Abstract
In the present paper, a novel spatial quantile regression model based on the Birnbaum–Saunders distribution is formulated. This distribution has been widely studied and applied in many fields. To formulate such a spatial model, a parameterization of the multivariate Birnbaum–Saunders distribution, where one of its parameters is associated with the quantile of the respective marginal distribution, is established. The model parameters are estimated by the maximum likelihood method. Finally, a data set is applied for illustrating the formulated model.
1. Introduction
An asymmetric distribution that has recently received considerable attention is the Birnbaum–Saunders (BS) model. It originated from material fatigue and has been applied to reliability and fatigue studies [1,2,3]. Extensive work has been done on the BS distribution with regard to its mathematical and statistical properties, inference, modeling, and diagnostics. Its natural applications have been mainly focused on engineering. However, today they range diverse fields including air pollution [4,5], business [6], earth sciences [7,8], industry [9,10], and medicine [11,12], among other areas. These applications have been performed by an international transdisciplinary group of researchers.
Standard regression models provide an estimate of the mean response given certain values of the covariates. These models cannot be applied to estimate other parameters that are different to the mean, being a limitation of such models. Nevertheless, first, in engineering, environmental, and social sciences, as well as in other areas, often the practitioners are interested in estimating quantiles for establishing warranties of products, determining the levels of nutrients in the soil or measuring economic inequality for poor (lower tail) and rich (upper tail) people by means of their household incomes [13]. Second, the other limitation of the standard regression models is that if the response variable follows a skew distribution, then the mean is not a good central tendency measure to summarize the data and, in this case, the median is a more informative and robust estimate. Additionally, third, regression models can describe parameters of the whole distribution related to variability, skewness, and other higher-order moments, which can characterize a distribution [14]. In order to solve the first two limitations mentioned above, quantile regression models were proposed by [15], extending the median regression model attributed to [16], and generalizing the ordinary sample quantiles to the regression setting. We are interested in modeling the median or other quantiles of the BS distribution by regression; see [17,18].
The accuracy of an estimator of the mean (or median) might be improved if a spatial component is added in the modeling [19]. The idea of spatial quantile regression was initially proposed by [20], and [21] discussed a general spatial quantile regression based on the conditional quantile function, while [22] showed variants of the spatial quantile regression. We provide background of quantile regression including the spatial case in the next section. Ref [23,24,25] introduced BS spatial mean regression models and their diagnostics for the conditional mean; see [26] for details on diagnostic methods. Stochastic processes are applied in the modeling of spatial data to know the corresponding finite dimensional multivariate distributions. BS multivariate distributions have been proposed and studied by [27,28,29]. BS quantile regression models were recently derived by [13] for the independent case, where household income data were considered. However, no studies on BS quantile regression for data with spatial dependence have been proposed.
The main objective of this work is to formulate a novel class of spatial quantile regression models based on the BS distribution. To accomplish this, we propose a quantile parameterization to generate a new multivariate BS model, whose parameters are estimated by the maximum likelihood method. Subsequently, a data set is applied for illustration.
The remainder paper is organized as follows. In Section 2, quantile regression models for the cases of independent and spatial data are described. Section 3 presents the univariate BS distribution in its original parameterization and a new parameterization of it, which allows us to model a quantile. In Section 4, the multivariate normal distribution and its connection to the new parametrization of the multivariate BS distribution are introduced. In Section 5, we formulate the spatial quantile regression model based on the BS distribution. Section 6 derives estimation of model parameters using the maximum likelihood method, whereas tools for model checking are discussed in Section 7. In Section 8, we carry out an empirical example with spatial data to illustrate potential applications of the novel model. Conclusions and future works are mentioned in Section 9. An Appendix A with derivatives for the score vector and Hessian matrix is provided at the end of this paper.
2. Quantile Regression
Standard regression models have been widely used in different areas and they are defined as
where Y is the dependent (or response) variable; corresponds to the values of the vector of independent variables (covariates) ; is a vector of regression parameters; and is a random error with , (constant variance), and , for (uncorrelated errors). This implies that a regression model describes the conditional mean , so that it can be written by the probability density function (PDF) of Y parameterized in terms of its mean. For example, if Y is normally distributed, then its linear regression model might be visualized as
with being independent random variables. Additionally, we can generalize the expression for given in (1) when considering , where is an invertible function, such as in generalized linear models [30]. If we now consider a k-parameter distribution, with , that is, distributions parameterized on their mean [31,32] in addition to other parameters, one may establish a more general model of the form
where Y now follows some distribution.
Quantile regression models for a response Y offer a mechanism to estimate and predict the median response as well as other quantiles [15]. This class of regression models is based on the quantile function that is given by
where is a parameter vector of the underlying distribution and . If one of the pararameters of the distribution of Y is its quantile function, we can represent a quantile regression model, similarly to (2), as
where h is an invertible function, with positive support and at least twice differentiable, is a fixed value and, as before, are independent random variables.
Let be a stochastic process that is defined over a region . We use the notation to represent the quantile function for Y in the location . If we consider spatial locations , the quantile function of the process can be modeled by regression as , or more generally as , for . Here, is the conditional quantile function of Y given a set of values for the covariates, in the location , where is a fixed value, and h is as given in (3). When , the median is modeled. Often it is assumed that the covariance function of the process only depends on the distance between spatial locations, that is, the stochastic process is stationary.
3. The Univariate Birnbaum-Saunders Distribution
If , then the random variable T given by
has a BS distribution with parameters of shape and scale , which is denoted by . The random variable T has positive support and the transformation given in (4) is one-to-one, which allows us to establish that
The PDF and cumulative distribution function (CDF) of T are expressed, respectively, by
where are the PDF and CDF of the standard normal distribution, whereas
Let . Subsequently, the following properties hold:
- (i)
- .
- (ii)
- .
- (iii)
- , for .
- (iv)
- .
- (v)
- , with and .
These properties are useful for diverse statistical purposes, such as the generation of moments and of random numbers, estimation of parameters, and modeling based on regression. Another property of the BS distribution is presented next. Given , note that the qth quantile of the BS distribution is defined as
where
with being the qth quantile of the standard normal distribution.
4. The Multivariate BS Distribution and a New Parametrization
Let be a random vector with n-variate normal distribution, denoted by , with mean vector and variance-covariance matrix , with . Note that is symmetric, non-singular, positive definite, and then the distribution of is non-singular [33]. When the mean vector is zero, that is, , we use the notation and for the n-variate normal PDF and CDF, respectively, where is an vector of zeros.
The random vector follows an n-variate BS distribution with parameters , , and , if , for , where T is given in (4) and , with being the variance-covariance matrix of with diagonal elements equal to one. Therefore, is also the correlation matrix of in this case. Note that is the correlation matrix of and not of , but we use the notation due to the relationship between the BS and normal distributions. Observe that the CDF and PDF of are defined, respectively, by
where , with , , and both and are as expressed in (5).
Let be a fixed number and . If we apply the transformation given by
where Q is defined in (6), then this transformation is one-to-one. Therefore, if , we have a new parametrization of the multivariate BS distribution, denoted by , acting similarly as in (8) by the transformation expressed as
where the elements of are related by (6) for the marginal distribution of , . Thus, according to (9), the CDF and PDF of are given, respectively, by
where , with , , and being defined in (7). Figure 1 and Figure 2 present different graphical plots for the PDF defined in (10) with , when the parameters and Q vary, for different rotations of these PDFs.
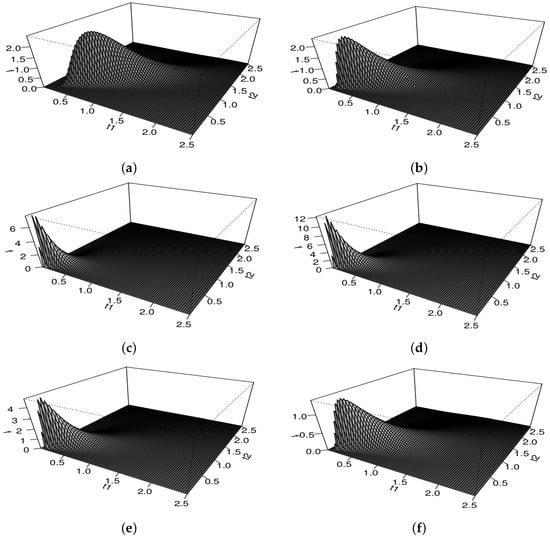
Figure 1.
Plots of the reparametrized bivariate BS PDF for (a), (b), (c) with , and (d), (e), (f) with , for and .
