Multiobjective Model Predictive Control of a Parabolic Advection-Diffusion-Reaction Equation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. The Multiobjective Optimal Control Problem
3. Multiobjective Model Predictive Control (Mompc)
| Algorithm 1 Multiobjective model predictive control |
| Given: Initial state . |
|
- (1)
- The statement from Theorem 3 is important, since it gives us performance bounds on the cost functions values of the MOMPC feedback control μ already after choosing the initial control , but before performing the MOMPC Algorithm 1. Thus, one strategy is to compute the entire Pareto set , which is computationally cheap due to the small time horizon , and then to choose the initial control according to the desired upper bounds on the cost functions.
- (2)
- Theorem 3 holds for arbitrary . In particular, by taking the limit , the result can also be shown for the infinite-horizon case.
| Algorithm 2 Multiobjective Gradient Descent Method |
| Given: Current iterate n, initial control , tolerance , Armijo parameter . |
- (1)
- Note that we cannot prove that the sequence has an accumulation point in the infinite-dimensional case. However, we will not encounter this problem in our numerical implementation, since the space will be discretized. Therefore, Algorithm 2 will in practice terminate in a finite number of steps.
- (2)
- By construction of the algorithm it holds , , for any initial control , so that (5) is fulfilled, if we choose .
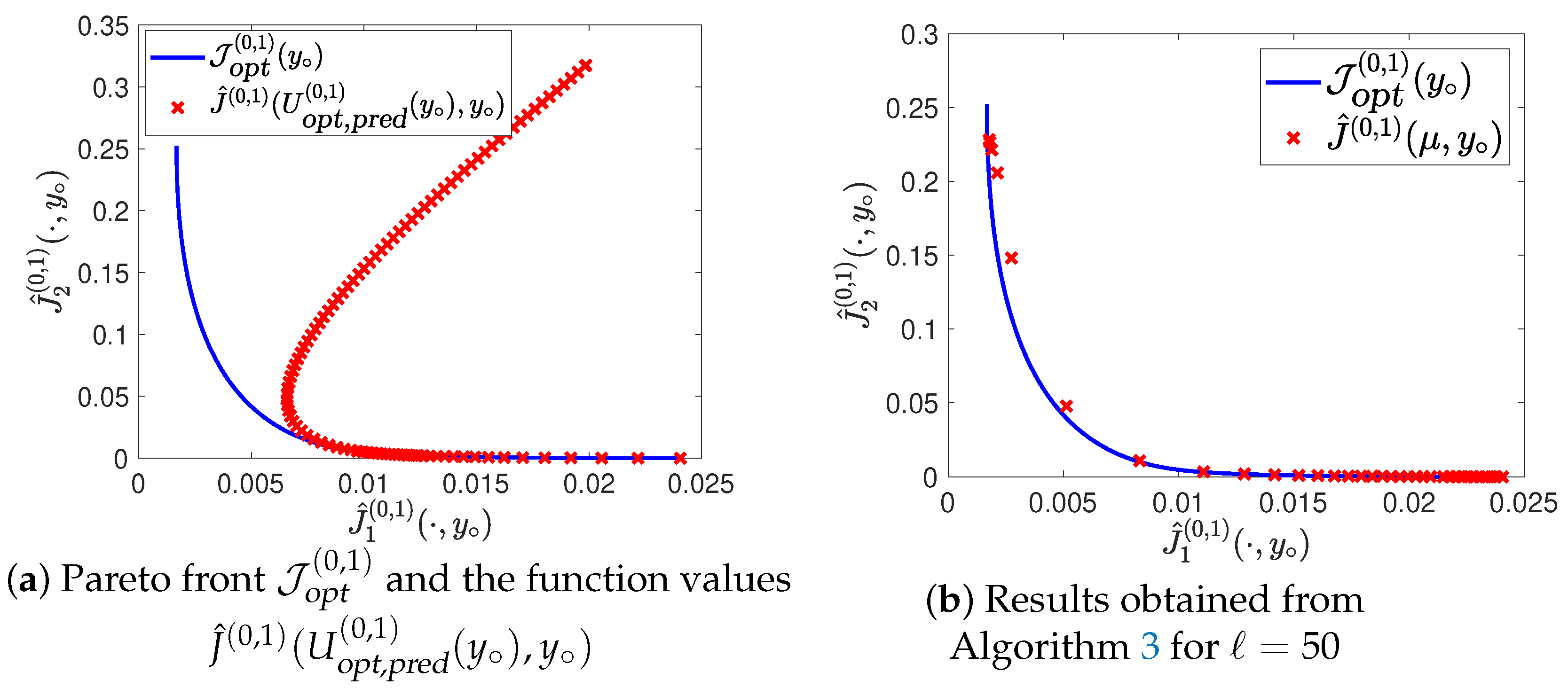
| Algorithm 3 Multiobjective Model Predictive Control |
| Given: Initial state . |
|
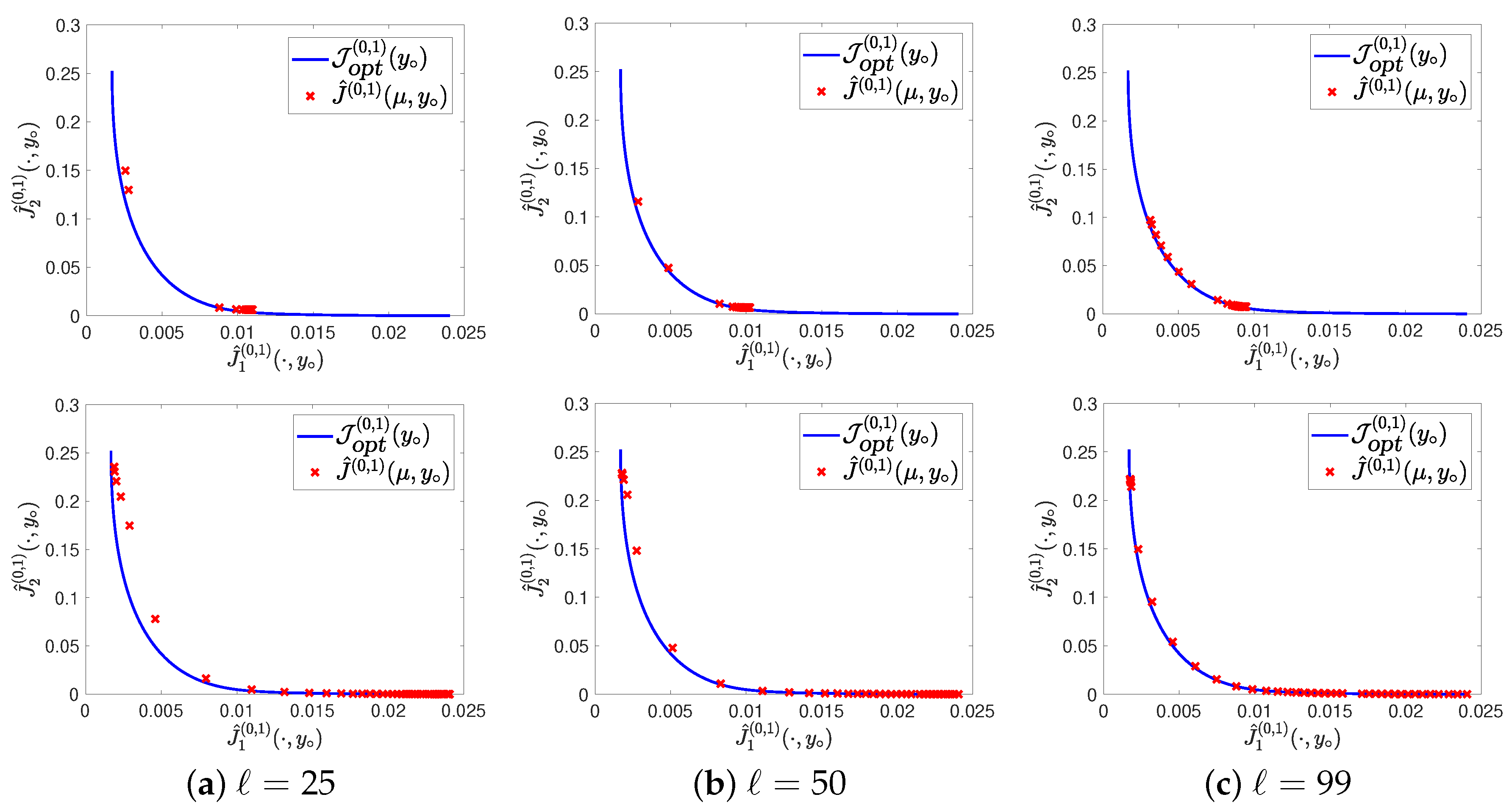
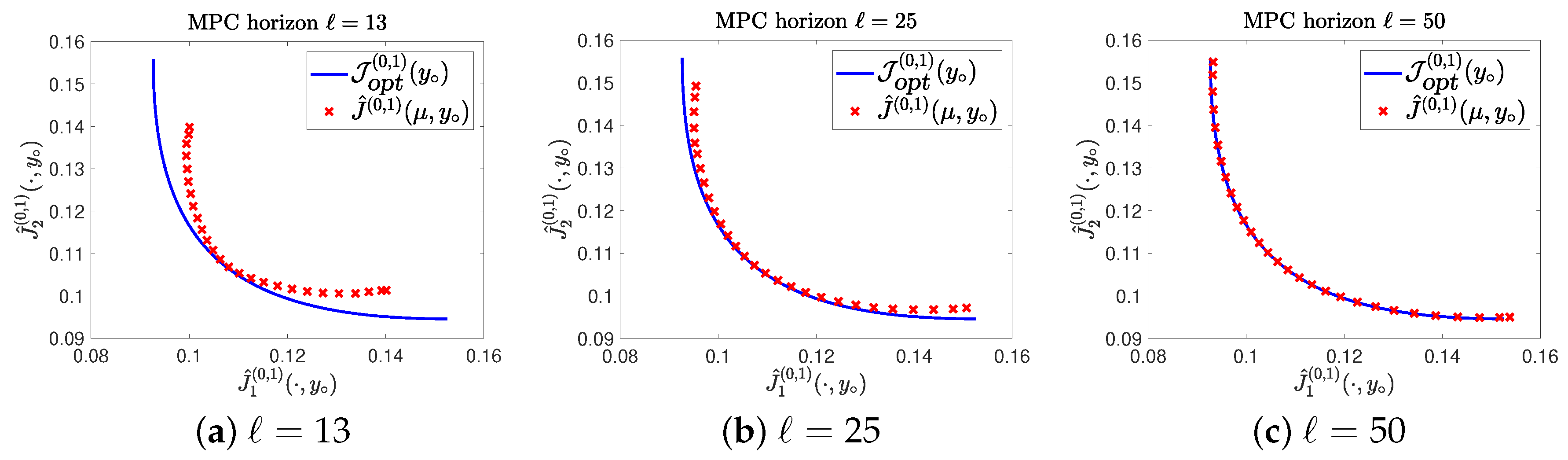
4. Numerical Tests
4.1. Example 1
4.2. Example 2
5. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MO | Multiobjective optimization |
