Classifying a Lending Portfolio of Loans with Dynamic Updates via a Machine Learning Technique



Abstract
1. Introduction
2. Background on Machine Learning
2.1. ML
- This type of learning through induction needs a lot of instances to get good knowledge.
- Since the process of learning is based upon the events that happened previously, there would not be a 100% guarantee to get a very accurate model for predicting in the future.
- Nonparametric discriminants [27]. a method of this category is the ANN, which tries to divide the original data space into various regions. In the simple case of a binary classification technique, The space of data is put into two areas.
- Similarity-based classifiers [10]. Since the financial data sets basically include more variables than samples, such techniques are more used in financial applications.
2.2. KNN
3. Lending Portfolio and Features
- The annualized-based maturity which indicates the time horizon for each loan that must be paid back thoroughly.
- The credit spread which under each ranking category specifies the component of a loan’s interest rate compensating the lender, i.e., the bank, for the credit risk of the borrower.
- The factor of remaining credit, which is a credit allocated to each individual by a bank based on their bank account turnovers or some amount of the requested loan (for instance, 20%) inside their accounts at/or prior to the time of the loan receipt. This is a common approach for some banks which do not intend to increase the loan’s interest according to their Central Bank regulations, while they are not eager to stay at the current national interest rates, see, e.g., [12]. This unfortunately helps the banks to hoodwink the public audience and earn much more interest rates for each loan by blocking 20% (more or less) of the whole amount of each loan (or its equivalent approaches.)
4. Quality of a Lending Portfolio

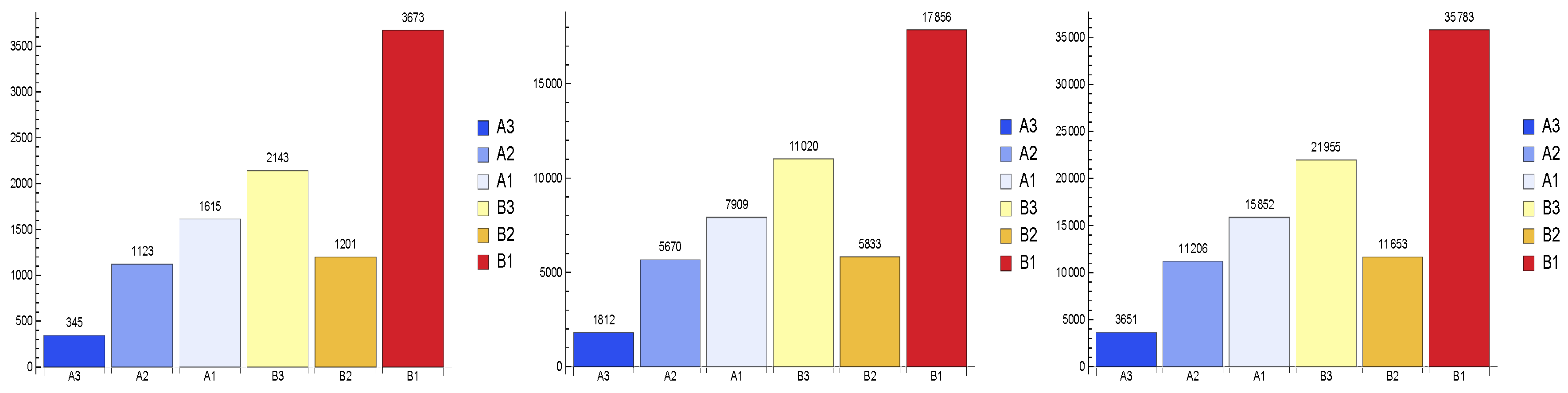
4.1. Variable Importance
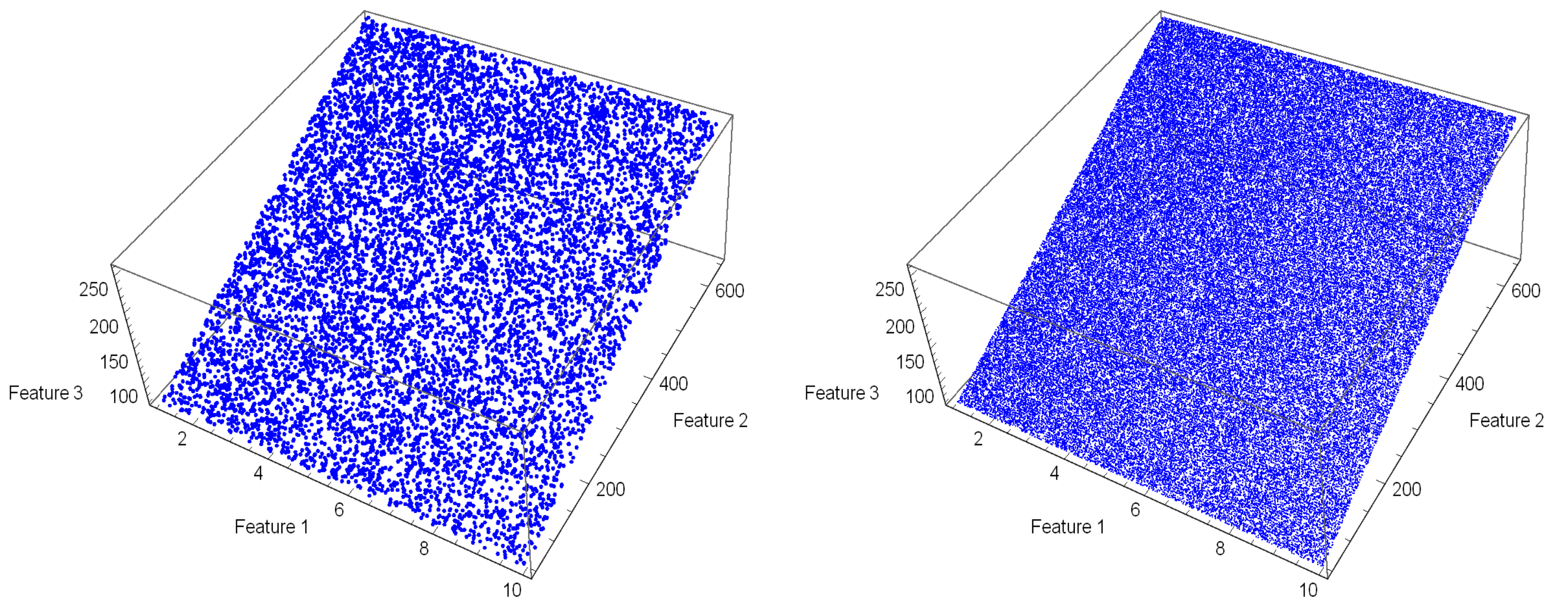
4.2. Data
4.3. General Observations
4.4. Dynamic Update of The Portfolio
4.5. Experiments: Top Probabilities
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- De Prado, M.L. Advances in Financial Machine Learning; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Singapore, 2020; Volume 28, pp. 1639–1670. [Google Scholar]
