
A Learning-Based Hybrid Framework for Dynamic Balancing of Exploration-Exploitation: Combining Regression Analysis and Metaheuristics





Abstract
:1. Introduction
2. Related Work
3. Proposed Hybrid Approach
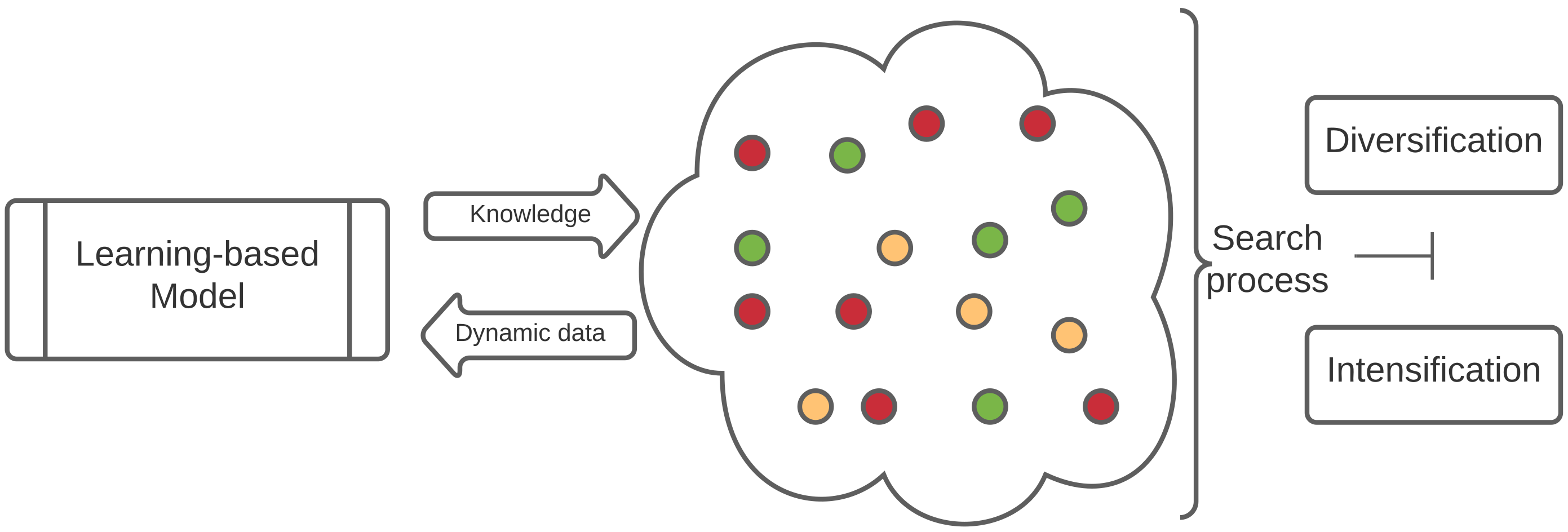
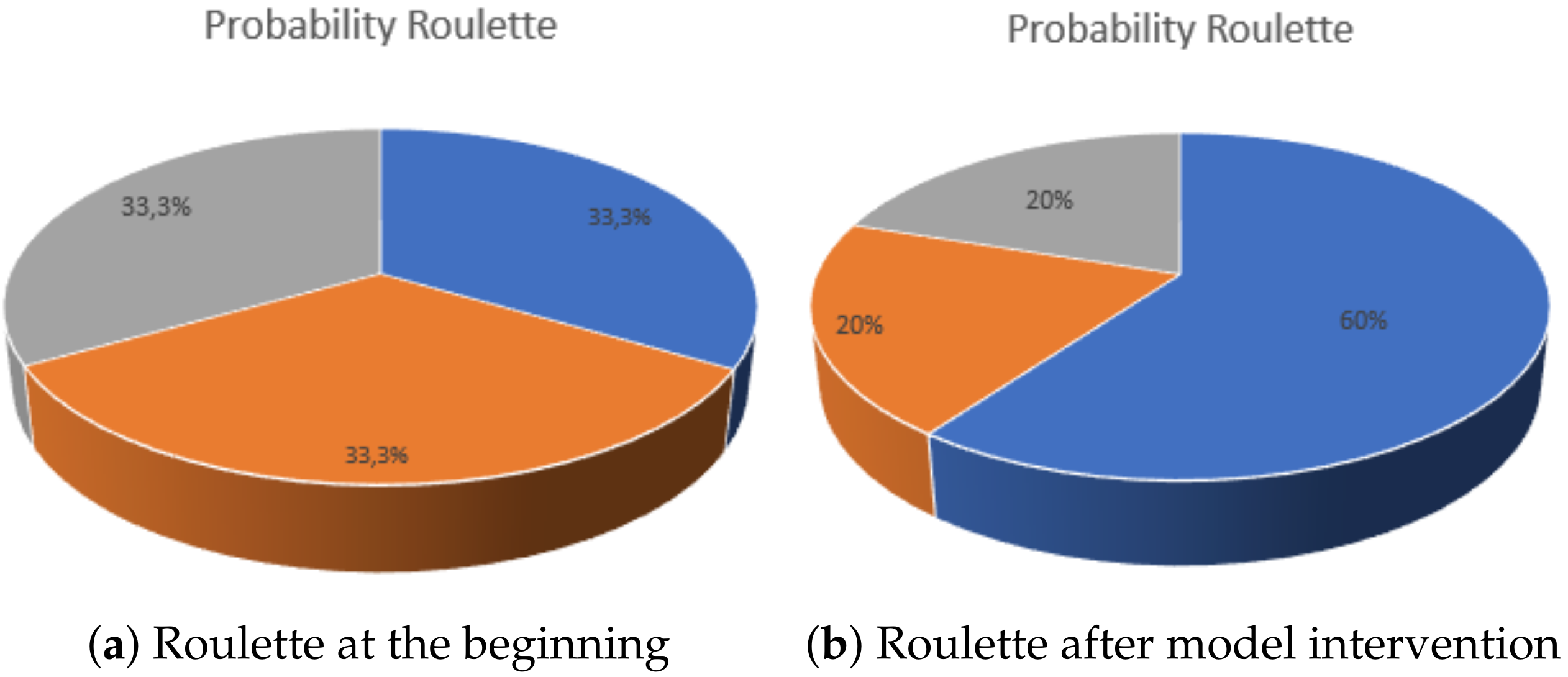
3.1. General Description
3.2. Methodology
3.3. Spotted Hyena Optimiser
- Encircling prey: Each hyena takes the current best candidate solution as the target prey. They will try to move towards the best position defined.where is the distance between the current spotted hyena and the prey, x indicates the current iteration, B and E are coefficient vectors, is the position of the prey, and P is the position of the spotted hyena. The vectors B and E are defined as follows:where = 1, 2, 3, … , , and are random vectors in [0, 1].
- Hunting: The hyenas make a cluster towards the best agent so far to update their positions. The equations are proposed as follows:where is the best spotted hyena in the population, and indicates the position of other spotted hyenas. Here, N is the number of spotted hyenas, which is computed as follows:Here, M is a random vector [0.5, 1], defines the number of solutions and count all candidate solutions plus M, and is a cluster of N number of optimal solutions.
- Attacking Prey: SHO works around the cluster forcing the spotted hyenas to assault towards the prey. The following equation was proposed:Here, updates the positions of each spotted hyenas according to the position of the best search agent and save the best solution.
