On the Use of Probabilistic Worst-Case Execution Time Estimation for Parallel Applications in High Performance Systems

 , , , , and
, , , , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Motivation
1.2. Contribution
- Contribution 1: Exploration of execution conditions. We integrate a software randomization layer in the geophysical exploration application to test its susceptibility to memory layouts caused by different code, heap and stack allocations. This contribution is provided in Section 2.
- Contribution 2: Worst-Case Execution Time (WCET) analysis. We analyze and fit an MBPTA technique for WCET prediction so that it can be used in the context of HPC applications running on high-performance systems. This contribution is provided in Section 3.
- Contribution 3: Evaluation and scalability. We evaluate those techniques on the geophysical exploration application, proving their viability to study its (high) execution time behavior, and showing that appropriate integration of those techniques allows scaling the application to the use of parallel paradigms, thus beyond the execution conditions considered in embedded systems. This contribution is provided in Section 4.
2. Execution Time Test Coverage Improvement for HPC
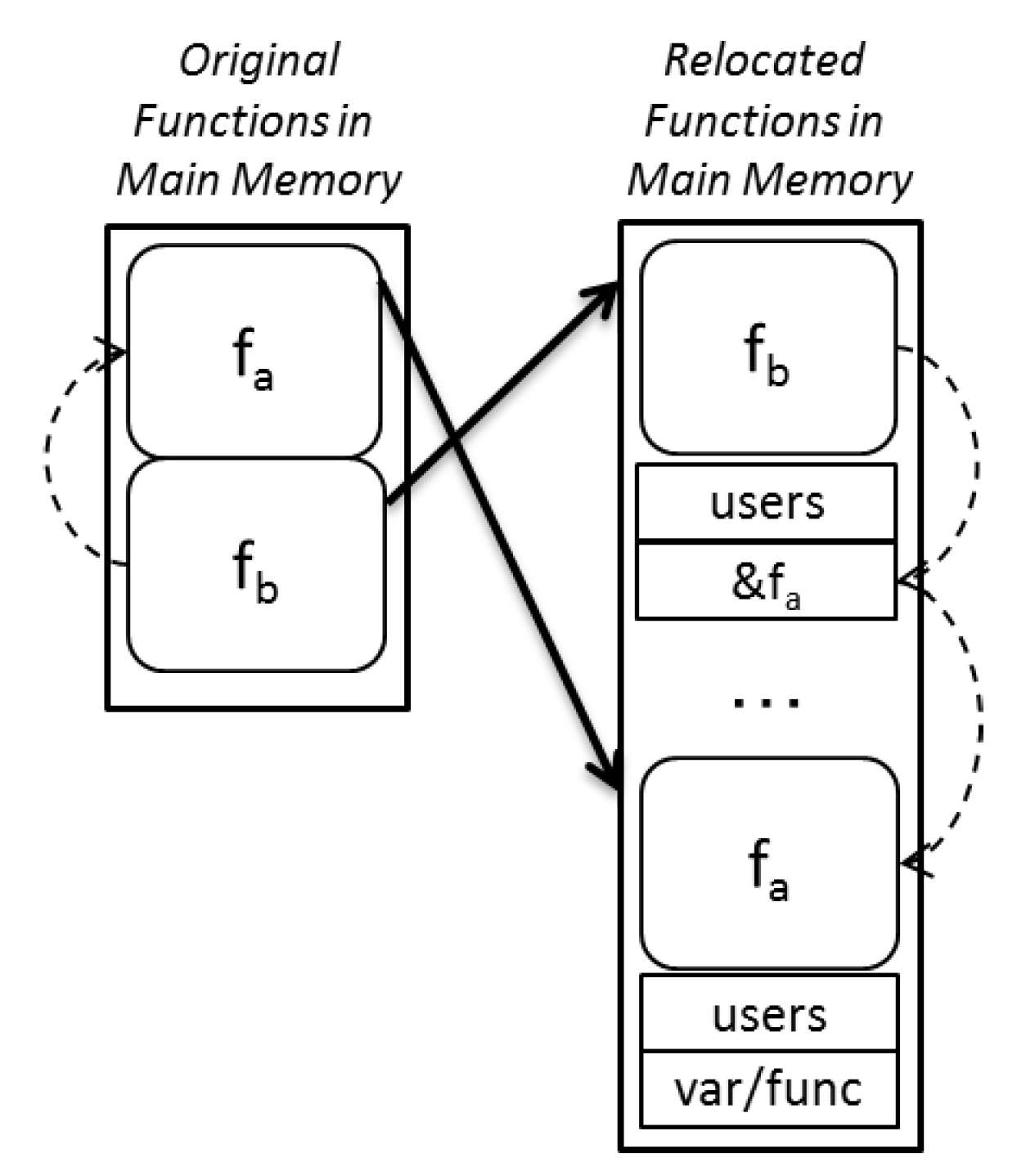
2.1. Memory-Placement Software Randomization
2.2. Code Randomization
2.3. Stack Randomization
2.4. Heap Randomization
2.5. Summary
3. Measurement-Based Probabilistic Timing Analysis for HPC
3.1. MBPTA-CV Fundamentals
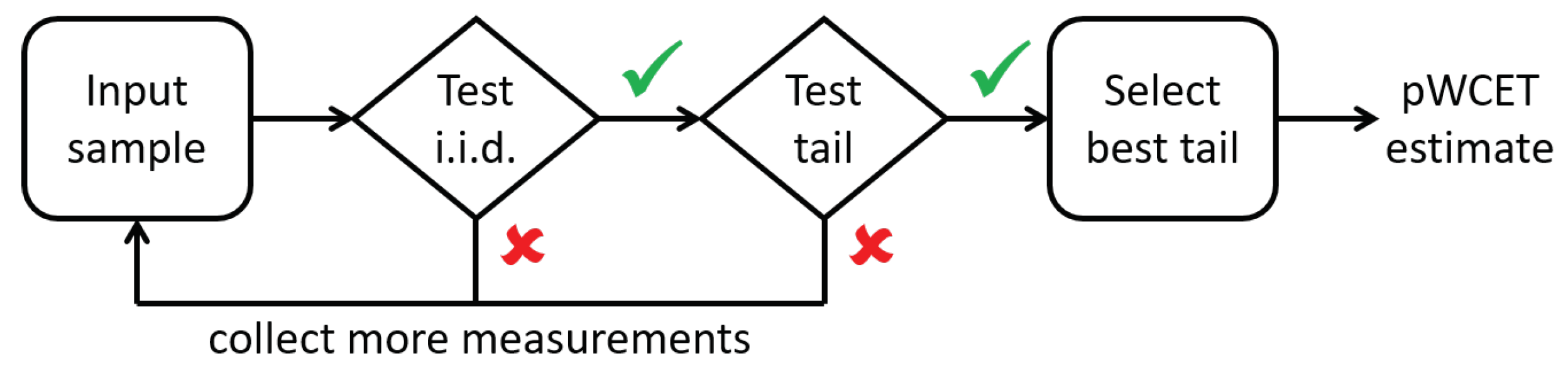
3.2. MBPTA-CV Steps
Input Sample Generation
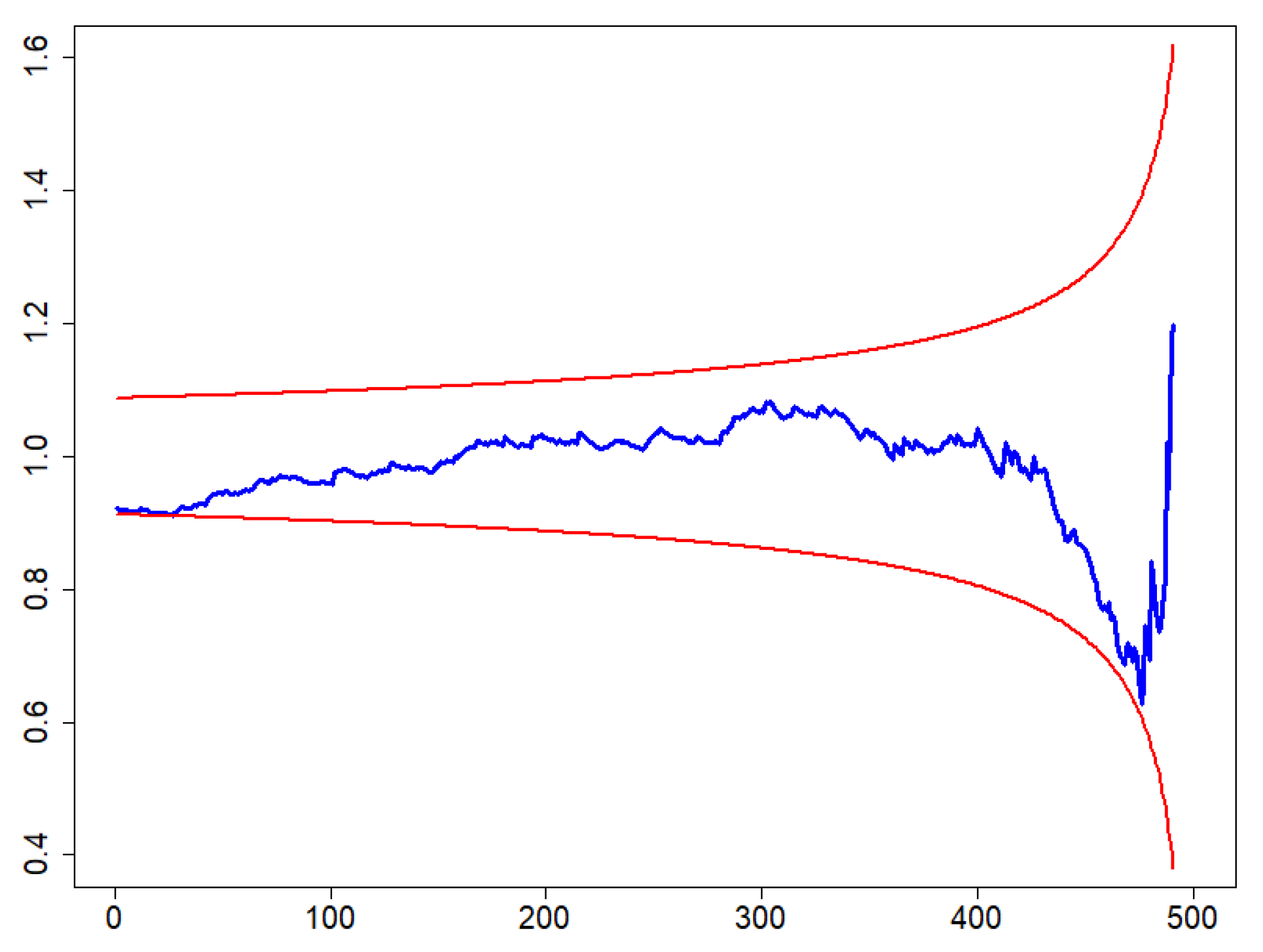
