
Two Approaches for a Dividend Maximization Problem under an Ornstein-Uhlenbeck Interest Rate


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Dividend Maximization with a Deterministic Time Horizon
2.1. HJB Approach
2.1.1. Payout on the Maximal Rate
2.1.2. Derivation of the Value Function
2.1.3. Properties of the Function M
- , .
- is decreasing in t.
- If , then because it holds that for all .
- Since , the function α is strictly increasing in t with .
2.1.4. Properties of the Function G
2.2. BSDE Approach
3. Dividend Maximization with an Exogenous Stochastic Time Horizon
3.1. HJB Approach
3.1.1. Properties of
3.1.2. The Case
3.2. BSDE Approach
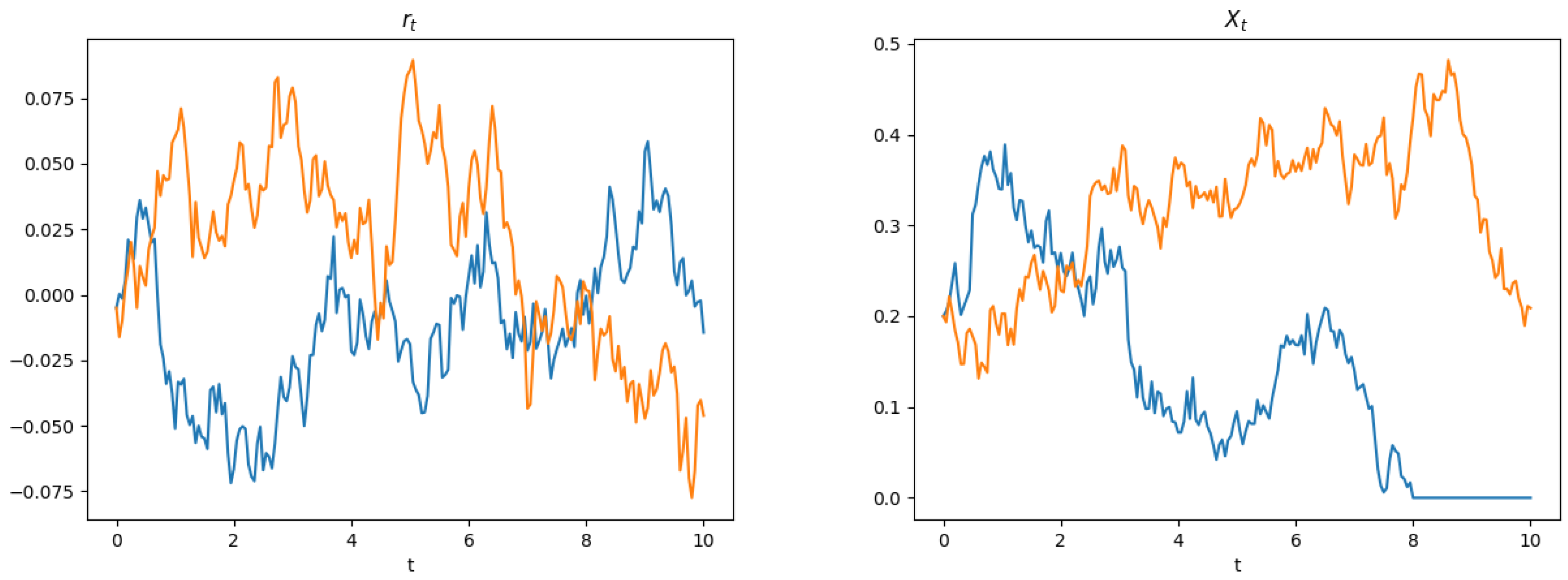
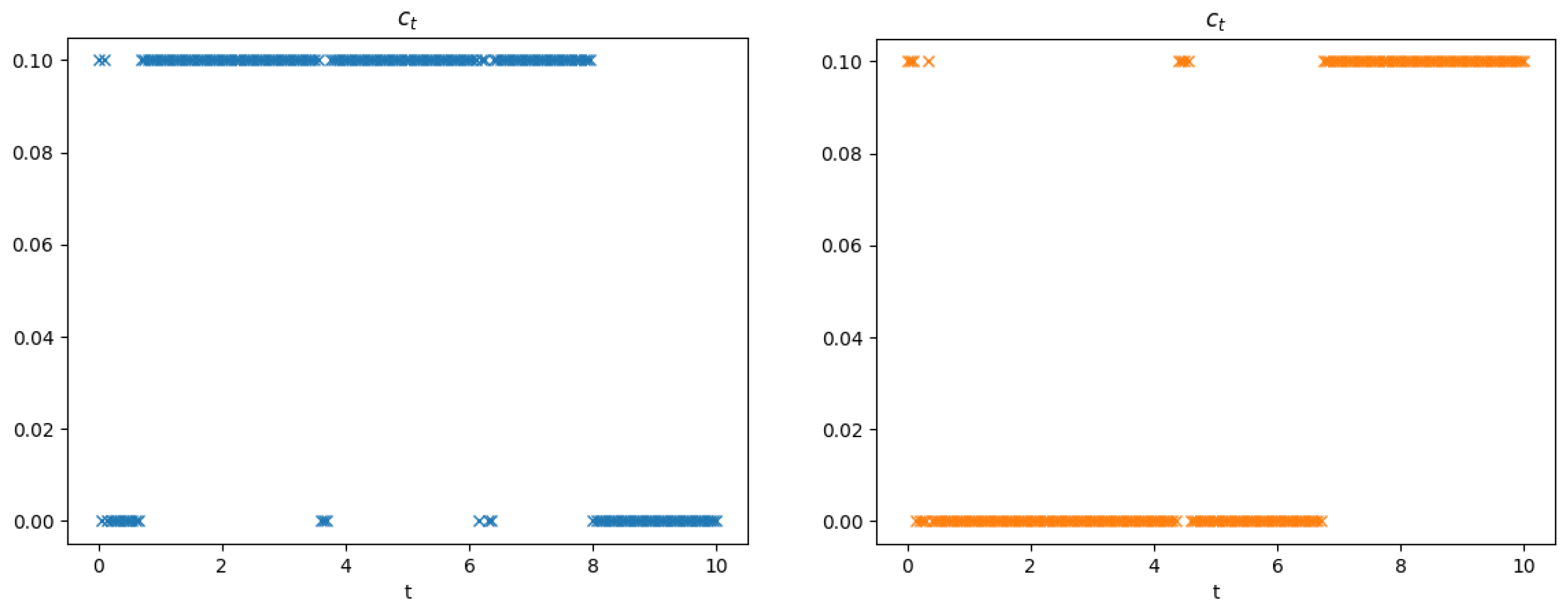
Evaluating the Strategy for the Stopping Times
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- De Finetti, B. Su un’impostazione alternativa della teoria collettiva del rischio. Trans. XVth Int. Congr. Actuar. 1957, 2, 433–443. [Google Scholar]
- Asmussen, S.; Taksar, M. Controlled diffusion models for optimal dividend pay-out. Insur. Math. Econ. 1997, 20, 1–15. [Google Scholar] [CrossRef]
- Azcue, P.; Muler, N. Optimal reinsurance and dividend distribution policies in the Cramér-Lundberg model. Math. Financ. Int. J. Math. Stat. Financ. Econ. 2005, 15, 261–308. [Google Scholar] [CrossRef]
- Strini, J.A.; Thonhauser, S. On a dividend problem with random funding. Eur. Actuar. J. 2019, 9, 607–633. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Siu, T.K.; Yang, H. Singular dividend optimization for a linear diffusion model with time-inconsistent preferences. Eur. J. Oper. Res. 2020, 285, 66–80. [Google Scholar] [CrossRef]
- Albrecher, H.; Thonhauser, S. Optimality results for dividend problems in insurance. RACSAM-Rev. Real Acad. Cienc. Exactas Fis. Nat. Ser. A Mat. 2009, 103, 295–320. [Google Scholar] [CrossRef] [Green Version]
- Avanzi, B. Strategies for dividend distribution: A review. N. Am. Actuar. J. 2009, 13, 217–251. [Google Scholar] [CrossRef]
- Schmidli, H. Stochastic Control in Insurance; Springer: London, UK, 2008. [Google Scholar]
- Jiang, Z.; Pistorius, M. Optimal dividend distribution under markov regime switching. Financ. Stoch. 2012, 16, 449–476. [Google Scholar] [CrossRef] [Green Version]
- Akyildirim, E.; Güney, I.E.; Rochet, J.C.; Soner, H.M. Optimal dividend policy with random interest rates. J. Math. Econ. 2014, 51, 93–101. [Google Scholar] [CrossRef]
- Bandini, E.; de Angelis, T.; Ferrari, G.; Gozzi, F. Optimal dividend payout under stochastic discounting. arXiv 2021, arXiv:2005.11538. [Google Scholar]
- Stübinger, J.; Endres, S. Pairs trading with a mean-reverting jump-diffusion model on high-frequency data. Quant. Financ. 2018, 18, 1735–1751. [Google Scholar] [CrossRef] [Green Version]
- Yatabe, Z.; Asubar, J.T. Ornstein–Uhlenbeck process in a human body weight fluctuation. Phys. A Stat. Mech. Appl. 2021, 582, 126286. [Google Scholar] [CrossRef]
- Blomberg, S.P.; Rathnayake, S.I.; Moreau, C.M. Beyond Brownian motion and the Ornstein-Uhlenbeck process: Stochastic diffusion models for the evolution of quantitative characters. Am. Nat. 2020, 195, 145–165. [Google Scholar] [CrossRef] [PubMed]
- Eisenberg, J. Optimal dividends under a stochastic interest rate. Insur. Math. Econ. 2015, 65, 259–266. [Google Scholar] [CrossRef]
- Bismut, J.-M. An introductory approach to duality in optimal stochastic control. SIAM Rev. 1978, 20, 62–78. [Google Scholar] [CrossRef]
- Pardoux, E.; Peng, S. Adapted solution of a backward stochastic differential equation. Syst. Control Lett. 1990, 14, 55–61. [Google Scholar] [CrossRef]
- El Karoui, N.; Peng, S.; Quenez, M.C. Backward stochastic differential equations in finance. Math. Financ. 1997, 7, 1–71. [Google Scholar] [CrossRef]
- Ma, J.; Morel, J.; Yong, J. Forward-Backward Stochastic Differential Equations and Their Applications; Number 1702 in Lecture Notes in Mathematics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Kohlmann, M.; Zhou, X.Y. Relationship between backward stochastic differential equations and stochastic controls: A linear-quadratic approach. SIAM J. Control Optim. 2000, 38, 1392–1407. [Google Scholar] [CrossRef]
- Pham, H. Continuous-Time Stochastic Control and Optimization with Financial Applications; Series SMAP; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kremsner, S.; Steinicke, A.; Szölgyenyi, M. A deep neural network algorithm for semilinear elliptic PDEs with applications in insurance mathematics. Risks 2020, 8, 136. [Google Scholar] [CrossRef]
- Han, J.; Jentzen, A.; Weinan, E. Solving high-dimensional partial differential equations using deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, 8505–8510. [Google Scholar] [CrossRef] [Green Version]
- Chessari, J.; Kawai, R. Numerical methods for backward stochastic differential equations: A survey. arXiv 2021, arXiv:2101.08936. [Google Scholar]
- Damiano Brigo and Fabio Mercurio. Interest Rate Models-Theory and Practice: With Smile, Inflation and Credit; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Borodin, A.N.; Salminen, P. Handbook of Brownian Motion-Facts and Formulae; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Carmona, R. Lectures on BSDEs, Stochastic Control, and Stochastic Differential Games with Financial Applications; SIAM: Philadelphia, PA, USA, 2016. [Google Scholar]
- Touzi, N. Optimal Stochastic Control, Stochastic Target Problems, and Backward SDE; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 29. [Google Scholar]
- Pardoux, É. Backward stochastic differential equations and viscosity solutions of systems of semilinear parabolic and elliptic PDEs of second order. In Stochastic Analysis and Related Topics VI; Springer: Berlin/Heidelberg, Germany, 1998; pp. 79–127. [Google Scholar]
- Pardoux, É. BSDEs, weak convergence and homogenization of semilinear PDEs. In Nonlinear Analysis, Differential Equations and Control; Springer: Berlin/Heidelberg, Germany, 1999; pp. 503–549. [Google Scholar]
- Briand, P.; Delyon, B.; Hu, Y.; Pardoux, E.; Stoica, L. Lp solutions of backward stochastic differential equations. Stoch. Process. Appl. 2003, 108, 109–129. [Google Scholar] [CrossRef] [Green Version]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eisenberg, J.; Kremsner, S.; Steinicke, A. Two Approaches for a Dividend Maximization Problem under an Ornstein-Uhlenbeck Interest Rate. Mathematics 2021, 9, 2257. https://doi.org/10.3390/math9182257
Eisenberg J, Kremsner S, Steinicke A. Two Approaches for a Dividend Maximization Problem under an Ornstein-Uhlenbeck Interest Rate. Mathematics. 2021; 9(18):2257. https://doi.org/10.3390/math9182257
Chicago/Turabian StyleEisenberg, Julia, Stefan Kremsner, and Alexander Steinicke. 2021. "Two Approaches for a Dividend Maximization Problem under an Ornstein-Uhlenbeck Interest Rate" Mathematics 9, no. 18: 2257. https://doi.org/10.3390/math9182257
APA StyleEisenberg, J., Kremsner, S., & Steinicke, A. (2021). Two Approaches for a Dividend Maximization Problem under an Ornstein-Uhlenbeck Interest Rate. Mathematics, 9(18), 2257. https://doi.org/10.3390/math9182257