Birnbaum-Saunders Quantile Regression Models with Application to Spatial Data



Abstract
1. Introduction
2. Quantile Regression
3. The Univariate Birnbaum-Saunders Distribution
- (i)
- .
- (ii)
- .
- (iii)
- , for .
- (iv)
- .
- (v)
- , with and .
4. The Multivariate BS Distribution and a New Parametrization
- (i)
- , for .
- (ii)
- , where , and is a matrix with ones in its diagonal and its other elements equal to element of the matrix Σ.
- (iii)
- where , with following a bivariate normal distribution and correlation matrix ; see [34].
- (iv)
- The variance-covariance matrix of is , where , and have elements , and , respectively, for , and ⊙ is the Hadamard product. If are independent random variables, then , where , that is, is a diagonal matrix with elements .
- (i)
- with being defined in Theorem 1(iii).
- (ii)
- (iii)
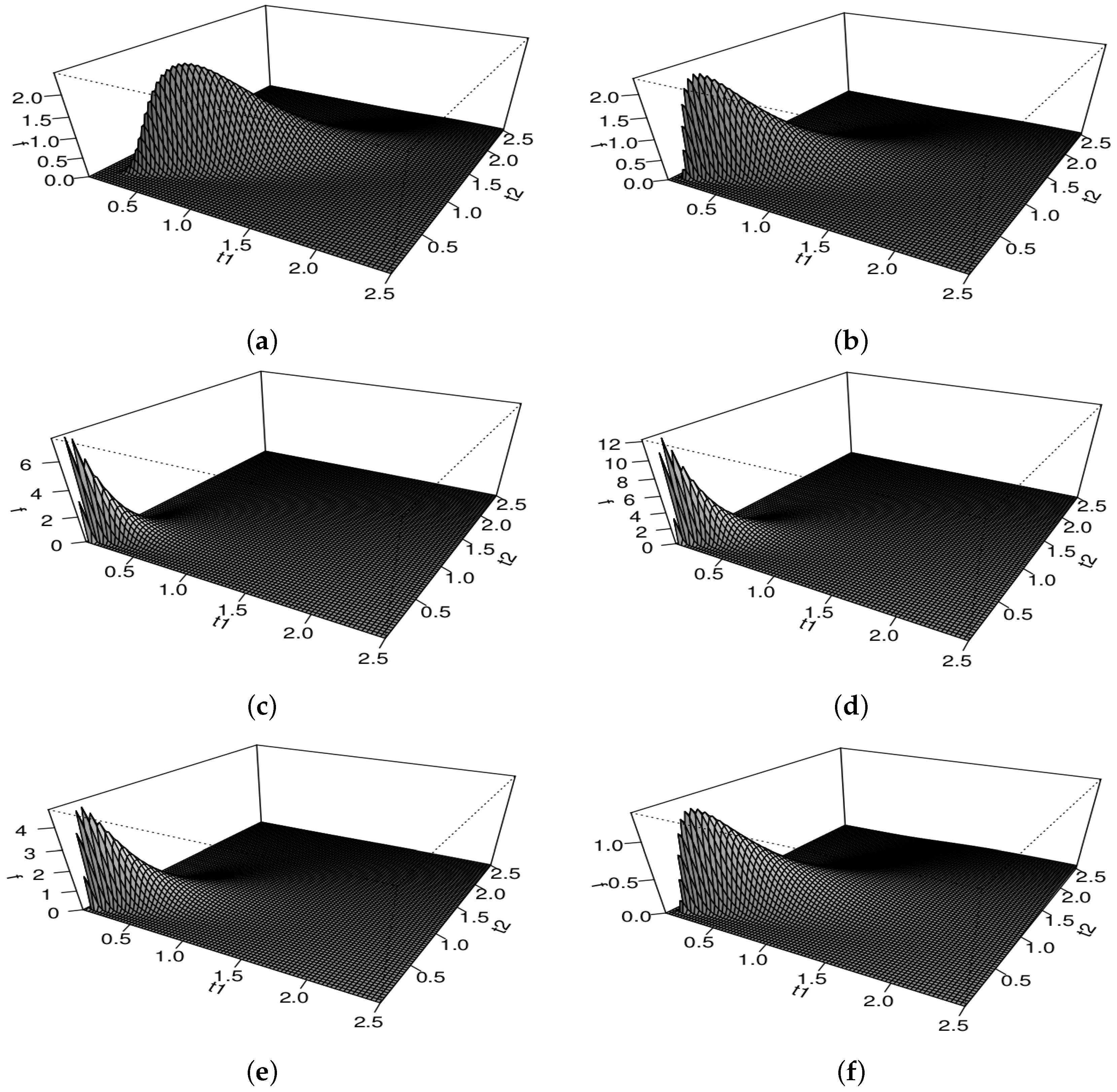
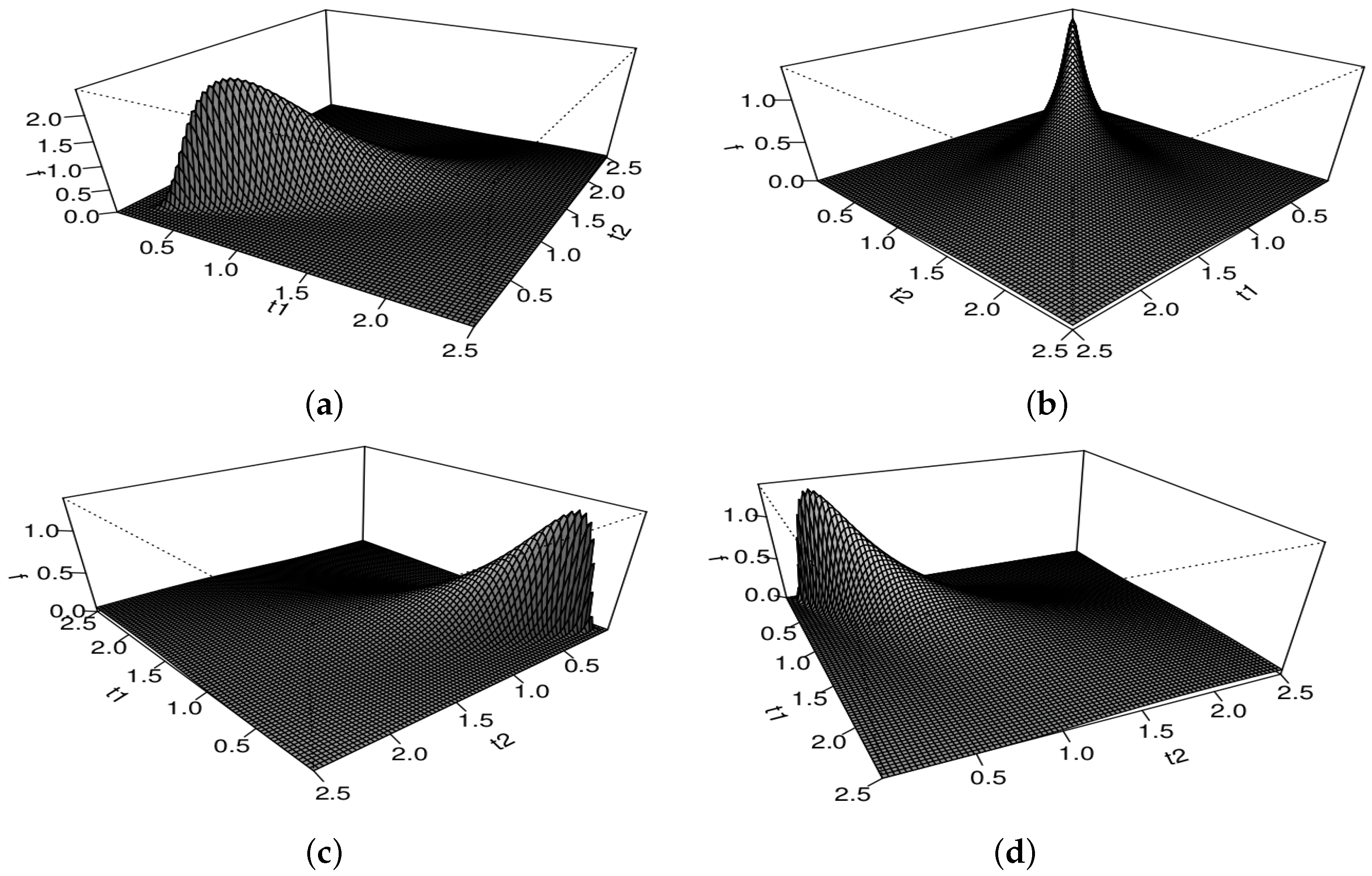
5. Formulation of the Spatial Model
6. Estimation of Model Parameters
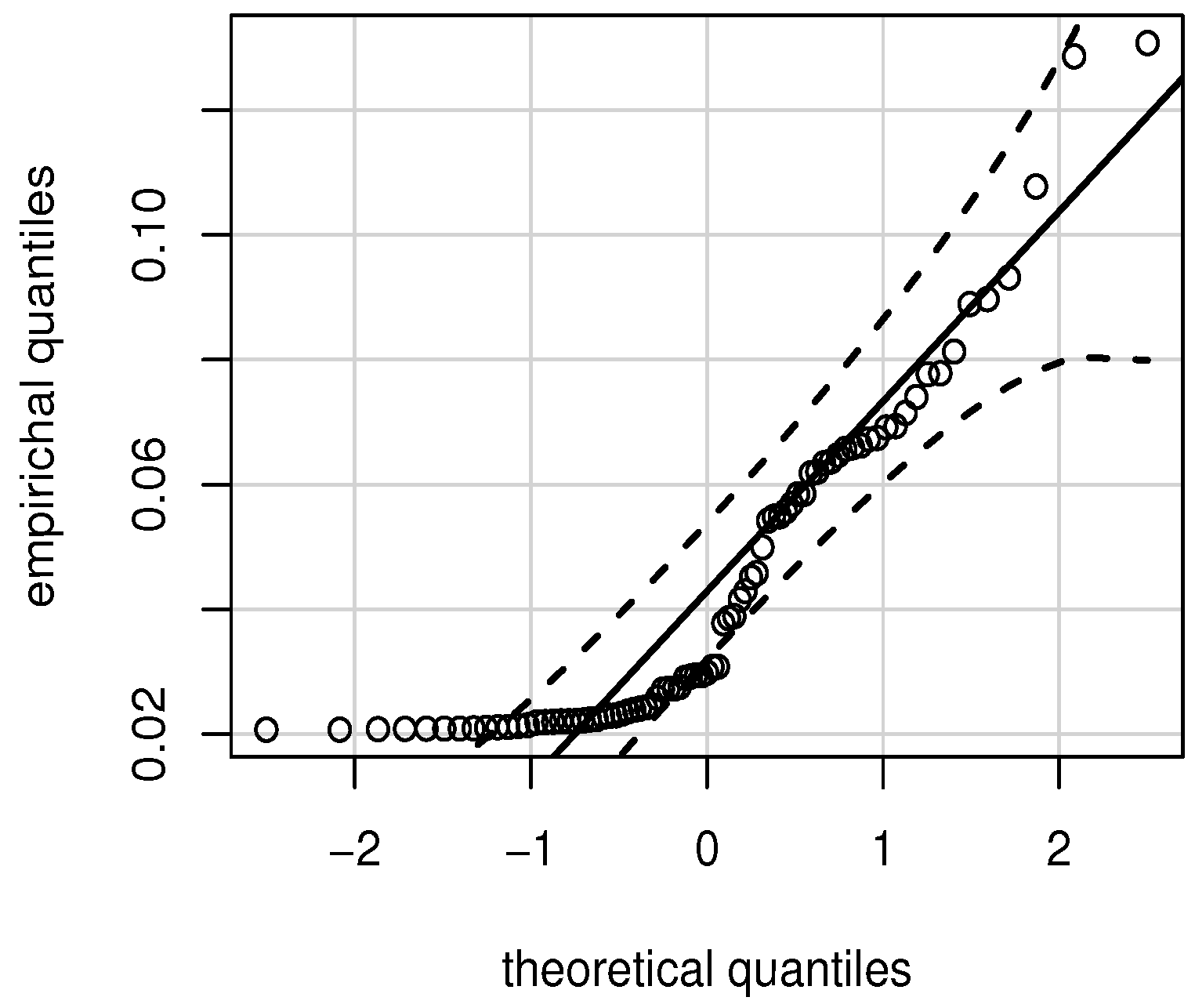