3.3. Independence and Identical Distribution
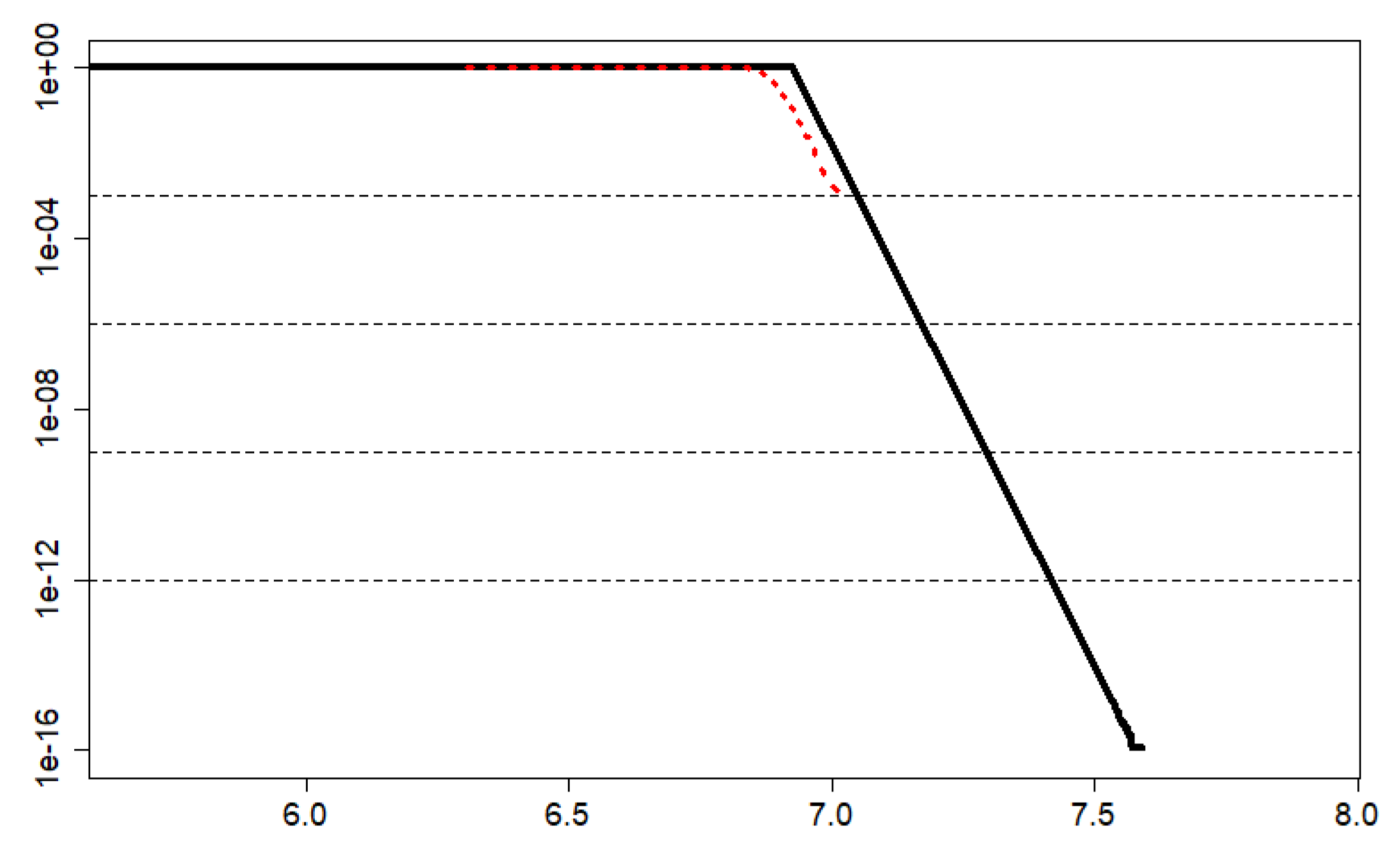
3.3.1. Exponential Tail Test
3.3.2. Select the Best Tail
3.3.3. pWCET Estimate
3.4. Summary
4. Evaluation
4.1. Case study
- Pre-processing: data is read from disk and several checks are performed to ensure that the subsequent processing is valid.
- Main processing: composed essentially by a frequency loop, the goal of this phase is to iteratively obtain the real value of a given variable (or a set of variables) from an initial guess. To do this, the signal of the input sources and the received data is bandpass-filtered to the frequency of interest by means of an adjoint-state method. The input model is modified to that with the smallest error. Once this has been achieved, another frequency is considered.
- Post-processing: the objective of this phase is to ensure that the numerical values of the generated output are quantitatively correct. Also, it holds all the specific routines to adapt the data to the output expected by the user (interpolation, file formats, etc.).
4.2. Experimental Framework
- Be representative of real problems.
- Deliver execution times no less than hundreds of milliseconds, as explained before, for a reliable application of MBPTA-CV despite OS noise.
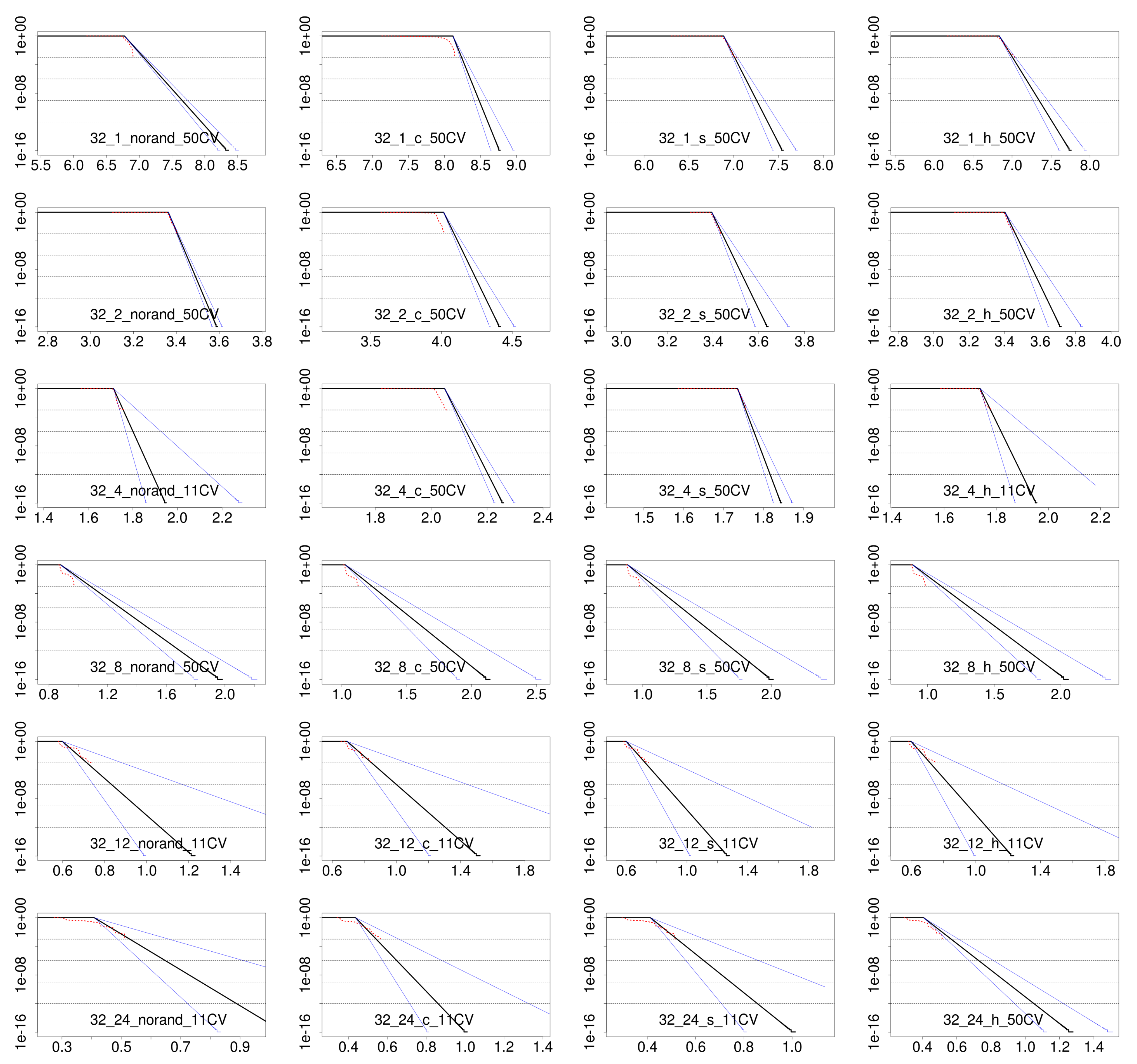
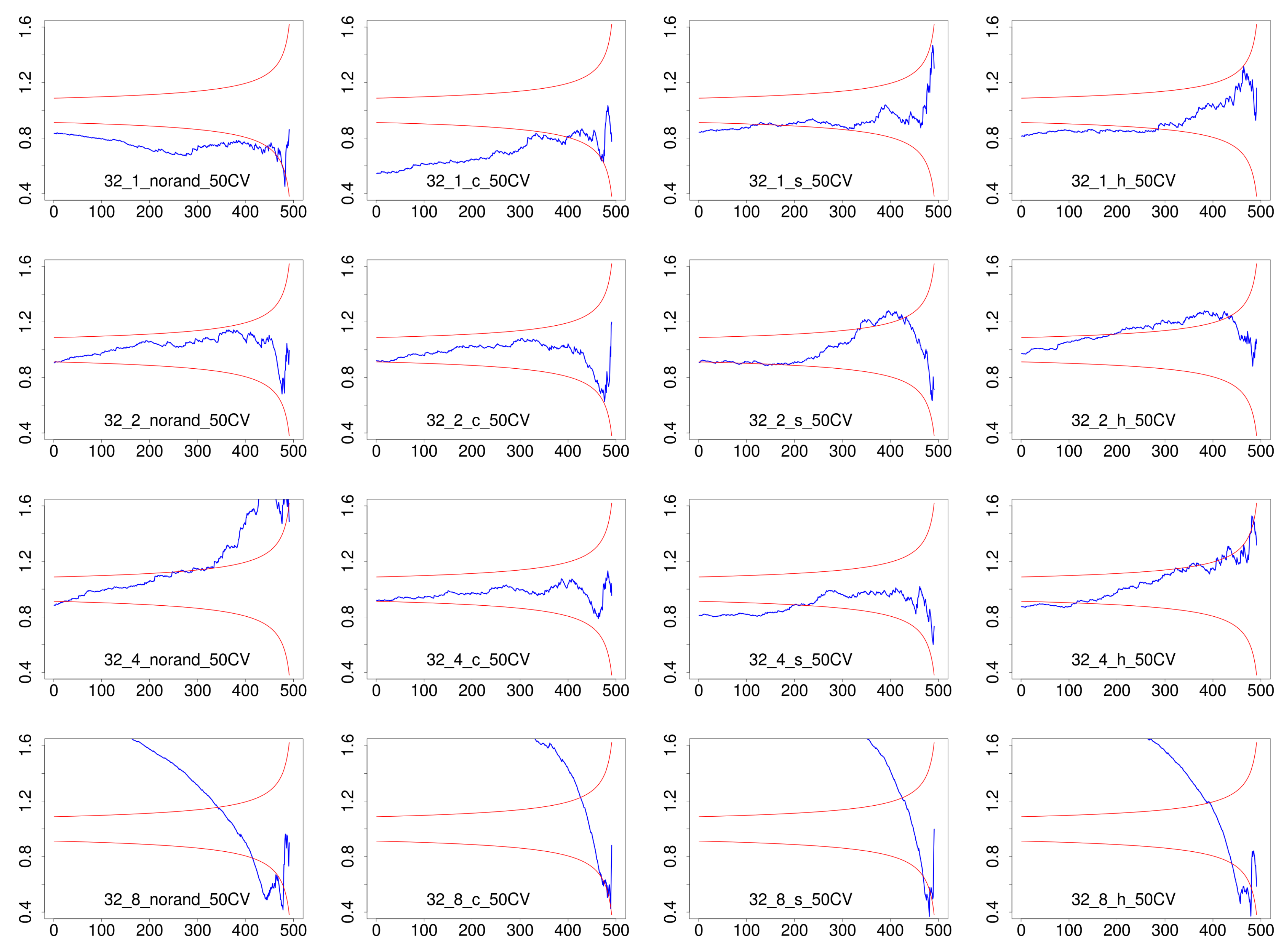
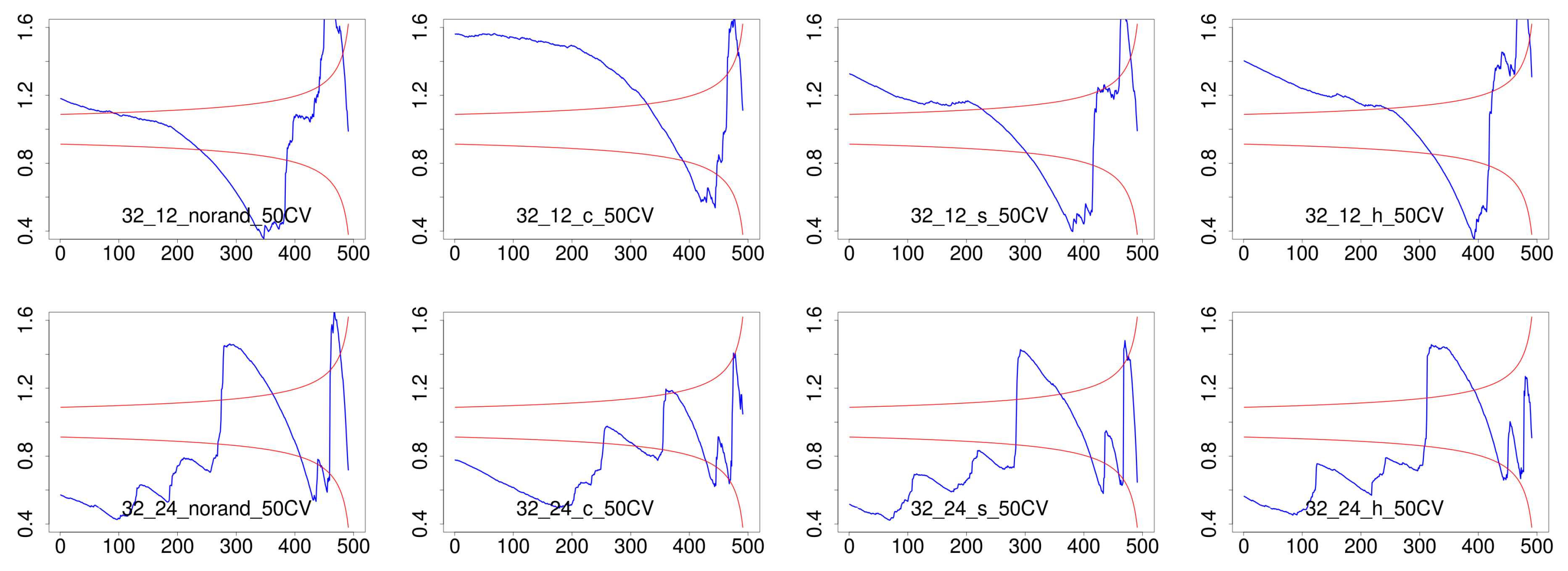
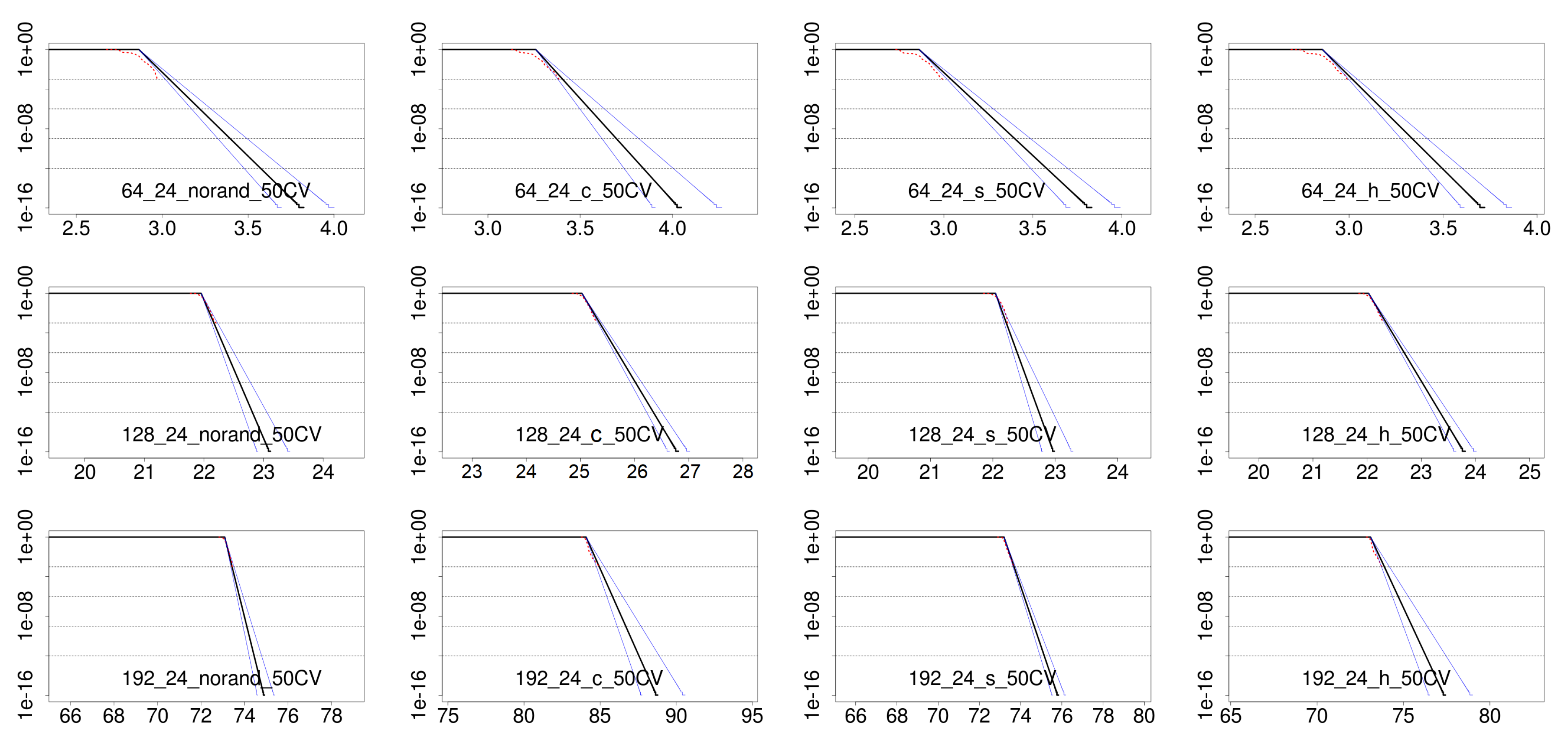
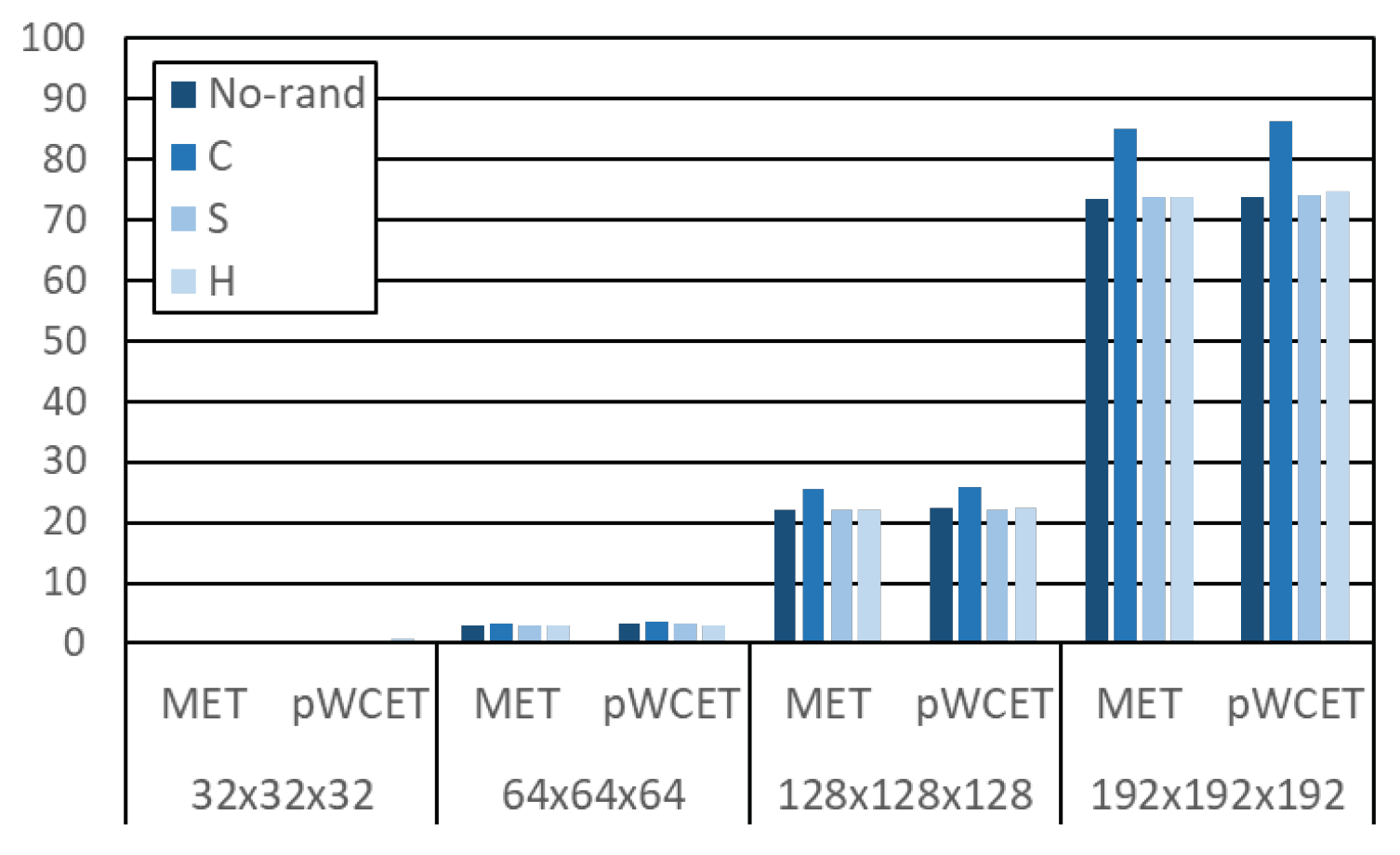
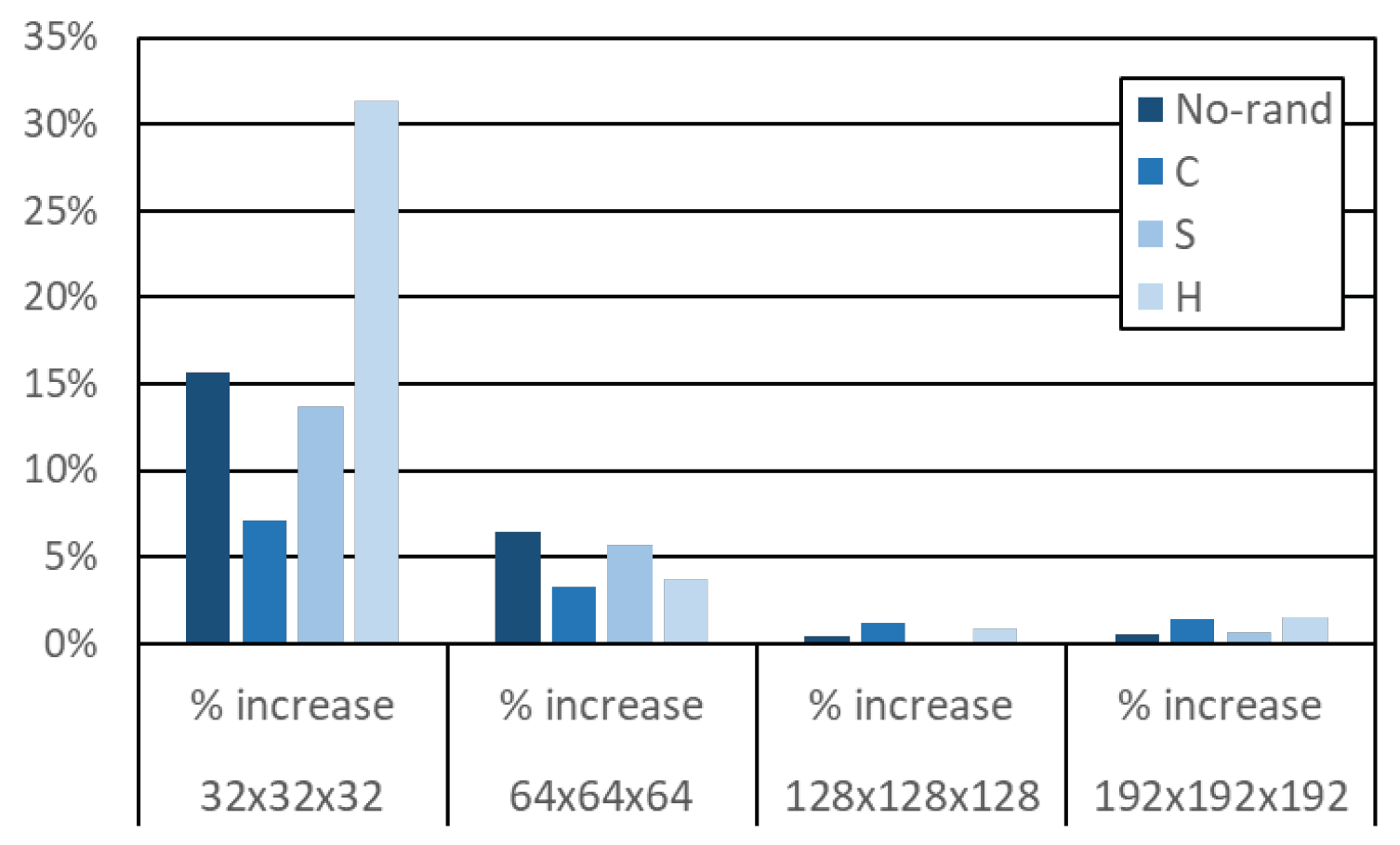
4.3. Results
5. Related Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| EVT | Extreme Value Theory |
| HPC | High-Performance Computing |
