1. Introduction
Volatile organic compounds (VOCs) are compounds with very high volatility which are in a gaseous state under normal circumstances. They include a variety of chemical species among which are benzene, toluene, ethylbenzene and xylene [
1] and are known as BETX, all of them are air pollutants, along with other compounds such us SO
2, NO
2, NO
x, PM
10, PM
2.5 or CO [
2].
Benzene is a hydrocarbon with a ring structure made up of six carbon atoms. It is one of the products that is most used as a raw material in industrial processes in the organic chemical industry. Its usual state is liquid, highly flammable, and colorless, although it does have a very characteristic odor and very high toxicity [
3].
Benzene has been used in the manufacture of several chemical products like styrene, phenols, in nylon and synthetic fibers, maleic anhydride, pharmaceuticals, detergents and dyes and explosives. It has also been used in fuel, where it is added as a lead substitute, chemical reagent and extraction agent for other chemical compounds [
3]. Derivates of benzene are used primarily as solvents and diluents in the manufacture of perfumes and in intermediates in the production of dyes, although the most important industrial use is as solvents and paint thinners [
4,
5].
Benzene has been banned as a component of products intended for domestic use and, in many countries, it has also been prohibited as a solvent and as a component of dry-cleaning liquids [
4].
Natural sources of benzene include emissions from volcanoes and forest fires [
6]. On the other hand, road traffic is an important source of emissions of VOCs, such as benzene, and other compounds that mainly come from vehicle exhausts and are generated during the incomplete combustion of fuels [
7].
A study [
8] has reported that there is a big discrepancy between the values obtained in measurements of industrial environments compared to the homogeneous values obtained in urban areas.
The main source of benzene exposure is tobacco smoke and other outdoor sources like automobile exhaust emissions [
5], combustion processes and industrial chemical vapors [
8]. Indoor sources include building materials, detergents, glues, furniture varnish and products such as solvents and paints from kitchens, attached garages and fuels for housing. The concentration of benzene indoors is generally higher than it is outdoors. It is affected by weather conditions and by the type of ventilation [
3,
5]. However, personal exposure concentrations of benzene in and around gas stations is considerably higher than indoor and ambient concentrations [
9].
Recent studies [
10] indicate that, while the limits of indoor concentration have been increasingly restrictive and the sources of interior emissions have been progressively reduced, outdoor benzene has become a significant, and even in many cases dominant, contributor to indoor concentration.
Air pollution is associated with adverse health effects such as respiratory and cardiovascular diseases, cancer and even death [
11]. In 2017, environmental contamination contributed to almost 5 million premature deaths in the world [
12]. More than 90% of the world’s population lives in areas where the WHO-established guidelines for the quality of healthy air are exceeded and about half, a total of 3.6 billion, was exposed to contamination in the home. Air pollution is related to premature deaths from ischemic heart disease (16%), chronic obstructive pulmonary disease (41%) and lung cancer (19%).
The sources of entry of benzene into the human body are the lungs, the digestive tract and the skin [
5] although population exposure is mainly produced through the inhalation of air containing benzene [
8].
Several factors influence benzene exposure, including mainly concentration, duration of exposure, contact pathway and also the presence of other chemical substances, as well as the characteristics and habits of people [
5].
A long or repeated exposure to benzene can affect the central nervous system and the immune system. It can also affect the bone marrow, and this can cause anemia and different types of leukemia. It may also cause inherited genetic damage in human germ cells [
4,
13].
Benzene has been categorized as being among group I carcinogens by the International Agency for Research on Cancer (IARC). It is considered as a known human carcinogen and no safe level can be recommended [
3,
14,
15].
Sensitive population groups such as the elderly, pregnant women, infants, children and people with previous cardiovascular and respiratory diseases are the most susceptible to poor air quality [
16]. Several studies indicate that there is a strong relationship between air pollution and infant mortality [
17] and diseases of the infant respiratory system, so that hospital admissions increase significantly when there are pollution peaks. Hospital admissions for other causes also increase when benzene levels and other air pollutants rise [
18,
19,
20].
Epidemiological studies have shown that there is a relationship between exposure to benzene and the development of acute myeloid leukemia [
14]. A Swiss pediatric oncology cohort study [
21] found an increased risk of leukemia among children whose mothers had been exposed to benzene at work. Studies like [
22] also indicate the existence of an increased risk of colon cancer in Nordic countries, while a study in France showed that long-term exposure to outdoor air pollution like benzene, fine particles, sulfur dioxide and nitrogen dioxide is a significant environmental risk factor for mortality [
23].
There are different limits established for exposure to benzene. The European Commission has established a concentration limit for benzene of 5 µg/m
3 as an annual averaging period in the Directive 2008/50/EC, Directive on environment air quality [
24].
Regarding occupational exposure limits [
13], TLV-TWA of 0.5 ppm (the threshold limit value considered as the time-weighted average for an 8 h day and 40 weekly hours) and 2.5 ppm as STEL (short-term exposure limit for periods of 15 min that should not be exceeded at any time) have been established.
OSHA regulates benzene levels in the workplace. The maximum amount of benzene in the air must not exceed 1 ppm during an 8 h day, 40 h a week [
5] (Directive 97/42/EC, amendment of 90/394/EEC).
