1. Introduction
Lattice theory plays an important role in many fields in everyday life. The notion of lattices was introduced by Richard Dedekind. Further, Garrett Birrkhoff [
1] started the general development of lattice theory in the mid 1930s. George Gratzer [
2] vitally developed the theory of lattices and discussed about the applications of lattice theory. In 1965, the notion of fuzzy set was introduced by Zadeh [
3] to handle uncertainty in various fields of everyday life. Fuzzy set theory is the generalization of classical set theory, whose range values are within the integer 0 and 1 to the interval [0, 1]. Many researchers such as Xu et al., Roy et al., Majumdar and Samanta, Tripathy et al., are attracted by the concept of fuzzy sets and they have developed new notions of fuzzy sets and applied them in many fields of science and technology, economics, medical science. There are several types of fuzzy set extensions in fuzzy set theory, including intuitionistic fuzzy set, interval-valued fuzzy set, vague set, picture fuzzy set and complex fuzzy set.
In real world complicated problems in engineering, social science, economics, medical science, … classical mathematics methods are always not successful because uncertainty is always present in these problems. A wide range of existing theories such as fuzzy set theory and it extensions in decision making [
4], sensitivity analysis in MCDM problems [
5], rough set theory in forecasting [
6], probability theory, vague set theory and interval mathematics are well known. Apart from that, mathematical approaches are useful to model vagueness. Each of these concepts has its inherent difficulties as pointed out in Reference [
7].
In 1999, Molodtsov initiated a new concept of soft set theory, which can be seen as a novel mathematical tool for dealing with uncertainty which is free from the limitations. This theory is useful in different fields such as decision making, data analysis and forecasting and so forth. The soft set model can be combined with other mathematical models. Maji et al. [
8] presented the concept of generalized fuzzy soft set theory, which is based on a combination of the fuzzy set and soft set theory. In addition, this concept has proven to be very useful in many different fields. One of the most common applications of soft set is decision making support. Tran Thi Ngan et al. [
9] proposed fuzzy aggregation operators and constructed a dental disease diagnosis from X-ray images using these proposed operators. Tran Manh Tuan et al. [
10] introduced similarity measure extensions in fuzzy and neutrosophic sets. These measures were implemented in predicting linkage in a co-authorship network with higher performance. Complex fuzzy sets were used in multi-criteria decision making problems [
11]. Complex fuzzy t-norms and t-conorms were introduced in this research and applied in solving decision making problem. The complex fuzzy measures on Mamdani complex fuzzy inference systems (Mamdani CFIS) were also presented in Reference [
12]. Mamdani fuzzy inference system was extended on complex fuzzy sets. By experimenting on different data sets, Mamdani CFIS worked better comparing with Adaptive Neuro Complex Fuzzy Inference System(ANFIS) and Mamdani Fuzzy Inference System (FIS).
Sebastian and Ramakrishnan [
13] proposed the concept of multi-fuzzy sets theory, which is a more general fuzzy set using ordinary fuzzy sets as building blocks and its membership function is an ordered sequence of ordinary fuzzy membership functions. In Reference [
14], the notion of multi-fuzzy sets provides a new method to represent some problems which are difficult to explain in other extensions of fuzzy set theory, such as color of pixels. Yong et al. [
15] introduced the concept of multi-fuzzy soft set by combining the multi-fuzzy set and soft set models and provided its application in decision making under an imprecise environment. Afterwards, Dey and Pal [
16] generalized the notion of multi-fuzzy soft set and its application to decision making.
Similarity measure is an important topic for dealing with uncertain data. In recent years, many researchers have introduced different similarity measures between fuzzy sets, vague sets, soft sets, fuzzy soft sets, intuitionistic fuzzy sets and intuitionistic fuzzy soft sets. Similarity measures have been extensively studied from many aspects and applied in different fields such as decision making, pattern recognition, region extraction, coding theory, image processing, signal detection, security verification systems, medical diagnosis and so on. In 2008, Majumdar and Samanta [
17] initiated the study of uncertainty measures of soft sets and also introduced some new similarity measures for fuzzy soft sets, which is based on distance, set theoretic approach and matching function in Reference [
18]. Liu et al. [
19] proposed similarity measures and entropy of fuzzy soft sets and its properties. Feng and Zheng [
20] studied new similarity measures for fuzzy soft sets based on distance measures.
