Attention-Enhanced Graph Neural Networks for Session-Based Recommendation

Abstract
1. Introduction
- To improve the representation of session sequences, we propose a novel model combining self-attention network with target attentive network, which can capture specific user interests related to a target item and the accurate priorities for different items.
- To model the representation of session sequences, we combine short-term user preferences with long-term user preferences based on attention-enhanced GNN-based recommender.
2. Related Work
2.1. Classical Recommendation Methods
2.2. Deep-Neural-Network-Based Recommendation Methods
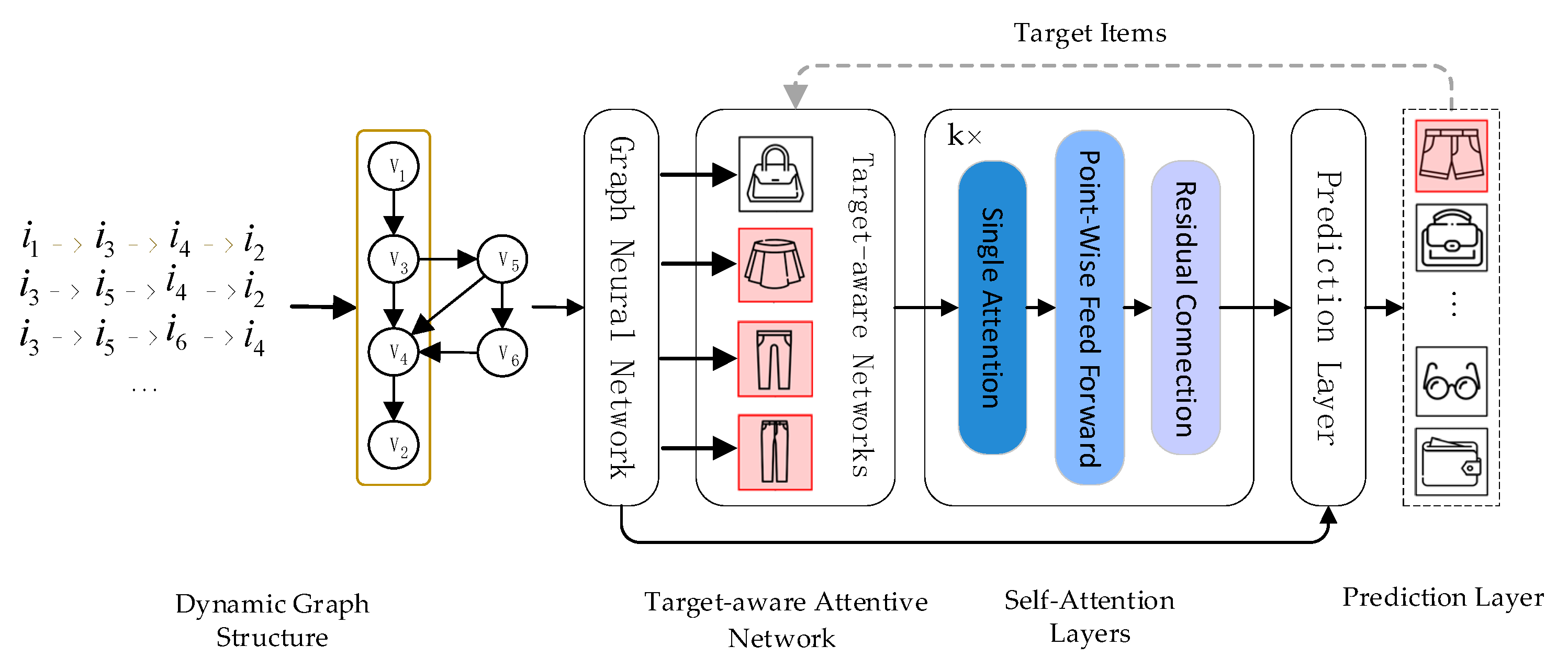
