Extended VIKOR-QUALIFLEX Method Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information for Multiple Attribute Decision-Making with Unknown Attribute Weight

Abstract
1. Introduction
- (1)
- Some basic concepts about TrF2DLVs are introduced, including expectation value based on scale function, distance measure, and trapezoidal fuzzy two-dimensional linguistic preference relation (TrF2DLPR).
- (2)
- A combination weight model based on trapezoidal fuzzy two-dimensional linguistic information is proposed to solve the MADM problems with unknown attribute weights, which includes proposing a trapezoidal fuzzy two-dimensional linguistic best-worst method (TrF2DL-BWM) to determine the subjective attribute weight, proposing a CRITIC method to determine the objective attribute weight, and proposing a method based on the maximum comprehensive evaluation value to determine the combination weight.
- (3)
- An extended VIKOR-QUALIFLEX method based on TrF2DLVs is presented to solve MADM problems, which can measure the concordance index of each ranking combination by means of group utility and individual maximum regret value of each evaluation alternative, and get more stable evaluation result.
- (4)
- A practical application of lean management assessment for industrial residential projects is solved by the proposed method.
2. Preliminaries
2.1. Trapezoidal Fuzzy Numbers
2.2. Linguistic Term Sets
- (i)
- The set is ordered: if and only if ;
- (ii)
- There is a negation operator: Neg () = ;
- (iii)
- If , then ;
- (iv)
- If , then .
2.3. Trapezoidal Fuzzy Two-Dimensional Linguistic Variables
- (i)
- ;
- (ii)
- ;
- (iii)
- ;
- (iv)
- ;
- (v)
- ;
- (vi)
- ;
- (vii)
- .
- (i)
- If , the ;
- (ii)
- If , the ;
- (iii)
- If , the .
- (i)
- ;
- (ii)
- If , then ;
- (iii)
- ;
- (iv)
- .
2.4. Trapezoidal Fuzzy Two-Dimensional Linguistic Preference Relation
3. Models of the Weights of Attributes for MADM Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information
3.1. Subjective Weight Model Based on TrF2DL-BWM
- Step 1
- determine the best and the worst attributes.
- Step 2
- obtain the Best-to-Others vector and the Others-to-Worst vector .
- Step 3
- convert the vector and to and , respectively.
- Step 4
- obtain the subjective weight vector by solving the model (28).
3.2. Objective Weight Model Based on CRITIC Method
- Step 1
- Normalize the decision matrix into () by the following formulas:For benefit attributes, we haveFor cost attributes, we have
- Step 2
- Calculate the correlation coefficient between the jth and the lth attributes by the following Equation (31) and obtain the correlation coefficient matrix :where and are the mean of jth and lth attributes. can be calculated by the following Equation (32). Similarly, can also be obtained.
- Step 3
- Calculate the standard deviation of the attribute by the following formula:
- Step 4
- Calculate the index () of the attribute by the following formula:
- Step 5
- Obtain the objective weight vector , where
3.3. Combination Weight Model Based on Maximum Expected Value of Evaluation
4. Extended VIKOR-QUALIFLEX Method Based on TrF2DLVs for MADM with Unknown Attribute Weight
4.1. Problem Description of MADM with Unknown Attribute Weight
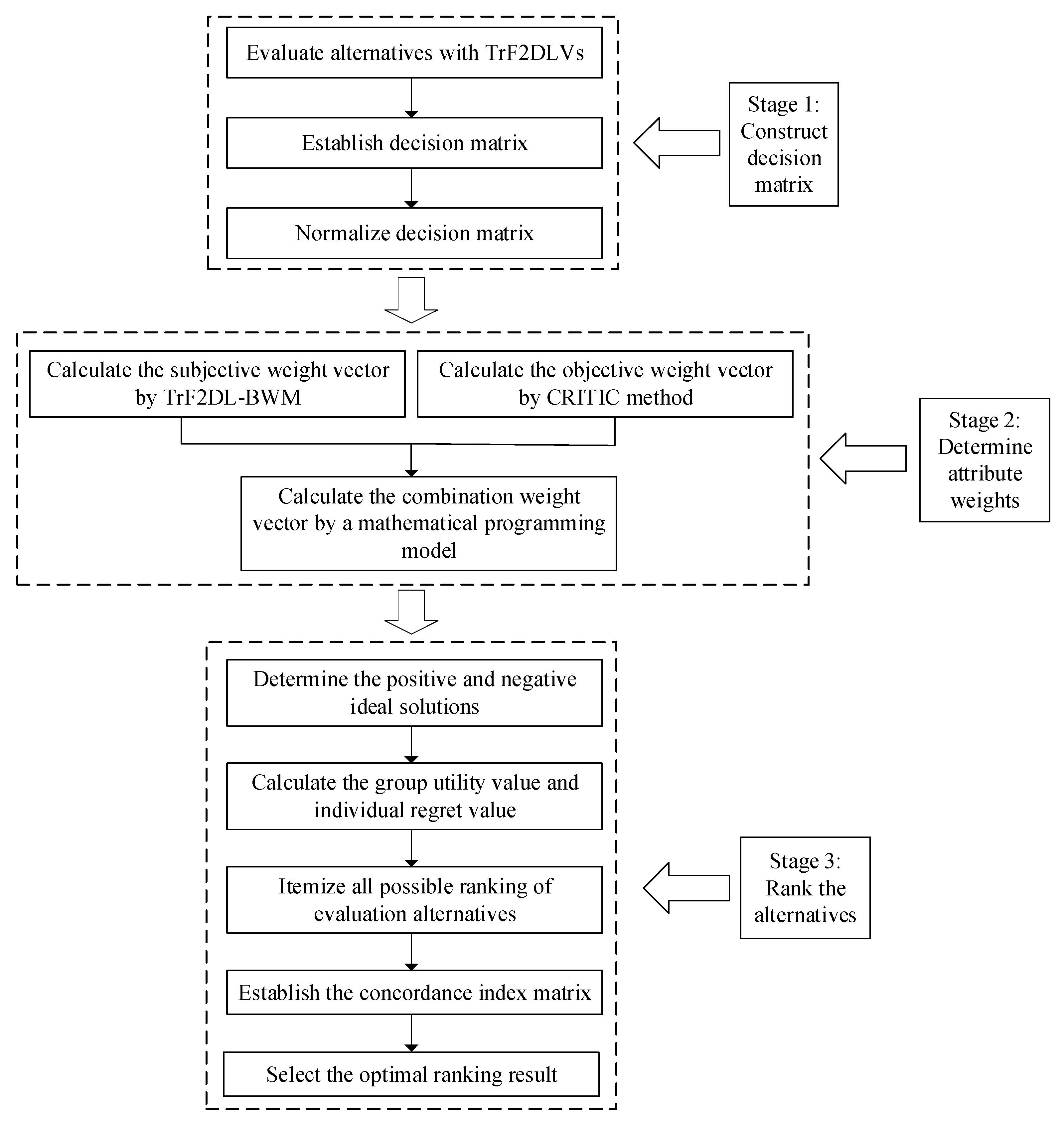
4.2. Extended VIKOR-QUALIFLEX Method Based on TrF2DLVs
- Step 1
- Establish decision matrix , where is the evaluation value of the alternative according to the attribute represented by a TrF2DLV . Then, normalize the decision-making unit according to the attribute of benefit type or cost type. The normalized matrix can be obtained from Equations (29) and (30) in Section 3.2.
