A Highly Efficient Neural Network Solution for Automated Detection of Pointer Meters with Different Analog Scales Operating in Different Conditions


Abstract
1. Introduction
2. Materials and Methods
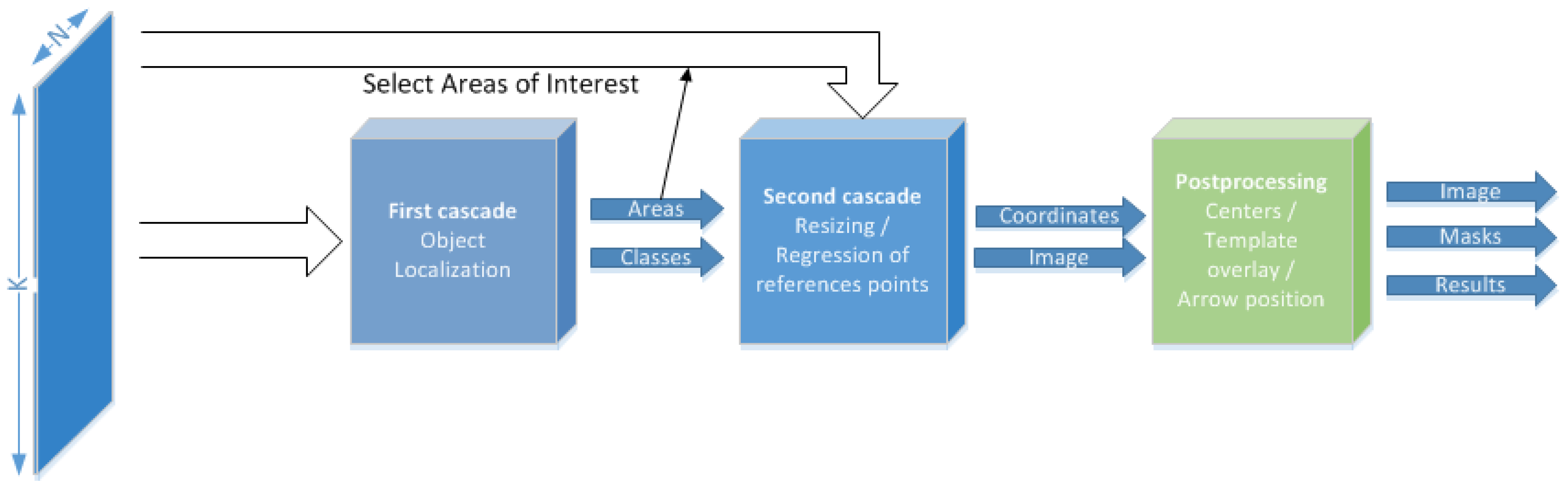
2.1. AMR Detector
2.1.1. Localization of the Objects
2.1.2. Resizing Cropped Images
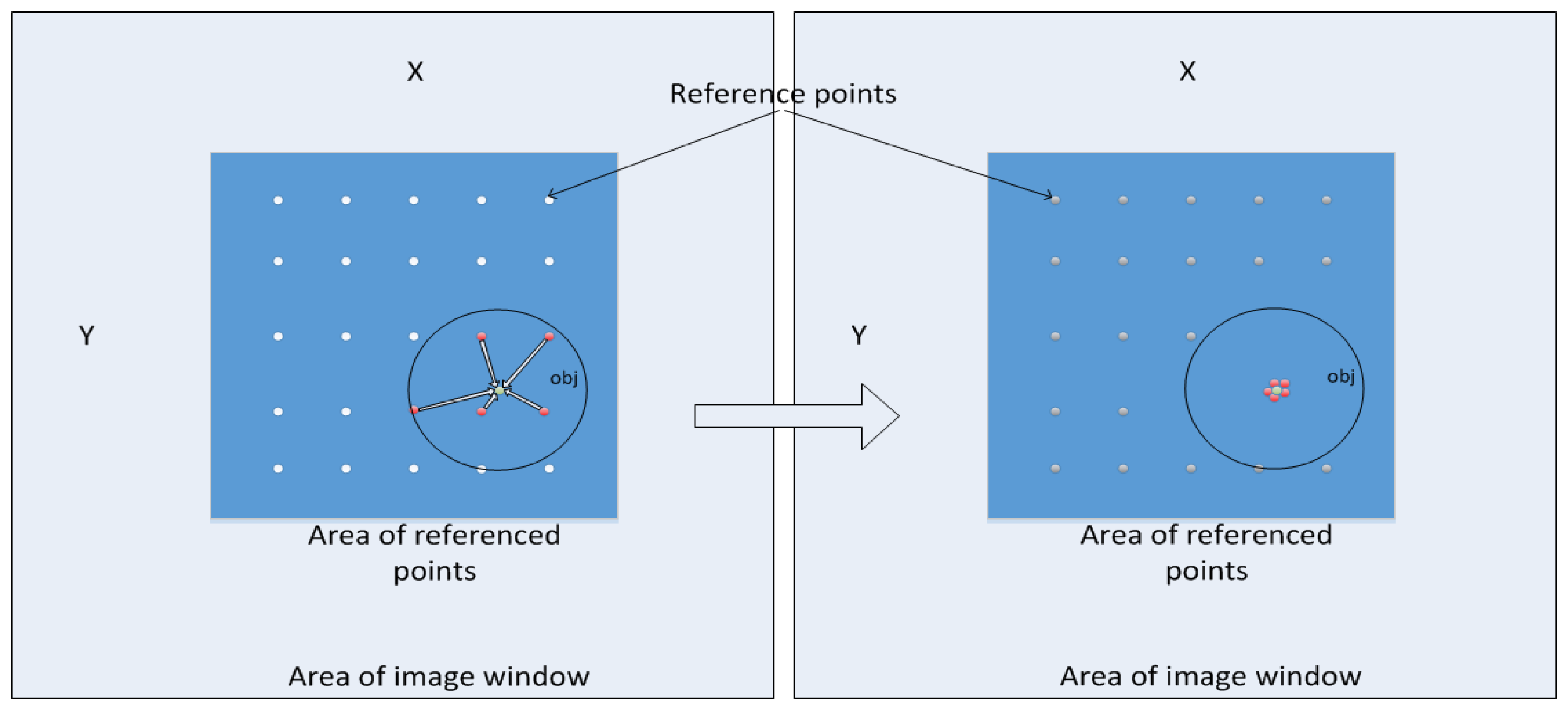
2.1.3. Regression of the Grid of Reference Points
2.1.4. Characteristics of the Network
2.2. Preparation of Training Data
2.2.1. Labeling and Preparation of the Dataset
2.2.2. Localization of the Centers of the Devices
2.2.3. Enumeration of the Symbols
2.3. Experiments
2.3.1. Type of Device Detection
2.3.2. Symbols’ Coordinates Detection
3. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, Y.; Ji, Q. Facial Landmark Detection: A Literature Survey. arXiv 2018, arXiv:1805.05563. [Google Scholar] [CrossRef]
- Kukharev, G.; Kamenskaya, E.; Matveev, Y.; Shchegoleva, N. Metody Obrabotki i Raspoznavanija Izobrazhenij lic v Zadachah Biometrii; Khitrov, M., Ed.; SPb.: Politechnika, Poland, 2013; pp. 88–132. [Google Scholar]
- Salomon, G.; Laroca, R.; Menotti, D. Deep Learning for Image-based Automatic Dial Meter Reading: Dataset and Baselines. arXiv 2020, arXiv:2005.03106. [Google Scholar]
- Ocampo, R.; Sanchez-Ante, G.; Falcon, L.; Sossa, H. Automatic Reading of Electro-mechanical Utility Meters. In Proceedings of the 2013 12th Mexican International Conference on Artificial Intelligence, Mexico City, Mexico, 24–30 November 2013; pp. 164–170. [Google Scholar] [CrossRef]
- Bao, H.; Tan, Q.; Liu, S.; Miao, J. Computer Vision Measurement of Pointer Meter Readings Based on Inverse Perspective Mapping. Appl. Sci. 2019, 9, 3729. [Google Scholar] [CrossRef]
