1. Introduction
With the rapid development of Internet technology and the increasing popularity of mobile devices, it is very easy for users to capture, transmit and share images through the networks. In these image data, near-duplicate images occupy a significant proportion. The task of near-duplicate image detection is to efficiently and effectively detect near-duplicate versions of a given query image from a large-scale image database. Near-duplicate image detection has been successfully applied in many applications, such as image copyright protection [
1,
2,
3], coverless information hiding [
4,
5,
6], secret image sharing [
7] and redundancy elimination [
8].
In recent years, deep learning techniques such as convolutional neural networks (CNNs) have received extensive attention in the area of computer vision [
9,
10]. In view of this fact, some researchers tend to use the features extracted from CNNs instead of hand-crafted features for the tasks of near-duplicate image detection or content-based image retrieval [
11,
12,
13,
14,
15,
16,
17]. In literature, it has been proven that CNN-based features achieve superior performance than the traditional hand-crafted features. In general, the existing CNN-based features can be divided into two categories: global CNN features and local CNN features.
The global CNN features are extracted by feeding the whole region of an image into a pretrained CNN model and pooling the outputs of the intermediate layers such as convolutional layers or fully connected layers. The most typical pooling methods used for global CNN feature extraction include max-pooling [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28], sum-pooling [
29,
30,
31,
32], and average-pooling [
33]. Researchers have proposed some improved versions of these pooling methods to extract the global CNN features, such as centering prior-based sum-pooled convolution (SPoC) feature [
29], the cross-dimensional weighting (CroW) feature [
30], and the regional maximum activations of convolution (R-MAC) [
18].
Recently, some researchers have focused on training deep learning models to extract image features [
34,
35,
36,
37]. However, since these methods fail to sufficiently consider the influence of background clutter and partial occlusion on the final representation, the extracted global CNN features are not robust enough to combat these attacks.
Instead of capturing the characteristics of the whole image region, the local CNN features [
19,
20,
21,
22,
38,
39,
40,
41,
42] characterize the local image regions. Generally, similar to the traditional hand-crafted local features such as scale-invariant feature transform (SIFT) [
43], the extraction of local CNN features consists of two stages: image region detection and descriptor generation. A number of image regions are first detected from each image, and the local descriptors are generated from the outputs of intermediate layers of a pretrained CNN model within the regions. In [
44], the local CNN features were proven to perform better than the traditional hand-crafted local features in many image retrieval/detection tasks. However, since a large number of local regions are usually detected from each image, the extraction and matching of local features usually have high computational complexity. To reduce the computational complexity, local features are usually integrated into a single image representation using a variety of integration methods such as bag of words (BOW) model [
45], fisher vector (FV) [
46], and vector of locally aggregated descriptors (VLAD) [
47] for near-duplicate image detection. However, the integration process causes a lot of important information to be lost and thus decreases the detection accuracy significantly.
In summary, although the extraction and matching of global CNN features are computationally efficient, the global CNN features suffer from the robustness problem in near-duplicate image detection. On the contrary, the local CNN features achieve higher robustness, but the matching of local CNN features between images has high computational complexity since a large number of local CNN features are extracted from each image.
In order to exploit the advantages of both global features and local features, we propose a coarse-to-fine feature matching scheme using both global and local CNN features for near-duplicate image detection. The main contributions of our method are summarized as follows:
(1) A coarse-to-fine feature matching scheme is proposed. The proposed coarse-to-fine feature matching scheme consists of a coarse matching stage and a fine matching stage. In the coarse matching stage, we match the global CNN features between a given query image and database images to filter most of irrelevant images of the query from an image database. In the fine matching stage, we extract and match the local CNN features between images to find the near-duplicate versions of the query. The proposed coarse-to-fine feature matching scheme allows a real-time and accurate near-duplicate image detection. Thus, it has important significance in practical applications of content-based image detection/retrieval.
(2) The saliency map-based local CNN features are extracted. In the tasks of facial expression recognition and image classification, the introduction of attention mechanisms leads to the significant improvements [
48,
49,
50,
51]. Motivated by these works, after the global CNN feature matching, we detect the saliency map by the graph-based visual saliency detection (GBVS) algorithm [
52] and extract the local CNN features from the local regions surrounding the maximum values of the saliency map. The extracted local CNN features not only have high robustness to background clutter and partial occlusion, but also achieve high repeatability due to the good stability of the maximum values of the saliency map. Consequently, in the fine feature matching stage, the local CNN feature matching further improves the accuracy of near-duplicate image detection.
The rest of this paper is organized as follows.
Section 2 introduces the related works. The details of the proposed detection method are presented in the
Section 3.
Section 4 displays and analyzes the experimental results. Finally, conclusions are drawn in
Section 5.
2. Related Works
With the increasing popularity of CNNs, the recent near-duplicate image detection methods tend to use the features extracted from pre-trained CNN models instead of the traditional hand-crafted features. The existing CNN-based features can be roughly categorized into global CNN features and local CNN features.
The global CNN features are usually extracted by feeding the whole region of an image into a pre-trained CNN model and then pooling the outputs of the intermediate layers such as convolutional layers and fully connected layers. In literature, the popular pooling methods include max-pooling [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28], sum-pooling [
29,
30,
31,
32], and average-pooling [
33]. Generally, the outputs of a convolutional layer are a set of convolutional feature maps (CFMs), and the global CNN features are extracted by implementing a pooling operation on the CFMs. The max-pooling method computes the maximum value of each CFM and concatenates all the maximum values to form the global CNN features, while sum-pooling and average-pooling methods compute the sum and the average value of each CFM, respectively. To improve the performance of the extracted global CNN features on near-duplicate image detection, researchers have proposed some improved versions of these pooling methods to extract the global CNN features. Babenko et al. [
29] proposed the SPoC descriptor, which is generated by an improved version of the sum-pooling, i.e., centering prior-based sum-pooling. In particular, instead of directly computing the sum of all activations of each CFM, SPoC [
29] is extracted by performing centering prior-based sum-pooling on the CFMs, where the activations near to the center of feature maps are assigned larger weighting coefficients. Kalantidis et al. [
30] generated CroW by computing the weighted sum values on the CFMs, where the weights of detected interest regions are set to be larger, while the weights of other regions are set to lower. Tolias et al. [
18] proposed an aggregation method based on variable sliding windows to generate the global CNN feature, i.e., R-MAC, where the max-pooling operation is implemented to aggregate activations of CFMs within sliding windows. The above global feature extraction methods have improved the performance of near-duplicate image detection to some extent.