- Step 2
- Calculate the weight vector of attributes using the weight determination model.
- Step 2.1
- Calculate the subjective weight vector using TrF2DL-BWM in Section 2.1, where ,;
- Step 2.2
- Calculate the objective weight vector using the CRITIC method in Section 2.2, where , ;
- Step 2.3
- Calculate the combination weight vector by a mathematical programming model in Section 2.3, where , .
- Step 3
- Determine positive and negative ideal solutions of each subattribute.The positive ideal solution and the negative ideal solution .Note: the comparison rules of are described in Section 2.3.
- Step 4
- Calculate the group utility value and individual regret value of each evaluation alternative, where
- Step 5
- List all possible ranking of m evaluation alternatives .
- Step 6
- The alternatives in each possible permutation are compared in pairs in order, and the concordance index of each comparison ( over ) is calculated by the following Equation (43). Then, the concordance index matrix is established.where , , , and . is the decision-making mechanism coefficient, which can balance the weights between group utility and individual regret. When , it indicates that DMs prefer to maximize group utility; when , it indicates that DMs prefer to minimize individual regret. In this study, we suppose that the “the maximum group utility” and “minimum individual regret” have the same importance, that is, .
- Step 7
- Calculate the overall concordance index for each possible ranking .
- Step 8
- The ranking with the largest overall concordance index is selected as the final ranking result.
5. Practical Case Application
5.1. Method Implementation Process
- Step 1.
- Since all attribute types are benefit type, the normalization can be omitted.
- Step 2.1.
- Calculate the subjective weight vector using TrF2DL-BWM.
- Step 2.1.1.
- First, the best attribute and the worst attribute are determined among all the primary attributes. Then, the best attribute and the worst attribute among the subattributes of each primary attribute are determined.For the five primary attributes, the DMs determine that the best attribute is and the worst attribute is . For the four subattributes under the primary attribute , DMs determine that the best attribute is , and the worst subattribute is . Similarly, for other primary attributes, the best subattributes are , , , and , and the worst subattributes are , , , and .
- Step 2.1.2.
- For the five primary attributes, DMs give the Best-to-Others vector:= = {([0.500, 0.500, 0.500, 0.500],), ([0.667, 0.733, 0.800, 0.867],), ([0.533, 0.600, 0.667, 0.733],), ([0.733, 0.800, 0.867, 0.933],), ([0.800, 0.867, 0.933, 1.000],)}, and the Others-to-Worst vector:= = {([0.800, 0.867, 0.933, 1.000],), ([0.533, 0.600, 0.667, 0.733],), ([0.667, 0.733, 0.800, 0.867],), ([0.667, 0.733, 0.800, 0.867],), ([0.500, 0.500, 0.500, 0.500],)}.For the four subattributes under the primary attribute , DMs give the Best-to-Others vector:= = {([0.500, 0.500, 0.500, 0.500],), ([0.533, 0.600, 0.667, 0.733],), ([0.800, 0.867, 0.933, 1.000],), ([0.667, 0.733, 0.800, 0.867],)}, and the Others-to-Worst vector:= {([0.800, 0.867, 0.933, 1.000],), ([0.667, 0.733, 0.800, 0.867],), ([0.500, 0.500, 0.500, 0.500],), ([0.667, 0.733, 0.800, 0.867],)}.Similarly, DMs can give the Best-to-Others vectors and the Others-to-Worst vectors of other subattributes under the primary attribute , , , and . For the convenience of reading, they are omitted here.
- Step 2.1.3.
- Convert the vector and to and , respectively.Here, we only take the primary attributes as an example to give the experimental results. = = {0.500, 0.767, 0.633, 0.833, 0.930},= {0.900, 0.633, 0.767, 0.575,0.500}.
- Step 2.1.4.
- For the five primary attributes, we can build the following model based on Equation (28):
- Step 2.2.
- Calculate the objective weight vector using the CRITIC method in Section 2.2.
- Step 2.2.1.
- For the four subattributes under the primary attribute , we calculate the correlation coefficient (j, l = 1, 2, 3, 4) between the jth and the lth attributes by the Equations (31) and (32), and the following correlation coefficient matrix: can be determined:
- Step 2.2.3.
- For the primary attributes, calculate the standard deviation of the (j = A, B, C, D, E) primary attribute by Equation (33). Similarly, the standard deviation (j = 1, 2, 3, 4 when and j = 1, 2, 3 when ) of subattributes under each primary attribute can also be obtained.
- Step 2.2.4.
- According to Equations (34) and (35), the objective weight vector for primary attributes and the objective weight vector can be obtained as below:
- Step 2.3.
- Calculate the combination weight vector of all subattributes by the mathematical programming model in Section 2.3 and Equation (40). The result is as follows:ϖ = (0.092, 0.074, 0.032, 0.046, 0.074, 0.091, 0.045, 0.045, 0.053, 0.065, 0.035, 0.067, 0.051, 0.044, 0.023, 0.031, 0.051, 0.050, 0.031)T.
