar] [CrossRef]
- Baehre, S.; O’Dwyer, M.; O’Malley, L.; Lee, N. The use of Net Promoter Score (NPS) to predict sales growth: Insights from an empirical investigation. J. Acad. Mark. Sci. 2021. [Google Scholar] [CrossRef]
- Jahnert, J.R.; Schmeiser, H. The relationship between net promoter score and insurers’ profitability: An empirical analysis at the customer level. Geneva Pap. Risk Insur. Issues Pr. 2021, 1–29. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Chen, Y.-S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36, 4176–4184. [Google Scholar] [CrossRef]
- Anderson, K.M. A method for customer lifetime value ranking. Prev. Sch. Fail. 1986, 51, 49–51. Available online: https://search.proquest.com/docview/220297257?accountid=12834 (accessed on 16 June 2021).
- Liu, D.-R.; Shih, Y.-Y. Integrating AHP and data mining for product recommendation based on customer lifetime value. Inf. Manag. 2005, 42, 387–400. [Google Scholar] [CrossRef]
- Venkatesan, R.; Kumar, V. A Customer Lifetime Value Framework for Customer Selection and Resource Allocation Strategy. J. Mark. 2004, 68, 106–125. [Google Scholar] [CrossRef]
- Chan, C.C.H. Intelligent value-based customer segmentation method for campaign management: A case study of automobile retailer. Expert Syst. Appl. 2008, 34, 2754–2762. [Google Scholar] [CrossRef]
- Kumar, V.; Venkatesan, R.; Bohling, T.; Beckmann, D. Practice Prize Report—The Power of CLV: Managing Customer Lifetime Value at IBM. Mark. Sci. 2008, 27, 585–599. [Google Scholar] [CrossRef]
- Yeh, I.-C.; Yang, K.-J.; Ting, T.-M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. Using customer lifetime value and neural networks to improve the prediction of bank deposit subscription in telemarketing campaigns. Neural Comput. Appl. 2015, 26, 131–139. [Google Scholar] [CrossRef]
- Hamilton, M.; Kaltcheva, V.D.; Rohm, A.J. Social Media and Value Creation: The Role of Interaction Satisfaction and Interaction Immersion. J. Interact. Mark. 2016, 36, 121–133. [Google Scholar] [CrossRef]
- Monalisa, S.; Nadya, P.; Novita, R. Analysis for Customer Lifetime Value Categorization with RFM Model. Procedia Comput. Sci. 2019, 161, 834–840. [Google Scholar] [CrossRef]
- Martínez, R.G.; Carrasco, R.A.; Garcia-Madariaga, J.; Gallego, C.P.; Herrera-Viedma, E. A comparison between Fuzzy Linguistic RFM Model and traditional RFM model applied to Campaign Management. Case study of retail business. Procedia Comput. Sci. 2019, 162, 281–289. [Google Scholar] [CrossRef]
- Haggerty, C.M.; Damrauer, S.M.; Levin, M.G.; Birtwell, D.; Carey, D.J.; Golden, A.M.; Hartzel, D.N.; Hu, Y.; Judy, R.; Kelly, M.A.; et al. Genomics-First Evaluation of Heart Disease Associated with Titin-Truncating Variants. Circulation 2019, 140, 42–54. [Google Scholar] [CrossRef]
- Mahdiraji, H.A.; Zavadskas, E.K.; Kazeminia, A.; Kamardi, A.A. Marketing strategies evaluation based on big data analysis: A CLUSTERING-MCDM approach. Econ. Res. Ekon. Istraž. 2019, 32, 2882–2898. [Google Scholar] [CrossRef]
- Vilaginés, J.A. Predicting customer behavior with Activation Loyalty per Period. From RFM to RFMAP. ESIC Mark. Econ. Bus. J. 2020, 51, 609–637. [Google Scholar] [CrossRef]
- Heldt, R.; Silveira, C.S.; Luce, F.B. Predicting customer value per product: From RFM to RFM/P. J. Bus. Res. 2021, 127, 444–453. [Google Scholar] [CrossRef]
- Rahim, M.A.; Mushafiq, M.; Khan, S.; Arain, Z.A. RFM-based repurchase behavior for customer classification and segmentation. J. Retail. Consum. Serv. 2021, 61, 102566. [Google Scholar] [CrossRef]
- Zong, Y.; Xing, H. Customer stratification theory and value evaluation—Analysis based on improved RFM model. J. Intell. Fuzzy Syst. 2021, 40, 4155–4167. [Google Scholar] [CrossRef]
- Hsieh, N.-C. An integrated data mining and behavioral scoring model for analyzing bank customers. Expert Syst. Appl. 2004, 27, 623–633. [Google Scholar] [CrossRef]
- King, S.F. Citizens as customers: Exploring the future of CRM in UK local government. Gov. Inf. Q. 2007, 24, 47–63. [Google Scholar] [CrossRef]
- Lumsden, S.-A.; Beldona, S.; Morrison, A.M. Customer Value in an All-Inclusive Travel Vacation Club: An Application of the RFM Framework. J. Hosp. Leis. Mark. 2008, 16, 270–285. [Google Scholar] [CrossRef]
- Li, Y.-M.; Lin, C.-H.; Lai, C.-Y. Identifying influential reviewers for word-of-mouth marketing. Electron. Commer. Res. Appl. 2010, 9, 294–304. [Google Scholar] [CrossRef]
- Van Vlasselaer, V.; Bravo, C.; Caelen, O.; Eliassi-Rad, T.; Akoglu, L.; Snoeck, M.; Baesens, B. APATE: A novel approach for automated credit card transaction fraud detection using network-based extensions. Decis. Support Syst. 2015, 75, 38–48. [Google Scholar] [CrossRef]