Environmental pollution processes are complex and direct measurement is not always possible. In addition, it is difficult to carry out an analysis to discover the source, the propagation and distribution models and to make predictions over time. Therefore, since the reduction of such pollution is an objective of the European Union, it is necessary to find methods that make it possible to model its behavior and predict its evolution.
In the case of pollution concentration modeling, there are two methodologies used in predicting air quality: physical models and models based on statistical data. Physical models are based on chemical dispersion and transport models, in which the input variables are often related to parameters obtained from meteorological observations, such as air temperature, dew point, relative humidity, atmospheric pressure, speed and direction of wind, UV radiation, another group of parameters related to the terrain such as vegetation, local topography, etc. and parameters related to emission sources that represent changes in traffic patterns, industrial activity and the distance to these sources. Statistical machine learning models are based on periodic parameters and these models do not need to understand physical phenomena. Models based on statistical parameters achieve better predictions than models that only used meteorological variables as input [
25].
The objective of this study was to predict the concentration of benzene from other pollutants, which were collected by several measurement stations of the Community of Madrid (Spain) every day during the period indicated in
Table 1 for each station, constituting voluminous information that allows their mathematical modeling and statistical learning to obtain an explanation of the dependency among the main pollutants in a geographic area based on the concentrations of other air pollutants in each station, as well as the environmental pollution existing at that time in other stations.
To make this prediction, time series forecasting techniques such as autoregressive moving average vectors (VARMAs), and integrated autoregressive moving average model (ARIMA) were applied and the results compared with those obtained with machine learning methodologies such as artificial neural networks (ANNs), support vector machines (SVMs), multivariate linear regressions (MLRs) and multivariate adaptative regression splines (MARSs).
In existing literature there are several success stories of applying these methodologies as a tool for predicting contamination and dispersion of air pollutants such as SO2, NO2, NOx, PM10, PM2.5 O3 or CO.
There are multiple studies of different pollutants to make predictions with ANNs such as [
25,
26,
27,
28]. Other models like SVMs have been studied by [
29,
30,
31]. MLRs by [
32,
33]. Time data series by [
34,
35,
36,
37] and MARSs by [
38,
39].
In many of these articles they analyze different models, compare the results and determine which method makes the best predictions for the pollutants that have been studied [
40,
41].
A previous study [
28] reviewed 139 articles about pollutants examined with ANN models and the results indicate that the most analyzed pollutants are particulate matter (PM
10, PM
2.5) in 62% of the articles, 36% nitrogen oxides (NO, NO
2 and NO
x), 31% O
3. SO
2 and CO modeling in 13% and 16% of articles. Almost a third of them include the study of several pollutants, but only one article [
42], has studied an ANN model for predicting benzene.
Therefore, models for the prediction of benzene have not yet been developed, and even less so to study the relationship between measurements obtained from other pollutants at stations with benzene. The methods used are data-oriented, so there is no need to make solid chemical-physical assumptions during the modeling process, they have the capacity to handle large amounts of data and are applied in different tasks such as studying the existing relationship between benzene and the rest of pollutants and its prediction.
2. Materials and Methods
2.1. The Database
In this study, data observed from various pollutants was used, along with four predictor variables: nitrogen dioxide (NO2), nitrogen oxides (NOx), particulate matter with a diameter less than 10 µm (PM10), and toluene (C7H8) were selected to perform the benzene (C6H6) prediction models.
These pollutants were collected by eight remote measurement stations in the Community of Madrid (Spain) every day, with hourly measurements during the periods indicated in
Table 1.
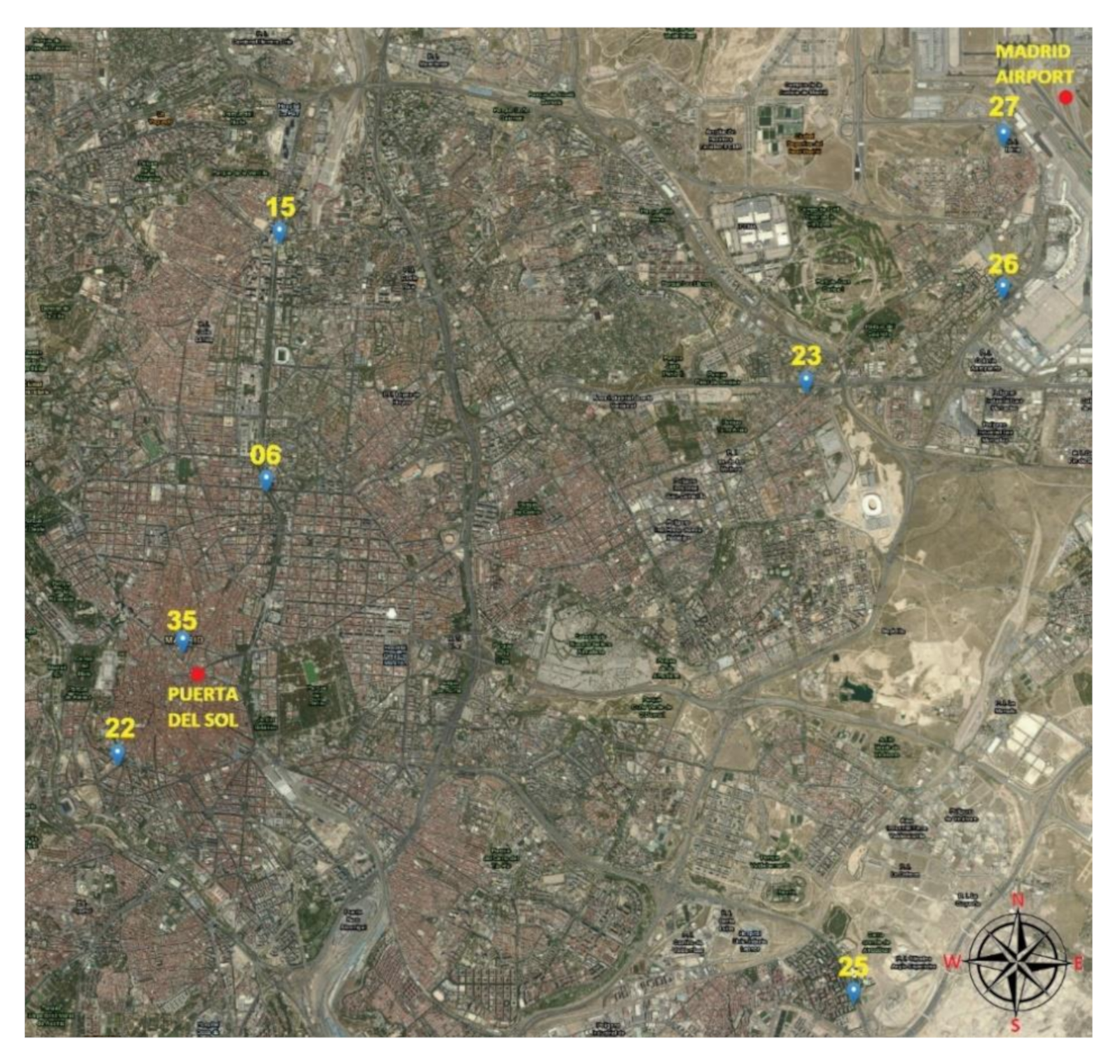