7. Model Checking
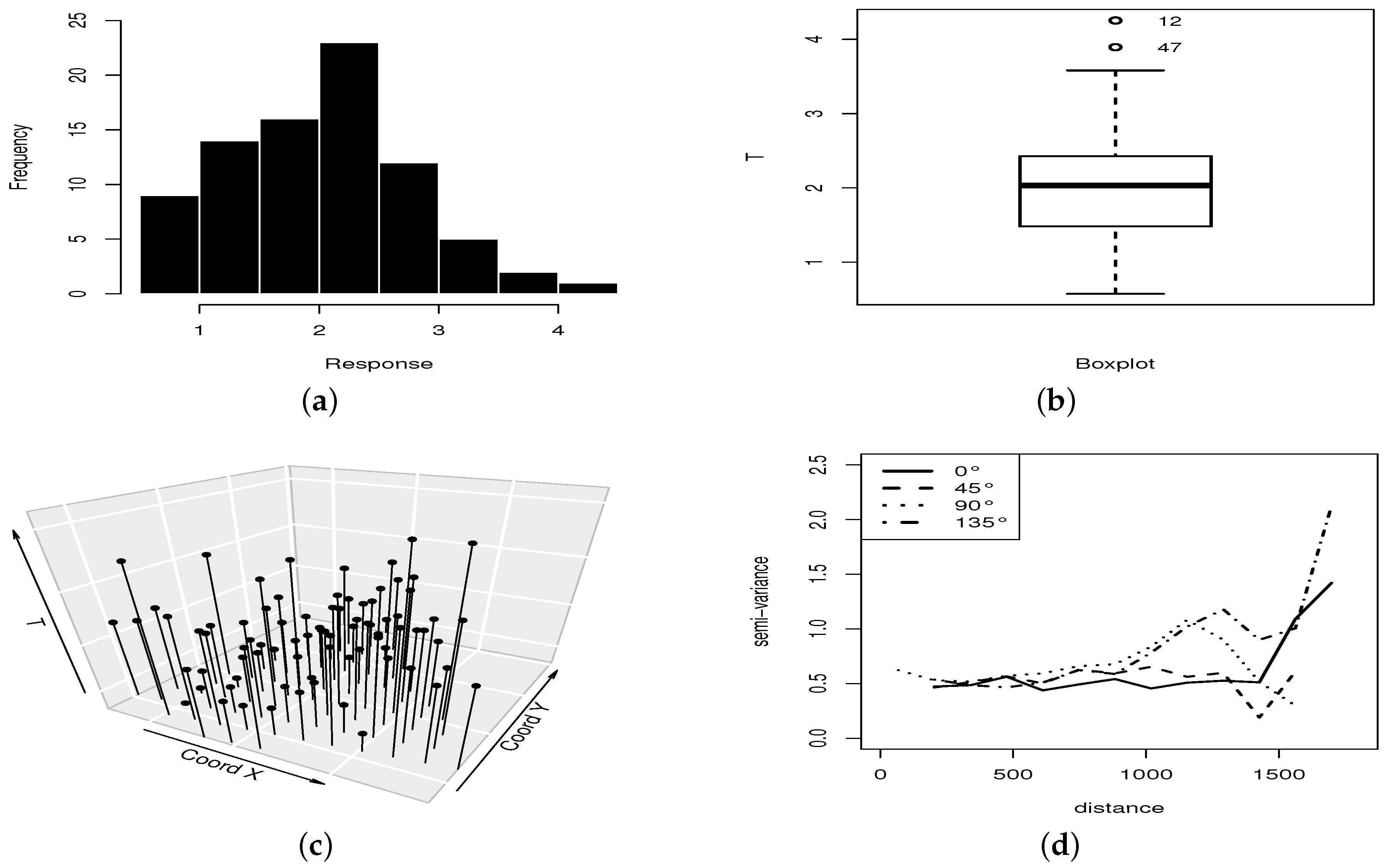
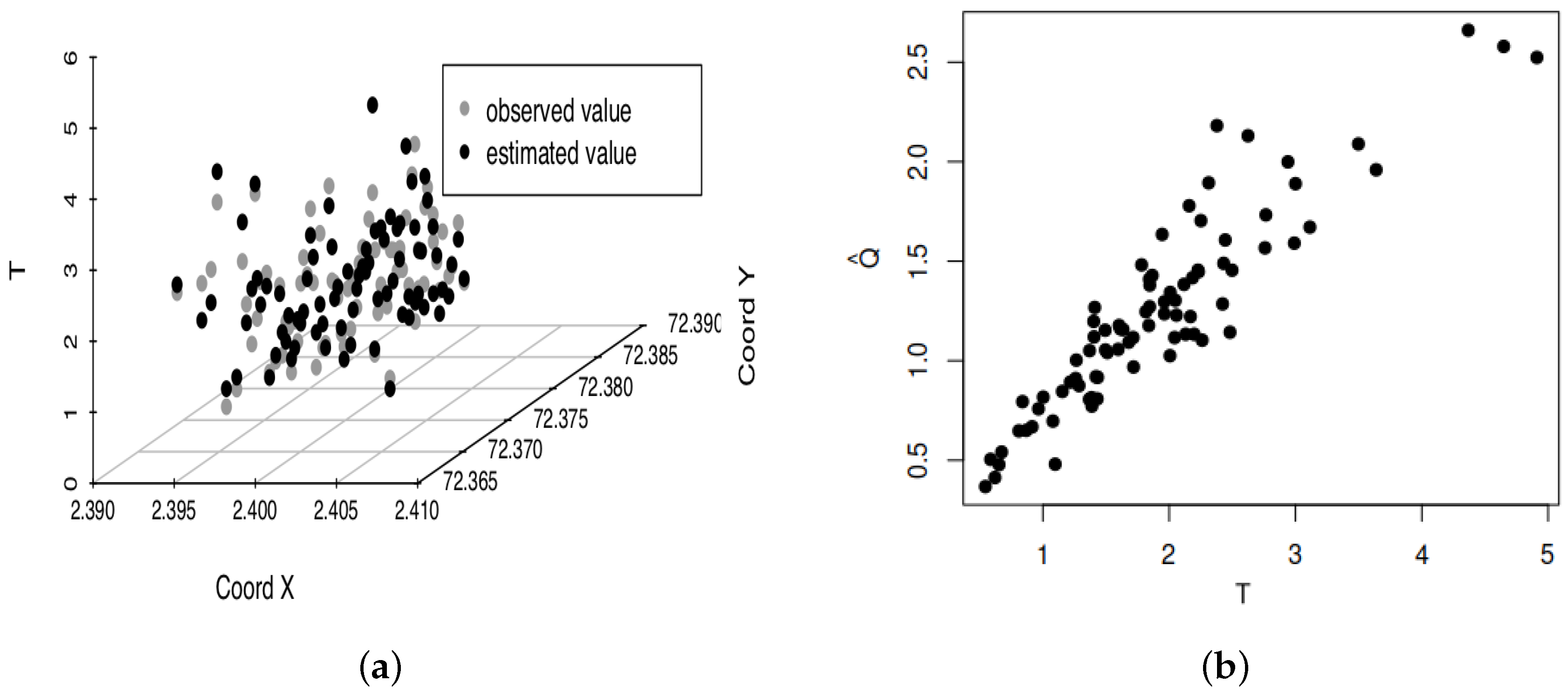
8. Empirical Illustrative Example
9. Conclusions and Future Works
- (i)
- A new parameterization of the multivariate Birnbaum-Saunders distribution has been established.
- (ii)
- A novel Birnbaum–Saunders spatial quantile regression model has been proposed and derived.
- (iii)
- We have developed maximum likelihood estimation for the parameters of the proposed model.
- (iv)
- A randomized quantile residual has been used for model checking. We have utilized the Wilson–Hilferty approximation for our spatial model residuals to evaluate adequacy model.
- (v)
- The obtained results have been applied to a real data set illustrating its potential usages.
- (i)
- A global test for independence might be stated based on (or , the identity matrix). Specifically, let be the likelihood function for the full model and be the likelihood function for the reduced model (under indicating independence). Subsequently, we can use the likelihood ratio statistic to test . Thus, instead of using the asymptotic distribution of , which is unknown, a bootstrap test can be employed.
- (ii)
- In addition, we can consider versus . In this case, the asymptotic distribution of under is an equally weighted mixture of chi-square distributions with zero and one degree of freedom, whose critical value is 2.7055 at a significance level of 5% [47]. In the spatial case, such a distribution might also be unknown, so that the bootstrap technique can be employed.
