1. Introduction: The Bingo Bag of Primes
This work aims to investigate two main objectives: what random means in the case of the distribution of prime numbers and the general conditions ensuring that what we know as
Prime Number Theorem and
Riemann Hypothesis also hold in the case of a generic random sequence of natural numbers. To achieve these goals, we will make use of models based on combinatorics and probability theory. Of course, this is not the first time that models are used to derive new conjectures and theorems about the prime sequence. In the mid-1930s, Cramér [
1,
2] proposed the first stochastic model of the sequence of primes as a way to formulate conjectures about their distribution. This model can be briefly summarized as follows.
Denote by
a sequence of independent random variables
, taking values
0 and
1 according to
(the probability may be arbitrarily chosen for
). Then, the random sequence of natural numbers
is a stochastic model of the sequence of primes. This means that if
is the set of all possible sequences
realizations of
S, then the prime sequence, say
, is obviously an element of
. We can therefore study the properties of the particular sequence
, through the methods of probability theory applied to the sample space
, and conjecture with Cramér that if a certain property holds in
with probability 1 (
w.p. 1 in that follows), that is for
almost all the sequences, the same property holds for the prime sequence
. Obviously, the results of these conjectures lay heavily on the assumption about the probability of the event
, which connects the model with the distribution of prime numbers as stated by the
Prime Number Theorem (
PNT)
with
being the prime-counting function. We see from (
1) that
can be interpreted as the expected density of primes around
n, or the probability that a given integer
n should be a prime.
As reported by Granville [
3] in his review article dedicated to the work of Cramér in this area, he imagined building the set of random sequences
S through a game of chance consisting of a series of repeated draws (independent trials) from an ordered sequence of urns (
) such that the
n-th urn contains
black balls and 1 white ball, starting from
forward. In this game, the event
is then realized by drawing the white ball from the urn number
n.
The heuristic method based on Cramér’s model has been playing an essential role since the mid-1930s to the present day when formulating conjectures concerning primes. The first serious difference between the prediction of the model and the actual behavior of the distribution of primes, was found in 1985 [
4]. As pointed out in [
3], this difference arises because of the assumptions made by heuristic procedures based on the probabilistic model: the hypothesis, when applying the ’Sieve of Eratosthenes’, that sieving by the different primes
are independent events and Gauss’s conjecture about the density of primes around
n.
The problem was known well before Cramér’s work. In their 1923 paper [
5], Hardy and Littlewood, while discussing some asymptotic formulas of Sylvester and Brun containing erroneous constant factors and functions of the number
(
is the Euler–Mascheroni constant), observe that “
any formula in the theory of primes, deduced from considerations of probability, is likely to be erroneous just in this way”. They explain this error arises because of the different answers to the question about the chance that a large number
n should be prime. Following
and Gauss’s conjecture, this chance is approximately
, while if we consider the chance
n should not be divisible by any prime
, assuming independent events for any prime (Hardy and Littlewood do not mention this condition, but it is implicit), this chance is asymptotically equivalent to
Hence, they conclude that any inference based on the previous formula is “
incorrect to the extent of a factor ”. More recently, new contradictions have been found, between the predictions of the model and the actual distribution of primes, that no Cramér-type model, assuming the hypothesis of independent random variables, can overcome [
6].
Cramer’s model founds its connection with the distribution of prime numbers on Gauss’s conjecture; hence, it assumes the
Prime Number Theorem as a priori hypothesis. In this work, a new model is proposed based on a class of combinatorial objects I call
First Occurrence Sequences (
FOS), reproducing the stochastic structure of the prime sequence as a result of the straightforward random structure of the model, based on a sequence of independent equally probable trials. The
Prime Number Theorem emerges, though without any a priori ad hoc assumption about the probability of events. Perhaps the best way to summarize the aim of this work is that it tries to answer the question Granville cites at the beginning of his paper [
3]:
“It is evident that the primes are randomly distributed but, unfortunately, we do not know what ‘random’ means” (the quote is of Prof. R. C. Vaughan).
Following Cramér’s method, we can describe the pinpoints of our model as a game of chance. Suppose we have an urn with balls of different colors, say black (B), and white (W), and let us consider the following sampling with replacement game: choose a ball, say B and replace it; repeat drawing until the white ball W occurs for the first time. In general, the game ends when you draw the ball with a color other than the first ball drawn. The sequences of B and W balls we get from this game are FOS of different lengths k. Some examples:
, ;
, ;
, ;
, .
Assuming each ball has the same probability of being drawn, it is easy to see the average numbers of steps we need to get both colors for the first time, or the average length of
FOS, when
, is equal to 3. If we repeat this simple game with different values of
n (number of colors) and the rule that the game ends when all colors appear in the sequence for the first time and compare the average length of
FOS of order
n (say
) with the prime number
of the same order, we would find the results reported in
Table 1 for
, and 6.
The correlation between
FOS average lengths and the sequence of primes is a general property of the model. Indeed, assuming each colored ball has the same probability of being drawn, and every sampling step with replacement is independent of each other, we can easily find
The above equation shows the close connection existing between the combinatorial objects I have called FOS and the primes. In particular, the average length of the n order FOS, obtained through the sampling with replacement game from an urn with n colored balls, is asymptotic to the expression of the n-th prime obtained as a consequence of PNT. In this sense, the n-th order FOS can be defined as the combinatorial counterpart of the n-th prime number.
The following sections are devoted to developing the theory of FOS and their analogies with the distribution of primes. Despite their simplicity, FOS may serve as a general model of random integer sequences which can be applied in different contexts, from combinatorics to physical models (I give a brief hint about this in the last section), showing the common features to all these fields, such as what is known as PNT. The method I followed in this work is to give a complete account of these combinatorial objects independently from the definition of other similar objects, starting from proper probability spaces and the general (recursive) probability relations, then to develop the full theory with particular attention to showing the connections with other research fields. A generalization is proposed in the last part of the work, starting from a continuous version of the original model.
In
Section 2, a formal definition of this kind of objects is given together with the probability spaces we need to define probability relations and probability recursive formulas. In
Section 3, the combinatorics of
FOS is completely solved, demonstrating its close connections with set partitions and Stirling numbers of the second kind. In
Section 4, the probability equations derived from the combinatorial analysis lead to new identities for Stirling numbers of the second kind and for harmonic numbers. The combinatorial model of primes based on
FOS is defined together with a discrete estimate
of the prime-counting function
, which is studied and numerically tested. We prove
PNT holds for this model while the
Riemann Hypothesis does not. In
Section 5, the model is generalized to investigate the conditions enabling both
PNT and the
Riemann Hypothesis. We find a general model of random sequences for which the
Riemann Hypothesis holds
w.p. 1 and apply this model to the problem of counting consecutive prime pairs as a function of the gap between successive primes. The theoretical results obtained from the model agree with the empirical data for large gaps and show the importance of the correlation between primes in the case of small gaps. Finally, this model is directly related to the sequence of primes, leading to new integral lower and upper bounds of the prime-counting function
. At last,
Section 6 summarizes this work’s general significance and hints at its links with other research areas, particularly with research on physical models.