- Step 3.
- Determine positive and negative ideal solutions of each subattribute.
- Step 4.
- Calculate the group utility value and individual regret value of each evaluation alternative based on Equations (41) and (42),
- Step 5.
- All possible ranking of 3 evaluation alternatives can be listed:
- Step 6.
- The concordance index matrix is established by Equation (43),
- Step 7.
- Calculate the overall concordance index for each possible ranking by Equation (44),
- Step 8.
- The largest overall concordance index is , thus the ranking result is .
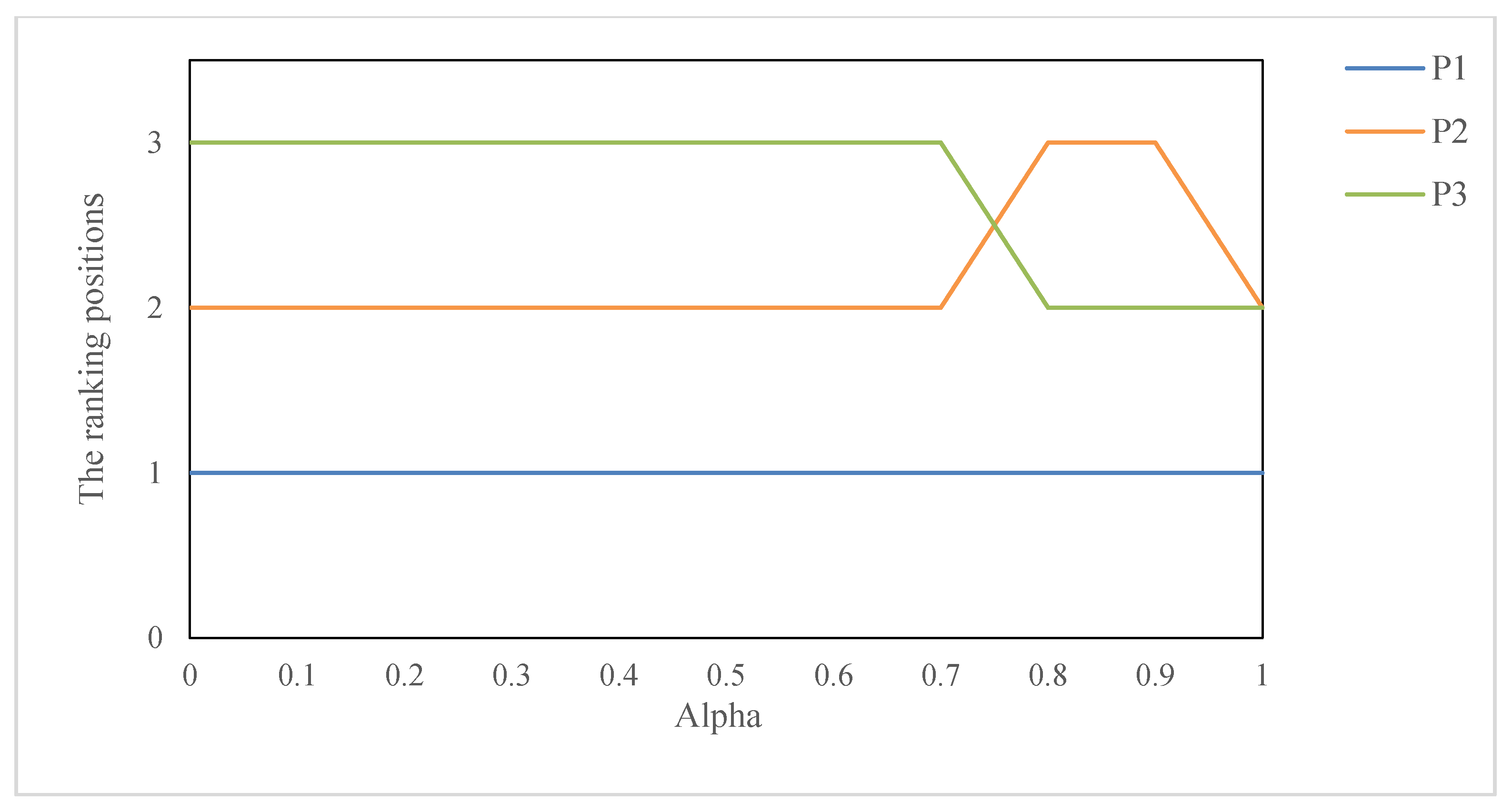
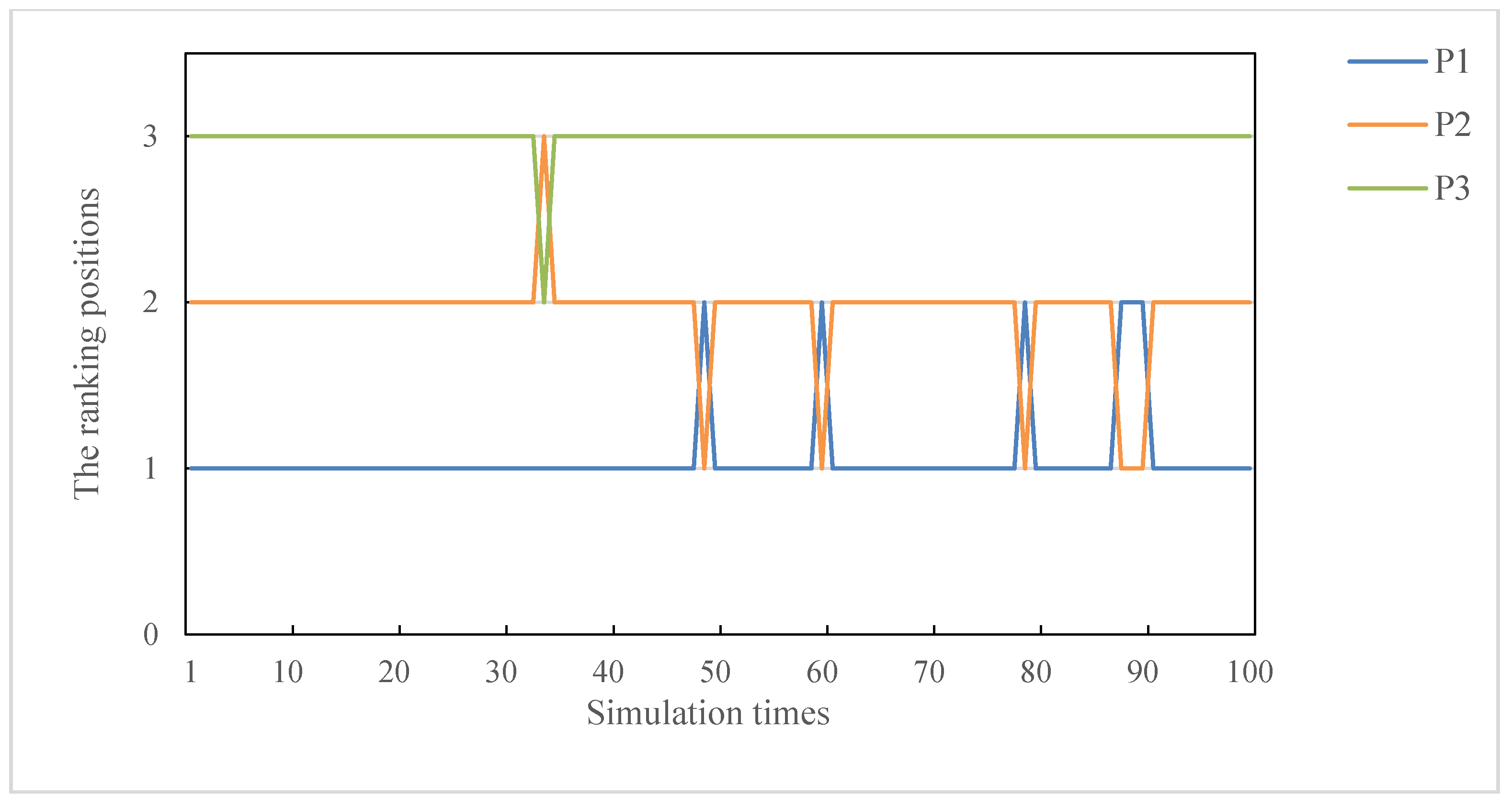
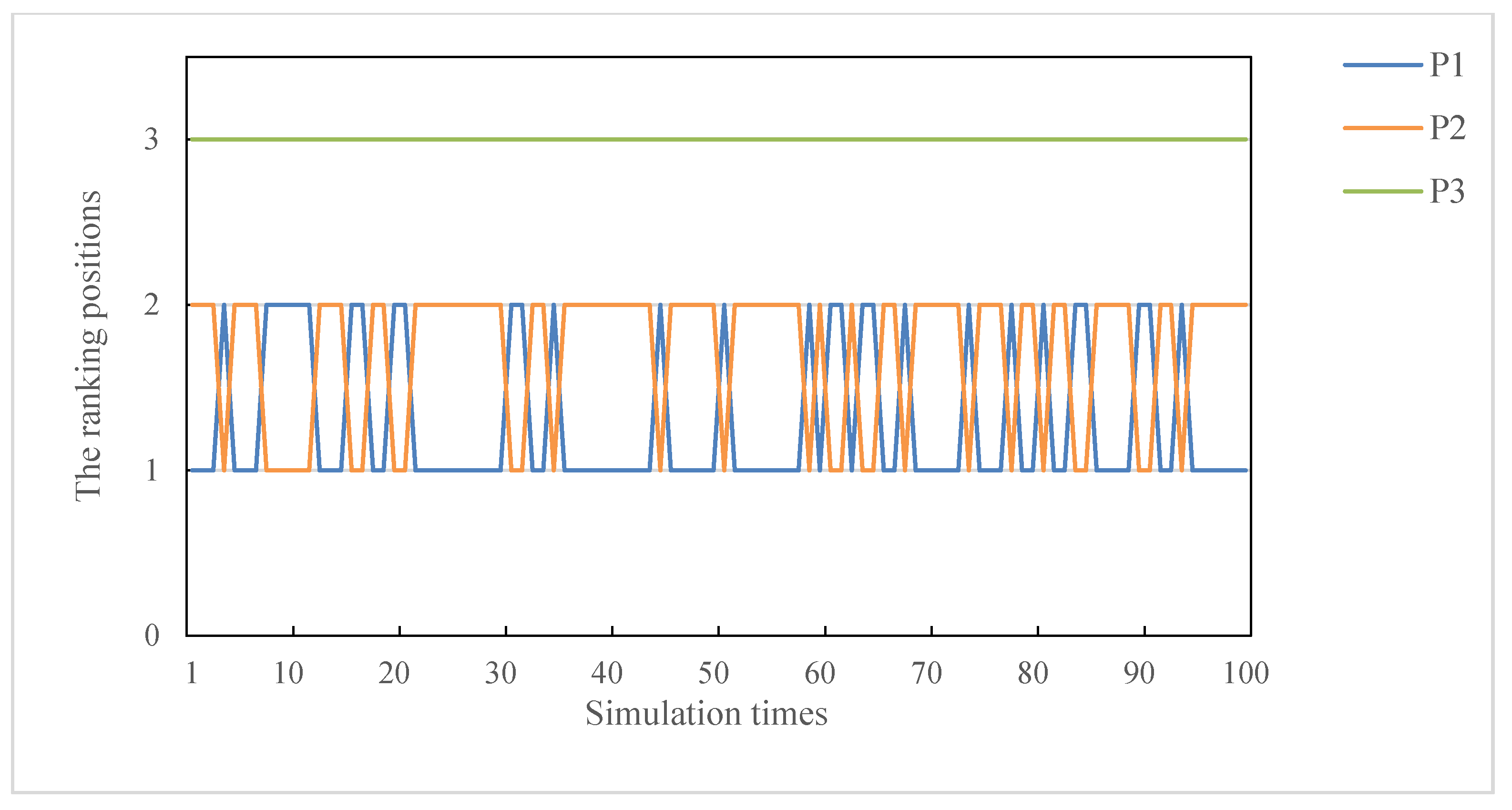
5.2. Parameter Sensitivity Analysis
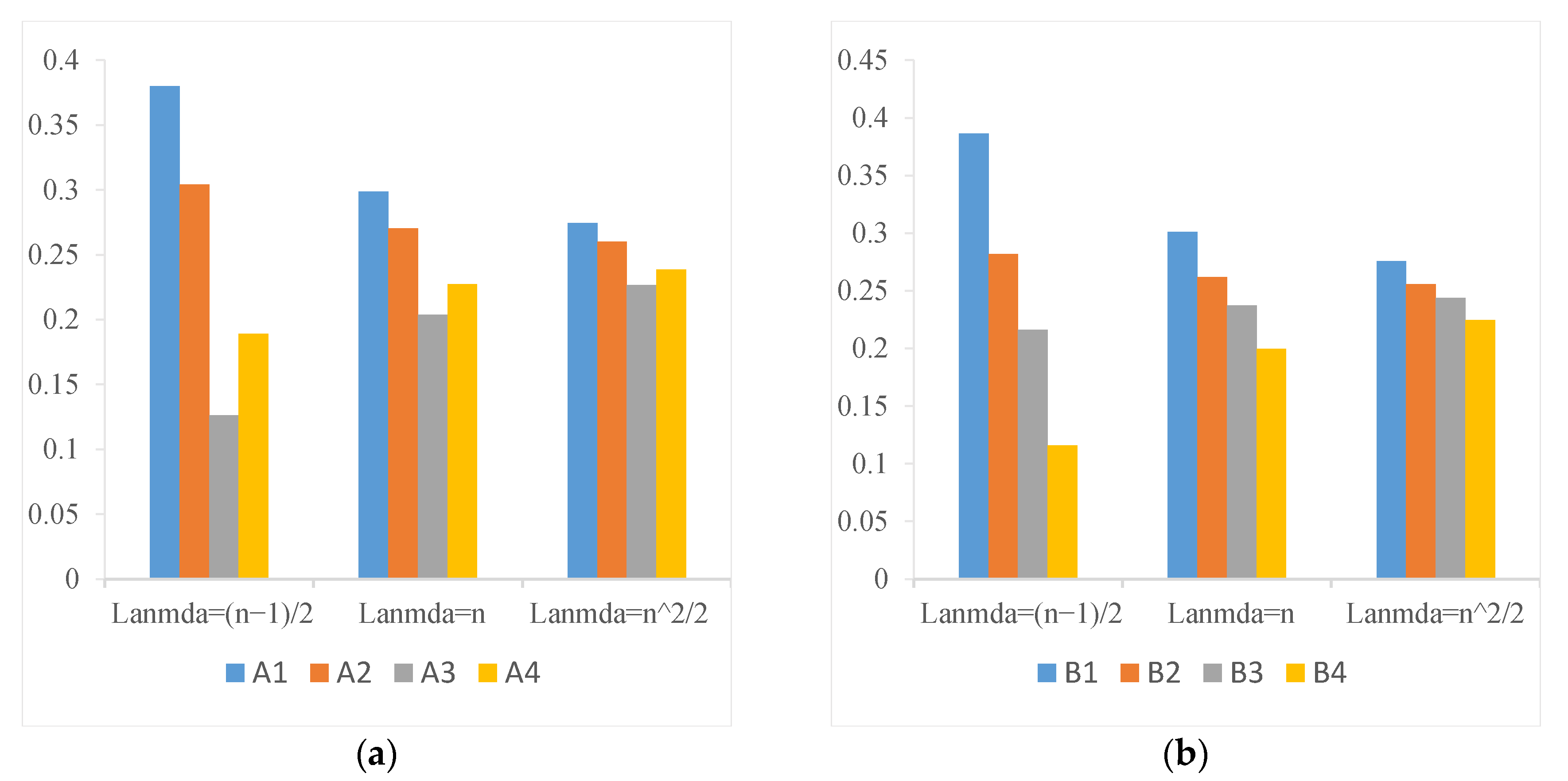
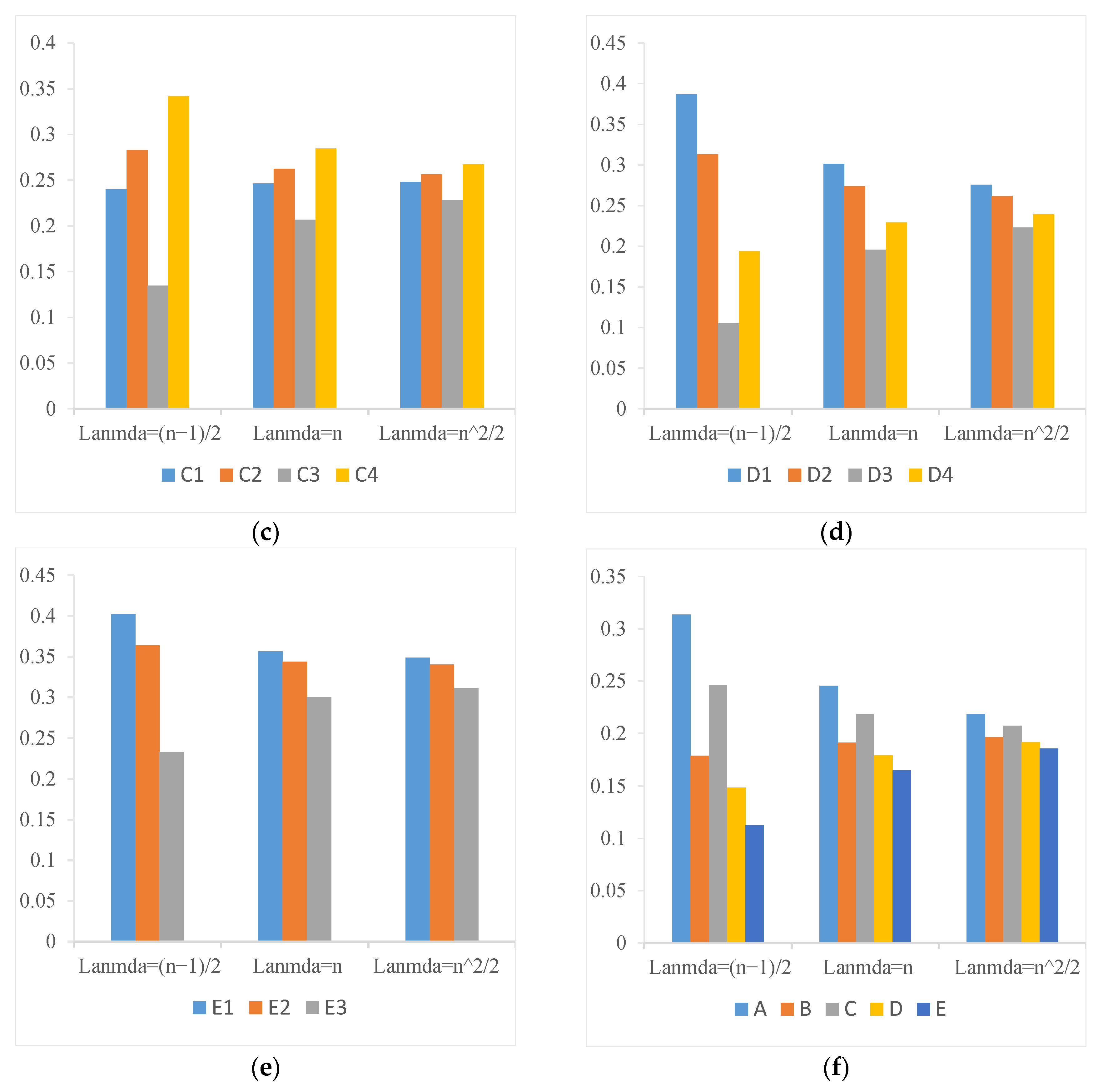
5.3. Weight Sensitivity Analysis
5.4. Comparative Analysis and Discussion
- (1)
- Compared with the method in [14]. The TF2DLPGWA operator in [14] can assign a corresponding weight to each attribute value, and the allocation principle is to adjust the weight of extreme value to a smaller weight. The result of this operation is to reconcile the evaluation value of the alternatives, reduce the differentiation between the alternatives, and make it difficult to distinguish some close alternatives. It is not suitable for those DMs with poor discrimination ability. In addition, the proposed method, which uses a CRITIC method to deal with the objective weight, can measure the contrast intensity and conflict, get a more distinct overall correlation coefficient, and then get a more clear objective weight. In addition, although the method based on TF2DLPGWA operator is simple and easy to operate, it is easy to cause the loss of decision-making information. Our method in this paper can calculate the overall concordance index of different ranking combinations by the group utility value and individual regret value, and then get more scientific and reliable ranking results.
- (2)
- Compared with the method in [15]. The WTF2DLPGHM operator in [15] also uses the power mean operator to change the weight of extreme evaluation value to eliminate the effect of extreme value. However, in this way, it may be difficult to distinguish the priority among the alternatives. In addition, although the method based on the WTF2DLPGHM operator uses the Hamy mean operator which can deal with the relationship between attributes, and contains variable parameters which can adapt to different DMs with different preferences. It also brings the corresponding disadvantage of obtaining unstable evaluation result. However, the ranking obtained by our method are easier to identify and distinguish, and more stable in response to the