- Search for Prey: The agents mostly search the prey based on the position of the cluster of spotted hyenas, which reside in vector . SHO makes use of the coefficient vector E and B with random values to force the search agents to move far away from the prey. This mechanism allows the algorithm to search globally.
3.4. Proposed Algorithm
| Algorithm 1Proposed |
|
| Algorithm 2Regression Model |
|
4. Experimental Results
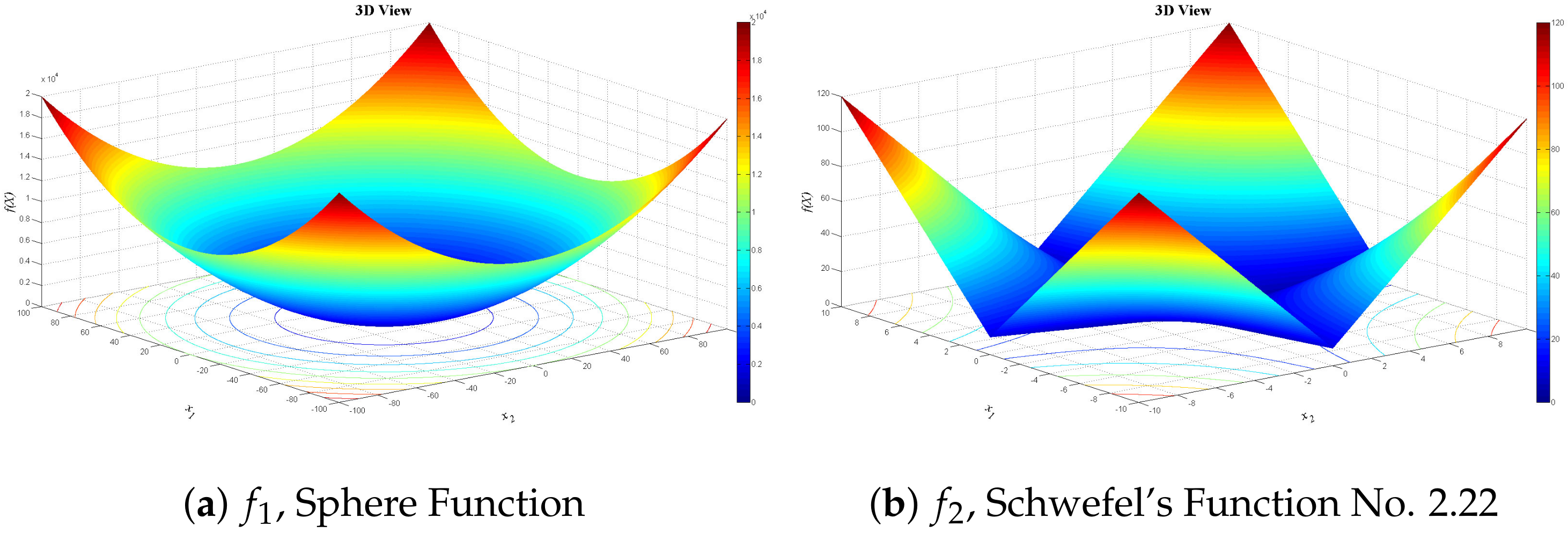
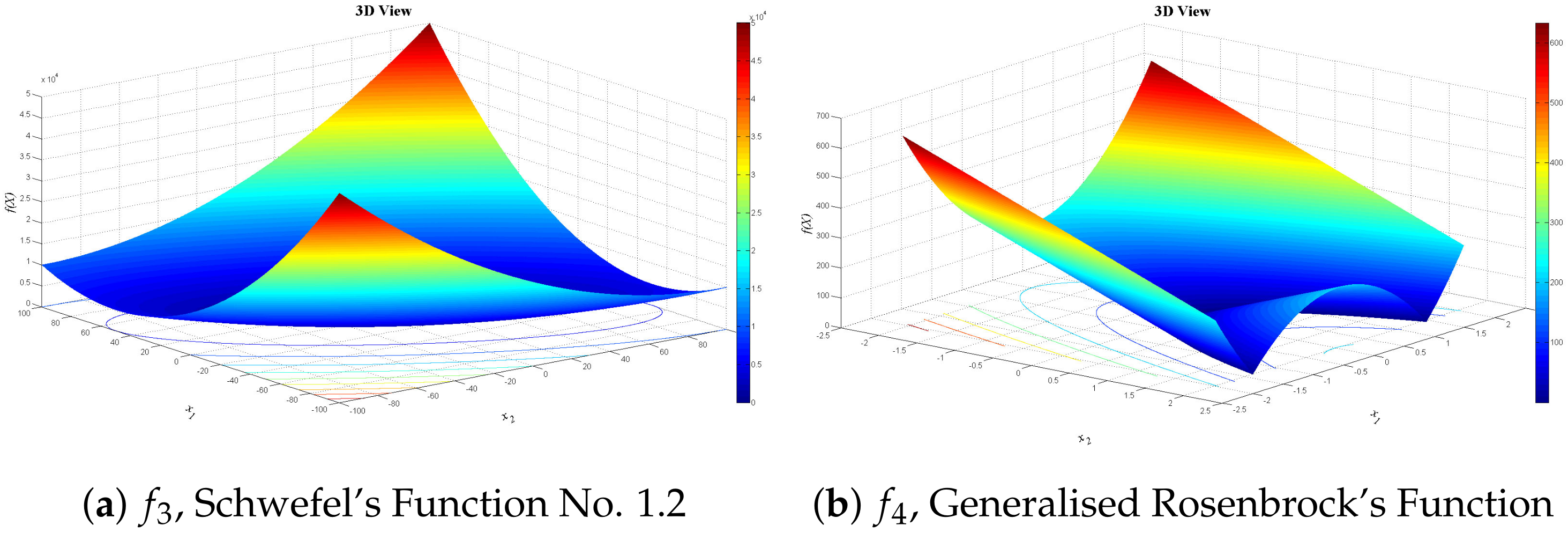
4.1. Benchmark Test Functions
- if
- 0 if
- if
4.2. Algorithms Used for Comparison and Experimental Setup
4.3. Performance Comparison
4.3.1. First Experimentation Phase
4.3.2. Second Experimentation Phase
4.3.3. Third Experimentation Phase
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Talbi, E.G. Combining metaheuristics with mathematical programming, constraint programming and machine learning. Ann. Oper. Res. 2016, 240, 171–215. [Google Scholar] [CrossRef]
- Gendreau, M.; Potvin, J.Y. Handbook of Metaheuristics, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Hussain, K.; Salleh, M.N.M.; Cheng, S.; Shi, Y. On the exploration and exploitation in popular swarm-based metaheuristic algorithms. Neural Comput. Appl. 2019, 31, 7665–7683. [Google Scholar] [CrossRef]
- Chu, X.; Wu, T.; Weir, J.D.; Shi, Y.; Niu, B.; Li, L. Learning–interaction–diversification framework for swarm intelligence optimizers: A unified perspective. Neural Comput. Appl. 2020, 32, 1789–1809. [Google Scholar] [CrossRef]
