Robust Reliability Estimation for Lindley Distribution—A Probability Integral Transform Statistical Approach


Abstract
1. Introduction
2. Lindley Distribution and Reliability Measures
3. Several Estimators of the Parameter of the Lindley Distribution
3.1. ML Estimator
3.2. OLS and WLS Estimators
4. M-Estimators
4.1. Efficiency Measure: Asymptotic Relative Efficiency
4.2. Robustness Measures: Influence Function and Breakdown Point
5. New Robust M-Estimator for the Parameter of the Lindley Distribution
5.1. Probability Integral Transform Statistic Estimator
5.2. ARE of the PITS Estimator
5.3. BP of PITS Estimator
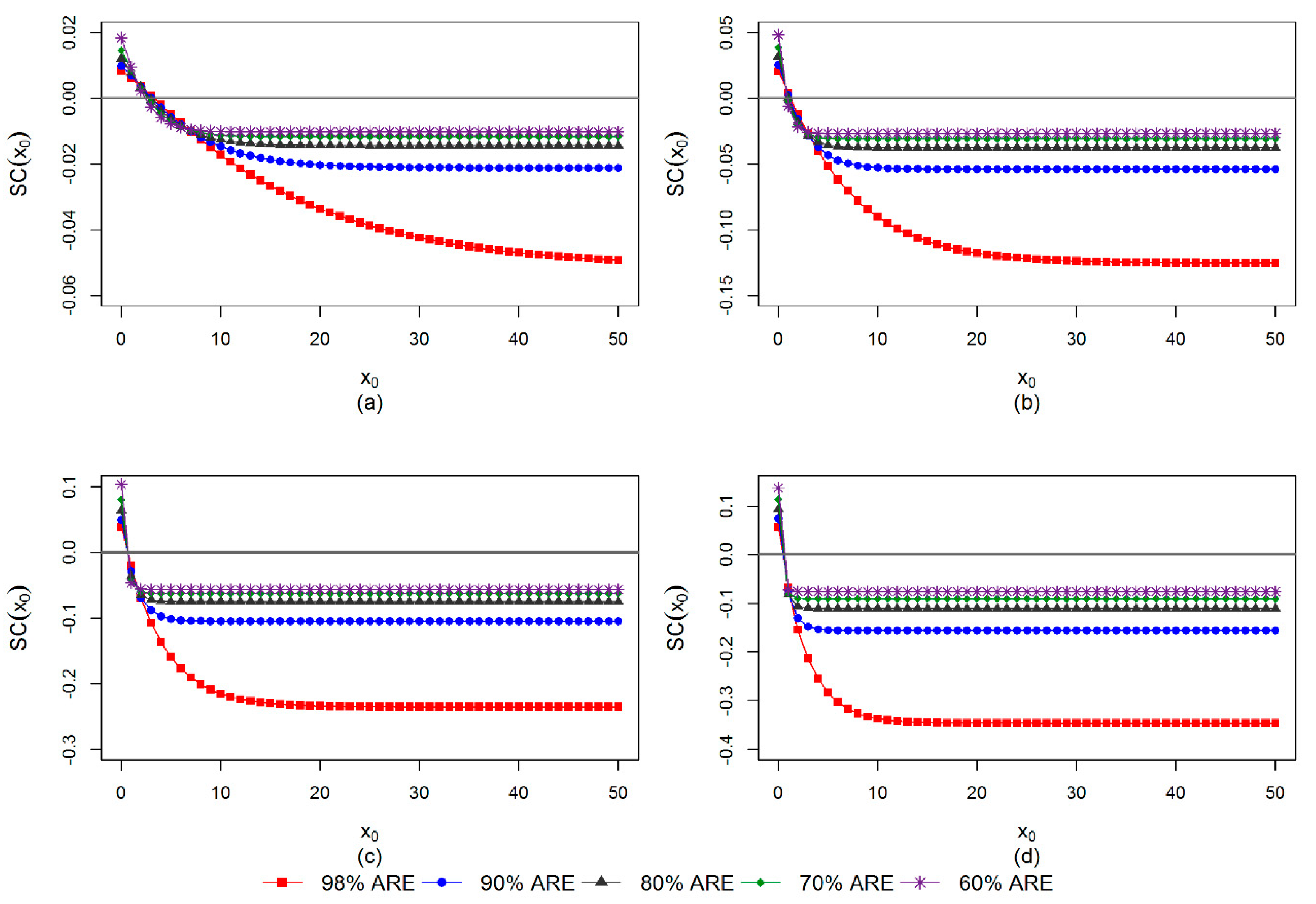
5.4. IF of PITS Estimator
6. Simulation Study
6.1. Simulation Framework
- Step 1:
- Generate a random variable from the Lindley distribution for two sample size settings, that is, small (n = 30, 50, 70) and large (n = 100, 300, 500), with parameter θ = 0.5, 1, 2, 3.
- Step 2:
- Randomly select some observations and replace them with outliers generated from the Lindley distribution with parameter 0.05θ. Note that by multiplying the true value of parameter θ with 0.05, the Lindley distribution will have heavier upper tail and will produce larger values of random variables, which are interpreted as outliers. For the small sample sizes, generate outliers for several fixed numbers, m = 0, 1, 3, 5. For the large sample sizes, simulate outliers for several fixed proportions, ε = 0%, 1%, 5%, 10%.
- Step 3:
- Estimate the parameter θ using the ML, OLS, WLS and PITS (98%, 90%, 80%, 70% and 60% AREs) methods.
- Step 4:
- Repeat steps 1–3 10,000 times.
- Step 5:
- Calculate the performance of each estimator using the percentage relative root mean square error (RRMSE). For a given true value of parameter θ, the RRMSE is given by the following:where is the estimated parameter for the i-th (i = 1, 2,…, N) sample and N is the number of simulated samples. A smaller RRMSE value indicates that the estimator is more accurate and precise. Thus, any estimation method that minimizes the RRMSE provides the best estimation of the parameter θ.