3. Combinatorics of FOS
In the previous section, we have obtained the probability of
FOS through the general recursive Formula (
25) and through closed-form solutions only in a few special cases. The aim of this section is the development of a combinatorial theory of
FOS in order to investigate their connections with other topics of combinatorics, such as set partitions and Stirling numbers of the second kind (Ch. 9, [
9]), then to derive the closed-form probability functions in the next section.
The following simple equation relates the cardinality of the sets
and
defined in Definition 2 and 3
The combinatorics of objects such as sequences
is well known and treated within the more general problem of counting functions between two finite sets in enumerative combinatorics (1.9 p. 71, [
10]), with applications to set partitions, words, and random allocation (II.3 p. 106, [
11]). The problem of finding
is the same as finding the number of words (or sequences) of length
k, over an alphabet of cardinality
n, containing
i letters (or symbols). As reported in (Equation (
5), [
12]), the total number
of possible sequences can be obtained through the following sum, involving the Stirling numbers of the second kind
(see equation (1.96) p. 75 for details, [
10]). (I keep here the same symbol with two different spellings,
and
S, both to denote the set of events (sequences) and the Stirling numbers of the second kind. The meaning is always clear from the context, in any case when
denotes a set, it is always followed by a subscript. The adoption of the same symbol is justified by the close connection existing between the cardinality of the set of sequences and the Stirling numbers of the second kind.)
The above equation decomposes the total number of sequences as the sum over
i of the number of such sequences that contain exactly
i distinct symbols. The same identity, obtained through classical algebraic methods, is reported in (Equation (
29), [
13])). On the other hand, remembering Remark 6, we can also write
hence, by comparing (
28) and (
29), it follows
The same solution is found in II.6 p. 113 [
11] under the hypothesis of random allocation of symbols, which is the same as Assumption 1. From (
30) and (
27), we can finally also derive an explicit expression for the cardinality of
FOS.
In the rest of this section, we prefer to present an alternative procedure that allows us to derive the number of FOS sequences directly in order both to find new identities involving the Stirling numbers of the second kind and to show a new combinatorial meaning of these numbers, strictly related to the sequence of primes, which is the main focus of this paper.
3.1. Ordered FOS
Remembering Definition 1 and Remark 3, let us introduce a new kind of combinatorial object.
Definition 5. Letbe an ordered subset of i distinct elements from, we denote with, k-length ordered First Occurrence Sequences (oFOS) withdistinct symbols on the ordered choice,,, the eventswhereis an elementary FOS outcome havingas i-distinct ordered choice, replicating the order of the first occurrence of its distinct i symbols. The following example can help to clarify the above definition.
Example 1. Suppose,and, with,; then the eventis made up of the following elementary outcomes: Remark 8. The cardinality of oFOS events depends on parameters i and k only, not on the particular choice of symbols in the ordered set .
The following theorem establishes the relation between FOS and oFOS.
Theorem 2. The cardinality of the set of FOS
is given by (, ):where is the number of k-length oFOS
on an ordered subset of i symbols Proof. Given the ordered choice of symbols
, any finite subset of
i indices
subject to the constraints
defines a finite-dimensional cylinder set on
through the following assignments:
Therefore, the
oFOS event is equal to
and the
FOS event
As far as the cardinality of the sets from the above equation we get
Since
with
i-combinations of
n elements, and
number of permutations of
i elements, Equation (
31) follows. □
3.2. Counting Ordered FOS
The problem of finding the number of
FOS is thus reduced to that of finding the numbers
. When
,
we immediately get
when
, it is
Indeed, for
, there is only one
oFOS, whatever the value of
. Note that (
33) is a particular case of the general property
The calculations are more complex when .
Example 3. ,, through elementary enumerative combinatorics we find Example 4. ,, through elementary enumerative combinatorics we find I will give, in the following, some results about the calculations of numbers, starting with the next lemma that states a recursive formula.
Lemma 2. The number of k-lengthon an ordered subset, as function of the cardinality on an ordered subset, isstarting with,, given by (33). Proof. Equation (
36) follows directly from Definition 5 and Remark 8, considering that from any
j-length
oFOS on an ordered set
, one can obtain
k-length
oFOS on an ordered set
having the
i-th symbol in the last position
k of the sequence.
Note that this lemma holds independently from Assumption 1 of equally probable symbols. □
The result reported below is simply the sum of the first k terms of a geometric series and will be referred to by the next theorem.
Lemma 3. Given q real,, then Theorem 3. Letbe the number of k-length oFOS on an ordered set of i distinct elements. Then the following statements hold:with coefficientsdefined recursively asstarting with Proof. Let us proceed by induction. Equation (
37) holds for
, indeed from Lemma 2 remembering (
34) we get
and, hence, from Lemma 3
Let us now prove that if (
37) is true for
i,
, then it is true for
. Substituting (
37) in (
36) for
we get
from which, after some manipulations, one gets
The single sum
after the application of Lemma 3
and some manipulations, can be written as
Finally we can write
hence
with
given by (
38),
,
given by (
39). □
The last theorem gives us a method to calculate each coefficient of the row from the coefficients of the previous row i. The following corollary state an alternative way to calculate the last term of each row, as function of the other coefficients of the same row.
Proof. The result follows directly from (
35) and (
37):
Hence, remembering (
38) and (
39), after some manipulations, one gets (
40). □
The first rows of coefficients
are reported in
Table 2.
Theorem 3 and the subsequent corollary state a method of calculating coefficients by rows. The next proposition establishes another way to find them, proceeding by columns.
Corollary 4. Given the coefficient, head of column j, the successive coefficients in the same column can be calculated as The column head coefficients can be calculated as a function of the previous ones only, through the following formulastarting with Proof. Equation (
41) is derived simply through a recursive application of Equation (
38), from the row index
to the required row index
i.
By substituting (
41) into (
39), we obtain the second Equation (
42). □
The next theorem states a general non-recursive formula to get the coefficients directly as a function of the indices .
Theorem 4. The following equation holds for each coefficient Proof. First of all, let us prove by induction, the formula holds in the case of column head coefficients. In this case, using the notation of Corollary 4, Equation (
43) becomes
The above equation is true for
, since we know it is
. Assuming it is true for
, from (
42) we get the identity
where the term on the left-hand side of the equation is the value of
calculated through (
42), the one on the right-hand side is the value of the same coefficient given by (
44). Then, the same identity holds for the next head of column coefficient
; indeed Equation (
42) leads to the result
The proof of (
43) in the case of non-head of column coefficients follows simply from (
41) after assuming (
44). □
The identity (
45) deserves some more attention: it expresses the normalization property of the
FOS probabilities
(see forward Equation (
76) and Remark 10). After some simple manipulations, it can be written as
that appears to be “complementary” of the well-known identity (see Equation (1.13), [
14])
3.3. Ordered FOS and Stirling Numbers of the Second Kind
The solution we have found about the number of elementary sequences of the event
, presented in Definition 5 as
oFOS of length
k with
i distinct symbols on the ordered choice
, allows us to show the equivalence of
numbers and Stirling numbers of the second kind. Indeed, from Equation (
37) of Theorem 3, it follows
and remembering (
39) of the same theorem
Substituting in the above equation
and
as given by (
43) and (
44) of Theorem 4, we get
Since
we finally arrive at
The right-hand side of the previous equation is the explicit formula for the Stirling number of the second kind
(see Equation (9.21), [
9]). The equivalence can be extended to values
and
, since from Equation (
34) for
it follows
and for
from (
33)
Note that the last equation solves the “bit tricky” case of the Stirling number
(p. 258, [
15]), by calculating it instead of assuming it “by convention” (this assumption is common to all the treatments of the subject, see for example (p. 73, [
10])). We have thus proved
Theorem 5. Given, the cardinality of the oFOS setdefined in Definition 5, and the Stirling number of the second kind, the following equation holds true: Remark 9. Due to the equivalence established by the previous theorem, Equation (36) of Lemma 2 can be rewritten asthat can be obtained through the repeated application of the recursive equation of the Stirling numbers of the second kind (see Equation (9.1), [9]) When
we know it is (see Equation (
35))
and, hence, from the general Formula (
49) we get
or
which is the identity (
47) mentioned above. This identity is thus closely related to the Stirling numbers and to the general property
,
(see Equation (
4) and [
13] and references therein). Note that by substituting (
31) with
given by (
50), into Equation (
27) we obtain for
the same Equation (
30).