Figure 1 shows the geographical location of the stations used in this study on the map of Madrid.
Before carrying out the formation phase of the models used, an imputation of the missing data due to breakdowns and maintenance of the stations was carried out, through multiple imputations by chained equations [
43].
The mean and standard deviation of the pollutants under study are shown in
Table 2.
2.2. Multivariate Linear Regression
Linear regression with several independent variables is known as multivariate or multiple linear regression (MLR), which is a generalization of simple regression when the relationship of a dependent variable designated by is represented by the linear combination of the other k independent variables, which are denoted by .
MLR model assumes a relationship of the type
, where
are (
k + 1) parameters called regression coefficients and
is the stochastic error associated with the regression. Regression parameters
are estimated in order to determine the best hyperplane among all of the form
. A set of
n observations is available for each of the dependent and independent variables, so the model is as follows [
44,
45]:
In order to be able to make predictions about the behavior of the
variable, it is first necessary to carry out the estimations
of the model parameters by the ordinary least square method whose objective is to find the hyperplanes that minimize the sum of square error (SSE) between the observed and predicted response:
, where
is the outcome and
is the model prediction. That is:
To minimize SSE, it is derived with respect to the parameters and equating to zero gives a system of equations called normal equations.
In matrix form, the MLR model involves finding the last square solution of the linear system , where is the input data matrix with each row an input vector (with a 1 in the first position), its transposed matrix, the vector of output in the training set and the parameters vector. Now the residual sum-of-squares is and to minimize is derived and equating to zero (assuming rank is k and, hence, is positive definite), that is: therefore, and finally .
The fitting values at the training inputs are
or what is the same:
Before modelling, stepwise regression [
45] was used to choose a significant subset of independent variables for every station. This method selects the predictors by automatic iteration forward procedure dropping and including variables. It stops when the lowest Akaike Information Criterion (AIC) is reached. The models were built based on
adjust when all variables were at 5% significance level and were validated by the k-fold cross validation method, which is explained later.
2.3. Multivariate Adaptive Regression Splines
Multivariate adaptive regression splines (MARSs) is a nonparametric statistical method developed by Friedman [
46] and is a generalization of recursive partitioning regression (RPR) that can consider complex relationships between a set of
k predictor independent variables, which are denoted by
and a dependent variable designated by
, and does not make starting assumptions about any type of functional relationship between input and output variables. The MARS model is defined as [
46,
47,
48].
where
is a function of the independent variables and their interactions,
is the intercept parameter,
is a vector of coefficients of the basis function,
is the total number of basis functions,
the spline basis function in the model and
is the fitting error.
To approximate the non-linear relationships between the independent variables
and the response variable Y, basis functions (BF) are used. They consist of a single spline function or the product of two or more spline functions for different predictors. Spline functions are piecewise linear functions, that is, truncated left-hand and right-hand functions, and take the form of hinge functions that are joined together smoothly at the knots.
where
is a constant called a node that specifies the boundary between the regions that have continuity from the base functions of the regions from left to right and that are smoothly joined at the given node and adaptively selected from the data. The “+” sign refers to the positive part and indicates a value of zero for negative values of the argument.
As stated in [
49], MARS forms reflected pairs for each predictor variable with knots of each value
,
with knots at each observed value
,
of that variable, where
is the sample size. The set of all possible pairs with the corresponding knots and the truncated linear basis functions can be expressed by the set
.
An adaptive regression algorithm is taken during a recursive partition strategy to automatically select the locations of the node or breakpoints, including the two-stage process: forward-stepwise regression selection and backward-stepwise elimination procedure [
50].
The first step, also called the construction phase, begins with the intercept and then sequentially adds to the model the predictor that best improves the fit; that is, when the maximum reduction in the sum-of-squares residual error occurs. The search for the best combination of variable and node is done iteratively. Considering a current model with
base functions, the following pair will be added to the model in the form of
. The
coefficients are estimated using the least-squares method [
44].
This process continues until a predetermined number of base functions (
) is reached or the
changes less than a threshold [
50]. A large number of BFs are added one after another and an overfitting model is created. Generally, the maximum number of BF is 2 to 4 times the number of predictor variables [
46].
The second step, also called the pruning phase, begins with the full model and simplifies it by eliminating terms by applying a backward procedure to avoid oversizing. MARS identifies the basis functions that contribute the least to the model and removes the least significant terms sequentially. The final model is chosen using the generalized cross-validation method (GCV) [
47], which is an adjustment of the sum-of-squares of the residuals and penalizes the complexity of the models by the number of basis functions and the number of knots.
where
M is the number of BF,
is the number of data sets,
denotes the predicted values of MARS and
is a penalty for each basis function, which takes the value of two for the additive model and three for an interaction model [
47]. The term
is the number of hinge functions knots [
44].
Note that MARS is a trademark and is used in this document as an acronym for multivariate adaptive regression splines.
The MARS model was made with the parameters degree = 9 and thresh = 1 × 10
−8. These parameters are explained in [
50].
2.4. Artificial Neural Networks
The artificial neural network (ANN) is a nonlinear and nonparametric statistical method designed to simulate the data processing of brain neurons [
51]. The ANN does not make any prior assumption about the model-building process or the relationship between input and output variables. Several studies [
52,
53] have indicated that MLP is the most suitable and widely-used class of neural network in atmospheric pollutants. The MLP is the most common neural network and is extensively developed in the following literature [
51,
54,
55].
The MLP network is divided into several layers: an input layer that has as many neurons as the model has independent variables, , a single hidden intermediate layer of neurons, , and an output layer with as many neurons as the model has dependent variables, .
In a previous study [
56] it was shown that a single hidden layer with a finite number of units is generally sufficient to fit any piecewise continuous function. In existing literature [
57], several proposals have been made to estimate the number of neurons, although the number of hidden units
was determined by trial-and-error training various networks and estimating the corresponding errors in the test data set. If the hidden layer has few neurons, many training errors occur due to insufficient fit or because the network could not converge during training. In contrast, too many hidden layer neurons lead to low training error, but due to overfitting, they memorize the dataset and cause high test error and poor generalization [
58].
Input variables are mapped by functions, called activation functions, into intermediate variables of the hidden layer, which are mapped to the output variables. MLP utilizes the following transformations [
40]:
,
,
, where
represents the inputs,
is the output of the hidden layer, an output layer with one dependent variable
, in this case, it is considered for generalization,
as the outputs of the network and
indicates the weight matrix between two layers.
and
are transfer functions of hidden layer and output layer. Both of these are logistic functions that map the output of each neuron to the interval [0,1].
All inputs were normalized as , where is the mean and the standard deviation of the observation dataset for each variable.
Neural networks fit to data using learning algorithms due to an iterative training process. In this case, a supervised learning algorithm characterized by the use of a target output was compared with the predicted output and by adjusting the weights. All weights and bias were initialized with random values taken from a standard normal distribution. The main steps of this iterative training procedure are as follows:
Perform forward propagation of the first vector of input variables through the whole MLP network, which ultimately calculates an output for inputs and current weights.
The input layer is just an information-receiving layer that receives the vectors of the input variables and redistributes them to the neurons in the hidden layer. This layer does not perform any type of processing on the data.
In the hidden layer, all inputs are multiplied by the weights and sum of all, taking into account the bias. The output of the i-th neuron of the hidden layer with
nodes is the one transformed by an activation function
. The output of the hidden layer is
where
is the weight connecting the i-th input with the j-th hidden node,
is a limit value known as the threshold value or bias,
and
. The activation function
f used in this paper is a non-linear and differentiable non-decreasing bounded function such as the logistic function
In the output layer, all the outputs of the hidden layer are multiplied by the weights and the sum of all, taking into account the bias. The output of the neuron
m-th of the output layer is transformed by an activation function
. The output of the output layer is:
where
is the weight connecting the
j-th output of the hidden layer with the m-th output node,
is the bias,
and
. The activation function used is the logistic function again.
During the training process, the predicted output will be different from the observed output . An error function is calculated as the sum of squared errors (SSE), where are the observations (input-output pairs) and the output nodes.
During the backward phase, the error is propagated backward through the network, but the neurons in the hidden layer only receive a part of the total error signal, which depends on the relative contribution that each neuron has made to the feed forward output. This whole forward and backward process is repeated for several iterations and stops when a given threshold is reached by all absolute partial derivatives
of the error function with respect to the weights [
59].