Recently, some researchers have focused on training deep learning models to extract global image features. Lia et al. [
34] evaluated a set of CNN-learned descriptors and concluded that the features learned from fine-tuned CNNs perform better than the off-the-shelf features. Shervin et al. [
35] gave a summary of promising works that use deep learning-based models for biometric recognition. Shervin et al. [
36] identified mild traumatic brain injury patients by combining a bag of adversarial features (BAF) and unsupervised feature learning techniques. Zhang et al. [
37] learned a general straightforward similarity function from raw image pairs for near-duplicate image detection.
However, since those global CNN features are extracted from the whole image region, they show weak robustness in regards to the background clutter and partial occlusion, which negatively influence on the performance of near-duplicate image detection.
In order to address the problem of weak robustness, one possible solution is to extract local CNN features for near-duplicate image detection. In literature, a variety of local CNN features have been proposed. Generally, similar to the traditional hand-crafted local features, the extraction of local CNN features consists of two steps: region detection and descriptor generation. In the image region detection, there are three kinds of popular regions: the image patches, interest point-based regions, and the object region proposals. In the descriptor generation stage, by feeding a given image into a pretrained CNN model, the local CNN features are extracted from the outputs of convolutional layers or fully connected layers within each image region. Gong et al. [
38] detected local image patches by adopting a multi-scale sliding window strategy on CFMs, and then concatenated the local CNN features extracted from all the image patches. In contrast from the R-MAC, the feature extraction is implemented at a multi-scale level. Razavian et al. [
19] divided images into a set of patches at the multi-scale level, the union of which covers the whole image, for local CNN feature extraction. Zagoruyko et al. [
20] detected the regions surrounding the difference of Gaussian (DOG) feature points, while Fischer et al. [
44] detected the maximally stable extremal regions (MSER). Mopuri et al. [
21] extracted image patches using selective search [
39]. In [
40], Uricchio et al. utilized the EdgeBox algorithm proposed by [
41] for region generation. By using the edge information, the EdgeBox first determines the number of contours in image boxes and the number of edges that overlap the edge of the boxes to score these boxes for generation of object region proposals. Salvador et al. [
22] located the potential object regions in an image by employing the region proposal network (RPN) [
42]. Besides these region detection algorithms, attention mechanisms have been introduced to capture local characteristics in image classification and facial expression recognition tasks [
48,
49,
51]. Assaf et al. [
48] improved the classical Capsule Network (CapsNet) architecture by embedding the self-attention module between the convolutional layers and the primary CapsNet layers for image classification. Shervin et al. [
49] proposed the spatial transformer network [
50] to detect important face parts for facial expression recognition. Wang et al. [
51] built the residual attention network by stacking multiple attention modules within the feed forward network architecture for image classification. Since the local CNN features are extracted at the region-level and some regions still survive after the attacks of background clutter and partial-occlusion, the local CNN features show much higher robustness than the global CNN features. However, due to the large number of local features, the extraction and matching of these local features is very time-consuming, which leads to the limited efficiency for near-duplicate image detection. Although some aggregation methods, such as the bag of words (BOW) model [
45], fisher vector (FV) [
46], and the vector of locally aggregated descriptors (VLAD) [
47] integrate local features into a single image representation to improve the efficiency, the detection accuracy will decrease significantly due to the information loss caused by the aggregation process. In summary, it is hard to directly use these CNN features to achieve a real-time and accurate near-duplicate image detection.
According to the above, there is still a lot of room for improvement in the performance of near-duplicate image detection. To achieve a real-time and accurate near-duplicate image detection, we attempt to take the advantages of both global and local CNN features. In this paper, we propose a coarse-to-fine matching scheme using global and local CNN features for near-duplicate image detection. In the coarse matching stage, we implement the sum-pooling operation on whole region of each image to extract global features and then match them between images. Since only a single global CNN feature is extracted from each image, the coarse matching stage can efficiently filter most of the irrelevant images of a given query image to narrow the search scope largely. In the fine matching stage, motivated by the attention-based image classification and facial expression recognition works [
48,
49,
51], we match the robust and stable local CNN features that are extracted from the regions surrounding the maximum values of CFMs and the saliency map generated by the graph-based visual saliency detection (GBVS) algorithm [
52]. Consequently, the proposed approach can effectively and efficiently detect near-duplicate images of a given query from image databases.
3. The Proposed Method
In this section, we introduce the proposed near-duplicate image detection approach in detail.
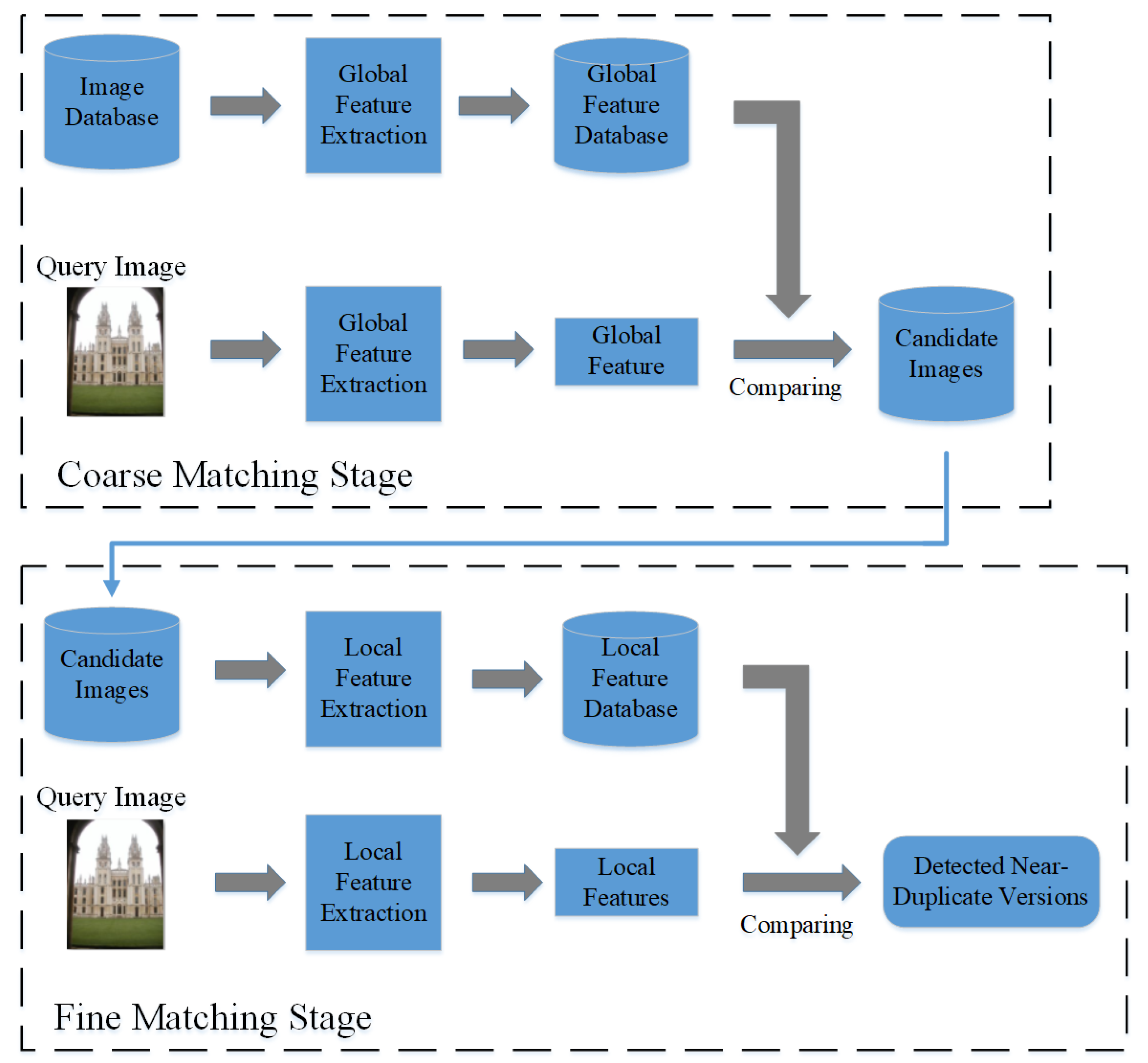
Figure 1 shows the framework of the proposed approach. As shown in
Figure 1, the proposed approach consists of two main components, which are the coarse matching stage and the fine matching stage, respectively.