| MBPTA-CV | Measurement-Based Probabilistic Timing Analysis using the Coefficient of Variation |
| pWCET | probabilistic Worst-Case Execution Time |
| WCET | Worst-Case Execution Time |
References
- Agosta, G.; Fornaciari, W.; Massari, G.; Pupykina, A.; Reghenzani, F.; Zanella, M. Managing Heterogeneous Resources in HPC Systems. In Proceedings of the 9th Workshop and 7th Workshop on Parallel Programming and RunTime Management Techniques for Manycore Architectures and Design Tools and Architectures for Multicore Embedded Computing Platforms, Manchester, UK, 23 January 2018; pp. 7–12. [Google Scholar]
- Flich, J.; Agosta, G.; Ampletzer, P.; Alonso, D.A.; Brandolese, C.; Cilardo, A.; Fornaciari, W.; Hoornenborg, Y.; Kovac, M.; Maitre, B.; et al. Enabling HPC for QoS-sensitive applications: The MANGO approach. In Proceedings of the 2016 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 702–707. [Google Scholar]
- Flich, J.; Agosta, G.; Ampletzerm, P.; Alonso, D.A.; Brandolese, C.; Cappe, E.; Cilardo, A.; Dragić, L.; Dray, A.; Duspara, A.; et al. Exploring manycore architectures for next-generation HPC systems through the MANGO approach. Microprocess. Microsyst. 2018, 61, 154–170. [Google Scholar] [CrossRef]
- Massari, G.; Pupykina, A.; Agosta, G.; Fornaciari, W. Predictive Resource Management for Next-generation High-Performance Computing Heterogeneous Platforms. In Proceedings of the 18th International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS’19), Samos, Greece, 7–11 July 2019. [Google Scholar]
