RNA: A Reject Neighbors Algorithm for Influence Maximization in Complex Networks



Abstract
:1. Introduction
- Proposed a refined k-shell centrality indicator for IMP;
- Proposed a node ranking and a reject neighbors-based node selection two-phase IMP algorithm;
- Achieved superior IMP results as compared with other state-of-the-art methods.
2. Algorithm Design
2.1. Refined Shell Index
- Set the number of shell layers s = 1;
- Iteratively removing nodes with degree value of s in the network and removing their connected edges, these nodes constitute the s-shell layer of the network;
- Calculate the maximum node degree, maxD, and the minimum node degree, mind, in this shell layer;
- Calculate coeffiK and coeffiB according to Equation (1), thereby calculating RS (i) of nodes in the shell layer;
- Increase the number of shell layers s, repeat steps 2, 3, and 4 until all nodes are removed.
| Centrality: RS index | |
| Input: The network G = n nodes, m edges | |
| Output:RS (i) represents the RS value of the network node | |
| 1: | s=1 // s represents the s-shell layer of the network |
| 2: | while num (G) > 0 do // num (G) represents the number of nodes in the network |
| 3: | while exists node (s) in G do //node (s) represents a node with degree s |
| 4: | remove node (s) from G |
| 5: | node (s) append to s-shell |
| 6: | end while |
| 7: | calculate maxD and minD in s-shell |
| 8: | calculate coeffiK and coeffiB in s-shell |
| 9: | calculate RS (i) in s-shell |
| 10: | s++ |
| 11: | end while |
2.2. Node Selection
- Sorting nodes in the network according to the RS index;
- Select the rejection domain order σ;
- Seeds store the seed nodes, and refuses store the neighbors of the seed nodes with the order from 0 to σ;
- Traverse the sorted nodes. If the node is not in refuses, the node is added to seeds, and the node’s neighbors with the order of 0 to σ are added to refuses;
- If the number of nodes is satisfied, the iteration is stopped, and the seeds set is the final key node set;
- If the number of nodes is still not satisfied at the end of the traversal, then relax the limit conditions, that is, decrease the order of the rejection domain.
| Algorithm 1: RNA | |
| Inout: The network G = n nodes, m edges | |
| Output: The key node-set Seeds | |
| 1: | sort nodes into array by RS index // array is the sorted sequence of nodes |
| 2: | fori = 1 to n step 1: |
| 3: | if num not meets do // The number of nodes set in advance is satisfied |
| 4: | if node not in Refuses do |
| 5: | array[i] is added to Seeds |
| 6: | [0, σ] neighbors of array [i] are added to Refuses |
| 7: | end if |
| 8: | else do |
| 11: | return Seeds |
| 12: | end if |
| 13: | if i = n do |
| 14: | σ-- |
| 15: | go to step 2 // return step 2 |
| 16: | end if |
| 17: | end for |
3. Experimental Analysis
3.1. Evaluation Index
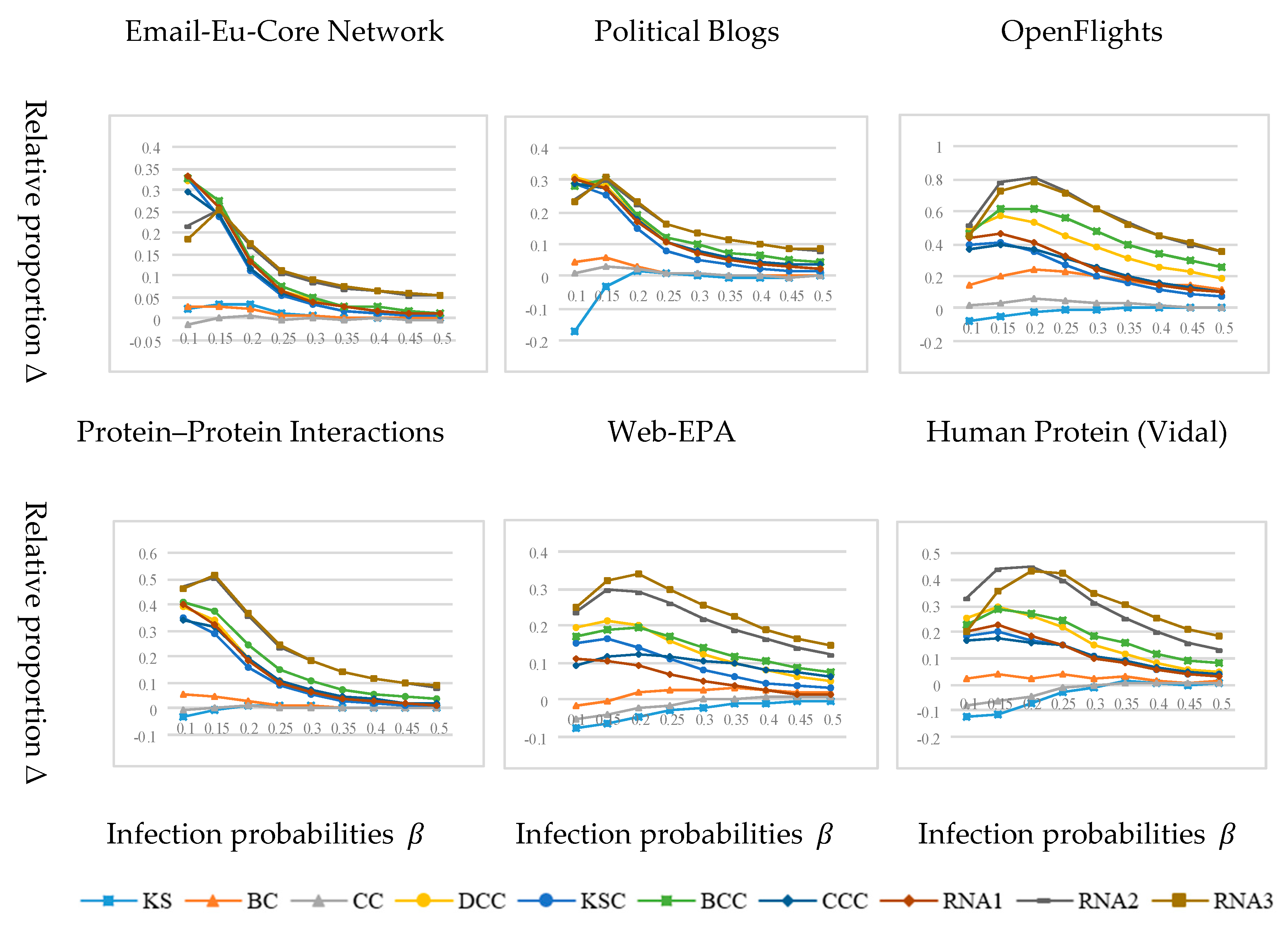
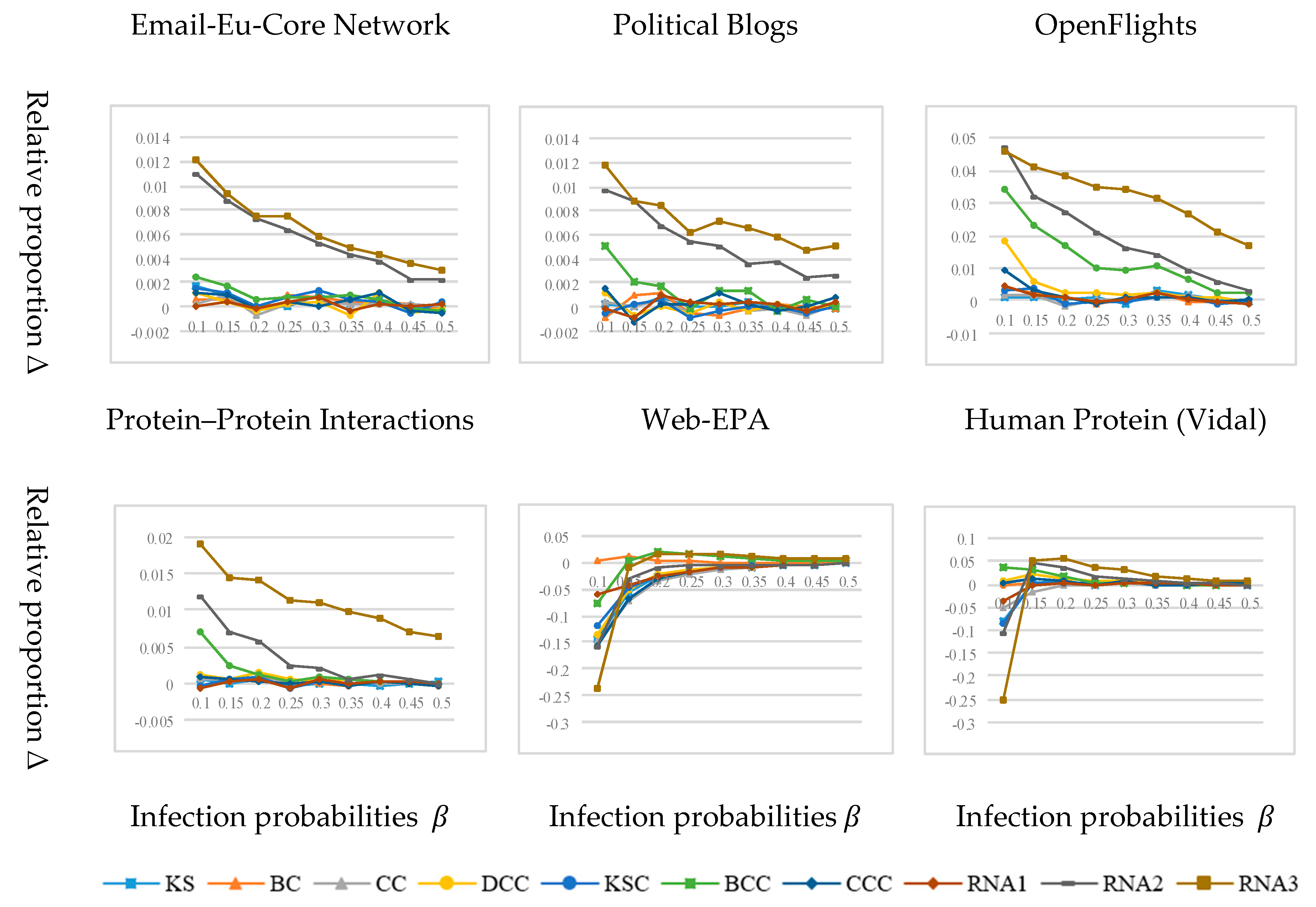
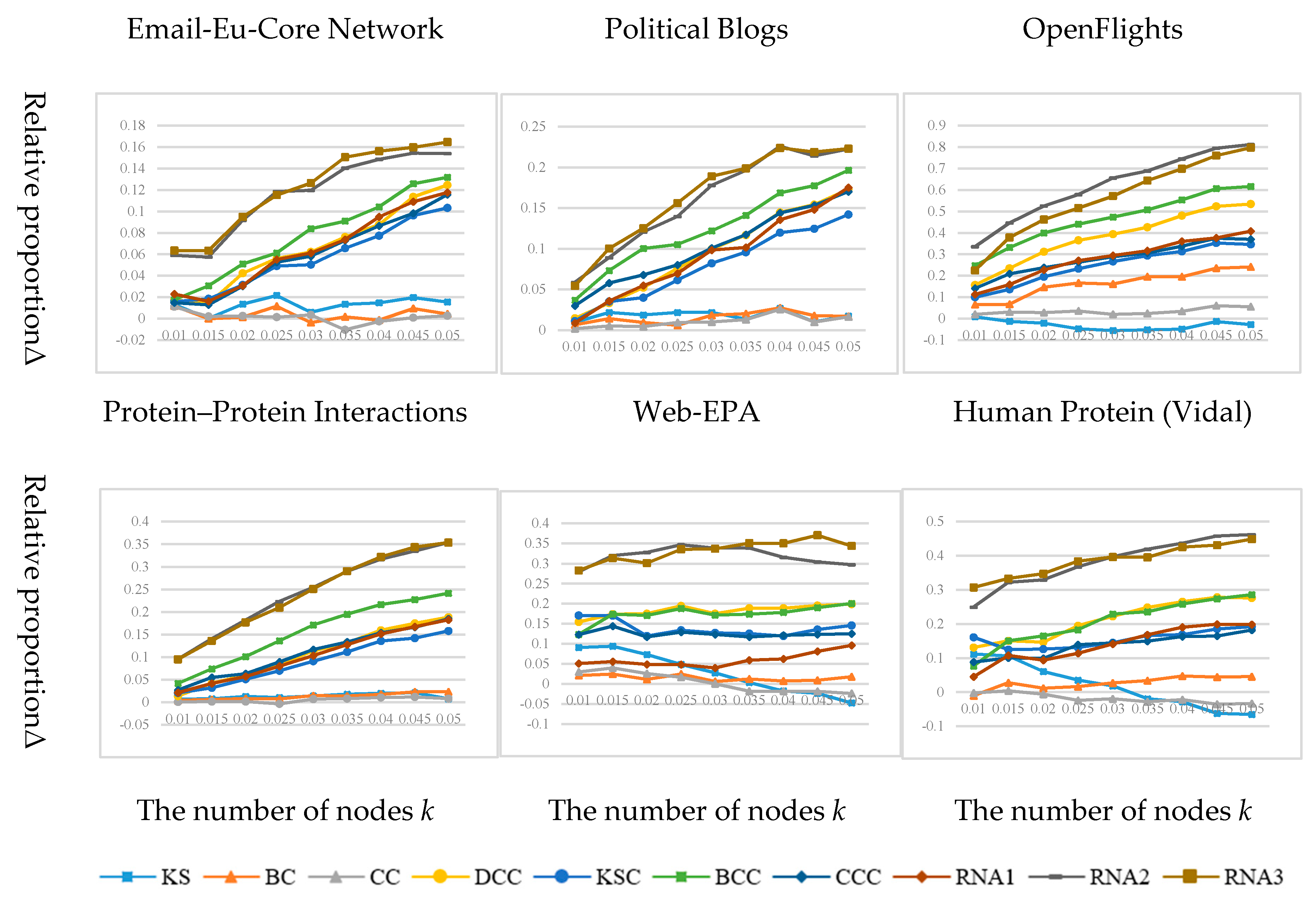
3.2. Network Datasets
- Email-Eu-Core Network [7] The dataset is generated using e-mail data from a large European research institution. If there is at least one e-mail exchange between the members of the two institutions, there is an edge in the network connecting the members of the two institutions. It merely contains the communication between the members of the organization and does not contain the communication information between the outside and the inside of the organization.
- Political Blogs [31] The dataset is a hyperlink-oriented network between U.S. political blogs recorded by Adamic and Glance, in 2005.
- OpenFlights [32] This dataset is extracted from the data of OpenFlights.org and corresponds to the network 14c in Tore Opsahl’s homepage dataset list. The network includes flights between airports around the world, and edges in the network indicate flights from one airport to another.
- Protein–Protein Interaction [33] The network is a sub-network of human protein interaction network. The protein interaction network is a network of protein complexes formed by biochemical events or electrostatic forces, which can play unique biological functions as complexes. Nodes in the network represent proteins, whereas edges represent interactions between proteins.
- Web-EPA [34] The dataset provides network data linked to www.epa.gov from a scientific network data warehouse called Network Repository, where nodes represent web pages and edges represent hyperlinks.
- Human Protein (Vidal) [35] The network represents the initial version of the proteome scale map of human binary protein–protein interactions. Compared with the Protein–Protein Interactions network, the Human Protein (Vidal) network is sparser.
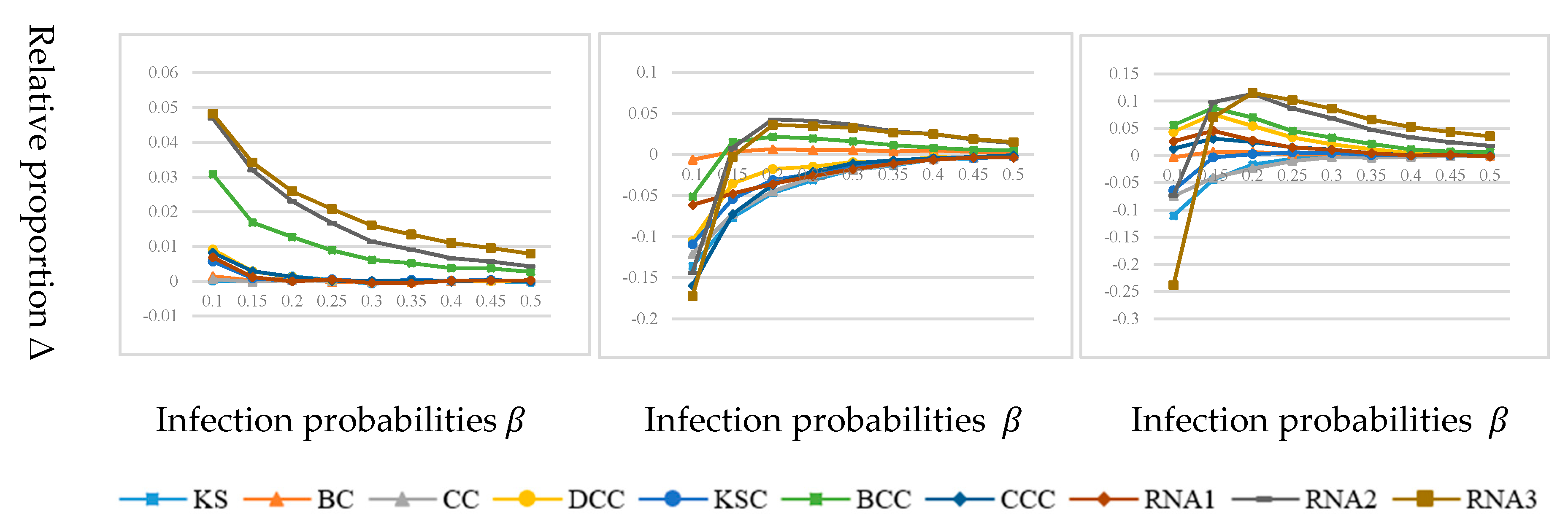
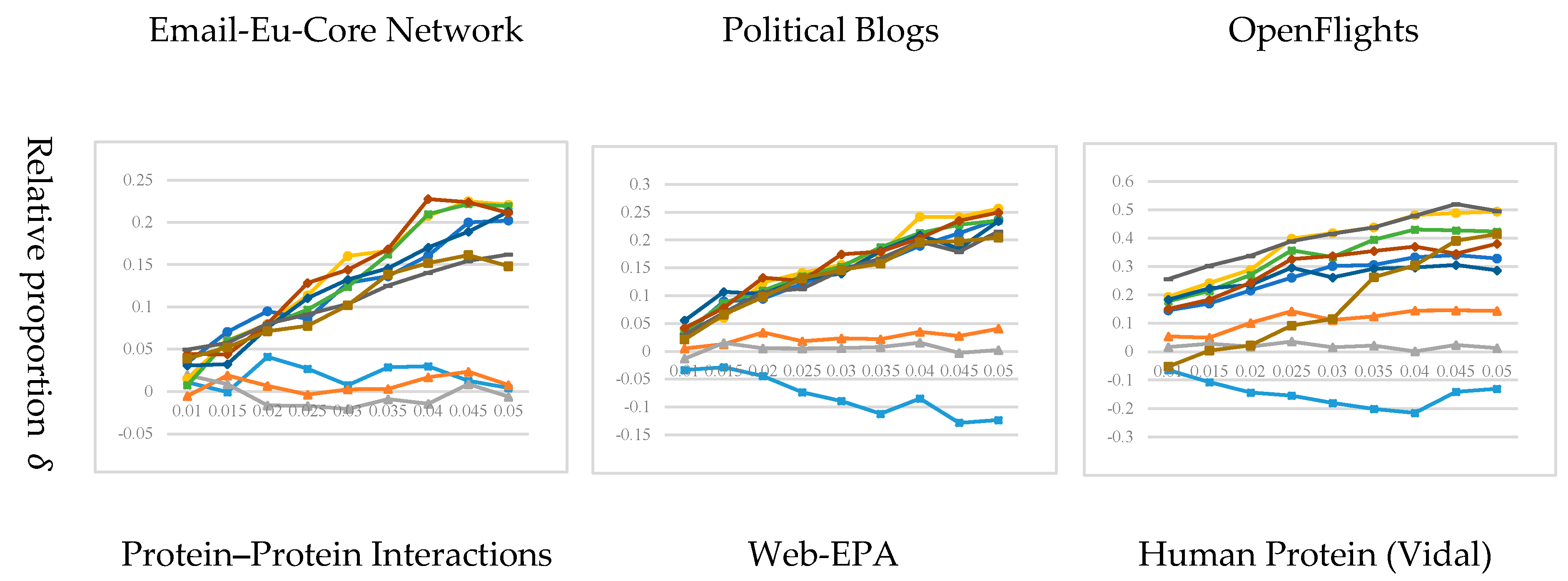
3.3. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lü, L.; Chen, D.; Ren, X.; Zhang, Q.; Zhang, Y.-C.; Zhou, T. Vital nodes identification in complex networks. Phys. Rep. 2016, 650, 1–63. [Google Scholar] [CrossRef] [Green Version]
- De Arruda, G.F.; Barbieri, A.L.; Rodriguez, P.M.; Rodrigues, F.A.; Moreno, Y.; Costa, L.D.F. Role of centrality for the identification of influential spreaders in complex networks. Phys. Rev. E 2014, 90, 032812. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Domingos, P.; Richardson, M. Mining the network value of customers. In Proceedings of the Seventh ACM SIGKDD International Conference, San Francisco, CA, USA, 26–29 August 2001; pp. 57–66. [Google Scholar]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the spread of influence through a social network. In Proceedings of the Ninth ACM SIGKDD International Conference, Washington, DC, USA, 24–27 August 2003; pp. 137–146. [Google Scholar]
- Thai, M.T.; Wu, W.; Xiong, H. Big Data in Complex and Social Networks; CRC Press: Boca Raton, FL, USA, 2016; pp. 1–242. [Google Scholar] [CrossRef]
- Peng, S.; Zhou, Y.; Cao, L.; Yu, S.; Niu, J.; Jia, W. Influence analysis in social networks: A survey. J. Netw. Comput. Appl. 2018, 106, 17–32. [Google Scholar] [CrossRef]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph evolution. ACM Trans. Knowl. Discov. Data 2007, 1, 2. [Google Scholar] [CrossRef]
- Sancen-Plaza, A.; Mendez-Vazquez, A. Influence Maximization for Big Data Through Entropy Ranking and Min-Cut. In Proceedings of the 9th IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing, Austin, TX, USA, 20–23 October 2013; pp. 87–95. [Google Scholar]
- Roy, M.; Pan, I. Lazy Forward Differential Evolution for Influence Maximization in Large Data Network. SN Comput. Sci. 2020, 1, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Wang, C.; Wang, Y. Scalable influence maximization for prevalent viral marketing in large-scale social networks. In Proceedings of the 16th ACM SIGKDD International Conference, Washington, DC, USA, 24–28 July 2010; pp. 1029–1038. [Google Scholar]
- Li, Y.; Fan, J.; Wang, Y.; Tan, K.-L. Influence Maximization on Social Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2018, 30, 1852–1872. [Google Scholar] [CrossRef]