We first generate convolutional feature maps (CFMs) by feeding images into a pre-trained CNN model. Then, in
Section 3.2, we extract global features from each image using sum-pooling operation and then match these features between images to obtain the candidate images of a given query from an image database. Finally, in
Section 3.3, local CNN features of the query image and candidate images are extracted and then matched to further detect the near-duplicate versions of the query. The details are given below.
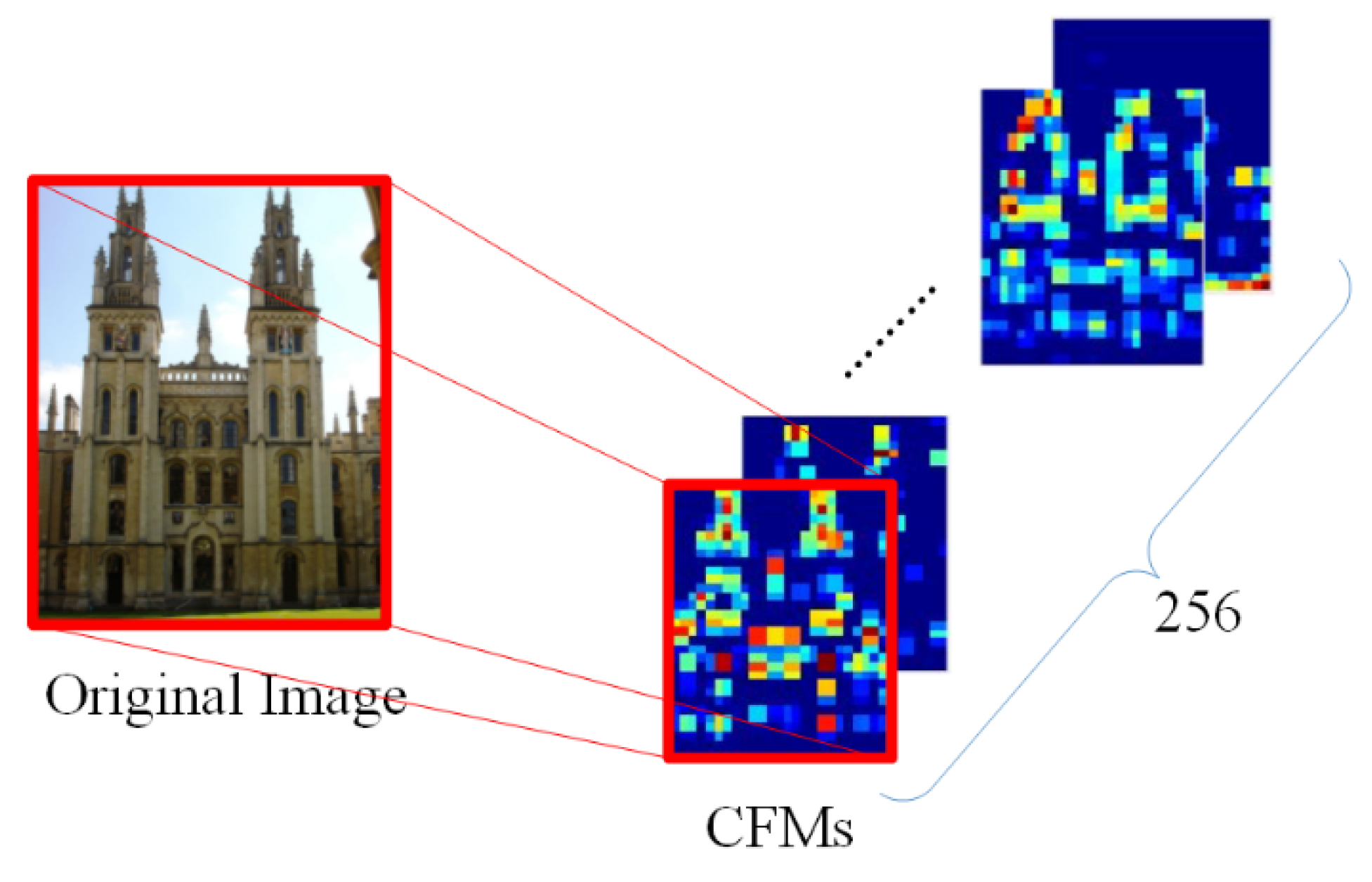
3.1. CFM Generation
According to [
25], a CNN model is composed of a set of layers including convolutional layers and fully connected layers. In the early years, researchers employed the outputs of fully connected layers to generate image representations. However, some research [
23,
24,
29,
44,
53] indicates that the features extracted from convolutional layers, especially the last convolutional layer, show better performance than the features extracted from fully connected layers, where the output of a convolutional layer is a set of feature maps, i.e., CFMs. In our approach, we feed each image to a pretrained CNN model, and use the output of the last convolutional layer for feature extraction. Note that we test the performances of our method when using different CNN models in the experimental part. To obtain a good trade-off between accuracy and efficiency, we adopt AlexNet [
25] as the pretrained CNN model in our method.
Figure 2 shows the 256 CFMs generated from the last convolutional layer after feeding an image into the AlexNet model, where the sizes of CFMs are proportional to the size of the original image.
