A Differential Game with Random Time Horizon and Discontinuous Distribution



{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Problem Formulation
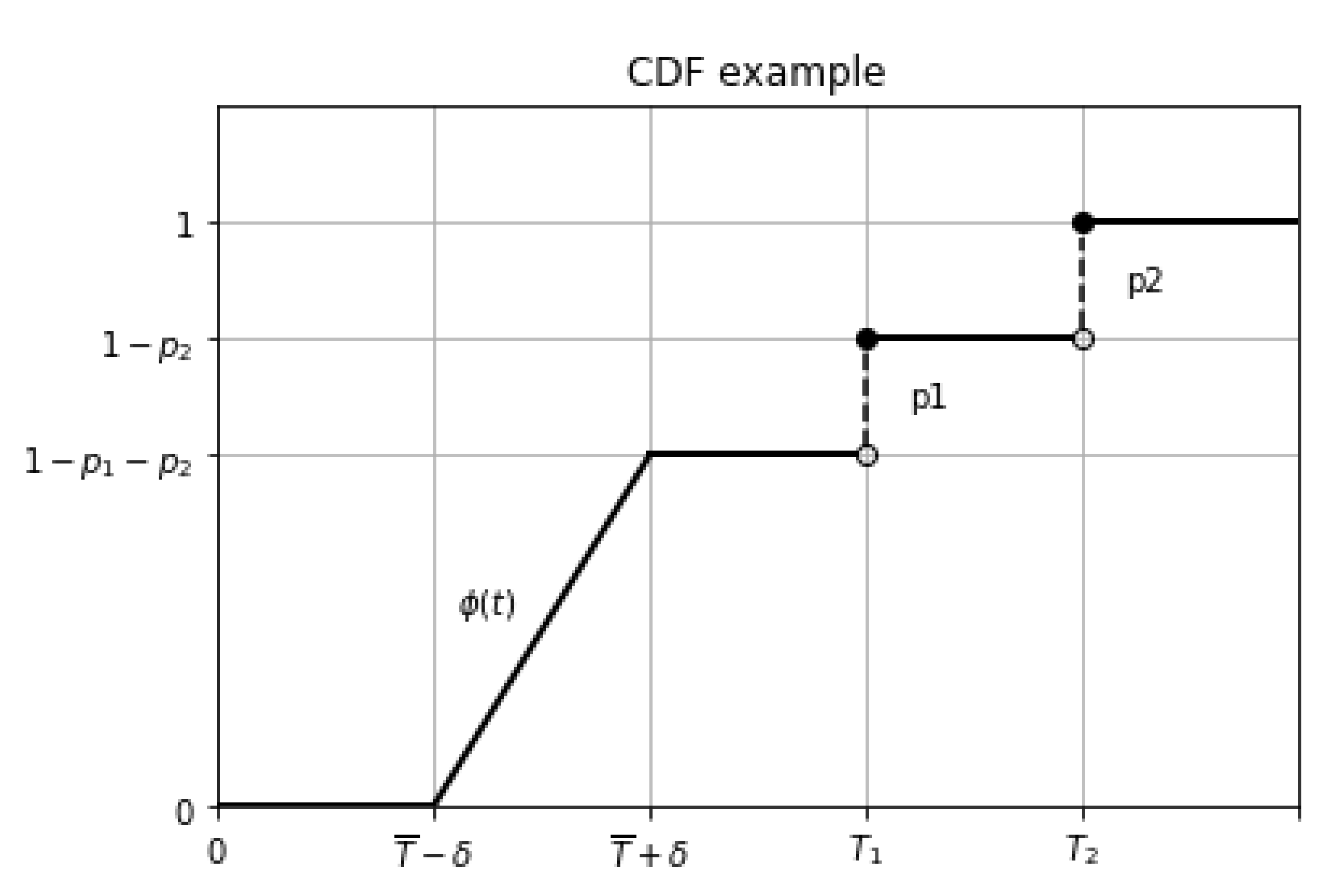
- the interval over which the game is played is , where and T are random variables defined on the interval , . The random variable corresponds to the discontinuous CDFwhere is assumed to be an absolutely continuous non-decreasing function, , , .The CDF of the random variable is assumed to be discontinuous with two jumps occurring on the bounded interval. The example of such CDF is given on Figure 1;
- the controls are open-loop strategies;
- the controls belong to the sets of admissible controls , which consist of all measurable functions on the interval , taking values in the set of admissible control values , which are in turn convex compact subsets of ;
- the instantaneous payoff of the i-th player at the moment is defined as . To shorten the notation, we writewhere ;
- in the deterministic case the integral payoff iswhere is a known moment of the end of the game, ;
- in the case of random time horizon, the mathematical expectation of the integral payoff is considered. Thus, the i-th player’s integral functional is:
3. Model Example
- –compute parameterized by ;
- –compute parameterized by , while using the previously obtained expression for that depends on ;
- –compute .
4. Computations
4.1. Intervals Calculations
4.2. Computation of the Parameters
- –compute parameterized by ;
- –compute parameterized by , while using the previously obtained expression for that depends on ;
- –compute .
5. Analysis of the Limiting Cases
5.1. Assumption of no Jumps in CDF
5.2. Assumption of a Piece-Wise Constant CDF
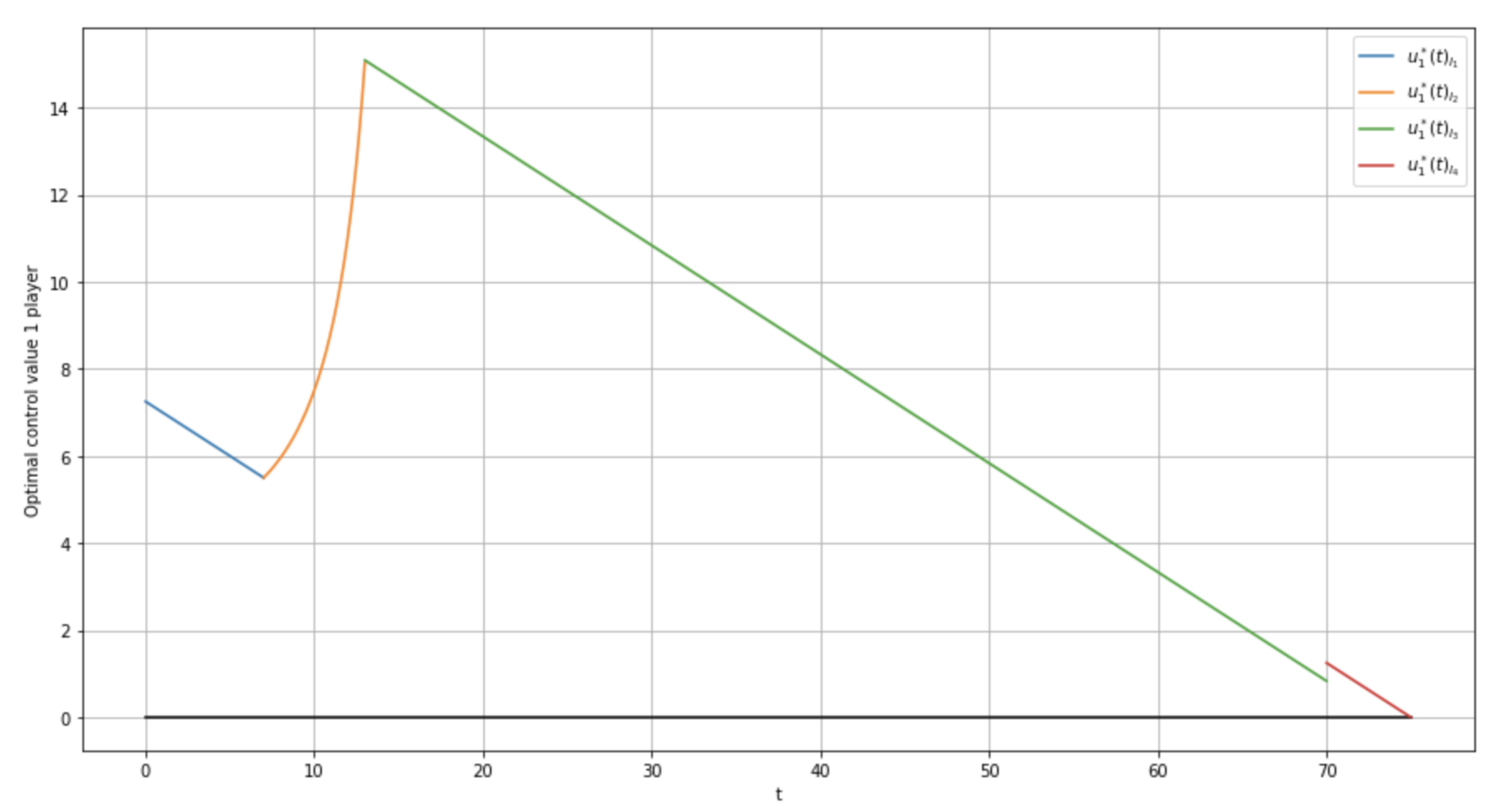
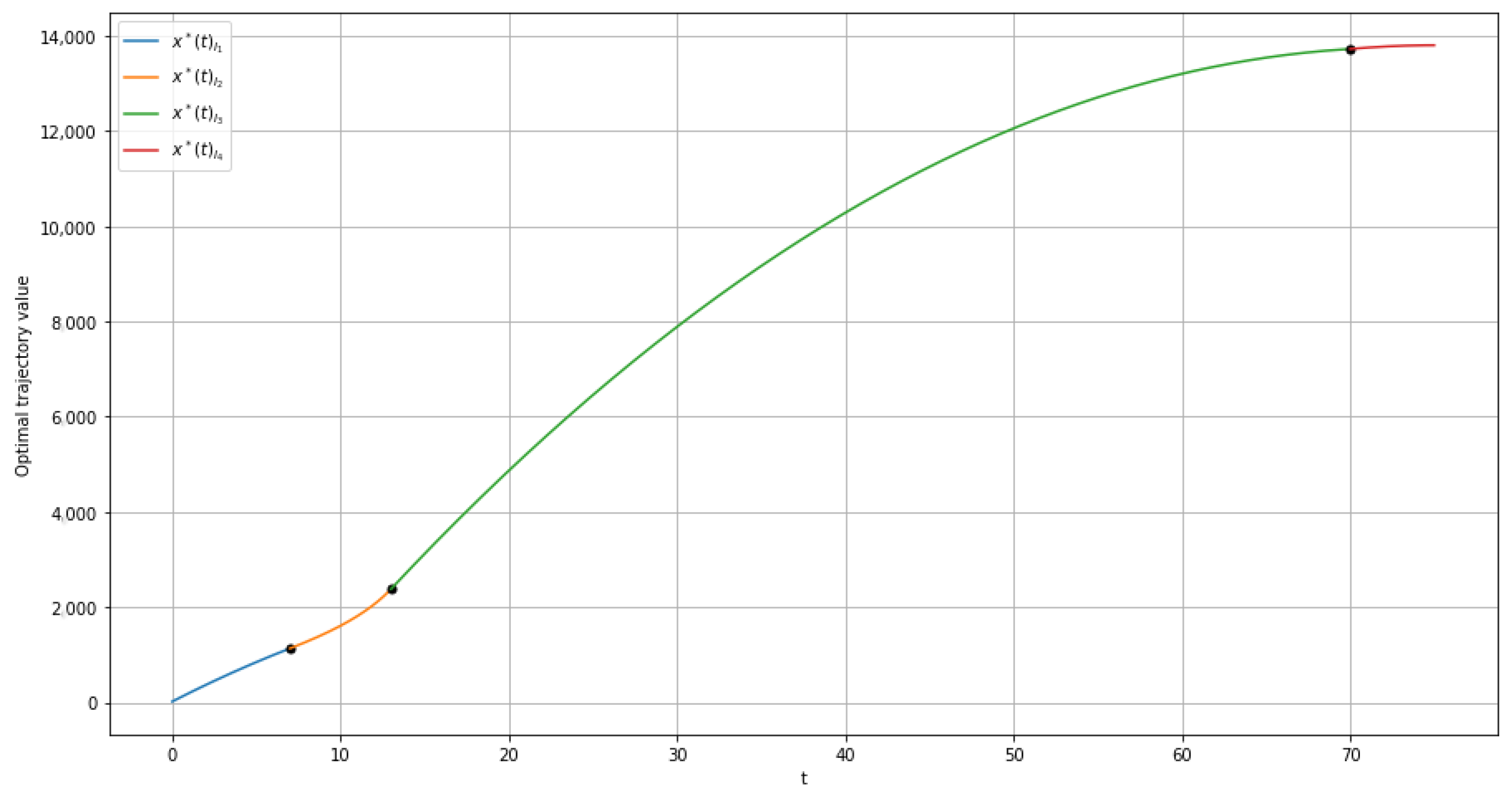
6. Numeric Example
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Interval I1
Appendix A.2. Interval I2
Appendix A.3. Interval I3
Appendix A.4. Interval I4
References
- Basar, T.; Olsder, G. Dynamic Noncooperative Game Theory; SIAM: New York, NY, USA, 1999. [Google Scholar]
- Petrosyan, L.; Danilov, N. Cooperative Differential Games and THEIR Applications; Izd. Tomskogo University: Tomsk, Russia, 1982. [Google Scholar]
- Dockner, E.J.; Jørgensen, S.; Long, N.V.; Sorger, G. Differential Games in Economics and Management Science. In Cambridge Books; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Yeung, D.; Petrosyan, L. Cooperative Stochastic Differential Games; Springer Science, Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Yaari, M. Uncertain lifetime, life insurance, and the theory of the consumer. Rev. Econ. Stud. 1965, 32, 137–150. [Google Scholar] [CrossRef]
- Petrosyan, L.; Murzov, N. Game-theoretic problems of mechanics. Litovsk. Math. Sb. 1966, 7, 423–433. [Google Scholar]
- Petrosyan, L.; Shevkoplyas, E. Cooperative differential games with stochastic time. Vestn. Petersburg Univ. Math. 2000, 33, 18–23. [Google Scholar]
- Marin-Solano, J.; Shevkoplyas, E. Non-constant discounting and differential games with random time horizon. Automatica 2011, 47, 2626–2638. [Google Scholar] [CrossRef]
- Gromova, E.; Malakhova, A.; Palestini, A. Payoff Distribution in a Multi-Company Extraction Game with Uncertain Duration. Mathematics 2018, 6, 165. [Google Scholar] [CrossRef]
- Gromova, E.; Tur, A. On the form of integral payoff in differential games with random duration. In Proceedings of the 2017 XXVI International Conference on Information, Communication and Automation Technologies (ICAT), Sarajevo, Bosnia-Herzegovina, 26–28 October 2017; pp. 1–6. [Google Scholar]
- Gromov, D.; Gromova, E. On a Class of Hybrid Differential Games. Dyn. Games Appl. 2017, 7, 266–288. [Google Scholar] [CrossRef]
- Reddy, P.V.; Schumacher, J.M.; Engwerda, J.C. Analysis of optimal control problems for hybrid systems with one state variable. SIAM J. Control. Optim. 2020, 58, 3262–3292. [Google Scholar] [CrossRef]
- Bonneuil, N.; Boucekkine, R. Optimal transition to renewable energy with threshold of irreversible pollution. Eur. J. Oper. Res. 2016, 248, 257–262. [Google Scholar] [CrossRef]
- Elliott, R.J.; Siu, T.K. A stochastic differential game for optimal investment of an insurer with regime switching. Quant. Financ. 2011, 11, 365–380. [Google Scholar] [CrossRef]
- Reddy, P.; Schumacher, J.; Engwerda, J. Optimal management with hybrid dynamics—The shallow lake problem. In Mathematical Control Theory I; Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–136. [Google Scholar]
- