Pointwise Optimality of Wavelet Density Estimation for Negatively Associated Biased Sample


Abstract
1. Introduction
2. Notations and Assumptions
- (A1)
- The function is bounded; that is, a positive constant exists, such that:
- (A2)
- The biasing function is non-increasing and for all , two positive constants and exist, i.e.,
3. Estimator and Main Result
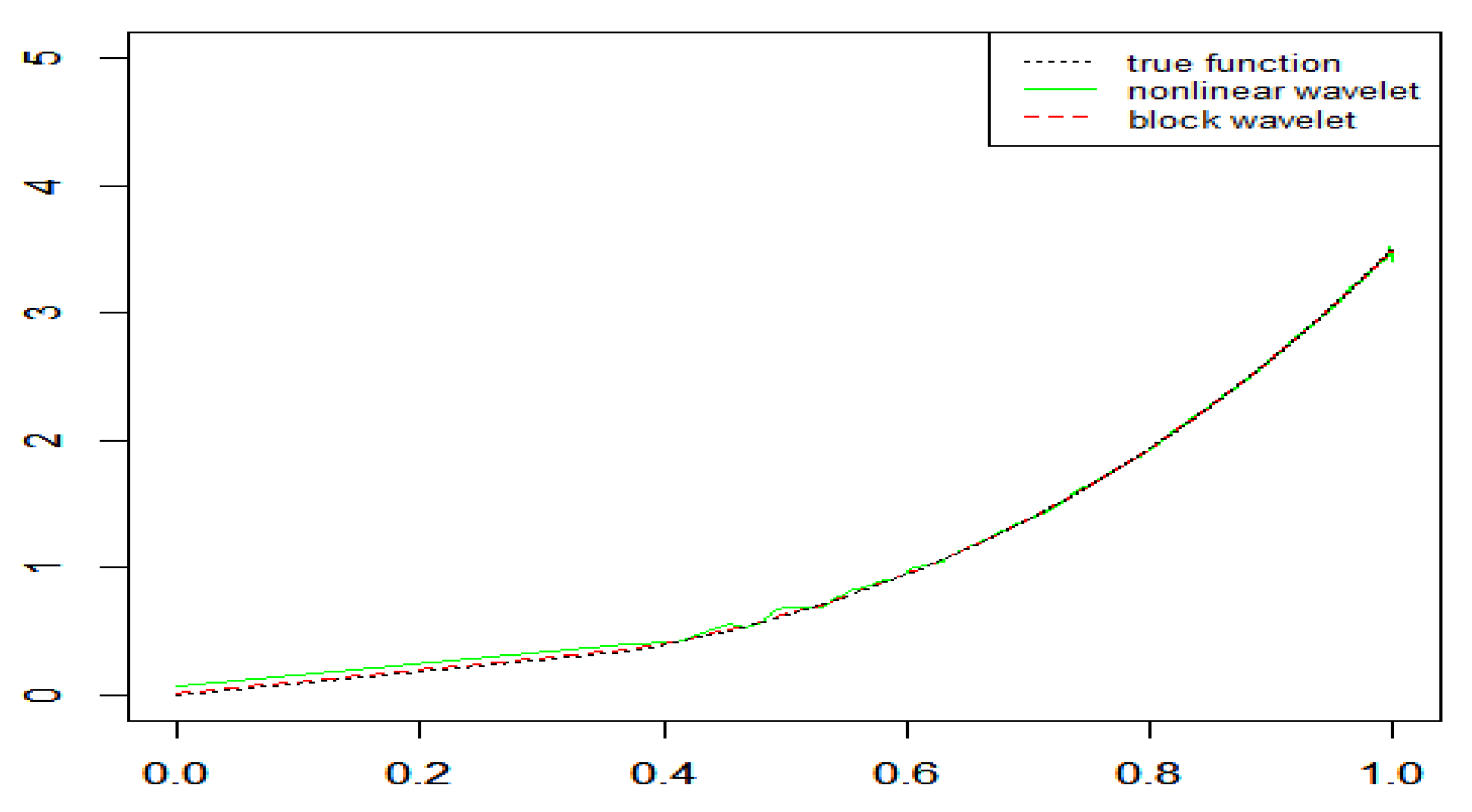
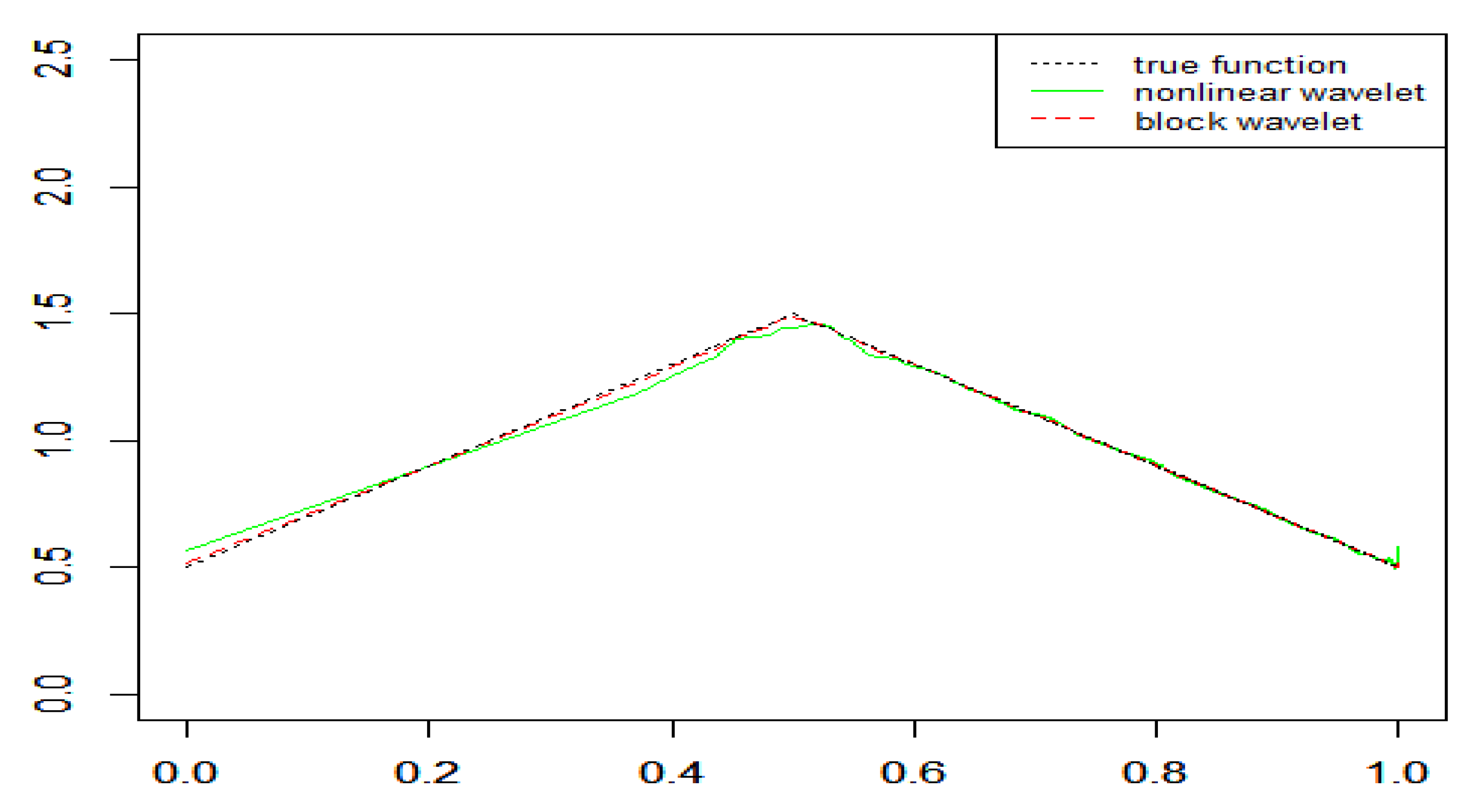
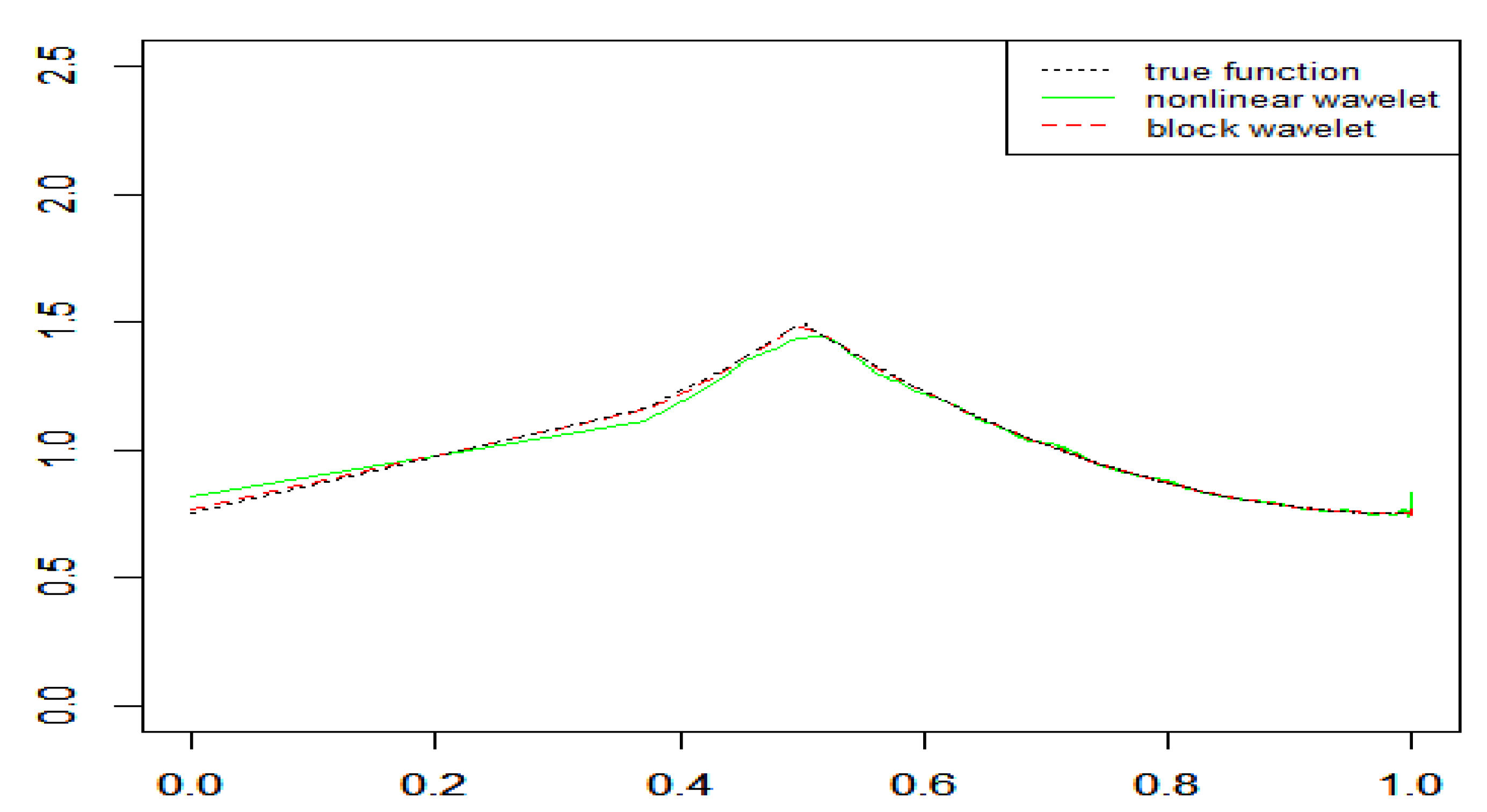
4. Simulation Study
5. Proof of Theorem 1
- (1)
- Rosenthal-type inequality: If for some then a constant (only depends on p) exists, such that:
- (2)
- Kolmogorov-type inequality: Denote , we have, for all , and :
Author Contributions
Funding
Conflicts of Interest
References
- Efromovich, S. Density estimation for biased data. Ann. Statist. 2004, 32, 1137–1161. [Google Scholar] [CrossRef]
- Ramirez, P.; Vidakovic, B. Wavelet density estimation for stratified size-biased sample. J. Stat. Plan. Inference 2010, 140, 419–432. [Google Scholar] [CrossRef]
- Chesneau, C. Wavelet block thresholding for density estimation in the presence of bias. J. Korean Stat. Soc. 2010, 39, 43–53. [Google Scholar] [CrossRef]
- Guo, H.; Kou, J. Pointwise density estimation for biased sample. J. Comput. Appl. Math. 2019, 361, 444–458. [Google Scholar] [CrossRef]