- Boussaïd, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Tapia, D.; Crawford, B.; Soto, R.; Cisternas-Caneo, F.; Lemus-Romani, J.; Castillo, M.; García, J.; Palma, W.; Paredes, F.; Misra, S. A Q-Learning Hyperheuristic Binarization Framework to Balance Exploration and Exploitation. In International Conference on Applied Informatics; Springer: Cham, Switzerland, 2020; pp. 14–28. [Google Scholar]
- Parsons, S. Introduction to Machine Learning by Ethem Alpaydin. In The Knowledge Engineering Review; MIT Press: Cambridge, MA, USA, 2005; Volume 20, pp. 432–433. [Google Scholar]
- Song, H.; Triguero, I.; Özcan, E. A review on the self and dual interactions between machine learning and optimisation. Prog. Artif. Intell. 2019, 8, 143–165. [Google Scholar] [CrossRef] [Green Version]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: New York, NY, USA, 2012. [Google Scholar]
- Lantz, B. Machine Learning with R; Packt Publishing: Birmingham, UK, 2013. [Google Scholar]
- Dietterich, T. Machine Learning. ACM Comput. Surv. 1996, 28, 3. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Spotted hyena optimizer: A novel bio-inspired based metaheuristic technique for engineering applications. Adv. Eng. Softw. 2017, 114, 48–70. [Google Scholar] [CrossRef]
- Soto, R.; Crawford, B.; Vega, E.; Gómez, A.; Gómez-Pulido, J.A. Solving the Set Covering Problem Using Spotted Hyena Optimizer and Autonomous Search. Advances and Trends in Artificial Intelligence. From Theory to Practice. In IEA/AIE 2019; Springer: Cham, Swizterland, 2019; Volume 11606. [Google Scholar]