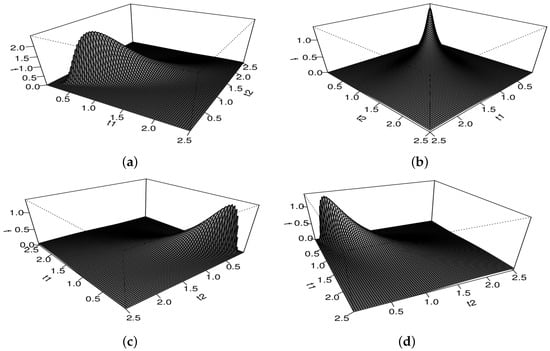
Figure 2.
Plots of the reparametrized bivariate BS PDF for and , for , with , (a–d) are seen from different angles.
Theorem 1.
Let , with , , and being an correlation matrix. Afterwards,
- (i)
- , for .
- (ii)
- , where , and is a matrix with ones in its diagonal and its other elements equal to element of the matrix Σ.
- (iii)
- where , with following a bivariate normal distribution and correlation matrix ; see [34].
- (iv)
- The variance-covariance matrix of is , where , and have elements , and , respectively, for , and ⊙ is the Hadamard product. If are independent random variables, then , where , that is, is a diagonal matrix with elements .
Proof.
The results are deduced using Theorem 3.1 and p. 117 of [34], with our parametrization. ☐
Corollary 1.
Let , with , and . Then,
- (i)
- with being defined in Theorem 1(iii).
- (ii)
- (iii)
Proof.
The results are obtained using ([34] p.117), with our parametrization; see also [35]. ☐
5. Formulation of the Spatial Model
Let be a stochastic process that is defined over a region . We assume that the stochastic process is stationary and isotropic, and that, for given spatial locations , with , the quantile function of the process can be modeled by
where h is an invertible function, with positive support, at least twice differentiable, and represents the values of covariates, with , for , that is, is the value of the covariate at the location . Note that must be satisfied. In addition, is a vector of unknown parameters to be estimated and , with and being an vector of ones. Observe that is related to defined in (9), but now depending on . Here, is the (non-singular) correlation matrix earlier defined. Thus, based on Theorem 1(iv), the variance-covariance matrix of the BS spatial quantile regression model can be written as
where , with for . Notice that the variance-covariance matrix of the BS spatial process that is stated in (12) depends on its quantile function.
Note that the spatial correlation is often modeled by a function of the Matérn family [19]. Subsequently, by using this family and an alternative parameterization suggested by [36], the elements of the matrix involved in (12) are given by
where is a shape parameter; is the usual gamma function; is the Euclidean distance between the locations and , that is, ; is a parameter known as the spatial dependence inverse radius [37] and also related to a parameter named microergodic by [36]; and, is the modified Bessel function of the third kind of order [38]. Some particular cases of the Matérn family are presented in Table 1.

Table 1.
Particular cases of the Matérn correlation function with h denoting a distance measure.
6. Estimation of Model Parameters
Let be a vector of unknown parameters of the spatial quantile regression model formulated in (11), which can be estimated by the maximum likelihood method, as follows. Note that is the spatial dependence inverse radius [39] of the Matérn spatial correlation function defined in (13). Therefore, the corresponding log-likelihood function for based on the vector of observations can be written as
where , with , , and involved in (12). Taking the derivative of (14), with respect to the corresponding parameters, leads to the score vector that is defined as
For details of the score vector given in (15), see the Appendix A. In order to find the maximum likelihood estimate of , the non-linear system must be solved. Because this system does not provide a closed analytical solution, must be computed using an iterative procedure for non-linear systems. Here, a quasi-Newton procedure, named Broyden-Fletcher-Goldfarb-Shanno [40,41], may be used through the functions optim and optimx implemented in the R software; see www.R-project.org and [42]. The signs of the determinants of the corresponding Hessian matrix and of its minors were also checked to ensure that a valid maximum has been attained.
Note that the Hessian matrix for the BS spatial quantile regression model is a diagonal block matrix. This Hessian matrix is obtained by taking the second derivative of (14), with respect to the corresponding parameters, and it is given by
where the elements of the matrix are detailed in the Appendix A. Therefore, for the BS spatial quantile regression model, the expected Fisher information matrix, as obtained from (16), is expressed as
where the elements of the matrix are detailed in the Appendix A as well.