- Pupykina, A.; Agosta, G. Optimizing Memory Management in Deeply Heterogeneous HPC Accelerators. In Proceedings of the 2017 46th International Conference on Parallel Processing Workshops (ICPPW), Bristol, UK, 14–17 August 2017; pp. 291–300. [Google Scholar]
- Mezzetti, E.; Vardanega, T. On the industrial fitness of wcet analysis. In Proceedings of the 11th International Workshop on Worst-Case Execution-Time Analysis, Porto, Portugal, 5 July 2011. [Google Scholar]
- Wilhelm, R.; Engblom, J.; Ermedahl, A.; Holsti, N.; Thesing, S.; Whalley, D.; Bernat, G.; Ferdinand, C.; Heckmann, R.; Mitra, T.; et al. The worst-case execution time problem: Overview of methods and survey of tools. ACM TECS 2008, 7, 1–53. [Google Scholar] [CrossRef]
- Abella, J.; Hernandez, C.; Quiñones, E.; Cazorla, F.J.; Conmy, P.R.; Azkarate-askasua, M.; Perez, J.; Mezzetti, E.; Vardanega, T. WCET Analysis Methods: Pitfalls and Challenges on their Trustworthiness. In Proceedings of the 10th IEEE International Symposium on Industrial Embedded Systems (SIES), Siegen, Germany, 8–10 June 2015. [Google Scholar]
- Bernat, G.; Colin, A.; Petters, S. WCET analysis of probabilistic hard real-time systems. In Proceedings of the 23rd IEEE Real-Time Systems Symposium, Austin, TX, USA, 3–5 December 2002. [Google Scholar]
- Cazorla, F.J.; Quiñones, E.; Vardanega, T.; Cucu, L.; Triquet, B.; Bernat, G.; Berger, E.; Abella, J.; Wartel, F.; Houston, M.; et al. PROARTIS: Probabilistically Analysable Real-Time Systems. ACM TECS 2012, 12, 1–26. [Google Scholar] [CrossRef]
- Cazorla, F.J.; Kosmidis, L.; Mezzetti, E.; Hernandez, C.; Abella, J.; Vardanega, T. Probabilistic Worst-Case Timing Analysis: Taxonomy and Comprehensive Survey. ACM Comput. Surv. 2019, 52, 14:1–14:35. [Google Scholar] [CrossRef]