3.2. Coarse Matching Stage
We will encounter the problem of high computational complexity if the local CNN features are directly extracted and matched between images to detect near-duplicate images from an image database, which usually consists of thousands of images. Due to the high efficiency of global feature extraction and matching, we first extract and match global features to implement a coarse feature matching to efficiently filter most irrelevant images of a given query.
3.2.1. The Extraction of Global CNN Feature
According to [
29], the global CNN features generated by sum-pooling of CFMs performs not only better than traditional hand-crafted features, but also better than those generated by max-pooling of CFMs. Thus, we adopt sum-pooling operation on the CFMs to extract the global features.
For a given image
, we feed it into the pretrained AlexNet model and collect the output of the fifth convolutional layer to form a set of CFMs, denoted as
, where
and
. For each CFM, i.e.,
, its size and activations are denoted as
W ×
H and
, respectively. Subsequently, we use Equation (1) to extract global features by sum-pooling operation:
After this, we concatenate all of these feature values to obtain a 256-dimensional feature vector , and normalize the feature vector as .
3.2.2. Global Feature Matching
For a given query image
and a database image
, we can obtain two corresponding normalized feature vectors
and
by the above feature extraction process. Then, we employ Equation (2) to compute the inner product of the two feature vectors to measure the global similarity between the two images.
After computing the similarity, we sort all similarity values in descending order , where and means the number of database images. In our method, we only keep detected images of the query as its candidate images, and remove the others.
3.3. Fine Matching Stage
Due to the weak robustness of global CNN features, the detection accuracy of the coarse matching stage is limited. Therefore, in the fine matching stage, we extract and match local features between images to further increase the detection accuracy. It is worth noting that, since only a small number of candidate images need to be verified to confirm whether they are the near-duplicate versions of the query, the efficiency of the fine matching is relatively high.
3.3.1. Central Cropping
Due to the fact that the target objects tend to be located near to the geometrical center of an image, we propose a central cropping strategy on CFMs to reduce the influence of irrelevant background before local feature extraction. As the feature extraction is based on CFMs, we implement the central cropping on the CFMs. In the cropping process, we make the sizes of the cropped CFMs proportional to the sizes of the original CFMs. Denote the ratio between the area of each cropped CFM and that of each original CFM as
. If the area of an original CFM is
, the area of a cropped CFM is
, where
. Thus, the width and height of the cropped CFM are
and
, respectively. To generate the cropped CFM, we set the coordinates of the central point of the cropped CFM by
Thus, the cropped CFM can be denoted as , which will be used for local region detection.
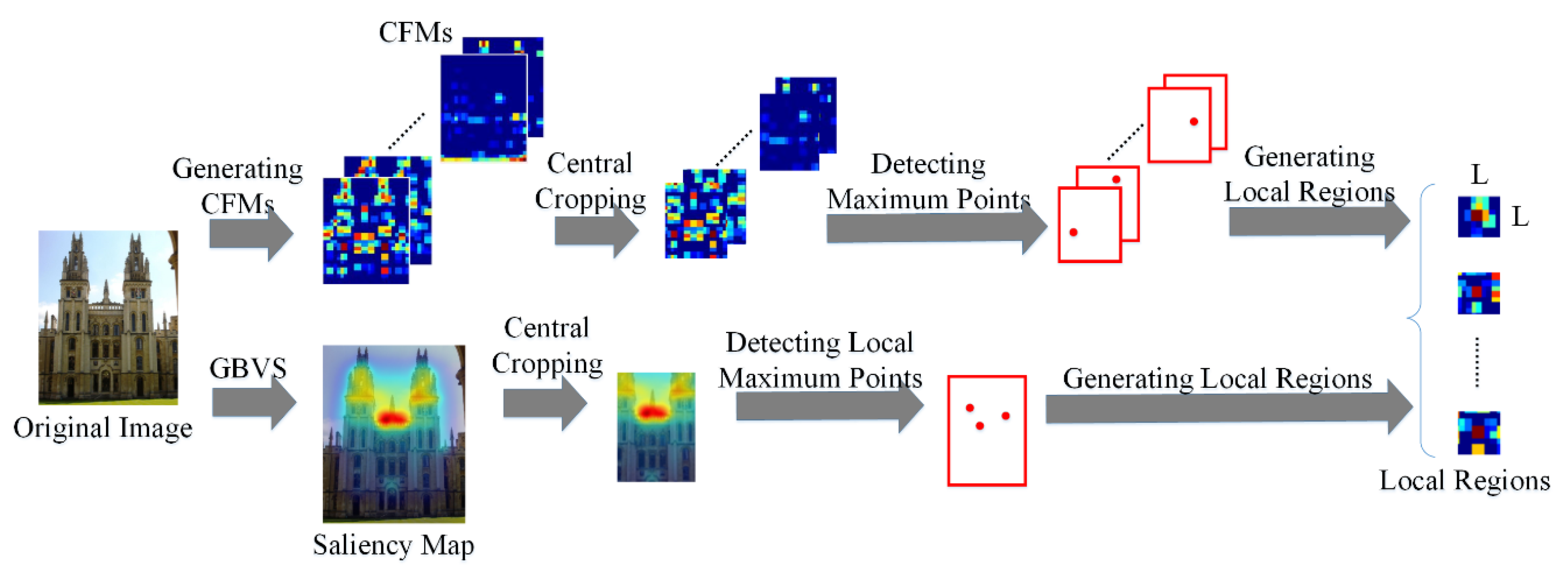
3.3.2. Local Region Detection
Since the maximum activations of a CFM are stable and their surrounding regions contain rich information, we detect the points with maximum activations, i.e., maximum points on the cropped CFMs, and then generate the regions surrounding these maximum points for local CNN feature extraction.
Figure 3 shows the flowchart of local region generation on cropped CFMs. For a CFM
, we select the maximum value among all the activations by
In addition, we generate the saliency map for local feature extraction. In our method, we generate the saliency map by the famous graph-based visual saliency detection (GBVS) algorithm [
52]. Then, we also apply central cropping on the saliency map, and detect the local maximum values of the saliency map, as illustrated in
Figure 3.
Next, by setting each detected point as a center, the patch surrounding the point is used as the local region, where the side length of the patch is denoted as . Suppose maximum points are generated from the CFMs in total. Thus, corresponding local regions are generated. To reduce storage memory and computational complexity in feature extraction and matching, we will not use all the regions generated from CFMs for feature extraction. Instead, we sort these regions in descending order according to the activation values of the corresponding maximum points, and select the first regions for local feature extraction. Since the number of local maximums of the saliency map is limited, we use all the regions generated from the saliency map for local feature extraction.
