
Efficiency Analysis with Educational Data: How to Deal with Plausible Values from International Large-Scale Assessments



Abstract
:1. Introduction
2. Plausible Values and How to Use Them in Empirical Analyses
2.1. What Are Plausible Values?
2.2. How to Use Plausible Values in Secondary Analyses
2.3. Plausible Values in Efficiency Analyses
3. Methodology
4. Data and Variables
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reynolds, D.; Teddlie, C. The International Handbook of School Effectiveness Research; Routledge: London, UK, 2002. [Google Scholar]
- Creemers, B.; Kyriakides, L. The Dynamics of Educational Effectiveness; Routledge: London, UK, 2008. [Google Scholar]
- Ergüzen, A.; Erdal, E.; Ünver, M.; Özcan, A. Improving Technological Infrastructure of Distance Education through Trustworthy Platform-Independent Virtual Software Application Pools. Appl. Sci. 2021, 11, 1214. [Google Scholar] [CrossRef]
- Dospinescu, O.; Dospinescu, N. Perception Over E-Learning Tools in Higher Education: Comparative Study Romania and Moldova. In Proceedings of the IE 2020 International Conference, Madrid, Spain, 20–23 July 2020; Volume 10. [Google Scholar]
- Gustafsson, J.-E. Effects of International Comparative Studies on Educational Quality on the Quality of Educational Research. Eur. Educ. Res. J. 2008, 7, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Fischman, G.E.; Topper, A.M.; Silova, I.; Goebel, J.; Holloway, J.L. Examining the influence of in-ternational large-scale assessments on national education policies. J. Educ. Policy 2019, 34, 470–499. [Google Scholar] [CrossRef]
- Rutkowski, L.; Gonzalez, E.; Joncas, M.; von Davier, M. International large-scale assessment data: Issues in secondary analysis and reporting. Educ. Res. 2010, 39, 142–151. [Google Scholar] [CrossRef]
- Sjøberg, S. PISA and ‘real life challenges’: Mission impossible? In PISA According to PISA: Does PISA Keep What It Promises; LIT: Wien, Vienna, 2007; pp. 241–263. [Google Scholar]
- Sáez-López, J.-M.; Domínguez-Garrido, M.-C.; Medina-Domínguez, M.-D.-C.; Monroy, F.; González-Fernández, R. The Competences from the Perception and Practice of University Students. Soc. Sci. 2021, 10, 34. [Google Scholar] [CrossRef]
- Mislevy, R.J.; Beaton, A.E.; Kaplan, B.; Sheehan, K.M. Estimating Population Characteristics From Sparse Matrix Samples of Item Responses. J. Educ. Meas. 1992, 29, 133–161. [Google Scholar] [CrossRef]
- OECD. PISA 2015 Technical Report; PISA, OECD Publishing: Paris, France, 2016. [Google Scholar]
- Boston College: TIMSS & PIRLS International Study Center. Methods and Procedures in TIMSS 2015. 2016. Available online: http://timssandpirls.bc.edu/publications/timss/2015-methods.html (accessed on 21 May 2021).
- Foy. TIMSS 2015 User Guide for the International Database. TIMSS & PIRLS; International Study Center, International Association for the Evaluation of Educational Achievement: Boston, MA, USA, 2017. [Google Scholar]
- De Witte, K.; López-Torres, L. Efficiency in education: A review of literature and a way forward. J. Oper. Res. Soc. 2017, 68, 339–363. [Google Scholar] [CrossRef]
- Zadeh, L. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Hatami-Marbini, A.; Emrouznejad, A.; Tavana, M. A taxonomy and review of the fuzzy data en-velopment analysis literature: Two decades in the making. Eur. J. Oper. Res. 2011, 214, 457–472. [Google Scholar] [CrossRef]
- Kao, C.; Liu, S.-T. Fuzzy efficiency measures in data envelopment analysis. Fuzzy Sets Syst. 2000, 113, 427–437. [Google Scholar] [CrossRef]
- Berezner, A.; Adams, R.J. Why large-scale assessments use scaling and item response theory. In Implementation of Large-Scale Education Assessments; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2017. [Google Scholar]
- von Davier, M.; Gonzalez, E.; Mislevy, R. Plausible values: What are they and why do we need them? IERI Monogr. Ser. Issues Methodol. Large-Scale Assess. 2009, 2, 9–36. [Google Scholar]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; John Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Schafer, J.L. Multiple Imputation in Multivariate Problems When the Imputation and Analysis Models Differ. Stat. Neerl. 2003, 57, 19–35. [Google Scholar] [CrossRef]
- Von Davier, M.; Sinharay, S. Analytics in international large-scale assessments: Item response the-ory and population models. In Handbook of International Large-Scale Assessment: Background, Technical Issues, And Methods of Data Analysis; Chapman and Hall/CRC: London, UK, 2013; pp. 155–174. [Google Scholar]