- Luo, Q.; Li, J.; Zhou, Y.; Liao, L. Using spotted hyena optimizer for training feedforward neural networks. Cogn. Syst. Res. 2021, 65, 1–16. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Cortés-Toro, E.M.; Crawford, B.; Gómez-Pulido, J.A.; Soto, R.; Lanza-Gutiérrez, J.M. A New Metaheuristic Inspired by the Vapour-Liquid Equilibrium for Continuous Optimization. Appl. Sci. 2018, 8, 2080. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Yan, F. Hybrid Nelder–Mead algorithm and dragonfly algorithm for function optimization and the training of a multilayer perceptron. Arab. J. Sci. Eng. 2019, 44, 3473–3487. [Google Scholar] [CrossRef]
- Bartz-Beielstein, T.; Lasarczyk, C.W.G.; Preuss, M. Sequential parameter optimization. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–5 September 2005; Volume 1, pp. 773–780. [Google Scholar]
- Wang, R.L.; Tang, Z.; Cao, Q.P. A learning method in Hopfield neural network for combinatorial optimization problem. Neurocomputing 2002, 48, 1021–1024. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Talbi, E.G. Combining metaheuristics with mathematical programming, constraint programming and machine learning. 4OR Q. J. Belg. Fr. Ital. Oper. Res. Soc. 2013, 11, 101–150. [Google Scholar] [CrossRef]
- Talbi, E.G. Machine Learning into Metaheuristics: A Survey and Taxonomy of Data-Driven Metaheuristics, Working Paper or Preprint. June 2020.
