
A New Hybrid Three-Term Conjugate Gradient Algorithm for Large-Scale Unconstrained Problems


Abstract
1. Introduction
2. Motivation and Algorithm
2.1. Algorithm for Uniformly Convex Functions
| Algorithm 1: New hybrid three-term conjugate gradient method (HTTCG). |
|
2.2. Convergence for Uniformly Convex Functions
3. Convergence for General Nonlinear Functions
| Algorithm 2: Hybrid three-term CG method using modified secant condition (HTTCGSC). |
|
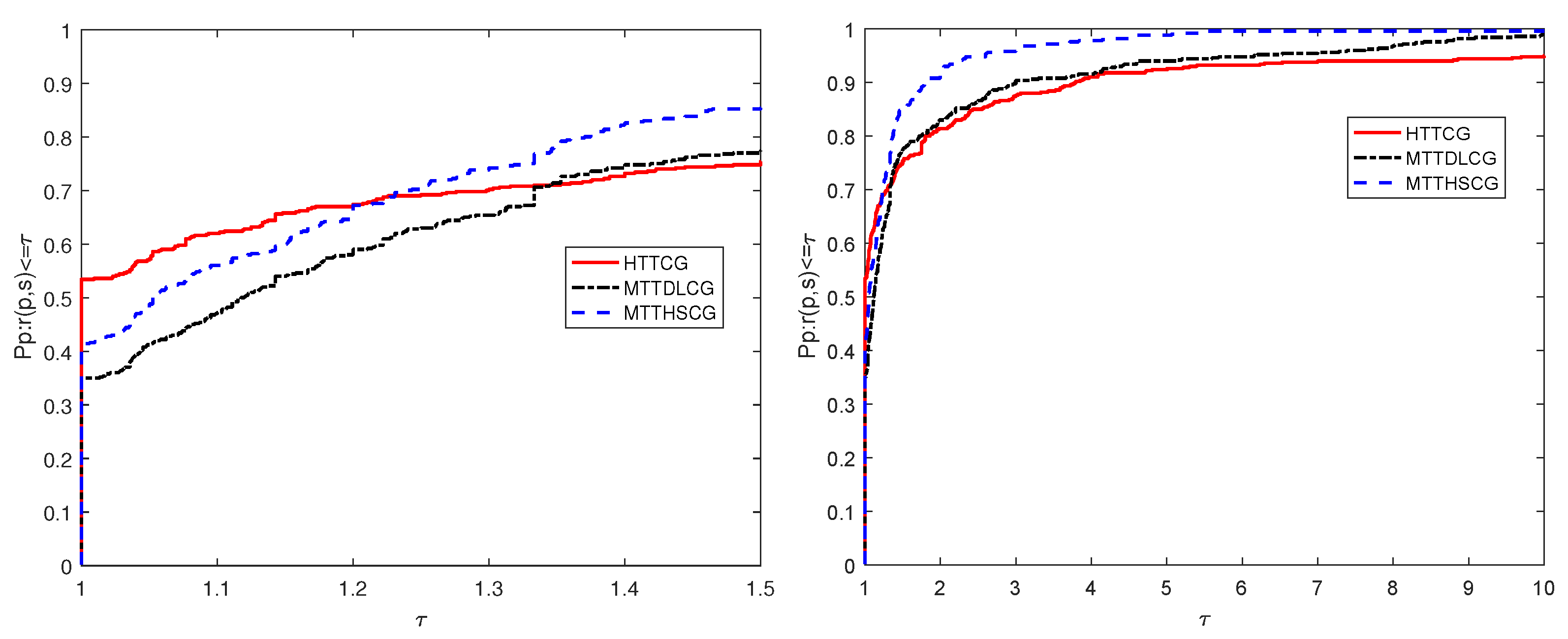
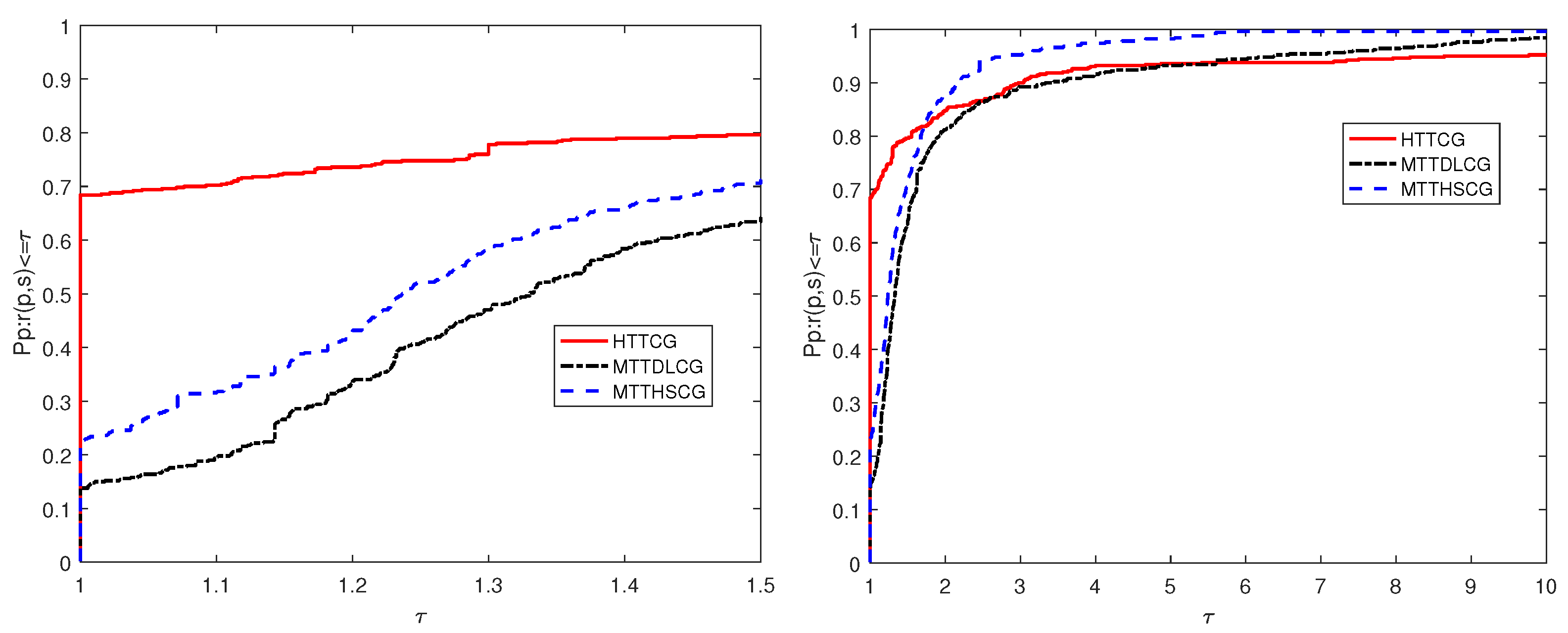
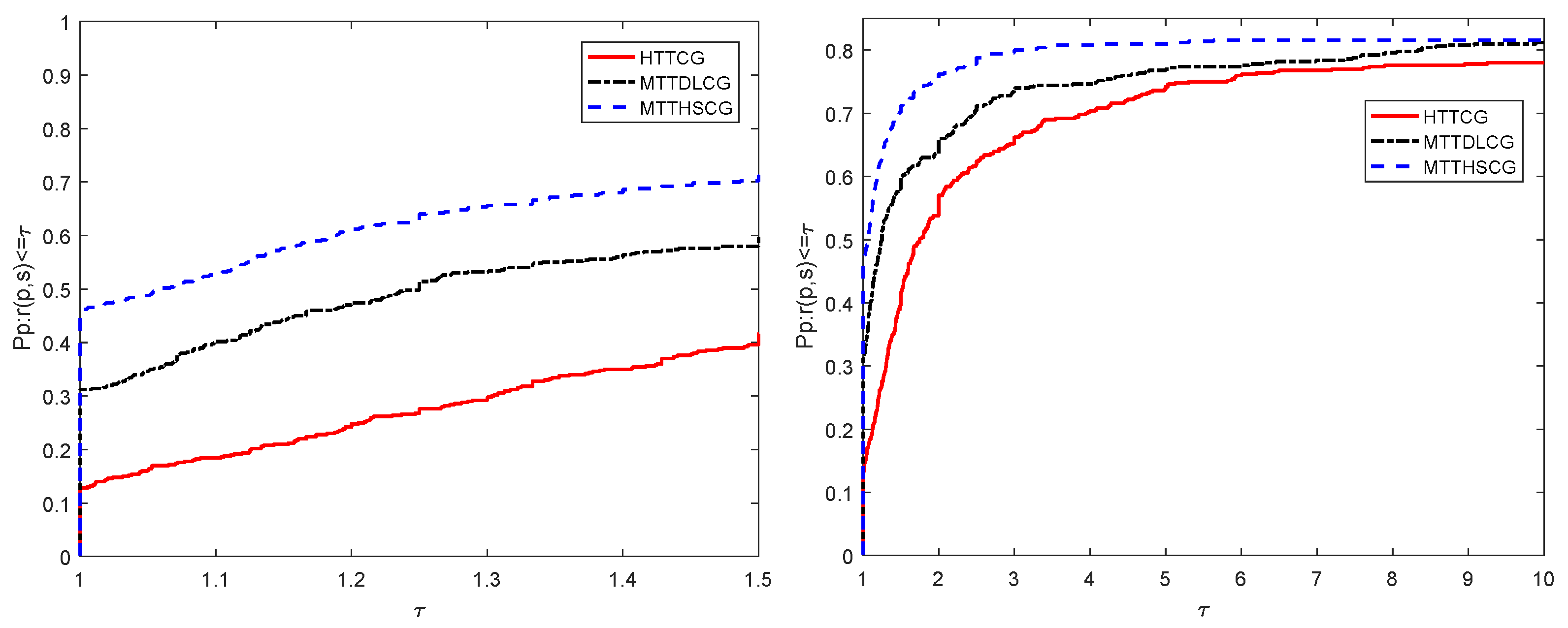
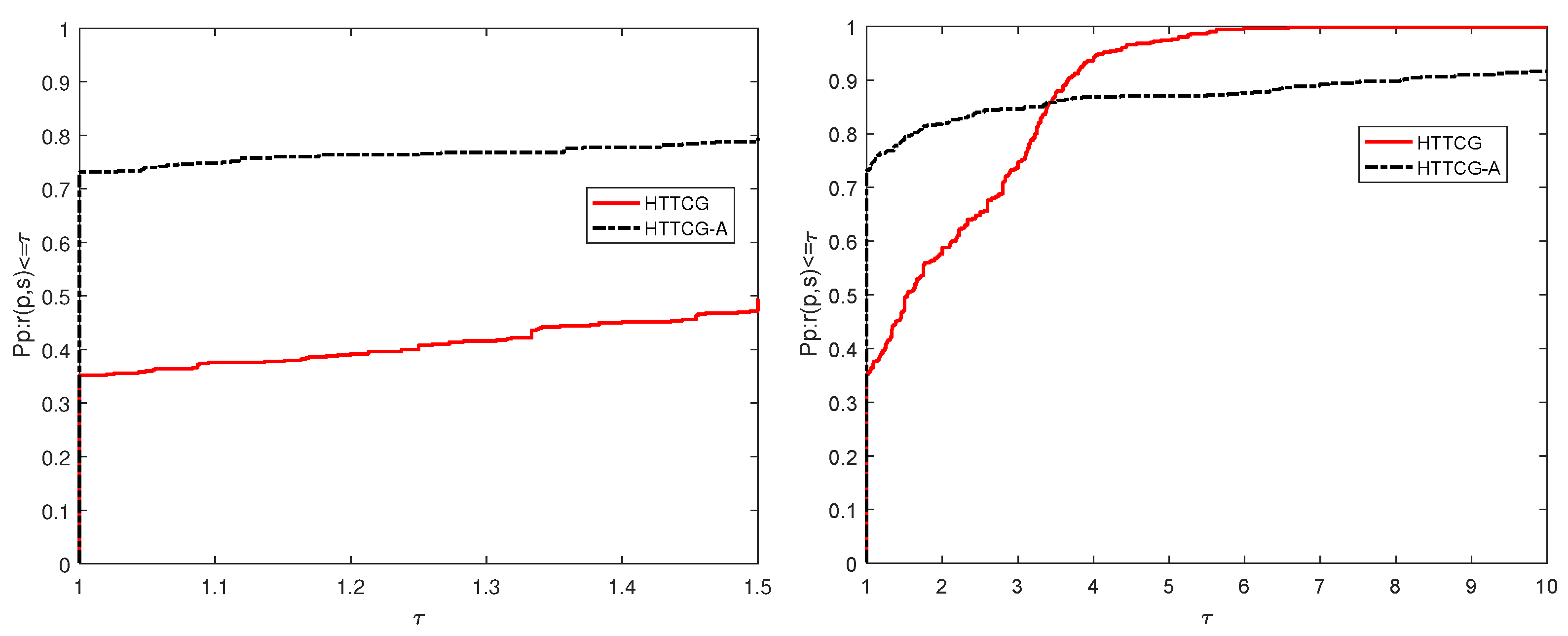
4. Numerical Results
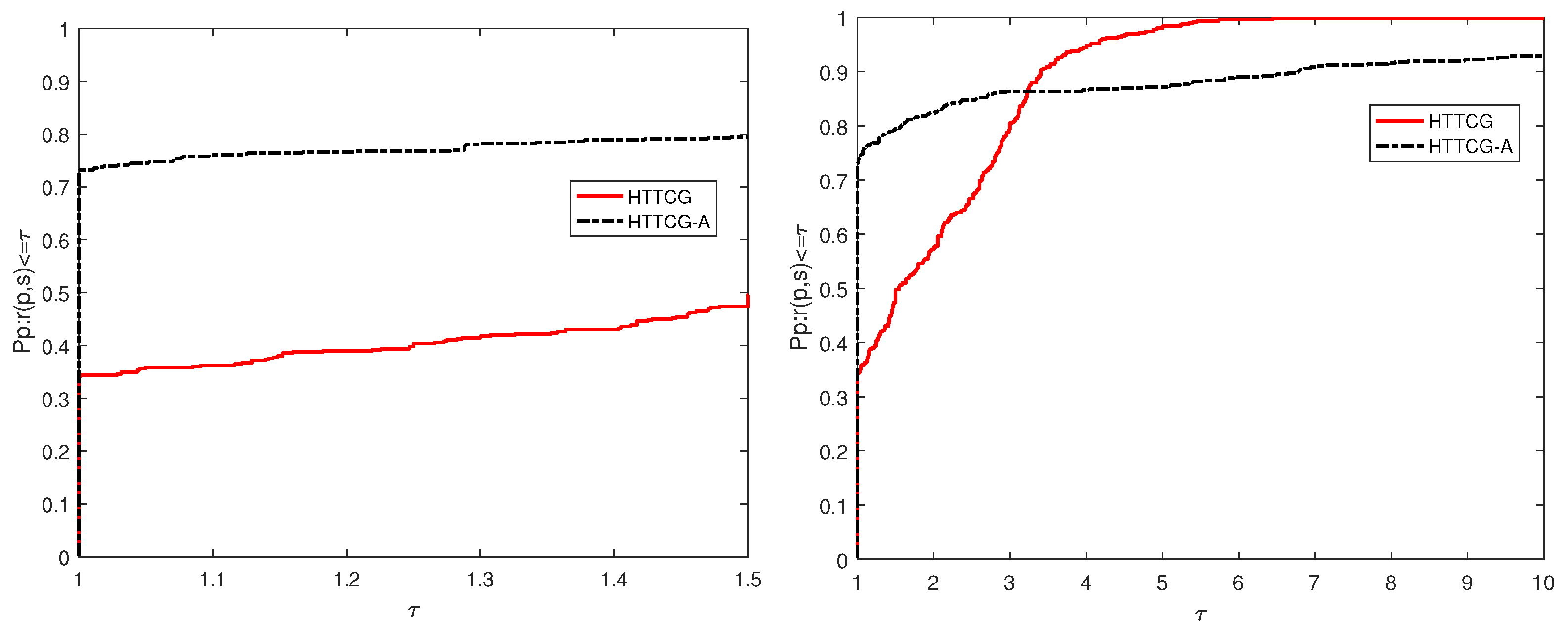
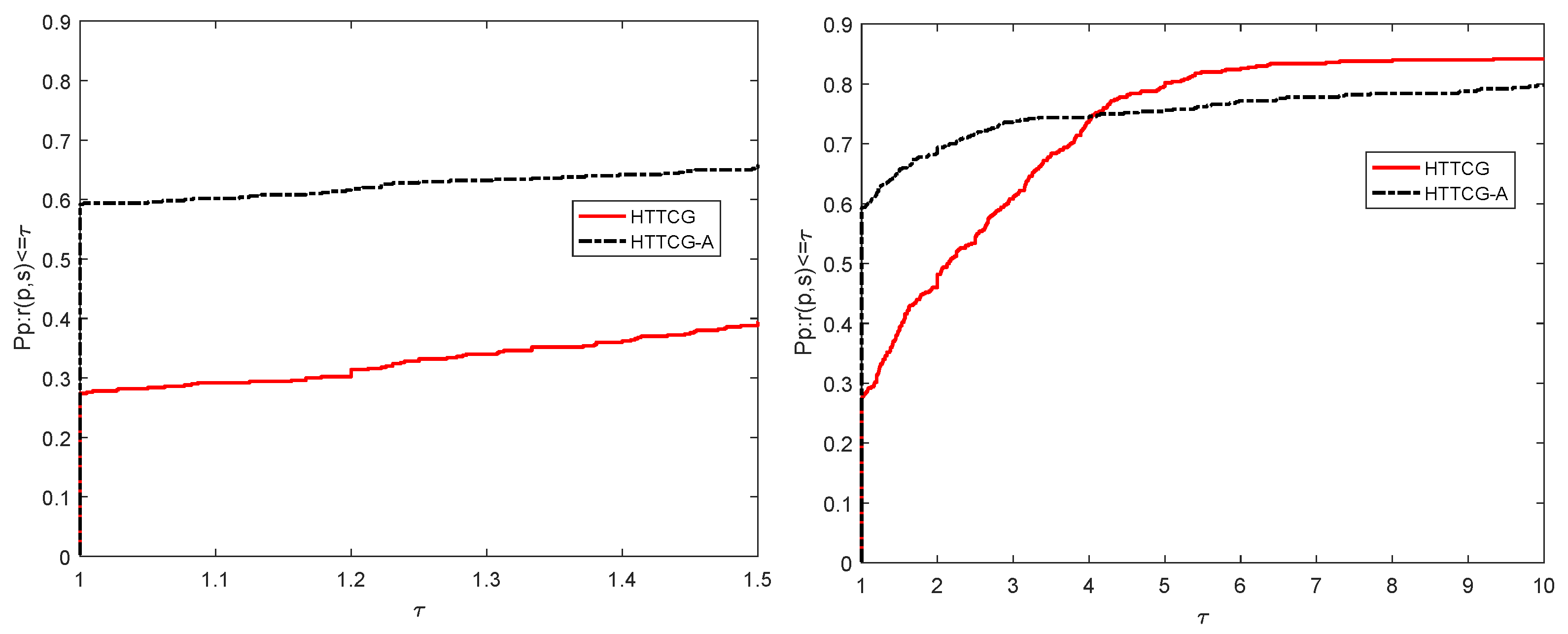
4.1. Numerical Performance of Algorithm 2
4.2. Accelerated Strategy for Algorithm 2
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fan, J.; Zeng, J. A Levenberg–Marquardt algorithm with correction for singular system of nonlinear equations. Appl. Math. Comput. 2013, 219, 9438–9446. [Google Scholar] [CrossRef]
- Yerina, M.; Izmailov, A. The Gauss–Newton method for finding singular solutions to systems of nonlinear equations. Comp. Math. Math. Phys. 2007, 47, 748–759. [Google Scholar] [CrossRef]