3. Research Methodology
3.1. Preliminaries
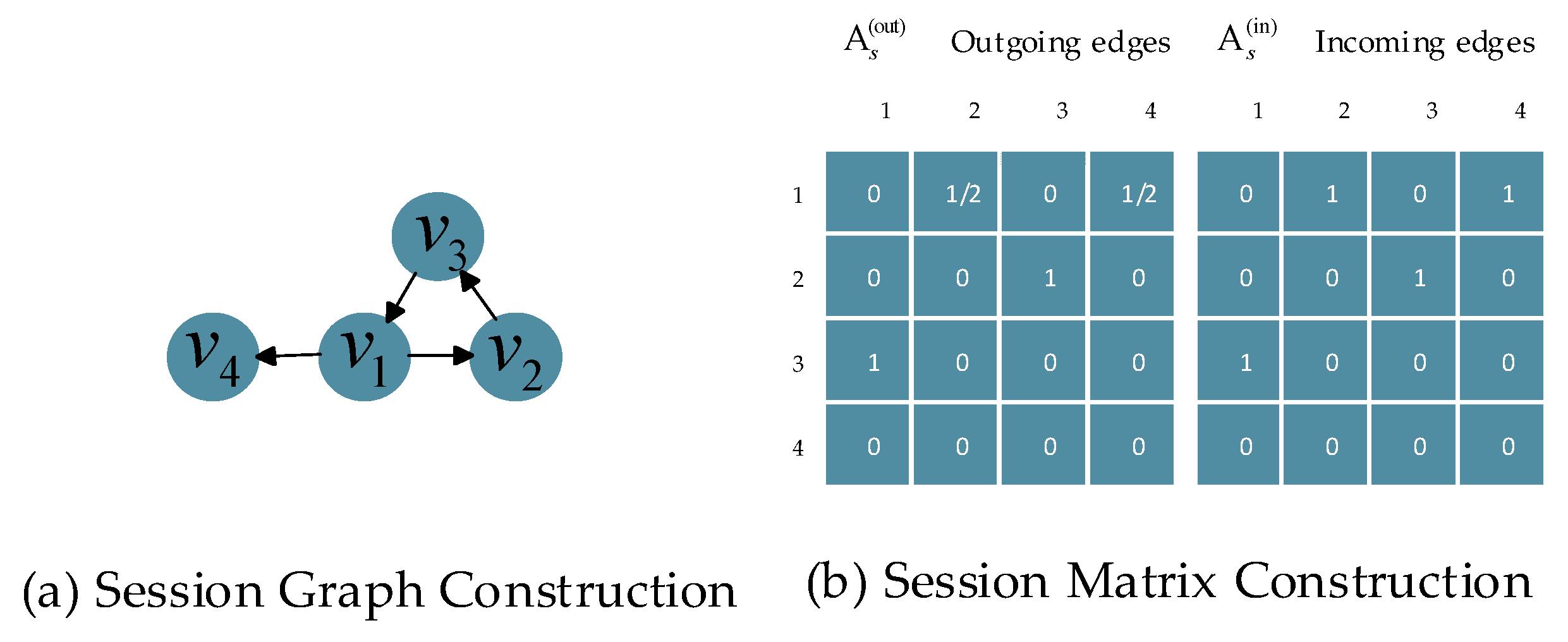
3.2. Dynamic Graph Structure
3.2.1. Construction for Session Graphs and Session Matrix
3.2.2. Learning Node Vectors on Session Graphs
3.3. Target-Aware Attentive Network Construction
3.4. Self-Attention Layers Construction
3.4.1. Self-Attention Layer
3.4.2. Point-Wise Feed-Forward Network
3.4.3. Multi-layer Self-Attention
3.5. Hybrid Session Embeddings Construction
3.6. Prediction Layer
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Baseline Algorithms
- (1)
- POP is a frequency-based recommendation model.
- (2)
- Item-k-nearest neighbor (Item-KNN) [19] is a similarity-based recommendation model.