weights of attributes. More importantly, the results are more convincing. It is worth noting that this paper also proposes a combination weight model to determine the attribute weights, which not only considers the subjective weight of the DMs but also considers the objective weight information contained in the evaluation data; this makes the weights of attribute more real and effective, thus improving the accuracy of decision-making. In addition, the proposed weight model can be flexibly applied to different index systems and DMs with different distinguishing ability based on the flexible parameter .
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brunelli, M.; Rezaei, J. A multiplicative best–worst method for multi-criteria decision making. Oper. Res. Lett. 2019, 47, 12–15. [Google Scholar] [CrossRef]
- Guo, S.; Zhao, H.R. Fuzzy best-worst multi-criteria decision-making method and its applications. Knowl.-Based Syst. 2017, 121, 23–31. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Hu, J. Multi-criteria decision-making method based on dominance degree and BWM with probabilistic hesitant fuzzy information. Int. J. Mach. Learn. Cybern. 2019, 10, 1671–1685. [Google Scholar] [CrossRef]
- Rezaei, J. Best-Worst Multi-Criteria Decision-Making Method. Omega 2015, 53, 49–57. [Google Scholar] [CrossRef]
- Wang, J.; Wu, J.; Wang, J.; Zhang, H.; Chen, X. Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inf. Sci. 2014, 288, 55–72. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Ayyildiz, E.; Gumus, A.T.; Erkan, M. Individual credit ranking by an integrated interval type-2 trapezoidal fuzzy ELECTRE methodology. Soft Comput. 2020, 24, 16149–16163. [Google Scholar] [CrossRef]
- Xie, J.; Zeng, W.; Li, J.; Yin, Q. Similarity measures of generalized trapezoidal fuzzy numbers for fault diagnosis. Soft Comput. 2019, 23, 1999–2014. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Zhu, W.D.; Zhou, G.Z.; Yang, S.L. An approach to group decision making based on 2-dimension linguistic assessment information. Syst. Eng. 2009, 27, 113–118. [Google Scholar]
- Liu, P.; Zhang, X.; Pedrycz, W. A consensus model for hesitant fuzzy linguistic group decision-making in the framework of Dempster-Shafer evidence theory. Knowl.-Based Syst. 2020, 106559. [Google Scholar] [CrossRef]
- Liu, P.; Wang, P.; Pedrycz, W. Consistency-and consensus-based group decision-making method with incomplete probabilistic linguistic preference relations. IEEE Trans. Fuzzy Syst. 2020, 1–15. [Google Scholar] [CrossRef]