We know Stirling numbers of the second kind have a combinatorial meaning directly related to the problem of partitioning a set into a fixed number of subsets,
, counting the number of ways a set of
n elements can be partitioned into
m nonempty disjoint subsets (Ch. 9, p. 113, [
9], Ch. 1.9, p. 73, [
10], and see also [
15] for a complete combinatorial treatment of the Stirling numbers). The analysis performed in this section highlights an alternative combinatorial interpretation of these numbers, together with the close connection of
oFOS with set partitions, that will be shown to be strictly related to the sequence of primes in the next section.
4. First Occurrence Sequences, Set Partitions, and the Sequence of Primes
In this section, we will delve into FOS sequences as a model of the distribution of prime numbers. The simple oFOS sequences can already act as a first-level model of the prime number distribution, as we will see in the next subsection, while the complete model based on FOS will be developed at the end of this section. In order to develop the tools to build this model, we continue in the following to deepen the combinatorial implications of Theorem 5, exploring some interesting identities involving Stirling numbers of the second kind and harmonic numbers, derived through the probabilities of FOS.
4.1. Ordered FOS and the Prime Number Theorem
The equivalence (
50) stated by Theorem 5 and the combinatorial meaning associated with
S and
g numbers suggest the following analogy with the distribution of primes. Given any integer set of the type
there exists a sequence of
successive primes
such that the prime-counting function
. The set
can be viewed as an ordered choice of
integers and the set
as an
oFOS over
(remember Definition 5). Note that the integers
i between two consecutive primes,
, are multiples of the primes from
to
, hence they can be considered as repetitions of these symbols, thus confirming the
oFOS schema. In the light of this analogy, some classical results of the theory of random partitions of finite sets can be reinterpreted as a general form of the
Prime Number Theorem, which holds for all
oFOS-like sequences.
The
oFOS model of the distribution of prime numbers can be defined as follows. Let us consider the number of primes less than or equal to
k, represented by the prime-counting function
, as a random variable
with probability mass function defined by
and, hence, from Theorem 5
Equation (
53) defines a uniform probability distribution on the class
of partitions of a set of
k elements, obtained by assigning the same probability
to each partition
,
where the total number of partitions
is equal to the
k-th Bell number defined as (9.4, p. 133, [
9])
The combinatorics of
is studied in [
16,
17] (see also Ch. IX, p. 692 [
11], for a brief summary of these results) in connection with the asymptotic (
) distribution of the probability measure
(Harper points out the methods used are based on the combinatorial implications of probability theory and ascribed to W. Feller (see Ch. X, p. 256 [
18]), and V. Goncharov (see [
16] and references therein), the first applications in this field). From this approach, it follows that the random variable
with uniform probability (
53), defined as a model of
, has mathematical expectation and variance asymptotically equal to (see Ch. 4, pp. 114–115 [
19])
where
, the unique positive solution of
,
being the Lambert function [
20] defined in the domain
. Since for the function
, we know it is
as
, the above equations say the average and variance of the random variable
are asymptotic to
Equation (
55), and the related variance (
56), represents the form assumed by
PNT when considering
oFOS-like sequences with uniform probability distribution of set partitions. This is not the only admissible distribution. About this problem and the general conditions in order that a uniform distribution is obtained, through random allocation algorithms (or random urn models), see [
21] and the references therein. The following result (see Theorem 1.1, p. 115, [
19]) completes the application of the methods derived from the theory of random partitions of sets, to the
oFOS model of the prime number distribution. The probability distribution of the normalized random variable
converges to that of the standard normal distribution as
, that is:
4.2. FOS Probabilities and Some Combinatorial Identities Involving Stirling Numbers
Let us collect, in this subsection, some formulas about the probability function
, which will be referred to in the rest of this paper. Under Assumption 1, from Equation (
31) of Theorem 2 the probability of
FOS is given by
By substituting
with Equations (
37) and (
39) of Theorem 3, we get the following expressions for
,
Finally, from (
43) of Theorem 4 the explicit expression for
follows
If we set
, the above equation can be written
When
(
,
), Equation (
60) becomes (it is easy to check this equation, and (
64) below, which also applies to the case
)
which, observing that
can be written as
Equation (
61) when
(
,
), becomes
which, observing that
can be written as
Let us now derive the sequence probabilities expressed through the Stirling numbers of the second kind. Remembering the equivalence (
50), Equation (
57) can be written as
From this equation and (
27), always under the hypothesis of equally probable symbols, hence (
19), (
20), it is easy to get
The above equations, combined with the general properties of the probability functions (
11)–(
18), give rise to a series of combinatorial identities involving the Stirling numbers of the second kind. The following corollary reports the less trivial ones.
Corollary 5. The following identities hold true.
Note that identity (
68) is the same as (
28) and identities (
68), (
71) imply (
70).
I report in the following two more results about the sum of probabilities
, that clarify the probabilistic meaning of identity (
46) and the close connection between these probabilities and the Stirling numbers of the second kind.
Corollary 6. The following equations hold true Proof of Equation (73). By applying Lemma 3
hence
Since we know that
and
it is
Finally from (
75) and (
76), Equation (
73) follows. □
Proof of Equation (74). Remembering (
66) we can write
and, hence, through identity (
70), we simply get (
74). □
Remark 10. Note that Equation (76) above is the same as (45), (46). Indeed, after some manipulations, it can be written as This identity thus has a probabilistic meaning connected with the normalization property of FOS probabilities.
Remark 11. We know (Equation (26.8.42), [22]) the Stirling number of the second kind, for fixed value of n, asis asymptotic to This asymptotic behavior follows very simply from Equation (74) due to the connection established between FOS probabilities and. 4.3. Bounds of Numbers and Stirling Numbers of the Second Kind
We speak of numbers since the results are directly related to their formulation through the coefficients , as stated by Theorem 3. The results are obviously applicable to the Stirling numbers of the second kind.
Definition 6. Let us define for,andwhere the sign ofis negative if j is an even number, positive if it is an odd number. Lemma 4. The following statements hold true: Proof. Equation (
77) follows simply from the values of the coefficients given by (
44).
Equation (
39) of Theorem 3 gives
from that and (
77), Equation (
78) follows.
Considering Definition 6, from (
39) we can write
with
, hence (
79).
