2. G-Optimal Designs
Let
denote the space of
d-variate real polynomials of total degree not greater than
n, restricted to a (discrete or continuous) compact set
, and let
be a design, that is, a probability measure, with
. In what follows we assume that
is
determining for
[
13], that is, polynomials in
vanishing on
vanish everywhere on
.
In the theory of optimal designs, a key role is played by the diagonal of the reproducing kernel for
in
(also called the Christoffel polynomial of degree
m for
)
where
is any
-orthonormal basis of
. Recall that
can be proved to be independent of the choice of the orthonormal basis. Indeed, a relevant property is the following estimate of the
-norm in terms of the
-norm of polynomials
Now, by (
1) and
-orthonormality of the basis we get
which entails that
.
Then, a probability measure
is then called a G-optimal design for polynomial regression of degree
m on
if
Observe that, since
for every
, an optimal design has also the following property
,
-a.e. in
.
Now, the well-known Kiefer-Wolfowitz General Equivalence Theorem [
14] (a cornerstone of optimal design theory), asserts that the difficult min-max problem (
4) is equivalent to the much simpler maximization problem
where
is the Gram matrix (or information matrix in statistics) of
in a fixed polynomial basis
of
. Such an optimality is called D-optimality, and ensures that an optimal measure always exists, since the set of Gram matrices of probability measures is compact and convex; see for example, References [
5,
12] for a general proof of these results, valid for continuous as well as for discrete compact sets.
Notice that an optimal measure is neither unique nor necessarily discrete (unless
is discrete itself). Nevertheless, the celebrated Tchakaloff Theorem ensures the existence of a positive quadrature formula for integration in
on
, with cardinality not exceeding
and which is exact for all polynomials in
. Such a formula is then a design itself, and it generates the same orthogonal polynomials and hence the same Christoffel polynomial of
, preserving G-optimality (see Reference [
15] for a proof of Tchakaloff Theorem with general measures).
We recall that G-optimality has two important interpretations in terms of statistical and deterministic polynomial regression.
From a statistical viewpoint, it is the probability measure on
that minimizes the maximum prediction variance by polynomial regression of degree
m, cf. for example, Reference [
5].
On the other hand, from an approximation theory viewpoint, if we call
the corresponding weighted least squares projection operator
, namely
by (
2) we can write for every
(where the second inequality comes from
-orthogonality of the projection), which gives
that is a G-optimal measure minimizes (the estimate of) the weighted least squares uniform operator norm.
We stress that in this paper we are interested in the fully discrete case of a finite design space , so that any design is identified by a set of positive weights (masses) summing up to 1 and integrals are weighted sums.
3. Computing near G-Optimal Compressed Designs
Since in the present context we have a finite design space , we may think a design as a vector of non-negative weights attached to the points, such that (the support of being identified by the positive weights). Then, a G-optimal (or D-optimal) design is represented by the corresponding non-negative vector . We write for the Christoffel polynomial and similarly for other objects (spaces, operators, matrices) corresponding to a discrete design. At the same time, , and (a weighted functional space on X) with .
In order to compute an approximation of the desired
, we resort to the basic multiplicative algorithm proposed by Titterington in the ’70s (cf. Reference [
16]), namely
with initialization
. Such an algorithm is known to be convergent sublinearly to a D-optimal (or G-optimal by the Kiefer-Wolfowitz Equivalence Theorem) design, with an increasing sequence of Gram determinants
where
V is a Vandermonde-like matrix in any fixed polynomial basis of
; cf., for example, References [
7,
10]. Observe that
is indeed a vector of positive probability weights if such is
. In fact, the Christoffel polynomial
is positive on
X, and calling
the probability measure on
X associated with the weights
we get immediately
by (
3) in the discrete case
.
Our implementation of (
7) is based on the functions
The function dCHEBVAND computes the
d-variate Chebyshev-Vandermonde matrix
, where
,
,
, is a suitably ordered total-degree product Chebyshev basis of the minimal box
containing
X, with
,
. Here we have resorted to the codes in Reference [
17] for the construction and enumeration of the required “monomial” degrees. Though the initial basis is then orthogonalized, the choice of the Chebyshev basis is dictated by the necessity of controlling the conditioning of the matrix. This would be on the contrary extremely large with the standard monomial basis, already at moderate regression degrees, preventing a successful orthogonalization.