In this paper the Rprop algorithm was used, a resilient backpropagation with weight backtracking [
59,
60,
61], which modifies the weights by adding a learning rate to find a local minimum of the error function so that when
the weight is augmented and when
the weight is reduced.
The main difference between Rprop and the backpropagation algorithm is that only the sign of the gradient is used to update the weights. In this way convergence is accelerated.
where
is the iteration of gradient descent and
the weights.
is the learning rate that will be increased if the corresponding partial derivative keeps its sign or it will be decreased if the partial derivative of the error function changes its sign, that is [
60]:
where
, usually
.
In this study, the neuralnet library [
59] of the R computer software was used. The number of neurons used was 8 for all stations. To determine this parameter, a random station was taken and was determined by trial-and-error and k-fold cross validation, k = 5, taking into account that in some studies such as [
53] it is indicated that the number of neurons
H could be the sum of the number of input variables plus the number of the output variables and the maximum number of neurons in the hidden layer twice the number of neurons in the input layer, although [
53,
58] indicate that there is no a “rule of thumb” to determine this parameter and so there should be an iterative approach to it.
The criteria used to stop the algorithm was the threshold for the partial derivatives of the error function, setting the threshold of 1 and a limit of maximum steps of
The detailed explanation of the parameters of the computer program are indicated in reference [
59]. The logistic function was chosen instead of other commonly-used functions such as the hyperbolic tangent as the activation function [
44,
62] because the values of the dependent variable take positive values given that it is the measure of benzene concentration. The input variables were normalized as indicated. As it is a regression-based model, the output parameter was fixed as linear.
2.5. Support Vector Machines
The support vector machine (SVM) is a nonparametric machine learning method developed by Vapnik [
63] for both classification as regression. In this paper, the method was used for regression, that is, support vector regression (SVR). There are two basic versions of SVM regression, epsilon-SVR and nu-SVR denoted by ε-SVR and ν-SVR, the differences between which will be discussed later.
The SVR task consists of transforming the training dataset to a higher dimensional space through a non-linear mapping by a kernel function where a linear regression can be done, with , , being the number of samples and the dimension of the input dataset.
The SVR model is defined as , where is the intercept of the model indicating the bias, is the dot or scalar product of weight vector and the kernel function.
The error function is defined in [
63] by an ε-insensitive loss function that defines a tube so that if the predicted value is within the tube the loss is zero, that is:
In order to solve the limitations that result from the optimization problem, introduce slack variables
that depend on the position in relation to the tube: above (
) or below (
). Therefore, the problem as indicated in [
63,
64] is stated as follows:
Minimize
, with the following constraints:
where
is the cost parameter whose function is to control the trade-off between the complexity of the model and the maximum level of deviation above
. If the cost parameter is large, the model becomes more flexible since the effect of the errors measured by the slack variables, and the value of
increases. On the other hand, if
C is small, the model will be tighter and less likely to overfit, since the effect of the norm of weights vector is greater and leads to a better generalization [
65].
The problem can be solved in a simpler way in its dual formulation, also making it possible to extend the problem to nonlinear functions. Therefore, a standard dualization method is used using Lagrange multipliers for the optimization problem, as described in [
64,
66] and applying the Karush–Kuhn–Tucker (KKT) optimality conditions of the primal problem [
67]. The kernel function
returns the scalar product between the pairwise in a high-order dimensional space without explicitly mapping data. [
63].
where
is the Lagrangian and
are the Lagrange multipliers for all
considered. A saddle point is found by partial derivatives with respect to
[
63]:
After which the dual variables
are eliminated after the substitution of
and
. Thus, the dual optimization is as described:
for all i (16)
where
is the kernel function that satisfies the Merced condition explained in [
68] and can be written as
The radial basis function (RBF) kernel is used in this paper, that is,
and
is a parameter that regulates the behavior of the kernel.
Finally, after solving the dual problem, the prediction function
can be formulated in terms of Lagrange multipliers and the kernel function as:
ε-SVR uses parameters
and
to apply an optimization penalty for points that were not predicted correctly. As it is difficult to select an appropriate ε, in [
69] a new algorithm ν-SVR is introduced that automatically adjusts the ε parameter, which defines the tolerance margin, by introducing a new parameter
that makes it possible to control the number of support vectors and training errors, establishing the relationship between the number of support vectors that remain in the solution with respect to the total number of samples in the data set. ε parameter is introduced in the optimization problem formulation and is estimated automatically. This formulation is:
which can be solved in a similar way to ε-SVR:
In [
70] it is explained how to solve ν-SVR in detail and in [
66] the relationship between ε-SVR and ν-SVR is discussed.
A grid search [
67] was carried out to determine the parameters in one of the stations, randomly chosen, and these values were used in all stations. The study was undertaken with the following parameters: tolerance: 0.01, 0.05, 0.1, 0.5;
C: 1, 10, 50; ε: 0.10, 0.11, 0.12, 0.15, 0.16, 0.20, 0.25; gamma: 0.15, 0.17, 0.20, 0.25;
: 0.2, 0.5, 0.6, 0.75.
The parameters used for SVM algorithms are as follows:
For ε-SVR model: tolerance = 0.01, C = 10, ε = 0.11, gamma = 0.15
For ν-SVR model: tolerance = 0.01, C = 10, = 0.6.
where gamma is a kernel parameter that defines the influence of a single training set point and tolerance is the termination criterion.