From Equation (
44) it is easy to prove that
hence the previous equation also implies (
80).
(
80) implies both (
81) and (
82). □
Lemma 5. Givenandof Definition 6, it is Proof. Suppose
j even, then we can write
By adding the pairs of the previous inequality, we obtain the thesis.
In the case when j is odd, we can repeat the above procedure considering the pairs for , then adding up these pairs and the last term taken with a positive sign. □
Theorem 6. Given the numbers,, the following bounds holdand, for i fixed Proof. From the Definition 6 we can write in general
and, remembering (
48),
The thesis (
83) follows from Lemma 5 and (
80), (
81) of Lemma 4.
The inequalities (
83) can be rewritten as
from which Equation (
84) follows. □
Remark 12. The closed-form (44) of coefficients allows us to rewrite (83) and (84) as When speaking of Stirling numbers of the second kind, the previous bounds become Note that (87) gives an alternative proof of the asymptotic behavior of for fixed i (see Remark 11). Remark 13. Assuming the left-hand side of the above inequality is positive both forand, that iswe get the bounds of the ratiothat forbecomesunder condition 4.4. FOS Average Length and Harmonic Numbers
As anticipated in the Introduction, calculating the average length of
FOS sequences, that is, of elementary events
,
of the countable space
, is a simple task leading to the result (
2) in the case
. This calculation is based on the following well-known results, in particular on Lemma 7, expressing the average number of trials one has to wait before obtaining the first success in a sequence of independent Bernoulli trials with
p probability of success.
Lemma 6. Given q real,, then Lemma 7. Given p real,, then Therefore, if we denote, in general, the quantity we are looking for with
, we can establish the following recursive relation
starting with
It is easy to see the above equation leads to
where
is the
n-th harmonic number
and
If we consider the set of discrete random variables
with probability mass function
then the quantity
can be also obtained as the mathematical expectation of the corresponding random variable
, hence through
From (
91) and (
90), remembering (
66), we get the following relation between harmonic numbers and Stirling numbers of the second kind.
Other combinatorial identities involving harmonic numbers and finite term series can be derived from the direct calculation of (
91) as established by the following proposition. (These identities appear to be new, such as the method of deriving them. Of course, it is not simple to establish the novelty of an identity involving harmonic numbers because of the historical interest of this subject and the great development of theory and applications. For an extensive collection of these identities, see [
23,
24,
25] and the references therein.)
Theorem 7. Assuming n and i positive integers,and, the following identity holds truewhereare the coefficients defined by Theorem 3. Proof. By substituting in (
91) the term
as given by (
58), we get
from which it follows
We can write
and remembering Lemma 6 and the sum of geometric series
In a similar way, the second term becomes
Inserting the previous formulas into (
94), we get
from which and Equations (
39), (
90), and (
93) follow. □
The following corollary is a simple application of the formulas of Theorem 4 to that of the previous theorem.
Corollary 8. For n and i positive integers,and, the following identity holds true Whenwe get for the n-th harmonic number 4.5. FOS as a Model of the Distribution of Primes
This subsection aims to analyze analogies and limits of FOS with respect to the true sequence of prime numbers. There is a correspondence between prime numbers and FOS as stated by the following remark.
Remark 14. Given any prime,, there exists an event FOS
(see Remark 7), and the whole sequence of prime numbers corresponds to the elementof the product setwe can define as FOS
universe. The model based on FOS takes then into consideration the set as the combinatorial counterpart of the n-th prime , considered as a discrete random variable assuming integer values between n and ∞. The statistics of this random variable are then used to define a “counting variable”, which is the FOS model equivalent of the prime-counting function. In order to avoid any confusion when dealing with our model, we keep the symbol to denote the “true” value of the n-th prime, and adopt the symbol for the random variable modeling it. The basic assumption of the model is the following.
Definition 7. The discrete random variablehas probability mass functionwith, defined in Equation (20). The results of the model are referred to the sequence of random variables and confronted with the analytical or numerical results we know about the true prime sequence . These results, some of which are reported in two sample tables, justify a posteriori the model’s adoption and the not completely rigorous approach we follow in deriving it.
From (
66) and (
90) respectively we get the probability
and the mean value of
Hence, given
,
k integer, the probability distribution function of
with
is simply expressed through the number of ways a set of
k elements can be partitioned into
n disjoint nonempty subsets
where the last equation follows from (
74).
Let us define the discrete random variable whose probability distribution is induced by through the following
In our combinatorial model, is associated with the value of the prime-counting function, considered as a random variable assuming integer values between 1 and k.
Theorem 8. The discrete random variablewith probability distribution (99) assumes values between 1 and k, has probability mass functionand mathematical expectation Proof. From (
98), due to the properties of
numbers, we get for
for
for
This proves the first statement.
Given
n and
m positive integers with
, from (
100) we get
From this relation, assuming
the probability mass function (
101) follows.
The mathematical expectation of
is given by
that is the same as Equation (
102) since
. □
Remark 15. The mean value of the discrete random variableis equal to The previous theorem suggests to assume
as an estimate
derived from the combinatorial model of the prime-counting function
, that is, remembering the equality (
98)
An alternative expression for
can be derived from Remark 15 and Equation (
73)
To check the quality of the function
as a numerical estimate of
, Equation (
104) looks more suitable since it can be written in a recursive form. Indeed, if we put
with
from the recursive equation of the Stirling numbers of the second kind (
51), we get the following recurrence for the terms
initialized as
Table 3 reports a series of values of the recursive estimate
, compared with the prime-counting function
and the logarithmic integral function
. The last column of the table reports the values obtained through continuous approximation formulas I will expose hereafter.
In order to analyze the asymptotic behavior of
, we look for a continuous approximation of the probability function
. After promoting
k and
n to be continuous variables, which is a justifiable assumption for
and considering the relation (
98) between
and
S, Equation (
97) is written as
Taking the derivative of the above equation, we get the differential equation for
that can be written as
We set
where
is a parameter function depending on
n and
k. Then the general solution of the differential equation is
and the value of the constant is
C is determined by the asymptotic condition
.
Remark 16. It is interesting to note the method, based on probabilistic arguments, that led to Equation (107), provides an alternative approach to the problem of exploring the asymptotics () of Stirling numbers of the second kind. Since this topic is outside the scope of this work, I cite only the following example. If we choosethen it isand from (98), we get the well known asymptotic approximation of(see [26] and references therein)which is valid in the region, coinciding asymptotically with the region of validity of (88),. As a continuous approximation of the probability function
we are looking for, let us choose a parameter function depending on
n only through the following simple relation
where the constant
a varies between 1 and
e as suggested by the boundary conditions of the Stirling number ratio. Indeed for
the ratio (
106) is
that implies
, while for
, we know it is
hence
.
Therefore (
107) becomes
and from (
102) and (
104), we get the continuous approximation of
The last column of
Table 3 reports some examples from this approximation formula with
.
Table 4 reports the values calculated through (
109) with
compared with the values of
up to
(data with
values are taken from N. J. A. Sloane, ‘The On-Line Encyclopedia of Integer Sequences. Sequence A006880’,
http://oeis.org (accessed on 31 March 2021); Wikipedia contributors, ‘Prime-counting function’, Wikipedia, The Free Encyclopedia,
https://en.wikipedia.org/w/index.php?title=Prime-counting_function&oldid=987382574 (accessed on 31 March 2021)).