6.2. Simulation Results
- In the cases of both small and large sample sizes (Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8), we found the following:
- When there are no outliers (m = 0 and ε = 0%) in the data, both the ML and PITS (98% ARE) estimators perform similarly and slightly outperform the OLS and WLS estimators.
- In the presence of outliers, the performance of the ML estimator is much worse than that of the other estimators. As the degree of contamination increases, the performance of the ML estimator deteriorates significantly.
- The OLS and WLS estimators are quite robust and offer some protection against outliers.
- As the sample size increases, for all the cases considered, the performance of all the estimators improve, with the RRMSE values becoming smaller.
- When the number of outliers is small (m = 1), the PITS (90% ARE) estimator performs best, that is, slightly better than the OLS and WLS estimators.
- When the number of outliers is moderate (m = 3), the OLS, WLS and PITS (70% and/or 60% AREs) estimators perform almost equally well and are considered to be the best methods for this particular case.
- When the number of outliers is large (m = 5), the PITS (60% ARE) estimator performs best, that is, slightly better than the OLS and WLS estimators.
- When the proportion of outliers is small (ε = 1%), for n = 100, the PITS (90% ARE) estimator performs best, that is, slightly better than the OLS and WLS estimators. For n = 300, 500, the OLS, WLS and PITS (90% and 80% AREs) estimators perform almost equally well and are considered to be the best methods for this particular case.
- When the proportion of outliers is moderate (ε = 5%), for n = 100, the OLS and PITS (70% ARE) estimators perform very similarly, slightly outperforming the WLS estimator. For n = 300, 500, the PITS (60% ARE) estimator performs best, outperforming all the other methods.
- When the proportion of outliers is large (ε = 10%), the performance of the PITS (60% ARE) estimator also surpasses that of other methods.
6.3. Some Guidelines for Selecting the Appropriate ARE of PITS Estimator
- When there are no outliers in the data, the PITS (98% ARE) estimator should be applied for estimating parameter θ.
- For small sample size setting, that is, n < 30:
- When number of outliers m ≤ 3, the PITS (60–90% AREs) estimators are preferable for estimating parameter θ.
- When number of outliers m ≥ 4, the PITS (50–60% AREs) estimators are preferable for estimating parameter θ.
- For small sample size setting, that is, 30 ≤ n ≤ 70:
- When number of outliers m ≤ 2, the PITS (80–90% AREs) estimators are recommended for estimating parameter θ.
- When number of outliers 3 ≤ m ≤ 4, the PITS (60–80% AREs) estimators are preferable for estimating parameter θ.
- When number of outliers m ≥ 5, the PITS (50–60% AREs) estimators are recommended for estimating parameter θ.
- For large sample size setting, that is, 70 < n ≤ 100:
- When number of outliers m ≤ 3, the PITS (70–90% AREs) estimators are recommended for estimating parameter θ.
- When number of outliers 4 ≤ m ≤ 6, the PITS (60–70% AREs) estimators are recommended for estimating parameter θ.
- When number of outliers m ≥ 7, the PITS (50–60% AREs) estimators are preferable for estimating parameter θ.
- For large sample size setting, that is, n > 100:
- When proportion of outliers ε ≤ 3%, the PITS (80–90% AREs) estimators are preferable for estimating parameter θ.
- When proportion of outliers 3% < ε ≤ 7%, the PITS (60–80% AREs) estimators are preferable for estimating parameter θ.
- When proportion of outliers ε > 7%, the PITS (50–60% AREs) estimators are recommended for estimating parameter θ.
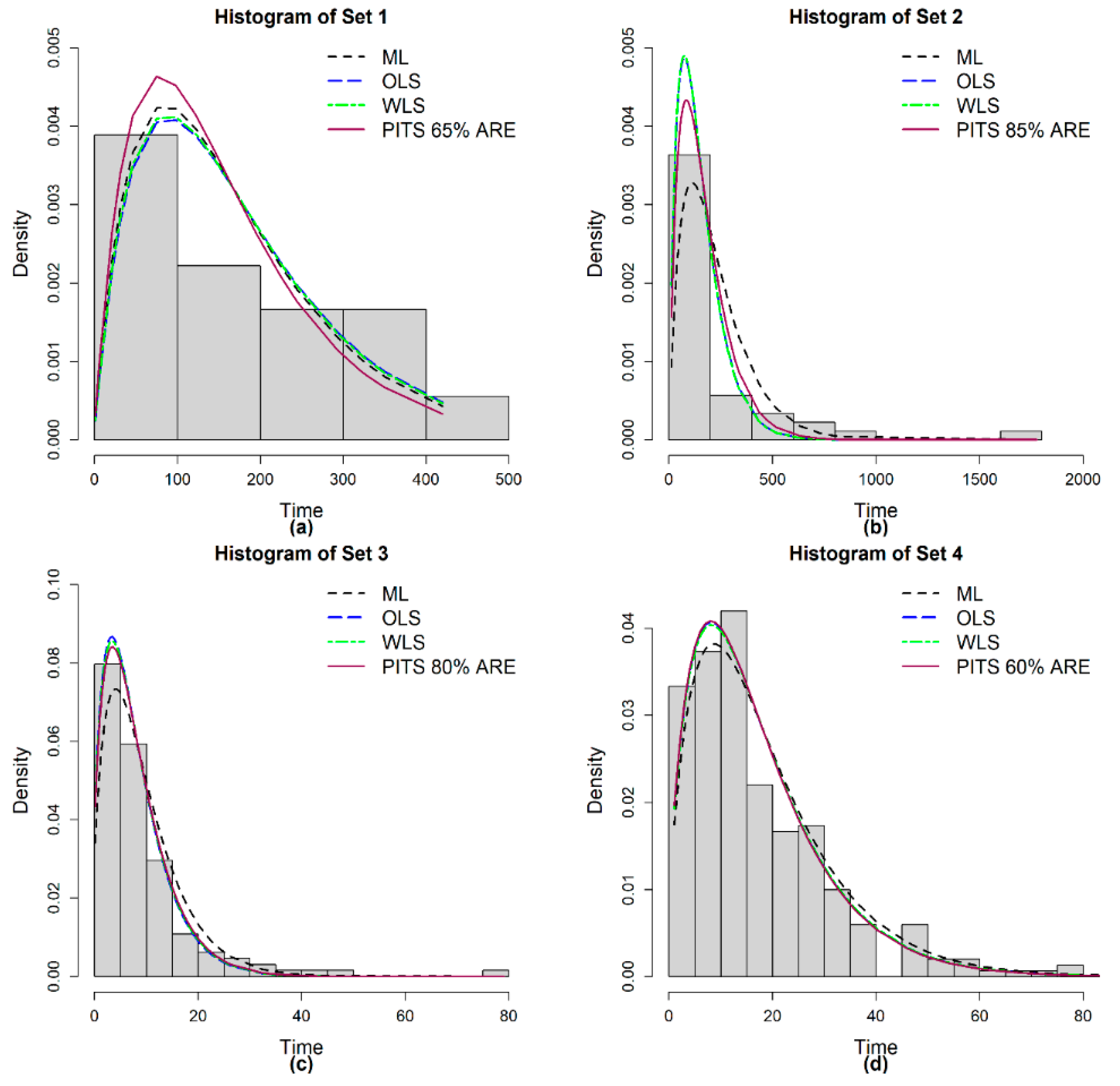
7. Applications and Discussion
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AIC | Akaike information criterion |
| ARE | Asymptotic relative efficiency |
| BIC | Bayesian information criterion |
| BP | Breakdown point |
| CDF | Cumulative distribution function |
| IF | Influence function |
| K-S | Kolmogorov-Smirnov |
| LBP | Lower breakdown point |
| ML | Maximum likelihood |
| MOM | Method of moments |
| MTTF | Mean time to failure |
| OLS | Ordinary least-squares |
| Probability density function | |
| PITS | Probability integral transform |
| RRMSE | Relative root mean square error |
| UBP | Upper breakdown point |
| WLS | Weighted least-squares |
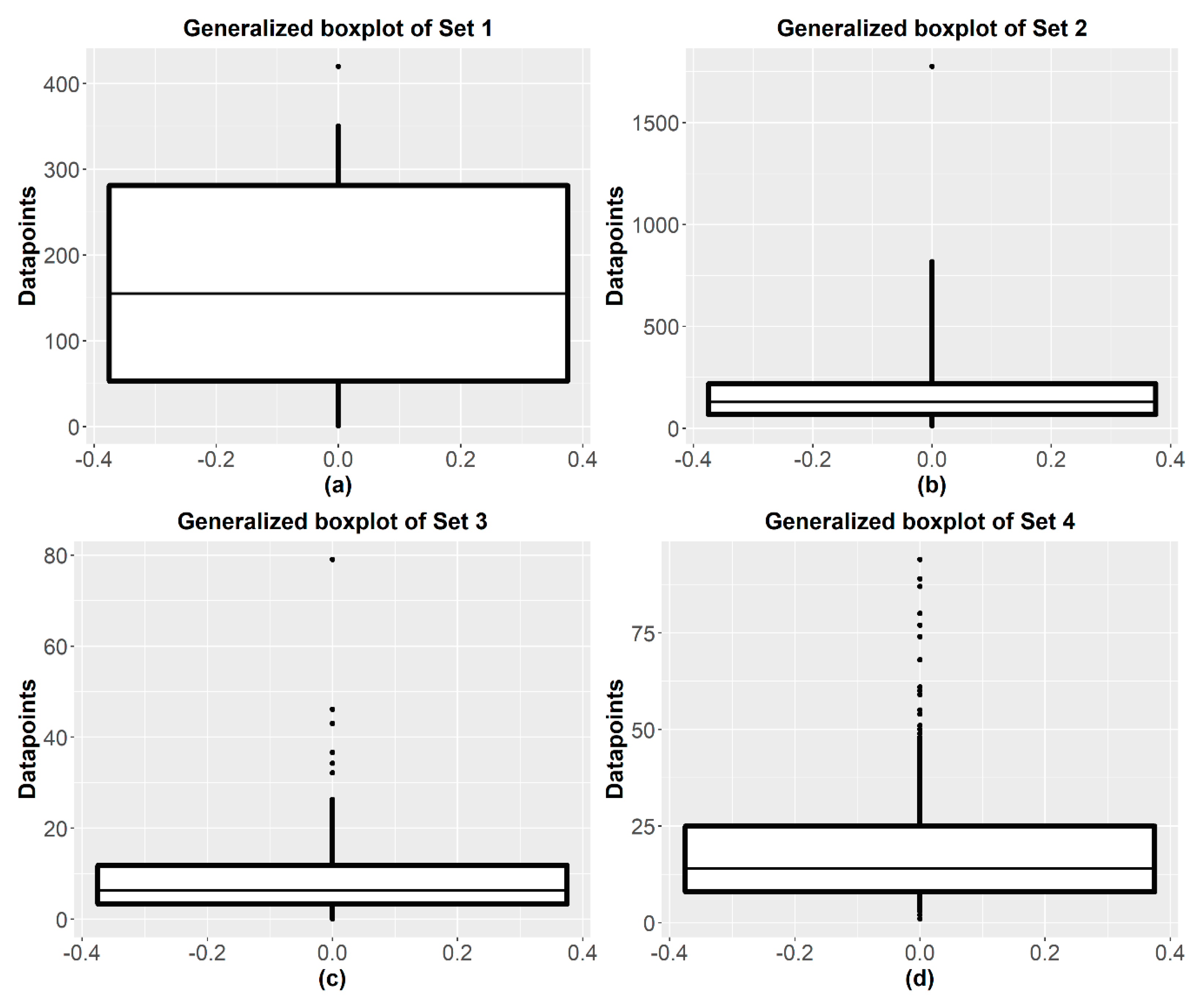
Appendix A. Real Data Sets
Appendix B. R Commands for PITS Estimator
### PITS Estimator ###
flin<-function(theta,data,tau){
n<-length(data)
fx<-(sum(((1+((theta *data)/(1+theta)))*exp(-theta*data))^tau)/n)-(1/(tau+1))
return(fx)
}
#solve using bisection method
# a-lower interval; b-upper interval
pits<-function(data,tau,a,b){
theta<-uniroot(flin,interval=c(a,b),data=data,tau=tau)$root
return(theta)
}
References
- IEEE. IEEE Standard Computer Dictionary: A Compilation of IEEE Standard Computer Glossaries; IEEE Std 610; IEEE Press: New York, NY, USA, 1991; pp. 1–217. [Google Scholar]
- Murthy, D.N.P.; Rausand, M.; Østerås, T. Product Reliability: Specification and Performance; Springer: London, UK, 2008. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; John Wiley & Sons: New York, NY, USA, 2014. [Google Scholar]
- Blischke, W.R.; Murthy, D.N.P. Reliability: Modeling, Prediction, and Optimization; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Lee, E.T.; Wang, J. Statistical Methods for Survival Data Analysis, 3rd ed.; John Wiley & Sons: New York, NY, USA, 2003; Volume 476. [Google Scholar]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Krishna, H.; Kumar, K. Reliability estimation in Lindley distribution with progressively type II right censored sample. Math. Comput. Simul. 2011, 82, 281–294. [Google Scholar] [CrossRef]
- Lindley, D.V. Fiducial Distributions and Bayes’ Theorem. J. R. Stat. Soc. Ser. B 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Nie, J.; Gui, W. Parameter estimation of Lindley distribution based on progressive type-II censored competing risks data with binomial removals. Mathematics 2019, 7, 646. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Alqallaf, F.; Al-Mutairi, D.K.; Husain, H.A. A two-parameter weighted Lindley distribution and its applications to survival data. Math. Comput. Simul. 2011, 81, 1190–1201. [Google Scholar] [CrossRef]
- Nadarajah, S.; Bakouch, H.S.; Tahmasbi, R. A generalized Lindley distribution. Sankhya B 2011, 73, 331–359. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Al-Zahrani, B.M.; Al-Shomrani, A.A.; Marchi, V.A.A.; Louzada, F. An extended Lindley distribution. J. Korean Stat. Soc. 2012, 41, 75–85. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K.; Balakrishnan, N.; Al-Enezi, L.J. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Oluyede, B.O.; Yang, T. A new class of generalized Lindley distributions with applications. J. Stat. Comput. Simul. 2015, 85, 2072–2100. [Google Scholar] [CrossRef]
- Ashour, S.K.; Eltehiwy, M.A. Exponentiated power Lindley distribution. J. Adv. Res. 2015, 6, 895–905. [Google Scholar] [CrossRef]
- Asgharzadeh, A.; Bakouch, H.S.; Nadarajah, S.; Sharafi, F. A new weighted lindley distribution with application. Brazilian J. Probab. Stat. 2016, 30, 1–27. [Google Scholar] [CrossRef]
- Kemaloglu, S.A.; Yilmaz, M. Transmuted two-parameter Lindley distribution. Commun. Stat. Theory Methods 2017, 46, 11866–11879. [Google Scholar] [CrossRef]
- MirMostafaee, S.M.T.K.; Alizadeh, M.; Altun, E.; Nadarajah, S. The exponentiated generalized power Lindley distribution: Properties and applications. Appl. Math. 2019, 34, 127–148. [Google Scholar] [CrossRef]
- Barnett, V.; Lewis, T. Outliers in Statistical Data, 3rd ed.; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Huber, S. (Non-)robustness of maximum likelihood estimators for operational risk severity distributions. Quant. Financ. 2010, 10, 871–882. [Google Scholar] [CrossRef]
- Ahmed, E.S.; Volodin, A.I.; Hussein, A.A. Robust weighted likelihood estimation of exponential parameters. IEEE Trans. Reliab. 2005, 54, 389–395. [Google Scholar] [CrossRef]
- Shahriari, H.; Radfar, E.; Samimi, Y. Robust estimation of systems reliability. Qual. Technol. Quant. Manag. 2017, 14, 310–324. [Google Scholar] [CrossRef]
- Boudt, K.; Caliskan, D.; Croux, C. Robust explicit estimators of Weibull parameters. Metrika 2011, 73, 187–209. [Google Scholar] [CrossRef]
- Adatia, A. Robust estimators of the 2-parameter gamma distribution. IEEE Trans. Reliab. 1988, 37, 234–238. [Google Scholar] [CrossRef]
- Marazzi, A.; Ruffieux, C. Implementing M-Estimators of the Gamma Distribution. In Robust Statistics, Data Analysis, and Computer Intensive Methods: In Honor of Peter Huber’s 60th Birthday; Rieder, H., Ed.; Springer: New York, NY, USA, 1996; pp. 277–297. [Google Scholar]
- Clarke, B.R.; McKinnon, P.L.; Riley, G. A fast robust method for fitting gamma distributions. Stat. Pap. 2012, 53, 1001–1014. [Google Scholar] [CrossRef]
- Serfling, R. Efficient and robust fitting of lognormal distributions. N. Am. Actuar. J. 2002, 6, 95–109. [Google Scholar] [CrossRef]
- Quesenberry, C.P. Probability integral transformations. Encycl. Stat. Sci. 2004, 10. [Google Scholar] [CrossRef]
- Finkelstein, M.; Tucker, H.G.; Alan Veeh, J. Pareto tail index estimation revisited. North Am. Actuar. J. 2006, 10, 1–10. [Google Scholar] [CrossRef]
- Safari, M.A.M.; Masseran, N.; Ibrahim, K.; Hussain, S.I. A robust and efficient estimator for the tail index of inverse Pareto distribution. Phys. A Stat. Mech. Its Appl. 2019, 517, 431–439. [Google Scholar] [CrossRef]
- Safari, M.A.M.; Masseran, N.; Ibrahim, K.; AL-Dhurafi, N.A. The power-law distribution for the income of poor households. Phys. A Stat. Mech. Its Appl. 2020, 557, 124893. [Google Scholar] [CrossRef]
- Jodrá, P. Computer generation of random variables with Lindley or Poisson-Lindley distribution via the Lambert W function. Math. Comput. Simul. 2010, 81, 851–859. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistics; John Wiley & Sons: New York, NY, USA, 1981. [Google Scholar]
- Hampel, F.R.; Ronchetti, E.M.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics: The Approach Based on Influence Functions; John Wiley & Sons: New York, NY, USA, 1986. [Google Scholar]
- Maronna, R.A.; Martin, R.D.; Yohai, V.J.; Salibián-Barrera, M. Robust Statistics: Theory and Methods (with R), 2nd ed.; John Wiley & Sons: Chichester, UK, 2019. [Google Scholar]
- Wang, F.K. A new model with bath tub-shaped failure rate using an additive Burr XII distribution. Reliab. Eng. Syst. Saf. 2000, 70, 305–312. [Google Scholar] [CrossRef]
- Efron, B. Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 1988, 83, 414–425. [Google Scholar] [CrossRef]
- Sharma, V.K.; Singh, S.K.; Singh, U.; Agiwal, V. The inverse Lindley distribution: A stress-strength reliability model with application to head and neck cancer data. J. Ind. Prod. Eng. 2015, 32, 162–173. [Google Scholar] [CrossRef]
- Adamu, P.I.; Oguntunde, P.E.; Okagbue, H.I.; Agboola, O.O. Statistical data analysis of cancer incidences in insurgency affected states in Nigeria. Data Br. 2018, 18, 2029–2046. [Google Scholar] [CrossRef]
- Bruffaerts, C.; Verardi, V.; Vermandele, C. A generalized boxplot for skewed and heavy-tailed distributions. Stat. Probab. Lett. 2014, 95, 110–117. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| τ | 0.16 | 0.29 | 0.46 | 0.63 | 0.81 | 1.00 | 1.21 | 1.45 | 1.72 | 2.04 | 2.41 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARE (%) | 98 | 95 | 90 | 85 | 80 | 75 | 70 | 65 | 60 | 55 | 50 |
| ARE (%) | 98 | 95 | 90 | 85 | 80 | 75 | 70 | 65 | 60 | 55 | 50 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| UBP | 0.14 | 0.22 | 0.32 | 0.39 | 0.45 | 0.50 | 0.55 | 0.59 | 0.63 | 0.67 | 0.71 |
| LBP | 0.86 | 0.78 | 0.68 | 0.61 | 0.55 | 0.5 | 0.45 | 0.41 | 0.37 | 0.33 | 0.29 |
| θ | m | RRMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | OLS | WLS | PITS 98% ARE | PITS 90% ARE | PITS 80% ARE | PITS 70% ARE | PITS 60% ARE | ||
| 0.5 | 0 | 14.02 | 15.42 | 14.94 | 14.01 | 14.24 | 14.82 | 15.61 | 16.66 |
| 1 | 38.97 | 15.51 | 15.08 | 18.71 | 14.48 | 14.55 | 15.18 | 16.14 | |
| 3 | 64.24 | 17.55 | 17.83 | 46.07 | 24.03 | 19.23 | 17.76 | 17.60 | |
| 5 | 74.95 | 22.53 | 22.81 | 67.20 | 38.26 | 27.91 | 23.87 | 21.70 | |
| 1 | 0 | 14.56 | 16.17 | 15.62 | 14.56 | 14.91 | 15.64 | 16.60 | 17.89 |
| 1 | 39.91 | 16.05 | 15.75 | 19.19 | 15.03 | 15.27 | 16.10 | 17.32 | |
| 3 | 64.71 | 18.25 | 18.59 | 46.66 | 24.66 | 19.85 | 18.42 | 18.40 | |
| 5 | 75.36 | 23.46 | 23.86 | 67.58 | 39.14 | 28.70 | 24.66 | 22.60 | |
| 2 | 0 | 15.52 | 17.37 | 16.69 | 15.52 | 16.01 | 16.89 | 18.04 | 19.58 |
| 1 | 41.21 | 17.47 | 16.83 | 20.13 | 15.97 | 16.37 | 17.37 | 18.82 | |
| 3 | 65.80 | 19.58 | 19.94 | 47.84 | 25.92 | 21.05 | 19.60 | 19.70 | |
| 5 | 76.22 | 25.00 | 25.49 | 68.11 | 40.61 | 30.08 | 25.99 | 24.06 | |
| 3 | 0 | 16.27 | 18.26 | 17.50 | 16.26 | 16.78 | 17.76 | 19.07 | 20.82 |
| 1 | 42.41 | 18.35 | 17.64 | 20.44 | 16.34 | 16.88 | 18.07 | 19.75 | |
| 3 | 66.83 | 20.03 | 20.31 | 48.52 | 26.36 | 21.37 | 20.10 | 20.23 | |
| 5 | 76.60 | 25.71 | 26.28 | 68.37 | 41.44 | 30.77 | 26.63 | 24.69 | |
| θ | m | RRMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | OLS | WLS | PITS 98% ARE | PITS 90% ARE | PITS 80% ARE | PITS 70% ARE | PITS 60% ARE | ||
| 0.5 | 0 | 10.63 | 11.66 | 11.30 | 10.63 | 10.81 | 11.24 | 11.82 | 12.60 |
| 1 | 29.44 | 11.73 | 11.41 | 12.97 | 10.94 | 11.13 | 11.64 | 12.38 | |
| 3 | 52.62 | 12.76 | 12.94 | 28.73 | 15.72 | 13.37 | 12.80 | 12.90 | |
