Using an Adaptive Fuzzy Neural Network Based on a Multi-Strategy-Based Artificial Bee Colony for Mobile Robot Control


Abstract
1. Introduction
2. The Structure of Pioneer 3-DX Mobile Robot
3. The Proposed Controller and Its Related Learning Algorithm
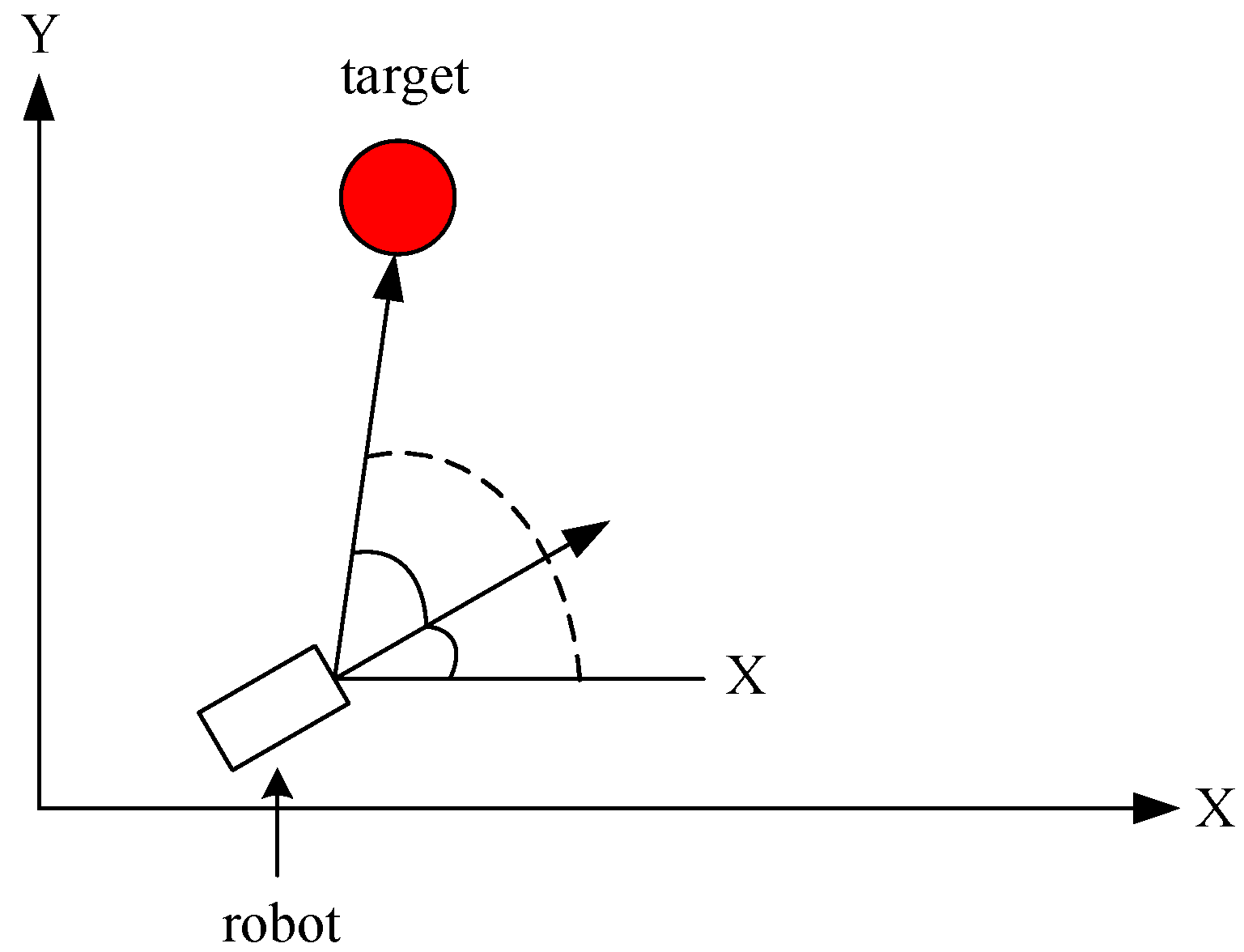
3.1. An Adaptive Fuzzy Neural Network (AFNN)
3.2. Proposed Multi-Strategy Artificial Bee Colony Learning Algorithm
- Step1:
- Initial SN individual of population. Each individual has D dimensions, and each individual of each dimension is in accordance with the evolutional problem that defines the border. It is random a number from the defined border. In this study, the initial fuzzy rule coding for AFNN and more AFNN of a set is called population. Figure 4 shows an AFNN applied to mobile robots for navigation control.