- Mohammadzadeh, M.; Hoseini, Z.Z.; Derafshi, H. A data mining approach for modeling churn behavior via RFM model in specialized clinics Case study: A public sector hospital in Tehran. Procedia Comput. Sci. 2017, 120, 23–30. [Google Scholar] [CrossRef]
- Perisic, A.; Pahor, M. Extended RFM logit model for churn prediction in the mobile gaming market. Croat. Oper. Res. Rev. 2020, 11, 249–261. [Google Scholar] [CrossRef]
- Stormi, K.; Lindholm, A.; Laine, T.; Korhonen, T. RFM customer analysis for product-oriented services and service business development: An interventionist case study of two machinery manufacturers. J. Manag. Gov. 2019, 24, 623–653. [Google Scholar] [CrossRef]
- Hwang, S.; Lee, Y. Identifying customer priority for new products in target marketing: Using RFM model and TextRank. Innov. Mark. 2021, 17, 125–136. [Google Scholar] [CrossRef]
- Wu, J.; Shi, L.; Lin, W.-P.; Tsai, S.-B.; Li, Y.; Yang, L.; Xu, G. An Empirical Study on Customer Segmentation by Purchase Behaviors Using a RFM Model and K-Means Algorithm. Math. Probl. Eng. 2020, 2020, 1–7. [Google Scholar] [CrossRef]
- McCarty, J.A.; Hastak, M. Segmentation approaches in data-mining: A comparison of RFM, CHAID, and logistic regression. J. Bus. Res. 2007, 60, 656–662. [Google Scholar] [CrossRef]
- Herrera, F.; Martinez, L. A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 2000, 8, 746–752. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process: Planning, Priority Setting, Resource Allocation; McGraw-Hill International Book Co: New York, NY, USA, 1980; 287p, Available online: https://ucm.on.worldcat.org/oclc/911278091 (accessed on 15 January 2021).
- Saaty, T.L. The Modern Science of Multicriteria Decision Making and Its Practical Applications: The AHP/ANP Approach. Oper. Res. 2013, 61, 1101–1118. [Google Scholar] [CrossRef]
- Khaira, A.; Dwivedi, R.K. A State of the Art Review of Analytical Hierarchy Process. Mater. Today Proc. 2018, 5, 4029–4035. [Google Scholar] [CrossRef]
- Ishizaka, A.; Labib, A. Review of the main developments in the analytic hierarchy process. Expert Syst. Appl. 2011, 38, 14336–14345. [Google Scholar] [CrossRef]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, F.; García-Madariaga, J.; Pedreño-Santos, A.; Herrera-Viedma, E. A Model to Obtain a Servperf Scale Evaluation of the Crm Customer Complaints: An Application to the 4g Telecommunications Sector. Technol. Econ. Dev. Econ. 2018, 24, 1606–1629. [Google Scholar] [CrossRef]
- Kotler, P. Marketing Management; Pearson Education Limited: Harlow, UK, 2016; Available online: https://www.pearson.com/uk/educators/higher-education-educators/program/Kotler-Marketing-Management-3rd-edn-3rd-Edition/PGM1093412.html (accessed on 20 July 2021).
- Kumar, V.; Reinartz, W. Strategic Customer Relationship Management Today. In Customer Relationship Management; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–20. [Google Scholar] [CrossRef]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Lu, W. Improved K-Means Clustering Algorithm for Big Data Mining under Hadoop Parallel Framework. J. Grid Comput. 2019, 18, 239–250. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Forero, L.N.; López, S.X.; Herrera-Viedma, E.; Porcel, C. Using the AHP model to improve the measurement of satisfaction in the ICT sector. Front. Artif. Intell. Appl. 2018, 303, 299–311. [Google Scholar] [CrossRef]
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef]
- Andrade, R.; Moazeni, S.; Ramirez-Marquez, J.E. A systems perspective on contact centers and customer service reliability modeling. Syst. Eng. 2019, 23, 221–236. [Google Scholar] [CrossRef]
- Zeithaml, V.A.; Berry, L.L.; Parasuraman, A. The Behavioral Consequences of Service Quality. J. Mark. 1996, 60, 31. [Google Scholar] [CrossRef]
- Parasuraman, A.; Zeithaml, V.A.; Berry, L.L. SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality. J. Retail. 1988, 64, 12–40. [Google Scholar]
- Hilken, T.; Heller, J.; Chylinski, M.; Keeling, D.I.; Mahr, D.; De Ruyter, K. Making omnichannel an augmented reality: The current and future state of the art. J. Res. Interact. Mark. 2018, 12, 509–523. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, F.; Herrera-Viedma, E. A 2-tuple Fuzzy Linguistic RFM Model and Its Implementation. Procedia Comput. Sci. 2015, 55, 1340–1347. [Google Scholar] [CrossRef]
- Kumar, V.; Aksoy, L.; Donkers, B.; Venkatesan, R.; Wiesel, T.; Tillmanns, S. Undervalued or Overvalued Customers: Capturing Total Customer Engagement Value. J. Serv. Res. 2010, 13, 297–310. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).