Parameter Estimation and Measurement of Social Inequality in a Kinetic Model for Wealth Distribution


Abstract
1. Introduction
2. Mathematical Model of Wealth Distribution
- -
- The encounter rate , which describes the rate of interactions between a candidate (or test) h-particle and a field k-particle.
- -
- The transition probability density , which describes the probability density that a candidate h-particle falls into the state after an interaction with a field k-particle. This function satisfies
3. Qualitative Analysis
3.1. Qualitative Analysis of Asymptotic Behaviors
- .
- .
- If , then .
- If , then .
- If , then .
3.2. Measuring Inequality and the Gini Coefficient
4. Parameter Estimation from Empirical Data
4.1. Defining the Optimization Problem
4.2. Numerical Results
4.2.1. Case Study 1: Model Generated Data
- In general, parameters are retrieved for data with noise with a lower relative error than in the case of and noise. However, notice that even with the highest level of noise we get reasonable results in most of the cases, so the results remain robust when we increase the noise.
- The best possible situation would be to have available data on the distribution functions . Indeed, the knowledge of these distributions allows also to calculate the Gini coefficient and wealth. That is why Experiments 1 and 6, which prioritize , in general give good results.
- When or , the parameter is recovered accurately. In contrast, the worst approximation is obtained in Experiment 2. Please note that it is reasonable to get these results due to the close relationship between and inequality, as explained in Section 3.2.
- When wealth is prioritized over the complete profiles, i.e., larger values of are considered, results lose accuracy and the quality of data recovery gets worse. Consequently, should not be larger than the other weights. However, some countries may have available information only on total wealth or GDP and not on the complete social profiles. If this is the situation, availability of information on Gini coefficients can clearly improve the results, specifically : indeed, Experiments 7 and 8 get better results than Experiment 2.
- It is worth noticing that in general, even if and are not retrieved accurately, their difference and quotient give much better results. This is expected from the detailed analysis performed in Section 3.1, where we showed that the dynamics depends on these quantities.
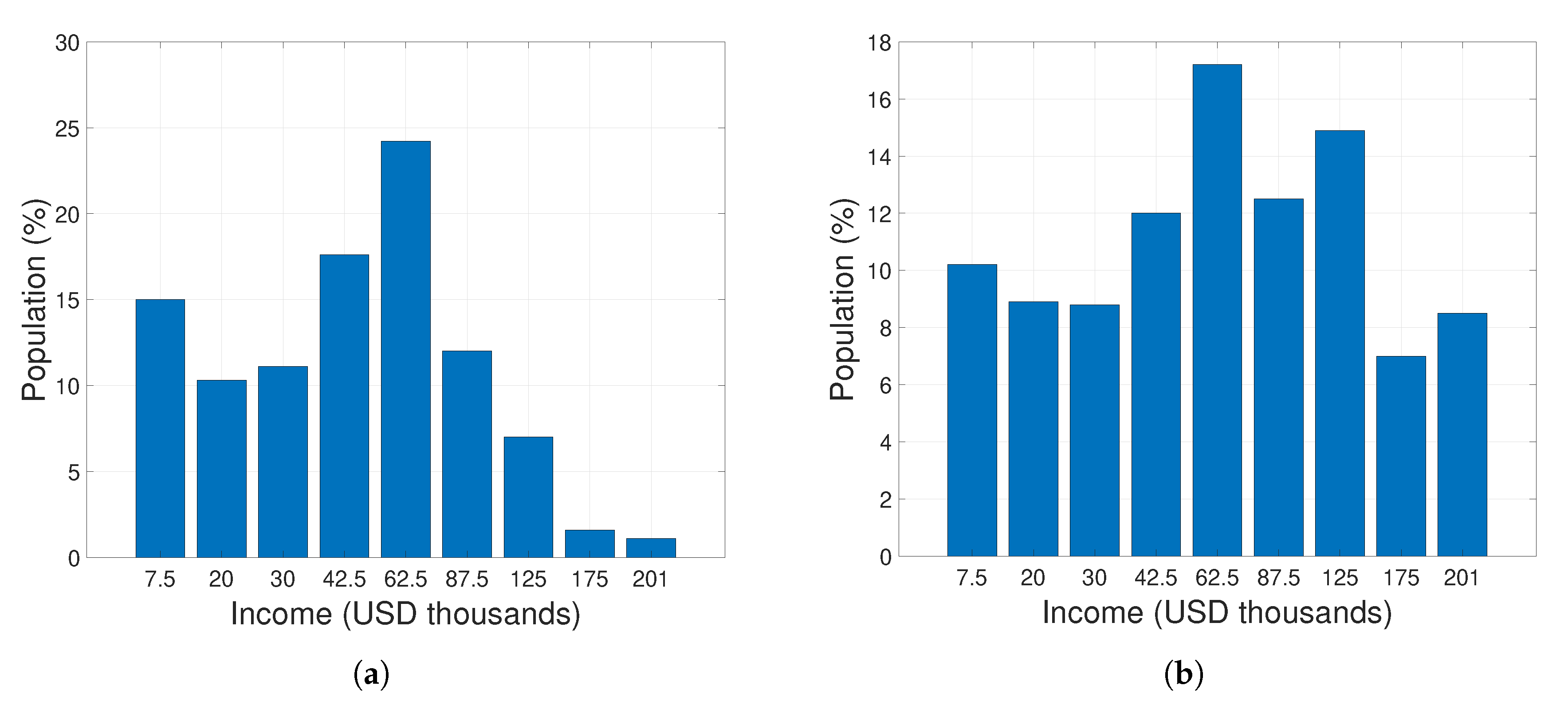
4.2.2. Case Study 2: US
5. Conclusions and Looking Ahead
Author Contributions
Funding
Conflicts of Interest
References
- Knopoff, D. On the modeling of migration phenomena on small networks. Math. Models Methods Appl. Sci. 2013, 23, 541–563. [Google Scholar] [CrossRef]
- UN General Assembly, International Migration and Development. Report of the Secretary-General, 18 May 2006, A/60/871. Available online: http://www.unhcr.org/refworld/docid/44ca2d934.html (accessed on 1 March 2020).
- Hurst, C.; Gibbon, H.; Nurse, A. Social Inequality: Forms, Causes, and Consequences; Routledge: Abington, UK, 2016. [Google Scholar]
- Yakovenko, V.; Rosser, J., Jr. Colloquium: Statistical mechanics of money, wealth, and income. Rev. Mod. Phys. 2009, 81, 1703. [Google Scholar] [CrossRef]