- Nazemi, A.; Heidenreich, K.; Fabozzi, F.J. Improving corporate bond recovery rate prediction using multi-factor support vector regressions. Eur. J. Oper. Res. 2018, 271, 664–675. [Google Scholar] [CrossRef]
- Pławiak, P.; Abdar, M.; Rajendra Acharya, U. Application of new deep genetic cascade ensemble of SVM classifiers to predict the Australian credit scoring. Appl. Soft Comput. J. 2019, 84, 105–740. [Google Scholar] [CrossRef]
- Tan, Z.; Yan, Z.; Zhu, G. Stock selection with random forest: An exploitation of excess return in the Chinese stock market. Heliyon 2019, 5, e02310. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.; Pierdzioch, C.; Vivian, A.J.; Wohar, M.E. The predictive value of inequality measures for stock returns: An analysis of long-span UK data using quantile random forests. Financ. Res. Lett. 2019, 29, 315–322. [Google Scholar] [CrossRef]
- Abdar, M.; Wijayaningrum, V.N.; Hussain, S.; Alizadehsani, R.; Pławiak, P.; Acharya, U.R.; Makarenkov, V. IAPSO-AIRS A novel improved machine learning-based system for wart disease treatment. J. Med. Syst. 2019, 220, 43. [Google Scholar] [CrossRef]
- Tuncer, T.; Ertam, F.; Dogan, S.; Aydemir, E.; Pławiak, P. Ensemble residual network-based gender and activity recognition method with signals. J. Supercomput. 2020, 76, 2119–2138. [Google Scholar] [CrossRef]
- Kandala, R.N.V.P.S.; Dhuli, R.; Pławiak, P.; Naik, G.R.; Moeinzadeh, H.; Gargiulo, G.D.; Gunnam, S. Towards real-time heartbeat classification: Evaluation of nonlinear morphological features and voting method. Sensors 2019, 19, 5079. [Google Scholar] [CrossRef] [PubMed]
- Henrique, B.M.; Sobreiro, V.A.; Kimura, H. Literature review: Machine learning techniques applied to financial market prediction. Expert Syst. Appl. 2019, 124, 226–251. [Google Scholar] [CrossRef]
- Weinan, E. Machine learning and computational mathematics. Commun. Comput. Phys. 2020, 28, 1639–1670. [Google Scholar]