- Banerjee, S.; Jenamani, M.; Pratihar, D.K. A survey on influence maximization in a social network. Knowl. Inf. Syst. 2020, 62, 3417–3455. [Google Scholar] [CrossRef] [Green Version]
- Holme, P.; Kim, B.J.; Yoon, C.N.; Han, S.K. Attack vulnerability of complex networks. Phys. Rev. E 2002, 65, 056109. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Wang, Y.; Yang, S. Efficient influence maximization in social networks. In Proceedings of the the 15th ACM SIGKDD International Conference, Paris, France, 28 June–1 July 2009; pp. 199–208. [Google Scholar]
- Zhao, X.; Huang, B.; Tang, M.; Zhang, H.; Chen, D.-B. Identifying effective multiple spreaders by coloring complex networks. EPL Europhys. Lett. 2014, 108, 68005. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.-X.; Chen, D.-B.; Dong, Q.; Zhao, Z.-D. Identifying a set of influential spreaders in complex networks. Sci. Rep. 2016, 6, 27823. [Google Scholar] [CrossRef]
- He, J.-L.; Fu, Y.; Chen, D.-B. A Novel Top-k Strategy for Influence Maximization in Complex Networks with Community Structure. PLoS ONE 2015, 10, e0145283. [Google Scholar] [CrossRef] [PubMed]
- Bao, Z.-K.; Liu, J.-G.; Zhang, H. Identifying multiple influential spreaders by a heuristic clustering algorithm. Phys. Lett. A 2017, 381, 976–983. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimed. Tools Appl. 2016, 77, 283–326. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutierrez, A.; Ortega, F. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.; Dimitriou, A.; Papavassiliou, S.; Vasiliki, P. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Carmi, S.; Havlin, S.; Kirkpatrick, S.; Shavitt, Y.; Shir, E. A model of Internet topology using k-shell decomposition. Proc. Natl. Acad. Sci. USA 2007, 104, 11150–11154. [Google Scholar] [CrossRef] [Green Version]
- Dey, P.; Chaterjee, A.; Roy, S. Influence maximization in online social network using different centrality measures as seed node of information propagation. Sadhana 2019, 44, 205. [Google Scholar] [CrossRef] [Green Version]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Mondragon, R. The Rich-Club Phenomenon in the Internet Topology. IEEE Commun. Lett. 2004, 8, 180–182. [Google Scholar] [CrossRef] [Green Version]
- Hethcote, H.W. The Mathematics of Infectious Diseases. SIAM Rev. 2000, 42, 599–653. [Google Scholar] [CrossRef] [Green Version]
- Wolfe, A.W. Social Network Analysis: Methods and Applications. Am. Ethnol. 1997, 24, 219–220. [Google Scholar] [CrossRef]
