Abstract
This paper describes the use of the non-homogeneous stochastic Weibull diffusion process, based on the two-parameter Weibull density function (the trend of which is proportional to the two-parameter Weibull probability density function). The trend function (conditioned and non-conditioned) is analyzed to obtain fits and forecasts for a real data set, taking into account the mean value of the process, the maximum likelihood estimators of the parameters of the model and the computational problems that may arise. To carry out the task, we employ the simulated annealing method for finding the estimators values and achieve the study. Finally, to evaluate the capacity of the model, the study is applied to real modeling data where we discuss the accuracy according to error measures.
1. Introduction
A diffusion process is a solution of the stochastic differential equation (SDE) of the form
with a standard unidimensional or multidimensional Wiener process and a and known functions (with a vector-valued and matrix-valued if is a multivariate process). indicates the unknown parameter and the inference issue discussed in that of estimating under continuous observation or discrete observations of . In order to give an example of stochastic processes, we cite the Brownian motion which plays a central role in the development of stochastic analysis. It is a process which is Gaussian, Markov, self-similar, a martingale and has stationary, independent increments. Brownian motion is also known as a Wiener process in honor of Norbert Wiener who’s work appeared in a series of papers in the early 1920s, a decade before Kolmogorov’s monograph that set probability theory on a rigorous mathematical foundation.
Stochastic modeling deals with real-world situations in which uncertainty is present and employ probability skills to model those circumstances. Therefore, the purpose of stochastic modeling is to study a forecast and to estimate the probability of its outcomes, to explain what conditions or decisions might happen under different situations for good results. Stochastic diffusion processes are well adapted to illustrate the advancement of diverse phenomena and to forecast their future trends, by using statistical inference methods. For instance, stochastic diffusion processes have been employed with respect to demography [1], electricity consumption [2], life expectancy at birth [3], effect of therapy on tumors [4] and population extinction [5].
These models are defined by stochastic diffusion processes, considered using stochastic calculus methods and on the corresponding statistical inference. In general, the solution to an Itô-type SDE is a diffusion process, whose trend function has a form similar to a curve associated with known distribution. In some cases, the maximum likelihood (ML) method is the feasible procedure since the transition density function of the diffusion process is known explicitly.
The difficulty of estimating parameters of the drift coefficient has collected important interest in latest years. In most cases, the statistical inference is based on approximating the ML methodology, see for example, Prakasa Rao [6].
In the same context described above, we propose in this paper a study of the Weibull-type stochastic diffusion model. The trend function (TF) of this model corresponds to the graph of the probability density function of the Weibull distribution. From the explicit expression of the transition density function of the process, the ML method is applied to find out the estimators of the parameters of the process. In the measure to estimate the parameters, we must overcome the difficulty appeared when we were solving the ML principle. To carry out the problem, we suggest using the simulated annealing (SA) method. This methodology is implemented on an example with real data also illustrated with simulated data by employing the resulted values of the parameters. The estimation of parameters produces a computational problem. This paper is structured as next: in Section 2, we introduce the non-homogeneous Weibull diffusion process and its probabilistic aspects. The parameters are then estimated in Section 3, using the ML method with discrete sampling in time and considering the computational problems involved by means of SA presented in Section 4. We then determine the approximate confidence bounds of the process. Finally, in Section 5, this method is applied to real data.
2. Stochastic Weibull Diffusion Process (SWDP)
2.1. The PDF and Moments of the Process
The SWDP, which is the proposed model in this study, is established as the non-homogeneous diffusion process depending on time and taking values in by the next Itô’s SDE
where is a univariate standard Wiener process and is a constant. Thus, we give the infinitesimal moments by the equations:
where and and are real constants.
This model is an extension of the SWDP defined in Reference [7]. In fact, by considering a constant instead of the terme in the drift coefficient in Reference [7]; that is, . Then, we obtain our stochastic Weibull diffusion process with a new drift coefficient defined in Equation (2).
Since, the functions and , , are Borel measurable and satisfy the uniform Lipschitz and the growth conditions (see Kloeden and Platen [8]). We conclude that there exists a constant such as the infinitesimal moments specified in Equation (2) verify the Lipschitz and growth conditions and .
In fact, let us consider and then from one side we have
From another side, for the particular case where we have
we note
Thus, there exist an (a.s.) continuous process , separable and measurable, which is the unique (a.s.) solution of the SDE (1). This solution is obtained by using Itô’s formula. Let us define a new variable by so that
This equation can be directly integrated, thus obtaining
and hence
Since conditionally on has a one-dimensional normal distribution . Consequently, conditionally on is lognormally distributed denoted by and we have given by
From the above, the probability density function (PDF) of the process considered has the next form
2.2. Moments of the Process
To determine the moments of the process, we take into account the useful property of the lognormal distribution, that the r-th conditional moment of the process is defined by
As matter of fact, when we consider the situation where , the conditional trend function (CTF) of the process is:
Thereby under the initial condition , the TF of the process is expressed by:
Remark 1.