- Le, H.H.; Viviani, J.-L. Predicting bank failure: An improvement by implementing a machine-learning approach to classical financial ratios. Res. Int. Busin. Financ. 2018, 44, 16–25. [Google Scholar] [CrossRef]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Owusu-Ansah, E.D.-G.J.; Barnes, B.; Donkoh, E.K.; Appau, J.; Effah, B.; Nartey, M.M. Quantifying economic risk: An application of extreme value theory for measuring fire outbreaks financial loss. Financ. Math. Appl. 2019, 4, 1–12. [Google Scholar]
- Carbo-Valverde, S.; Cuadros-Solas, P.; Rodríguez-Fernández, F. A machine learning approach to the digitalization of bank customers: Evidence from random and causal forests. PLoS ONE 2020, 15, e0240362. [Google Scholar] [CrossRef] [PubMed]
- Cuadros-Solas, P.J.; Salvador Muñoz, C. Potential spillovers from the banking sector to sovereign credit ratings. Appl. Econ. Lett. 2020. [Google Scholar] [CrossRef]
- Khandani, A.E.; Kim, A.J.; Lo, A.W. Consumer credit-risk models via machine-learning algorithms. J. Bank. Financ. 2010, 34, 2767–2787. [Google Scholar] [CrossRef]
- De Moor, L.; Luitel, P.; Sercu, P.; Vanpee, R. Subjectivity in Sovereign credit ratings. J. Bank. Financ. 2010, 88, 366–392. [Google Scholar] [CrossRef]
- Klaas, J. Machine Learning for Finance; Packt Publishing: Birmingham, UK, 2019. [Google Scholar]
- Eller, P.R.; Cheng, J.-R.C.; Maier, R.S. Dynamic linear solver selection for transient simulations using multi-label classifiers. Procedia Comput. Sci. 2012, 9, 1523–1532. [Google Scholar] [CrossRef][Green Version]
- Kim, H.; Cho, H.; Ryu, D. Corporate default predictions using machine learning: Literature review. Sustainability 2020, 12, 6325. [Google Scholar] [CrossRef]
- Hammad, M.; Pławiak, P.; Wang, K.; Rajendra Acharya, U. ResNet-Attention model for human authentication using ECG signals. Expert Syst. 2020, e12547. [Google Scholar] [CrossRef]
- Hlivka, I. Machine Learning in Finance: Data Classification Approach; Quant Solutions Group: London, UK, 2015. [Google Scholar]
- Sirignano, J.; Sadhwani, A.; Giesecke, K. Deep learning for mortgage risk. J. Financ. Econom. 2020, 1–20. [Google Scholar] [CrossRef]
- Yu, Q.; Miche, Y.; Séverin, E.; Lendasse, A. Bankruptcy prediction using extreme learning machine and financial expertise. Neurocomputing 2014, 128, 296–302. [Google Scholar] [CrossRef]
- Galindo, J.; Tamayo, P. Credit risk assessment using statistical and machine learning basic methodology and risk modeling applications. Comput. Econ. 2000, 15, 107–143. [Google Scholar] [CrossRef]