Indeed, the second function dORTHVAND computes a Vandermonde-like matrix in a
u-orthogonal polynomial basis on
X, where
u is the probability weight array. This is accomplished essentially by numerical rank evaluation for
and QR factorization
(with
Q orthogonal rectangular and
R square invertible), where
. The matrix
has full rank and corresponds to a selection of the columns of
C (i.e., of the original basis polynomials) via QR with column pivoting, in such a way that these form a basis of
, since
. A possible alternative, not yet implemented, is the direct use of a rank-revealing QR factorization. The in-out parameter “jvec” allows to pass directly the column index vector corresponding to a polynomial basis after a previous call to dORTHVAND with the same degree
n, avoiding numerical rank computation and allowing a simple “economy size” QR factorization of
.
Summarizing,
U is a Vandermonde-like matrix for degree
n on
X in the required
u-orthogonal basis of
, that is
where
is the multi-index resulting from pivoting. Indeed by (
8) we can write the scalar product
as
for
, which shows orthonormality of the polynomial basis in (
9).
We stress that
could be strictly smaller than
, when there are polynomials in
vanishing on
X that do not vanish everywhere. In other words,
X lies on a lower-dimensional algebraic variety (technically one says that
X is not
-determining [
13]). This certainly happens when
is too small, namely
, but think for example also to the case when
and
X lies on the 2-sphere
(independently of its cardinality), then we have
.
Iteration (
7) is implemented within the third function dNORD whose name stands for
d-dimensional Near G-Optimal Regression Designs, which calls dORTHVAND with
. Near optimality is here twofold, namely it concerns both the concept of G-efficiency of the design and the sparsity of the design support.
We recall that G-efficiency is the percentage of G-optimality reached by a (discrete) design, measured by the ratio
knowing that
by (
3) in the discrete case
. Notice that
can be easily computed after the construction of the
u-orthogonal Vandermonde-like matrix
U by dORTHVAND, as
In the multiplicative algorithm (
7), we then stop iterating when a given threshold of G-efficiency (the input parameter “gtol” in the call to dNORD) is reached by
, since
as
, say for example
or
. Since convergence is sublinear and in practice we see that
, for a
G-efficiency the number of iterations is typically in the tens, whereas it is in the hundreds for
one and in the thousands for
. When a G-efficiency very close to 1 is needed, one could resort to more sophisticated multiplicative algorithms, see for example, References [
9,
10].
In many applications however a G-efficiency of 90–
could be sufficient (then we may speak of near G-optimality of the design), but though in principle the multiplicative algorithm converges to an optimal design
on
X with weights
and cardinality
, such a sparsity is far from being reached after the iterations that guarantee near G-optimality, in the sense that there is a still large percentage of non-negligible weights in the near optimal design weight vector, say
Following References [
18,
19], we can however effectively compute a design which has the same G-efficiency of
but a support with a cardinality not exceeding
, where in many applications
, obtaining a remarkable compression of the near optimal design.
The theoretical foundation is a generalized version [
15] of Tchakaloff Theorem [
20] on positive quadratures, which asserts that for every measure on a compact set
there exists an algebraic quadrature formula exact on
, with positive weights, nodes in
and cardinality not exceeding
.
In the present discrete case, that is, where the designs are defined on
, this theorem implies that for every design
on
X there exists a design
, whose support is a subset of
X, which is exact for integration in
on
. In other words, the design
has the same basis moments (indeed, for any basis of
)
where
,
are the weights of
,
and
are the positive weights of
. For
, which certainly holds if
, this represents a compression of the design
into the design
, which is particularly useful when
.