- Escalante, H.J.; Ponce-López, V.; Escalera, S.; Baró, X.; Morales-Reyes, A.; Martínez-Carranza, J. Evolving weighting schemes for the bag of visual words. Neural Comput. Appl. 2016, 28, 925–939. [Google Scholar] [CrossRef]
- Stein, G.; Chen, B.; Wu, A.S.; Hua, K.A. Decision tree classifier for network intrusion detection with GA-based feature selection. In Proceedings of the 43rd Annual Southeast Regional Conference, Kennesaw, GA, USA, 18 March 2005; Volume 2, pp. 136–141. [Google Scholar]
- Sörensen, K.; Janssens, G.K. Data mining with genetic algorithms on binary trees. Eur. J. Oper. Res. 2003, 151, 253–264. [Google Scholar] [CrossRef]
- Fernández Caballero, J.C.; Martinez, F.J.; Hervas, C.; Gutierrez, P.A. Sensitivity versus accuracy in multiclass problems using memetic pareto evolutionary neural networks. IEEE Trans. Neural Netw. 2010, 21, 750–770. [Google Scholar] [CrossRef]
- Huang, C.L.; Wang, C.J. A GA-based feature selection and parameters optimization for support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Glover, F.; Hao, J.K. Diversification-based learning in computing and optimization. J. Heuristics 2019, 25, 521–537. [Google Scholar] [CrossRef] [Green Version]
- Máximo, V.R.; Nascimento, M.C. Intensification, learning and diversification in a hybrid metaheuristic: An efficient unification. J. Heuristics 2019, 25, 539–564. [Google Scholar] [CrossRef]
- Lessmann, S.; Caserta, M.; Arango, I.M. Tuning metaheuristics: A data mining based approach for particle swarm optimization. Expert Syst. Appl. 2011, 38, 12826–12838. [Google Scholar] [CrossRef]
- Zennaki, M.; Ech-Cherif, A. A new machine learning based approach for tuning metaheuristics for the solution of hard combinatorial optimization problems. J. Appl. Sci. 2010, 10, 1991–2000. [Google Scholar] [CrossRef]
- Porumbel, D.C.; Hao, J.K.; Kuntz, P. A search space “cartography” for guiding graph coloring heuristics. Comput. Oper. Res. 2010, 37, 769–778. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.H.; Plastino, A.; Martins, S.L. Hybridization of GRASP metaheuristic with data mining techniques. J. Math. Model. Algorithms 2006, 5, 23–41. [Google Scholar] [CrossRef]
- Dalboni, F.L.; Ochi, L.S.; Drummond, L.M.A. On improving evolutionary algorithms by using data mining for the oil collector vehicle routing problem. In Proceedings of the International Network Optimization Conference, Rio de Janeiro, Brazil, 22 April 2003; pp. 182–188. [Google Scholar]
- Amor, H.B.; Rettinger, A. Intelligent exploration for genetic algorithms: Using self-organizing maps in evolutionary computation. In Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation, Washington DC, USA, 25–29 June 2005; pp. 1531–1538. [Google Scholar]
- Yuen, S.Y.; Chow, C.K. A genetic algorithm that adaptively mutates and never revisits. IEEE Trans. Evol. Comput. 2008, 13, 454–472. [Google Scholar] [CrossRef]
- Dhaenens, C.; Jourdan, L. Metaheuristics for Big Data; Wiley: Hoboken, NJ, USA, 2016; ISBN 9781119347606. [Google Scholar]
- Yang, L.; Shami, A. On Hyperparameter Optimization of Machine Learning Algorithms: Theory and Practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. ACM Int. Conf. Proc. Ser. 2006, 148, 161–168. [Google Scholar]
- Article, R. Linear Regression Analysis. Dtsch. äRzteblatt Int. 2010, 107, 776–782. [Google Scholar]