- -As mentioned above, this process is a generalisation of the one defined in Reference [7]. In fact, assuming , the SWDP obtained becomes the SWDP based on the two-parameters Weibull distribution.
- -Moreover, the trend function of the process, given in Equation (9), is corresponding to the PDF of the Weibull distribution.
3. Statistical Inference
3.1. Maximum Likelihood Estimation
The drift and diffusion parameters of the process that are , and are estimated by ML method and discrete sampling. Therefore, we treat a discrete sampling of the process at times and we denote in the following. Moreover, we presume that the time gap among two successive observations is constant (i.e., for ). Hereafter, by taking the initial condition, the linked likelihood function can be obtained from Equation (7) by:
Since taking derivatives of a product is tedious, the log-likelihood for Equation (10) is usually maximised, that is,
By applying the principle of ML, we obtain , and which are the estimators of , and respectively. As a matter of fact, we derivate the log-likelihood function with respect to , and then we get the next equations:
For we denote:
From Equation (12a), we obtain (as a positive solution) the expression of the estimator on the following result:
3.2. Confidence Bounds of the Process
The confidence bounds (CB) of the process are obtained using the same procedure as in Reference [9]. Thus, from Equation (5), we consider the variable
Since the random variable is the so-called independent increments and is normally distributed an estimation for the variable is normally distributed
Thus, the 95% CB for the variable is obtained from the next characteristic:
A CB for with the following form can thus be obtained:
where,
4. Computational Aspects
4.1. Estimated TF and Estimated CBs
From Zenha’s theorem [10], by replacing the parameters by their estimators in Equations (8) and (9), the estimated conditional trend (ECTF) function can be obtained from:
and the estimated trend function (ETF) is given by:
What is more, the ECB are contructed by replacing the parameters by their estimators in Equation (14).
4.2. Simulated Annealing Method
Simulated Annealing (SA) was first introduced by References [11,12], who showed up significant initial results, following a prior investigation by Reference [13] who attempted to minimise a function on a very large, finite set. The actual approach was subsequently applied to optimising a continuous set by Reference [14].
SA is a technique to approximating the solution to tough combinatorial optimisation questions. The problem we get into is
or equivalently
Under the proposed algorithm, in every repetition, we have an actual solution x which is represented by an objective function value , for this solution a neighbour is chosen from the neighbourhood of x indicated and determined as the set of all its nearest neighbours. For every move, the objective variance is measured. From maximisation problems, takes the place of x when Moreover, could also be admitted with a probability The approval probability is compared to a randomly-generated number r and is accepted whenever We have to fulfill the stopping criteria to find out the point which is a close solution to the issue.
In our situation, the problem is to maximise log-likelihood function obtained in Equation (11). Therefore, the objective function to minimise is a function of parameters , and :
In SA the motivation is to avoid trapping local optima, thereby enabling upward moves to higher-cost solutions under the orientation of a control parameter termed ‘temperature’.
5. Application and Simulation: The Age Dependency Ratio
5.1. Application
The following time-dependent stochastic variable (stochastic process) is considered: that is, the ratio of the dependent population (those aged under 15 or over 65 years) to the working-age population (aged 15 to 65 years) during year t in Morocco. This ratio is expressed as the number of “dependents” per 100 “workers”. This indicator is a decisive quantity of concern for demographic analysis also for pay-as-you-go retirement structure, social security system and health care insurance [15,16]. Indeed, the age dependency ratio measures the charge that the old population shows for the workers also it demonstrates how the dependency between young and old populations is making progress during demographic transitions. Formally, the age dependency ratio ,
where represents the number of individuals with age at time We also introduce for the average number of individuals with age a at time
The age dependency ratio in Morocco has significantly decreased; according to official Data in Table 1, the annual age dependency ratio fell from 105.58% (i.e., 105.58 dependents per 100 persons of working age) in 1968 to 51.89% in 2017. The mean ratio during this period was 74.55% with a minimum of 51.64% in 2015. The evolution of this ratio is associated with factors such as birth rate, fertility rate, employment trends, life expectancy and economic growth rates.

Table 1.
Age dependency ratio (% of working-age population) in Morocco.
The data used for this purpose correspond to the period 1968–2017 (see Table 1) and were provided in World Bank’s database. The method applied is composed of two phases:
- Step 1: Data for 1968–2014 are used to estimate the process parameters as described above. Using the Matlab package, the following estimator values are obtained: and
- Step 2: Data for 2015–2017 are explored to forecast the expected values of the process. The results in Table 2 resume the behaviour of the conditional and the non-conditional trend functions given, respectively, by Equations (15) and (16) also the values of the confidence bounds (given 95%) established from Equation (14). The performance of the SWDP for the previsions is represented in Figure 1 and Figure 2.
