1. Introduction
Today, wireless sensor networks (WSNs) have been transformed into an attractive research field for many researchers in industry and academia. These networks include a large number of sensor nodes, which are randomly or deterministically deployed in the network environment without any infrastructure [
1,
2]. Sensor nodes have been tasked to monitor the Region of Interest (RoI).
WSNs are applied in many applications, such as industry [
3], agriculture [
3], military [
4], medicine [
3,
5], and Internet of Things (IoT) [
4]. Today, micro-electro-mechanical systems have grown dramatically. As a result, many low-cost and robust sensor nodes have been produced [
6]. Each sensor node is a multi-functional device including a sensing unit, processing unit, memory unit, communication unit, energy unit, and so on [
7,
8]. They can sense a target or phenomenon that occurs in their sensing range, they then process the data received from the environment, and finally forward their data packets to the base station (BS) in a single-hop or multi-hop manner [
9,
10].
Sensor nodes have small sensing and communication ranges. Furthermore, they have limited energy resources [
11,
12]. In WSNs, quality of service (QoS) and resource management are two critical issues that must be addressed. QoS is measured based on connectivity and coverage [
13,
14]. Thus, appropriate coverage and maintenance of connectivity play a important role in the network performance.
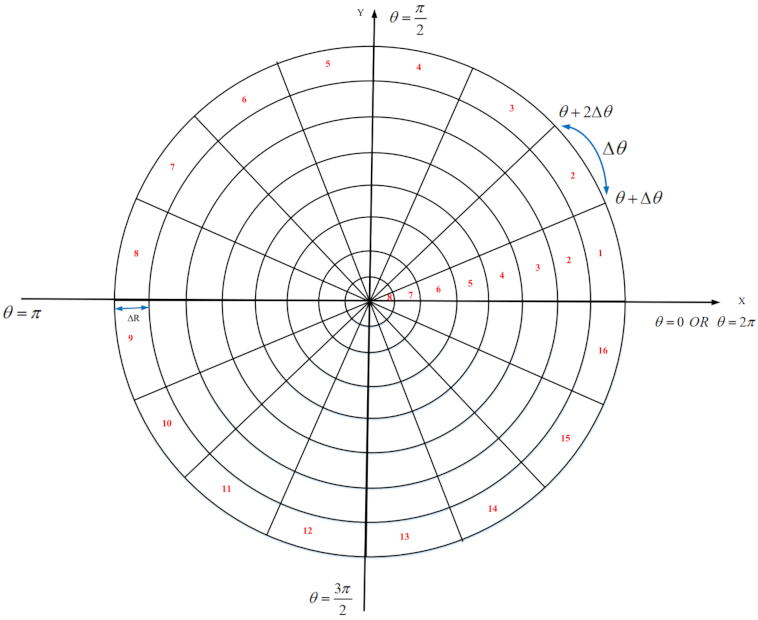
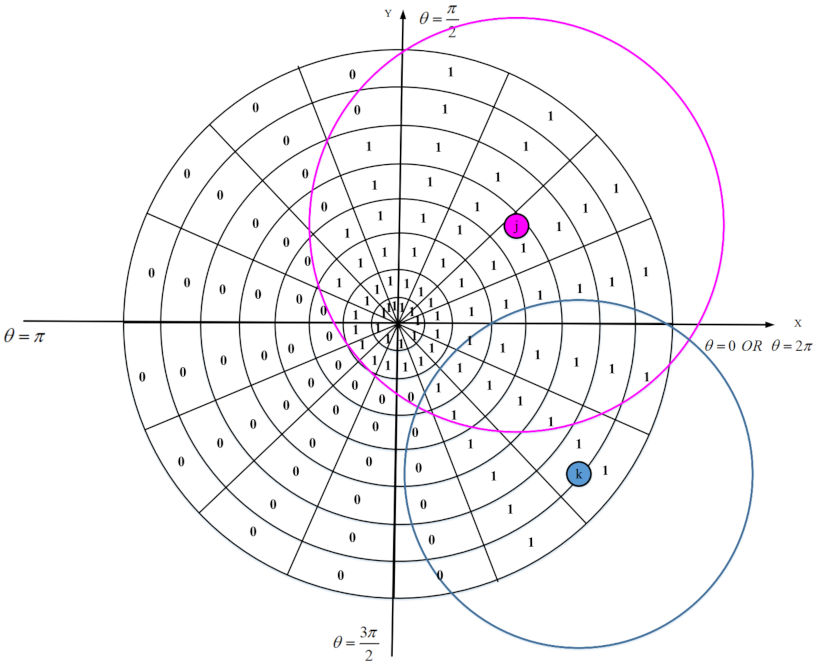
Coverage is defined as the area/point covered or monitored by the sensor nodes deployed in the network area. If an area/point is inside the sensing range of at least one active sensor node; then, it can be said that this area/point have been covered or monitored [
15,
16]. In general, coverage is classified into several groups according to what exactly is monitored:
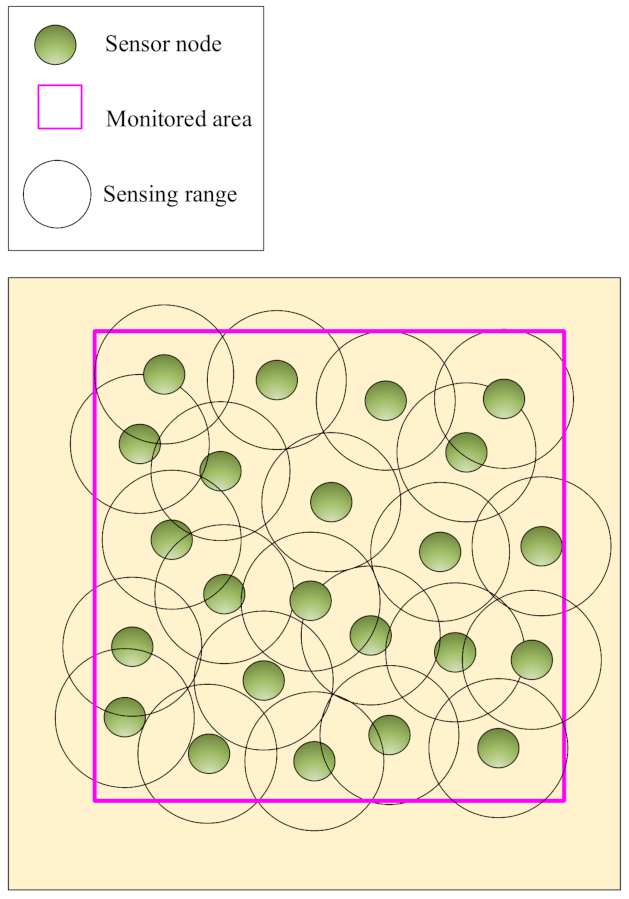
Area coverage: In this coverage, the main goal is to cover or monitor the RoI so that any point in this area should be covered [
17,
18]. See this coverage type in
Figure 1. Area coverage is divided into two categories based on the desired application, including partial and full coverage:
Partial coverage
In this coverage, the area is partially covered to guarantee the efficient and acceptable coverage degree according to the desired application. In partial coverage, the goal is to cover the
P percentage of the area. This coverage type is also called
P-coverage. Partial coverage can save energy of sensor nodes and increase network lifetime. Moreover, it requires a less number of sensor nodes compared to the full coverage [
18]. For example, it is sufficient to achieve 80% area coverage in applications, such as environment monitoring, calculating the environment temperature, and forest fire detection during rainy seasons.