- Step2:
- Next, according to the evolutional problem, an appropriate evaluation function is designed, which is detailed in the next section.
- Step3:
- Next, multiple strategy selection is performed. Each strategy of the success and failure number is used to calculate each strategy of probability. Initial success and failure number are set as zero. A fuzzification operation serves as the Gaussian membership function:where K represents the strategy number, G represents the evaluation number, PkG represents the probability of k number strategy, and SkG represents the parameter of k strategy. SkG is expressed as follows:where ns represents the success number, nf represents the failure number, and g to G − 1 represent the collected data number of ns with nf. By contrast, LP success and failure numbers are collected.
- Step4:
- The algorithm applies the probability and select strategy, which evaluates a new individual. It acquires a new fitness and greedy select best individual; according to the greedy selection of the result that saves each strategy of success and failure number.where ϕi represents a uniformly distributed random number between [−1,1] and k represents a randomly selected number of individuals; i ≠ k.
- Step5:
- Thereafter, the algorithm conducts the onlooker bee before. It is necessary to calculate the probability with which each individual is selected. Let the onlooker bee appropriately select more best individuals of fitness than the individuals explored and developed again.
- Step6:
- It uses Step4, which has updated success and failure number, for calculating the probability of selecting each strategy.
- Step7:
- The population size limit of the onlooker bee is used to select the individual and strategy of the number. Let the best performance of an individual have a large probability that can acquire the exploration and development chance again. The onlooker bee equation is the same as the employ bee equation shown in Step3.
- Step8:
- The scout bee determines whether that algorithm falls into the local minimum. The best individual repeats the initial equation when its iteration number exceeds the parameter “limit.” The algorithm has some disturbance for avoiding falling into the local minimum. The initial equation is expressed as follows:
- Step9:
- Thereafter, it finds the best individual from the population compared so far and the best individual greed selection and update.
4. Navigation Control of a Mobile Robot
4.1. The Proposed Navigation Method
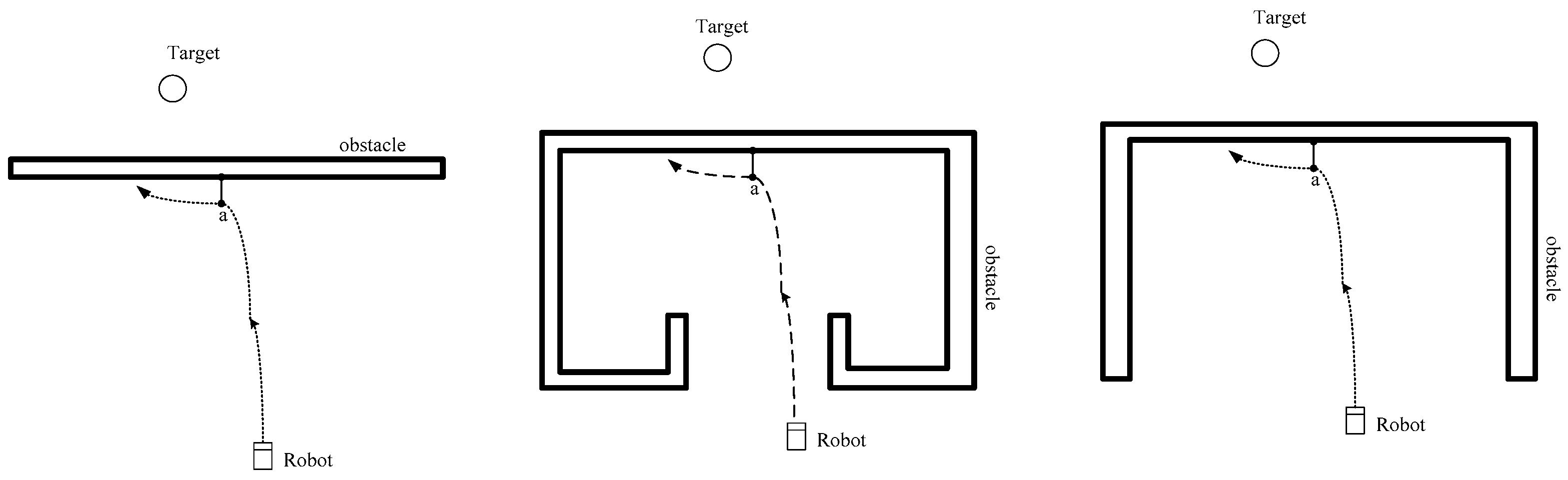
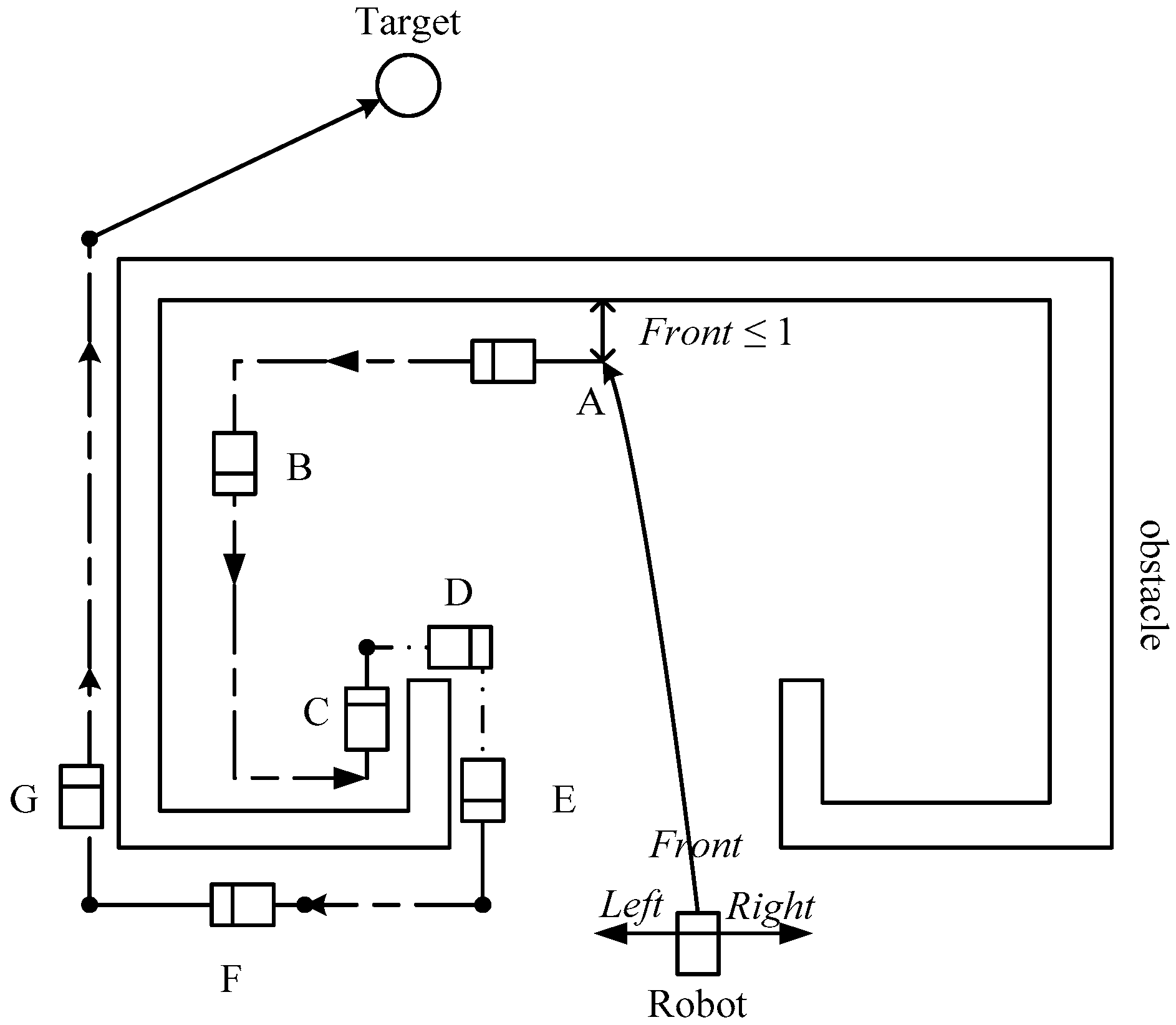
4.2. The Escape Method in Special Environments
5. Experimental Results
5.1. Performance Comparisons of Various Learning Algorithms
5.2. Verification of Mobile Robot Escape in Special Environments
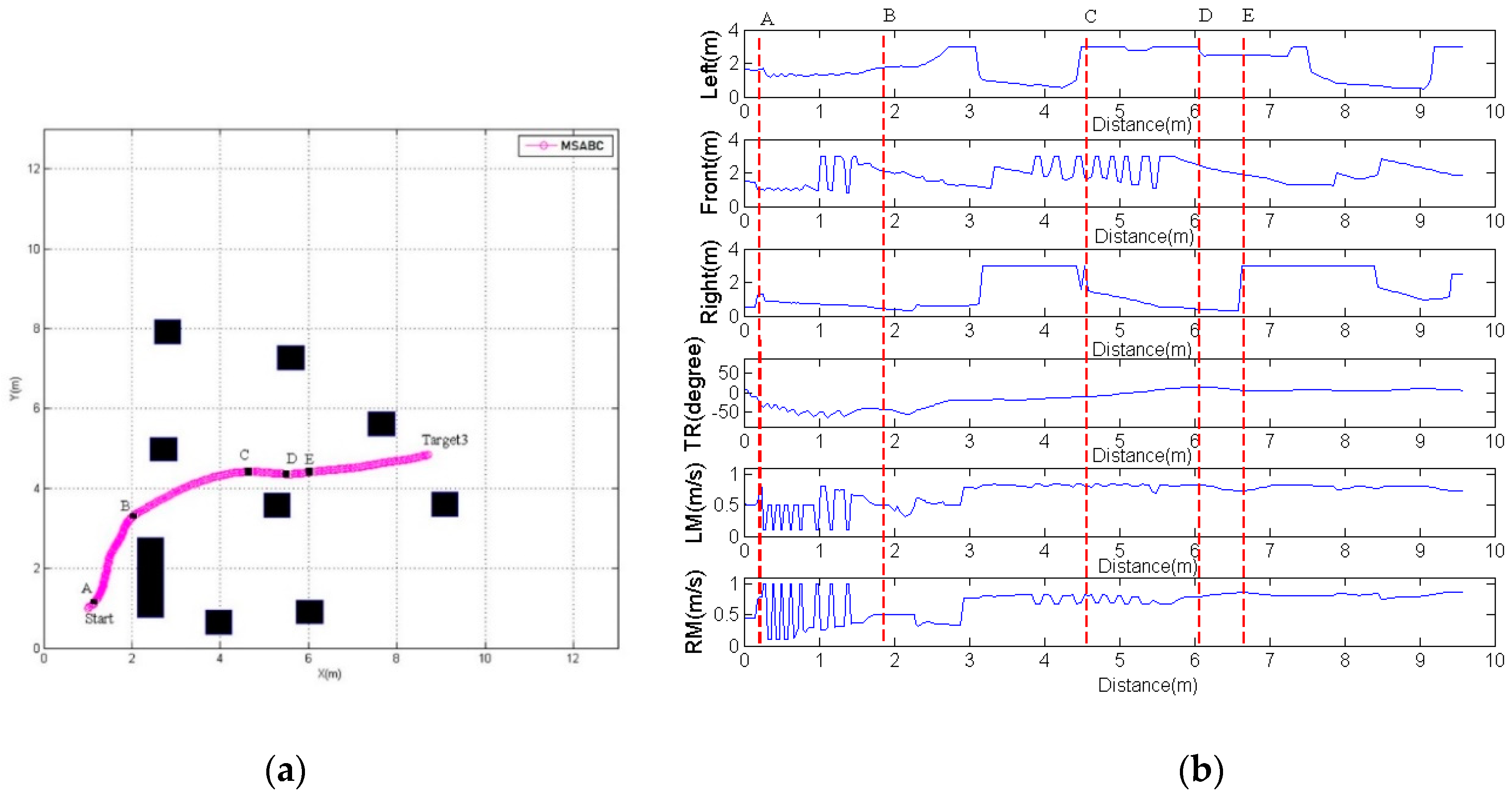
5.3. PIONEER 3-DX Robot Navigation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Seraji, H.; Howard, A. Behavior-based robot navigation on challenging terrain: A fuzzy logic approach. IEEE Trans. Robot. Autom. 2002, 18, 308–321. [Google Scholar] [CrossRef]
- Abdessemed, F.; Benmahammed, K.; Monacelli, E. A fuzzy-based reactive controller for a non-holonomic mobile robot. Robot. Auton. Syst. 2004, 47, 31–46. [Google Scholar] [CrossRef]
- Pratihar, D.K.; Deb, K.; Ghosh, A. A genetic-fuzzy approach for mobile robot navigation among moving obstacles. Int. J. Approx. Reason. 1999, 20, 145–172. [Google Scholar] [CrossRef]
- Boubertakh, H.; Tadjine, M.; Glorennec, P.Y. A new mobile robot navigation method using fuzzy logic and a modified Q-learning algorithm. J. Intell. Fuzzy Syst. 2010, 21, 113–119. [Google Scholar] [CrossRef]