- Son, Y.; Byun, H.; Lee, J. Nonparametric machine learning models for predicting the credit default swaps: An empirical study. Expert Sys. Appl. 2016, 58, 210–220. [Google Scholar] [CrossRef]
- Jaafar, H.B.; Mukahar, N.B.; Ramli, D.A.B. A methodology of nearest neighbor: Design and comparison of biometric image database. In Proceedings of the 2016 IEEE Student Conference on Research and Development (SCOReD), Kuala Lumpur, Malaysia, 13–14 December 2016; pp. 1–6. [Google Scholar]
- Döring, M.; Györfi, L.; Walk, H. Rate of convergence of k-nearest-neighbor classification rule. J. Mach. Lear. Res. 2018, 18, 1–16. [Google Scholar]
- Elseberg, J.; Magnenat, S.; Siegwart, R.; Nüchter, A. Comparison on nearest-neigbour-search strategies and implementations for efficient shape registration. J. Soft. Eng. Robot. 2012, 3, 2–12. [Google Scholar]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications; SIAM: Philadelphia, PA, USA, 2007. [Google Scholar]
- Teknomo, K. K-Nearest Neighbor Tutorial. 2019. Available online: https://people.revoledu.com/kardi/tutorial/KNN/ (accessed on 16 November 2020).
- Vieira, J.R.D.C.; Barboza, F.; Sobreiro, V.A.; Kimura, H. Machine learning models for credit analysis improvements: Predicting low-income families’ default. Appl. Soft Comput. 2019, 83, 105640. [Google Scholar] [CrossRef]
- Moayedi, H.; Bui, D.T.; Kalantar, B.; Foong, L.K. Machine-learning-based classification approaches toward recognizing slope stability failure. Appl. Sci. 2019, 9, 4638. [Google Scholar] [CrossRef]
- Wu, D.; Fang, M.; Wang, Q. An empirical study of bank stress testing for auto loans. J. Financ. Stab. 2018, 39, 79–89. [Google Scholar] [CrossRef]
- Cremers, K.J.M.; Driessen, J.; Maenhout, P. Explaining the level of credit spreads: Option-implied jump risk premia in a firm value model. Rev. Financ. Stud. 2008, 21, 2209–2242. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Chinchor, N. MUC-4 Evaluation Metrics. Proceeding of the Fourth Message Understanding Conference, McLean, Virginia, 16–18 June 1992; pp. 22–29. [Google Scholar]
- Antonov, A. Variable Importance Determination by Classifiers Implementation in Mathematica; Lecture Notes; Wolfram: Windermere, FL, USA, 2015. [Google Scholar]