- (iii)
- it is of interest to study details of the asymptotic behavior and performance of maximum likelihood estimators [48]. However, applicability of asymptotic frameworks to spatial data is not an easy aspect. This is due to there being at least two relevant frameworks, which can behave quite differently when estimating the spatial dependence parameters; see details about these asymptotic frameworks and their implications in [49].
- (iv)
- The Birnbaum–Saunders distribution is based on the normal distribution and then parameter estimation in spatial quantile regression models can be affected by atypical cases. Thus, robust estimation to these cases, for example based on the Birnbaum–Saunders-t distribution, can be considered to decrease their effects; see [50].
- (v)
- Besides fixed effects that are added to the modeling by regression, random effects can also be added by mixed models, which may produce a more sophisticated Birnbaum-Saunders spatial quantile regression model and closer to reality [51].
- (vi)
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Score Vector and Fisher Information Matrix
Appendix A.1. Score Vector
Appendix A.2. Information Matrix
References
- Arrue, J.; Arellano-Valle, R.B.; Gomez, H.W.; Leiva, V. On a new type of Birnbaum-Saunders models and its inference and application to fatigue data. J. Appl. Stat. 2020. [Google Scholar] [CrossRef]
- Khan, M.Z.; Khan, M.F.; Aslam, M.; Mughal, A.R. Design of fuzzy sampling plan using the Birnbaum-Saunders distribution. Mathematics 2019, 7, 9. [Google Scholar] [CrossRef]
- Leiva, V.; Saunders, S.C. Cumulative damage models. In Wiley StatsRef: Statistics Reference Online; Wiley: Hoboken, NJ, USA, 2015; pp. 1–10. [Google Scholar]
- Marchant, C.; Leiva, V.; Cysneiros, F.J.A.; Liu, S. Robust multivariate control charts based on Birnbaum-Saunders distributions. J. Stat. Comput. Simul. 2018, 88, 182–202. [Google Scholar] [CrossRef]
- Cavieres, M.F.; Leiva, V.; Marchant, C.; Rojas, F. A methodology for data-driven decision making in the monitoring of particulate matter environmental contamination in Santiago of Chile. Rev. Environ. Contam. Toxicol. 2020. [Google Scholar] [CrossRef]
- Leiva, V.; Santos-Neto, M.; Cysneiros, F.J.A.; Barros, M. A methodology for stochastic inventory models based on a zero-adjusted Birnbaum-Saunders distribution. Appl. Stoch. Model. Bus. Ind. 2016, 32, 74–89. [Google Scholar] [CrossRef]
- Carrasco, J.M.F.; Figueroa-Zuniga, J.I.; Leiva, V.; Riquelme, M.; Aykroyd, R.G. An errors-in-variables model based on the Birnbaum-Saunders and its diagnostics with an application to earthquake data. Stoch. Environ. Res. Risk Assess. 2020, 34, 1–12. [Google Scholar] [CrossRef]
- Martinez, S.; Giraldo, R.; Leiva, V. Birnbaum-Saunders functional regression models for spatial data. Stoch. Environ. Res. Risk Assess. 2019, 33, 1765–1780. [Google Scholar] [CrossRef]
- Huerta, M.; Leiva, V.; Liu, S.; Rodriguez, M.; Villegas, D. On a partial least squares regression model for asymmetric data with a chemical application in mining. Chemom. Intell. Lab. Syst. 2019, 190, 55–68. [Google Scholar] [CrossRef]
- Leiva, V.; Aykroyd, R.G.; Marchant, C. Discussion of “Birnbaum-Saunders distribution: A review of models, analysis, and applications” and a novel multivariate data analytics for an economics example in the textile industry. Appl. Stoch. Model. Bus. Ind. 2019, 35, 112–117. [Google Scholar] [CrossRef]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. Incorporation of frailties into a cure rate regression model and its diagnostics and application to melanoma data. Stat. Med. 2018, 37, 4421–4440. [Google Scholar] [CrossRef]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. A survival model with Birnbaum-Saunders frailty for uncensored and censored cancer data. Braz. J. Probab. Stat. 2018, 32, 707–729. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Appl. Stoch. Models Bus. Ind. 2020. [Google Scholar] [CrossRef]