- Yuan, G.; Wei, Z.; Wang, Z. Gradient trust region algorithm with limited memory BFGS update for nonsmooth convex minimization. Comput. Optim. Appl. 2013, 54, 45–64. [Google Scholar] [CrossRef]
- Yuan, G.; Wei, Z.; Lu, X. Global convergence of BFGS and PRP methods under a modified weak Wolfe–Powell line search. Appl. Math. Model. 2017, 47, 811–825. [Google Scholar] [CrossRef]
- Yuan, G.; Lu, J.; Wang, Z. The PRP conjugate gradient algorithm with a modified WWP line search and its application in the image restoration problems. Appl. Numer. Math. 2020, 152, 1–11. [Google Scholar] [CrossRef]
- Dai, Y.; Han, J.; Liu, G.; Sun, D.; Yin, H.; Yuan, Y. Convergence properties of nonlinear conjugate gradient methods. SIAM J. Optim. 2000, 10, 345–358. [Google Scholar] [CrossRef]
- Yuan, G.; Wang, X.; Sheng, Z. Family weak conjugate gradient algorithms and their convergence analysis for nonconvex functions. Numer. Algorithms 2020, 84, 935–956. [Google Scholar] [CrossRef]
- Hager, W.; Zhang, H. A survey of nonlinear conjugate gradient methods. Pac. J. Optim. 2006, 2, 35–58. [Google Scholar]
- Andrei, N. Numerical comparison of conjugate gradient algorithms for unconstrained optimization. Stud. Inform. Control. 2007, 16, 333–352. [Google Scholar]
