A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function





Abstract
1. Introduction
- ,
- ,
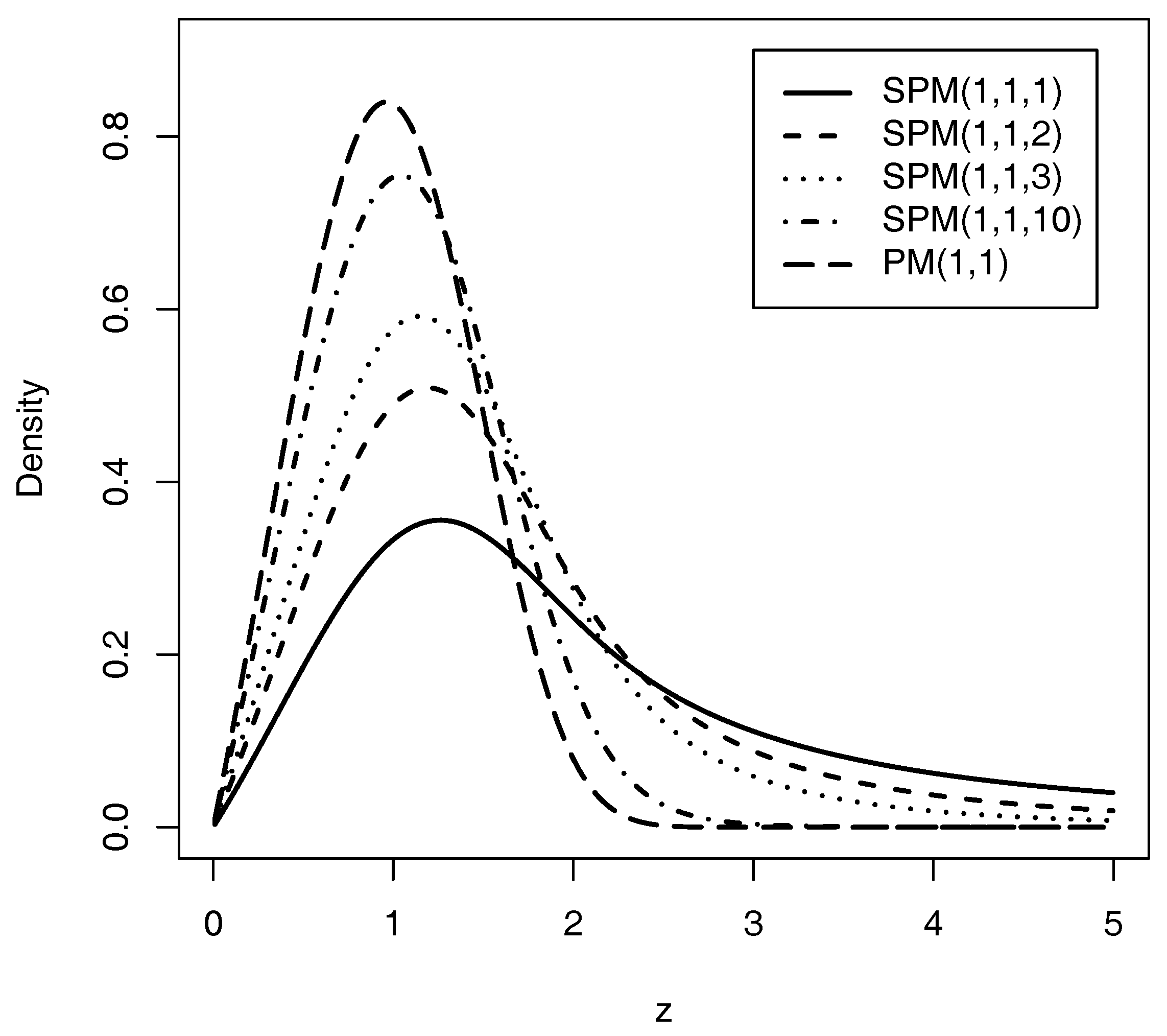
2. Probability Density Function
2.1. Stochastic Representation
2.2. Density Function
2.3. Probabilistic Properties
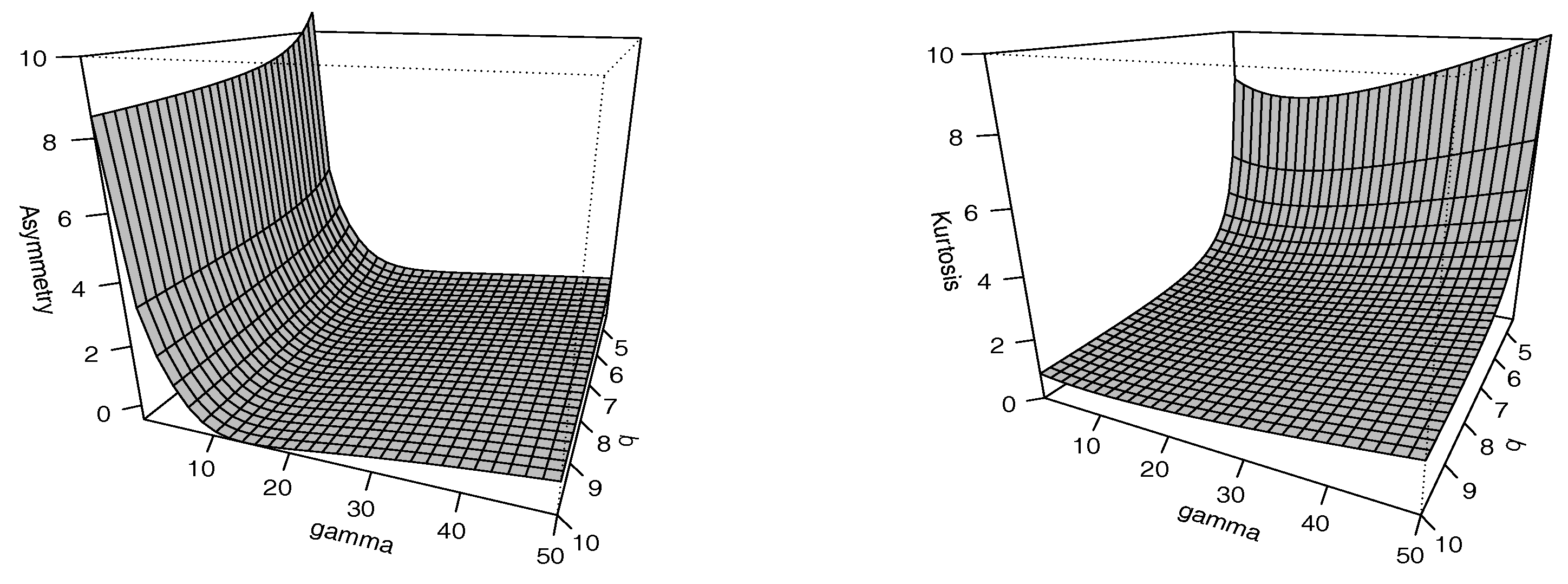
2.4. Moments
- 1.
- 2.
- 3.
- 4.
3. Inference
3.1. Moment Method Estimators
3.2. Ml Estimation
3.3. Simulation Study
- Simulate
- Compute where W is the Lambert W function.
- Compute
4. Applications
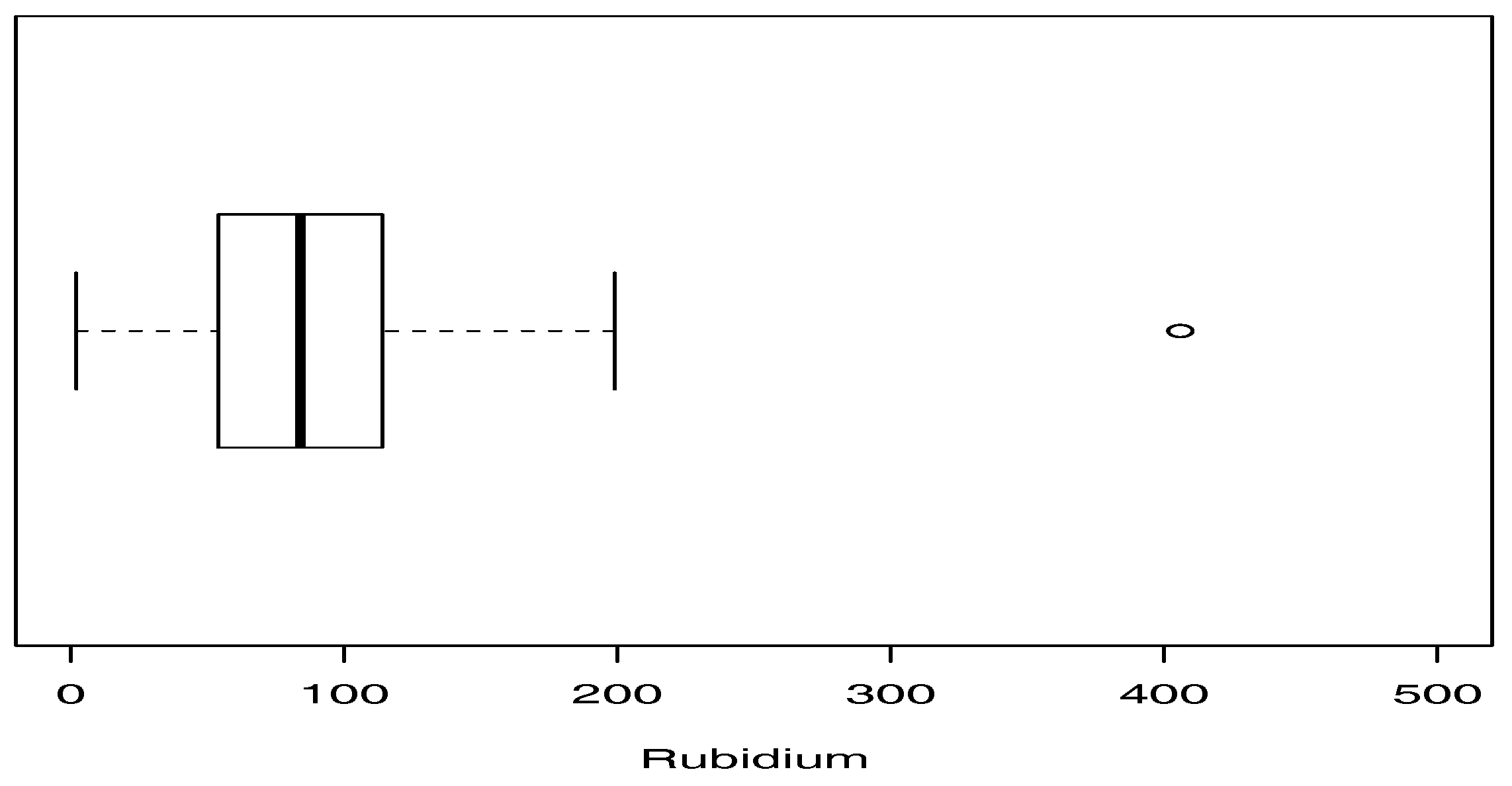
4.1. Application I (Rubidium Concentration)
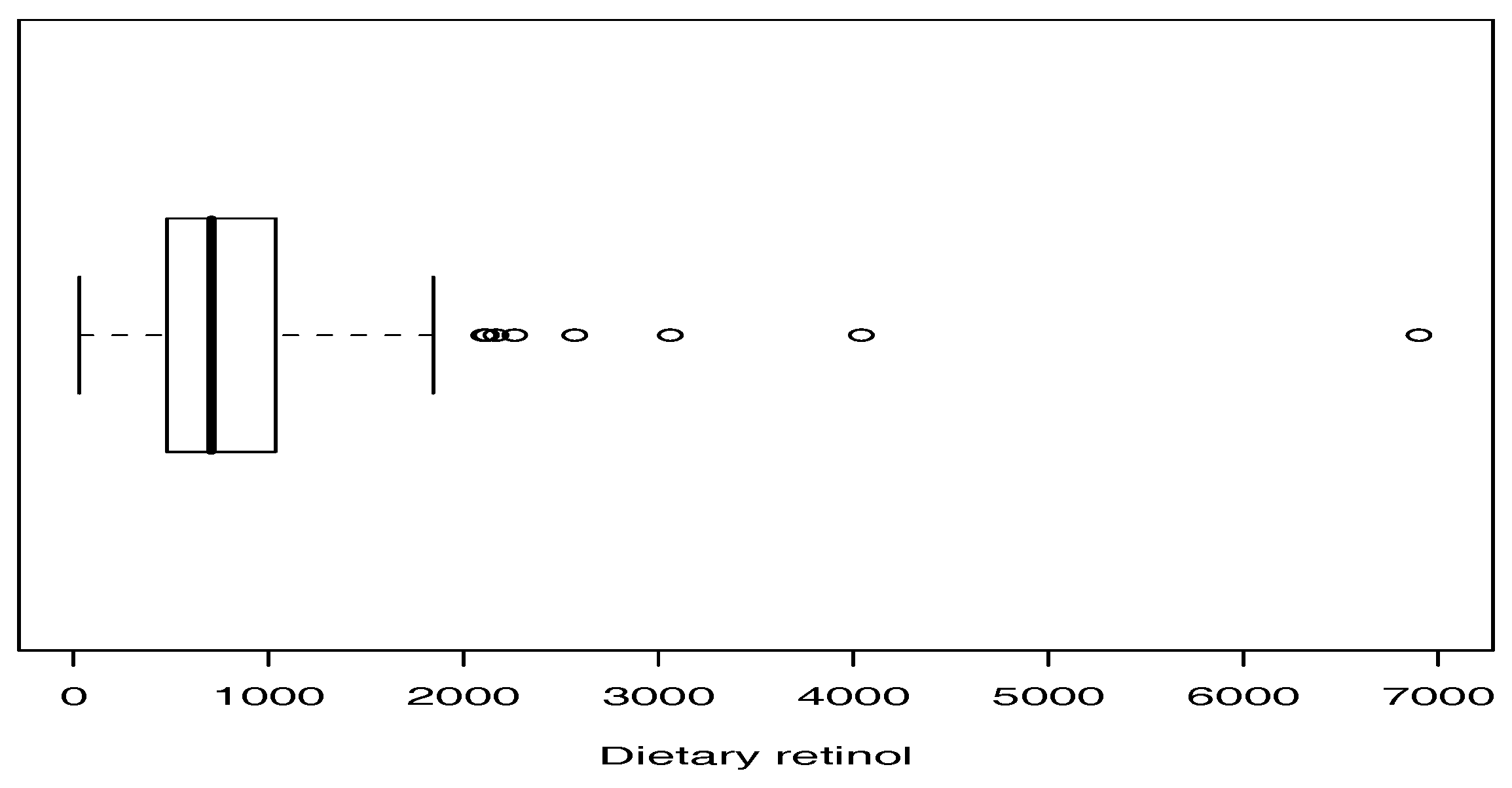
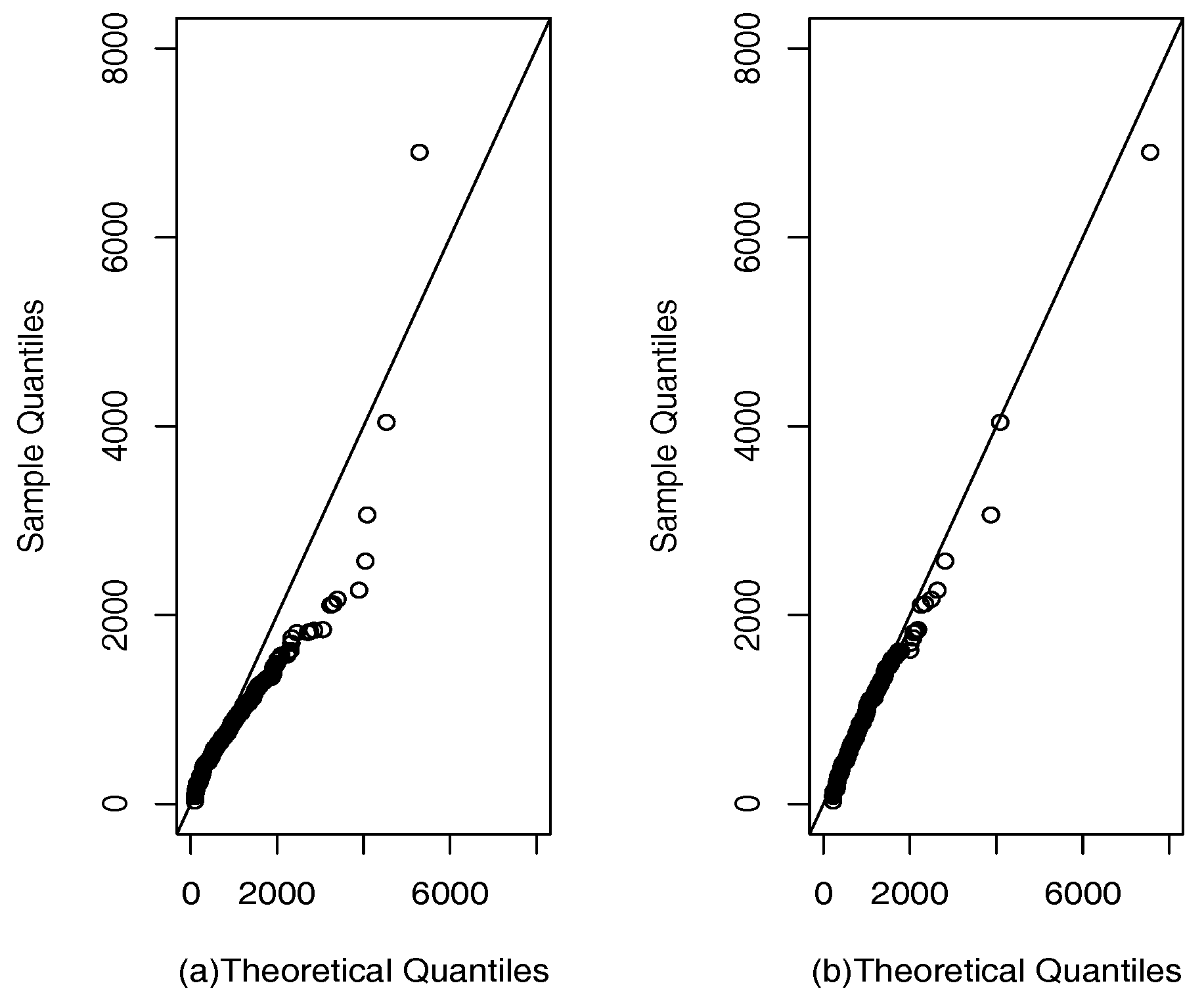
4.2. Application II (Dietary Retinol Consumed)
5. Discussion
- The density of the SPM model has a closed-form and is expressed in terms of the incomplete generalized integro-exponential function.
- The SPM model presents more flexible coefficients of asymmetry and kurtosis than those of the PM model. Furthermore, as shown in Table 1, the tails become heavier when the parameter q is smaller.
- We discuss two stochastic representations for the SPM model: one is based on the quotient between two independent random variables, a PM in the numerator, and a power of a U in the denominator; the other is obtained as a mixture of the scale of a PM model and a U model.