- Marsman, M.; Maris, G.K.J.; Bechger, T.M.; Glas, C.A.W. What can we learn from plausible val-ues? Psychometrika 2016, 81, 274–289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laukaityte, I.; Wiberg, M. Using plausible values in secondary analysis in large-scale assessments. Commun. Stat. Theory Methods 2016, 46, 11341–11357. [Google Scholar] [CrossRef]
- Wu, M. The role of plausible values in large-scale surveys. Stud. Educ. Eval. 2005, 31, 114–128. [Google Scholar] [CrossRef]
- Mislevy, R.J. Should “multiple imputations” be treated as “multiple indicators”? Psychometrika 1993, 58, 79–85. [Google Scholar] [CrossRef]
- Luo, Y.; Dimitrov, D.M. A Short Note on Obtaining Point Estimates of the IRT Ability Parameter With MCMC Estimation in Mplus: How Many Plausible Values Are Needed? Educ. Psychol. Meas. 2019, 79, 272–287. [Google Scholar] [CrossRef]
- OECD. PISA 2018 Technical Report; PISA, OECD Publishing: Paris, France, 2019. [Google Scholar]
- Bibby, Y. Plausible Values: How Many for Plausible Results? Ph.D. Thesis, University of Melbourne, Melbourne, Australia, 2020. [Google Scholar]
- Goldstein, H. International comparisons of student attainment: Some issues arising from the PISA study. Assess. Educ. Princ. Policy Pract. 2004, 11, 319–330. [Google Scholar] [CrossRef]
- Braun, H.; von Davier, M. The use of test scores from large-scale assessment surveys: Psychometric and statistical considerations. Large-Scale Assess. Educ. 2017, 5, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Macdonald, K. PV: Stata Module to Perform Estimation with Plausible Values; Statistical Software Compo-nents S456951; College Department of Economics: Boston, MA, USA, 2019. [Google Scholar]
- Avvisati, F.; Keslair, F. REPEST: Stata Module to Run Estimations with Weighted Replicate Samples and Plausible Values; Statistical Software Components; College Department of Economics: Boston, MA, USA, 2020. [Google Scholar]
- OECD. PISA Data Analysis Manual, SPSS Second Edition; OECD Publishing: Paris, France, 2009. [Google Scholar]
- Cordero, J.M.; Polo, C.; Santín, D.; Simancas, R. Efficiency measurement and cross-country differ-ences among schools: A robust conditional nonparametric analysis. Econ. Model. 2018, 74, 45–60. [Google Scholar] [CrossRef]
- De Witte, K.; Kortelainen, M. What explains the performance of students in a heterogeneous envi-ronment? Conditional efficiency estimation with continuous and discrete environmental variables. Appl. Econ. 2013, 45, 2401–2412. [Google Scholar] [CrossRef]
- Agasisti, T.; Zoido, P. Comparing the Efficiency of Schools Through International Benchmarking: Results From an Empirical Analysis of OECD PISA 2012 Data. Educ. Res. 2018, 47, 352–362. [Google Scholar] [CrossRef]
- Agasisti, T.; Zoido, P. The efficiency of schools in developing countries, analysed through PISA 2012 data. Socio-Econ. Plan. Sci. 2019, 68, 100711. [Google Scholar] [CrossRef]
- Aparicio, J.; Cordero, J.M.; Pastor, J.T. The determination of the least distance to the strongly effi-cient frontier in Data Envelopment Analysis oriented models: Modelling and computational aspects. Omega 2017, 71, 1–10. [Google Scholar] [CrossRef]
- Aparicio, J.; Cordero, J.M.; Gonzalez, M.; Lopez-Espin, J.J. Using non-radial DEA to assess school efficiency in a cross-country perspective: An empirical analysis of OECD countries. Omega 2018, 79, 9–20. [Google Scholar] [CrossRef]
- Cordero, J.M.; Prior, D.; Simancas, R. A comparison of public and private schools in Spain using robust nonparametric frontier methods. Central Eur. J. Oper. Res. 2015, 24, 659–680. [Google Scholar] [CrossRef] [Green Version]
- Cordero, J.M.; Santín, D.; Simancas, R. Assessing European primary school performance through a conditional nonparametric model. J. Oper. Res. Soc. 2017, 68, 364–376. [Google Scholar] [CrossRef]
- De Jorge, J.; Santin, D. Determinantes de la eficiencia educativa en la Unión Europea. Hacienda Pública Española 2010, 193, 131–155. [Google Scholar]
- Crespo-Cebada, E.; Pedraja-Chaparro, F.; Santín, D. Does school ownership matter? An unbiased efficiency comparison for regions of Spain. J. Prod. Anal. 2014, 41, 153–172. [Google Scholar] [CrossRef]
- Banker, R.D.; Charnes, A.; Cooper, W.W. Some Models for Estimating Technical and Scale Ineffi-ciencies in Data Envelopment Analysis. Manag. Sci. 1984, 30, 1078–1092. [Google Scholar] [CrossRef] [Green Version]
- Emrouznejad, A.; Tavana, M.; Hatami-Marbini, A. The State of the Art in Fuzzy Data Envelopment Analysis. In Performance Measurement with Fuzzy Data Envelopment Analysis; Springer: Berlin/Heidelberg, Germany; pp. 1–48.