- Li, X.; Wang, X.; Sheng, Z.; Duan, X. A modified conjugate gradient algorithm with backtracking line search technique for large-scale nonlinear equations. Int. J. Comput. Math. 2018, 95, 382–395. [Google Scholar] [CrossRef]
- Wang, X.; Hu, W.; Yuan, G. A Modified Wei-Yao-Liu Conjugate Gradient Algorithm for Two Type Minimization Optimization Models; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Yuan, G.; Meng, Z.; Li, Y. A modified Hestenes and Stiefel conjugate gradient algorithm for large-scale nonsmooth minimizations and nonlinear equations. J. Optim. Theory Appl. 2016, 168, 129–152. [Google Scholar] [CrossRef]
- Cao, J.; Wu, J. A conjugate gradient algorithm and its applications in image restoration. Appl. Numer. Math. 2020, 152, 243–252. [Google Scholar] [CrossRef]
- Møller, F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar]
- Zhou, Y.; Wu, Y.; Li, X. A New Hybrid PRPFR Conjugate Gradient Method for Solving Nonlinear Monotone Equations and Image Restoration Problems. Math. Probl. Eng. 2020, 2020, 1–13. [Google Scholar] [CrossRef]
- Hestenes, R.; Stiefel, L. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 2, 149–154. [Google Scholar] [CrossRef]
- Dai, Y.; Liao, L. New conjugacy conditions and related nonlinear conjugate gradient methods. Appl. Math. Opt. 2001, 43, 87–101. [Google Scholar] [CrossRef]