- Wang, P.; Liu, P.; Chiclana, F. Multi-stage consistency optimization algorithm for decision making with incomplete probabilistic linguistic preference relation. Inf. Sci. 2020, 1–28. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Liu, P. Multiple attribute group decision-making methods based on trapezoidal fuzzy two-dimension linguistic power generalized aggregation operators. Soft Comput. 2016, 20, 2689–2704. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Y. The Trapezoidal Fuzzy Two-Dimensional Linguistic Power Generalized Hamy Mean Operator and Its Application in Multi-Attribute Decision-Making. Mathematics 2020, 8, 122. [Google Scholar] [CrossRef]
- Yin, K.; Yang, B.; Li, X. Multiple attribute group decision-making methods based on trapezoidal fuzzy two-dimensional linguistic partitioned Bonferroni mean aggregation operators. Int. J. Environ. Res. Public Health 2018, 15, 194. [Google Scholar] [CrossRef]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Stević, Ž.; Tanackov, I.; Prentkovskis, O. A novel multicriteria approach–rough step-wise weight assessment ratio analysis method (R-SWARA) and its application in logistics. Stud. Inform. Control 2018, 27, 97–106. [Google Scholar] [CrossRef]
- Kumar, A.; Aswin, A.; Gupta, H. Evaluating green performance of the airports using hybrid BWM and VIKOR methodology. Tour. Manag. 2020, 76, 103941. [Google Scholar] [CrossRef]
- Muravev, D.; Mijic, N. A Novel Integrated Provider Selection Multicriteria Model: The BWM-MABAC Model. Decis. Mak. Appl. Manag. Eng. 2020, 3, 60–78. [Google Scholar] [CrossRef]
- Cui, Y.; Feng, P.; Jin, J.; Liu, L. Water resources carrying capacity evaluation and diagnosis based on set pair analysis and improved the entropy weight method. Entropy 2018, 20, 359. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, Y. The maximizing deviation method for group multiple attribute decision making under linguistic environment. Fuzzy Sets Syst. 2007, 158, 1608–1617. [Google Scholar] [CrossRef]
- Hu, Y.; Wu, L.; Shi, C.; Wang, Y.; Zhu, F. Research on optimal decision-making of cloud manufacturing service provider based on grey correlation analysis and TOPSIS. Int. J. Prod. Res. 2020, 58, 748–757. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Li, L.; Zhao, X.; Liu, P. Q-rung orthopair fuzzy multiple attribute group decision-making method based on normalized bidirectional projection model and generalized knowledge-based entropy measure. J. Ambient Intell. Humaniz. Comput. 2020, 1–16. [Google Scholar] [CrossRef]
- Babatunde, M.; Ighravwe, D. A CRITIC-TOPSIS framework for hybrid renewable energy systems evaluation under techno-economic requirements. J. Proj. Manag. 2019, 4, 109–126. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R. A novel plithogenic TOPSIS-CRITIC model for sustainable supply chain risk management. J. Clean. Prod. 2020, 247, 119586. [Google Scholar] [CrossRef]