- Almeida, A.M.D.; Castel-Branco, M.M.; Falcao, A.C. Linear regression for calibration lines revisited: Weighting schemes for bioanalytical methods. J. Chromatogr. B 2002, 774, 215–222. [Google Scholar] [CrossRef]
- Digalakis, J.; Margaritis, K. On benchmarking functions for genetic algorithms. Int. J. Comput. Math 2001, 77, 481–506. [Google Scholar] [CrossRef]
- Yang, X. Firefly algorithm, stochastic test functions and design optimisation. Int. J. Bio-Inspired Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Yao, X.; Liu, Y.; Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 1999, 3, 82–102. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lilliefors, H. On the kolmogorov–smirnov test for normality with mean and variance unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]
- Mann, H.; Whitney, D. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Amount of Intensification | Amount of Diversification |
|---|---|---|
| Soft | 1 | 1 |
| Medium | 2 | 2 |
| Hard | 3 | 3 |
| Pool of Operators | |
|---|---|
| Intensification | Diversification |
| Exploitation movement 1 | Exploration movement 1 |
| Exploitation movement 2 | Exploration movement 2 |
| : | : |
| Function | Search Subsets | Opt | Sol |
|---|---|---|---|
| (x) | 0 | ||
| (x) | 0 | ||
| (x) | 0 | ||
| (x) | 0 | ||
| (x) | −12,596.487 | ||
| (x) | 0 | ||
| (x) | 0 | ||
| (x) | 0 | ||
| (x) | 0 | ||
| (x) | 1 | ||
| (x) | −1.0316285 | (0.08983, −0.7126) and (−0.08983, 0.7126) | |
| (x) | for and for | 0.397887 | (−3.142, 12.275), (3.142, 2.275), and (9.425, 2.425) |
| (x) | 3 | (0, −1) | |
| (x) | −3.86 | (0.114, 0.556, 0.852) | |
| (x) | −3.32 | (0.201, 0.150, 0.477, 0.275, 0.275, 0.377, 0.657) |
| i | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 3 | 10 | 30 | 1 | 0.3689 | 0.1170 | 0.2673 |
| 2 | 0.1 | 10 | 35 | 1.2 | 0.4699 | 0.4387 | 0.7470 |
| 3 | 3 | 10 | 30 | 3 | 0.1091 | 0.8732 | 0.5547 |
| 4 | 0.1 | 10 | 30 | 3.2 | 0.03815 | 0.5743 | 0.8828 |
| i | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 3 | 17 | 3.5 | 1.7 | 8 | 1 | 0.131 | 0.169 | 0.556 | 0.012 | 0.828 | 0.588 |
| 2 | 0.05 | 10 | 17 | 0.1 | 8 | 14 | 1.2 | 0.232 | 0.413 | 0.830 | 0.373 | 0.100 | 0.999 |
| 3 | 3 | 3.5 | 1.7 | 10 | 17 | 8 | 3 | 0.234 | 0.141 | 0.352 | 0.288 | 0.304 | 0.665 |
| 4 | 17 | 8 | 0.05 | 10 | 0.1 | 14 | 3.2 | 0.404 | 0.882 | 0.873 | 0.574 | 0.109 | 0.038 |
| F | SHO | WOA | DE | GSA | PSO | VLE | INMDA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | |
| 0.0006 | 0.0005 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||||||||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.1941 | 0.0000 | 0.0000 | ||||||||
| 0.0007 | 0.0005 | 0.0000 | 0.0000 | 70.126 | 22.119 | 5.2020 | 0.7986 | 0.0000 | 0.0000 | |||||||
| 2.7511 | 0.0502 | 27.866 | 0.7636 | 0.0000 | 0.0000 | 67.543 | 62.225 | 96.718 | 60.116 | 79.199 | 37.400 | 0.0000 | 0.0000 | |||
| F | SHO | WOA | DE | GSA | PSO | VLE | INMDA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | |
| 0.5059 | 0.0014 | 68.705 | −2245.1500 | 2.8400 | ||||||||||||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 69.200 | 38.800 | 25.968 | 7.4701 | 46.704 | 11.629 | 34.5830 | 17.8860 | 0.0000 | 0.0000 | |
| 0.0000 | 0.0000 | 7.4043 | 9.8976 | 0.23628 | 0.27602 | 0.50901 | 3.1704 | 3.9211 | 0.0000 | |||||||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 27.702 | 5.0403 | 0.5074 | 0.5041 | 0.0000 | 0.0000 | |||||