- The moments and coefficients of asymmetry and kurtosis have closed-form expressions and are expressed in terms of the generalized integro-exponential function.
- In the applications, two criteria (AIC and BIC) were used to compare the models. In both data sets, the coefficient of kurtosis is high, indicating the presence of atypical observations. The criteria indicate that the SPM model provides the best fit to the data.
- The SPM distribution is a good alternative for modeling continuous positive data sets with atypical observations. These situations are common in all areas of knowledge, for example environmental science, economic, geo-chemistry, survival, reliability, etc. In the future, we will use this distribution in problems of regression, reliability, survival analysis, and Bayesian inference.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; Wiley-Interscience: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Rogers, W.H.; Tukey, J.W. Understanding some long-tailed symmetrical distributions. Statist. Neerl. 1972, 26, 211–226. [Google Scholar] [CrossRef]
- Mosteller, F.; Tukey, J.W. Data Analysis and Regression; Addison-Wesley: Boston, MA, USA, 1977. [Google Scholar]
- Kafadar, K. A biweight approach to the one-sample problem. J. Am. Stat. Assoc. 1982, 77, 416–424. [Google Scholar] [CrossRef]
- Gómez, H.W.; Quintana, F.A.; Torres, F.J. New Family of Slash-Distributions with Elliptical Contours. Stat. Probabil. Lett. 2007, 77, 717–725. [Google Scholar] [CrossRef]
- Gómez, H.W.; Venegas, O. Erratum to: A New Family of Slash-Distributions with Elliptical Contours. Stat. Probab. Lett. 2008, 78, 2273–2274. [Google Scholar] [CrossRef]
- Gómez, H.W.; Olivares-Pacheco, J.F.; Bolfarine, H. An extension of the generalized Birnbaum–Saunders distribution. Stat. Probab. Lett. 2009, 79, 331–338. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Gómez, H.W.; Bolfarine, H. An extension of the half-normal distribution. Stat. Pap. 2012, 53, 875–886. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Bolfarine, H.; Gómez, H.W. An extension of the generalized half-normal distribution. Stat. Pap. 2014, 55, 967–981. [Google Scholar] [CrossRef]
- Reyes, J.; Barranco-Chamorro, I.; Gallardo, D.I.; Gómez, H.W. Generalized modified slash Birnbaum–Saunders distribution. Symmetry 2018, 10, 724. [Google Scholar] [CrossRef]
- Gómez, Y.M.; Bolfarine, H.; Gómez, H.W. Gumbel distribution with heavy tails and applications to environmental data. Math. Comput. Simul. 2019, 157, 115–129. [Google Scholar] [CrossRef]