- Freeman, L.C. A Set of Measures of Centrality Based on Betweenness. Sociometry 1977, 40, 35. [Google Scholar] [CrossRef]
- Gullickson, T. Review of Social Network Analysis: A Handbook. Contemp. Psychol. 1993, 38, 655. [Google Scholar] [CrossRef]
- Adamic, L.A.; Glance, N. The political blogosphere and the 2004 U.S. election. In Proceedings of the 3rd International Workshop on Software Engineering for Parallel Systems, Amsterdam, The Netherlands, 1 November 2016; pp. 36–43. [Google Scholar]
- Opsahl, T.; Agneessens, F.; Skvoretz, J. Node centrality in weighted networks: Generalizing degree and shortest paths. Soc. Netw. 2010, 32, 245–251. [Google Scholar] [CrossRef]
- Livstone, M.; Breitkreutz, B.-J.; Stark, C.; Boucher, L.; Chatr-Aryamontri, A.; Oughtred, R.; Nixon, J.; Reguly, T.; Rust, J.; Winter, A.; et al. The BioGRID Interaction Database. Nat. Proc. 2011. [Google Scholar] [CrossRef]
- Rossi, R.A.; Ahmed, N.K. The network data repository with interactive graph analytics and visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 4292–4293. [Google Scholar]
- Rual, J.-F.; Venkatesan, K.; Hao, T.; Hirozane-Kishikawa, T.; Dricot, A.; Li, N.; Berriz, G.F.; Gibbons, F.D.; Dreze, M.; Ayivi-Guedehoussou, N.; et al. Towards a proteome-scale map of the human protein–protein interaction network. Nature 2005, 437, 1173–1178. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Edges | |
|---|---|---|---|
| Email-Eu-Core Network | 986 | 16,064 | 32.5842 |
| Political Blogs | 1222 | 16,714 | 27.3552 |
| OpenFlights | 2905 | 15,645 | 10.7711 |
| Protein–Protein Interactions | 3852 | 37,841 | 19.6475 |
| Web-EPA | 4253 | 8897 | 4.1839 |
| Human Protein (Vidal) | 2783 | 6607 | 4.3169 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Yan, J.; Chen, D.; Fang, B.; Huang, X. RNA: A Reject Neighbors Algorithm for Influence Maximization in Complex Networks. Mathematics 2020, 8, 1313. https://doi.org/10.3390/math8081313
Wang D, Yan J, Chen D, Fang B, Huang X. RNA: A Reject Neighbors Algorithm for Influence Maximization in Complex Networks. Mathematics. 2020; 8(8):1313. https://doi.org/10.3390/math8081313
Chicago/Turabian StyleWang, Dongqi, Jiarui Yan, Dongming Chen, Bo Fang, and Xinyu Huang. 2020. "RNA: A Reject Neighbors Algorithm for Influence Maximization in Complex Networks" Mathematics 8, no. 8: 1313. https://doi.org/10.3390/math8081313