- Waldo, S. On the use of student data in efficiency analysis: Technical efficiency in Swedish upper sec-ondary school. Econ. Educ. Rev. 2007, 26, 173–185. [Google Scholar] [CrossRef]
- Santin, D. La medición de la eficiencia de las escuelas: Una revisión crítica. Hacienda Pública Española 2006, 177, 57–82. [Google Scholar]
- Aparicio, J.; Cordero, J.M.; Ortiz, L. Measuring efficiency in education: The influence of imprecision and variability in data on DEA estimates. Socio-Econ. Plan. Sci. 2019, 68, 100698. [Google Scholar] [CrossRef]
- Thieme, C.; Prior, D.; Tortosa-Ausina, E. A multilevel decomposition of school performance using robust nonparametric frontier techniques. Econ. Educ. Rev. 2013, 32, 104–121. [Google Scholar] [CrossRef] [Green Version]
- Ganzeboom, H.; De Graaf, P.M.; Treiman, D.J. A standard international socio-economic index of occupational status. Soc. Sci. Res. 1992, 21, 1–56. [Google Scholar] [CrossRef] [Green Version]
- Cooper, W.W.; Seiford, L.M.; Tone, K. Data Envelopment Analysis: A Comprehensive Text with Models, Applications, References and DEA-Solver Software; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- R Core Team. Package “Stats.”. RA Lang. Environment Stat. Comput. Vienna, Austria: R Foundation for Statistical Computing. 2021. Available online: https://www.R-project.org (accessed on 21 October 2020).
- Konis, K.; Konis, M.K. Package ‘lpSolveAPI’. 2020. Available online: https://cran.r-project.org/web/packages/lpSolveAPI/lpSolveAPI.pdf (accessed on 21 October 2020).
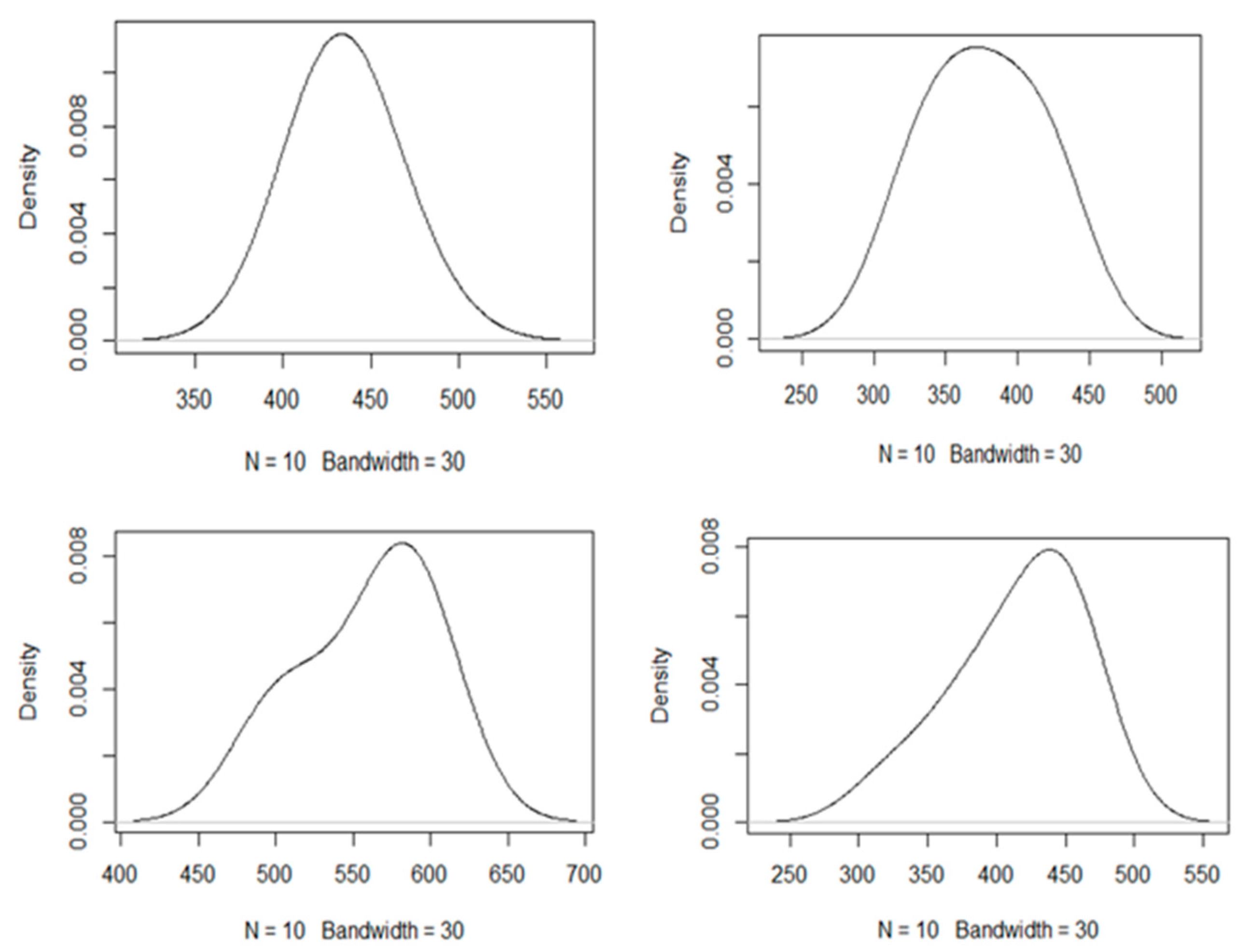

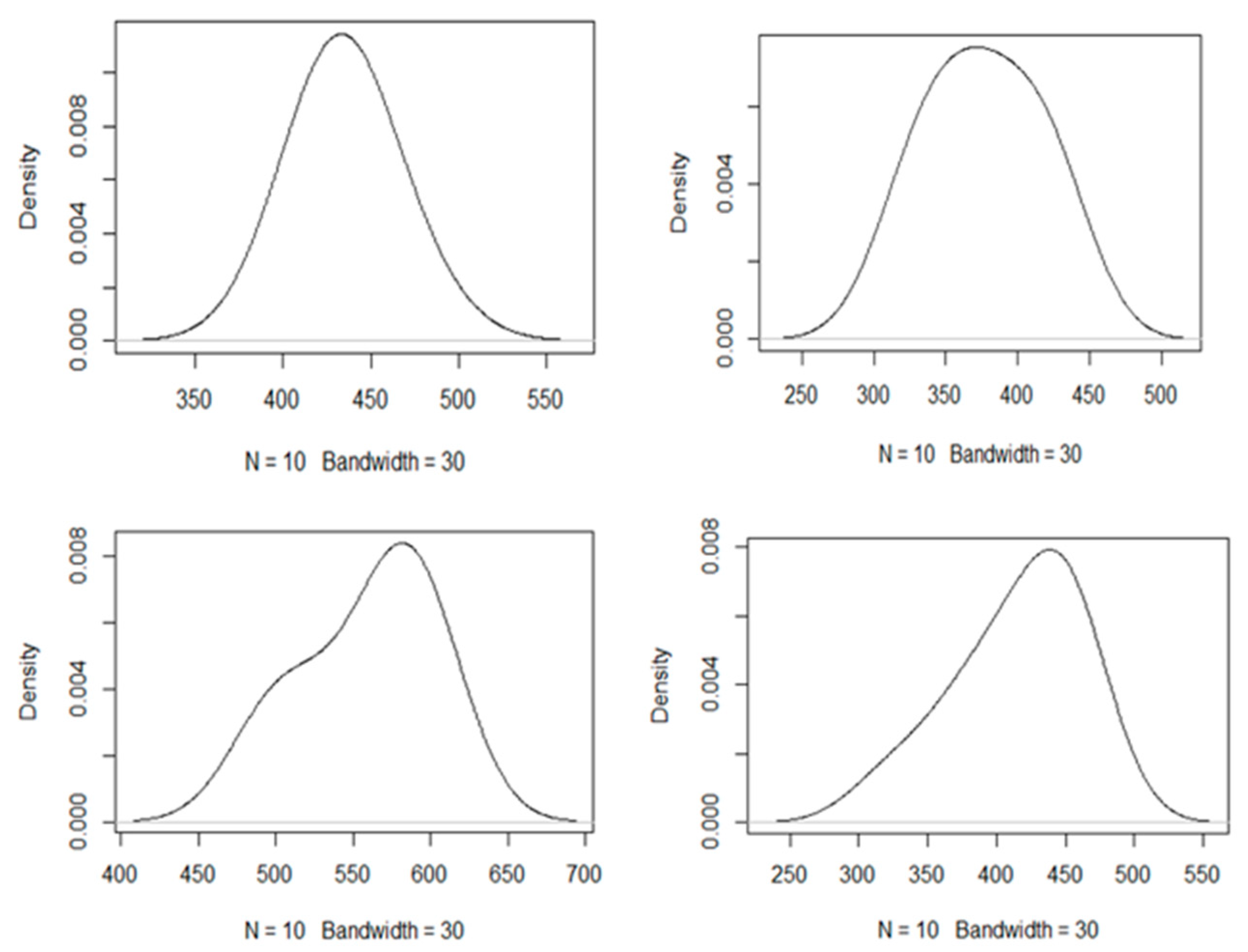{kind=link}
| Student | Domains | Mean | SD | Variation Coefficient |
|---|---|---|---|---|
| 1635 | MATHS | 497.14 | 41.98 | 0.08 |
| READING | 511.04 | 45.79 | 0.09 | |
| SCIENCE | 496.84 | 23.64 | 0.05 | |
| 5102 | MATHS | 479.41 | 13.48 | 0.03 |
| READING | 504.24 | 10.68 | 0.02 | |
| SCIENCE | 526.04 | 17.65 | 0.03 |
| MATH | READ | SCIE | ||||
|---|---|---|---|---|---|---|
| α | MATHL | MATHU | READL | READU | SCIEL | SCIEU |
| 0.7 | 445.1619 | 533.7739 | 459.1364 | 547.8178 | 474.0604 | 514.9951 |