Table 2. Predictions with trend function (TF) and conditional trend function (CTF) of the process.
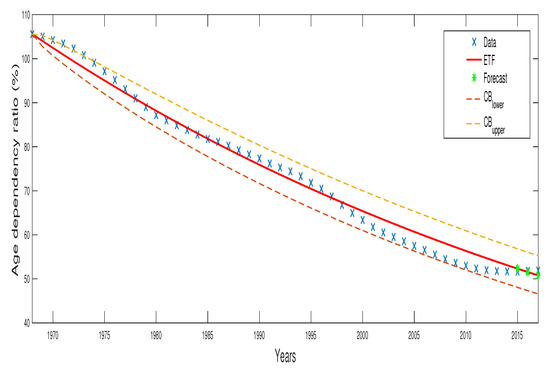 Figure 1. Observed data, estimated trend function (ETF) and the forecasted values.
Figure 1. Observed data, estimated trend function (ETF) and the forecasted values.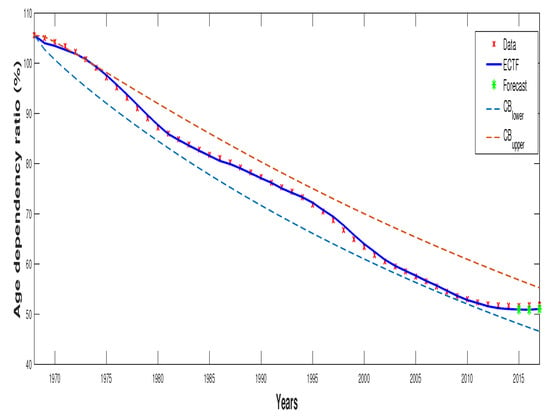 Figure 2. Observed data, estimated conditional trend function (ECTF) and the forecasted values.
Figure 2. Observed data, estimated conditional trend function (ECTF) and the forecasted values.
5.2. Goodness of Fit
The following scale-dependent quantities are based on the absolute error or squared errors and measures based on percentage errors:
- Mean Absolute Error (MAE) = mean (),
- Root Mean Square Error (RMSE) =
- Mean Absolute Percentage Error (MAPE) = mean (),
assuming with is obtained by substituting the parameters in Equation (5) by their estimators.
The values obtained for the above error measures are acceptably low, especially the MAPE according to Table 3. The statistical measures obtained are illustrated in the Table 4.
Table 3.
Interpretation of typical Mean Absolute Percentage Error (MAPE) values.
Table 4.
Goodness of fit of the model.
5.3. Simulation
The sample paths were simulated by Equation (5), taking values of , , and tight to those evaluated for these parameters in the real example in the application for which this investigation was established in Section 5.1. Ten trajectories with 500 values each were generated and the following time instants considered.
Figure 3 shows the simulated trajectories of the SWDP, where the red curve represents the theoretical trend function, for the particular case of , which match, respectively to values near to those obtained in the study of
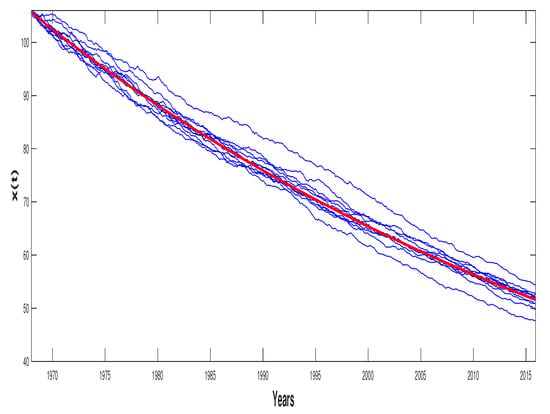
Figure 3.
The Stochastic Weibull Diffusion Process (SWDP) simulated with the theoretical trend function.
6. Conclusions
The SWDP was applied to analyse the age dependency ratio in Morocco. This obtained an improved description of the time series considered (1968–2014) and improved medium-term forecasts (2015–2017). From the results obtained (see Table 2, Figure 1 and Figure 2), we deduce that when the real case considered is modelled by the SWDP model according to the estimation procedure designated in Section 3, the fit and prediction achieved, based on ETF and ECTF, present an important degree of accuracy Table 4.
From one hand, as the retirement age is stable, when the life expectancy is rising, an important part of one’s lifetime is spent in pension. On the other hand, while the birth rates is decreasing, the part of population who will afterwards represent the support to the rest of the population is going down. In view of the fact that the dependency ratio indicates how many people need to be supported relative to the number of people who are working, consequently, the increasing number of retirees and the decreasing workforce drive up the dependency ratio.