7. Model Checking
We consider a property of the multivariate BS distribution related to the Mahalanobis distance in order to evaluate the fit of the spatial model, which might be used to validate the model in practice. Let
where , with
and being the maximum likelihood estimate of obtained using the data set without the case i. A Newton–Raphson one-step approximation to can be obtained by
where and are the Hessian matrix and score vector of the BS spatial quantile regression model with its parameters estimated by the maximum likelihood method without the case i. Subsequently, under the assumption defined in (17) is an observation of a random variable that follows approximately a distribution with degrees of freedom, for . Thus, by using the Wilson–Hilferty approximation [43], we have that
is an observation of a random variable which follows approximately a standard normal distribution. Hence, a plot of theoretical versus empirical quantiles (QQ) for given in (18) can be used to evaluate the model fit. In addition to the approximation of Wilson–Hilferty, the randomized quantile residual defined by [44] may be employed to evaluate the fit of the BS spatial quantile regression model. In the case of this model, such a residual is given by
where is the inverse N(0, 1) CDF and F is the CDF. Because the randomized quantile residual has approximately a N(0, 1) distribution, a QQ plot of defined in (19) might also be employed for evaluating the model fit.
8. Empirical Illustrative Example
We analyze a chemical data set associated with imbalances and deficiencies of key nutrients in the soil in order to illustrate the results obtained in this paper. This data set corresponds to levels of magnesium (Mg), which affects the development of the root system, and calcium (Ca) that competes with Mg for absorption of nutrients, for locations of an area in Brazil. The response variable (T) is the content of Mg in the soil (in cmolc/dm3) and the covariate (X) is the content of Ca in the soil (in cmolc/dm3).
A descriptive summary of the response variable includes the sample values (in cmolc/dm3) of the median = 2.0306; mean = 2.008; standard deviation = 0.7713; coefficient of variation = 0.3841; coefficient of skewness = 0.3394; coefficient of kurtosis = 2.9717; minimum = 0.5734; and, maximum = 4.2538. Figure 3 shows the histogram (a), boxplot (b), and scatterplot (c) of the values of the response T. In the boxplot, we detect two outliers that correspond to locations #12 and #47. The directional variogram in Figure 3d shows that there is no preferred direction, that is, an omni-directional semi-variogram is appropriate. Thus, the associated stochastic process can be considered as isotropic.
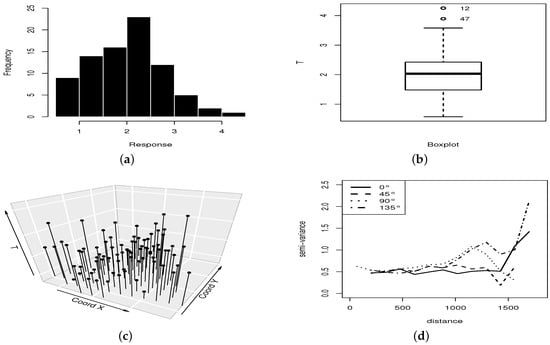
Figure 3.
Histogram (a), boxplot (b), scatterplot (c), and semi-variogram (d) for the response variable with chemical data.
In order to estimate the parameters of BS spatial quantile regression model, we consider the following: (i) the spatial correlation is obtained according to the Matérn function (with ; see Table 1); (ii) the random vector is assumed; (iii) (the quantile to model the median); and, (iii) the identity, logarithm, and square root functions for the link h of the spatial quantile regression defined in (11) are used and expressed as
where is the regression coefficient vector and , with being the value of X for the location i.
We can compare spatial regression models while using the corrected Akaike information criterion (CAIC) and the Schwarz Bayesian information criterion (BIC). The CAIC and BIC are given, respectively, by
where is the log-likelihood function for the parameter associated with the model evaluated at , d is the dimension of the parameter space, and n is the size of the data set. Both criteria are based on the log-likelihood function and penalize the model with more parameters. A model whose information criterion has a smaller value is better [45]. The log-likelihood, CAIC, and BIC values for the model with links defined in (20) are presented in Table 2. Additionally, we fit a Gaussian spatial regression to the data set, which considers the modeling of the mean = median (symmetric case), allowing us to compare the models that are given in (20). Note that the BS model with square root link is better than the Gaussian model. From this table, we conclude that the BS spatial quantile regression with square root link function should be selected.