- Tian, E.; Zhang, H.; Hanafiah, M. A pointer location algorithm for computer visionbased automatic reading recognition of pointer gauges. Open Phys. 2019, 17, 86–92. [Google Scholar] [CrossRef]
- Gao, J.W.; Xie, H.T.; Zuo, L.; Zhang, C.H. A robust pointer meter reading recognition method for substation inspection robot. In Proceedings of the 2017 International Conference on Robotics and Automation Sciences (ICRAS), Hong Kong, China, 26–29 August 2017; pp. 43–47. [Google Scholar]
- Xing, H.; Du, Z.; Su, B. Detection and recognition method for pointer-type meter in transformer substation. Yi Qi Yi Biao Xue Bao/Chin. J. Sci. Instrum. 2017, 38, 2813–2821. [Google Scholar]
- Fang, Y.; Dai, Y.; He, G.; Qi, D. A Mask RCNN based Automatic Reading Method for Pointer Meter. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8466–8471. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zuo, L.; He, P.; Zhang, C.; Zhang, Z. A Robust Approach to Reading Recognition of Pointer Meters Based on Improved Mask-RCNN. Neurocomputing 2020, 388, 90–101. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, S.; Terrail, J.O.D.; Jurie, F. Recent Advances in Object Detection in the Age of Deep Convolutional Neural Networks. arXiv 2018, arXiv:1809.03193. [Google Scholar]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. arXiv 2018, arXiv:1807.05511. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Wong, A.; Shafiee, M.J.; Li, F.; Chwyl, B. Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection. arXiv 2018, arXiv:1802.06488. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June 2016–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Veit, A.; Wilber, M.J.; Belongie, S.J. Residual Networks are Exponential Ensembles of Relatively Shallow Networks. arXiv 2016, arXiv:1605.06431. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 30 May 2020).