3.3.3. Local Features Extraction and Matching
After generating a set of local regions, we extract a 256-dimensional feature vector by sum-pooling the activations of CFMs within each local region rather than the whole image region, and then normalize it. Thus, for a given image
, we can extract a set of 256-dimensional normalized local feature vectors
, the number of which is denoted as
. Next, we match these local features between images. For a query image
and a candidate image
, by the above local feature extraction method, we can obtain their
256-dimensional local feature vectors, denoted as
and
, respectively. Then, we sequentially compare each pair of feature vectors to compute their similarity by inner products. By comparing a query feature vector
to each feature vector
in
, where
, we can obtain
similarity scores and then select the maximum score as the matching score of
.
Thus, there are
matching scores in total. Next, we sum up all the matching scores as the final similarity between the query image
and the candidate image
by Equation (6).
Finally, we compare the similarity score to a pre-set threshold to determine whether the candidate image is a near-duplicate version of the query .
4. Experiments
In this section, we first introduce the public datasets and the evaluation criteria used in our method. Second, for the three parameters of our method, i.e., the cropping ratio between areas of cropped CFMs and original CFMs, the maximum number of regions , and the side length of regions , we determine the parameter settings to achieve the optimal performance of our proposed method. Third, we measure the detection performance of the proposed method and compare it with those of its two versions, which separately use global CNN features or local CNN features, as well as the state-of-the-art features.
4.1. Datasets and Evaluation Criteria
In this experiment, we adopt three near-duplicate image detection datasets, i.e., the Oxford5k dataset [
54], the Holidays dataset [
55], and the Paris6k dataset [