- (3)
- Factorization-based methods Bayesian personalized ranking (BPR-MF) [20] is factorization-based methods Bayesian personalized ranking.
- (4)
- FPMC [3] is an effective session-based recommendation based on factorizing personalized Markov chain.
- (5)
- Gated recurrent unit for recommendation (GRU4REC) [4] is an RNN-based recommendation model for the session-based recommendation.
- (6)
- STAMP [10] is a short-term attention/memory priority model for current interests.
- (7)
- Session-based recommendation with graph neural networks (SR-GNN) [5] is a GNN-based model capturing users’ long-term interests and current interests by using graph neural network.
- (8)
- Target attentive graph neural networks (TAGNN) [8] are a GNN-based model introducing target attentive units for session-based recommendation tasks.
4.1.3. Parameter Setting
4.1.4. Evaluation Metrics
4.2. Results and Analysis
4.2.1. Observations about Our Model
4.2.2. Other Observations
4.3. Ablation Analysis of Our Model
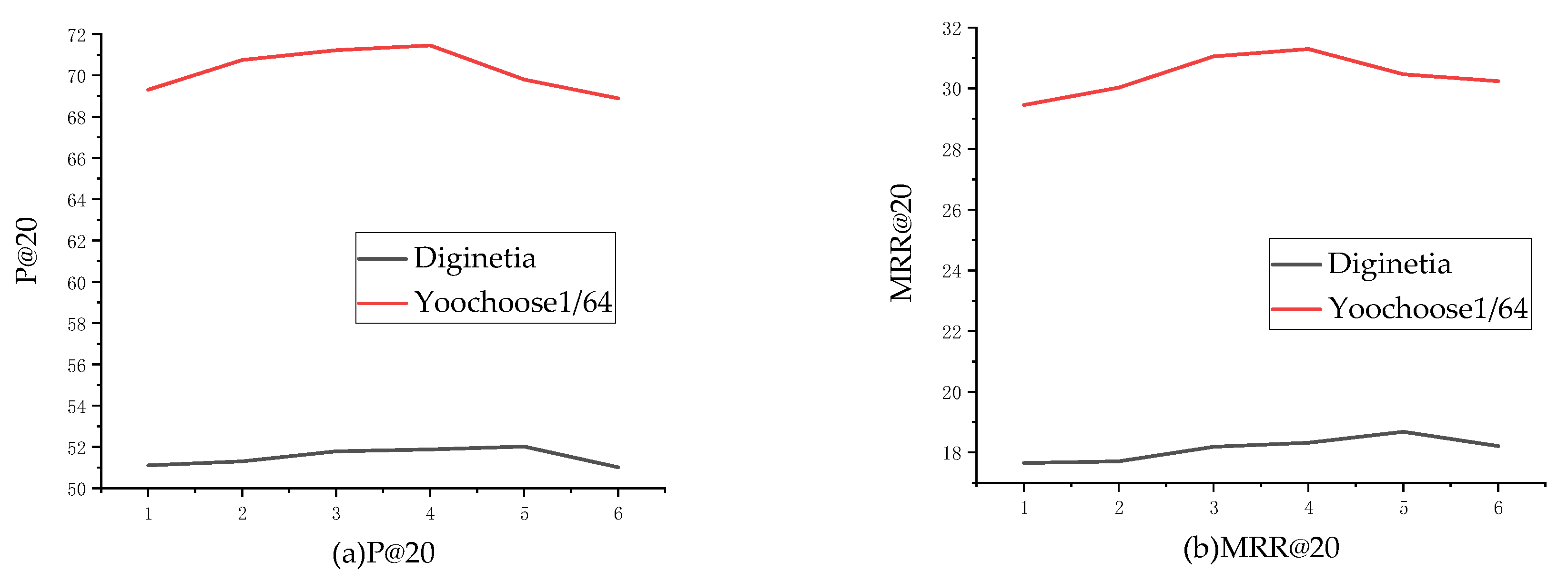
4.3.1. Impact of the Number of Self-attention Blocks
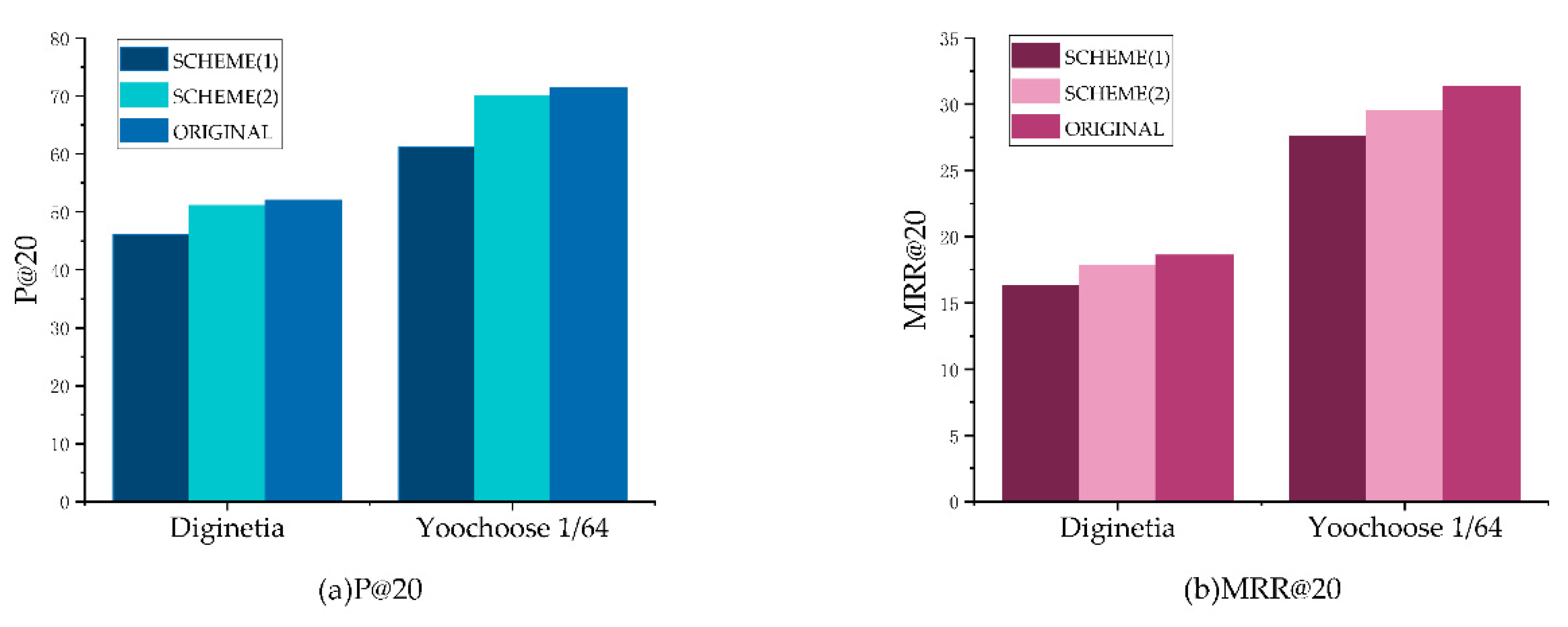
4.3.2. Impact of Varying Session Representations
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 20–27 April 2018; pp. 1835–1844. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based Recommendation with Graph Neural Network. In Proceedings of the National Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; pp. 346–353. [Google Scholar]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar]
- Xu, C.; Zhao, P.; Liu, Y.; Sheng, V.S.; Xu, J.; Zhuang, F.; Fang, J.; Zhou, X. Graph contextualized self-attention network for session-based recommendation. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3940–3946. [Google Scholar]