- Chakrabarti, B.; Chakraborti, A.; Chakravarty, S.; Chatterjee, A. Econophysics of Income and Wealth Distributions; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Wolff, E.N. Household Wealth Trends in the United States, 1962 to 2013: What Happened over the Great Recession? RSF Russell Sage Found. J. Soc. Sci. 2016, 2, 24–43. [Google Scholar]
- Bellomo, N.; Knopoff, D.; Soler, J. On the difficult interplay between life “complexity” and mathematical sciences. Math. Models Methods Appl. Sci. 2013, 23, 1861–1913. [Google Scholar] [CrossRef]
- Bellomo, N. Modeling Complex Living Systems: A Kinetic Theory and Stochastic Game Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Dolfin, M.; Lachowicz, M. Modeling opinion dynamics: How the network enhances consensus. Netw. Heterog. Media 2015, 4, 421–441. [Google Scholar] [CrossRef]
- Knopoff, D. On a mathematical theory of complex systems on networks with application to opinion formation. Math. Models Methods Appl. Sci. 2014, 24, 405–426. [Google Scholar] [CrossRef]
- Burini, D.; De Lillo, S. On the complex interaction between collective learning and social dynamics. Symmetry 2019, 11, 967. [Google Scholar] [CrossRef]
- Burini, D.; De Lillo, S.; Gibelli, L. Collective learning modeling based on the kinetic theory of active particles. Phys. Life Rev. 2016, 16, 126–139. [Google Scholar] [CrossRef]
- Dolfin, M.; Knopoff, D.; Leonida, L.; Patti, D. Escaping the trap of “blocking”: A kinetic model linking economic development and political competition. Kinet. Relat. Models 2017, 10, 423–443. [Google Scholar] [CrossRef]
- Bertotti, M.L.; Delitala, M. From discrete kinetic and stochastic game theory to modelling complex systems in applied sciences. Math. Models Methods Appl. Sci. 2004, 14, 1061–1084. [Google Scholar] [CrossRef]
- Bertotti, M.L.; Delitala, M. Conservation laws and asymptotic behavior of a model of social dynamics. Nonlinear Anal. RWA 2008, 9, 183–196. [Google Scholar] [CrossRef]
- Bellomo, N.; Herrero, M.A.; Tosin, A. On the dynamics of social conflicts looking for the Black Swan. Kinet. Relat. Models 2013, 6, 459–479. [Google Scholar] [CrossRef]
- Knopoff, D.; Torres, G. On an optimal control strategy in a kinetic social dynamics model. Commun. Appl. Ind. Math. 2018, 9, 22–33. [Google Scholar] [CrossRef]
- Furioli, G.; Pulvirenti, A.; Terraneo, E.; Toscani, G. Fokker–Planck equations in the modeling of socio–economic phenomena. Math. Models Methods Appl. Sci. 2017, 27, 115–158. [Google Scholar] [CrossRef]
- Furioli, G.; Pulvirenti, A.; Terraneo, E.; Toscani, G. Non–Maxwellian kinetic equations modeling the dynamics of wealth distribution. Math. Models Methods Appl. Sci. 2020, 30, 1–41. [Google Scholar] [CrossRef]
- Lim, G.; Min, S. Analysis of solidarity effect for entropy, Pareto, and Gini indices on two-class society using kinetic wealth exchange model. Entropy 2020, 22, 386. [Google Scholar] [CrossRef]
- Quadrini, V.; Rios-Rull, J. Models of the distribution of wealth. Fed. Reserve Bank Minneap. Q. Rev. 1997, 21, 1–21. [Google Scholar]
- De Nardi, M.; Fella, G. Saving and wealth inequality. Rev. Econ. Dyn. 2017, 26, 280–300. [Google Scholar] [CrossRef]
- Schelling, T. Dynamic models of segregation. J. Math. Sociol. 1971, 1, 143–186. [Google Scholar] [CrossRef]