Full coverage
When it is necessary to cover the entire area, the full coverage is applied. In the full coverage, any point of RoI should be monitored by at least one sensor node. Full area coverage is very costly because it requires a large number of sensor nodes [
19]. In addition, the coverage degree is defined based on the application requirements. In some applications, simple coverage is required, i.e., one sensor node is sufficient to cover each point of RoI. However, in other applications, at least
k sensor nodes (
) must cover any point of RoI. In this case, the network is fault-tolerant, and, if a sensor node dies, then the network will continue its normal performance with the
sensor nodes; however, this is impossible in simple coverage.
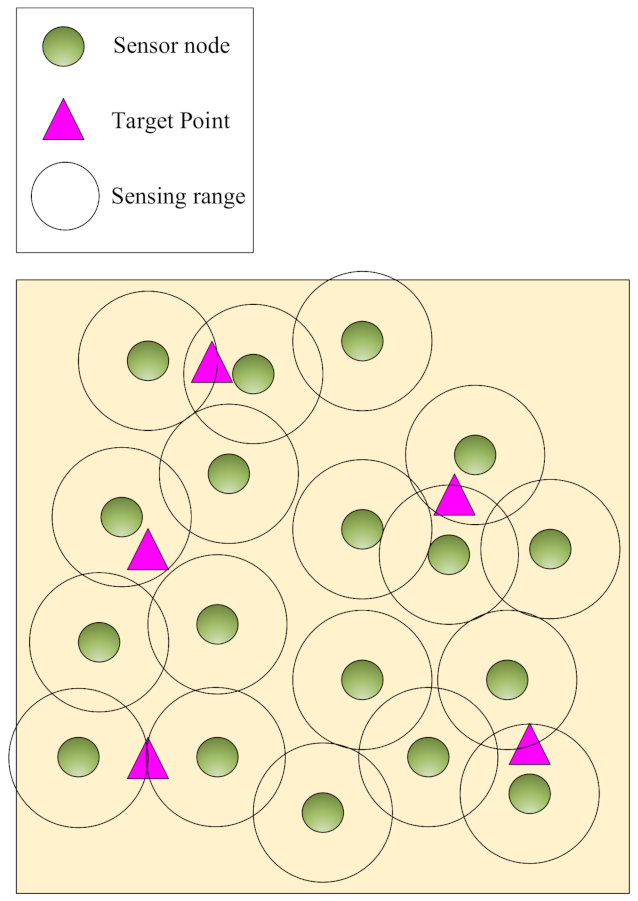
Point coverage: In this coverage, it is sufficient to monitor some points of RoI depending on the application. It has a low-cost network deployment because fewer sensor nodes are used to cover the target points [
20,
21].
Figure 2 shows the point coverage.
Barrier coverage: In this coverage, the purpose is to create a barrier using sensor nodes deployed in the network. When sensor nodes sense some subversive activities of attackers at this barrier, they transmit their sensed data to the base station. Barrier coverage is applied in some applications, such as creating infrastructure margins or monitoring important areas, such as country borders, coastlines, battlefield boundaries, and so on [
18]. This coverage is shown in
Figure 3.
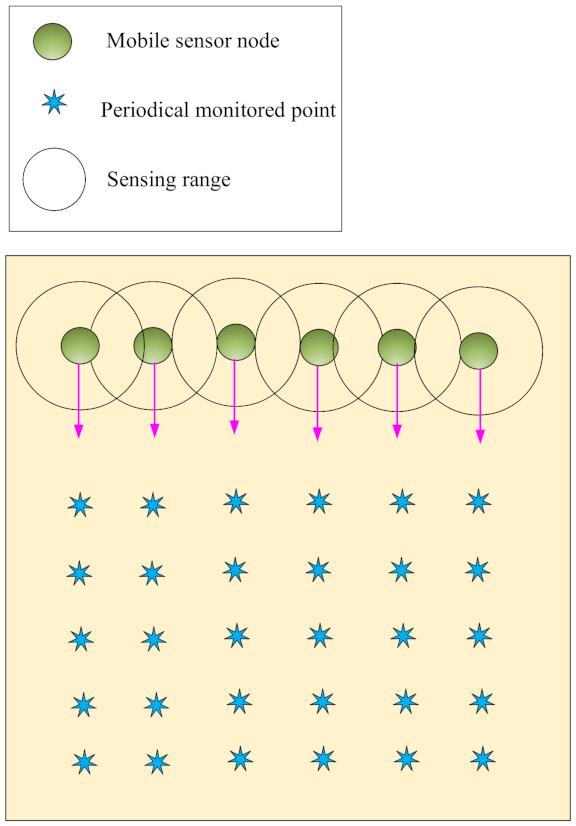
Sweep coverage: In this coverage, some points of RoI must be monitored periodically, i.e., target points are covered at a certain time interval. Therefore, it is better to cover the target points using a minimum number of mobile sensor nodes [
19,
22]. Sweep coverage should not be done using static sensor nodes because they have weak performance and additional overhead. This coverage is illustrated in
Figure 4.
On the other hand, coverage methods are classified into two categories: centralized coverage schemes and distributed (decentralized) coverage schemes. In centralized coverage methods, only the base station is tasked to manage the coverage process in the network. Whereas, in distributed coverage methods, sensor nodes also participate in this process. In large-scale WSNs, distributed coverage schemes are more efficient because they do not require global information of all sensor nodes in the network, and each sensor node manages the coverage process based on local information received from its neighboring nodes. Coverage methods can be categorized into static and dynamic classes.
In static coverage schemes, the best replacement strategy of sensor nodes is first determined in the network so that proper coverage rate is ensured. Then, this strategy is fixed throughout the network lifetime. However, in dynamic coverage methods, this strategy is always not fixed and updated periodically or when an event occurs [
23]. Dynamic coverage methods are more suitable for WSNs due to their limited resources, failure of sensor nodes, and establishing holes.
In most engineering and science problems, it is important to find the maximum or minimum value of a function with different variables. In some cases, there are algorithms based on applied analysis, such as linear programming, that can be used to find the global optimum solution. However, in hybrid or discrete optimization problems, there is no efficient algorithm to find the optimum solution. In the real world, optimization problems are very complex, high dimensions, and highly dynamic.
As a result, it is necessary to use heuristic or metaheuristic methods as algorithms, such as dynamic programming or divide and conquer, have a lot of computational overhead. Today, the metaheuristic algorithms are dramatically becoming popular because they can find acceptable solutions for NP-Hard and nonlinear optimization problems. Metaheuristic algorithms provide a general framework for solving complex optimization problems [
24].
These methods are generally inspired by a natural phenomenon. Today, many biological algorithms have been invented or improved. They have successfully been used to solve hybrid and numerical optimization problems—for example, ant colony optimization (ACO) [
25], particle swarm optimization (PSO) [
26], artificial bee colony (ABC) algorithm [
27], shuffled frog-leaping algorithm (SFLA) [
28], and artificial immune system (AIS) [
29].
Many studies have been presented to solve the coverage problem in WSNs. Coverage techniques focus on several issues: designing a replacement strategy for sensor nodes in the network environment, designing a scheduling mechanism for sensor nodes, and selecting a subset of nodes for full coverage. We review a number of papers related to the research subject in
Section 2 and express their strengths and weaknesses.
Most of these methods do not consider the energy of the sensor nodes in the network. They have a lot of communication overhead, which threatens the network lifetime. Moreover, they are often centralized and static schemes and propose no useful strategy for reconstructing holes created in the network. These problems reduce their scalability and network lifetime. Therefore, it is necessary to design an efficient area coverage method, which schedules the activity of sensor nodes in the network intelligently.
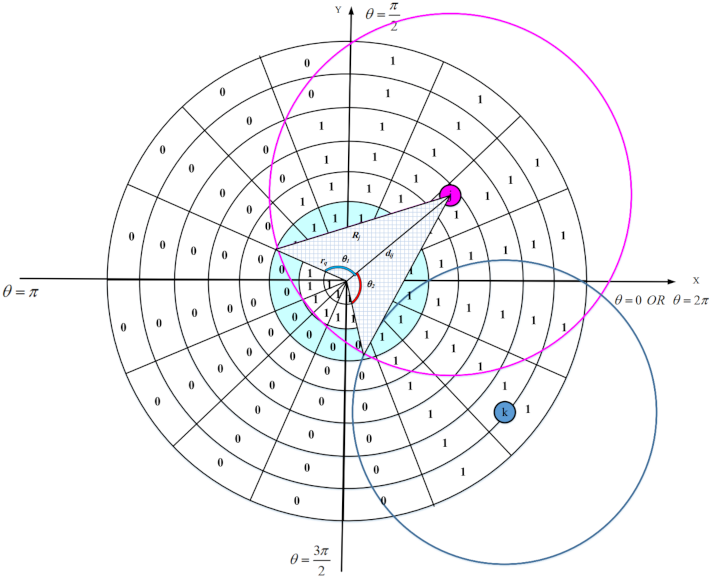
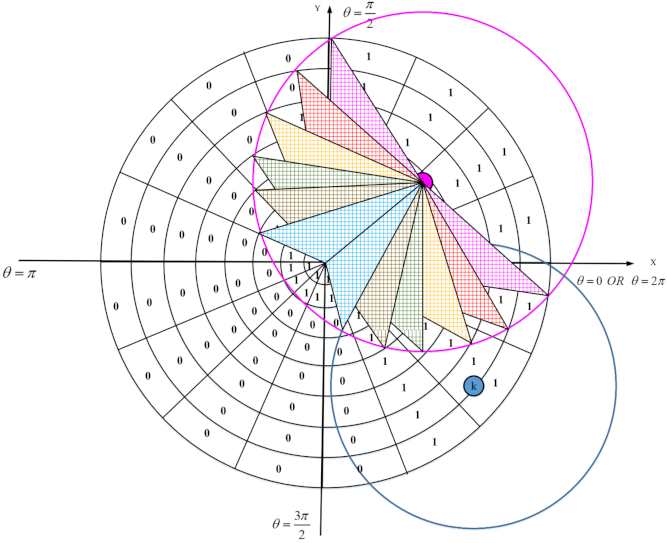
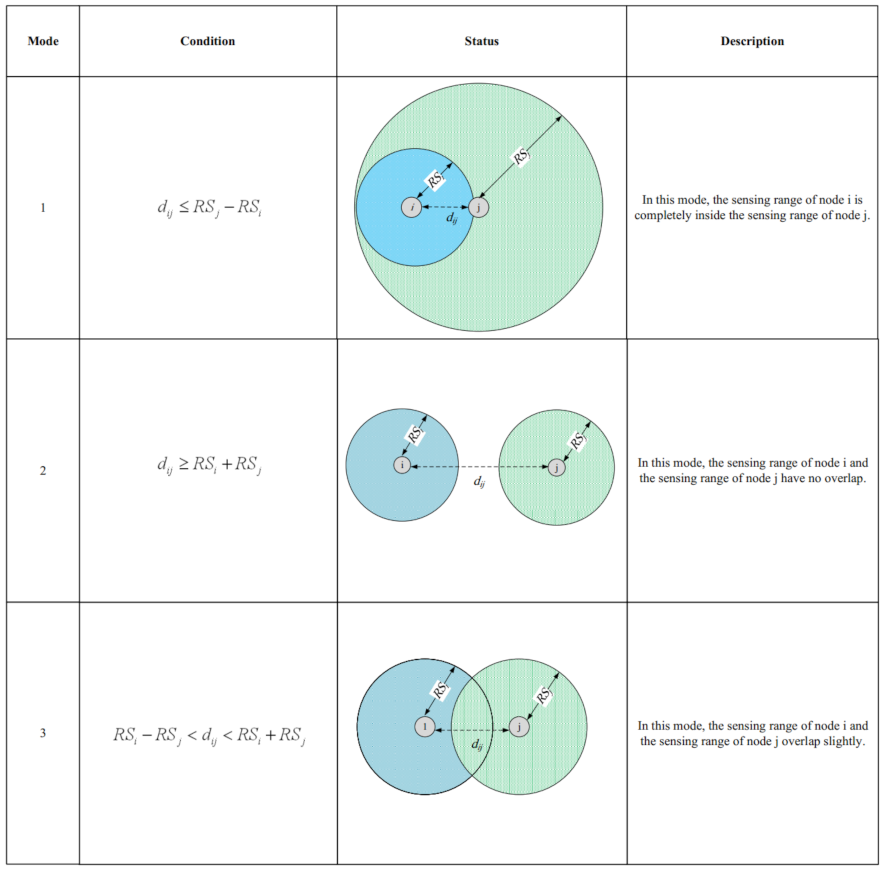
We design an appropriate strategy for reconstructing holes in the network. Furthermore, it is important and critical to calculate the overlap of nodes to select the lowest number of active sensor nodes in the network. However, calculating the overlap between the sensing ranges of sensor nodes is a complicated, time-consuming, and difficult task due to limited resources and low energy of sensor nodes.