- Ventura, M.; Saulo, H.; Leiva, V.; Monsueto, S. Log-symmetric regression models: Information criteria, application to movie business and industry data with economic implications. Appl. Stoch. Model. Bus. Ind. 2019, 34, 963–977. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Laplace, P. Th’eorie Analytique des Probabilit’es; Editions Jacques Gabayr: Paris, France, 1818. [Google Scholar]
- Dasilva, A.; Dias, R.; Leiva, V.; Marchant, C.; Saulo, H. Birnbaum-Saunders regression models: A comparative evaluation of three approaches. J. Stat. Comput. Simul. 2020, in press. [Google Scholar]
- Saulo, H.; Leao, J.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders autoregressive conditional duration models applied to high-frequency financial data. Stat. Pap. 2019, 60, 1605–1629. [Google Scholar] [CrossRef]
- Diggle, P.; Ribeiro, P. Model-Based Geoestatistics; Springer: New York, NY, USA, 2007. [Google Scholar]
- Kostov, P. A spatial quantile regression hedonic model of agricultural land prices. Spat. Econ. Anal. 2009, 4, 53–72. [Google Scholar] [CrossRef]
- Trzpiot, G. Spatial quantile regression. Comp. Econ. Res. 2013, 15, 265–279. [Google Scholar] [CrossRef]
- McMillen, D. Quantile Regression for Spatial Data; Springer: New York, NY, USA, 2013. [Google Scholar]
- Garcia-Papani, F.; Uribe-Opazo, M.A.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders spatial modelling and diagnostics applied to agricultural engineering data. Stoch. Environ. Res. Risk Assess. 2017, 31, 105–124. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Ruggeri, F.; Uribe-Opazo, M.A. Kriging with external drift in a Birnbaum-Saunders geostatistical model. Stoch. Environ. Res. Risk Assess. 2018, 32, 1517–1530. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Uribe-Opazo, M.A.; Aykroyd, R.G. Birnbaum-Saunders spatial regression models: Diagnostics and application to chemical data. Chemom. Intell. Lab. Syst. 2018, 177, 114–128. [Google Scholar] [CrossRef]
- Liu, Y.; Mao, G.; Leiva, V.; Liu, S.; Tapia, A. Diagnostic analytics for an autoregressive model under the skew-normal distribution. Mathematics 2020, 8, 693. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Caro-Lopera, F.J.; Cysneiros, F.J.A. On matrix-variate Birnbaum-Saunders distributions and their estimation and application. Braz. J. Probab. Stat. 2015, 29, 790–812. [Google Scholar] [CrossRef]
- Kundu, D. Bivariate sinh-normal distribution and a related model. Braz. J. Probab. Stat. 2015, 20, 590–607. [Google Scholar] [CrossRef]
- Kundu, D.; Balakrishnan, N.; Jamalizadeh, A. Generalized multivariate Birnbaum-Saunders distributions and related inferential issues. J. Multivar. Anal. 2013, 116, 230–244. [Google Scholar] [CrossRef]
- Dobson, A. An Introduction to Statistical Modelling; Chapman and Hall: New York, NY, USA, 2002. [Google Scholar]
- Leiva, V.; Santos-Neto, M.; Cysneiros, F.J.A.; Barros, M. Birnbaum-Saunders statistical modelling: A new approach. Stat. Model. 2014, 14, 21–48. [Google Scholar] [CrossRef]
- Santos-Neto, M.; Cysneiros, F.J.A.; Leiva, V.; Barros, M. Reparameterized Birnbaum-Saunders regression models with varying precision. Electron. J. Stat. 2016, 10, 2825–2855. [Google Scholar] [CrossRef]
- Diaz-Garcia, J.A.; Leiva, V.; Galea, M. Singular elliptic distribution: Density and applications. Commun. Stat. Theory Methods 2002, 31, 665–681. [Google Scholar] [CrossRef]
- Kundu, D.; Balakrishnan, N.; Jamalizadeh, A. Bivariate Birnbaum-Saunders distribution and associated inference. J. Multivar. Anal. 2010, 101, 113–125. [Google Scholar] [CrossRef]