| 0.8 | 453.0232 | 520.3045 | 468.1629 | 537.2065 | 478.1630 | 510.2898 |
| 0.9 | 462.4251 | 507.2320 | 478.7103 | 525.5529 | 482.8929 | 504.7852 |
| 1 | 483.6888 | 483.6888 | 501.9167 | 501.9167 | 493.4934 | 493.4934 |
| Variable | Mean | SD | Min | Max | ||
|---|---|---|---|---|---|---|
| Input | ESCS (Crisp) | 4.06 | 1.18 | 0.15 | 7.59 | |
| Outputs | MATH (Fuzzy) | PV1MATH | 490.56 | 82.97 | 182.21 | 763.90 |
| PV2MATH | 490.30 | 82.91 | 188.22 | 743.36 | ||
| PV3MATH | 491.45 | 83.53 | 202.83 | 822.88 | ||
| PV4MATH | 490.00 | 83.04 | 120.56 | 793.86 | ||
| PV5MATH | 490.05 | 82.97 | 192.22 | 800.69 | ||
| PV6MATH | 489.15 | 82.57 | 145.55 | 766.85 | ||
| PV7MATH | 491.03 | 85.34 | 181.32 | 796.75 | ||
| PV8MATH | 490.78 | 83.51 | 188.53 | 755.75 | ||
| PV9MATH | 492.13 | 83.50 | 189.36 | 770.91 | ||
| PV10MATH | 491.21 | 83.86 | 163.28 | 797.26 | ||
| READ (Fuzzy) | PV1READ | 499.63 | 85.55 | 161.77 | 779.97 | |
| PV2READ | 498.72 | 85.83 | 190.47 | 757.95 | ||
| PV3READ | 500.65 | 86.00 | 174.56 | 789.86 | ||
| PV4READ | 498.52 | 85.83 | 162.16 | 746.98 | ||
| PV5READ | 500.42 | 86.98 | 158.96 | 758.82 | ||
| PV6READ | 500.86 | 86.70 | 164.17 | 734.15 | ||
| PV7READ | 499.96 | 86.75 | 118.88 | 752.60 | ||
| PV8READ | 501.32 | 85.36 | 192.69 | 767.53 | ||
| PV9READ | 499.77 | 84.13 | 175.96 | 755.31 | ||
| PV10READ | 499.89 | 86.66 | 163.25 | 767.98 | ||
| SCIE (Fuzzy) | PV1SCIE | 497.14 | 86.47 | 210.70 | 754.33 | |
| PV2SCIE | 497.53 | 86.81 | 190.18 | 763.32 | ||
| PV3SCIE | 497.60 | 85.94 | 186.66 | 805.02 | ||
| PV4SCIE | 497.23 | 87.48 | 147.04 | 789.23 | ||
| PV5SCIE | 497.27 | 87.13 | 191.37 | 760.99 | ||
| PV6SCIE | 497.50 | 86.80 | 187.20 | 745.63 | ||
| PV7SCIE | 497.07 | 86.78 | 194.79 | 752.90 | ||
| PV8SCIE | 497.70 | 87.01 | 222.69 | 763.39 | ||
| PV9SCIE | 497.37 | 86.53 | 214.96 | 755.82 | ||
| PV10SCIE | 496.99 | 86.73 | 195.06 | 758.77 | ||
| MIN | Q1 | Median | Mean | Q3 | MAX | |||
|---|---|---|---|---|---|---|---|---|
| Model A | Score | 1 | 1.22 | 1.34 | 1.38 | 1.49 | 2.78 | |
| Model B | PV1 | 1 | 1.27 | 1.39 | 1.43 | 1.55 | 3.37 | |