- Kosmidis, L.; Quiñones, E.; Abella, J.; Vardanega, T.; Hernandez, C.; Gianarro, A.; Broster, I.; Cazorla, F.J. Fitting processor architectures for measurement-based probabilistic timing analysis. Microprocess. Microsyst. 2016, 47, 287–302. [Google Scholar] [CrossRef]
- Milutinovic, S.; Mezzetti, E.; Abella, J.; Vardanega, T.; Cazorla, F.J. On uses of extreme value theory fit for industrial-quality WCET analysis. In Proceedings of the 2017 12th IEEE International Symposium on Industrial Embedded Systems (SIES), Toulouse, France, 14–16 June 2017. [Google Scholar]
- Cucu-Grosjean, L.; Santinelli, L.; Houston, M.; Lo, C.; Vardanega, T.; Kosmidis, L.; Abella, J.; Mezzetti, E.; Quiñones, E.; Cazorla, F.J. Measurement-Based Probabilistic Timing Analysis for Multi-path Programs. In Proceedings of the 2012 24th Euromicro Conference on Real-Time Systems (ECRTS), Pisa, Italy, 11–13 July 2012. [Google Scholar]
- Abella, J.; Padilla, M.; Del Castillo, J.; Cazorla, F. Measurement-Based Worst-Case Execution Time Estimation Using the Coefficient of Variation; ACM: New York, NY, USA, 2017. [Google Scholar]
- Curtsinger, C.; Berger, E.D. STABILIZER: Statistically Sound Performance Evaluation. SIGARCH Comput. Archit. News 2013, 41, 219–228. [Google Scholar] [CrossRef]
- Kosmidis, L.; Curtsinger, C.; Quiones, E.; Abella, J.; Berger, E.; Cazorla, F.J. Probabilistic timing analysis on conventional cache designs. In Proceedings of the 2013 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 603–606. [Google Scholar]
- Kormann, J.; Rodríguez, J.; Gutiérrez, N.; Ferrer, M.; Rojas, O.; De la Puente, J.; Hanzich, M.; María Cela, J. Toward an automatic full-wave inversion: Synthetic study cases. Lead. Edge 2016, 35, 1047–1052. [Google Scholar] [CrossRef]