- Alam, K.; Saxena, K.L. Positive dependence in multivariate distributions. Commun. Stat. Theory Method. 1981, 10, 1183–1196. [Google Scholar]
- Joag-Dev, K.; Proschan, F. Negative association of random variables with applications. Ann. Stat. 1983, 11, 286–295. [Google Scholar] [CrossRef]
- Liang, H.Y. Complete convergence for weighted sums of negatively associated random variables. Statist. Probab. Lett. 2000, 48, 317–325. [Google Scholar] [CrossRef]
- Matula, P. A note on the almost sure convergence of sums of negatively dependent random variables. Statist. Probab. Lett. 1992, 5, 209–212. [Google Scholar] [CrossRef]
- Roussas, G.G. Asymptotic normality of random fields of positively or negatively associated processes. J. Multivariate Anal. 1994, 50, 152–173. [Google Scholar] [CrossRef]
- Chen, P.; Sung, S.H. On the strong convergence for weighted sums of negatively associated random variables. Statist. Probab. Lett. 2014, 92, 45–52. [Google Scholar] [CrossRef]
- Miao, Y.; Xu, W.; Chen, S. Some limit theorems for negatively associated random variables. Pro. Math. Sci. 2014, 124, 447–456. [Google Scholar] [CrossRef]
- Wu, Y. On complete moment convergence for arrays of rowwise negatively associated random variables. RACSAM 2014, 108, 669–681. [Google Scholar] [CrossRef]
