On q-Quasi-Newton’s Method for Unconstrained Multiobjective Optimization Problems



Abstract
1. Introduction
2. Preliminaries
3. The -Quasi-Newton Direction for Multiobjective
- 1.
- for all .
- 2.
- The conditions below are equivalent:
- (a)
- The point x is non stationary.
- (b)
- (c)
- .
- (d)
- is a descent direction.
- 3.
- The function ψ is continuous.
4. Algorithm and Convergence Analysis
| Algorithm 1q-Gradient Algorithm |
|
| Algorithm 2q-Quasi-Newton’s Algorithm for Unconstrained Multiobjective (q-QNUM) |
|
- (a)
- for all
- (b)
- for all with
- (c)
- for all ,
- (d)
- (e)
- (f)
- 1.
- 2.
- ,
- 3.
- 4.
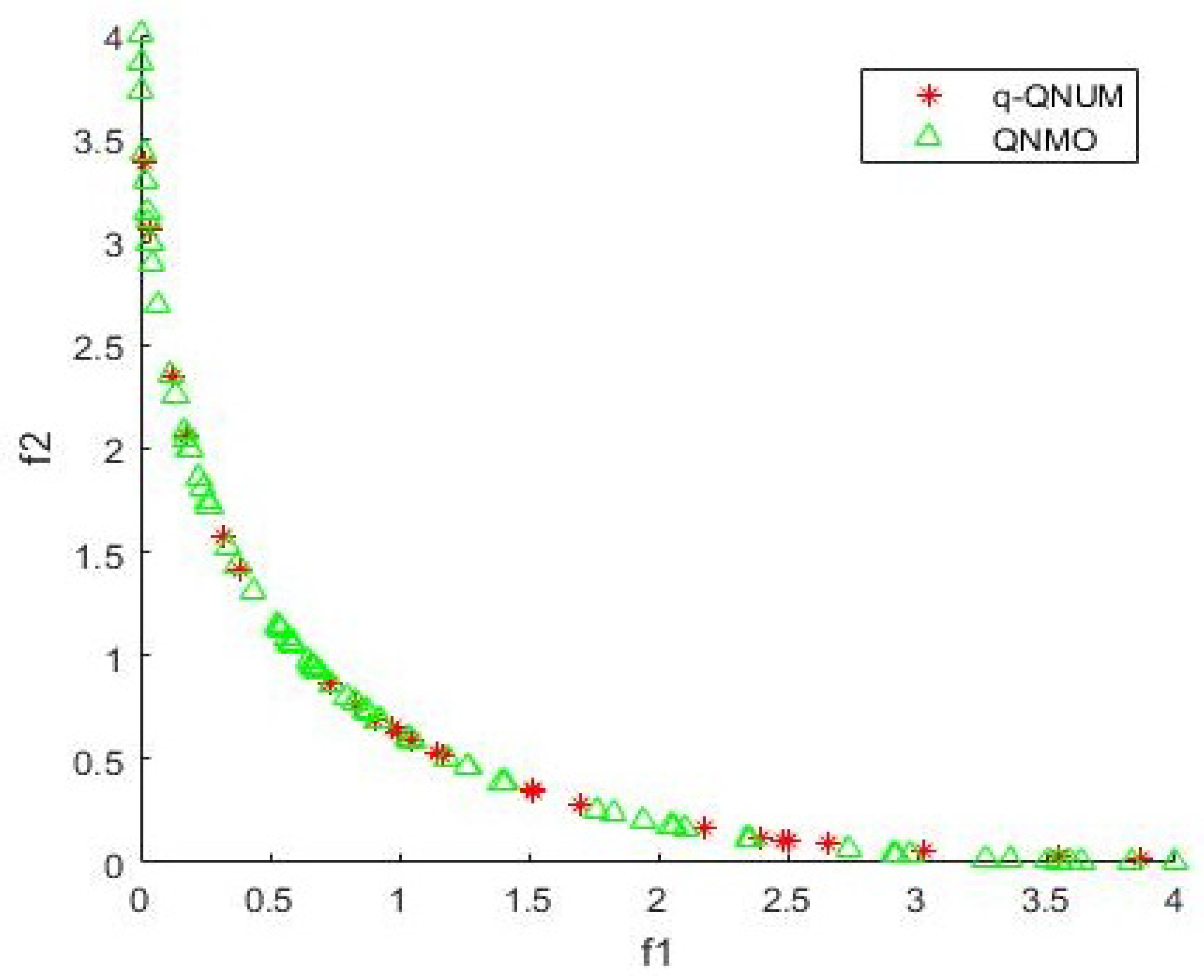
5. Numerical Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Eschenauer, H.; Koski, J.; Osyczka, A. Multicriteria Design Optimization: Procedures and Applications; Springer: Berlin, Germany, 1990. [Google Scholar]
- Haimes, Y.Y.; Hall, W.A.; Friedmann, H.T. Multiobjective Optimization in Water Resource Systems; Elsevier Scientific: Amsterdam, The Netherlands, 1975. [Google Scholar]
- Nwulu, N.I.; Xia, X. Multi-objective dynamic economic emission dispatch of electric power generation integrated with game theory based demand response programs. Energy Convers. Manag. 2015, 89, 963–974. [Google Scholar] [CrossRef]
- Badri, M.A.; Davis, D.L.; Davis, D.F.; Hollingsworth, J. A multi-objective course scheduling model: Combining faculty preferences for courses and times. Comput. Oper. Res. 1998, 25, 303–316. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nakashima, Y.; Nojima, Y. Performance evaluation of evolutionary multiobjective optimization algorithms for multiobjective fuzzy genetics-based machine learning. Soft Comput. 2011, 15, 2415–2434. [Google Scholar] [CrossRef]
- Liu, S.; Vicente, L.N. The stochastic multi-gradient algorithm for multi-objective optimization and its application to supervised machine learning. arXiv 2019, arXiv:1907.04472. [Google Scholar]
- Tavana, M. A subjective assessment of alternative mission architectures for the human exploration of mars at NASA using multicriteria decision making. Comput. Oper. Res. 2004, 31, 1147–1164. [Google Scholar] [CrossRef]
- Gass, S.; Saaty, T. The computational algorithm for the parametric objective function. Nav. Res. Logist. Q. 1955, 2, 39–45. [Google Scholar] [CrossRef]
- Miettinen, K. Nonlinear Multiobjective Optimization; Kluwer Academic: Boston, MA, USA, 1999. [Google Scholar]
- Fishbum, P.C. Lexicographic orders, utilities and decision rules: A survey. Manag. Sci. 1974, 20, 1442–1471. [Google Scholar] [CrossRef]
- Coello, C.A. An updated survey of GA-based multiobjective optimization techniques. ACM Comput. Surv. (CSUR) 2000, 32, 109–143. [Google Scholar] [CrossRef]
- Fliege, J.; Svaiter, B.F. Steepest descent method for multicriteria optimization. Math. Method. Oper. Res. 2000, 51, 479–494. [Google Scholar] [CrossRef]