- Polak, E. The conjugate gradient method in extreme problems. USSR Comput. Math. Math. Phys. 1969, 9, 94–112. [Google Scholar] [CrossRef]
- Polak, E.; Ribière, G. Note sur la convergence de directions conjugees. Rev. Fr. Informat Rech. Opertionelle 1969, 16, 35–43. [Google Scholar]
- Zhang, K.; Liu, H.; Liu, Z. A new Dai-Liao conjugate gradient method with optimal parameter choice. Numer. Funct. Anal. Optim. 2019, 40, 194–215. [Google Scholar] [CrossRef]
- Andrei, N. A Dai-Liao conjugate gradient algorithm with clustering of eigenvalues. Numer. Algorithms 2018, 77, 1273–1282. [Google Scholar] [CrossRef]
- Babaie-kafaki, S.; Ghanbari, R. The Dai-Liao nonlinear conjugate gradient method with optimal parameter choices. Eur. J. Oper. Res. 2014, 234, 625–630. [Google Scholar] [CrossRef]
- Zheng, Y.; Zheng, B. Two new Dai-Liao-type conjugate gradient methods for unconstrained optimization problems. J. Optim. Theory Appl. 2017, 175, 502–509. [Google Scholar] [CrossRef]
- Peyghami, M.; Ahmadzadeh, H.; Fazli, A. A new class of efficient and globally convergent conjugate gradient methods in the Dai-Liao family. Optim. Method. Softw. 2015, 30, 843–863. [Google Scholar] [CrossRef]
- Yuan, G.; Wang, X.; Sheng, Z. The projection technique for two open problems of unconstrained optimization problems. J. Optim. Theory Appl. 2020, 186, 590–619. [Google Scholar] [CrossRef]