In matrix terms this can be seen as the fact that the underdetermined
-moment system
has a non-negative solution
whose positive components, say
,
, determine the support points
(for clarity we indicate here by
the matrix
U computed by dORTHVAND at degree
n). This fact is indeed a consequence of the celebrated Caratheodory Theorem on conic combinations [
21], asserting that a linear combination with non-negative coefficients of
M vectors in
with
can be re-written as linear positive combination of at most
N of them. So, we get the discrete version of Tchakaloff Theorem by applying Caratheodory Theorem to the columns of
in the system (
11), ensuring then existence of a non-negative solution
v with at most
nonzero components.
In order to compute such a solution to (
11) we choose the strategy based on Quadratic Programming introduced in Reference [
22], namely on sparse solution of the Non-Negative Least Squares (NNLS) problem
by a new accelerated version of the classical Lawson-Hanson active-set method, proposed in Reference [
3] in the framework of design optimization in
and implemented by the function LHDM (Lawson-Hanson with Deviation Maximization), that we tune in the present package for very large-scale
d-variate problems (see the next subsection for a brief description and discussion). We observe that working with an orthogonal polynomial basis of
allows to deal with the well-conditioned matrix
in the Lawson-Hanson algorithm.
The overall computational procedure is implemented by the function
,
where dCATCH stands for d-variate CAratheodory-TCHakaloff discrete measure compression. It works for any discrete measure on a discrete set X. Indeed, it could be used, other than for design compression, also in the compression of d-variate quadrature formulas, to give an example. The output parameter is the array of support points of the compressed measure, while is the corresponding positive weight array (that we may call a d-variate near G-optimal Tchakaloff design) and is the moment residual. This function is called LHDM.
In the present framework we call dCATCH with
and
, cf. (
10), that is, we solve
In such a way the compressed design generates the same scalar product of
in
, and hence the same orthogonal polynomials and the same Christoffel function on
X keeping thus invariant the G-efficiency
with a (much) smaller support.
From a deterministic regression viewpoint (approximation theory), let us denote by the polynomial in of best uniform approximation for f on X, where we assume with , D being a compact domain (or even lower-dimensional manifold), and by and the best uniform polynomial approximation errors on X and D.
Then, denoting by
and
the weighted least squares polynomial approximation of
f (cf. (
5)) by the near G-optimal weights
and
w, respectively, with the same reasoning used to obtain (
6) and by (