- Segovia, F.A.; Gómez, Y.M.; Venegas, O.; Gómez, H.W. A power Maxwell distribution with heavy tails and applications. Mathematics 2020, 8, 1116. [Google Scholar] [CrossRef]
- Muth, J.E. Reliability models with positive memory derived from the mean residual life function. In The Theory and Applications of Reliability; Tsokos, C.P., Shimi, I., Eds.; Academic Press: New York, NY, USA, 1977; Volume II, pp. 401–435. [Google Scholar]
- Jodrá, P.; Jiménez-Gamero, M.D.; Alba-Fernández, M.V. On the Muth Distribution. Math. Model. Anal. 2015, 20, 291–310. [Google Scholar] [CrossRef]
- Milgram, M.S. The generalized integro-exponential function. Math. Comput. 1985, 44, 443–458. [Google Scholar] [CrossRef]
- Chiccoli, C.; Lorenzutta, S.; Maino, G. A numerical method for generalized exponential integrals. Comp. Math. Applic. 1987, 14, 261–268. [Google Scholar] [CrossRef]
- Chiccoli, C.; Lorenzutta, S.; Maino, G. Recent results for generalized exponential integrals. Comp. Math. Applic. 1990, 19, 21–29. [Google Scholar] [CrossRef]
- Jodrá, P.; Gómez, H.W.; Jiménez-Gamero, M.D.; Alba-Fernández, M.V. The power Muth distribution. Math. Model. Anal. 2017, 22, 186–201. [Google Scholar] [CrossRef]