- Narushima, Y.; Yabe, H.; Ford, J. A three-term conjugate gradient method with sufficient descent property for unconstrained optimization. SIAM J. Optim. 2011, 21, 212–230. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Li, D. Some descent three-term conjugate gradient methods and their global convergence. Optim. Method. Softw. 2007, 22, 697–711. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Li, D. A descent modified Polak-Ribière-Polyak conjugate gradient method and its global convergence. IMA J. Numer. Anal. 2006, 26, 629–640. [Google Scholar] [CrossRef]
- Andrei, N. A simple three-term conjugate gradient algorithm for unconstrained optimization. J. Comput. Appl. Math. 2013, 241, 19–29. [Google Scholar] [CrossRef]
- Babaie-Kafaki, S.; Ghanbari, R. Two modified three-term conjugate gradient methods with sufficient descent property. Optim. Lett. 2014, 8, 2285–2297. [Google Scholar] [CrossRef]
- Li, D.; Fukushima, M. A modified BFGS method and its global convergence in nonconvex minimization. J. Comput. Appl. Math. 2001, 129, 15–35. [Google Scholar] [CrossRef]
- Zhang, L. A derivative-free conjugate residual method using secant condition for general large-scale nonlinear equations. Numer. Algorithms 2020, 83, 1277–1293. [Google Scholar] [CrossRef]