In this paper, we present a simple, efficient, and distributed method to calculate the overlap between sensor nodes. The purpose of this paper is to present a suitable area coverage scheme for heterogeneous WSNs, and thus this method can balance the energy consumption of sensor nodes in the network and improve network lifetime. We attempt to increase the coverage quality in the network. The main contributions of the paper are expressed as follows:
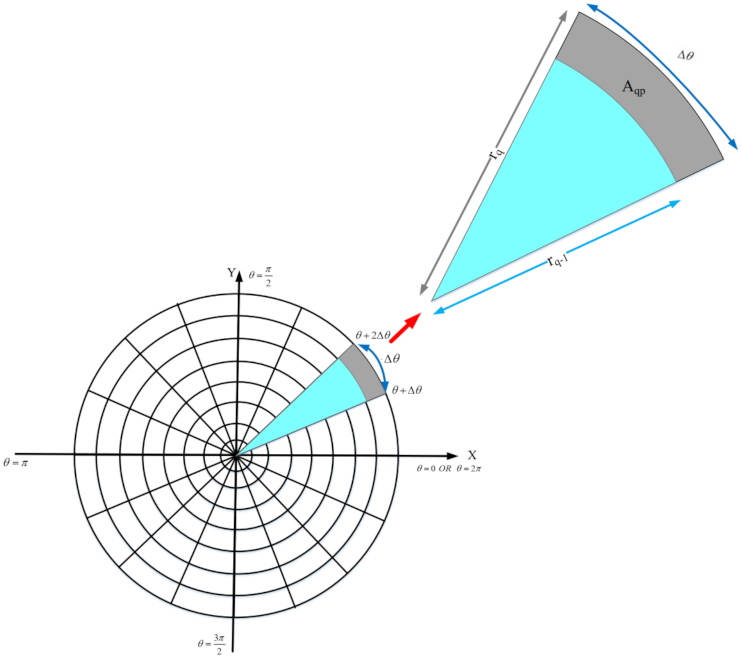
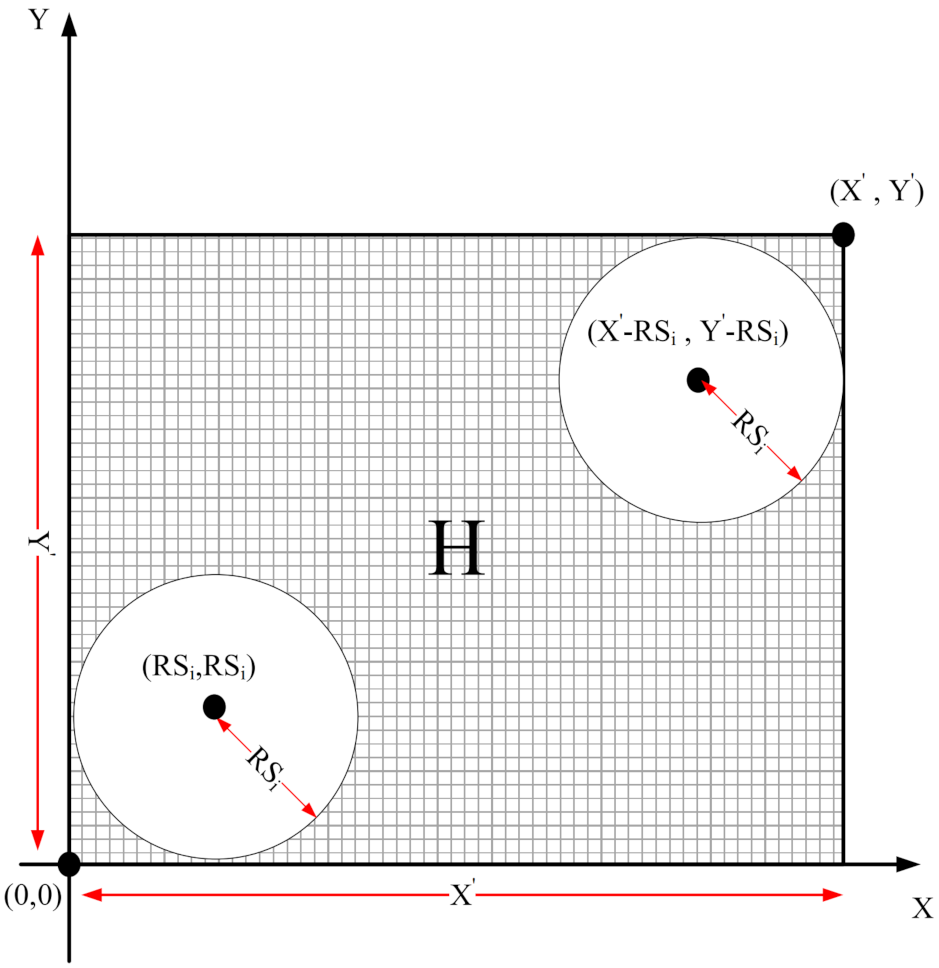
In the first phase, each sensor node estimates the overlap between its sensing range and sensing ranges of neighboring nodes using a distributed method based on geometric mathematics. Calculating the overlap between the sensing range of a sensor node and its neighboring nodes is a complex operation with a lot of computational overhead and high time complexity. In the proposed method, we attempt to reduce computational overhead and introduce a new, efficient and distributed method based on a digital matrix to calculate the overlap.