2.6. Autoregressive Integrated Moving Average
Autoregressive integrated moving average (ARIMA) is a parametric method of univariate analysis of time series that have a stochastic nature, and whose methodology was described by Box and Jenkins [
71,
72,
73,
74,
75].
The variable , where n is the total number of observations, depends only on its own past and a set of random shocks, but on no other independent variables. It is; therefore, a matter of making forecasts about the future values of said variable using as information only that contained in the past values of the time series itself.
In the ARIMA model (p, d, q), p represents the order of the autoregressive process (AR), d is the number of differences that are necessary for the process to be stationary (I) and q represents the order of the moving average process (MA).
This methodology is fundamentally based on two principles [
71]:
(a) Selection of the model iteratively through four steps: identification to determine the order p, d, q of the model, estimation of the parameters, validation to verify that the model fits the data and prediction.
(b) Concise parameterization or parsimony for the representation of the model with the minimum number of possible parameters.
is defined as lag operator
as the result of delaying observations by one period, in general,
where
k is the number of lags and
as difference operator of the form
, then as a function of
operator, is
, in general,
[
73].
The autoregressive or AR(
) model is based on the fact that the value of the series at a given moment
t is the linear combination of the past values up to a maximum number
and a random error, that is,
, where
are the past values of the series,
are the constants, with values different from zero, that have to be estimated with the regression and
is a Gaussian white noise error random variable.
Another representation can be given as
, where
[
73].
The moving average or MA(
) model is represented by a relationship between the variable and the present and
past values of white noise, that is,
, where
are constants, with values different from zero and
the lagged errors.
Then
, where
[
73]
When a time series is non-stationary, the integrated process I(d) is the method to make the time series near-stationary by differencing, where d is the number of differentiations necessary to make the series stationary, that is, using lag and difference operators:
Hence, an ARIMA (
p,
d,
q) model can be written as follows, where
is a constant:
as indicated in [
76].
A stationary model is an ARMA (p, q) process, that is an ARIMA (p, 0, q).
To adjust the best ARIMA model for each station, the auto.arima function [
77] of the forecast library of the R software was used. The value of the parameters
p,
d,
q is indicated in Table 7.
2.7. Vector Autoregressive Moving Average
Vector autoregressive moving-average (VARMA) is a parametric method of multivariate analysis time series that have a stochastic nature. They are a generalization of univariate models ARMA, with the difference that instead of a single variable there are several variables; that is, they study the relationships between several time series, without distinguishing between exogenous and endogenous variables. A detailed explanation of the model can be found in [
71,
78].
In the VARMA model (p, q) p represents the order of the autoregressive process (VAR) and q represents the order of the moving average process (VMA).
This methodology is fundamentally based on two principles [
71]:
(a) Selection of the model iteratively. First, determination of the p, q order of the model, estimation of the parameters, validation that the model fits the data and prediction.
(b) Representation of the model with the minimum number of possible parameters.
is defined as lag operator in the same way that in the previous section
where
k is the number of lags [
73].
Vector autoregressive or VAR() is a model in which the value of the series at a given time are a linear combination of the past values of the variable and of the other variables up to a maximum number and a random error vector, that is, where is a vector of variables to be predicted at time , is a dimensional vector of constants, are matrices for and not a null matrix. are the multivariate white noise vectors with a positive definite covariance matrix and zero mean.
Another representation with
operator can be given as
, where
is a degree
polynomial of matrices and
is
identity matrix [
71].
The vector moving average or VMA(
) model is represented by a relationship between the time series and the present and
past values of white noise, that is,
, where
are
matrices and
not a null matrix,
.
is constant vector containing the mean of the process.
are white noise series. Using
lag operator, the model becomes
, where
is a matrix polynomial of order
and
is
identity matrix [
78].
The vector autoregressive moving-average VARMA (
,
) can be written as follows:
The VARMA parameters p and q have been determined by trial-and-error, choosing those that allow determining a smaller RMSE error. These parameters are shown in Table 8.
2.8. Performance Measurements
In order to make comparisons of the performance measures between the machined learning models, for each model the same parameters were established for all the stations, as indicated in the corresponding sections.
The different models that have been developed in this study are evaluated for their accuracy by root mean squared error (RMSE) [
79,
80], mean absolute error (MAE) [
80,
81] and bias [
80] according to the following equations:
As a method to estimate the prediction error, a k-fold cross validation was used for machine learning algorithms. This method uses part of the data to fit the model and another part to test it [
44]. The dataset has been divided into k = 5 equal parts.
To validate the model of the time series algorithms, the data was divided into two sets, 80% of the initial data to fit the algorithm. A prediction was made on 20% of the final observations, which are the values used to calculate the RMSE, MAE and bias errors.
3. Results and Discussion
In this section the performance of the forecasts performed with the MLR, MARS, MLPNN, SVM, ARIMA and VARMA models are presented.
Table 3 shows RMSE, MAE and bias values for the MLR models of all the stations, while
Table 4 shows the same information for the MARS models while
Table 5,
Table 6,
Table 7 and
Table 8 do the same for SVM, MLPNN with a single hidden layer with eight neurons, ARIMA and VARMA models, respectively. In the case of SVM, both ε-SVR and ν-SVR regressions were tested.