| PV2 | 1 | 1.26 | 1.38 | 1.42 | 1.54 | 3.16 | ||
| PV3 | 1 | 1.29 | 1.41 | 1.45 | 1.57 | 2.92 | ||
| PV4 | 1 | 1.27 | 1.39 | 1.44 | 1.55 | 4.33 | ||
| PV5 | 1 | 1.27 | 1.38 | 1.42 | 1.55 | 2.78 | ||
| PV6 | 1 | 1.25 | 1.37 | 1.42 | 1.54 | 3.26 | ||
| PV7 | 1 | 1.24 | 1.36 | 1.40 | 1.52 | 3.39 | ||
| PV8 | 1 | 1.26 | 1.38 | 1.42 | 1.54 | 2.84 | ||
| PV9 | 1 | 1.26 | 1.37 | 1.41 | 1.53 | 2.68 | ||
| PV10 | 1 | 1.27 | 1.39 | 1.43 | 1.55 | 2.98 | ||
| Model C FDEA (different α-cuts) | 0.7 | EL | 1 | 1.10 | 1.20 | 1.23 | 1.33 | 2.18 |
| EU | 1 | 1.36 | 1.49 | 1.55 | 1.68 | 3.44 | ||
| 0.8 | EL | 1 | 1.13 | 1.23 | 1.26 | 1.36 | 2.27 | |
| EU | 1 | 1.33 | 1.46 | 1.51 | 1.64 | 3.27 | ||
| 0.9 | EL | 1 | 1.16 | 1.27 | 1.30 | 1.40 | 2.40 | |
| EU | 1 | 1.31 | 1.43 | 1.48 | 1.60 | 3.08 | ||
| 1 | EL | 1 | 1.24 | 1.35 | 1.40 | 1.51 | 2.72 | |
| EU | 1 | 1.24 | 1.35 | 1.40 | 1.51 | 2.72 | ||
| Ij * | 1 | 1.07 | 1.10 | 1.11 | 1.13 | 1.65 | ||
| Model A | Model B | Model C | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PV1 | PV2 | PV3 | PV4 | PV5 | PV6 | PV7 | PV8 | PV9 | PV10 | FDEA (α = 1) | Ij * | |||
| Model A | 1.000 | |||||||||||||
| Model B | PV1 | 0.931 | 1.000 | |||||||||||
| PV2 | 0.924 | 0.854 | 1.000 | |||||||||||
| PV3 | 0.925 | 0.856 | 0.839 | 1.000 | ||||||||||
| PV4 | 0.931 | 0.858 | 0.859 | 0.848 | 1.000 | |||||||||
| PV5 | 0.932 | 0.861 | 0.853 | 0.858 | 0.859 | 1.000 | ||||||||
| PV6 | 0.933 | 0.860 | 0.858 | 0.850 | 0.862 | 0.857 | 1.000 | |||||||
| PV7 | 0.938 | 0.865 | 0.857 | 0.856 | 0.869 | 0.869 | 0.869 | 1.000 | ||||||
| PV8 | 0.925 | 0.852 | 0.859 | 0.835 | 0.854 | 0.852 | 0.857 | 0.863 | 1.000 | |||||
| PV9 | 0.934 | 0.865 | 0.856 | 0.856 | 0.865 | 0.862 | 0.865 | 0.871 | 0.860 | 1.000 | ||||
| PV10 | 0.933 | 0.867 | 0.851 | 0.862 | 0.856 | 0.855 | 0.860 | 0.865 | 0.856 | 0.864 | 1.000 | |||
| Model C | FDEA (α = 1) | 0.991 | 0.926 | 0.918 | 0.920 | 0.925 | 0.926 | 0.923 | 0.931 | 0.918 | 0.929 | 0.926 | 1.000 | |
| Ij * | 0.983 | 0.921 | 0.917 | 0.912 | 0.922 | 0.916 | 0.923 | 0.927 | 0.911 | 0.924 | 0.919 | 0.979 | 1.000 | |