An interesting area for future research would be to examine the possibility of defining a non-homogeneous Weibull model, introducing exogenous factors into the drift, similarly to the approach adopted for other diffusions [17,18]. This would enable us to study the factors affecting the evolution of the age dependency ratio for example: fertility, immigration, mortality, health and work ability.
Author Contributions
A.N. accomplished the formal analysis; A.N., and M.B. developed the methodology; M.B., B.A. and R.G.-S. analysed the data, M.B. wrote the first draft, A.N., R.G.-S. and B.A. wrote the evaluation and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This reasearch was financed by LAMSAD from “Fonds propres de l’Université Hassan I” (Morocco) and FQM-147 from “Plan Andaluz de l’Investigaciòn” (Spain).
Acknowledgments
We would like to thank the Editor and all the referees for constructive comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gutiérrez, R.; Gutiérrez-Sánchez, R.; Nafidi, A. Trend analysis and computational statistical estimation in a stochastic Rayleigh model: Simulation and application. Math. Comput. Simul. 2008, 77, 209–217. [Google Scholar] [CrossRef]
- Giovanis, A.; Skiadas, C. A stochastic logistic innovation diffusion model studying the electricity consumption in Greece and the United States. Technol. Forecast. Soc. Chang. 1999, 61, 235–246. [Google Scholar] [CrossRef]
- Gutiérrez, R.; Gutiérrez-Sánchez, R.; Nafidi, A. The Stochastic Rayleigh diffusion model: Statistical inference and computational aspects. Applications to modelling of real cases. Appl. Math. Comput. 2006, 175, 628–644. [Google Scholar] [CrossRef]
- Albano, G.; Giorno, V.; Román-Román, P.; Torres-Ruiz, F. Inferring the effect of therapy on tumors showing stochastic Gompertzian growth. J. Theor. Biol. 2011, 276, 67–77. [Google Scholar] [CrossRef] [PubMed]
- Skvortsov, A.; Ristic, B.; Kamenev, A. Predicting population extinction from early observations of the Lotka–Volterra system. Appl. Math. Comput. 2018, 320, 371–379. [Google Scholar] [CrossRef]
- Rao, B.P.; Rao, B.P. Statistical Inference for Diffusion Type Processes; Arnold: London, UK, 1999. [Google Scholar]
- Nafidi, A.; Bahij, M.; Achchab, B.; Gutiérrez-Sanchez, R. The stochastic Weibull diffusion process: Computational aspects and simulation. Appl. Math. Comput. 2019, 348, 575–587. [Google Scholar] [CrossRef]
- Kloeden, P.E.; Platen, E.; Gelbrich, M.; Romisch, W. Numerical Solution of Stochastic Differential Equations. SIAM Rev. 1995, 37, 272–274. [Google Scholar]
- Katsamaki, A.; Skiadas, C. Analytic solution and estimation of parameters on a stochastic exponential model for a technological diffusion process. Appl. Stoch. Model. Data Anal. 1995, 11, 59–75. [Google Scholar] [CrossRef]
- Zehna, P.W. Invariance of maximum likelihood estimators. Ann. Math. Stat. 1966, 37, 744. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Černỳ, V. Thermodynamical approach to the traveling salesman problem: An efficient simulation algorithm. J. Optim. Theory Appl. 1985, 45, 41–51. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of State Calculations by Fast Computing Machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Duflo, M. Random Iterative Models; Springer Science & Business Media: Berlin, Germany, 2013; Volume 34. [Google Scholar]
- Boumezoued, A.; Hardy, H.L.; Karoui, N.E.; Arnold, S. Cause-of-death mortality: What can be learned from population dynamics? Insur. Math. Econ. 2018, 78, 301–315. [Google Scholar] [CrossRef]
- Boyle, P.P.; Freedman, R. Population waves and fertility fluctuations: Social security implications. Insur. Math. Econ. 1985, 4, 65–74. [Google Scholar] [CrossRef]
- Gutiérrez, R.; Gutiérrez-Sánchez, R.; Nafidi, A. Electricity consumption in Morocco: Stochastic Gompertz diffusion analysis with exogenous factors. Appl. Energy 2006, 83, 1139–1151. [Google Scholar] [CrossRef]
- Nafidi, A.; Gutiérrez, R.; Gutiérrez-Sánchez, R.; Ramos-Ábalos, E.; El Hachimi, S. Modelling and predicting electricity consumption in Spain using the stochastic Gamma diffusion process with exogenous factors. Energy 2016, 113, 309–318. [Google Scholar] [CrossRef]



© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).