| 5 | 64.76 | 15.52 | 15.91 | 45.84 | 23.49 | 17.93 | 15.95 | 15.03 | |
| 1 | 0 | 11.13 | 12.36 | 11.89 | 11.14 | 11.42 | 11.96 | 12.66 | 13.58 |
| 1 | 30.03 | 12.45 | 12.05 | 13.21 | 11.37 | 11.72 | 12.38 | 13.27 | |
| 3 | 53.48 | 13.30 | 13.48 | 29.30 | 16.11 | 13.84 | 13.39 | 13.73 | |
| 5 | 65.42 | 16.04 | 16.51 | 46.39 | 23.90 | 18.31 | 16.42 | 15.42 | |
| 2 | 0 | 11.66 | 13.14 | 12.59 | 11.68 | 12.10 | 12.77 | 13.61 | 14.70 |
| 1 | 31.98 | 13.22 | 12.71 | 13.99 | 12.10 | 12.54 | 13.32 | 14.36 | |
| 3 | 55.12 | 14.27 | 14.47 | 30.48 | 17.08 | 14.78 | 14.40 | 14.94 | |
| 5 | 66.69 | 17.29 | 17.84 | 47.71 | 25.26 | 19.53 | 17.61 | 16.73 | |
| 3 | 0 | 12.23 | 13.93 | 13.28 | 12.25 | 12.77 | 13.55 | 14.51 | 15.73 |
| 1 | 32.77 | 14.02 | 13.39 | 14.42 | 12.64 | 13.21 | 14.11 | 15.30 | |
| 3 | 55.81 | 14.94 | 15.11 | 31.06 | 17.62 | 15.38 | 15.05 | 15.57 | |
| 5 | 67.58 | 17.88 | 18.45 | 48.36 | 25.87 | 20.07 | 18.17 | 17.05 | |
| θ | m | RRMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | OLS | WLS | PITS 98% ARE | PITS 90% ARE | PITS 80% ARE | PITS 70% ARE | PITS 60% ARE | ||
| 0.5 | 0 | 8.88 | 9.80 | 9.46 | 8.89 | 9.07 | 9.44 | 9.92 | 10.57 |
| 1 | 55.91 | 9.87 | 9.56 | 10.69 | 9.16 | 9.37 | 9.81 | 10.43 | |
| 3 | 79.24 | 10.52 | 10.61 | 23.47 | 12.35 | 10.81 | 10.56 | 10.91 | |
| 5 | 86.74 | 12.21 | 12.55 | 39.28 | 17.67 | 13.69 | 12.46 | 11.91 | |
| 1 | 0 | 9.29 | 10.36 | 9.95 | 9.30 | 9.56 | 10.01 | 10.57 | 11.30 |
| 1 | 56.68 | 10.42 | 10.04 | 11.11 | 9.62 | 9.91 | 10.44 | 11.14 | |
| 3 | 79.67 | 11.06 | 11.15 | 24.22 | 12.85 | 11.31 | 11.10 | 11.51 | |
| 5 | 87.03 | 12.98 | 13.29 | 40.34 | 18.36 | 14.31 | 13.09 | 12.79 | |
| 2 | 0 | 9.72 | 11.00 | 10.51 | 9.74 | 10.10 | 10.68 | 11.41 | 12.34 |
| 1 | 58.04 | 11.06 | 10.61 | 11.59 | 10.11 | 10.53 | 11.21 | 12.12 | |
| 3 | 80.51 | 11.69 | 11.79 | 25.33 | 13.48 | 11.94 | 11.74 | 12.39 | |
| 5 | 87.30 | 13.88 | 14.13 | 41.95 | 19.27 | 15.08 | 13.88 | 13.68 | |
| 3 | 0 | 10.22 | 11.53 | 10.99 | 10.23 | 10.60 | 11.22 | 11.99 | 12.98 |
| 1 | 59.02 | 11.60 | 11.08 | 11.92 | 10.50 | 10.99 | 11.73 | 12.70 | |
| 3 | 81.13 | 12.18 | 12.26 | 26.09 | 13.93 | 12.40 | 12.22 | 12.99 | |
| 5 | 87.76 | 14.30 | 14.64 | 43.13 | 19.87 | 15.58 | 14.38 | 14.21 | |
| θ | ε (%) | RRMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | OLS | WLS | PITS 98% ARE | PITS 90% ARE | PITS 80% ARE | PITS 70% ARE | PITS 60% ARE | ||
| 0.5 | 0 | 7.34 | 8.15 | 7.86 | 7.35 | 7.51 | 7.85 | 8.28 | 8.84 |
| 1 | 18.48 | 8.19 | 7.92 | 8.23 | 7.56 | 7.83 | 8.23 | 8.78 | |
| 5 | 48.82 | 9.63 | 9.89 | 23.91 | 12.64 | 10.38 | 9.66 | 9.75 | |
| 10 | 65.36 | 13.77 | 14.27 | 45.56 | 22.86 | 16.75 | 14.31 | 13.03 | |
| 1 | 0 | 7.70 | 8.56 | 8.23 | 7.71 | 7.92 | 8.30 | 8.78 | 9.41 |
| 1 | 19.23 | 8.60 | 8.28 | 8.57 | 7.95 | 8.25 | 8.70 | 9.32 | |
| 5 | 49.74 | 10.05 | 10.35 | 24.53 | 13.06 | 10.78 | 10.10 | 10.22 | |
| 10 | 66.05 | 14.52 | 15.12 | 46.34 | 23.63 | 17.41 | 14.95 | 13.60 | |
| 2 | 0 | 8.21 | 9.26 | 8.85 | 8.22 | 8.54 | 9.01 | 9.59 | 10.32 |
| 1 | 20.65 | 9.30 | 8.90 | 9.05 | 8.54 | 8.93 | 9.49 | 10.21 | |
| 5 | 51.52 | 10.88 | 11.20 | 25.60 | 13.86 | 11.56 | 10.98 | 11.13 | |
| 10 | 67.26 | 15.63 | 16.31 | 47.55 | 24.80 | 18.45 | 15.96 | 14.68 | |
| 3 | 0 | 8.61 | 9.72 | 9.25 | 8.63 | 8.95 | 9.46 | 10.10 | 10.90 |
| 1 | 21.45 | 9.75 | 9.29 | 9.36 | 8.88 | 9.33 | 9.95 | 10.75 | |