| SD | Model A | Model B | Model C (FDEA) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Student | MATH | READ | SCIE | Score | PV1 | PV2 | PV3 | PV4 | PV5 | PV6 | PV7 | PV8 | PV9 | PV10 | α = 1 | Ij * |
| 185 | 38.37 | 77.36 | 46.35 | 2.20 | 1.92 | 2.40 | 2.24 | 2.18 | 1.91 | 2.93 | 1.69 | 2.42 | 2.10 | 2.60 | 2.24 | 1.36 |
| 557 | 32.81 | 58.84 | 31.50 | 1.97 | 1.72 | 2.16 | 1.99 | 1.82 | 1.81 | 2.34 | 2.10 | 1.88 | 1.93 | 1.81 | 1.96 | 1.26 |
| 583 | 46.70 | 43.38 | 55.29 | 2.00 | 1.75 | 2.23 | 1.94 | 2.38 | 2.05 | 2.64 | 2.08 | 2.02 | 2.37 | 1.95 | 2.05 | 1.32 |
| 906 | 51.18 | 32.09 | 41.62 | 2.11 | 2.24 | 1.91 | 1.95 | 2.44 | 2.14 | 2.48 | 2.47 | 2.14 | 2.11 | 2.44 | 2.22 | 1.36 |
| 958 | 46.23 | 57.57 | 37.43 | 2.28 | 2.76 | 1.91 | 2.19 | 2.13 | 1.95 | 2.41 | 2.41 | 2.64 | 2.44 | 2.13 | 2.38 | 1.45 |
| 1219 | 40.72 | 45.78 | 32.16 | 1.92 | 2.04 | 2.06 | 1.80 | 2.26 | 1.63 | 2.27 | 2.07 | 2.06 | 2.27 | 1.93 | 2.08 | 1.27 |
| 1226 | 60.37 | 48.15 | 53.14 | 2.78 | 3.37 | 2.47 | 2.92 | 4.33 | 2.78 | 3.02 | 3.39 | 2.23 | 2.37 | 2.54 | 2.72 | 1.65 |
| 2252 | 35.56 | 56.73 | 46.84 | 1.53 | 1.58 | 1.47 | 1.70 | 1.62 | 1.41 | 1.63 | 1.60 | 1.73 | 1.80 | 1.70 | 1.60 | 1.16 |
| 2900 | 36.67 | 60.53 | 33.98 | 1.63 | 1.60 | 1.90 | 1.53 | 1.72 | 1.79 | 1.64 | 1.79 | 1.76 | 1.88 | 1.54 | 1.81 | 1.20 |
| 2925 | 42.93 | 65.98 | 33.59 | 2.05 | 2.05 | 2.46 | 1.63 | 2.48 | 1.75 | 1.93 | 1.96 | 2.00 | 1.92 | 1.96 | 1.99 | 1.30 |
| 3258 | 55.95 | 37.06 | 40.64 | 2.12 | 2.71 | 2.02 | 2.05 | 1.83 | 1.69 | 1.95 | 2.58 | 1.89 | 2.15 | 2.36 | 2.04 | 1.38 |
| 3316 | 47.05 | 63.21 | 31.78 | 1.86 | 1.76 | 2.08 | 1.67 | 1.74 | 1.68 | 2.17 | 1.77 | 2.23 | 1.92 | 1.90 | 1.78 | 1.27 |
| 3381 | 48.36 | 55.56 | 47.17 | 1.94 | 1.68 | 2.61 | 1.83 | 1.78 | 1.92 | 2.00 | 2.32 | 1.99 | 2.06 | 2.13 | 1.93 | 1.30 |
| 3542 | 56.59 | 34.18 | 30.17 | 2.25 | 2.53 | 2.24 | 2.32 | 1.97 | 2.73 | 2.41 | 2.36 | 2.20 | 2.11 | 2.19 | 2.34 | 1.37 |
| 4010 | 53.58 | 25.39 | 31.14 | 2.02 | 1.62 | 2.38 | 2.07 | 1.90 | 2.05 | 2.37 | 1.86 | 1.94 | 2.20 | 1.82 | 2.04 | 1.29 |
| 4170 | 24.73 | 54.92 | 43.73 | 2.26 | 2.40 | 2.46 | 2.25 | 2.42 | 2.45 | 2.07 | 2.44 | 2.57 | 2.44 | 1.76 | 2.41 | 1.41 |