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Pang, Y.; Sun, M.; Jiang, X.; Li, X. Convolution in Convolution for Network in Network. arXiv 2016, arXiv:1603.06759. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.; Chen, Y. Batch-normalized Maxout Network in Network. arXiv 2015, arXiv:1511.02583. [Google Scholar]
- Alexeev, A.; Matveev, Y.; Kukharev, G. Using a Fully Connected Convolutional Network to Detect Objects in Images. In Proceedings of the 2018 Fifth International Conference on Social Networks Analysis, Management and Security (SNAMS), Valencia, Spain, 15–18 October 2018; pp. 141–146. [Google Scholar] [CrossRef]
- Alexeev, A.; Matveev, Y.; Matveev, A.; Pavlenko, D. Residual learning for FC kernels of convolutional network. In Artificial Neural Networks and Machine Learning—ICANN 2019: Deep Learning. ICANN 2019; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2019; Volume 11728, pp. 361–372. [Google Scholar] [CrossRef]
- Alexeev, A.; Matveev, Y.; Matveev, A.; Kukharev, G.; Almatarneh, S. Detector of Small Objects with Application to the License Plate Symbols. In Advances in Computational Intelligence. IWANN 2019; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2019; Volume 11506, pp. 533–544. [Google Scholar] [CrossRef]
- Cheng, Y. Mean Shift, Mode Seeking, and Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fitzgibbon, A.; Pilu, M.; Fisher, R. Direct Least-squares fitting of ellipses. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; Volume 21, pp. 253–257. [Google Scholar] [CrossRef]








{kind=link}
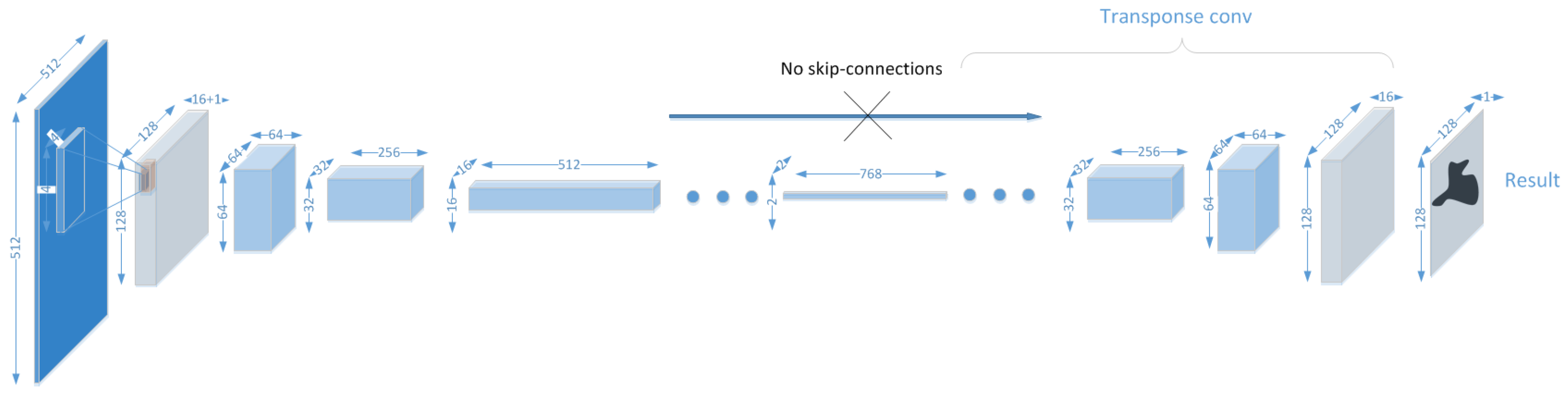{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Window/Step/Output | Kernel | Number of Parameters |