Table 2.
Values of log-likelihood, CAIC, and BIC for indicated models with chemical data.
The maximum likelihood estimates of the selected model parameters and the corresponding asymptotic standard errors, estimated by using the robust covariance matrix method [46] and reported in parentheses, are:
These standard errors are low, indicating that all of the parameters are estimated with good statistical precision and allow us to infer they must be part of the model. Based on (13), note that the parameter is significant at 5% using the confidence interval-method, which means that exists spatial dependence. Therefore, the estimated BS spatial quantile regression model is given by
where the correlation matrix is determined as , for and evaluated at , whereas the variance-covariance matrix of the BS spatial quantile regression model defined in (12) is estimated as
where corresponds to evaluated at , and is obtained evaluating at and .
Figure 4 provides the QQ plot of the residuals, transformed by the Wilson–Hilferty approximation, after removing a location that was outside the bands. Note that most of the residuals are inside of the bands. Additionally, Figure 5a displays a three-dimensional scatterplot that shows the estimated and observed values of T. These same values are presented in a two-dimensional scatterplot in Figure 5b. These plots allow us to observe a good fit of our model to the data. Therefore, we conclude that the BS spatial quantile regression model is adequate to describe these spatial data, but a better fitting could be obtained if a heavy-tailed asymmetric distribution is considered, such as the BS-Student-t distribution. However, this is beyond of the objective of the present study and it provides a challenge for further research.
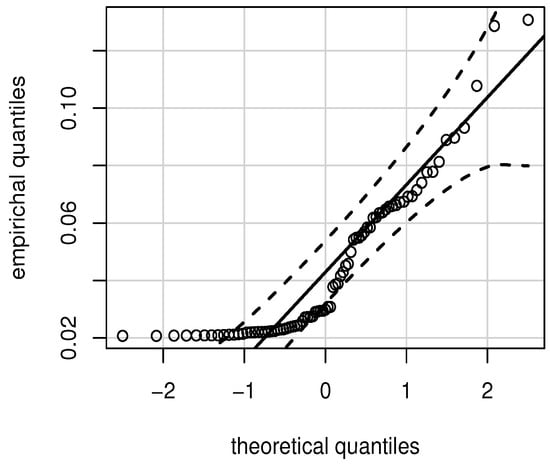
Figure 4.
QQ plots for transformed residuals with chemical data.
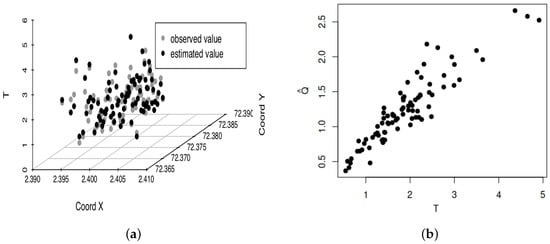
Figure 5.
Three-dimensional (a) and two-dimensional (b) scatterplots estimated versus observed response values with chemical data.
9. Conclusions and Future Works
In this paper, we have obtained the following findings:
- (i)
- A new parameterization of the multivariate Birnbaum-Saunders distribution has been established.
- (ii)
- A novel Birnbaum–Saunders spatial quantile regression model has been proposed and derived.
- (iii)
- We have developed maximum likelihood estimation for the parameters of the proposed model.
- (iv)
- A randomized quantile residual has been used for model checking. We have utilized the Wilson–Hilferty approximation for our spatial model residuals to evaluate adequacy model.
- (v)
- The obtained results have been applied to a real data set illustrating its potential usages.
Therefore, we have derived a novel class of spatial quantile regression, which is useful for modeling data generated from a positive skew distribution. The main feature of this spatial regression is the modeling of a quantile for a response variable that follows the Birnbaum–Saunders distribution. The numerical results have reported the good performance of the spatial quantile regression model, indicating that the Birnbaum–Saunders distribution is a good modeling choice when dealing with data that have spatial dependence, positive support and follow a distribution skewed to the right. Hence, it can be a valuable addition to the tool-kit of applied statisticians and data scientists.
The following aspects are open problems for the Birnbaum–Saunders spatial quantile regression models and they can be considered for future work:
- (i)
- A global test for independence might be stated based on (or , the identity matrix). Specifically, let be the likelihood function for the full model and be the likelihood function for the reduced model (under indicating independence). Subsequently, we can use the likelihood ratio statistic to test . Thus, instead of using the asymptotic distribution of , which is unknown, a bootstrap test can be employed.