- Hanzich, M.; Kormann, J.; Gutiérrez, N.; Rodríguez, J.; De la Puente, J.; María Cela, J. Developing Full Waveform Inversion Using HPC Frameworks: BSIT. In Proceedings of the EAGE Workshop on High Performance Computing for Upstream, Chania, Crete, 7–10 September 2014. [Google Scholar]
- Kosmidis, L.; Vargas, R.; Morales, D.; Quiñones, E.; Abella, J.; Cazorla, F.J. TASA: Toolchain Agnostic Software Randomisation for Critical Real-Time Systems. In Proceedings of the ICCAD, Austin, TX, USA, 7–10 November 2016. [Google Scholar]
- Kosmidis, L.; Quiñones, E.; Abella, J.; Farrall, G.; Wartel, F.; Cazorla, F.J. Containing Timing-Related Certification Cost in Automotive Systems Deploying Complex Hardware. In Proceedings of the 51st Annual Design Automation Conference, San Francisco, CA, USA, 1–5 June 2014; ACM: New York, NY, USA, 2014; pp. 22:1–22:6. [Google Scholar]
- Cros, F.; Kosmidis, L.; Wartel, F.; Morales, D.; Abella, J.; Broster, I.; Cazorla, F.J. Dynamic software randomisation: Lessons learnec from an aerospace case study. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 103–108. [Google Scholar]
- Berger, E.D.; Zorn, B.G. DieHard: Probabilistic memory safety for unsafe languages. In Proceedings of the ACM SIGPLAN 2006 Conference on Programming Language Design and Implementation, Ottawa, ON, Canada, 11–14 June 2006; pp. 158–168. [Google Scholar]
- Berger, E.D.; Zorn, B.G.; McKinley, K.S. Composing High-performance Memory Allocators. ACM SIGPLAN Not. 2001, 36, 114–124. [Google Scholar] [CrossRef]