13) we can write the operator norm estimates
Moreover, since
for any
, we can write the near optimal estimate
Notice that
is constructed by sampling
f only at the compressed support
. The error depends on the regularity of
f on
, with a rate that can be estimated whenever
D admits a multivariate Jackson-like inequality, cf. Reference [
23].
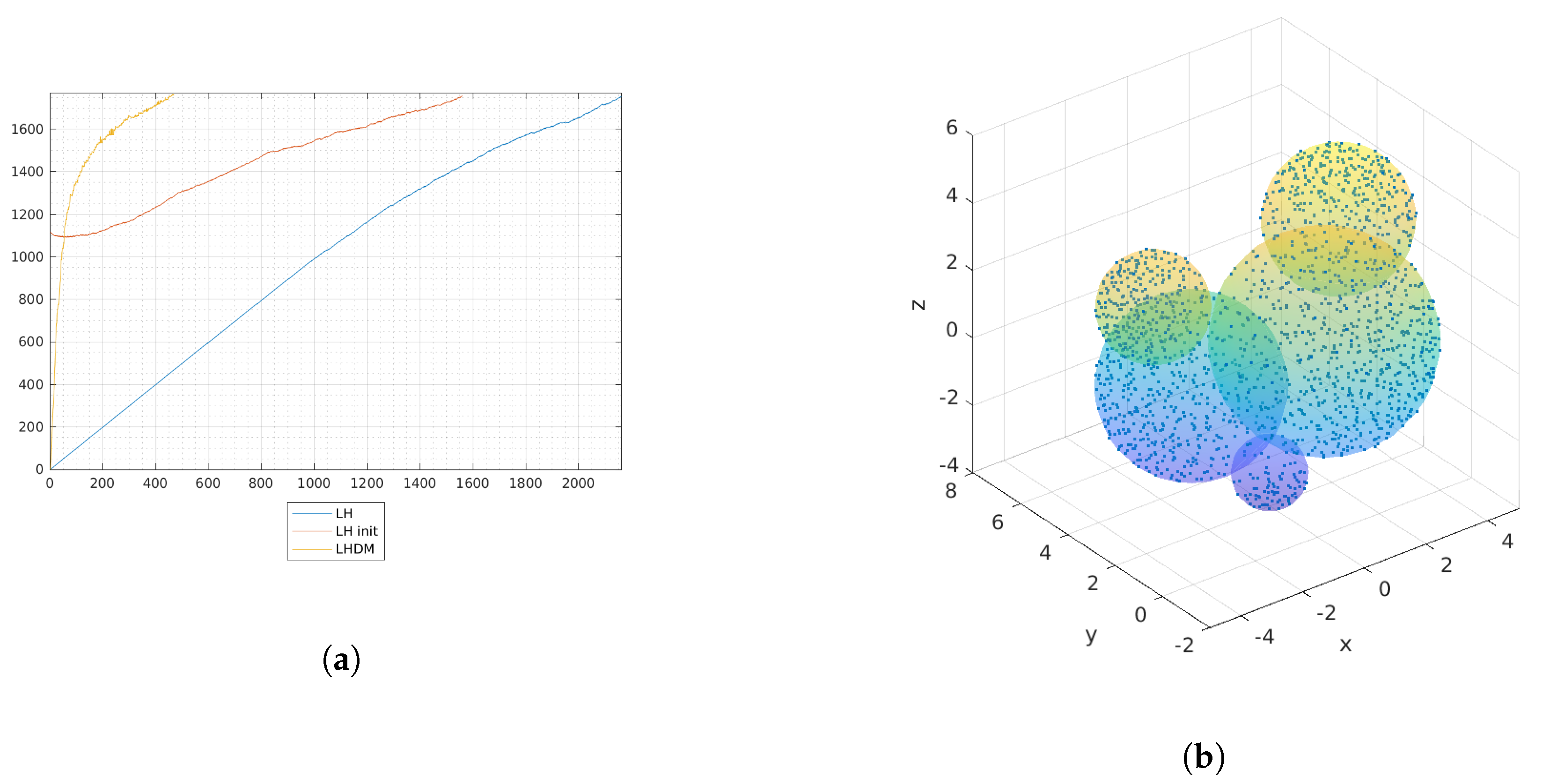
Accelerating the Lawson-Hanson Algorithm by Deviation Maximization (LHDM)
Let
and
. The NNLS problem consists of seeking
that solves
This is a convex optimization problem with linear inequality constraints that define the
feasible region, that is the positive orthant
. The very first algorithm dedicated to problem (
14) is due to Lawson and Hanson [
24] and it is still one of the most often used. It was originally derived for solving overdetermined linear systems, with
. However, in the case of underdetermined linear systems, with
, this method succeeds in sparse recovery.
Recall that for a given point
x in the feasible region, the index set
can be partitioned into two sets: the active set
Z, containing the indices of active constraints
, and the passive set
P, containing the remaining indices of inactive constraints
. Observe that an optimal solution
of (
14) satisfies
and, if we denote by
and
the corresponding passive and active sets respectively,
also solves in a least square sense the following unconstrained least squares subproblem
where
is the submatrix containing the columns of
A with index in
, and similarly
is the subvector made of the entries of
whose index is in
. The remaining entries of
, namely those whose index is in
, are null.
The Lawson-Hanson algorithm, starting from a null initial guess
(which is feasible), incrementally builds an optimal solution by moving indices from the active set
Z to the passive set
P and vice versa, while keeping the iterates within the feasible region. More precisely, at each iteration first order information is used to detect a column of the matrix
A such that the corresponding entry in the new solution vector will be strictly positive; the index of such a column is moved from the active set
Z to the passive set
P. Since there’s no guarantee that the other entries corresponding to indices in the former passive set will stay positive, an inner loop ensures the new solution vector falls into the feasible region, by moving from the passive set
P to the active set
Z all those indices corresponding to violated constraints. At each iteration a new iterate is computed by solving a least squares problem of type (
15): this can be done, for example, by computing a QR decomposition, which is substantially expensive. The algorithm terminates in a finite number of steps, since the possible combinations of passive/active set are finite and the sequence of objective function values is strictly decreasing, cf. Reference [
24].