- Corless, R.M.; Gonnet, G.H.; Hare, D.E.G.; Jeffrey, D.J.; Knuth, D.E. On the Lambert W function. Adv. Comput. Math. 1996, 5, 329–359. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distribution | |||
|---|---|---|---|
| PM(1,1) | |||
| SPM(1,1,10) | 0.00360 | 0.00015 | |
| SPM(1,1,3) | 0.05910 | 0.01870 | 0.00765 |
| SPM(1,1,2) | 0.08834 | 0.03727 | 0.01908 |
| SPM(1,1,1) | 0.11111 | 0.06250 | 0.04000 |
| n | q | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | 1 | 2 | 1.0391 | 0.1372 | 91.6 | 1.0535 | 0.2106 | 91.8 | 2.3550 | 0.8728 | 95.4 |
| 100 | 1 | 1 | 2 | 1.0260 | 0.0934 | 93.0 | 1.0234 | 0.1399 | 91.8 | 2.2321 | 0.4495 | 95.3 |
| 150 | 1 | 1 | 2 | 1.0163 | 0.0752 | 92.5 | 1.0089 | 0.1112 | 93.5 | 2.1538 | 0.3294 | 95.0 |
| 200 | 1 | 1 | 2 | 1.0182 | 0.0651 | 92.0 | 0.9981 | 0.0943 | 91.1 | 2.1515 | 0.2798 | 92.9 |
| 50 | 1 | 1 | 3 | 1.0078 | 0.1227 | 92.9 | 1.0701 | 0.1963 | 93.5 | 3.3892 | 1.5270 | 93.1 |
| 100 | 1 | 1 | 3 | 1.0125 | 0.0880 | 93.9 | 1.0214 | 0.1290 | 94.0 | 3.3267 | 0.9484 | 95.0 |
| 150 | 1 | 1 | 3 | 1.0019 | 0.0694 | 93.3 | 1.0107 | 0.1028 | 94.3 | 3.1859 | 0.6382 | 94.6 |
| 200 | 1 | 1 | 3 | 1.0076 | 0.0609 | 94.6 | 1.0039 | 0.0880 | 94.8 | 3.1639 | 0.5385 | 95.4 |
| 50 | 1 | 1 | 4 | 0.9766 | 0.1179 | 93.4 | 1.0465 | 0.1862 | 95.0 | 4.1195 | 2.1138 | 89.4 |