Many various similarity measures on fuzzy sets (FS) were proposed. Peng [
21] proposed similarity and distance measure on Pythagorean FS (PFS). These new measures overcame the limitations of introduced similarity or distance measures. This was prove by examples and application in pattern recognition. Fei et al. [
22] introduced a novel vector valued similarity measure between two intuitionistic fuzzy sets (IFS). This measure included the uncertainty and similarity for intuitionistic fuzzy sets. This measure was applied in solving classification problem on Iris dataset from UCI. The uncertainty supported the classification when the similarity between two classes was the same. Song et al. [
23] reviewed available similarity measures and proposed a similarity measure on IFS based on the functions of IFS (membership, non-membership and hesitation functions). The application on medical data set showed the advantages of proposed measure comparing with other presented ones. The similarity measure on complex multi-fuzzy soft set was presented in Reference [
24]. This measure was used to evaluate the alternatives in order to make accuracy decision.
Not only measure the similarity among fuzzy sets, other similarity measures on different objects were also constructed. Chenlei Lv et al. [
25] defined a measure to calculate nasal similarity among faces in 3D space. This measure was mainly based on the shape comparison, it was applied into facial classification and identification via a hierarchical structure on public facial datasets. To define users with the same behavior in recommender system based on collaborative filtering, a similarity measure was introduced by Gazdar and Hidri [
26]. By experimental results on three UCI data sets, proposed similarity measure obtained higher performance in accuracy and ranking-oriented metrics. Tran Manh Tuan et al. [
27] proposed complex fuzzy similarity measures and their weighted versions. These similarity measures were applied in a new rule reduction in order to construct an effective decision making support system.
In 2014, Zhang and Shu [
28] extended the idea of multi-fuzzy soft set and introduced the notion of possibility multi-fuzzy soft set and applied it to a decision making problem and also discussed the similarity between two possibility multi-fuzzy soft set and its application to medical diagnosis. Yousef Al-Qudah and Nasruddin Hassan introduced axiomatic definitions of entropy and similarity measure for Complex multi-fuzzy soft set in Reference [
24]. Selvachandran et al. proposed distance and distance induced intuitionistic entropy measures for the generalized intuitionistic fuzzy soft set model in Reference [
29]. The information measures of distance and similarity for the complex vague soft set model was introduced by Selvachandran et al. in References [
30,
31] respectively. Vimala et al. initiated new theories such as fuzzy lattice ordered group [
32], anti-lattice ordered fuzzy soft group [
33], lattice ordered interval-valued hesitant fuzzy soft sets [
34] and applied it to decision making problems [
35] and also introduced the new concept of complex intuitionistic fuzzy soft lattice ordered group and its weighted distance measures in Reference [
36]. Further, Sabeena begam et al. [
37] derived the concept of lattice approach on multi-fuzzy soft set and also illustrated its application using forecasting process. The similarity measure between two
was not proposed. Later, the algebraic aspects of
such as new concept of modular and distributive
were presented in Reference [
38]. Its properties were also established.
The main purpose of this paper is to introduce the concept of similarity between two lattice ordered multi-fuzzy soft sets. This is a new similarity measure between two
. To illustrate the proposed measure, two numerical examples are performed step by step. Our proposed fuzzy similarity measure has some main advantages. Firstly, this measure is simple and very efficient to evaluate. Secondly, this measure is introduced in multi-dimension using the lattice structure that makes it be easier for explanation in many problems. The properties of proposed measure and an application in decision making using this measure are also presented. Although the good properties of a similarity measure between two vectors were pointed out in Reference [
39]. But in this paper, we are checking the similarity measure based on soft set theory. Thus, properties mentioned in Reference [
39] were not suitable to evaluate our measure.
This paper is organized as follows—in
Section 2, fundamentals of fuzzy set theory, soft set theory, fuzzy soft set theory, multi-fuzzy set theory, multi-fuzzy soft set theory,
and its operations which are useful for subsequent discussions are presented. Novel similarity measures between two
are discussed in
Section 3.
Section 4 discusses the application of similarity measures in two
. In
Section 5, some conclusions and further works are provided.
3. Similarity between Two Based on Set Theoretic Approach
In this section, we introduce the concept of similarity measure of two and further results on similarity measure of two . In all the following context, denote to be the minimum of a and b, denote to be the maximum of a and b.
Definition 16. Let .
The similarity measure of and over U is defined as Example 2. Let . Let .
Let , for which .
Let which are defined as follows:
,
,
,
and
,
,
,
.
where .
By Definition 16, we obtain, Then the similarity between and over is thus
.
Theorem 1. Let . Then the following holds:
- i.
.
- ii.
.
- iii.
- iv.
.
- v.