| 1.906 | 0.0865 | 1.8286 | 0.3397 | 0.2149 | 1.7996 | 0.95114 | 0.2369 | 0.2877 | 0.0000 | 0.0000 | ||||||
| F | SHO | WOA | DE | GSA | PSO | VLE | INMDA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | Avg | StdDev | |
| 1.0000 | 0.0000 | 2.1120 | 2.4986 | 0.99800 | 5.8598 | 3.8313 | 3.6272 | 2.5608 | 0.99800 | N/A | N/A | |||||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0315 | N/A | N/A | ||||||
| 0.8718 | 0.0502 | 1.5436 | 0.4223 | 0.39791 | 0.39789 | 0.39789 | 0.0000 | 0.39789 | 0.0000 | 0.39815 | N/A | N/A | ||||
| 36.0716 | 4.1607 | 32.6845 | 3.0000 | 3.0000 | 3.0000 | 3.0000 | 3.0097 | N/A | N/A | |||||||
| −2.1211 | 0.1284 | −2.0081 | −3.8562 | N/A | N/A | −3.8628 | −3.8628 | −3.8628 | N/A | N/A | ||||||
| −0.8515 | 0.3541 | −1.5870 | 0.5016 | −2.9811 | 0.37665 | N/A | N/A | −3.3178 | −3.2663 | −3.3179 | N/A | N/A | ||||
| Problem | PSO | PSO + SPO | |
|---|---|---|---|
| Sphere | 0 | ||
| Rosenbrock | 148.84 | 4.20 | 0 |
| Rastrigin | 10.43 | 0.98 | 0 |
| Griewangk | 0.12 | 0.07 | 0 |
| F | Opt | SHO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Avg | StdDev | Avg Time(s) | Best | Worst | Avg | StdDev | Avg Time(s) | ||
| 0 | 0 | 0.0021 | 0.0006 | 0.0005 | 51.6432 | 0 | 0 | 0 | 0 | 50.2377 | |
| 0 | 0 | 0 | 0 | 0 | 78.9275 | 0 | 0 | 0 | 0 | 80.7524 | |
| 0 | 0 | 0.0009 | 0.0007 | 0.0005 | 95.5684 | 0 | 0 | 0 | 0 | 96.3627 | |
| 0 | 2.7091 | 2.9351 | 2.7511 | 0.0502 | 75.8810 | 71.0024 | |||||
| −12,569.487 | 0.5059 | 121.3511 | 0.0014 | 110.3354 | |||||||
| 0 | 0 | 0 | 0 | 0 | 172.9312 | 0 | 0 | 0 | 0 | 60.6482 | |
| 0 | 0 | 256.8700 | 0 | 24.9122 | |||||||
| 0 | 0 | 0 | 0 | 0 | 198.8546 | 0 | 0 | 0 | 0 | 21.7758 | |
| 0 | 1.8290 | 2.5642 | 1.906 | 0.0865 | 256.8707 | 1.8285 | 1.8286 | 1.8286 | 24.9172 | ||
| 1 | 130.3552 | 1 | 1 | 1 | 0 | 17.5661 | |||||
| −1.0316 | 0 | 0 | 0 | 0 | 29.1582 | 0 | 0 | 0 | 0 | 7.5244 | |
| 0.3979 | 0.8298 | 0.9523 | 0.8718 | 0.0502 | 22.5778 | 1.1905 | 2.0325 | 1.5436 | 0.4223 | 4.5528 | |
| 3 | 32.6845 | 44.4562 | 36.0716 | 4.1607 | 35.7789 | 32.6845 | 32.6845 | 32.6845 | 3.6846 | ||
| −3.86 | −2.4301 | −2.0081 | −2.211 | 0.1284 | 53.2235 | −2.0081 | −2.0080 | −2.0081 | 7.1120 | ||
| −3.32 | −1.1676 | −0.4676 | −0.8515 | 0.3541 | 80.4755 | −2.1676 | −2.1676 | −2.1676 | 0 | 8.1145 | |
| F | Opt | NN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Avg | StdDev | Avg Time(s) | Best | Worst | Avg | StdDev | Avg Time(s) | ||
| 0 | 0.0639 | 0.2223 | 0.1068 | 0.0435 | 347.4073 | 0 | 0 | 0 | 0 | 50.2377 | |
| 0 | 1.2426 | 5.8827 | 4.4004 | 0.8284 | 375.2112 | 0 | 0 | 0 | 0 | 80.7524 | |
| 0 | 0.0001 | 0.0379 | 0.0103 | 0.0108 | 377.0420 | 0 | 0 | 0 | 0 | 96.3627 | |
| 0 | 211.4253 | 3037.6363 | 1376.6472 | 1041.5627 | 375.6543 | 71.0024 | |||||
| −12,569.487 | 2056.9973 | 357.8577 | 0.0014 | 110.3354 | |||||||
| 0 | 1.8672 | 7.8028 | 4.2664 | 1.5939 | 357.7703 | 0 | 0 | 0 | 0 | 60.6482 | |
| 0 | 0.2687 | 0.5169 | 0.3905 | 0.0689 | 350.7136 | 0 | 24.9122 | ||||
| 0 | 0.0416 | 1.1238 | 0.8017 | 0.1986 | 354.9282 | 0 | 0 | 0 | 0 | 21.7758 | |
| 0 | 29,752,063.66 | 29,800,464.52 | 29,792,019.73 | 9855.6445 | 357.1411 | 1.8285 | 1.8286 | 1.8286 | 24.9172 | ||
| 1 | 0.0160 | 495.8931 | 214.7364 | 200.8041 | 343.9354 | 1 | 1 | 1 | 0 | 17.5661 | |