| 100 | 1 | 1 | 4 | 1.0065 | 0.0852 | 94.2 | 1.0174 | 0.1216 | 95.2 | 4.4275 | 1.5731 | 95.3 |
| 150 | 1 | 1 | 4 | 1.0115 | 0.0699 | 94.7 | 1.0015 | 0.0960 | 95.5 | 4.3927 | 1.2308 | 94.9 |
| 200 | 1 | 1 | 4 | 1.0109 | 0.0597 | 95.0 | 0.9999 | 0.0823 | 93.5 | 4.3101 | 0.9668 | 95.1 |
| 50 | 3 | 1 | 2 | 2.9590 | 0.4196 | 92.0 | 1.0179 | 0.2117 | 94.0 | 2.3601 | 0.7448 | 98.0 |
| 100 | 3 | 1 | 2 | 3.1021 | 0.3145 | 98.0 | 1.0034 | 0.1495 | 96.0 | 2.4675 | 0.5667 | 100.0 |
| 150 | 3 | 1 | 2 | 3.1885 | 0.2512 | 92.0 | 1.0075 | 0.1156 | 98.0 | 2.6076 | 0.4875 | 100.0 |
| 200 | 3 | 1 | 2 | 3.1785 | 0.2199 | 94.0 | 0.9806 | 0.0982 | 94.0 | 2.6012 | 0.4217 | 90.0 |
| 50 | 2 | 1 | 2 | 2.0166 | 0.2702 | 94.0 | 1.0699 | 0.2161 | 86.0 | 2.3286 | 0.7356 | 94.0 |
| 100 | 2 | 1 | 2 | 2.0362 | 0.1823 | 92.0 | 1.0260 | 0.1374 | 92.0 | 2.2804 | 0.4400 | 98.0 |
| 150 | 2 | 1 | 2 | 2.0972 | 0.1616 | 92.0 | 0.9978 | 0.1112 | 90.0 | 2.4041 | 0.4160 | 98.0 |
| 200 | 2 | 1 | 2 | 2.1220 | 0.1372 | 86.0 | 0.9856 | 0.0903 | 88.0 | 2.4925 | 0.3741 | 96.0 |
| n | ||||
|---|---|---|---|---|
| 86 | 88.5698 | 56.4683 | 2.1948 | 13.4317 |
| Parameter Estimates | PM (SE) | SPM (SE) |
|---|---|---|
| 81.6487 (6.6748) | 67.6313 (6.0901) | |
| 0.6311 (0.0468) | 0.6398 (0.0890) | |