| 5 | 52.70 | 11.26 | 11.58 | 26.22 | 14.27 | 11.94 | 11.34 | 11.58 | |
| 10 | 68.16 | 16.23 | 16.97 | 48.34 | 25.53 | 19.06 | 16.52 | 15.28 | |
| θ | ε (%) | RRMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | OLS | WLS | PITS 98% ARE | PITS 90% ARE | PITS 80% ARE | PITS 70% ARE | PITS 60% ARE | ||
| 0.5 | 0 | 4.25 | 4.75 | 4.56 | 4.26 | 4.37 | 4.57 | 4.81 | 5.11 |
| 1 | 17.25 | 4.81 | 4.71 | 6.09 | 4.70 | 4.69 | 4.86 | 5.13 | |
| 5 | 49.24 | 7.41 | 7.85 | 23.64 | 11.57 | 8.67 | 7.47 | 7.07 | |
| 10 | 65.80 | 12.63 | 13.18 | 45.57 | 22.60 | 16.06 | 13.23 | 11.58 | |
| 1 | 0 | 4.40 | 4.86 | 4.67 | 4.40 | 4.51 | 4.72 | 4.98 | 5.33 |
| 1 | 18.14 | 4.92 | 4.83 | 6.26 | 4.84 | 4.83 | 5.02 | 5.33 | |
| 5 | 50.26 | 7.77 | 8.28 | 24.27 | 11.97 | 9.00 | 7.82 | 7.38 | |
| 10 | 66.48 | 13.31 | 13.97 | 46.26 | 23.28 | 16.64 | 13.77 | 12.10 | |
| 2 | 0 | 4.68 | 5.24 | 5.00 | 4.69 | 4.84 | 5.10 | 5.42 | 5.82 |
| 1 | 19.58 | 5.34 | 5.22 | 6.73 | 5.26 | 5.26 | 5.49 | 5.84 | |
| 5 | 52.02 | 8.50 | 9.08 | 25.36 | 12.79 | 9.72 | 8.54 | 8.07 | |
| 10 | 67.74 | 14.49 | 15.27 | 47.57 | 24.59 | 17.77 | 14.82 | 13.10 | |
| 3 | 0 | 4.83 | 5.45 | 5.18 | 4.84 | 5.02 | 5.30 | 5.64 | 6.08 |
| 1 | 20.30 | 5.51 | 5.36 | 6.85 | 5.39 | 5.42 | 5.68 | 6.07 | |
| 5 | 53.22 | 8.76 | 9.39 | 25.93 | 13.13 | 9.99 | 8.80 | 8.34 | |
| 10 | 68.63 | 14.99 | 15.85 | 48.30 | 25.26 | 18.31 | 15.29 | 13.53 | |
| θ | ε (%) | RRMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | OLS | WLS | PITS 98% ARE | PITS 90% ARE | PITS 80% ARE | PITS 70% ARE | PITS 60% ARE | ||
| 0.5 | 0 | 3.25 | 3.62 | 3.48 | 3.26 | 3.34 | 3.48 | 3.67 | 3.91 |
| 1 | 16.98 | 3.75 | 3.71 | 5.53 | 3.80 | 3.71 | 3.79 | 3.98 | |
| 5 | 49.32 | 6.89 | 7.37 | 23.56 | 11.34 | 8.29 | 7.00 | 6.41 | |
| 10 | 65.89 | 12.38 | 12.93 | 45.53 | 22.51 | 15.90 | 12.99 | 11.21 | |
| 1 | 0 | 3.36 | 3.75 | 3.59 | 3.36 | 3.46 | 3.63 | 3.84 | 4.11 |
| 1 | 17.89 | 3.91 | 3.87 | 5.78 | 4.01 | 3.88 | 3.98 | 4.19 | |
| 5 | 50.46 | 7.31 | 7.89 | 24.28 | 11.82 | 8.69 | 7.39 | 6.78 | |
| 10 | 66.57 | 13.14 | 13.82 | 46.32 | 23.29 | 16.57 | 13.61 | 11.80 | |
| 2 | 0 | 3.55 | 4.02 | 3.82 | 3.57 | 3.70 | 3.90 | 4.14 | 4.45 |
| 1 | 19.29 | 4.19 | 4.13 | 6.09 | 4.26 | 4.15 | 4.28 | 4.52 | |
| 5 | 52.23 | 7.88 | 8.54 | 25.28 | 12.49 | 9.24 | 7.90 | 7.27 | |
| 10 | 67.82 | 14.16 | 14.97 | 47.49 | 24.46 | 17.55 | 14.51 | 12.67 | |
| 3 | 0 | 3.71 | 4.23 | 4.02 | 3.73 | 3.89 | 4.12 | 4.39 | 4.73 |
| 1 | 20.11 | 4.40 | 4.33 | 6.32 | 4.49 | 4.35 | 4.52 | 4.79 | |
| 5 | 53.42 | 8.25 | 8.96 | 25.95 | 12.95 | 9.62 | 8.27 | 7.61 | |
| 10 | 68.70 | 14.81 | 15.68 | 48.30 | 25.25 | 18.21 | 15.10 | 13.20 | |
| Set | Sample Size (n) | Mean | Median | Min | Max | Std. Deviation | Skewness | No. of Outliers (Proportion) |
|---|---|---|---|---|---|---|---|---|
| Set 1 | 18 | 171.50 | 155.00 | 1.00 | 420.00 | 132.27 | 0.28 | 1 (5.55%) |
| Set 2 | 44 | 223.48 | 128.50 | 12.20 | 1776.00 | 305.43 | 3.27 | 1 (2.27%) |
| Set 3 | 128 | 9.37 | 6.40 | 0.08 | 79.05 | 10.51 | 3.25 | 6 (4.69%) |
| Set 4 | 300 | 18.44 | 14.00 | 1.00 | 94.00 | 15.89 | 1.96 | 17 (5.67%) |
| Data | Method | Estimated Parameter | K-S Statistic | p-Value | AIC | BIC |
|---|---|---|---|---|---|---|
| Set 1 | ML | 0.01160 | 0.1737 | 0.5895 | 230.7422 | 231.6326 |
| OLS | 0.01115 | 0.1802 | 0.5434 | 230.7963 | 231.6867 | |
| WLS | 0.01127 | 0.1786 | 0.5550 | 230.7720 | 231.6623 | |