The following proposition, which is the
FOS equivalent of the
Prime Number Theorem, can be stated for the function
defined by (
109).
Theorem 9. Given, however small, it holdsdefinitively for. Proof. ,
,
, is a decreasing function with
n. Indeed,
Given
and
such that
, we can write
and, due to the decreasing of
with
n,
Given
,
, let
, hence
, and
then the previous inequalities become (note that
for
)
The limit for
of the left-hand and the right-hand side of the previous inequality, say
and
respectively, gives
that is
and
that is
Let , then for we get the thesis. □
What does the model say about the
Riemann Hypothesis [
27]? We know the most famous
millennium problem (E. Bombieri, “Problems of the Millennium: The Riemann Hypothesis”, Clay Math. Institute. (2000) online at
http://www.claymath.org/sites/default/files/official_problem_description.pdf accessed on 31 March 2021) is equivalent to establish the bound of the prime-counting function
[
28]
with
constant, definitively for
x sufficiently large (
is the logarithmic integral function defined for
as
, where the integral is to be intended as Cauchy principal value). We can prove that this bound, which I will refer to as the
RH rule throughout this work, occurs
w.p. 0, or better, that the
RH rule does not hold
w.p. 1 for the random variable
, defined above as the stochastic counterpart of
in our model.
Theorem 10. Letthen random variable with probability distribution (99), then it is Proof. Since
it is easy to see that both
and
From (
103) then it follows
□
Theorems 9 and 10 say what we know as PNT when dealing with primes holds for the counting variable associated with the set of sequences generated through the random sampling with replacement game I proposed in the Introduction, while the Riemann Hypothesis requires compliance with much stricter requirements such that it has zero probability to occur for the same counting variable.
5. Model Generalization and the Connection with the Riemann Hypothesis
This section deals with the generalization of the FOS model so that we can discriminate between two classes of models, compliant and not compliant with the RH rule. This allows us to use the different stochastic properties, depending on different models, of the random variables and to deduce some properties of the whole sequence of primes. In particular, we apply the model to infer the counting of successive prime pairs and then compare the result with actual sequences of prime pairs.
5.1. Model Generalization
In this section, we will consider the random variables
of Definition 7 as a continuous random variable, assuming values in
according to the following probability distribution function
with
given by the solution of the differential equation
obtained by considering a more general expression for the ratio (
106), where
n is substituted by
, a positive function of
n.
Notation. The probability density function of, that is the functionof the FOS
model, will be denoted as follows: Therefore, the probability functions of
become
The constant
C is determined by the normalization condition
hence
The complete expressions of the probability density and distribution function are
Note that
has a single maximum point at
The mathematical expectation of
(this calculation is reported in [
29] for the case
) is
where
is the Euler–Mascheroni constant and
is the exponential integral function with positive real argument
, sometimes referred to as upper (or complementary) incomplete gamma function
, defined by (see functions 5.1.1, 6.5.3, [
30])
We require the mathematical model to satisfy a similar condition to (
95) about the mean of
, that leads to the following formula
obtained from (
114), assuming
sufficiently large, so we can neglect the terms
and
. Note that the function
decreases rapidly as
, in particular [
31], (1.4)
Remark 17. The FOS combinatorial model studied in Section 4.5 corresponds to the function. In this case (115) is satisfied for(in particular whenit is). We know from Theorem 10 that the RH rule does not hold w.p. 1 for this class of models, which I will refer to as n-Model.
Another class of models of particular interest to our study, as we will see in the following, is the one determined by the choice
. In this case, condition (
115) can be satisfied using different functions having opposing implications as far as the compliance of the model with the
RH rule. We focus, in particular, on a solution ensuring the
RH rule holds
w.p. 1.
Remark 18. The model withwill be referred to as log(n)-Model.
The simplest
log(
n)
-Model is the one defined by the choice
hence by the parameter value
Through the methods of the previous section, it is possible to prove the same statements as Theorems 9 and 10, that is, this log(n)-Model is compliant with PNT and not with the RH rule.
Let us consider instead the
log(
n)
-Model defined by the assumption
where
is the inverse function of the logarithmic integral function
(I use for this function the same notation as in [
32]). In this case, we get
and condition (
115) is satisfied since we know it is (Theorem 3.3, [
32])
Equations (
111) and (
112), under the approximation for
, become
with
.
The double exponential distribution function (
122) is often called Gumbel distribution [
33,
34].
Remark 19. In the case of the model with, the ratio (106) is equal toit isasand deviates asymptotically from the Stirling number ratio which is. Briefly speaking, the log(n)-Model defined above corresponds to a subset of the FOS universe which is different from the one of the n-Model, containing sequences conforming to both PNT and the RH rule, as stated by the following theorems.
The continuous approximation function
becomes
In addition, for this function we can enunciate a proposition, which is the equivalent of the Prime Number Theorem.
Theorem 11. Givenhowever small, there existssuch that forit holdswhere the functionis defined by (123). The proof is completely analogous to that of Theorem 9.
Remark 20. Associated with the log(n)-Model we can define the counting random variableas in Definition 8, after assuming the probability distribution (110). It is easy to prove the analog of Theorem 8 for this variable, in particular Equations (101) and (103). We can therefore apply the probability method developed for the n-Model also in the case of the log(n)-Model. The
RH rule holds
w.p. 1 for the
log(
n)
-Model with
defined by (
118).
Lemma 8. Letbe the inverse function of the logarithmic integral functionandits n-th derivative. Then we haveand forwith Proof. Note that the function
is real analytic. The first derivative follows directly from the definition, since
. We proceed by induction. The thesis is true for
, indeed
Let us assume it is true for (
)
then we have for the
n-th derivative
from which, grouping the terms by powers of
, the thesis follows. □
Theorem 12. Letbe the random counting variable of Definition 8 with probability distribution (110) associated with the log(n)-Model (118), then it is Proof. Let
and
then from (
103) we know it is
with probability distribution functions given by (
122),
Since we know
is real analytic, consider its Taylor series
at
from Lemma 8
which can be written
From the asymptotic expansion of
we get
which leads to the following expression for
From (
124) and (
125) we finally get
and the limits for
Through analogous calculations for
we find
and the limits for
From (
103) then it follows
□
We can get an estimate of the speed of convergence to 1 of the probability of the RH rule as follows. If we denote with the subset of random sequences of positive integers distributed according to the log(n)-Model with mean , under the assumption that the sequence of prime numbers belongs to the set , we can use the properties of the Gumbel distribution and Chebyshev’s inequality to get the probability of the RH rule, more generally the probability of any difference , as a function of n. In other words, we can consider as a stochastic process of random variables differently distributed and the sequence of primes as particular realization of the process.