- Žižović, M.; Miljković, B.; Marinković, D. Objective methods for determining criteria weight coefficients: A modification of the CRITIC method. Decis. Mak. Appl. Manag. Eng. 2020, 3, 149–161. [Google Scholar] [CrossRef]
- Liu, P.; Gao, H.; Ma, J. Novel green supplier selection method by combining quality function deployment with partitioned Bonferroni mean operator in interval type-2 fuzzy environment. Inf. Sci. 2019, 490, 292–316. [Google Scholar] [CrossRef]
- Liu, P.; Zhu, B.; Wang, P.; Shen, M. An approach based on linguistic spherical fuzzy sets for public evaluation of shared bicycles in China. Eng. Appl. Artif. Intell. 2020, 87, 103295. [Google Scholar] [CrossRef]
- Komazec, N.; Petrović, A. Application of the AHP-VIKOR hybrid model in media selection for informing of endangered in emergency situations. Oper. Res. Eng. Sci. Theory Appl. 2019, 2, 12–23. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Stević, Ž.; Pamučar, D.; Puška, A.; Chatterjee, P. Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of alternatives and ranking according to COmpromise solution (MARCOS). Comput. Ind. Eng. 2020, 140, 106231. [Google Scholar] [CrossRef]
- Ghorabaee, M.K.; Amiri, M.; Sadaghiani, J.S.; Goodarzi, G.H. Multiple criteria group decision-making for supplier selection based on COPRAS method with interval type-2 fuzzy sets. Int. J. Adv. Manuf. Technol. 2014, 75, 1115–1130. [Google Scholar] [CrossRef]
- Xu, D.; Wei, X.; Ding, H.; Bin, H. A New Method Based on PROMETHEE and TODIM for Multi-Attribute Decision-Making with Single-Valued Neutrosophic Sets. Mathematics 2020, 8, 1816. [Google Scholar] [CrossRef]
- Liang, Y.; Qin, J.; Martínez, L.; Liu, J. A heterogeneous QUALIFLEX method with criteria interaction for multi-criteria group decision making. Inf. Sci. 2020, 512, 1481–1502. [Google Scholar] [CrossRef]
- Li, R. Theory and Application on the Fuzzy Multiple Attribute Decision Making; Science Press: Beijing, China, 2002. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E. Linguistic decision analysis: Steps for solving decision problems under linguistic information. Fuzzy Sets Syst. 2000, 115, 67–82. [Google Scholar] [CrossRef]
- Xu, Z. Group decision making with triangular fuzzy linguistic variables. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin/Heidelberg, Germany, 2007; pp. 17–26. [Google Scholar]
- Tanino, T. Fuzzy preference orderings in group decision making. Fuzzy Sets Syst. 1984, 12, 117–131. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Herrera, F.; Chiclana, F.; Luque, M. Some issues on consistency of fuzzy preference relations. Eur. J. Oper. Res. 2004, 154, 98–109. [Google Scholar] [CrossRef]
- Liu, P. Study on Evaluation Methods and Application of Enterprise Informatization Level Based on Fuzzy Multi-Attribute Decision Making; Beijing Jiaotong University: Beijing, China, 2009. [Google Scholar]
- Diakoulaki, D.; Mavrotas, G.; Papayannakis, L. Determining objective weights in multiple criteria problems: The CRITIC method. Comput. Oper. Res. 1995, 22, 763–770. [Google Scholar] [CrossRef]
- Žižović, M.; Pamucar, D. New model for determining criteria weights: Level Based Weight Assessment (LBWA) model. Decis. Mak. Appl. Manag. Eng. 2019, 2, 126–137. [Google Scholar] [CrossRef]
- Žižović, M.; Pamučar, D.; Albijanić, M.; Chatterjee, P.; Pribićević, I. Eliminating Rank Reversal Problem Using a New Multi-Attribute Model—The RAFSI Method. Mathematics 2020, 8, 1015. [Google Scholar] [CrossRef]
- Guan, H.J.; Zhao, A.W.; Shi, G.Q. Research on E-Commerce Precision Poverty Alleviation; Economic Science Press: Beijing, China, 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Primary Attributes | Subattributes |
|---|---|
| Design lean management A | Assembling design management A1 |
| Standardized design management A2 | |
| Personalized design management A3 | |
| Design suitability management A4 | |
| Component production and logistics lean management B | Component production standardization management B1 |
| Component quality control management B2 | |
| Logistics time management B3 | |
| Component lossless transport management B4 | |
| Construction lean management C | Construction mechanization management C1 |
| Environmental construction management C2 | |
| Construction process management C3 | |
| Construction safety management C4 | |
| Organizational collaborative lean management D | Organizational integration management D1 |
| Organizational trust management D2 | |
| Cooperative intention management D3 | |
| Organizational collaboration technology management D4 | |
| Information collaborative lean management E | Information accuracy management E1 |
| Information delivery time management E2 | |
| Information transfer cost management E3 |
| ([0.245, 0.267, 0.298, 0.321],) | ([0.256, 0.276, 0.281, 0.285],) | ([0.203, 0.237, 0.271, 0.305],) | |
| ([0.305, 0.343, 0.381, 0.419],) | ([0.312, 0.343, 0.365, 0.392],) | ([0.076, 0.114, 0.153, 0.191],) | |
| ([0.276, 0.322, 0.368, 0.414],) | ([0.356, 0.367, 0.373, 0.401],) | ([0.184, 0.230, 0.276, 0.322],) | |
| ([0.309, 0.347, 0.386, 0.425],) | ([0.398, 0.401, 0.412, 0.433],) | ([0.155, 0.193, 0.231, 0.270],) | |
| ([0.175, 0.219, 0.263, 0.307],) | ([0.350, 0.394, 0.438, 0.482],) | ([0.175, 0.219, 0.263, 0.307],) | |
| ([0.345, 0.389, 0.432, 0.475],) | ([0.234, 0.245, 0.259, 0.302],) | ([0.086, 0.130, 0.173, 0.216],) | |