- Sugiki, K.; Narushima, Y.; Yabe, H. Globally convergent three-term conjugate gradient methods that use secant conditions and generate descent search directions for unconstrained optimization. J. Optim. Theory Appl. 2012, 153, 733–757. [Google Scholar] [CrossRef]
- Wei, Z.; Li, G.; Qi, L. New quasi-Newton methods for unconstrained optimization problems. Appl. Math. Comput. 2006, 175, 1156–1188. [Google Scholar] [CrossRef]
- Yuan, G.; Wei, Z. Convergence analysis of a modified BFGS method on convex minimizations. Comput. Optim. Appl. 2010, 47, 237–255. [Google Scholar] [CrossRef]
- Dai, Y.; Kou, C. A nonlinear conjugate gradient algorithm with an optimal property and an improved wolfe line search. SIAM J. Optim. 2013, 23, 296–320. [Google Scholar] [CrossRef]
- Andrei, N. An unconstrained optimization test functions collection. Adv. Model Optim. 2008, 10, 147–161. [Google Scholar]
- Dolan, E.; Moré, J. Benchmarking optimization software with performance profiles. Math. Program 2002, 91, 201–213. [Google Scholar] [CrossRef]
- Andrei, N. An acceleration of gradient descent algorithm with backtracking for unconstrained optimization. Numer. Algorithms 2006, 42, 63–73. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N0 | Problem | N0 | Problem |
|---|---|---|---|
| 1 | Extended Trigonometric Function | 26 | BDQRTIC (CUTE) |
| 2 | Extended Rosenbrock Function | 27 | ARWHEAD (CUTE) |
| 3 | Extended White and Holst Function | 28 | NONDIA (Shanno-78) (CUTE) |
| 4 | Extended Beale Function U63 (MatrixRom) | 29 | DQDRTIC (CUTE) |
| 5 | Extended Penalty Function | 30 | EG2 (CUTE) |
| 6 | Raydan 1 Function | 31 | DIXMAANA (CUTE) |
| 7 | Raydan 2 Function | 32 | DIXMAANB (CUTE) |
| 8 | Diagonal 3 Function | 33 | DIXMAANC (CUTE) |
| 9 | Generalized Tridiagonal-1 Function | 34 | DIXMAANE (CUTE) |
| 10 | Extended Tridiagonal-1 Function | 35 | Broyden Tridiagonal |
| 11 | Extended Three Exponential Terms | 36 | EDENSCH Function (CUTE) |
| 12 | Generalized Tridiagonal-2 Function | 37 | VARDIM Function (CUTE) |
| 13 | Diagonal 4 Function | 38 | DIAGONAL 6 |
| 14 | Diagonal 5 Function (MatrixRom) | 39 | DIXMAANF (CUTE) |
| 15 | Extended Himmelblau Function | 40 | DIXMAANG (CUTE) |
| 16 | Generalized PSC1 Function | 41 | DIXMAANH (CUTE) |
| 17 | Extended PSC1 Function | 42 | DIXMAANI (CUTE) |
| 18 | Extended Maratos Function | 43 | DIXMAANJ (CUTE) |
| 19 | Extended Cliff Function | 44 | DIXMAANK (CUTE) |
| 20 | Extended Wood Function | 45 | DIXMAANL (CUTE) |