Different bounds of the difference
have been established for the sequence of prime numbers, depending on the conditions assumed. From ((1.3), [
35]) we know that it holds unconditionally for
while under the
Riemann Hypothesis, we get (Theorem 6.2, [
32])
From the properties of the Gumbel distribution we know the variance of
is (note that the probability distribution (
112) is not exactly a Gumbel distribution because of the cut at
of definition (
110). Assuming
n sufficiently large, so that (
121) and (
122) hold, we can consider the probability distribution of the model as a Gumbel distribution).
hence, from Chebyshev’s inequality (see Chapter IX, p. 233, [
18]), it follows that the probability of the unconditioned bound converges to 1 with a quadratic law
while in the case the
Riemann Hypothesis holds
5.2. Counting Successive Prime Pairs through the log(n)-Model
The general problem of prime pairs can be stated as follows: given d and N positive integers, d even, what is the number of pairs of primes (not necessarily consecutive), such that ? Connected with this there is the following one, we can call as the problem of counting successive prime pairs: given d and N positive integers, d even, what’s the number of pairs of primes , separated by the gap d, that is such that ?
Mathematics has no certain results about these two problems which are different from the so called “bounded gaps problem”, recently solved by mathematician Yitang Zhang [
36], who proved that as
there are infinitely many prime pairs
, with
. Successively, this bound has been lowered to 246 through the extension of the method of Zhang and other contributors. Nevertheless, the twin primes conjecture which requires the bound to be reduced to
, remains unproven. Important results towards this goal can be found in [
37,
38], showing in particular that
, that is there always be pairs of primes
with
d less than any fraction of
, the average spacing between successive primes.
In 1923, Hardy and Littlewood proposed the following formula as a solution of the general problem, stressing that it was impossible for them “to offer anything approaching a rigorous proof” (see Conjecture B, [
5]):
where
The product is over all odd primes in (
127), over odd primes dividing
d in (
128). The constant
is called the twin prime constant, while the term
is responsible for the irregularities and the oscillating pattern of the counting functions. A formula similar to (
126) for the counting of successive prime pairs separated by a gap
d, was suggested by Wolf ([
39], and the references therein) after enumerating, by means of a computer program, all gaps between consecutive primes up to
. Starting from the observed pattern, which showed an exponential decay of the number of pairs depending on
d, at the end of a heuristic procedure including approximations due to
PNT, he deduced the complete formula (the procedure is reported in M. Wolf (2018),
Some Heuristics on the Gaps between Consecutive Primes, available at
https://arxiv.org/abs/1102.0481 accessed on 31 March 2021).
The functional dependence on
N of the formula above can be transformed into a dependence on the sequence number
n of the greatest prime
interested in the count. Indeed, we can set
and
and, hence, it is easy to get
and the counting formula becomes
where I changed the capital letter
N to lower case
n so as to remember the different meaning of the functional dependence.
The original Hardy and Littlewood conjecture was empirically tested by several authors and used to calculate the number of pairs
in the case of small gaps