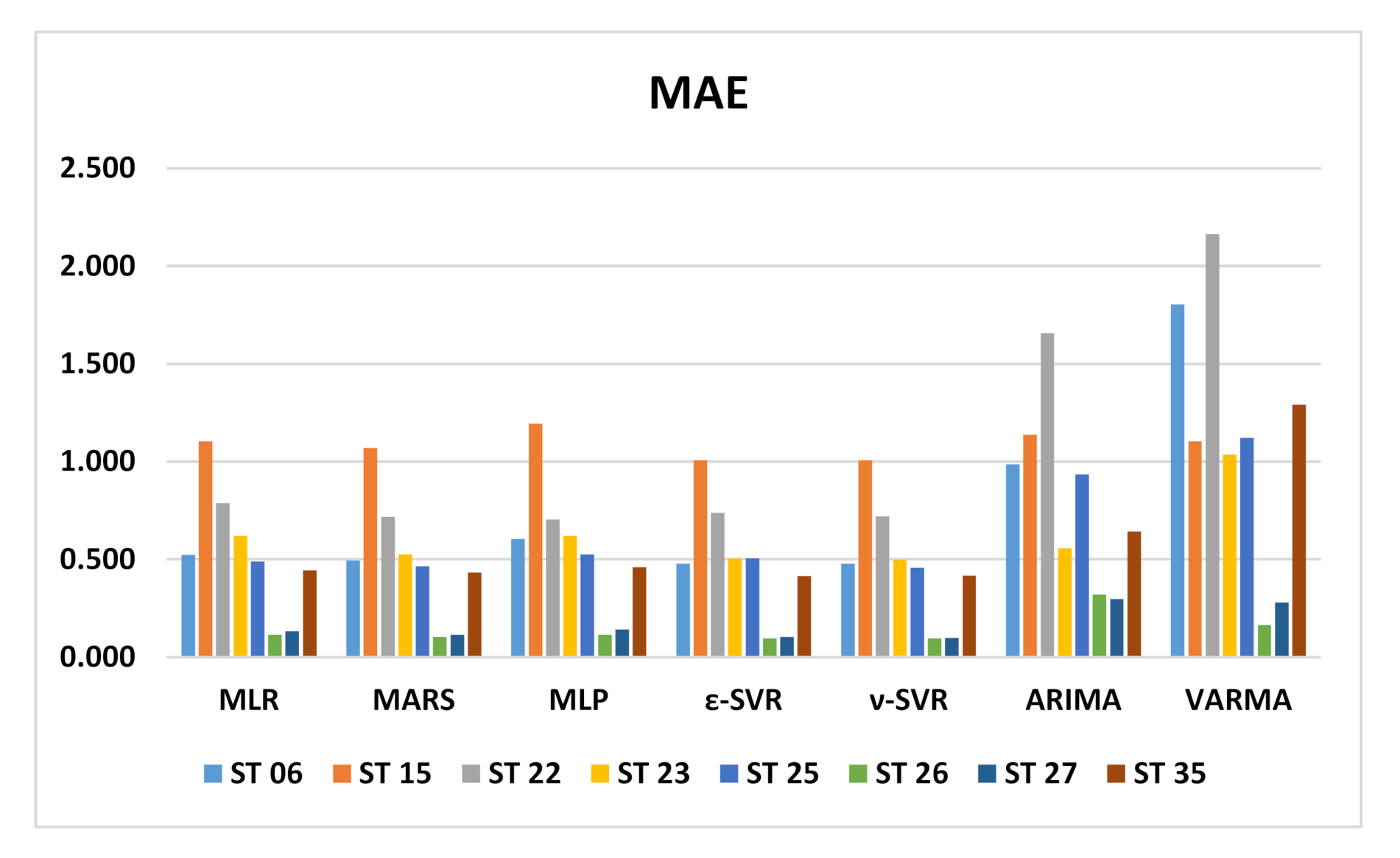
Figure 2 shows a comparison of all RMSE values for all models and stations, the same is made for MAE in
Figure 3 and BIAS in
Figure 4.
For station 06, RMSE values are very similar and close to unity for the MLR, MARS and SVM models. The lowest value corresponds to MARS model with 0.936. RMSE value for MLP is slightly higher at 1.171. The highest values were reached with the time series models with 1.654 for ARIMA and 2.106 for VARMA. A similar behavior occurs with MAE, as the lowest value for the ε-SVR model is 0.478 and MLR, ν-SVR and MARS show values close to 0.5. MLP has a slightly higher value with 0.606 and the time series models reach the highest values, with 1.805 being the highest of the VARMA model. Regarding the bias error, all the models have negative values, so the prediction tends to be higher than the observed value. Again, the MLR, MARS and SVR models reached values close to zero and the time series models have a greater bias with values of 1.449 for VARMA.
RMSE values for station 15 are higher than those for station 06 overall. In this case, the lowest RMSE value was obtained for the ARIMA model, with 1.474. The SVR, MARS and MLR models have RMSE between 1.7 to 1.8 and the highest value was obtained for the MLP model, with 2.027. The MAE values are very close to each other, from 1.006 for ε-SVR to 1.195 for MLP, including time series models. However, the worst bias error values were obtained for the ARIMA model with −0.922 followed by VARMA with 0.6613. The rest of the models have a bias error close to zero, with positive values for MLR and MARS, together with VARMA.