56]. The Oxford5k dataset consists of 5062 pictures of Oxford buildings collected from the Flickr website. These images have been manually labeled as one of 11 different landmarks, each of which contains five query images. The Holidays dataset contains a total of 1491 pictures, which are divided into 500 groups. Each group of images contains a specific object or scene captured by different viewpoints. The first image of each group is used as the query image. The Paris6k dataset is composed of 6412 pictures of Paris buildings from the Flickr website. There are 500 query images in total. The above three public datasets are used to test the detection performance of different methods. We use the mAP value, which represents the average detection accuracy at different recall rates, to measure the detection accuracy. In addition, we adopt the average query time to test the detection efficiency.
4.2. Parameter Determination
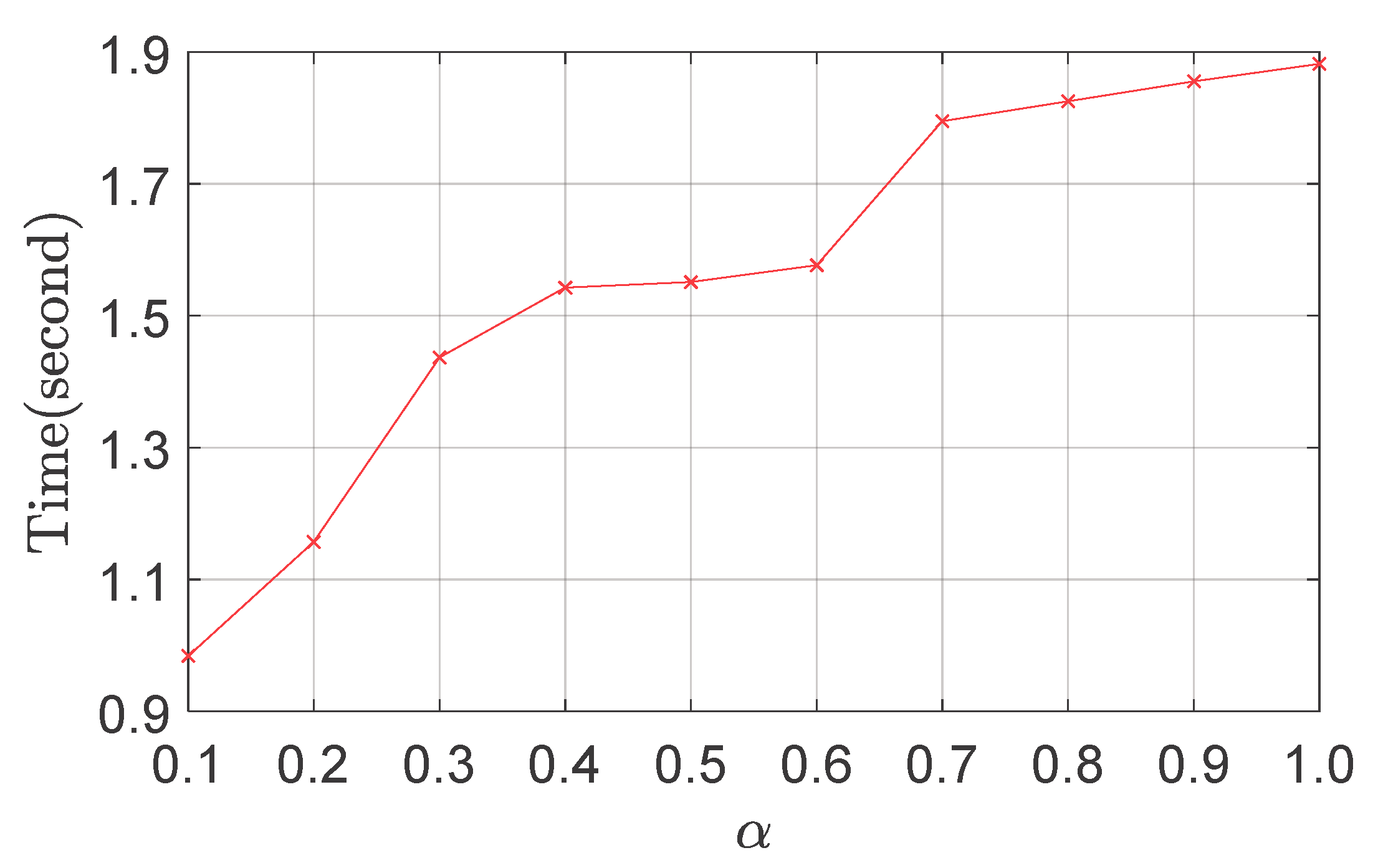
In this subsection, we observe the effects of the three parameters of the proposed method, and then find the proper parameter settings for the proposed method. The three important parameters are
,
and
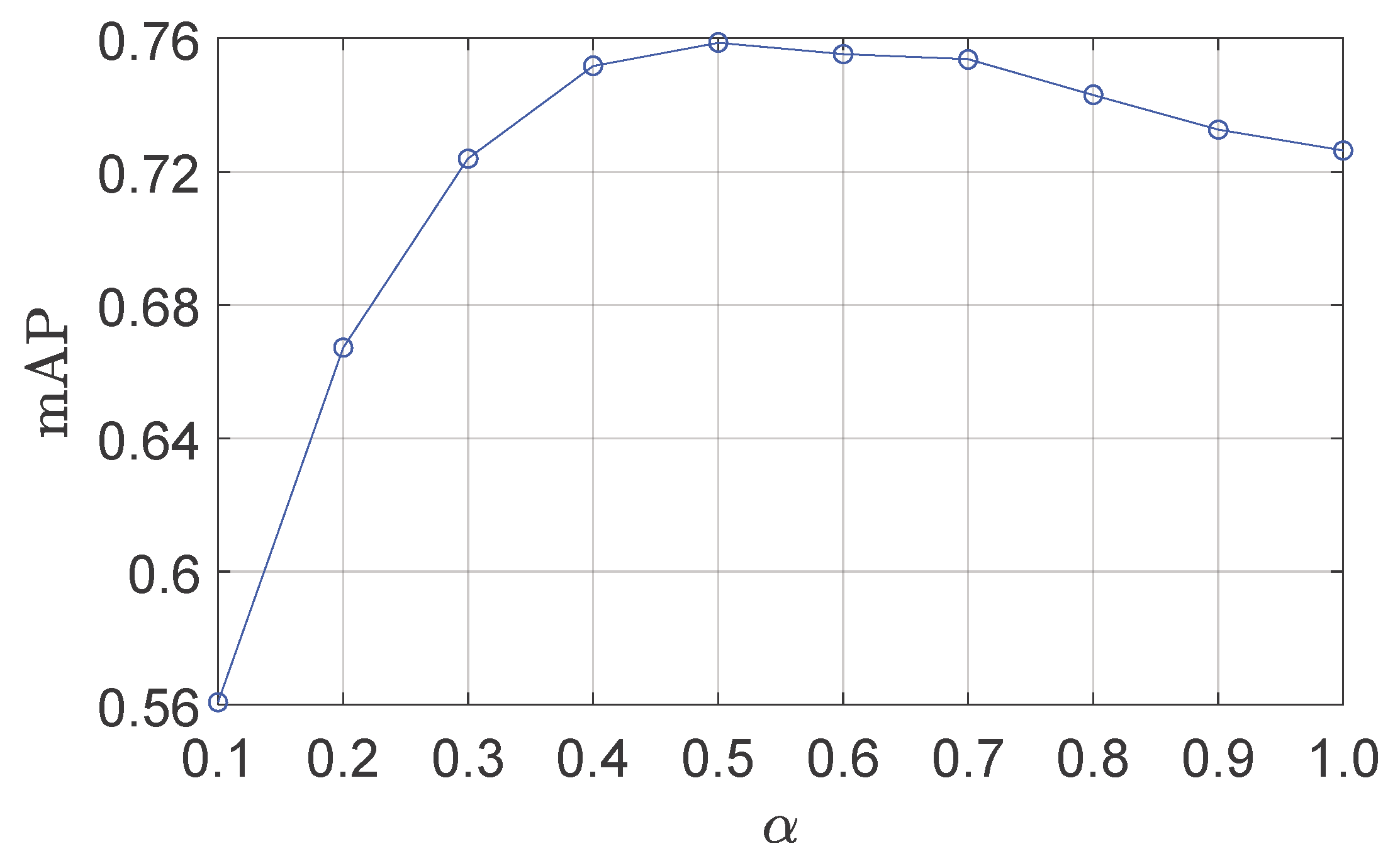
, representing the cropping ratio between areas of cropped CFMs and CFMs, the maximum number of regions, and the side length of regions, respectively. We implement the experiment on the Oxford5k dataset. We first fix parameters
and
to the default values, 3 and 100, respectively, to test the impact of the parameter
in the aspects of the accuracy and efficiency. The effects of
are illustrated in
Figure 4 and
Figure 5. From
Figure 4, we can clearly observe that a larger
is helpful for performance improvement, because larger cropped CFMs contain more crucial content. However, increasing
does not consistently improve the performance. This might be because larger cropped CFMs (
) also contain more irrelevant background clutter, which would introduce more noises in the image features. From
Figure 5, it is clear that the increase of
leads to the increase of detection time, because more features will be extracted from larger cropped CFMs. Therefore, to find a good trade-off between accuracy and efficiency, we set the parameter
as 0.5, which provides good accuracy and high efficiency.
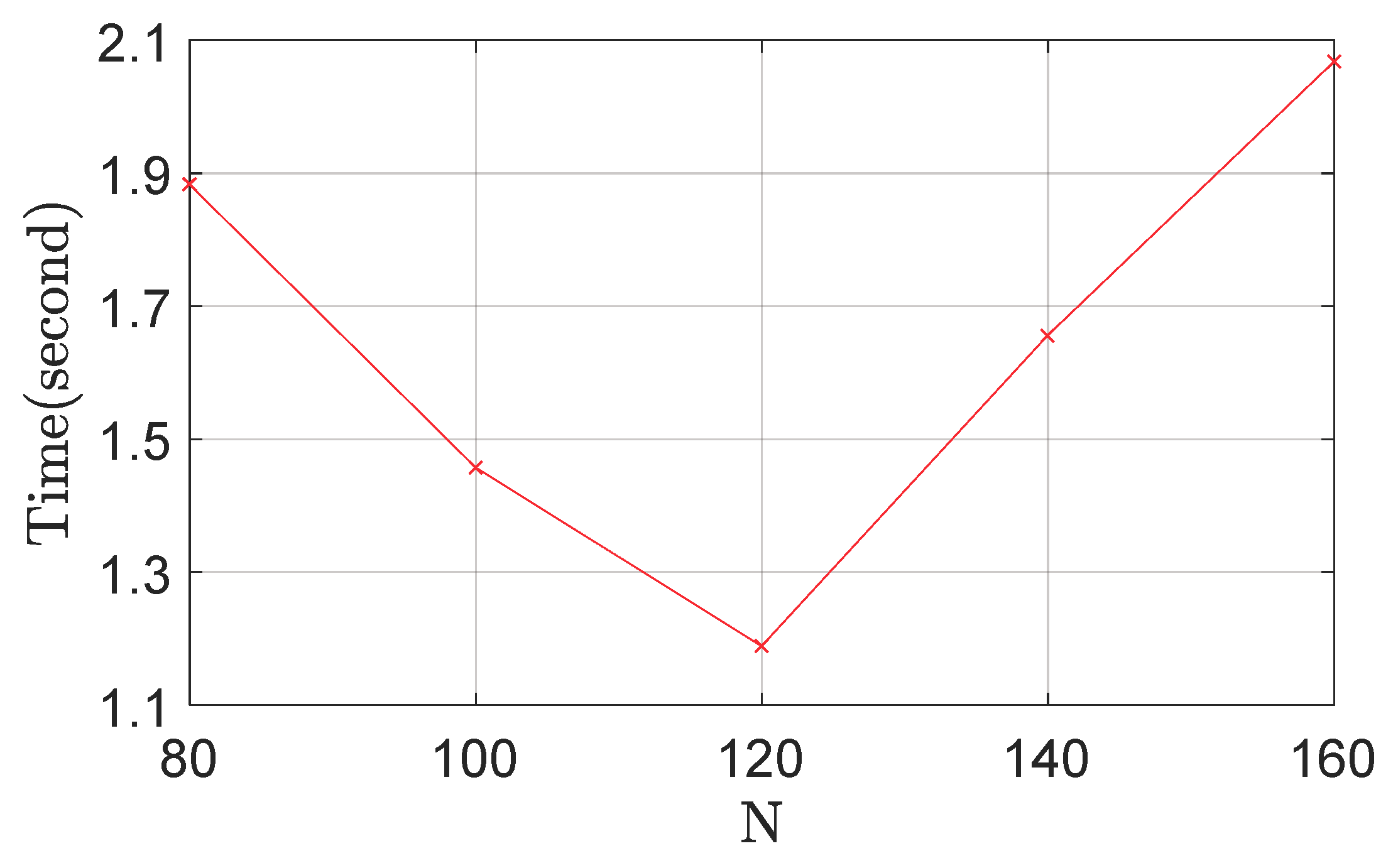
The effects of
on the detection accuracy and efficiency are illustrated in
Figure 6 and
Figure 7, respectively. It can be clearly observed that a larger
is helpful for performance improvement. However, when
is too large, it becomes very likely that many irrelevant local regions are used for feature extraction. Thus, we set the parameter
as 100 for the following experiments.