The
deviation maximization (DM) technique is based on the idea of adding a whole set of indices
T to the passive set at each outer iteration of the Lawson-Hanson algorithm. This corresponds to select a block of new columns to insert in the matrix
, while keeping the current solution vector within the feasible region in such a way that sparse recovery is possible when dealing with non-strictly convex problems. In this way, the number of total iterations and the resulting computational cost decrease. The set
T is initialized to the index chosen by the standard Lawson-Hanson (LH) algorithm, and it is then extended, within the same iteration, using a set of candidate indices
C chosen is such a way that the corresponding entries are likely positive in the new iterate. The elements of
T are then chosen carefully within
C: note that if the columns corresponding to the chosen indices are linearly dependent, the submatrix of the least squares problem (
15) will be rank deficient, leading to numerical difficulties. We add
k new indices, where
k is an integer parameter to tune on the problem size, in such a way that, at the end, for every pair of indices in the set
T, the corresponding column vectors form an angle whose cosine in absolute value is below a given threshold
. The whole procedure is implemented in the function
.
The input variable is a structure containing the user parameters for the LHDM algorithm; for example, the aforementioned k and . The output parameter x is the least squares solution, is the squared 2-norm of the residual and is set to 0 if the LHDM algorithm has reached the maximum number of iterations without converging and 1 otherwise.
In the literature, an accelerating technique was introduced by Van Benthem and Keenan [
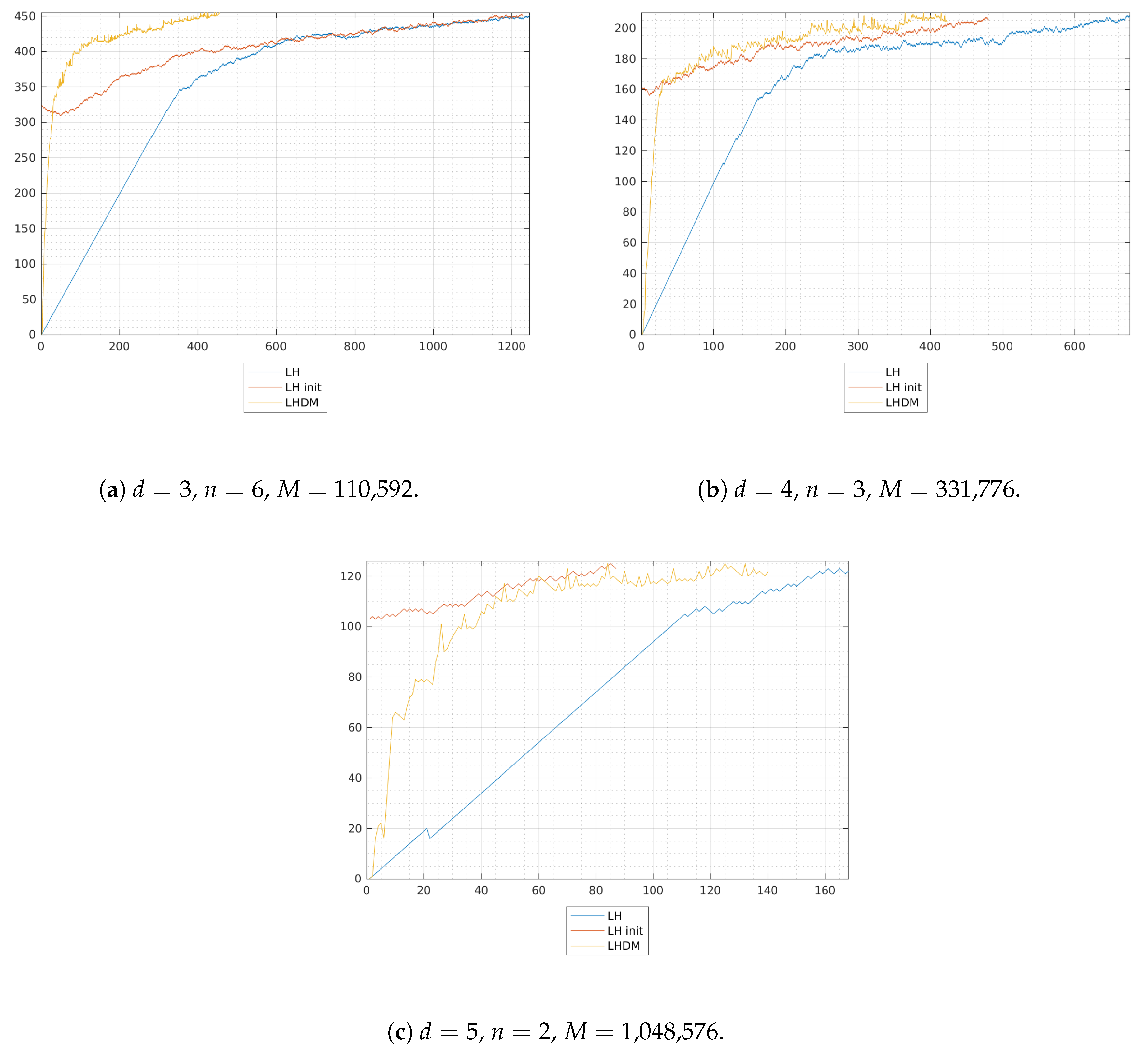