- Yu, F.; Zhu, Y.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. TAGNN: Target attentive graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Xi’an, China, 25–30 July 2020; pp. 1921–1924. [Google Scholar]
- Zimdars, A.; Chickering, D.M.; Meek, C. Using temporal data for making recommendations. In Proceedings of the Uncertainty In Artificial Intelligence, Seattle, WA, USA, 2–5 August 2001; pp. 580–588. [Google Scholar]
- Liu, Q.; Zeng, Y.; Mokhosi, R.; Zhang, H. STAMP: Short-term attention/memory priority model for session-based recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1831–1839. [Google Scholar]
- Huang, J.; Zhao, W.X.; Dou, H.; Wen, J.; Chang, E.Y. Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks. In Proceedings of the International ACM Sigir Conference on Research and Development In Information Retrieval, Ann Arbor Michigan, MI, USA, 8–12 July 2018; pp. 505–514. [Google Scholar]
- Wang, B.; Cai, W. Knowledge-enhanced graph neural networks for sequential recommendation. Information 2020, 11, 388. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R.J.A.P.A. Gated graph sequence neural networks. In Proceedings of the International Conference on Learning Representations Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017; pp. 5998–6008. [Google Scholar]
- Li, X.; Song, J.; Gao, L.; Liu, X.; Huang, W.; Gan, C.; He, X. Beyond RNNs: Positional self-attention with co-attention for video question answering. In Proceedings of the National Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8658–8665. [Google Scholar]
- Kang, W.; Mcauley, J. Self-attentive sequential recommendation. In Proceedings of the International Conference on Data Mining, Singapore, 17–19 November 2018; pp. 197–206. [Google Scholar]