- Juang, C.F.; Chang, Y.C. Evolutionary-group-based particle-swarm-optimized fuzzy controller with application to mobile-robot navigation in unknown environments. IEEE Trans. Fuzzy Syst. 2011, 19, 379–392. [Google Scholar] [CrossRef]
- Yang, J.; Zhuang, Y.; Li, C. Towards behavior control for evolutionary robot based on RL with ENN. Int. J. Adv. Robot. Syst. 2012, 10, 157. [Google Scholar] [CrossRef]
- Nakhaeinia, D.; Karasfi, B. A behavior-based approach for collision avoidance of mobile robots in unknown and dynamic environments. J. Intell. Fuzzy Syst. 2013, 24, 299–311. [Google Scholar] [CrossRef]
- Mohanty, P.K.; Parhi, D.R. A new intelligent motion planning for mobile robot navigation using multiple adaptive neuro-fuzzy inference system. Appl. Math. Inf. Sci. 2014, 8, 2527–2535. [Google Scholar] [CrossRef][Green Version]
- Eiben, A.E.; Hinterding, R.; Michalewicz, Z. Parameter control in evolutionary algorithms. IEEE Trans. Evol. Comput. 1999, 3, 124–141. [Google Scholar] [CrossRef]
- Hu, Y.; Zheng, J.; Zou, J.; Yang, S.; Ou, J. A dynamic multi-objective evolutionary algorithm based on intensity of environmental change. Inf. Sci. 2020, 523, 49–62. [Google Scholar] [CrossRef]
- Cordon, O.; Gomide, F.; Herrera, F.; Hoffmann, F.; Magdalena, L. Ten years of genetic fuzzy systems: Current framework and new trends. Fuzzy Sets Syst. 2004, 141, 5–31. [Google Scholar] [CrossRef]
- Kong, F.; Jiang, J.; Huang, Y. An Adaptive Multi-Swarm Competition Particle Swarm Optimizer for Large-Scale Optimization. Mathematics 2019, 7, 521. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Li, L.; Jayasena, K.P.N.; Xiong, S. Multiobjective big data optimization based on a hybrid salp swarm algorithm and differential evolution. Appl. Math. Model. 2020, 80, 929–943. [Google Scholar] [CrossRef]