| MOP | Multiobjective optimization problem |
| MOCP | Multiobjective optimal control problem |
| MPC | Model predictive control |
| MOMPC | Multiobjective model predictive control |
| ODE | Ordinary differential equation |
| PDE | Partial differential equation |
References
- Rawlings, J.; Mayne, D. Model Predictive Control: Theory and Design; Nob Hill Publishing: Madison, WI, USA, 2009. [Google Scholar]
- Forbes, M.G.; Patwardhan, R.S.; Hamadah, H.; Gopaluni, R.B. Model Predictive Control in Industry: Challenges and Opportunities. In Proceedings of the 9th IFAC Symposium on Advanced Control of Chemical Processes—ADCHEM 2015, Whistler, BC, Canada, 7–10 June 2015; Volume 48, pp. 531–538. [Google Scholar]
- Grüne, L. Approximation properties of receding horizon optimal control. Jahresbericht der Deutschen Mathematiker-Vereinigung 2016, 118, 3–37. [Google Scholar] [CrossRef]
- Grüne, L.; Pannek, J. Nonlinear Model Predictive Control: Theory and Algorithms, 2nd ed.; Communications and Control Engineering; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Laabidi, K.; Bouani, F.; Ksouri, M. Multi-criteria optimization in nonlinear predictive control. Math. Comput. Simul. 2008, 76, 363–374. [Google Scholar] [CrossRef]
- Bemporad, A.; Muñoz de la Peña, D. Multiobjective model predictive control. Automatica 2009, 45, 2823–2830. [Google Scholar] [CrossRef]
- He, D.; Wang, L.; Sun, J. On stability of multiobjective NMPC with objective prioritization. Automatica 2015, 57, 189–198. [Google Scholar] [CrossRef]
- Zavala, V.M.; Flores-Tlacuahuac, A. Stability of multiobjective predictive control: A utopia-tracking approach. Automatica 2012, 48, 2627–2632. [Google Scholar] [CrossRef]
- Peitz, S.; Schäfer, K.; Ober-Blöbaum, S.; Eckstein, J.; Köhler, U.; Dellnitz, M. A Multiobjective MPC Approach for Autonomously Driven Electric Vehicles. IFAC PapersOnLine 2017, 50, 8674–8679. [Google Scholar] [CrossRef]