| 21 | Extended Quadratic Penalty QP1 Function | 46 | DIXMAAND (CUTE) |
| 22 | Extended Quadratic Penalty QP2 Function | 47 | ENGVAL1 (CUTE) |
| 23 | A Quadratic Function QF2 | 48 | COSINE (CUTE) |
| 24 | Extended EP1 Function | 49 | Extended DENSCHNB (CUTE) |
| 25 | Extended Tridiagonal-2 Function | 50 | Extended DENSCHNF (CUTE) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Q.; Wang, X.; Pang, L.; Zhang, M.; Meng, F. A New Hybrid Three-Term Conjugate Gradient Algorithm for Large-Scale Unconstrained Problems. Mathematics 2021, 9, 1353. https://doi.org/10.3390/math9121353
Tian Q, Wang X, Pang L, Zhang M, Meng F. A New Hybrid Three-Term Conjugate Gradient Algorithm for Large-Scale Unconstrained Problems. Mathematics. 2021; 9(12):1353. https://doi.org/10.3390/math9121353
Chicago/Turabian StyleTian, Qi, Xiaoliang Wang, Liping Pang, Mingkun Zhang, and Fanyun Meng. 2021. "A New Hybrid Three-Term Conjugate Gradient Algorithm for Large-Scale Unconstrained Problems" Mathematics 9, no. 12: 1353. https://doi.org/10.3390/math9121353
APA StyleTian, Q., Wang, X., Pang, L., Zhang, M., & Meng, F. (2021). A New Hybrid Three-Term Conjugate Gradient Algorithm for Large-Scale Unconstrained Problems. Mathematics, 9(12), 1353. https://doi.org/10.3390/math9121353