- Weile, D.S.; Michielssen, E. Genetic algorithm optimization applied to electromagnetics: A review. IEEE Trans. Antennas Propag. 1997, 45, 343–353. [Google Scholar] [CrossRef]
- Coelho, L.D.S.; Herrera, B.M. Fuzzy identification based on a chaotic particle swarm optimization approach applied to a nonlinear yo-yo motion system. IEEE Trans. Ind. Electron. 2007, 54, 3234–3324. [Google Scholar] [CrossRef]
- Wai, R.J.; Lee, J.D.; Chuang, K.L. Real-time PID control strategy for maglev transportation system via particle swarm optimization. IEEE Trans. Ind. Electron. 2011, 58, 629–646. [Google Scholar] [CrossRef]
- Price, K.V.; Storn, R.M.; Lampinen, J.A. Differential Evolution: A Practical Approach to Global Optimization; Springer-Verlag: Berlin, Germany, 2005. [Google Scholar]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M.A. Opposition-based differential evolution. IEEE Trans. Evol. Comput. 2008, 12, 107–125. [Google Scholar] [CrossRef]
- Wang, Y.; Cai, Z.X.; Zhang, Q.F. Differential evolution with composite trial vector generation strategies and control parameters. IEEE Trans. Evol. Comput. 2011, 15, 55–66. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Yang, X.S. Engineering optimizations via nature-inspired virtual bee algorithms. Lect. Notes Comput. Sci. 2005, 3562, 317–323. [Google Scholar]
- Pham, D.T.; Ghanbarzadeh, A.; Koc, E.; Otri, S.; Rahim, S.; Zaidi, M. The Bees Algorithm, Technical Report; Manufacturing Engineering Centre, Cardiff University: Cardiff, UK, 2005. [Google Scholar]
- Karaboga, D. An Idea Based on Honeybee Swarm for Numerical Optimization; Computer Engineering Department, Engineering Faculty, Erciyes University: Talas/Kayseri, Turkey, 2005. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Lin, T.C.; Chen, C.C.; Lin, C.J. Wall-following and navigation control of mobile robot using reinforcement learning based on dynamic group artificial bee colony. J. Intell. Robot. Syst. 2018, 92, 343–357. [Google Scholar] [CrossRef]