| q | 4.7829 (1.9498) | |
| AIC | 922.1212 | 910.826 |
| BIC | 927.030 | 918.188 |
| n | ||||
|---|---|---|---|---|
| 315 | 832.7143 | 347261.600 | 4.453 | 40.447 |
| Parameter Estimates | PM (SE) | SPM (SE) |
|---|---|---|
| 755.999 (35.916) | 566.988 (29.268) | |
| 0.566 (0.019) | 1.024 (0.078) | |
| q | − | 3.110 (0.437) |
| AIC | 4810.924 | 4699.180 |
| BIC | 4818.429 | 4710.438 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Astorga, J.M.; Reyes, J.; Santoro, K.I.; Venegas, O.; Gómez, H.W. A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function. Mathematics 2020, 8, 1537. https://doi.org/10.3390/math8091537
Astorga JM, Reyes J, Santoro KI, Venegas O, Gómez HW. A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function. Mathematics. 2020; 8(9):1537. https://doi.org/10.3390/math8091537
Chicago/Turabian StyleAstorga, Juan M., Jimmy Reyes, Karol I. Santoro, Osvaldo Venegas, and Héctor W. Gómez. 2020. "A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function" Mathematics 8, no. 9: 1537. https://doi.org/10.3390/math8091537
APA StyleAstorga, J. M., Reyes, J., Santoro, K. I., Venegas, O., & Gómez, H. W. (2020). A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function. Mathematics, 8(9), 1537. https://doi.org/10.3390/math8091537