- Chesneau, C.; Dewan, I.; Doosti, H. Wavelet linear density estimation for associated stratified size-biased sample. J. Nonparametr. Stat. 2012, 2, 429–445. [Google Scholar] [CrossRef]
- Liu, Y.M.; Xu, J.L. Wavelet density estimation for negatively associated stratified size-biased sample. J. Nonparametr. Stat. 2014, 26, 537–554. [Google Scholar] [CrossRef]
- Guo, H.J.; Kou, J.K. Pointwise density estimation based on negatively associated data. J. Inequal. Appl. 2019, 206, 1–16. [Google Scholar] [CrossRef]
- Cai, T.; Chicken, E. Block thresholding for density estimation: Local and global adaptivity. J. Multivariate Anal. 2005, 95, 76–106. [Google Scholar]
- Brown, L.; Cai, T.; Zhang, R.; Zhao, L. The root-unroot algorithm for density estimation as implemented via wavelet block thresholding. Probab. Theory Related Fields 2010, 146, 401–433. [Google Scholar] [CrossRef]
- Chesneau, C. Wavelet estimation via block thresholding: A minimax study under the Lp risk. Statist. Sinica. 2008, 18, 1007–1024. [Google Scholar]
- Donoho, D.L.; Johnstone, I.M. Minimax estimation via wavelet shrinkage. Ann. Stat. 1998, 26, 879–921. [Google Scholar] [CrossRef]