- Drummond, L.M.G.; Iusem, A.N. A projected gradient method for vector optimization problems. Comput. Optim. Appl. 2004, 28, 5–29. [Google Scholar] [CrossRef]
- Drummond, L.M.G.; Svaiter, B.F. A steepest descent method for vector optimization. J. Comput. Appl. Math. 2005, 175, 395–414. [Google Scholar] [CrossRef]
- Branke, J.; Dev, K.; Miettinen, K.; Slowiński, R. (Eds.) Multiobjective Optimization: Interactive and Evolutionary Approaches; Springer: Berlin, Germany, 2008. [Google Scholar]
- Mishra, S.K.; Ram, B. Introduction to Unconstrained Optimization with R; Springer Nature: Singapore, 2019; pp. 175–209. [Google Scholar]
- Fliege, J.; Drummond, L.M.G.; Svaiter, B.F. Newton’s method for multiobjective optimization. SIAM J. Optim. 2009, 20, 602–626. [Google Scholar] [CrossRef]
- Chuong, T.D. Newton-like methods for efficient solutions in vector optimization. Comput. Optim. Appl. 2013, 54, 495–516. [Google Scholar] [CrossRef]
- Qu, S.; Liu, C.; Goh, M.; Li, Y.; Ji, Y. Nonsmooth Multiobjective Programming with Quasi-Newton Methods. Eur. J. Oper. Res. 2014, 235, 503–510. [Google Scholar] [CrossRef]
- Jiménez, M.A.; Garzón, G.R.; Lizana, A.R. (Eds.) Optimality Conditions in Vector Optimization; Bentham Science Publishers: Sharjah, UAE, 2010. [Google Scholar]
- Al-Saggaf, U.M.; Moinuddin, M.; Arif, M.; Zerguine, A. The q-least mean squares algorithm. Signal Process. 2015, 111, 50–60. [Google Scholar] [CrossRef]
- Aral, A.; Gupta, V.; Agarwal, R.P. Applications of q-Calculus in Operator Theory; Springer: New York, NY, USA, 2013. [Google Scholar]
- Rajković, P.M.; Marinković, S.D.; Stanković, M.S. Fractional integrals and derivatives in q-calculus. Appl. Anal. Discret. Math. 2007, 1, 311–323. [Google Scholar]
- Gauchman, H. Integral inequalities in q-calculus. Comput. Math. Appl. 2004, 47, 281–300. [Google Scholar] [CrossRef]
- Bangerezako, G. Variational q-calculus. J. Math. Anal. Appl. 2004, 289, 650–665. [Google Scholar] [CrossRef]
- Abreu, L. A q-sampling theorem related to the q-Hankel transform. Proc. Am. Math. Soc. 2005, 133, 1197–1203. [Google Scholar] [CrossRef]
- Koornwinder, T.H.; Swarttouw, R.F. On q-analogues of the Fourier and Hankel transforms. Trans. Am. Math. Soc. 1992, 333, 445–461. [Google Scholar]
- Ernst, T. A Comprehensive Treatment of q-Calculus; Springer: Basel, Switzerland; Heidelberg, Germany; New York, NY, USA; Dordrecht, The Netherlands; London, UK, 2012. [Google Scholar]
- Noor, M.A.; Awan, M.U.; Noor, K.I. Some quantum estimates for Hermite-Hadamard inequalities. Appl. Math. Comput. 2015, 251, 675–679. [Google Scholar] [CrossRef]
- Pearce, C.E.M.; Pec̆arić, J. Inequalities for differentiable mappings with application to special means and quadrature formulae. Appl. Math. Lett. 2000, 13, 51–55. [Google Scholar] [CrossRef]