| ([0.253, 0.284, 0.316, 0.348],) | ([0.312, 0.334, 0.345, 0.356],) | ([0.253, 0.284, 0.316, 0.348],) | |
| ([0.231, 0.270, 0.309, 0.347],) | ([0.356, 0.367, 0.381, 0.392],) | ([0.309, 0.347, 0.386, 0.424],) | |
| ([0.305, 0.343, 0.381, 0.419],) | ([0.305, 0.343, 0.381, 0.419],) | ([0.076, 0.114, 0.153, 0.191],) | |
| ([0.277, 0.312, 0.346, 0.381],) | ([0.346, 0.381, 0.381, 0.381],) | ([0.139, 0.173, 0.208, 0.242],) | |
| ([0.162, 0.203, 0.243, 0.284],) | ([0.162, 0.203, 0.243, 0.284],) | ([0.324, 0.365, 0.405, 0.446],) | |
| ([0.276, 0.322, 0.368, 0.414],) | ([0.184, 0.230, 0.276, 0.322],) | ([0.184, 0.230, 0.276, 0.322],) | |
| ([0.222, 0.259, 0.296, 0.333],) | ([0.296, 0.333, 0.370, 0.408],) | ([0.222, 0.259, 0.296, 0.333],) | |
| ([0.253, 0.284, 0.316, 0.348],) | ([0.253, 0.284, 0.316, 0.348],) | ([0.253, 0.284, 0.316, 0.348],) | |
| ([0.250, 0.313, 0.374, 0.437],) | ([0.250, 0.313, 0.374, 0.437],) | ([0.116, 0.174, 0.233, 0.291],) | |
| ([0.324, 0.365, 0.405, 0.446],) | ([0.162, 0.203, 0.243, 0.284],) | ([0.162, 0.203, 0.243, 0.284],) | |
| ([0.198, 0.248, 0.296, 0.346],) | ([0.245, 0.286, 0.327, 0.367],) | ([0.010, 0.050, 0.099, 0.149],) | |
| ([0.327, 0.367, 0.408, 0.449],) | ([0.209, 0.261, 0.312, 0.365],) | ([0.082,0.123,0.164,0.204],) | |
| ([0.364, 0.455, 0.545, 0.636],) | ([0.395, 0.445, 0.494, 0.544],) | ([0.209, 0.261, 0.312, 0.365],) |
| Weights | Ranking | ||
|---|---|---|---|
| Subjective weights | |||
| Combination weights | |||
| Subjective weights | |||
| Combination weights | |||
| Subjective weights | |||
| Combination weights |
| Weights | Ranking | |
|---|---|---|
| Subjective weights | ||
| Objective weights | ||
| Combination weights |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Liu, Y. Extended VIKOR-QUALIFLEX Method Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information for Multiple Attribute Decision-Making with Unknown Attribute Weight. Mathematics 2021, 9, 37. https://doi.org/10.3390/math9010037
Li Y, Liu Y. Extended VIKOR-QUALIFLEX Method Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information for Multiple Attribute Decision-Making with Unknown Attribute Weight. Mathematics. 2021; 9(1):37. https://doi.org/10.3390/math9010037
Chicago/Turabian StyleLi, Ye, and Yisheng Liu. 2021. "Extended VIKOR-QUALIFLEX Method Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information for Multiple Attribute Decision-Making with Unknown Attribute Weight" Mathematics 9, no. 1: 37. https://doi.org/10.3390/math9010037
APA StyleLi, Y., & Liu, Y. (2021). Extended VIKOR-QUALIFLEX Method Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information for Multiple Attribute Decision-Making with Unknown Attribute Weight. Mathematics, 9(1), 37. https://doi.org/10.3390/math9010037