- Karaboga, D.; Gorkemli, B. Solving traveling salesman problem by using combinatorial artificial bee colony algorithms. Int. J. Artif. Intell. Tools 2019, 28, 1950004. [Google Scholar] [CrossRef]
- Karaboga, D.; Aslan, S. Discovery of conserved regions in DNA sequences by artificial bee colony (ABC) algorithm based methods. Nat. Comput. 2019, 18, 333–350. [Google Scholar] [CrossRef]
- Karaboga, D.; Kaya, E. Training ANFIS by using an adaptive and hybrid artificial bee colony algorithm (aABC) for the identification of nonlinear static systems. Arab. J. Sci. Eng. 2019, 44, 3531–3547. [Google Scholar] [CrossRef]
- Chen, C.H. An efficient compensatory neuro-fuzzy system and its applications. Int. J. Gen. Syst. 2012, 41, 353–371. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X′1 X′2 | Near | Medium | Far |
|---|---|---|---|
| Near | Back | Fast | Fast |
| Medium | Fast | Medium | Medium |
| Far | Fast | Slow | Slow |
| X′1 X′2 | Near | Medium | Far |
|---|---|---|---|
| Near | Back | Slow | Slow |
| Medium | Back | Medium | Medium |
| Far | Back | Fast | Fast |
| Parameters | Values |
|---|---|
| Population size (PS) | 30 |
| Crossover rate (CR) | 0.9 |
| Scale factor (F) | 0.5 |
| Evaluation number | 10,000 |
| Number of rule | 10 |
| Scout bee limit | 40 |
| LP | 50 |
| Algorithms | MSABC | DE\Best1 | DE\Best2 | DE\Rand\Best\1 | DE\Rand\Best\2 | ABC |
|---|---|---|---|---|---|---|
| Average fitness f | 2.362 | 2.173 | 1.796 | 2.112 | 1.9317 | 1.314 |
| STD | 0.16 | 0.387 | 0.2819 | 0.231 | 0.235 | 0.29 |
| Algorithms | MSABC | DE\Best1 | ||