- Ernst, T. A Method for q-Calculus. J. Nonl. Math. Phys. 2003, 10, 487–525. [Google Scholar] [CrossRef]
- Sterroni, A.C.; Galski, R.L.; Ramos, F.M. The q-gradient vector for unconstrained continuous optimization problems. In Operations Research Proceedings; Hu, B., Morasch, K., Pickl, S., Siegle, M., Eds.; Springer: Heidelberg, Germany, 2010; pp. 365–370. [Google Scholar]
- Gouvêa, E.J.C.; Regis, R.G.; Soterroni, A.C.; Scarabello, M.C.; Ramos, F.M. Global optimization using q-gradients. Eur. J. Oper. Res. 2016, 251, 727–738. [Google Scholar] [CrossRef]
- Chakraborty, S.K.; Panda, G. Newton like line search method using q-calculus. In International Conference on Mathematics and Computing. Communications in Computer and Information Science; Giri, D., Mohapatra, R.N., Begehr, H., Obaidat, M., Eds.; Springer: Singapore, 2017; Volume 655, pp. 196–208. [Google Scholar]
- Mishra, S.K.; Panda, G.; Ansary, M.A.T.; Ram, B. On q-Newton’s method for unconstrained multiobjective optimization problems. J. Appl. Math. Comput. 2020. [Google Scholar] [CrossRef]
- Jackson, F.H. On q-functions and a certain difference operator. Earth Environ. Sci. Trans. R. Soc. Edinb. 1908, 46, 253–281. [Google Scholar] [CrossRef]
- Bento, G.C.; Neto, J.C. A subgradient method for multiobjective optimization on Riemannian manifolds. J. Optimiz. Theory App. 2013, 159, 125–137. [Google Scholar] [CrossRef]
- Andrei, N. A diagonal quasi-Newton updating method for unconstrained optimization. Numer. Algorithms 2019, 81, 575–590. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2006. [Google Scholar]
- Povalej, Z. Quasi-Newton’s method for multiobjective optimization. J. Comput. Appl. Math. 2014, 255, 765–777. [Google Scholar] [CrossRef]
- Ye, Y.L. D-invexity and optimality conditions. J. Math. Anal. Appl. 1991, 162, 242–249. [Google Scholar] [CrossRef]
- Morovati, V.; Basirzadeh, H.; Pourkarimi, L. Quasi-Newton methods for multiobjective optimization problems. 4OR-Q. J. Oper. Res. 2018, 16, 261–294. [Google Scholar] [CrossRef]
- Samei, M.E.; Ranjbar, G.K.; Hedayati, V. Existence of solutions for equations and inclusions of multiterm fractional q-integro-differential with nonseparated and initial boundary conditions. J. Inequal Appl. 2019, 273. [Google Scholar] [CrossRef]
- Adams, C.R. The general theory of a class of linear partial difference equations. Trans. Am. Math.Soc. 1924, 26, 183–312. [Google Scholar]
- Sefrioui, M.; Perlaux, J. Nash genetic algorithms: Examples and applications. In Proceedings of the 2000 Congress on Evolutionary Computation, La Jolla, CA, USA, 16–19 July 2000; Volume 1, pp. 509–516. [Google Scholar]
- Huband, S.; Hingston, P.; Barone, L.; While, L. A review of multiobjective test problems and a scalable test problem toolkit. IEEE T. Evolut. Comput. 2006, 10, 477–506. [Google Scholar] [CrossRef]