| PITS (75% ARE) | 0.01180 | 0.1707 | 0.6112 | 230.7532 | 231.6435 | |
| PITS (70% ARE) | 0.01214 | 0.1655 | 0.6483 | 230.8193 | 231.7097 | |
| PITS (65% ARE) | 0.01261 | 0.1641 | 0.6583 | 231.0041 | 231.8945 | |
| PITS (60% ARE) | 0.01324 | 0.1866 | 0.4998 | 231.4050 | 232.2954 | |
| Set 2 | ML | 0.00891 | 0.2194 | 0.0243 | 581.1628 | 582.9470 |
| OLS | 0.01325 | 0.1374 | 0.3453 | 597.0666 | 598.8508 | |
| WLS | 0.01333 | 0.1380 | 0.3404 | 597.5451 | 599.3293 | |
| PITS (95% ARE) | 0.01035 | 0.1510 | 0.2425 | 583.2425 | 585.0267 | |
| PITS (90% ARE) | 0.01117 | 0.1225 | 0.4864 | 586.0117 | 587.7959 | |
| PITS (85% ARE) | 0.01178 | 0.1220 | 0.4916 | 588.7263 | 590.5104 | |
| PITS (80% ARE) | 0.01227 | 0.1280 | 0.4306 | 591.2379 | 593.0220 | |
| Set 3 | ML | 0.19605 | 0.1164 | 0.0623 | 841.0598 | 843.9118 |
| OLS | 0.23028 | 0.0597 | 0.7509 | 847.9594 | 850.8115 | |
| WLS | 0.22761 | 0.0580 | 0.7826 | 846.9738 | 849.8258 | |
| PITS (80% ARE) | 0.22368 | 0.0555 | 0.8247 | 845.6468 | 848.4988 | |
| PITS (75% ARE) | 0.22635 | 0.0571 | 0.7977 | 846.5308 | 849.3828 | |
| PITS (70% ARE) | 0.22852 | 0.0586 | 0.7718 | 847.2994 | 850.1514 | |
| PITS (65% ARE) | 0.23032 | 0.0598 | 0.7504 | 847.8874 | 850.7394 | |
| Set 4 | ML | 0.10338 | 0.0772 | 0.0558 | 2326.7150 | 2330.4190 |
| OLS | 0.10998 | 0.0439 | 0.6099 | 2329.0490 | 2332.7520 | |
| WLS | 0.10922 | 0.0476 | 0.5049 | 2328.5550 | 2332.2590 | |
| PITS (75% ARE) | 0.10929 | 0.0472 | 0.5152 | 2328.6020 | 2332.3060 | |
| PITS (70% ARE) | 0.10973 | 0.0451 | 0.5753 | 2328.8820 | 2332.5860 | |
| PITS (65% ARE) | 0.11012 | 0.0432 | 0.6306 | 2329.1500 | 2332.8540 | |
| PITS (60% ARE) | 0.11039 | 0.0419 | 0.6673 | 2329.3420 | 2333.0460 |
| Method | Estimated Parameter | K-S Statistic | p-Value | AIC | BIC |
|---|---|---|---|---|---|
| ML | 0.81958 | 0.4256 | <0.0001 | 401.3450 | 403.9502 |
| OLS | 2.06962 | 0.0618 | 0.8383 | 608.0914 | 610.6965 |
| WLS | 2.04933 | 0.0610 | 0.8505 | 603.0340 | 605.6391 |
| PITS (90% ARE) | 1.92935 | 0.0658 | 0.7784 | 573.7682 | 576.3734 |
| PITS (85% ARE) | 1.98865 | 0.0581 | 0.8875 | 588.0901 | 590.6952 |
| PITS (80% ARE) | 2.02738 | 0.0600 | 0.8638 | 597.5959 | 600.2011 |
| PITS (75% ARE) | 2.05503 | 0.0612 | 0.8471 | 604.4503 | 607.0555 |
| PITS (70% ARE) | 2.07697 | 0.0621 | 0.8340 | 609.9304 | 612.5355 |
| PITS (65% ARE) | 2.09547 | 0.0629 | 0.8232 | 614.5775 | 617.1827 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safari, M.A.M.; Masseran, N.; Abdul Majid, M.H. Robust Reliability Estimation for Lindley Distribution—A Probability Integral Transform Statistical Approach. Mathematics 2020, 8, 1634. https://doi.org/10.3390/math8091634
Safari MAM, Masseran N, Abdul Majid MH. Robust Reliability Estimation for Lindley Distribution—A Probability Integral Transform Statistical Approach. Mathematics. 2020; 8(9):1634. https://doi.org/10.3390/math8091634
Chicago/Turabian StyleSafari, Muhammad Aslam Mohd, Nurulkamal Masseran, and Muhammad Hilmi Abdul Majid. 2020. "Robust Reliability Estimation for Lindley Distribution—A Probability Integral Transform Statistical Approach" Mathematics 8, no. 9: 1634. https://doi.org/10.3390/math8091634
APA StyleSafari, M. A. M., Masseran, N., & Abdul Majid, M. H. (2020). Robust Reliability Estimation for Lindley Distribution—A Probability Integral Transform Statistical Approach. Mathematics, 8(9), 1634. https://doi.org/10.3390/math8091634