| Evaluation Function | NavigationTime (s) | TravelDistance (m) | NavigationTime (s) | TravelDistance (m) |
| Target 1 | 9.184 | 7.8884 | 10.784 | 7.8508 |
| Target 2 | 15.648 | 11.4683 | 17.248 | 11.4190 |
| Target 3 | 14.6875 | 9.5638 | 16.0625 | 9.6121 |
| Algorithms | DE\Best2 | DE\Rand\Best\1 | ||
| EvaluationFunction | NavigationTime (s) | TravelDistance (m) | NavigationTime (s) | TravelDistance (m) |
| Target 1 | 9.504 | 7.7824 | 9.76 | 7.7982 |
| Target 2 | 16.416 | 11.3935 | 17.376 | 11.425 |
| Target 3 | 15.75 | 9.6328 | 15.8125 | 9.6047 |
| Algorithms | DE\Rand\Best\2 | ABC | ||
| EvaluationFunction | NavigationTime (s) | TravelDistance (m) | NavigationTime (s) | TravelDistance (m) |
| Target 1 | 11.168 | 7.8614 | 12.256 | 7.501 |
| Target 2 | 20.832 | 11.9809 | 24.96 | 10.8298 |
| Target 3 | 19.625 | 11.1805 | 23.168 | 11.2815 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-H.; Jeng, S.-Y.; Lin, C.-J. Using an Adaptive Fuzzy Neural Network Based on a Multi-Strategy-Based Artificial Bee Colony for Mobile Robot Control. Mathematics 2020, 8, 1223. https://doi.org/10.3390/math8081223
Chen C-H, Jeng S-Y, Lin C-J. Using an Adaptive Fuzzy Neural Network Based on a Multi-Strategy-Based Artificial Bee Colony for Mobile Robot Control. Mathematics. 2020; 8(8):1223. https://doi.org/10.3390/math8081223
Chicago/Turabian StyleChen, Cheng-Hung, Shiou-Yun Jeng, and Cheng-Jian Lin. 2020. "Using an Adaptive Fuzzy Neural Network Based on a Multi-Strategy-Based Artificial Bee Colony for Mobile Robot Control" Mathematics 8, no. 8: 1223. https://doi.org/10.3390/math8081223
APA StyleChen, C.-H., Jeng, S.-Y., & Lin, C.-J. (2020). Using an Adaptive Fuzzy Neural Network Based on a Multi-Strategy-Based Artificial Bee Colony for Mobile Robot Control. Mathematics, 8(8), 1223. https://doi.org/10.3390/math8081223