- Ikeda, K.; Kita, H.; Kobayashi, S. Failure of Pareto-based MOEAs: Does non-dominated really mean near to optimal? In Proceedings of the 2001 Congress on Evolutionary Computation, Seoul, Korea, 27–30 May 2001; Volume 2, pp. 957–962. [Google Scholar]
- Shim, M.B.; Suh, M.W.; Furukawa, T.; Yagawa, G.; Yoshimura, S. Pareto-based continuous evolutionary algorithms for multiobjective optimization. Eng Comput. 2002, 19, 22–48. [Google Scholar] [CrossRef]
- Valenzuela-Rendón, M.; Uresti-Charre, E.; Monterrey, I. A non-generational genetic algorithm for multiobjective optimization. In Proceedings of the Seventh International Conference on Genetic Algorithms, East Lansing, MI, USA, 19–23 July 1997; pp. 658–665. [Google Scholar]
- Vlennet, R.; Fonteix, C.; Marc, I. Multicriteria optimization using a genetic algorithm for determining a Pareto set. Int. J. Syst. Sci. 1996, 27, 255–260. [Google Scholar] [CrossRef]


{kind=link}
| Problem | Source | [lb,ub] | (q-QNUM) | (QNMO) | ||||
|---|---|---|---|---|---|---|---|---|
| BK1 | [46] | [−5, 10] | 200 | 200 | 200 | 200 | 200 | 200 |
| MOP5 | [46] | [−30, 30] | 141 | 965 | 612 | 333 | 518 | 479 |
| MOP6 | [46] | [0, 1] | 250 | 2177 | 1712 | 181 | 2008 | 2001 |
| MOP7 | [46] | [−400, 400] | 200 | 200 | 200 | 751 | 1061 | 1060 |
| DG01 | [47] | [−10, 13] | 175 | 724 | 724 | 164 | 890 | 890 |
| IKK1 | [47] | [−50, 50] | 170 | 170 | 170 | 253 | 254 | 253 |
| SP1 | [45] | [−3, 2] | 200 | 200 | 200 | 525 | 706 | 706 |
| SSFYY1 | [45] | [−2, 2] | 200 | 200 | 200 | 200 | 300 | 300 |
| SSFYY2 | [45] | [−100, 100] | 263 | 277 | 277 | 263 | 413 | 413 |
| SK1 | [48] | [−10, 10] | 139 | 1152 | 1152 | 87 | 732 | 791 |
| SK2 | [48] | [−3, 11] | 154 | 1741 | 1320 | 804 | 1989 | 1829 |
| VU1 | [49] | [−3, 3] | 316 | 1108 | 1108 | 11,361 | 19,521 | 11,777 |
| VU2 | [49] | [−3, 7] | 99 | 1882 | 1882 | 100 | 1900 | 1900 |
| VFM1 | [50] | [−2, 2] | 195 | 195 | 195 | 195 | 290 | 290 |
| VFM2 | [50] | [−4, 4] | 200 | 200 | 200 | 524 | 693 | 678 |
| VFM3 | [50] | [−3, 3] | 161 | 1130 | 601 | 690 | 1002 | 981 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, K.K.; Mishra, S.K.; Ram, B. On q-Quasi-Newton’s Method for Unconstrained Multiobjective Optimization Problems. Mathematics 2020, 8, 616. https://doi.org/10.3390/math8040616
Lai KK, Mishra SK, Ram B. On q-Quasi-Newton’s Method for Unconstrained Multiobjective Optimization Problems. Mathematics. 2020; 8(4):616. https://doi.org/10.3390/math8040616
Chicago/Turabian StyleLai, Kin Keung, Shashi Kant Mishra, and Bhagwat Ram. 2020. "On q-Quasi-Newton’s Method for Unconstrained Multiobjective Optimization Problems" Mathematics 8, no. 4: 616. https://doi.org/10.3390/math8040616
APA StyleLai, K. K., Mishra, S. K., & Ram, B. (2020). On q-Quasi-Newton’s Method for Unconstrained Multiobjective Optimization Problems. Mathematics, 8(4), 616. https://doi.org/10.3390/math8040616