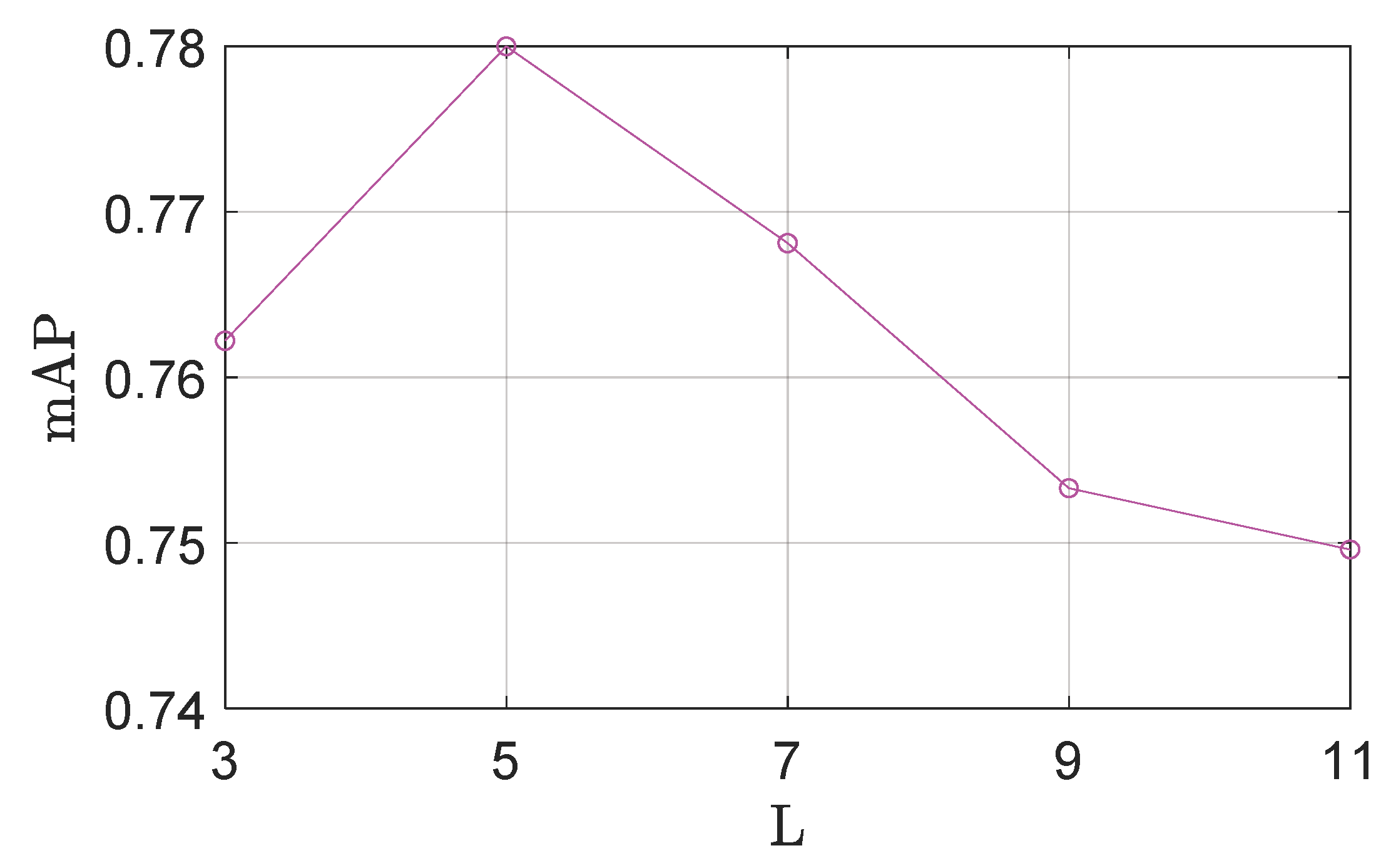
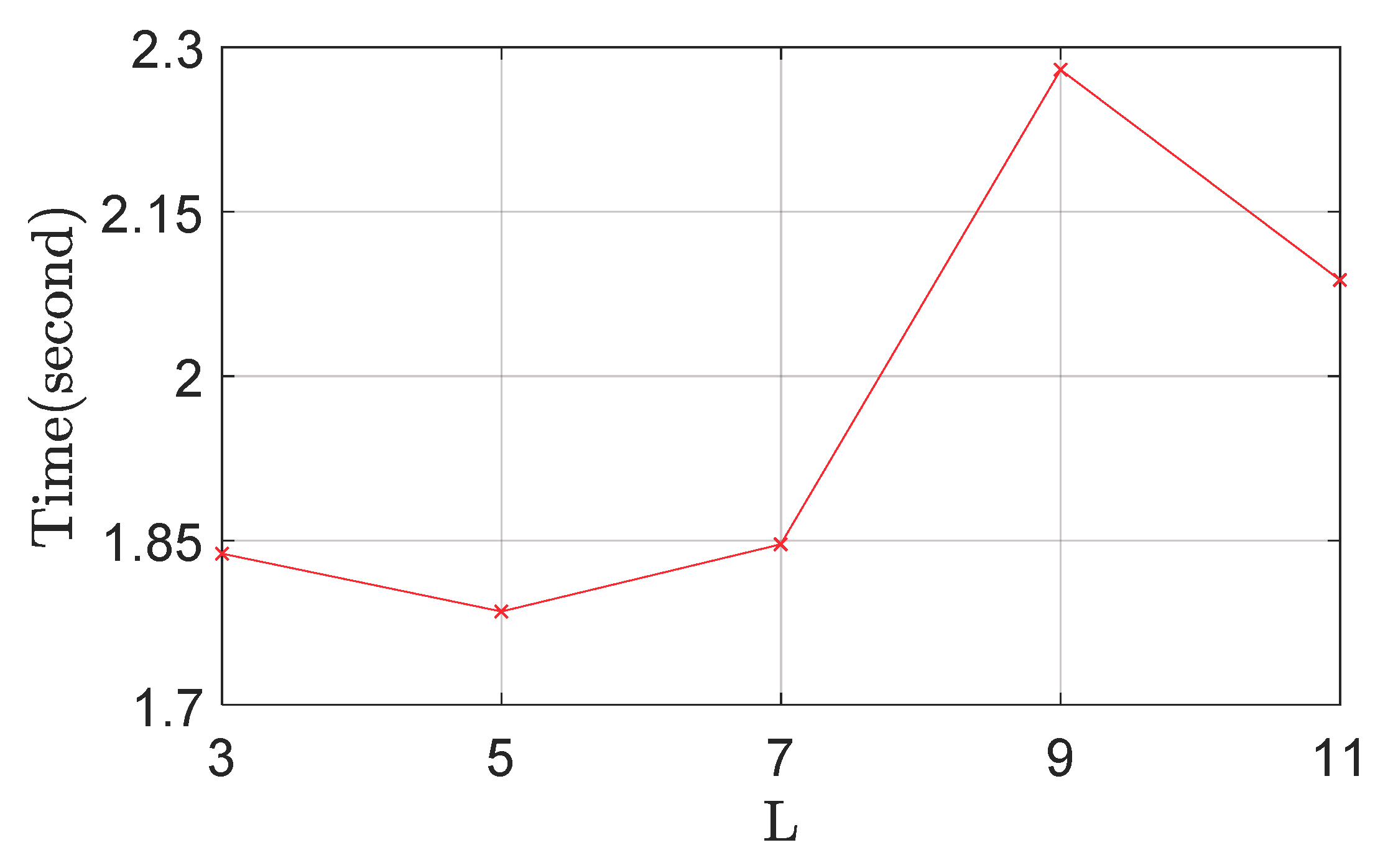
The effects of
are illustrated in
Figure 8 and
Figure 9. It is clear that the detection performance degrades if
is too large or too small. That is because a smaller
results in smaller local regions, which contain insufficient visual content; If the area of local regions is too large, these regions would be sensitive to background clutter and partial occlusion. To find a good trade-off between accuracy and efficiency, we set the value of
as five.
In the proposed method, we adopt the optimal settings of these three parameters, i.e., 0.5 for , 100 for and 5 for in the following experiments.
4.3. Performance When Using Different Pre-Trained Networks
In the experiments, we also test the performances of our method when using different kinds of pre-trained networks to observe their impacts on our method. We chose four famous convolutional neural networks including AlexNet [
25], VGG16 [
57], VGG19 [
57], and ResNet-18 [
58] to implement the test, where the last convolutional layers, or ReLu layers, of these networks are adopted.
Table 1 shows the mAP values and time costs of our method when using different pre-trained CNNs on Oxford5k dataset.
In
Table 1, it is clearly observed that the detection accuracy when using Vgg16, Vgg19, and ResNet-18 is slightly higher than that when using AlexNet. However, AlexNet leads to much higher time efficiency than the other networks, due to the fewer feature maps needed to be processed for feature extraction. Thus, to find a good trade-off between accuracy and efficiency, we chose AlexNet in our method.
4.4. Performance Comparison
After selecting the parameters, we use Oxford5k as the baseline dataset to compare the detection performances between our method and its two other versions in the aspects of detection accuracy, average time cost, and average memory consumption.
The two versions are the methods that separately use the extracted global CNN features or local CNN features. In
Table 2, the “global CNN features” and the “local CNN features” denote the methods using the extracted global CNN features and local CNN features, respectively. The “Time” means the average time cost for a query image, while the “Memory” represents the average memory required to store the features of an image.
As shown in