| −1.0316 | −0.0079 | 0.0103 | 0.0005 | 0.0041 | 344.4559 | 0 | 0 | 0 | 0 | 7.5244 | |
| 0.3979 | 10.0004 | 16.3393 | 12.2766 | 1.3941 | 369.1712 | 1.1905 | 2.0325 | 1.5436 | 0.4223 | 4.5528 | |
| 3 | 3.0227 | 5.4062 | 5.3044 | 1.5586 | 369.8705 | 32.6845 | 32.6845 | 32.6845 | 3.6846 | ||
| −3.86 | −3.8417 | −3.5163 | −3.7177 | 0.0913 | 376.6538 | −2.0081 | −2.0080 | −2.0081 | 7.1120 | ||
| −3.32 | −1.4809 | −0.7560 | −1.0409 | 0.2019 | 342.6122 | −2.1676 | −2.1676 | −2.1676 | 0 | 8.1145 | |
| F | Opt | SCA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Avg | StdDev | Avg Time(s) | Best | Worst | Avg | StdDev | Avg time(s) | ||
| 0 | 0 | 0 | 0 | 0 | 10.4656 | 0 | 0 | 0 | 0 | 50.2377 | |
| 0 | 0 | 0 | 0 | 0 | 17.3875 | 0 | 0 | 0 | 0 | 80.7524 | |
| 0 | 0 | 0 | 0 | 0 | 74.3906 | 0 | 0 | 0 | 0 | 96.3627 | |
| 0 | 29 | 17.4000 | 14.9755 | 13.4296 | 71.0024 | ||||||
| −12,569.487 | 0.0696 | 0.0181 | 0.0251 | 9.5828 | 0.0014 | 110.3354 | |||||
| 0 | 0 | 0 | 0 | 0 | 11.2296 | 0 | 0 | 0 | 0 | 60.6482 | |
| 0 | 0 | 15.1140 | 0 | 24.9122 | |||||||
| 0 | 0 | 0 | 0 | 0 | 13.3500 | 0 | 0 | 0 | 0 | 21.7758 | |
| 0 | 1.8285 | 1.8416 | 1.8304 | 0.0042 | 78.2046 | 1.8285 | 1.8286 | 1.8286 | 24.9172 | ||
| 1 | 0.0003 | 4.9301 | 1.0010 | 2.0705 | 28.9609 | 1 | 1 | 1 | 0 | 17.5661 | |
| −1.0316 | 1.0316 | 1.0316 | 1.0316 | 2.7093 | 0 | 0 | 0 | 0 | 7.5244 | ||
| 0.3979 | 0.1555 | 3.9503 | 1.1009 | 1.3759 | 2.9765 | 1.1905 | 2.0325 | 1.5436 | 0.4223 | 4.5528 | |
| 3 | 29.6845 | 30.0547 | 29.7444 | 0.1229 | 4.1765 | 32.6845 | 32.6845 | 32.6845 | 3.6846 | ||
| −3.86 | 1.8519 | 1.8519 | 1.8519 | 0 | 7.0265 | −2.0081 | −2.0080 | −2.0081 | 7.1120 | ||
| −3.32 | 2.1523 | 2.1524 | 2.1524 | 0 | 9.5578 | −2.1676 | −2.1676 | −2.1676 | 0 | 8.1145 | |
| F | SHO | ||
|---|---|---|---|
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | ||
| >0.05 | - | ||
| SHO | - | ||
| >0.05 | - | ||
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | ||
| >0.05 | - | ||
| SHO | - | ||
| >0.05 | - | ||
| SHO | - | 0.02067 | |
| >0.05 | - | ||
| SHO | - | >0.05 | |
| 0.04 | - | ||
| SHO | - | >0.05 | |
| >0.05 | - | ||
| SHO | - | ||
| >0.05 | - | ||
| SHO | - | ||
| >0.05 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vega, E.; Soto, R.; Crawford, B.; Peña, J.; Castro, C. A Learning-Based Hybrid Framework for Dynamic Balancing of Exploration-Exploitation: Combining Regression Analysis and Metaheuristics. Mathematics 2021, 9, 1976. https://doi.org/10.3390/math9161976
Vega E, Soto R, Crawford B, Peña J, Castro C. A Learning-Based Hybrid Framework for Dynamic Balancing of Exploration-Exploitation: Combining Regression Analysis and Metaheuristics. Mathematics. 2021; 9(16):1976. https://doi.org/10.3390/math9161976
Chicago/Turabian StyleVega, Emanuel, Ricardo Soto, Broderick Crawford, Javier Peña, and Carlos Castro. 2021. "A Learning-Based Hybrid Framework for Dynamic Balancing of Exploration-Exploitation: Combining Regression Analysis and Metaheuristics" Mathematics 9, no. 16: 1976. https://doi.org/10.3390/math9161976
APA StyleVega, E., Soto, R., Crawford, B., Peña, J., & Castro, C. (2021). A Learning-Based Hybrid Framework for Dynamic Balancing of Exploration-Exploitation: Combining Regression Analysis and Metaheuristics. Mathematics, 9(16), 1976. https://doi.org/10.3390/math9161976