- Georgakopoulos, N.L. Illustrating Finance Policy with Mathematica; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
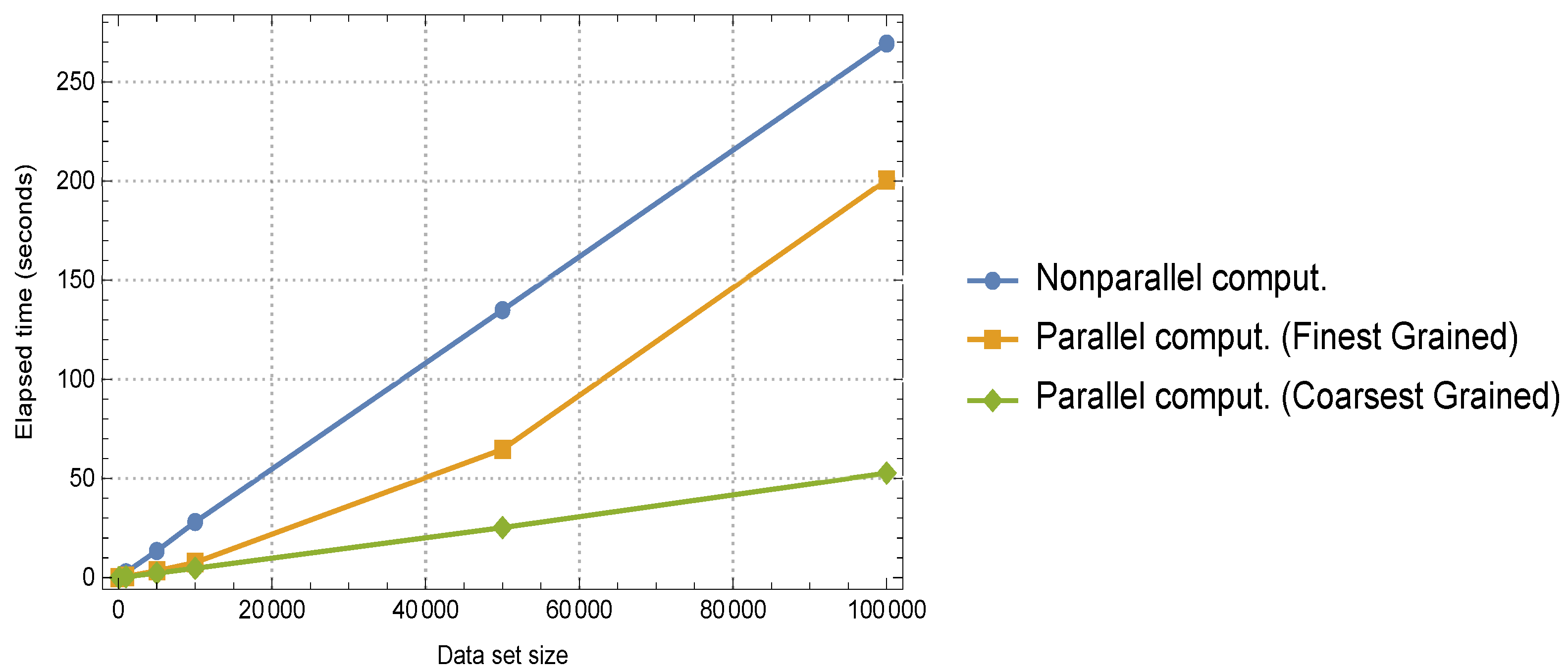
- Kwiatkowski, J. Evaluation of parallel programs by measurement of its granularity. Parallel Process. Appl. Math. 2002, 2328, 145–153. [Google Scholar]







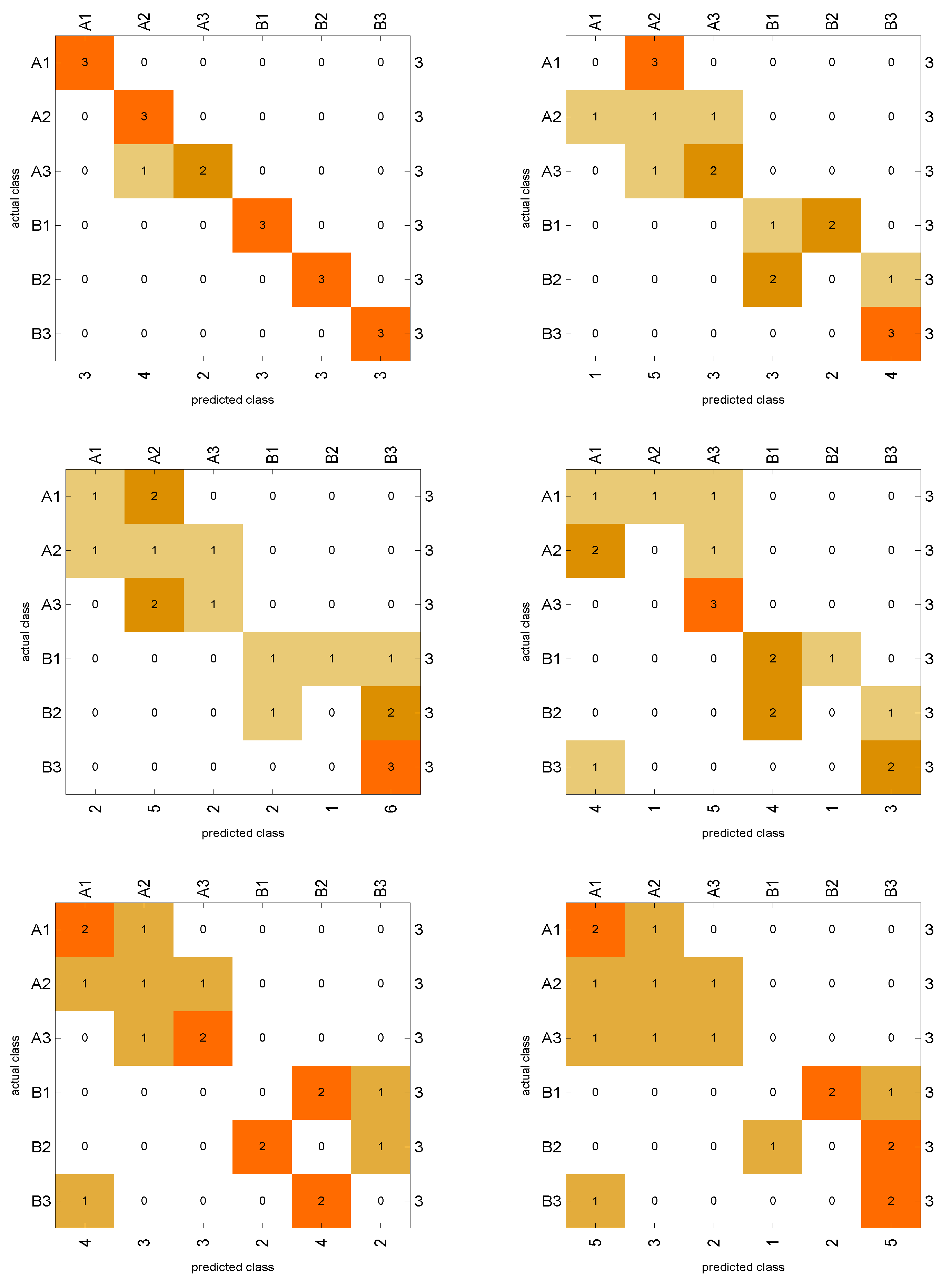{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A1 | A2 | A3 | B1 | B2 | B3 | Accuracy | |
|---|---|---|---|---|---|---|---|
| 1.00 | 0.85 | 0.80 | 1.00 | 1.00 | 1.00 | 94% | |
| 0.00 | 0.25 | 0.66 | 0.33 | 0.00 | 0.85 | 38% | |
| 0.40 | 0.25 | 0.40 | 0.40 | 0.00 | 0.66 | 38% | |
| 0.28 | 0.00 | 0.75 | 0.57 | 0.00 | 0.66 | 44% | |
| 0.57 | 0.33 | 0.66 | 0.00 | 0.00 | 0.00 | 27% | |
| 0.50 | 0.33 | 0.40 | 0.00 | 0.00 | 0.50 | 33% |
| KNN | RF | SVM | ANN | |
|---|---|---|---|---|
| Sub-method | Octree, Neighbors number = 1 | Feature fraction = 0.57, Leaf size = 3, Tree number = 50 | Kernel type = Radial basis function, Gamma scaling parameter = 0.34, Multi class strategy = one vs. one | Network depth = 8, Max. training rounds = 1000 |
| Single evaluation time | 1.45 ms/example | 3.77 ms/example | 9.57 ms/example | 2.79 ms/example |
| Batch evaluation speed | 144. example/ms | 44.4 example/ms | 9.09 example/ms | 53.4 example/ms |
| Loss | ||||
| Model memory | 115 kB | 198 kB | 212 kB | 358 kB |
| Training time | 208 ms | 224 ms | 819 ms | 2.46 s |
| Techniques→ | KNN () | SVM | ANN | |||
|---|---|---|---|---|---|---|
| Features↓ | Shuffled Accuracy | Ratio | Shuffled Accuracy | Ratio | Shuffled Accuracy | Ratio |
| Maturity | 0.51 | 0.54 | 0.33 | 0.67 | 0.36 | 1.10 |
| Credit spread | 0.22 | 0.24 | 0.21 | 0.42 | 0.15 | 0.47 |
| Remaining credit | 0.44 | 0.47 | 0.33 | 0.67 | 0.40 | 1.21 |
| Maturity | Credit Spread | Remaining Credit | ||||||
|---|---|---|---|---|---|---|---|---|
| 2.5 | 100 | 25 | 0.055 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 |