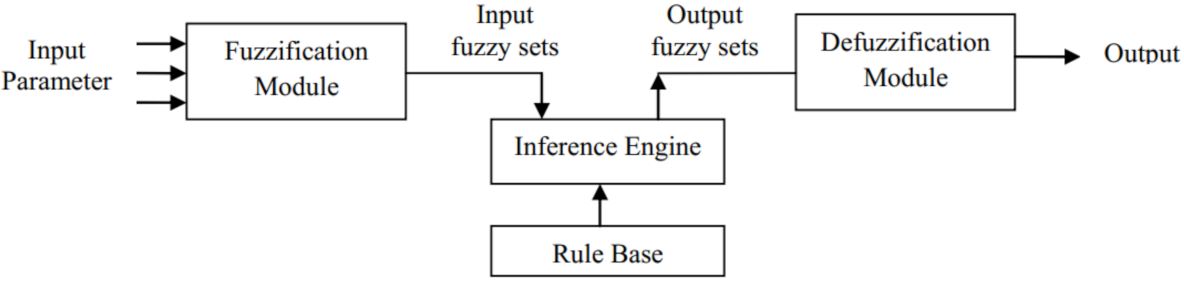
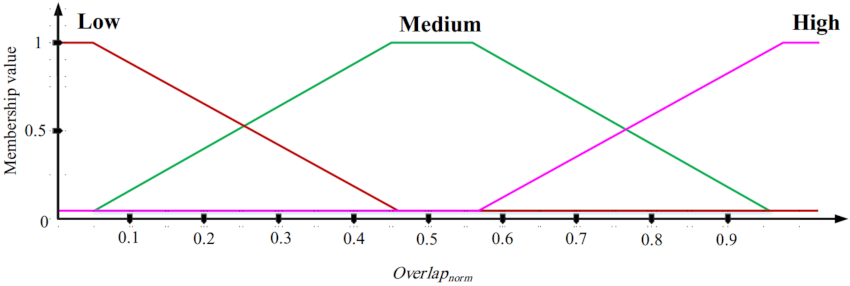
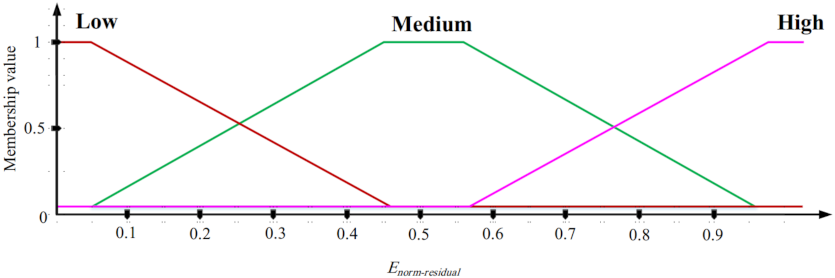
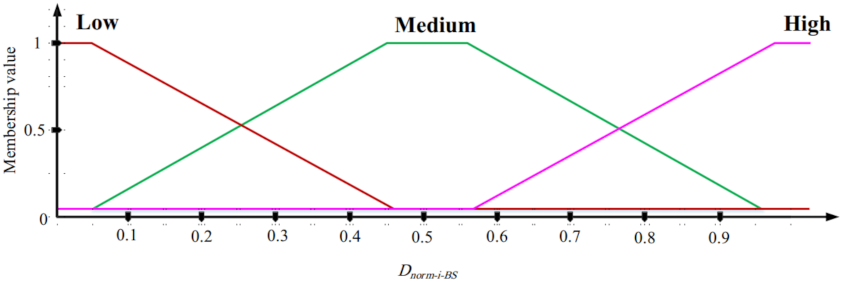
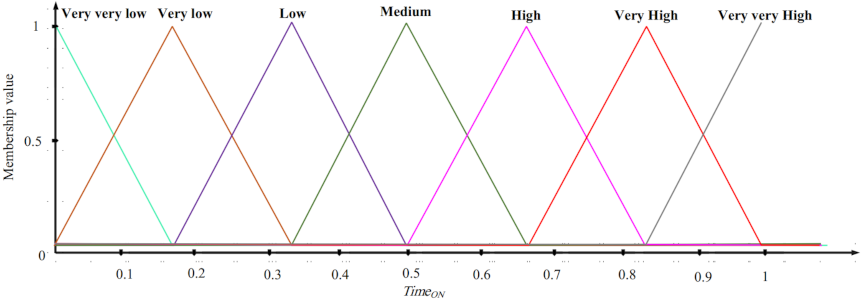
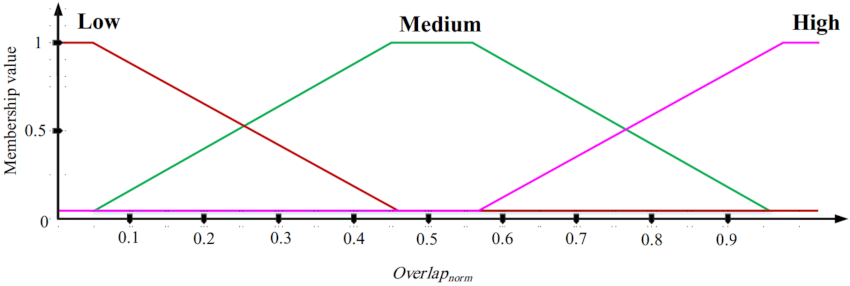
In the second phase, the goal is to design an ON/OFF scheduling mechanism based on fuzzy logic. This fuzzy system has three inputs: the overlap between sensing range of a sensor node and sensing ranges of its neighboring nodes, the residual energy, and the distance between a sensor node and BS. The fuzzy system output is the activity time of each sensor node (ON time). In this fuzzy system, if the overlap between the sensing range of a sensor node and sensing ranges of neighboring nodes is low and its energy level is high and the distance between this node and BS is low, then this node stays at the ON state for more time slots.
In the third phase, we attempt to present a suitable method that predicts the death time of sensor nodes and prevents possible holes in the network, and thus there is no interruption in the data transmission process to the base station.
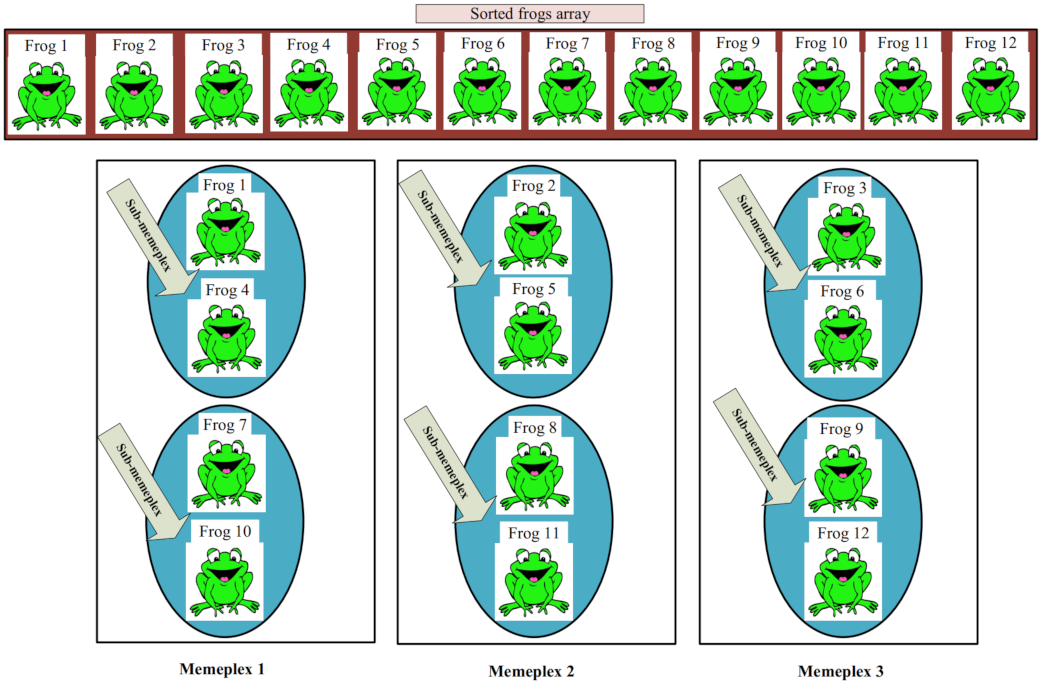
In the fourth phase, the goal is to find the best replacement strategy for mobile nodes to maximize the coverage rate and minimize the number of mobile nodes applied for covering holes. For this purpose, we use the shuffled frog-leaping algorithm (SFLA) and present a suitable and multi-objective fitness function.
The rest of paper is organized as follows: In
Section 2, some recent studies are reviewed in the coverage field for WSNs. In
Section 3, the basic concepts used in the proposed scheme, namely the fuzzy logic and the shuffled frog-leaping algorithm (SFLA), are described briefly. In
Section 4, we present the system model in the proposed method. This model includes the network model, energy model, sensing model, and communication model. In
Section 5, we define the problem studied in this paper. In
Section 6, the proposed scheme is described in detail. In
Section 7, the simulation results of the proposed scheme are presented and compared with some coverage methods. Finally, our conclusions are presented in
Section 8.
2. Related Works
Coverage is one of the most important and fundamental issues in WSNs, because it has a direct effect on the energy consumption of sensor nodes and network lifetime. Generally, coverage is defined as monitoring on the network environment effectively and efficiently. Today, many papers have been published in the coverage field in WSNs. These papers often focus on three concepts: deploying sensor nodes in a predetermined manner, designing a scheduling mechanism, and selecting a subset of sensor nodes for ensuring full coverage. In the following, we briefly introduce some coverage methods.
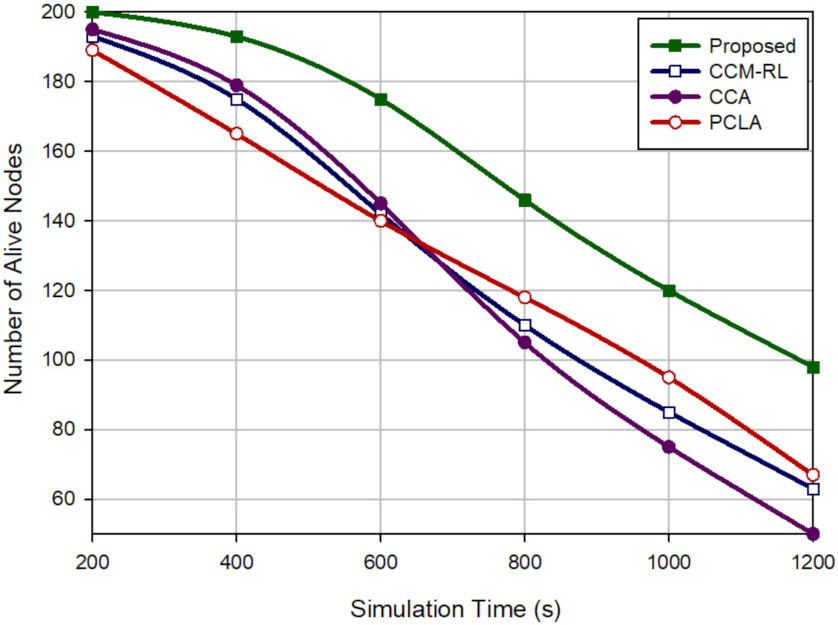
Sharma et al. [
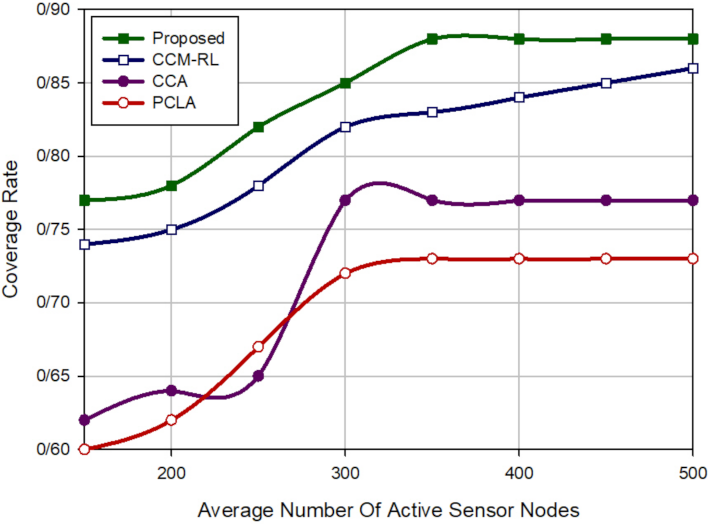
30] suggested the coverage connectivity maintenance based on reinforcement learning (CCM-RL) protocol in wireless sensor networks. The purpose of this method is to achieve the maximum coverage rate, maintain connectivity, and save energy efficiently. In this scheme, the learning algorithm is implemented in each sensor node. This algorithm allows them to automatically learn their optimal activity. The purpose of this algorithm is that only subsets of sensor nodes are activated in each scheduling round to minimize energy consumption, maximize the coverage rate, and maintain network connectivity.
In addition, CCM-RL presents a sensing range customization mechanism for removing coverage redundancy. After executing the learning algorithm, active sensor nodes, which overlap with each other, should customize their sensing range using this mechanism to maintain network resources, such as energy and memory, reduce duplicated data packets, and lower network congestion. CCM-RL is a dynamic and distributed coverage method, that is, the sensor nodes participate in the scheduling process.