- Saulo, H.; Leao, J.; Vila, R.; Leiva, V.; Tomazella, V. On mean-based bivariate Birnbaum-Saunders distributions: Properties, inference and application. Commun. Stat. Theory Methods 2020. [Google Scholar] [CrossRef]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging; Springer: New York, NY, USA, 1999. [Google Scholar]
- Mardia, K.; Marshall, R. Maximum likelihood estimation of models for residual covariance in spatial regression. Biometrika 1984, 71, 135–146. [Google Scholar] [CrossRef]
- Gradshteyn, I.; Ryzhik, I. Tables of Integrals, Series and Products; Academic Press: New York, NY, USA, 2000. [Google Scholar]
- Zhang, H.; Wang, Y. Kriging and cross-validation for massive spatial data. Environmetrics 2010, 21, 290–304. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Lange, K. Numerical Analysis for Statisticians; Springer: New York, NY, USA, 2001. [Google Scholar]
- R-Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Marchant, C.; Leiva, V.; Cysneiros, F.J.A.; Vivanco, J.F. Diagnostics in multivariate generalized Birnbaum-Saunders regression models. J. Appl. Stat. 2016, 43, 2829–2849. [Google Scholar] [CrossRef]
- Dunn, P.; Smyth, G. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Ferreira, M.; Gomes, M.I.; Leiva, V. On an extreme value version of the Birnbaum-Saunders distribution. REVSTAT 2012, 10, 181–210. [Google Scholar]
- Bhatti, C. The Birnbaum–Saunders autoregressive conditional duration model. Math. Comput. Simul. 2010, 80, 2063–2078. [Google Scholar] [CrossRef]
- Song, P.X.K.; Zhang, P.; Qu, A. Maximum likelihood inference in robust linear mixed-effects models using the multivariate T Distributions. Stat. Sin. 2007, 17, 929–943. [Google Scholar]
- Genton, M.G.; Zhang, H. Identifiability problems in some non-Gaussian spatial random fields. Chil. J. Stat. 2012, 3, 171–179. [Google Scholar]
- Zhang, H.; Zimmerman, D.L. Towards reconciling two asymptotic frameworks in spatial statistics. Biometrika 2005, 92, 921–936. [Google Scholar] [CrossRef]
- Athayde, E.; Azevedo, A.; Barros, M.; Leiva, V. Failure rate of Birnbaum-Saunders distributions: Shape, change-point, estimation and robustness. Braz. J. Probab. Stat. 2019, 33, 301–328. [Google Scholar] [CrossRef]
- Villegas, C.; Paula, G.A.; Leiva, V. Birnbaum-Saunders mixed models for censored reliability data analysis. IEEE Trans. Reliab. 2011, 60, 748–758. [Google Scholar] [CrossRef]
- Santana, L.; Vilca, F.; Leiva, V. Influence analysis in skew-Birnbaum-Saunders regression models and applications. J. Appl. Stat. 2011, 38, 1633–1649. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Shape Parameter | Correlation Function |
|---|---|---|
| Exponential | ||
| Whittle | ||
| Gaussian |
| Model | CAIC | BIC | |
|---|---|---|---|
| Gaussian | −32.1411 | 70.5900 | 77.5024 |
| BS–identity link | −36.3659 | 81.2513 | 90.3587 |
| BS–logarithm link | −36.3659 | 81.2513 | 90.3587 |
| BS–square root link | −24.9112 | 58.3419 | 67.4493 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders Quantile Regression Models with Application to Spatial Data. Mathematics 2020, 8, 1000. https://doi.org/10.3390/math8061000
Sánchez L, Leiva V, Galea M, Saulo H. Birnbaum-Saunders Quantile Regression Models with Application to Spatial Data. Mathematics. 2020; 8(6):1000. https://doi.org/10.3390/math8061000
Chicago/Turabian StyleSánchez, Luis, Víctor Leiva, Manuel Galea, and Helton Saulo. 2020. "Birnbaum-Saunders Quantile Regression Models with Application to Spatial Data" Mathematics 8, no. 6: 1000. https://doi.org/10.3390/math8061000
APA StyleSánchez, L., Leiva, V., Galea, M., & Saulo, H. (2020). Birnbaum-Saunders Quantile Regression Models with Application to Spatial Data. Mathematics, 8(6), 1000. https://doi.org/10.3390/math8061000