d between successive primes [
40]. I show in the following that the conjecture of Wolf, which is based on a large amount of empirical data, can be derived from the combinatorial model we defined as
log(
n)
-Model in Remark 19.
Remark 21. Note that the conjecture (131) can be written aswhereis the function defined in (130) and Definition 9. Given the sequence of primes, let us define the gapbetween successive primes and the number of successive prime pairsseparated by a gap d depending on the sequence number n as The gap
can be modeled as the difference between the random variables
with probability mass function
where
is the joint probability density function of the couple
. We can obtain the estimate of the function
, as resulting from the combinatorial model adopted, through the equation
We do the following assumption.
Assumption 2. (Large gaps independence law) Forsufficiently large, the two eventsandare independent.
Under the previous assumption, the joint probability
can be written as the product of the two probability density functions
and its value depends on the type of model we choose.
Let us calculate the joint probability (
135) for the
log(
n)
-Model defined in Remark 18.
We adopt the following approximations
and
valid for both (this means the results we are going to obtain depend on
PNT only, not on the
Riemann Hypothesis).
and
Then (
135) becomes
and (
133), after the variable change
is written
Let
be
then the integral
Finally, the probability mass function (
133) resulting from the
log(
n)
-Model under Assumption 2 and
is (note it is independent of parameter
a)
Comparing the previous equation with (
132), we see the
log(
n)
-Model confirms Wolf’s conjecture, in particular the exponential decay of the pair number depending on
d, at least for large values of the gap
d, when Assumption 2 can be considered valid. Note that in the case of the
n-Model, we would get the same expression as in (
136), but with the function
n in place of
. The fact that only the
RH rule compliant model agrees with the counting function of consecutive prime pairs, derived from empirical data, is a notable achievement of the theory, since it is a strong indication that the counting problem is deeply connected with the Riemann Hypothesis.
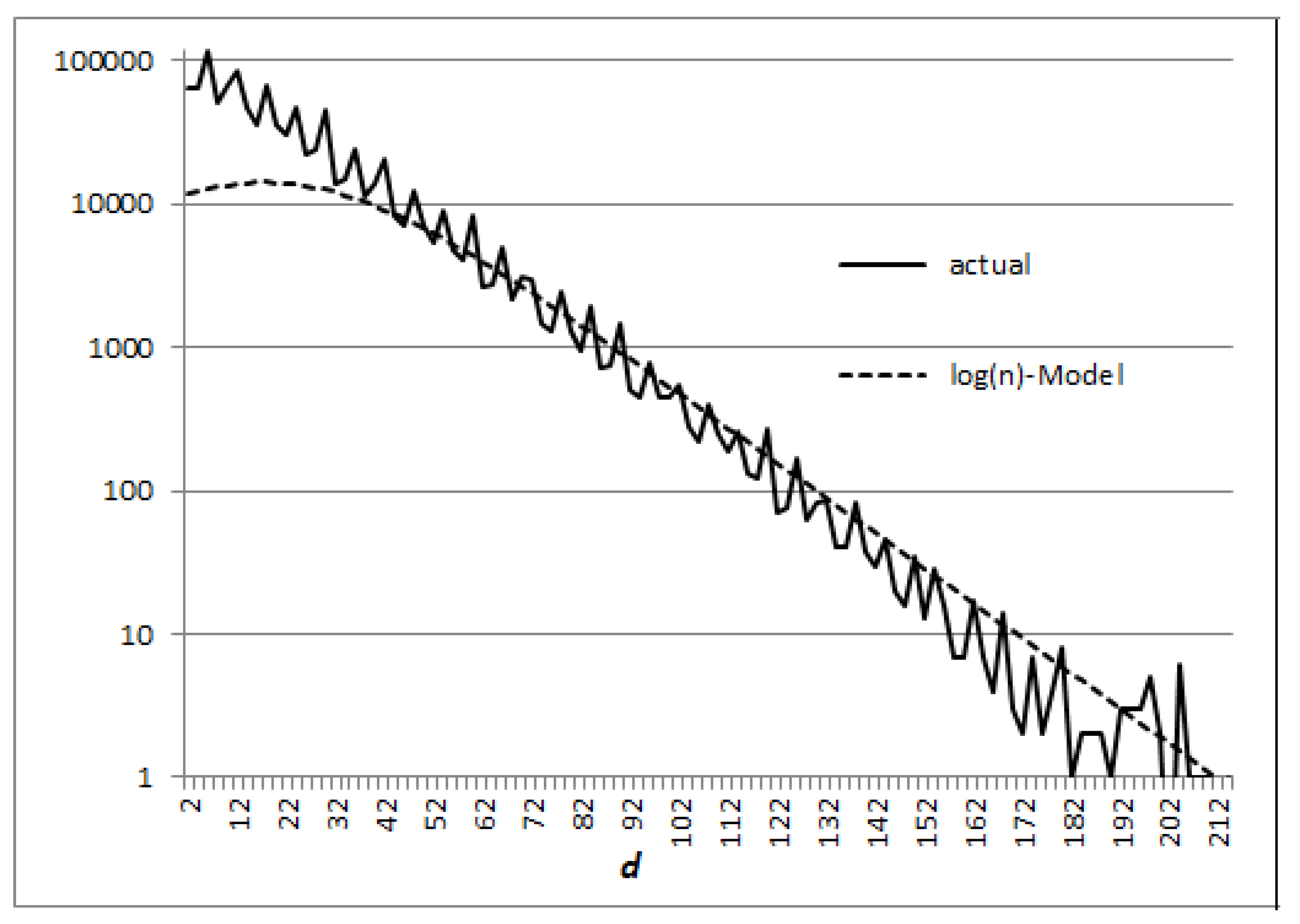
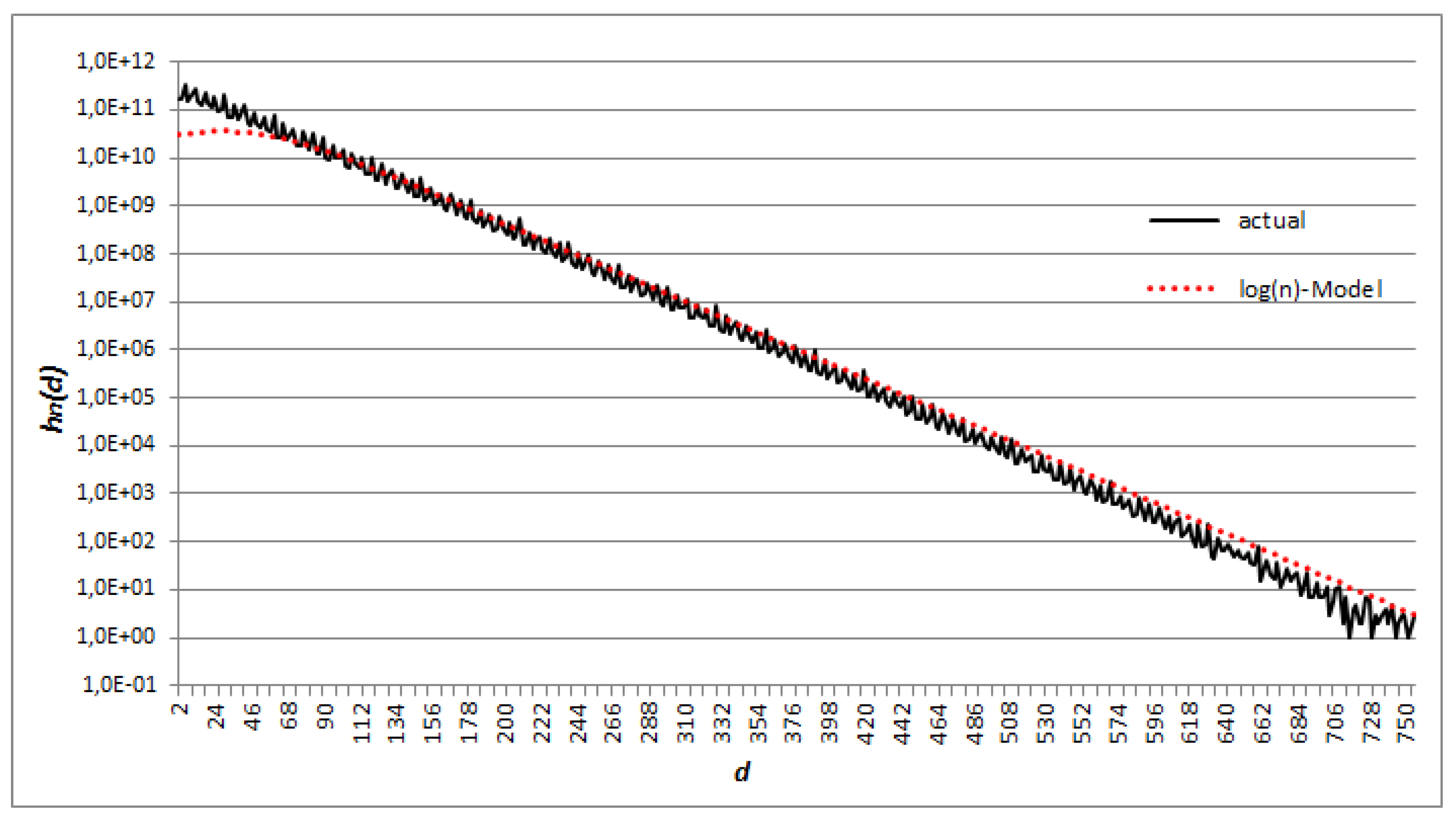
Figure 1 and
Figure 2 show the results obtained from the
log(
n)
-Model with respect to the actual numbers of pairs in two cases:
and
.
5.3. A Heuristic Model of the Distribution of Prime Numbers
The generalized model we presented in
Section 5.1 can be directly related to the sequence of primes by changing condition (
115) into the following
which leads to the value
while the point of maximum of the probability density function (
113) becomes
It is interesting to note we would obtain the same expressions, with
, if we substitute the condition (
137) with the following one, on the point of maximum of the function
In this case, the mean value of
changes to
This model has the property to express the prime counting function
through the values of the sequence of primes
from
to
. Let consider indeed the case when
is constant. In this case, the average of the random counting variable (
102) is
and it approximates the value of
with any precision depending on
.
Indeed
since
we can write
Assuming
and
, (
140) easily follows.
Note that for each term of the sum (
139) it is
hence (
141).
From Equation (
137) we get in the case of the
log(
n)
-Model,
:
in the case of the
n-Model,
:
The probability functions above are valid for
(remember (
110)),
sufficiently large, and
.