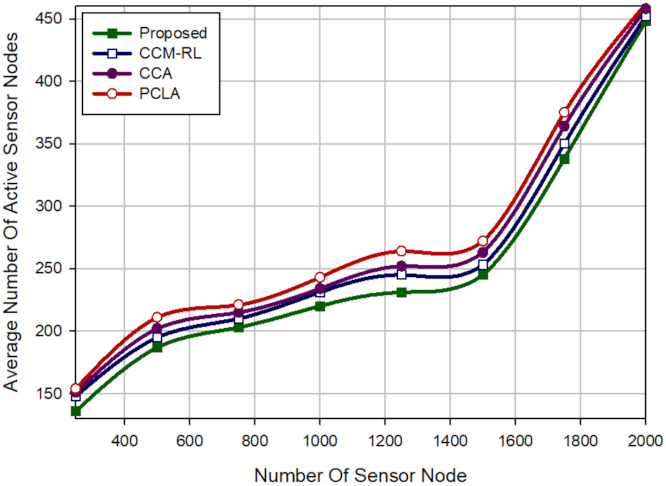
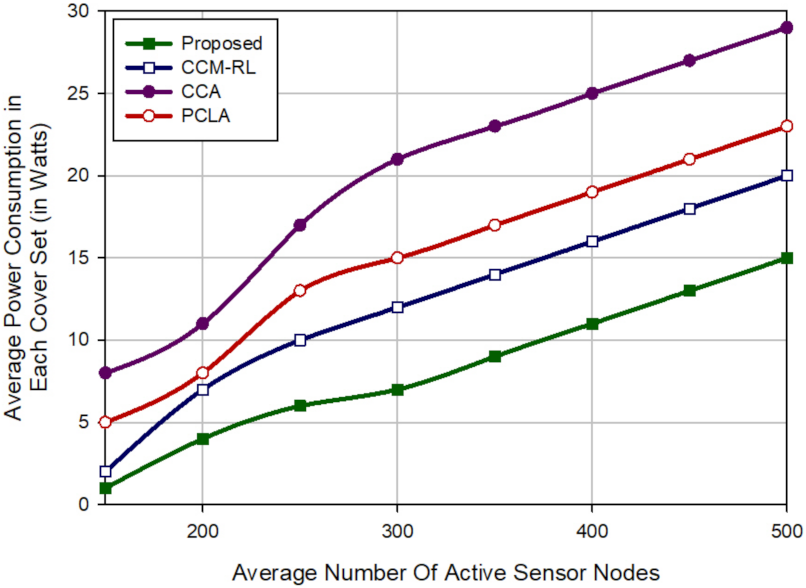
As a result, CCM-RL is a scalable scheme. However, CCM-RL schedules sensor nodes based on only two parameters, including distance and coverage rate. It ignores energy parameters in this process. Furthermore, CCM-RL may have a lot of delay. This method does not provide any mechanism for detecting or reconstructing coverage holes in the network.
Yu et al. [
31] presented two centralized and distributed protocols based on the coverage contribution area (CCA) concept to solve the
K-coverage problem in homogeneous wireless sensor networks. The purpose of this method is to achieve
K-coverage with a minimum number of sensor nodes and improve network lifetime. CCA presents a scheduling process to activate a subset of sensor nodes for covering the RoI. This process is based on two criteria, including energy and distance. After implementing this algorithm, nodes are in two modes, including ON (active) or OFF (inactive).
Yu et al. introduced the centralized k-coverage protocol in two dynamic and static modes. However, the dynamic scheme has a higher delay than the static method; but it provides better coverage. In general, the centralized CCA is not scalable. As a result, it is not suitable for the large scale WSN. As the sink node requires global information of all sensor nodes in the network. The distributed CCA is scalable and solves the problem of the centralized CCA method, but it has high communication overhead. CCA presents no detection and reconstruction mechanism for repairing network holes.
Mostafaei et al. [
32] offered a partial coverage with learning automata (PCLA) scheme in WSNs. The main purpose of this method is to minimize the number of sensor nodes required for covering RoI and maintain connectivity. PCLA uses the learning automata (LA) for scheduling sensor nodes. This scheme provides a probabilistic framework to select the subset of the sensor nodes to create a backbone to improve the coverage rate and guarantee network connectivity.
PCLA has two phases: (1) The learning phase. In this phase, subsets of sensor nodes are selected to create a backbone in the network so that network connectivity is guaranteed. (2) The partial coverage phase. If the selected subset in the first phase cannot provide a suitable coverage rate of the RoI, additional nodes are added to this subset to satisfy the appropriate coverage level. PCLA is a distributed, dynamic and scalable method. However, it has a lot of communication overhead. Moreover, PCLA does not present any mechanism for detecting and reconstructing network holes.
Hanh et al. [
33] proposed an area coverage method based on genetic algorithm (GA) called MIGA in heterogeneous WSNs. MIGA is an improved version of IGA. In this method, a stable and reliable fitness function was presented to evaluate the area coverage approximately.
MIGA has five phases: (1) Individual representation. In this phase, each genotype is divided into k sections corresponding to k sensor types and each section has several genes. (2) Population initialization. In this phase, population initialization is not random. In fact, it is done based on a heuristic algorithm. (3) Genetic operators. In MIGA, two crossover operators are used, namely Laplace crossover (LX) and Arithmetic crossover method (AMXO). Then, generated individuals are sorted based on location of sensor nodes in the network. (4) Designing the fitness function. In MIGA, an integral-based fitness function has been proposed to evaluate the RoI coverage. (5) VFA Optimization.
When the MIGA algorithm is stopped, the best solution can be improved using Virtual Force Algorithm (VFA) to maximize area coverage. In this phase, the overlapping sensor nodes are slightly spaced apart to reduce their overlap. As a result, each sensor node executes a local search with neighboring nodes to optimize the final solution. MIGA has several advantages: achieving a stable and quality solution and maximizing area coverage.
Furthermore, this method has certain disadvantages: (1) The integral-based fitness function is not comprehensive and cannot cover all different cases that two sensor nodes may overlap with each other. However, this method introduce a new idea for calculating the overlap between different sensor nodes and can be improved. (2) In this MIGA, the authors attempted to reduce the computational overhead, but they achieved little success. (3) In this method, a centralized area coverage scheme was presented. Therefore, it was not scalable.
Luo et al. [
34] introduced the maximum coverage sets scheduling (MCSS) problem in WSNs. The purpose of this scheme is to find the optimal scheduling strategy for coverage sets to maximize the network lifetime. In this method, two algorithms, called greedy-MCSS and MCSSA, were presented to solve this problem. This method has the advantages: (1) acceptable time complexity, (2) appropriate computational complexity, and (3) improving the network lifetime through the proper scheduling of coverage sets.
However, this method also has disadvantages: (1) It is assumed that the coverage sets are predetermined (the coverage set represents a subset of sensor nodes in the network that can cover the entire network). However, it is important to define these sets. However, the authors ignored this problem. (2) Furthermore, it is assumed that the time slots required for the activity of sensor nodes are already known, whereas this is a false hypothesis that can limit the application of this method. (3) The MCSSA algorithm is a centralized method. As a result, it is not scalable and cannot be desirable for large-scale WSNs. (4) The authors only considered the activity time of the sensor nodes for solving the MCSS problem. However, this is an important weakness because other parameters, such as the energy and distance of nodes from each other, are critical.
Benahmed et al. [
35] presented an optimal barrier coverage method that minimizes the number of sensor nodes and maximizes the coverage rate in homogeneous WSNs. This method can calculate the minimum number of sensor nodes that cover a 2D area completely. Moreover, a geometric mathematics-based formula was proposed for calculating the coverage value. In this method, the minimum number of sensor nodes was calculated based on the distance and angle between two neighboring nodes that have overlap.