- (ii)
- In addition, we can consider versus . In this case, the asymptotic distribution of under is an equally weighted mixture of chi-square distributions with zero and one degree of freedom, whose critical value is 2.7055 at a significance level of 5% [47]. In the spatial case, such a distribution might also be unknown, so that the bootstrap technique can be employed.
- (iii)
- it is of interest to study details of the asymptotic behavior and performance of maximum likelihood estimators [48]. However, applicability of asymptotic frameworks to spatial data is not an easy aspect. This is due to there being at least two relevant frameworks, which can behave quite differently when estimating the spatial dependence parameters; see details about these asymptotic frameworks and their implications in [49].
- (iv)
- The Birnbaum–Saunders distribution is based on the normal distribution and then parameter estimation in spatial quantile regression models can be affected by atypical cases. Thus, robust estimation to these cases, for example based on the Birnbaum–Saunders-t distribution, can be considered to decrease their effects; see [50].
- (v)
- Besides fixed effects that are added to the modeling by regression, random effects can also be added by mixed models, which may produce a more sophisticated Birnbaum-Saunders spatial quantile regression model and closer to reality [51].
- (vi)
- Local influence diagnostics can be conducted for Birnbaum–Saunders spatial quantile regression, which permits the detection of individual or combined influence of cases. Works on local influence in Birnbaum–Saunders models were conducted by a number of authors; see, for example, [18,23,25,52].
Research on these issues is in progress and their findings will be reported in future articles.
Author Contributions
All authors contributed with results and ideas when writing this paper. All authors have read and agreed to the published version of the manuscript.
Funding
The research was partially supported by the project grants “FONDECYT 1200525” from the National Commission for Scientific and Technological Research of the Chilean government (V. Leiva) and “Puente 001/2019” from the Research Directorate of the Vice President for Research of the Pontificia Universidad Católica de Chile, Chile (M. Galea).
Acknowledgments
The authors would also like to thank the Editor and Reviewers for their constructive comments which led to improve the presentation of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Score Vector and Fisher Information Matrix
Appendix A.1. Score Vector
The elements of the score vector given in (15) are detailed as
where and , with
In addition, , with elements defined as
where .
Appendix A.2. Information Matrix
To obtain the Fisher information matrix, must be evaluated at . For the BS spatial quantile regression model presented in (11), the elements of the Hessian matrix can be expressed as
where
and , whose elements are given by
with . In addition, the and vectors and , respectively, have elements given by
where , with
Furthermore, we have
where , with
and
References
- Arrue, J.; Arellano-Valle, R.B.; Gomez, H.W.; Leiva, V. On a new type of Birnbaum-Saunders models and its inference and application to fatigue data. J. Appl. Stat. 2020. [Google Scholar] [CrossRef]
- Khan, M.Z.; Khan, M.F.; Aslam, M.; Mughal, A.R. Design of fuzzy sampling plan using the Birnbaum-Saunders distribution. Mathematics 2019, 7, 9. [Google Scholar] [CrossRef]
- Leiva, V.; Saunders, S.C. Cumulative damage models. In Wiley StatsRef: Statistics Reference Online; Wiley: Hoboken, NJ, USA, 2015; pp. 1–10. [Google Scholar]
- Marchant, C.; Leiva, V.; Cysneiros, F.J.A.; Liu, S. Robust multivariate control charts based on Birnbaum-Saunders distributions. J. Stat. Comput. Simul. 2018, 88, 182–202. [Google Scholar] [CrossRef]
- Cavieres, M.F.; Leiva, V.; Marchant, C.; Rojas, F. A methodology for data-driven decision making in the monitoring of particulate matter environmental contamination in Santiago of Chile. Rev. Environ. Contam. Toxicol. 2020. [Google Scholar] [CrossRef]