Again, at station 22, the RMSE values are very similar for machine learning models, ranging from 1.220 for MLP to 1.304 for MLR. The time series models present much higher RMSE values, namely 3.008 for ARIMA and 2.642 for VARMA. The same occurs with the MAE values, which all remain at 0.7, varying from 0.704 for MLP to 0.788 for MLR. The MAE value for the time series models is 1.658 for ARIMA and the highest value is for VARMA, with 2.164. The bias error has values very close to zero for all machine learning models. MLR and ε-SVR have positive values, while the MARS, ν-SVR and MLP models have negative values of the bias error. Regarding the bias in time series models, it is 0.864 for VARMA and −1.6490 for ARIMA.
Station 23 does not have such a differentiated error pattern between machine learning models and early series models, and the error values are more clustered. The lowest value for RMSE was reached for both SVR models with 1.095 and the highest value for MLP, with 1.360. Something similar occurs with the MAE error. The lowest error was achieved for ν-SVR with 0.498 and the highest value for MLP, with 0.621. The lowest bias error was reached for MLR with and the highest value for VARMA with 0.679, with positive values for MLR and MARS and negative for the rest of the models.
At station 25, the RMSE error ranges from 1.015 for the MARS model to 1.397 for the VARMA model. Time series models have slightly higher RMSE than machine learning models. Regarding MAE, the time series models have approximately twice the value of the other models, the lowest value being 0.458 for ν-SVR and the highest for VARMA, with 1.123. The same goes for the bias error. All bias errors in machine learning models are negative and close to zero with the lowest value for MLR. On the other hand, the time series models present positive values; that is, the observed value is greater than that predicted by these models, with the highest bias value for VARMA, with 0.579.
At station 26, the ARIMA model is the one that differs the most from the rest of the models, which show similar behavior for the three errors. The lowest value of RMSE was reached for the MARS and SVR models with 0.24, followed by MLP and MLR with 0.25 and 0.27 for VARMA. The ARIMA model has an RMSE of 0.36. The smallest MAE error was achieved in SVR, with 0.097. The rest of the models vary from 0.104 for MARS to 0.164 for VARMA, reaching 0.319 for the ARIMA model. The smallest bias error is for MLR, with a positive 5 × 10−6 value. In the rest of the models the values are negative, except ARIMA, which reached a value of 0.243.
All machine learning models show similar behavior at station 27, with the lowest RMSE value for the MARS model being 0.271. The time series models have a somewhat higher RMSE with a higher value for the ARIMA model, with 0.517. The lowest value of MAE is 0.100 and was achieved with the ν-SVR model. The behavior is similar to that of the RMSE error. The highest value was obtained for ARIMA, with 0.298. Regarding the bias error, the models that perform better are MLR and MARS, with positive values of 10 × 10−5. The rest of the models have a negative bias error and the highest value was obtained for the VARMA model, with −0.195.
The behavior of the RMSE error in station 35 was very similar for all models, acquiring the lowest value for ε-SVR with 0.880 and the highest value for ARIMA, with 1.088. Machine learning models have a similar MAE error, the smallest being 0.416 for ε-SVR. Time series models have a slightly larger MAE error of 0.643 for ARIMA. The bias error is negative for all models except for VARMA, being very close to zero and the lowest value on the order of −10 × 10−4 corresponds to MLR. The RVS models show a bias error of −0.02, while the bias error of the ARIMA model is −0.318.
At stations 15 and 23, the MLP model has a very high RMSE in relation to the machine learning models, compared to the homogeneity of the RMSE error performance in the rest of the stations. Station 35 has a very homogeneous RMSE error for all models. In stations 06 and 22, the machine learning models also have a homogeneous RMSE, but there is a clear difference with respect to the time series models, whose RMSE is higher. Station 15 has the highest RMSE and MAE in machine learning models, but this does not happen in time series models. Stations 26 and 27 have clearly lower RMSE and MAE values in all models, including time series models. The worst bias error for the ARIMA model is found at station 22. This model is the one that, together with VARMA, has the highest bias error for all stations, in general. The SVM models, both ε-SVR and ν-SVR, perform in a very similar way.
4. Conclusions
This paper studies the relationship between four predictors and benzene in order to establish predictions at eight stations in the community of Madrid, Spain, using seven mathematical models: MLR, MARS, ε-SVR, ν-SVR, MLP, ARIMA and VARMA.
Stations 06, 15, 22 and 35 are stations that are located in the city center and have observations with an average concentration of benzene higher than the rest of the stations located in the east, on the outskirts of the city or near the airport.
The models were evaluated using RMSE, MAE and bias. The validation of the machine learning models was carried out using k times the cross validation with k = 5 and with 20% of the observations for the time series models.
The results showed that, in general, machine learning models are more effective at predicting than time series models, but this does not happen at all stations, since at station 15 the lowest RMSE occurs in the VARMA model. The highest error values occur for the time series models, except at station 15, where they were obtained for the MLP model.
MLR, MARS, SVR and MLP follow similar behavior patterns for all stations and stations 26 and 27 show the lowest errors.
The time series models, ARIMA and VARMA, present greater variations in the values obtained for the stations, not following the same pattern as the machine learning models.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}