|---|---|---|---|
| Conv1 | / / | 125 | |
| Conv2 | / / | 729 | |
| Conv3 | / / | 4913 | |
| Conv4 | / / | 36 K | |
| Conv5 | / / | 275 K | |
| Conv6 | / / | 2.1 M | |
| Conv7 | / / | 17 M | |
| Conv8 | / / | 135 M | |
| Conv9 | / / | 406 M | |
| Total | − | − | 560 M |
| Layer Type | Window / Step / Output | Kernel | Number of Parameters |
|---|---|---|---|
| Conv1 | / / | 125 | |
| Conv2 | / / | 4913 | |
| Conv3 | / / | 275 K | |
| Conv4 | / / | 17 M | |
| Conv5 | / / | 17 M | |
| Conv6 | / / | 17 M | |
| Conv7 | / / | 17 M | |
| Conv8 | / / | 1.2 M | |
| Total | − | − | 70 M |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexeev, A.; Kukharev, G.; Matveev, Y.; Matveev, A. A Highly Efficient Neural Network Solution for Automated Detection of Pointer Meters with Different Analog Scales Operating in Different Conditions. Mathematics 2020, 8, 1104. https://doi.org/10.3390/math8071104
Alexeev A, Kukharev G, Matveev Y, Matveev A. A Highly Efficient Neural Network Solution for Automated Detection of Pointer Meters with Different Analog Scales Operating in Different Conditions. Mathematics. 2020; 8(7):1104. https://doi.org/10.3390/math8071104
Chicago/Turabian StyleAlexeev, Alexey, Georgy Kukharev, Yuri Matveev, and Anton Matveev. 2020. "A Highly Efficient Neural Network Solution for Automated Detection of Pointer Meters with Different Analog Scales Operating in Different Conditions" Mathematics 8, no. 7: 1104. https://doi.org/10.3390/math8071104
APA StyleAlexeev, A., Kukharev, G., Matveev, Y., & Matveev, A. (2020). A Highly Efficient Neural Network Solution for Automated Detection of Pointer Meters with Different Analog Scales Operating in Different Conditions. Mathematics, 8(7), 1104. https://doi.org/10.3390/math8071104