- Leiva, V.; Santos-Neto, M.; Cysneiros, F.J.A.; Barros, M. A methodology for stochastic inventory models based on a zero-adjusted Birnbaum-Saunders distribution. Appl. Stoch. Model. Bus. Ind. 2016, 32, 74–89. [Google Scholar] [CrossRef]
- Carrasco, J.M.F.; Figueroa-Zuniga, J.I.; Leiva, V.; Riquelme, M.; Aykroyd, R.G. An errors-in-variables model based on the Birnbaum-Saunders and its diagnostics with an application to earthquake data. Stoch. Environ. Res. Risk Assess. 2020, 34, 1–12. [Google Scholar] [CrossRef]
- Martinez, S.; Giraldo, R.; Leiva, V. Birnbaum-Saunders functional regression models for spatial data. Stoch. Environ. Res. Risk Assess. 2019, 33, 1765–1780. [Google Scholar] [CrossRef]
- Huerta, M.; Leiva, V.; Liu, S.; Rodriguez, M.; Villegas, D. On a partial least squares regression model for asymmetric data with a chemical application in mining. Chemom. Intell. Lab. Syst. 2019, 190, 55–68. [Google Scholar] [CrossRef]
- Leiva, V.; Aykroyd, R.G.; Marchant, C. Discussion of “Birnbaum-Saunders distribution: A review of models, analysis, and applications” and a novel multivariate data analytics for an economics example in the textile industry. Appl. Stoch. Model. Bus. Ind. 2019, 35, 112–117. [Google Scholar] [CrossRef]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. Incorporation of frailties into a cure rate regression model and its diagnostics and application to melanoma data. Stat. Med. 2018, 37, 4421–4440. [Google Scholar] [CrossRef]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. A survival model with Birnbaum-Saunders frailty for uncensored and censored cancer data. Braz. J. Probab. Stat. 2018, 32, 707–729. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Appl. Stoch. Models Bus. Ind. 2020. [Google Scholar] [CrossRef]
- Ventura, M.; Saulo, H.; Leiva, V.; Monsueto, S. Log-symmetric regression models: Information criteria, application to movie business and industry data with economic implications. Appl. Stoch. Model. Bus. Ind. 2019, 34, 963–977. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Laplace, P. Th’eorie Analytique des Probabilit’es; Editions Jacques Gabayr: Paris, France, 1818. [Google Scholar]
- Dasilva, A.; Dias, R.; Leiva, V.; Marchant, C.; Saulo, H. Birnbaum-Saunders regression models: A comparative evaluation of three approaches. J. Stat. Comput. Simul. 2020, in press. [Google Scholar]
- Saulo, H.; Leao, J.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders autoregressive conditional duration models applied to high-frequency financial data. Stat. Pap. 2019, 60, 1605–1629. [Google Scholar] [CrossRef]
- Diggle, P.; Ribeiro, P. Model-Based Geoestatistics; Springer: New York, NY, USA, 2007. [Google Scholar]
- Kostov, P. A spatial quantile regression hedonic model of agricultural land prices. Spat. Econ. Anal. 2009, 4, 53–72. [Google Scholar] [CrossRef]
- Trzpiot, G. Spatial quantile regression. Comp. Econ. Res. 2013, 15, 265–279. [Google Scholar] [CrossRef]
- McMillen, D. Quantile Regression for Spatial Data; Springer: New York, NY, USA, 2013. [Google Scholar]
- Garcia-Papani, F.; Uribe-Opazo, M.A.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders spatial modelling and diagnostics applied to agricultural engineering data. Stoch. Environ. Res. Risk Assess. 2017, 31, 105–124. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Ruggeri, F.; Uribe-Opazo, M.A. Kriging with external drift in a Birnbaum-Saunders geostatistical model. Stoch. Environ. Res. Risk Assess. 2018, 32, 1517–1530. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Uribe-Opazo, M.A.; Aykroyd, R.G. Birnbaum-Saunders spatial regression models: Diagnostics and application to chemical data. Chemom. Intell. Lab. Syst. 2018, 177, 114–128. [Google Scholar] [CrossRef]
- Liu, Y.; Mao, G.; Leiva, V.; Liu, S.; Tapia, A. Diagnostic analytics for an autoregressive model under the skew-normal distribution. Mathematics 2020, 8, 693. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Caro-Lopera, F.J.; Cysneiros, F.J.A. On matrix-variate Birnbaum-Saunders distributions and their estimation and application. Braz. J. Probab. Stat. 2015, 29, 790–812. [Google Scholar] [CrossRef]