.
Proof. (ii) Proof of this condition is trivally followed from the Definition 16.
(v) Since
,
□
Next, we discuss about the application of similarity measure.
4. Application of Using Similarity Measure in Decision Making
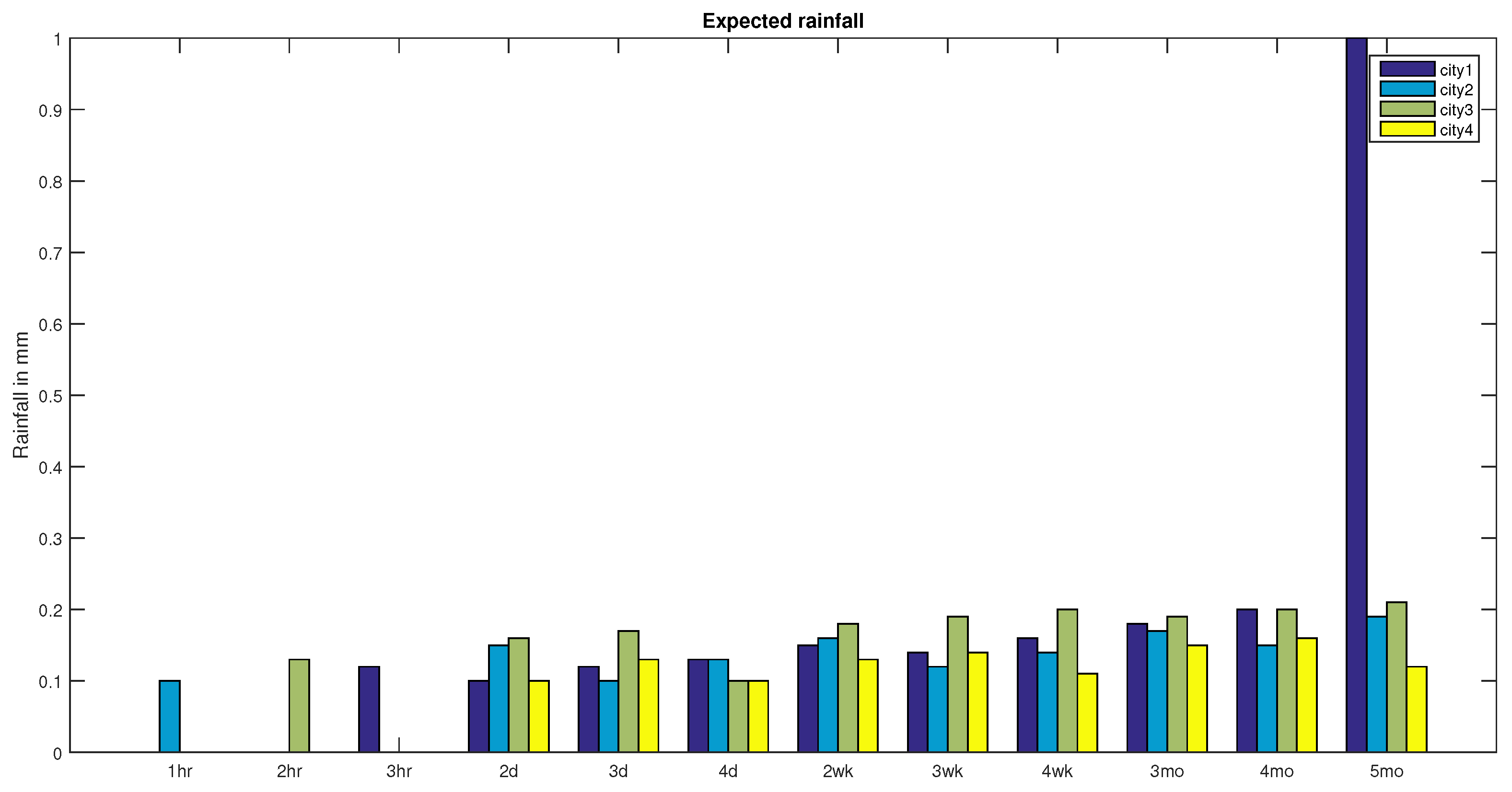
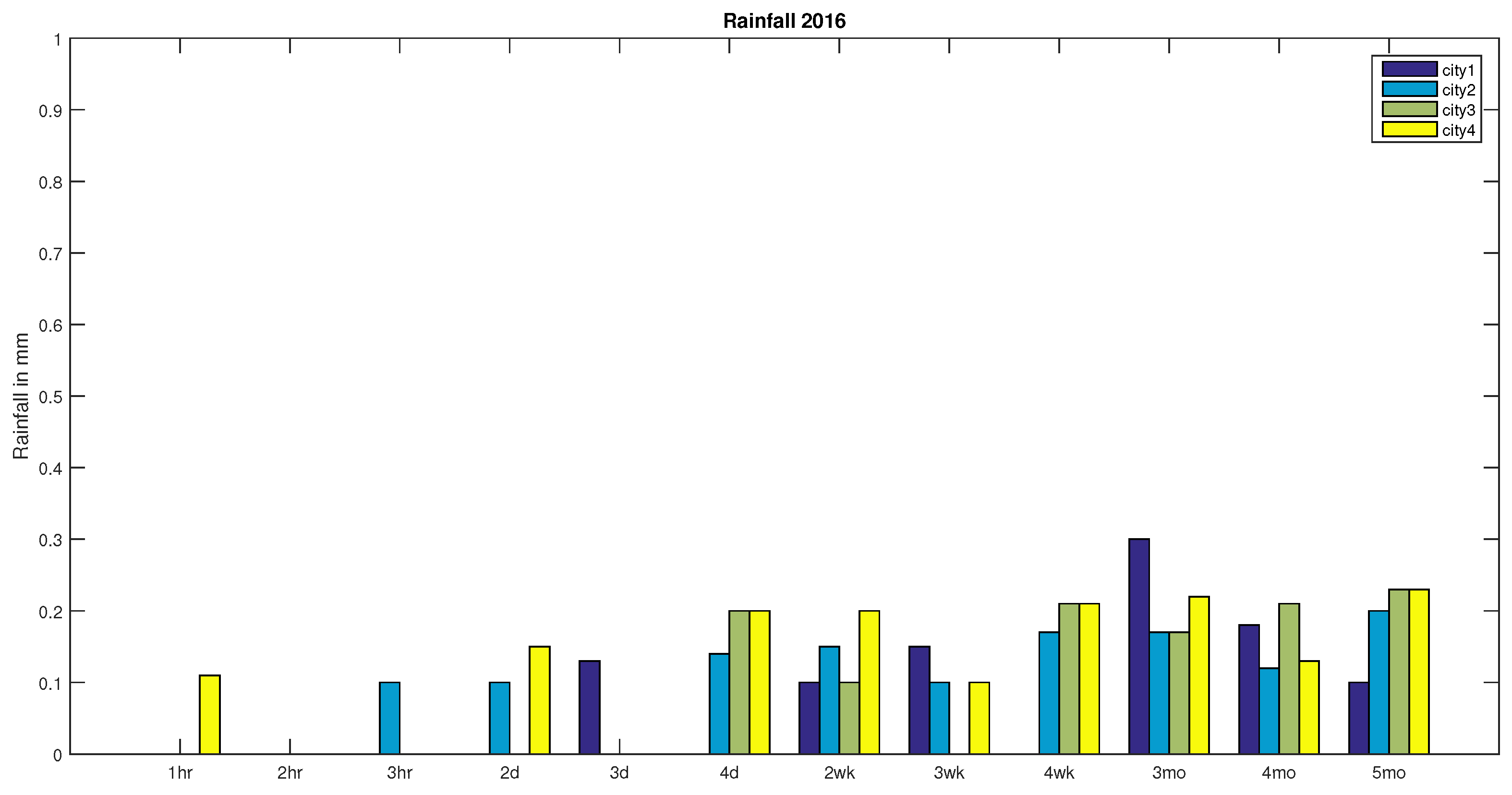
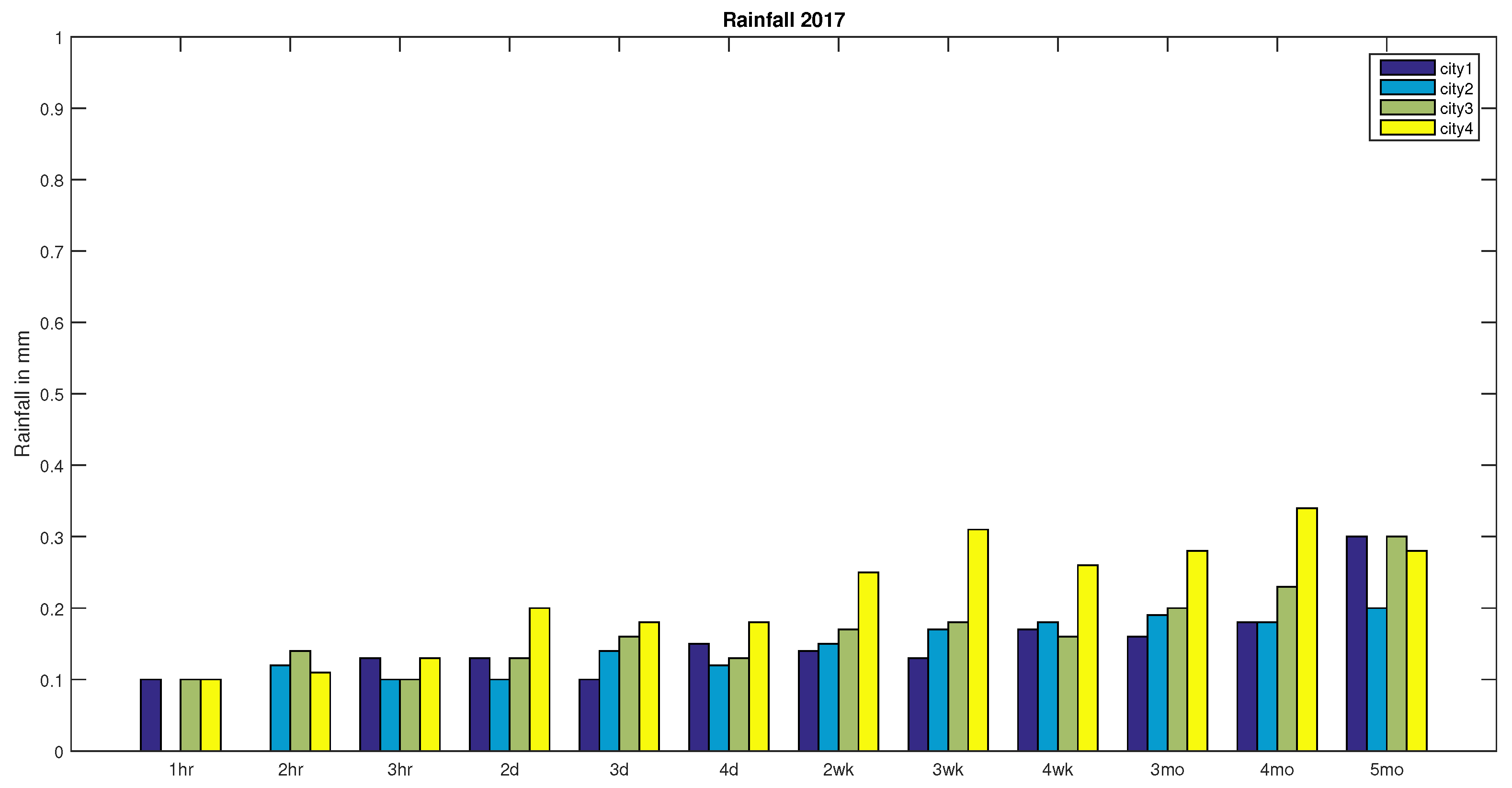
In this section, an application for the decision making by using the similarity measure of two to analyse the rainfall in 2016 and 2017 with expected rainfall.
Let be the universal set, where stands for the set of four cities in India. Let as the parameters which is consider as the set of rainfalls in rainy season, where stands for “Hour-wise rainfall” which includes 1 h, 2 h, and 3 h, stands for “Day-wise rainfall” which includes 2 day, 3 day and 4 day, stands for “Week-wise rainfall” which includes 2 week, 3 week, 4 week and stands for “Month-wise rainfall” which includes 3 month, 4 month, 5 month respectively.
In this example, suppose represents the expected rainfall in India, defined as follows:
,
,
.
Now let represents the recorded rainfall in India for the year 2016 and 2017 respectively, defined as follows:
,
,
,
,
,
.
In order to make the decision of whether the rainfall in 2016 or the rainfall in 2017 is the expected rainfall in India, we use similarity measure on to calculate the similarity between the expected rainfall and the rainfall in 2016 (); the similarity between the expected rainfall and the rainfall in 2017 (). Comparing the obtained results, the higher similarity means the closer to expected rainfall.
First we calculate the similarity measure between
and
:
Hence .
Next we calculate the similarity measure between
and
:
Hence .
It is clear from the above results, that has significantly greater similarity to , as compared with to . So we conclude that the rainfall in 2016 is not an expected rainfall and the rainfall in 2017 is an expected rainfall in India.






{kind=link}
{kind=link}
{kind=link}