- Agirre, I.; Azkarate-askasua, M.; Hernandez, C.; Abella, J.; Perez, J.; Vardanega, T.; Cazorla, F.J. IEC-61508 SIL 3 Compliant Pseudo-Random Number Generators for Probabilistic Timing Analysis. In Proceedings of the 2015 Euromicro Conference on Digital System Design, Madeira, Portugal, 26–28 August 2015; pp. 677–684. [Google Scholar]
- Abella, J. MBPTA-CV. Available online: https://doi.org/10.5281/zenodo.1065776 (accessed on 18 December 2019).
- Coles, S. An Introduction to Statistical Modeling of Extreme Values; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Kotz, S.; Nadarajah, S. Extreme Value Distributions: Theory and Applications; World Scientific: Singapore, 2000. [Google Scholar]
- Del Castillo, J.; Daoudi, J.; Lockhart, R. Methods to Distinguish Between Polynomial and Exponential Tails. Scand. J. Stat. 2014, 41, 382–393. [Google Scholar] [CrossRef]
- Lu, Y.; Nolte, T.; Bate, I.; Cucu-Grosjean, L. A new way about using statistical analysis of worst-case execution times. SIGBED Rev. 2011, 8, 11–14. [Google Scholar] [CrossRef]
- Sarma, K. Neural Network based Feature Extraction for Assamese Character and Numeral Recognition. Int. J. Artif. Intell. 2009, 2, 37–56. [Google Scholar]
- Pozna, C.; Precup, R.E.; Tar, J.K.; Škrjanc, I.; Preitl, S. New results in modelling derived from Bayesian filtering. Knowl.-Based Syst. 2010, 23, 182–194. [Google Scholar] [CrossRef]
- Nowakova, J.; Prílepok, M.; Snasel, V. Medical Image Retrieval Using Vector Quantization and Fuzzy S-tree. J. Med. Syst. 2017, 41. [Google Scholar] [CrossRef] [PubMed]