- Grüne, L.; Stieler, M. Performance guarantees for multiobjective model predictive control. In Proceedings of theIEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, 12–15 December 2017; pp. 5545–5550. [Google Scholar]
- Grüne, L.; Stieler, M. Multiobjective model predictive control for stabilizing cost criteria. Discret. Contin. Dyn. Syst. B 2019, 24, 3905. [Google Scholar] [CrossRef]
- Ehrgott, M. Multicriteria Optimization, 2nd ed.; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2005. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer: New York, NY, USA, 1998. [Google Scholar]
- Iapichino, L.; Trenz, S.; Volkwein, S. Multiobjective optimal control of semilinear parabolic problems using POD. In Numerical Mathematics and Advanced Applications (ENUMATH 2015); Karasözen, B., Manguoglu, M., Tezer-Sezgin, M., Goktepe, S., Ugur, Ö., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 389–397. [Google Scholar]
- Iapichino, L.; Ulbrich, S.; Volkwein, S. Multiobjective PDE-constrained optimization using the reduced-basis method. Adv. Comput. Math. 2017, 43, 945–972. [Google Scholar] [CrossRef]
- Peitz, S. Exploiting Structure in Multiobjective Optimization and Optimal Control. Ph.D. Thesis, Paderborn University, Paderborn, Germany, 2017. [Google Scholar]
- Peitz, S.; Dellnitz, M. Gradient-Based Multiobjective Optimization with Uncertainties. In Proceedings of the NEO 2016: Results of the Numerical and Evolutionary Optimization Workshop NEO 2016 and the NEO Cities 2016 Workshop, Tlalnepantla, Mexico, 20–24 September 2016; Maldonado, Y., Trujillo, L., Schütze, O., Riccardi, A., Vasile, M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 159–182. [Google Scholar] [CrossRef]