| 4351 | 33.06 | 44.46 | 41.12 | 2.04 | 2.15 | 2.18 | 2.27 | 2.34 | 2.28 | 2.13 | 1.94 | 1.75 | 2.49 | 2.10 | 2.10 | 1.30 |
| 4694 | 64.17 | 44.90 | 23.01 | 1.99 | 2.04 | 2.24 | 1.87 | 2.30 | 1.67 | 2.12 | 1.61 | 2.30 | 1.89 | 2.11 | 2.06 | 1.28 |
| 4888 | 22.12 | 61.87 | 41.77 | 1.96 | 1.92 | 1.92 | 2.18 | 2.01 | 1.86 | 1.88 | 2.08 | 1.91 | 2.24 | 2.17 | 1.98 | 1.25 |
| 5212 | 49.70 | 29.40 | 38.51 | 1.77 | 1.65 | 2.12 | 1.72 | 1.97 | 1.77 | 2.00 | 1.95 | 1.76 | 1.90 | 1.65 | 1.80 | 1.21 |
| 5963 | 34.25 | 63.22 | 34.64 | 2.26 | 2.52 | 1.98 | 2.48 | 2.37 | 2.19 | 2.50 | 2.09 | 1.99 | 1.96 | 2.06 | 2.12 | 1.35 |
| 6486 | 62.03 | 57.37 | 53.83 | 1.72 | 1.76 | 3.16 | 1.79 | 1.62 | 1.64 | 1.85 | 1.87 | 1.85 | 1.47 | 2.03 | 1.73 | 1.27 |
| 6489 | 29.86 | 50.01 | 33.10 | 1.77 | 2.04 | 1.70 | 1.86 | 1.99 | 2.11 | 1.90 | 1.64 | 1.97 | 1.74 | 1.83 | 1.89 | 1.22 |
| Mod. A | Mod. B | Mod. C—FDEA (Different α-Cuts) | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.7 | 0.8 | 0.9 | 1 | |||||||||||||||||
| Student | Score | PV1 | PV2 | PV3 | PV4 | PV5 | PV6 | PV7 | PV8 | PV9 | PV10 | EL | EU | EL | EU | EL | EU | EL | EU | Ij * |
| 502 | 1.00 | 1.00 | 1.00 | 1.03 | 1.00 | 1.01 | 1.02 | 1.00 | 1.00 | 1.00 | 1.00 | 1 | 1.05 | 1 | 1.03 | 1 | 1.01 | 1.00 | 1.00 | 1.01 |
| 613 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1 | 1.00 | 1 | 1.00 | 1 | 1.00 | 1.00 | 1.00 | 1.00 |
| 952 | 1.00 | 1.08 | 1.04 | 1.09 | 1.05 | 1.00 | 1.05 | 1.00 | 1.03 | 1.09 | 1.07 | 1 | 1.12 | 1 | 1.10 | 1 | 1.08 | 1.04 | 1.04 | 1.03 |
| 1098 | 1.00 | 1.00 | 1.03 | 1.00 | 1.00 | 1.07 | 1.01 | 1.04 | 1.06 | 1.04 | 1.01 | 1 | 1.11 | 1 | 1.07 | 1 | 1.05 | 1.02 | 1.02 | 1.02 |
| 1795 | 1.00 | 1.02 | 1.08 | 1.00 | 1.00 | 1.00 | 1.00 | 1.09 | 1.11 | 1.00 | 1.01 | 1 | 1.11 | 1 | 1.08 | 1 | 1.05 | 1.00 | 1.00 | 1.03 |
| 2062 | 1.00 | 1.00 | 1.11 | 1.01 | 1.10 | 1.00 | 1.02 | 1.04 | 1.02 | 1.14 | 1.09 | 1 | 1.12 | 1 | 1.10 | 1 | 1.08 | 1.01 | 1.01 | 1.03 |
| 2853 | 1.00 | 1.00 | 1.03 | 1.00 | 1.00 | 1.00 | 1.18 | 1.00 | 1.19 | 1.10 | 1.07 | 1 | 1.10 | 1 | 1.07 | 1 | 1.03 | 1.00 | 1.00 | 1.04 |