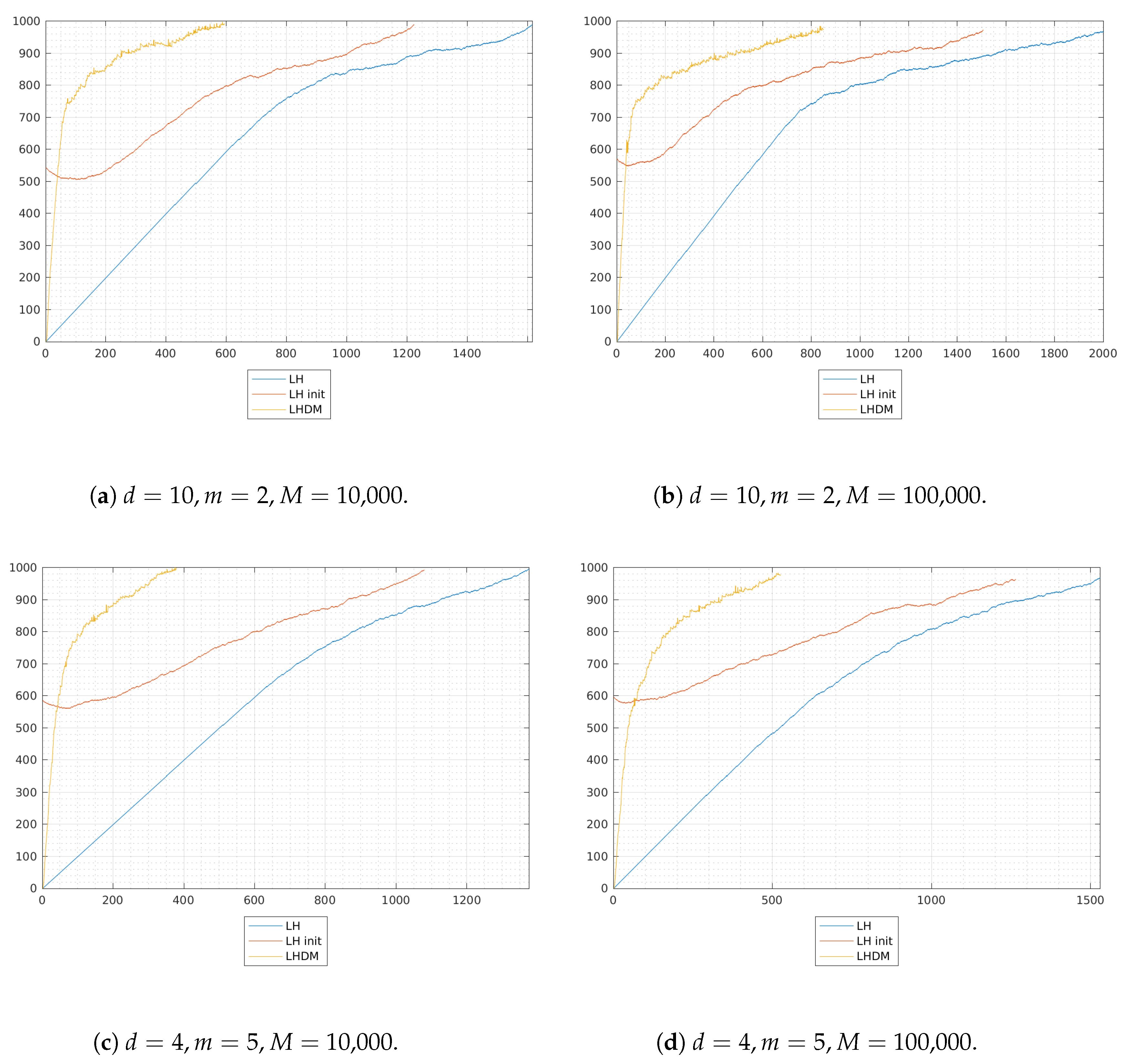
25], who presented a different NNLS solution algorithm, namely “fast combinatorial NNLS”, designed for the specific case of a large number of right-hand sides. The authors exploited a clever reorganization of computations in order to take advantage of the combinatorial nature of the problems treated (multivariate curve resolution) and introduced a nontrivial initialization of the algorithm by means of unconstrained least squares solution. In the following section we are going to compare such an approach, briefly named LHI, and the standard LH algorithm with the LHDM procedure just summarized.
5. Conclusions
In this paper, we have presented
dCATCH [
1], a numerical software package for the computation of a
d-variate near G-optimal polynomial regression design of degree
m on a finite design space
. The mathematical foundation is discussed connecting statistical design theoretic and approximation theoretic aspects, with a special emphasis on deterministic regression (Weighted Least Squares). The package takes advantage of an accelerated version of the classical NNLS Lawson-Hanson solver developed by the authors and applied to design compression.
As a few examples of use cases of this package we have shown the results on a complex shape (multibubble) in three dimensions, and on hypercubes discretized with Chebyshev grids and with Halton points, testing different combinations of dimensions and degrees which generate large-scale problems for a personal computer.
The present package, dCATCH works for any discrete measure on a discrete set X. Indeed, it could be used, other than for design compression, also in the compression of d-variate quadrature formulas, even on lower-dimensional manifolds, to give an example.
We may observe that with this approach we can compute a
d-variate compressed design starting from a high-cardinality sampling set
X, that discretizes a continuous compact set (see
Section 4.2 and
Section 4.3). This design allows an
m-th degree near optimal polynomial regression of a function on the whole
X, by sampling on a small design support. We stress that the compressed design is function-independent and thus can be constructed “once and for all” in a pre-processing stage. This approach is potentially useful, for example, for the solution of
d-variate parameter estimation problems, where we may think to model a nonlinear cost function by near optimal polynomial regression on a discrete
d-variate parameter space
X; cf., for example, References [
32,
33] for instances of parameter estimation problems from mechatronics applications (
Digital Twins of controlled systems) and references on the subject. Minimization of the polynomial model could then be accomplished by popular methods developed in the growing research field of Polynomial Optimization, such as Lasserre’s SOS (Sum of Squares) and measure-based hierarchies, and other recent methods; cf., for example, References [
34,
35,
36] with the references therein.
From a computational viewpoint, the results shown in
Table 3,
Table 4 and
Table 5 show relevant speed-ups in the compression stage, with respect to the standard Lawson-Hanson algorithm, in terms of the number of iterations required and of computing time within the Matlab scripting language. In order to further decrease the execution times and to allow us to tackle larger design problems, we would like in the near future to enrich the package
dCATCH with an efficient C implementation of its algorithms and, possibly, a CUDA acceleration on GPUs.






{kind=link}
{kind=link}
{kind=link}