| 2.5 | 100 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 100 | 75 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 100 | 100 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 200 | 25 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 200 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 200 | 75 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 200 | 100 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 300 | 25 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 300 | 50 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 300 | 75 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 300 | 100 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 400 | 25 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 2.5 | 400 | 50 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 2.5 | 400 | 75 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 2.5 | 400 | 100 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 2.5 | 500 | 25 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 | 0.055 |
| 2.5 | 500 | 50 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 |
| 2.5 | 500 | 75 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 |
| 2.5 | 500 | 100 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 |
| 5. | 100 | 25 | 0.055 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 |
| 5. | 100 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 100 | 75 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 100 | 100 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 200 | 25 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 200 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 200 | 75 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 200 | 100 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 300 | 25 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 300 | 50 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 300 | 75 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 300 | 100 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 400 | 25 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 5. | 400 | 50 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 5. | 400 | 75 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 5. | 400 | 100 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 5. | 500 | 25 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 | 0.055 |
| 5. | 500 | 50 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 |
| 5. | 500 | 75 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 |
| 5. | 500 | 100 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 | 0.055 |
| 7.5 | 100 | 25 | 0.055 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 |
| 7.5 | 100 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 100 | 75 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 100 | 100 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 200 | 25 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 200 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 200 | 75 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 200 | 100 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 300 | 25 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 300 | 50 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 300 | 75 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 300 | 100 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 400 | 25 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 |
| 7.5 | 400 | 50 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 7.5 | 400 | 75 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 7.5 | 400 | 100 | 0.055 | 0.055 | 0.055 | 0.055 | 0.055 | 0.722 |
| 10. | 100 | 25 | 0.055 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 |
| 10. | 100 | 50 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 10. | 100 | 75 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
| 10. | 100 | 100 | 0.055 | 0.722 | 0.055 | 0.055 | 0.055 | 0.055 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soleymani, F.; Masnavi, H.; Shateyi, S. Classifying a Lending Portfolio of Loans with Dynamic Updates via a Machine Learning Technique. Mathematics 2021, 9, 17. https://doi.org/10.3390/math9010017
Soleymani F, Masnavi H, Shateyi S. Classifying a Lending Portfolio of Loans with Dynamic Updates via a Machine Learning Technique. Mathematics. 2021; 9(1):17. https://doi.org/10.3390/math9010017
Chicago/Turabian StyleSoleymani, Fazlollah, Houman Masnavi, and Stanford Shateyi. 2021. "Classifying a Lending Portfolio of Loans with Dynamic Updates via a Machine Learning Technique" Mathematics 9, no. 1: 17. https://doi.org/10.3390/math9010017
APA StyleSoleymani, F., Masnavi, H., & Shateyi, S. (2021). Classifying a Lending Portfolio of Loans with Dynamic Updates via a Machine Learning Technique. Mathematics, 9(1), 17. https://doi.org/10.3390/math9010017