- Perez, H.; Tah, J.H.M. Improving the accuracy of convolutional neural networks by identifying and removing outlier images in datasets Using t-SNE. Mathematics 2020, 8, 662. [Google Scholar] [CrossRef]
- Sarwar, B.M.; Karypis, G.; Konstan, J.A.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the Web Conference, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Miller, A.H.; Fisch, A.; Dodge, J.; Karimi, A.-H.; Bordes, A.; Weston, J. Key-value memory networks for directly reading documents. In Proceedings of the EMNLP16, Austin, TX, USA, 1–5 November 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Diginetica | Yoochoose 1/64 | ||
|---|---|---|---|---|
| P@20 | MRR@20 | P@20 | MRR@20 | |
| POP | 0.87 | 0.19 | 6.74 | 1.63 |
| Item-KNN | 35.69 | 11.54 | 51.59 | 21.79 |
| BPR-MF | 5.21 | 1.89 | 31.28 | 12.07 |
| FPMC | 26.52 | 6.94 | 45.61 | 15.01 |
| GRU4REC | 29.40 | 8.31 | 60.67 | 22.90 |
| STAMP | 45.59 | 14.29 | 68.69 | 29.64 |
| SR-GNN | 50.72 | 17.56 | 70.56 | 30.92 |
| TAGNN | 51.29 | 17.93 | 70.98 | 31.03 |
| OUR MODEL | 52.02 | 18.58 | 71.45 | 31.29 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Cai, W. Attention-Enhanced Graph Neural Networks for Session-Based Recommendation. Mathematics 2020, 8, 1607. https://doi.org/10.3390/math8091607
Wang B, Cai W. Attention-Enhanced Graph Neural Networks for Session-Based Recommendation. Mathematics. 2020; 8(9):1607. https://doi.org/10.3390/math8091607
Chicago/Turabian StyleWang, Baocheng, and Wentao Cai. 2020. "Attention-Enhanced Graph Neural Networks for Session-Based Recommendation" Mathematics 8, no. 9: 1607. https://doi.org/10.3390/math8091607
APA StyleWang, B., & Cai, W. (2020). Attention-Enhanced Graph Neural Networks for Session-Based Recommendation. Mathematics, 8(9), 1607. https://doi.org/10.3390/math8091607