- Shao, Q.M. A comparison theorem on maximum inequalities between negatively associated and independent random variables. J. Theoret. Probab. 2000, 13, 343–356. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| n | Example 1 | Example 2 | Example 3 | |||
|---|---|---|---|---|---|---|
| Block | Nonlinear | Block | Nonlinear | Block | Nonlinear | |
| 512 | 0.0047 | 0.0072 | 0.0064 | 0.0102 | 0.0067 | 0.0114 |
| 1024 | 0.0043 | 0.0065 | 0.0056 | 0.0098 | 0.0054 | 0.0101 |
| 2048 | 0.0039 | 0.0058 | 0.0053 | 0.0096 | 0.0048 | 0.0093 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, R.; Liu, X.; Yu, Y. Pointwise Optimality of Wavelet Density Estimation for Negatively Associated Biased Sample. Mathematics 2020, 8, 176. https://doi.org/10.3390/math8020176
Ye R, Liu X, Yu Y. Pointwise Optimality of Wavelet Density Estimation for Negatively Associated Biased Sample. Mathematics. 2020; 8(2):176. https://doi.org/10.3390/math8020176
Chicago/Turabian StyleYe, Renyu, Xinsheng Liu, and Yuncai Yu. 2020. "Pointwise Optimality of Wavelet Density Estimation for Negatively Associated Biased Sample" Mathematics 8, no. 2: 176. https://doi.org/10.3390/math8020176
APA StyleYe, R., Liu, X., & Yu, Y. (2020). Pointwise Optimality of Wavelet Density Estimation for Negatively Associated Biased Sample. Mathematics, 8(2), 176. https://doi.org/10.3390/math8020176