- Benard, S.; Willer, R. A wealth and status-based model of residential segregation. Math. Sociol. 2007, 31, 149–174. [Google Scholar] [CrossRef]
- Hatna, E.; Benenson, I. The Schelling model of ethnic residential dynamics: Beyond the integrated-segregated dichotomy of patterns. J. Artif. Soc. Soc. Simul. 2012, 15, 6. [Google Scholar] [CrossRef]
- Hazan, A.; Randon-Furling, J. A Schelling model with switching agents: Decreasing segregation via random allocation and social mobility. Eur. Phys. J. B 2013, 86, 421. [Google Scholar] [CrossRef]
- Chuang, Y.; Chou, T.; D’Orsogna, M. A network model of immigration: Enclave formation vs. cultural integration. Netw. Heterog. Media 2019, 14, 53. [Google Scholar] [CrossRef]
- Jarvis, M.; Lange, G.M.; Hamilton, K.; Desai, D.; Fraumeni, B.; Edens, B.; Ferreira, S.; Fraumeni, B.; Jarvis, M.; Kingsmill, W.; et al. The Changing Wealth of Nations: Measuring Sustainable Development in the New Millennium; The World Bank: Washington, DC, USA, 2011. [Google Scholar]
- Cohen, J.E. Population growth and earth’s human carrying capacity. Science 1995, 269, 341–346. [Google Scholar] [CrossRef]
- Guzman, G.G. Household Income; American Community Survey Briefs: Washington, DC, USA, 2016. [Google Scholar]
- United States Census Bureau. Available online: https://www.census.gov/en.html (accessed on 1 March 2020).
- Taleb, N.N. The Black Swan: The Impact of the Highly Improbable; Random House: New York, NY, USA, 2007. [Google Scholar]
- Chuang, Y.L.; Chou, T.; D’Orsogna, M.R. Age-structured social interactions enhance radicalization. J. Math. Sociol. 2018, 3, 128–151. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| n | Number of social classes |
| Social states | |
| Number of individuals that have social state | |
| T | Maximum observation time |
| N | Population |
| W | Total wealth |
| V | Wealth per capita |
| Encounter rates | |
| Transition probability densities | |
| , r | Net proliferation rates |
| Social threshold | |
| Probability of decreasing one social class | |
| Probability of increasing one social class | |
| Asymptotic value of W when | |
| Asymptotic value of V when | |
| Asymptotic value of when | |
| g | Gini coefficient |
| Experiment | Society I | Society II | ||||
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
| Experiment | Society I | Society II | ||||
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
| Experiment | Society I | Society II | ||||
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buffa, B.A.; Knopoff, D.; Torres, G. Parameter Estimation and Measurement of Social Inequality in a Kinetic Model for Wealth Distribution. Mathematics 2020, 8, 786. https://doi.org/10.3390/math8050786
Buffa BA, Knopoff D, Torres G. Parameter Estimation and Measurement of Social Inequality in a Kinetic Model for Wealth Distribution. Mathematics. 2020; 8(5):786. https://doi.org/10.3390/math8050786
Chicago/Turabian StyleBuffa, Bruno Adolfo, Damián Knopoff, and Germán Torres. 2020. "Parameter Estimation and Measurement of Social Inequality in a Kinetic Model for Wealth Distribution" Mathematics 8, no. 5: 786. https://doi.org/10.3390/math8050786
APA StyleBuffa, B. A., Knopoff, D., & Torres, G. (2020). Parameter Estimation and Measurement of Social Inequality in a Kinetic Model for Wealth Distribution. Mathematics, 8(5), 786. https://doi.org/10.3390/math8050786