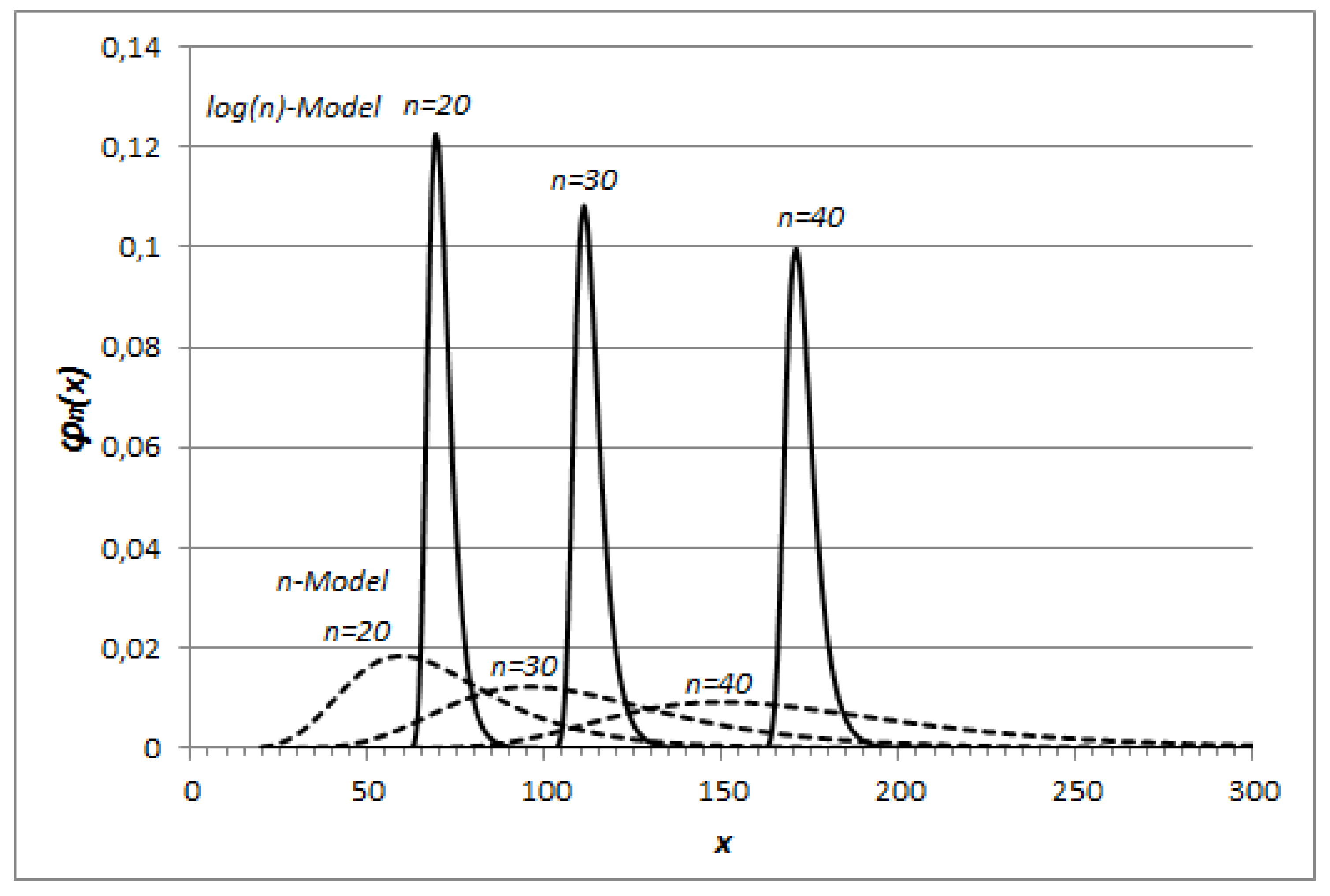
Definition 10. Equations (142)–(145) define the heuristic log(n)-Model and the heuristic n-Model respectively. Examples of different probability distribution functions
resulting for these heuristic models are given in
Figure 3, for
.
From
Figure 3, we see the dispersion of the random variable
around its mean value
is very small in the case of the
heuristiclog(
n)
-Model, so that we can assume the estimate
is very close to the prime-counting function itself
for this model as stated by Remark 22 in the particular case
.
Table 5 shows some examples of estimate of
, calculated through the
heuristiclog(
n)
-Model with
, for different orders of magnitude.
The following considerations we propose in the case of the heuristic log(n)-Model, because of its relevance, are obviously valid in the case , constant.
The following theorem gives a quantitative evaluation of the probability of error we do, when considering the random variable (in practice its mean value for small variances) as an estimate of .
Theorem 13. Given the random variableof Definition 8,, letbe the first kind error,the second kind error ofatandthe sum of the two error probabilities. Then for the heuristic log(n)-Model defined by Equations (142) and (143) withit is Proof. From the theory of Gumbel distribution we know the variance of
is
hence from Chebyshev’s inequality
It is
and
and, therefore, we can also write
From (
99), (
100) it follows
□
Remark 23. Through the heuristic model we can derive new lower and upper bounds of the prime-counting function:where We know ([
41,
42]) the following lower and upper bounds of the
n-th prime
hold
for
the left-hand side and
the right-hand side, hence for
given by (
143) it follows
and assuming
sufficiently large so that the condition
may be neglected, we can write (
147) for
given by
From Remark 22 and Theorem 13, we know we can consider the approximation
as valid for the heuristic model, from which we get (
147).
6. Concluding Remarks
The first aim of this work was to deepen the problem of randomness in the distribution of prime numbers through such simple combinatorial objects as
First Occurrence Sequences, showing new analogies between the classical set partition problem and the distribution of primes themselves.
First Occurrence Sequences define a general class of objects for which the
Prime Number Theorem holds, such as for the prime sequence, but they fail to represent more stringent constraints, required by the
Riemann Hypothesis, such as the equivalent condition established by Helge von Koch I called
RH rule. In order to investigate this second step, the simple model must be generalized (or the class of combinatorial objects must be restricted) to discriminate between
RH rule compliant and noncompliant models. The analysis based on probability methods shows the
Riemann Hypothesis holds
w.p. 1 (together with the
Prime Number Theorem, of course) for the class of random sequences represented by the
log(
n)
-Model with mean equal to
, the inverse function of the logarithmic integral function. Therefore, we can conclude that the property represented by the
Riemann Hypothesis through the
RH rule is largely independent of the primes and belongs to a large class of random sequences. Whether this class also contains the sequence of prime numbers cannot be decided by the model except statistically. Something similar happens within the context of analytical theory when speaking of zeta function
, Dirichlet L-functions
(Chap. 12, [
43]) (
s is the complex variable
), and the
Generalized Riemann Hypothesis “that is the hypothesis that not only
but all the functions
have their zeros in the critical strip on the line
” (p. 124, [
44]).
Attempts to prove the Riemann hypothesis through the methods of physics go back as far as the so-called Hilbert–Polya conjecture, which associates the imaginary part of non-trivial zeros of
to the eigenvalues of some self-adjoint (Hermitian) operator that might be considered like the Hamiltonian of a physical system (the story of Hilbert–Polya conjecture is documented on Odlyzko’s personal website; see
http://www.dtc.umn.edu/~odlyzko/ accessed on 31 March 2021). Each type of combinatorial model we presented in the previous sections, based on probability equations such as (
111) and more generally (
25), can be transformed into a single particle Hamiltonian of an equivalent quantum system that emerges as a solution to an underlying combinatorial problem. This topic is outside the scope of this work and will not be treated here; I just want to mention that the analogy with the physical problem allows us to overcome some critical points of the combinatorial model and eliminate any arbitrariness in the choice of the mean of the random variable
(the combinatorial counterpart of the
n-th prime). The solution
emerges as a general asymptotic solution for such models due to concepts such as interaction potential and energy levels, that play an important role also in describing integer sequences such as Fibonacci numbers and prime numbers, and the application of the Hellmann–Feynman theorem to the whole system (see [
45] for a mathematical foundation of the theorem). These methods result in computational benefits improving the estimates obtained from the combinatorial model and may suggest new conjectures about the distribution of primes. In [
29], the quantum model derived from what we have called
n-Model is developed and applied to explore the region beyond the Skewes number in connection with the numerical results known in the literature derived through analytical methods.
These two topics (the parallelism between the treatment from the point of view of random sequences and of Riemann zeta and Dirichlet L-functions; the transposition of the problem into a quantum physics framework), seem worthy of being addressed in future work.







{kind=link}
{kind=link}
{kind=link}