- Banhozer, S.; Dellnitz, M.; Gebken, B.; Peitz, S.; Volkwein, S. ROM-based multiobjective optimization of elliptic PDEs via numerical continuation. arXiv 2019, arXiv:1906.09075v1. [Google Scholar]
- Wierzbicki, A.P. The Use of Reference Objectives in Multiobjective Optimization. In Multiple Criteria Decision Making Theory and Application; Springer: Berlin/Heidelberg, Germany, 1980; pp. 468–486. [Google Scholar]
- Wierzbicki, A.P. On the completeness and constructiveness of parametric characterizations to vector optimization problems. Oper. Res. Spektrum 1986, 8, 73–87. [Google Scholar] [CrossRef]
- Banholzer, S.; Beermann, D.; Volkwein, S. POD-Based Bicriterial Optimal Control by the Reference Point Method. IFAC PapersOnLine 2016, 49, 210–215. [Google Scholar] [CrossRef]
- Banholzer, S. POD-Based Bicriterial Optimal Control of Convection-Diffusion Equations. Master’s Thesis, University of Konstanz, Konstanz, Germany, 2017. [Google Scholar]
- Banholzer, S.; Beermann, D.; Volkwein, S. POD-Based error control for reduced-order bicriterial PDE-constrained optimization. Annu. Rev. Control 2017, 44, 226–237. [Google Scholar] [CrossRef]
- Dautray, R.; Lions, J.L. Mathematical Analysis and Numerical Methods for Science and Technology; Volume 5: Evolution Problems I; Springer Science & Business Media: Cham, Switzerland, 2000. [Google Scholar]
- Schäffler, S.; Schultz, R.; Weinzierl, K. Stochastic Method for the Solution of Unconstrained Vector Optimization Problems. J. Optim. Theory Appl. 2002, 114, 209–222. [Google Scholar] [CrossRef]
- Fliege, J.; Svaiter, B. Steepest descent methods for multicriteria optimization. Math. Methods Oper. Res. 2000, 51, 479–494. [Google Scholar] [CrossRef]
- Grüne, L.; Schaller, M.; Schiela, A. Sensitivity analysis of optimal control for a class of parabolic PDEs motivated by model predictive control. SIAM J. Control Optim. 2019, 57, 2753–2774. [Google Scholar] [CrossRef]
- Grüne, L.; Schaller, M.; Schiela, A. Exponential sensitivity analysis for Model Predictive Control of PDEs. Preprint, Department of Mathematics, University of Bayreuth. 2020. Available online: http://nbn-resolving.org/urn:nbn:de:bvb:703-epub-4590-3 (accessed on 4 May 2020).
- Banholzer, S.; Volkwein, S. Hierarchical Convex Multiobjective Optimization by the Euclidean Reference Point Method; Technical Report; University of Konstanz: Konstanz, Germany, 2019. [Google Scholar]
- Sirovich, L. Turbulence and the dynamics of coherent structures part I: Coherent structures. Q. Appl. Math. 1987, 45, 561–571. [Google Scholar] [CrossRef]
- Gubisch, M.; Volkwein, S. Proper Orthogonal Decomposition for Linear-Quadratic Optimal Control. In Model Reduction and Approximation: Theory and Algorithms; Benner, P., Cohen, A., Ohlberger, M., Willcox, K., Eds.; SIAM: Philadelphia, PA, USA, 2017; pp. 5–66. [Google Scholar] [CrossRef]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banholzer, S.; Fabrini, G.; Grüne, L.; Volkwein, S. Multiobjective Model Predictive Control of a Parabolic Advection-Diffusion-Reaction Equation. Mathematics 2020, 8, 777. https://doi.org/10.3390/math8050777
Banholzer S, Fabrini G, Grüne L, Volkwein S. Multiobjective Model Predictive Control of a Parabolic Advection-Diffusion-Reaction Equation. Mathematics. 2020; 8(5):777. https://doi.org/10.3390/math8050777
Chicago/Turabian StyleBanholzer, Stefan, Giulia Fabrini, Lars Grüne, and Stefan Volkwein. 2020. "Multiobjective Model Predictive Control of a Parabolic Advection-Diffusion-Reaction Equation" Mathematics 8, no. 5: 777. https://doi.org/10.3390/math8050777
APA StyleBanholzer, S., Fabrini, G., Grüne, L., & Volkwein, S. (2020). Multiobjective Model Predictive Control of a Parabolic Advection-Diffusion-Reaction Equation. Mathematics, 8(5), 777. https://doi.org/10.3390/math8050777