- Kundu, D. Bivariate sinh-normal distribution and a related model. Braz. J. Probab. Stat. 2015, 20, 590–607. [Google Scholar] [CrossRef]
- Kundu, D.; Balakrishnan, N.; Jamalizadeh, A. Generalized multivariate Birnbaum-Saunders distributions and related inferential issues. J. Multivar. Anal. 2013, 116, 230–244. [Google Scholar] [CrossRef]
- Dobson, A. An Introduction to Statistical Modelling; Chapman and Hall: New York, NY, USA, 2002. [Google Scholar]
- Leiva, V.; Santos-Neto, M.; Cysneiros, F.J.A.; Barros, M. Birnbaum-Saunders statistical modelling: A new approach. Stat. Model. 2014, 14, 21–48. [Google Scholar] [CrossRef]
- Santos-Neto, M.; Cysneiros, F.J.A.; Leiva, V.; Barros, M. Reparameterized Birnbaum-Saunders regression models with varying precision. Electron. J. Stat. 2016, 10, 2825–2855. [Google Scholar] [CrossRef]
- Diaz-Garcia, J.A.; Leiva, V.; Galea, M. Singular elliptic distribution: Density and applications. Commun. Stat. Theory Methods 2002, 31, 665–681. [Google Scholar] [CrossRef]
- Kundu, D.; Balakrishnan, N.; Jamalizadeh, A. Bivariate Birnbaum-Saunders distribution and associated inference. J. Multivar. Anal. 2010, 101, 113–125. [Google Scholar] [CrossRef]
- Saulo, H.; Leao, J.; Vila, R.; Leiva, V.; Tomazella, V. On mean-based bivariate Birnbaum-Saunders distributions: Properties, inference and application. Commun. Stat. Theory Methods 2020. [Google Scholar] [CrossRef]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging; Springer: New York, NY, USA, 1999. [Google Scholar]
- Mardia, K.; Marshall, R. Maximum likelihood estimation of models for residual covariance in spatial regression. Biometrika 1984, 71, 135–146. [Google Scholar] [CrossRef]
- Gradshteyn, I.; Ryzhik, I. Tables of Integrals, Series and Products; Academic Press: New York, NY, USA, 2000. [Google Scholar]
- Zhang, H.; Wang, Y. Kriging and cross-validation for massive spatial data. Environmetrics 2010, 21, 290–304. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Lange, K. Numerical Analysis for Statisticians; Springer: New York, NY, USA, 2001. [Google Scholar]
- R-Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Marchant, C.; Leiva, V.; Cysneiros, F.J.A.; Vivanco, J.F. Diagnostics in multivariate generalized Birnbaum-Saunders regression models. J. Appl. Stat. 2016, 43, 2829–2849. [Google Scholar] [CrossRef]
- Dunn, P.; Smyth, G. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Ferreira, M.; Gomes, M.I.; Leiva, V. On an extreme value version of the Birnbaum-Saunders distribution. REVSTAT 2012, 10, 181–210. [Google Scholar]
- Bhatti, C. The Birnbaum–Saunders autoregressive conditional duration model. Math. Comput. Simul. 2010, 80, 2063–2078. [Google Scholar] [CrossRef]
- Song, P.X.K.; Zhang, P.; Qu, A. Maximum likelihood inference in robust linear mixed-effects models using the multivariate T Distributions. Stat. Sin. 2007, 17, 929–943. [Google Scholar]
- Genton, M.G.; Zhang, H. Identifiability problems in some non-Gaussian spatial random fields. Chil. J. Stat. 2012, 3, 171–179. [Google Scholar]
- Zhang, H.; Zimmerman, D.L. Towards reconciling two asymptotic frameworks in spatial statistics. Biometrika 2005, 92, 921–936. [Google Scholar] [CrossRef]
- Athayde, E.; Azevedo, A.; Barros, M.; Leiva, V. Failure rate of Birnbaum-Saunders distributions: Shape, change-point, estimation and robustness. Braz. J. Probab. Stat. 2019, 33, 301–328. [Google Scholar] [CrossRef]
- Villegas, C.; Paula, G.A.; Leiva, V. Birnbaum-Saunders mixed models for censored reliability data analysis. IEEE Trans. Reliab. 2011, 60, 748–758. [Google Scholar] [CrossRef]
- Santana, L.; Vilca, F.; Leiva, V. Influence analysis in skew-Birnbaum-Saunders regression models and applications. J. Appl. Stat. 2011, 38, 1633–1649. [Google Scholar] [CrossRef]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).