In addition, the authors presented an algorithm to reduce overlap between sensor nodes as much as possible so that appropriate distance between two sensor nodes is obtained based on the optimal number of nodes and the maximum coverage rate. They proposed a mechanism for detecting failed nodes and reconstructing holes created in the network. The most important advantage of this method is the appropriate coverage rate with the minimum number of sensor nodes.
On the other hand, the geometric mathematical model presented in this method is a novel and attractive solution that can be improved. This method takes into account parameters, like the distance and the overlap between the sensor nodes, to determine the coverage rate of the network. This method can be improved by considering more parameters, such as the energy of the sensor nodes.
One of the disadvantages of this scheme is that it applied a reactive mechanism for detecting failed nodes and reconstructing holes in the network, i.e., when a failed node or hole is identified, then this mechanism is executed to repair it. This can disrupt network performance and increase delay in the data transmission process to BS. Therefore, it is better to use predictive methods to detect nodes that may be damaged in the near future.
Saha et al. [
36] introduced a suitable and rapid scheme to approximate the area covered in homogeneous WSNs. This approach utilizes digital geometry to approximate a real circle (i.e., sensing range of each sensor node) using a digital circle. The authors argue that their proposed algorithm has less computational complexity and lower time complexity than geometric mathematics-based operations executed on a real circle.
In addition, each digital circle is estimated using two squares: (1) the largest square inside the circle and (2) the smallest square outside the circle. As a result, this method can estimate the area covered by each sensor node with an acceptable error rate and appropriate time complexity. The authors proposed a fast, simple and distributed algorithm, which has low computational overhead, to estimate the total area covered in the network. As a result, it is suitable for energy-limited WSN.
However, the authors added some points to improve the performance of this method: (1) In this method, a suitable scheduling mechanism was not designed to adjust the activity time of nodes. Moreover, it is important to take into account various parameters, such as the node energy for modeling this mechanism. (2) This method ignores a reconstruction and detection mechanism to repair holes created in the network due to the death of some sensor nodes. (3) This method is a static area coverage scheme, whereas, WSNs have a dynamic topology and are more compatible with dynamic schemes.
Binh et al. [
37] proposed two nature-based algorithms, including improved cuckoo search (ICS) and chaotic flower pollination algorithm (CFPA), to improve area coverage in heterogeneous WSNs. The purpose of this method is to reduce energy consumption of sensor nodes. This method has several steps, including individual representation, initialization and fitness function, and updating individuals. Refer to [
37] for more details.
The proposed fitness function in these algorithms is based on the overlap between sensing range of sensor nodes. Obviously, if the overlap between sensor nodes is reduced, then they can cover a larger area. ICS and CFPA algorithms can reduce computational complexity and generate high quality responses. Another advantage of these algorithms is their simplicity and high convergence speed.
However, these two algorithms also have disadvantages: (1) The fitness function considers only one parameter, namely the overlap between the sensor nodes. However, it can improve with considering more parameters. (2) This method is a static area coverage. It searches for the best replacement strategy for sensor nodes. However, it does not provide a reconstruction and detection mechanism to resolve problems related to death of some sensor nodes and hole establishment in the network.
Binh et al. [
38] proposed two meta-heuristic algorithms, namely genetic algorithm (GA) and particle swarm optimization (PSO) to maximize the area coverage in a heterogeneous WSN. It is assumed that network includes a number of obstacles, which block communications between sensor nodes. Therefore, the authors have defined the maximum area coverage problem in a network having obstacles and have proposed two algorithms GA and PSO to solve this problem.
In this method, a novel fitness function was designed based on the overlap between sensing ranges of the sensor nodes with respect to obstacles in the network. The purpose of these algorithms is to reduce the overlap between sensor nodes in the network. Refer to [
38] for more details. These algorithms have an important advantage: maximizing the area coverage with acceptable computational overhead.
However, this method also has disadvantages: (1) It considers only one parameter i.e., the overlap for designing fitness function. (2) In this method, the aim is maximum area coverage. However, the maximum network lifetime is also important. If the residual energy of the sensor nodes has been considered in the fitness function, then it can also improve network lifetime. (3) This is a static and centralized area coverage method. Thus, it has low scalability.
Li et al. [
39] presented a reasonable mathematical model to solve the weak coverage problem in WSNs. The area coverage algorithm can adjust movement direction of the sensor nodes toward low-density areas, and thus that the area coverage is maximized. As a result, sensor nodes are almost distributed in the network uniformly. The authors improved the virtual force algorithm. Refer to [
39] for more details.
This method has several advantages: (1) maximizing the network coverage rate and (2) a low computational complexity. However, this method also has some disadvantages: (1) It is a centralized area coverage method, whereas distributed area coverage schemes are more desirable for WSNs. (2) This method does not take into account the network lifetime. Considering energy of the nodes is important in WSNs. (3) This area coverage method is static. This can weaken its efficiency.
Kashi et al. [
40] proposed a heterogeneous distributed precise coverage rate (HDPCR) mechanism, which calculates the area coverage in a distributed manner. This method can detect the network boundaries, holes, and stains using simple mathematical calculations and compute the entire area covered in the network exactly. This process is locally done and each sensor node participates in it. This method includes several important advantages: (1) a low computational overhead and (2) a distributed area coverage method that is more suitable for WSNs than for centralized schemes.
However, it suffers from several major weaknesses: (1) High communication overhead. (2) This method only calculates the area covered in the network. It does not describe the purpose of these operations. Generally, the main purposes of an area coverage method are searching for the best replacement strategy for sensor nodes in the network, obtaining the best area coverage quality with the minimum sensor nodes, achieving the maximum network lifetime, designing suitable scheduling schemes, and so on.
Therefore, calculating the area covered in the network alone is not the main goal of an area coverage method. (3) In this approach, the covered area is locally calculated through the sensor nodes in the network. If one of the sensor nodes performs its calculations incorrectly, then the final result will not be accurate.
Miao et al. [
41] introduced a grey wolf optimizer with enhanced hierarchy (GWO-EH) that improved the grey wolf optimizer (GWO) algorithm. The authors claimed that GWO-EH can solve certain weaknesses of GWO, such as the low convergence speed and becoming trapped in local optimum. They solved the convergence rate by improving the weight coefficients. To balance global and local searches, they improve the position updating equation. Then, they applied GWO-EH to solve the area coverage problem in homogeneous WSNs.
The experiments indicate that this method has a suitable convergence rate. However, this method also has some disadvantages: (1) In this scheme, if the number of sensor nodes in the network is increased, then the convergence rate will be reduced. Therefore, this method is not scalable. (2) Its computational complexity is high. (3) This is a centralized area coverage method. (4) It is a static coverage scheme and cannot provide a suitable reconstruction and detection mechanism for covering holes established in the network.
Table 1 lists the advantages and disadvantages of different coverage schemes, which were briefly reviewed in this section.




 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}