| 2863 | 1.00 | 1.00 | 1.05 | 1.08 | 1.06 | 1.02 | 1.00 | 1.00 | 1.00 | 1.04 | 1.01 | 1 | 1.04 | 1 | 1.02 | 1 | 1.00 | 1.00 | 1.00 | 1.01 |
| 2907 | 1.00 | 1.02 | 1.12 | 1.10 | 1.15 | 1.06 | 1.02 | 1.00 | 1.13 | 1.00 | 1.00 | 1 | 1.16 | 1 | 1.13 | 1 | 1.10 | 1.02 | 1.02 | 1.03 |
| 3312 | 1.00 | 1.00 | 1.00 | 1.00 | 1.02 | 1.00 | 1.00 | 1.00 | 1.04 | 1.00 | 1.00 | 1 | 1.06 | 1 | 1.05 | 1 | 1.03 | 1.00 | 1.00 | 1.02 |
| 4274 | 1.00 | 1.02 | 1.02 | 1.06 | 1.02 | 1.13 | 1.03 | 1.04 | 1.00 | 1.00 | 1.13 | 1 | 1.08 | 1 | 1.06 | 1 | 1.03 | 1.00 | 1.00 | 1.03 |
| 5874 | 1.00 | 1.01 | 1.03 | 1.11 | 1.00 | 1.00 | 1.09 | 1.00 | 1.05 | 1.04 | 1.10 | 1 | 1.12 | 1 | 1.09 | 1 | 1.05 | 1.00 | 1.00 | 1.03 |
| 6126 | 1.00 | 1.08 | 1.00 | 1.00 | 1.01 | 1.01 | 1.04 | 1.03 | 1.05 | 1.00 | 1.10 | 1 | 1.11 | 1 | 1.09 | 1 | 1.08 | 1.02 | 1.02 | 1.02 |
| 6467 | 1.00 | 1.00 | 1.03 | 1.00 | 1.13 | 1.03 | 1.01 | 1.00 | 1.07 | 1.00 | 1.00 | 1 | 1.06 | 1 | 1.05 | 1 | 1.01 | 1.00 | 1.00 | 1.02 |
| 6654 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.05 | 1.00 | 1.03 | 1.00 | 1.00 | 1 | 1.00 | 1 | 1.00 | 1 | 1.00 | 1.00 | 1.00 | 1.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aparicio, J.; Cordero, J.M.; Ortiz, L. Efficiency Analysis with Educational Data: How to Deal with Plausible Values from International Large-Scale Assessments. Mathematics 2021, 9, 1579. https://doi.org/10.3390/math9131579
Aparicio J, Cordero JM, Ortiz L. Efficiency Analysis with Educational Data: How to Deal with Plausible Values from International Large-Scale Assessments. Mathematics. 2021; 9(13):1579. https://doi.org/10.3390/math9131579
Chicago/Turabian StyleAparicio, Juan, Jose M. Cordero, and Lidia Ortiz. 2021. "Efficiency Analysis with Educational Data: How to Deal with Plausible Values from International Large-Scale Assessments" Mathematics 9, no. 13: 1579. https://doi.org/10.3390/math9131579
APA StyleAparicio, J., Cordero, J. M., & Ortiz, L. (2021). Efficiency Analysis with Educational Data: How to Deal with Plausible Values from International Large-Scale Assessments. Mathematics, 9(13), 1579. https://doi.org/10.3390/math9131579