- Alvarez Gil, R.; Johanyák, Z.; Kovács, T. Surrogate model based optimization of traffic lights cycles and green period ratios using microscopic simulation and fuzzy rule interpolation. Int. J. Artif. Intell. 2018, 16, 20–40. [Google Scholar]
- Santinelli, L.; Morio, J.; Dufour, G.; Jacquemart, D. On the Sustainability of the Extreme Value Theory for WCET Estimation. In Proceedings of the 14th International Workshop on Worst-Case Execution Time (WCET) Analysis, Madrid, Spain, 18 July 2014. [Google Scholar]












© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fusi, M.; Mazzocchetti, F.; Farres, A.; Kosmidis, L.; Canal, R.; Cazorla, F.J.; Abella, J. On the Use of Probabilistic Worst-Case Execution Time Estimation for Parallel Applications in High Performance Systems. Mathematics 2020, 8, 314. https://doi.org/10.3390/math8030314
Fusi M, Mazzocchetti F, Farres A, Kosmidis L, Canal R, Cazorla FJ, Abella J. On the Use of Probabilistic Worst-Case Execution Time Estimation for Parallel Applications in High Performance Systems. Mathematics. 2020; 8(3):314. https://doi.org/10.3390/math8030314
Chicago/Turabian StyleFusi, Matteo, Fabio Mazzocchetti, Albert Farres, Leonidas Kosmidis, Ramon Canal, Francisco J. Cazorla, and Jaume Abella. 2020. "On the Use of Probabilistic Worst-Case Execution Time Estimation for Parallel Applications in High Performance Systems" Mathematics 8, no. 3: 314. https://doi.org/10.3390/math8030314
APA StyleFusi, M., Mazzocchetti, F., Farres, A., Kosmidis, L., Canal, R., Cazorla, F. J., & Abella, J. (2020). On the Use of Probabilistic Worst-Case Execution Time Estimation for Parallel Applications in High Performance Systems. Mathematics, 8(3), 314. https://doi.org/10.3390/math8030314