Table 2, the proposed method achieves a significant improvement in detection accuracy compared to the method only using global CNN features, and it has much higher detection efficiency compared to the method only using local CNN features. Moreover, since our method stores two types of CNN features, the memory consumption of the proposed method is higher than that of the two other methods. However, its total memory is slightly higher than that of the method using CNN local features, since the number of candidate images has been greatly reduced by the coarse feature matching. Additionally, the detection accuracy of the proposed method is comparable to that of the method only using local CNN features. That is because most of potential near-duplicate versions of a given query are kept by the coarse feature matching.
Also, we compare our method with five state-of-the-art methods: max-pooling [
18], VLAD-CNN [
24], SPoC [
29], R-MAC [
18], and CroW [
30].
Table 3 shows the mAP values of these methods on three different datasets. From
Table 3, it is clear that our method achieves higher detection accuracy than all of those methods on Oxford5k and Holidays. The detection accuracy of our method is only slightly lower than that of R-MAC on Paris6k. Overall, the proposed method generally outperforms these state-of-the-art methods.
Figure 10 shows some examples of detection results of the proposed method on Oxford5k. In summary, our method achieves high detection efficiency and meets real-time detection demand, while maintaining good accuracy in the task of near-duplicate image detection.
5. Conclusions
We presented a coarse-to-fine feature matching scheme using both global feature and local feature for near-duplicate image detection. By exploiting the advantages of both global and local CNN features, the proposed method can achieve real-time and accurate near-duplicate image detection. In the coarse matching stage, we extract global features to quickly filter most of the irrelevant images. In the following fine matching stage, we detect CFMs and use the saliency map to extract and match the proposed local CNN features to obtain the final detection results. The experimental results show our method achieves desirable performances in both accuracy and efficiency, which makes it appealing for practical applications of content-based image detection/retrieval tasks.
In our method, we directly use the pre-trained CNNs for near-duplicate image detection, but these CNNs are originally designed for image classification. Thus, it might be more effective to adopt the transfer learning methods to generate a fine-tuned CNN model for near-duplicate image detection. Additionally, the saliency map is generated by an unsupervised method to locate potential object regions for local feature extraction. In future work, we will study the supervised object recognition methods to accurately locate the object regions for local feature extraction to further improve the detection performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}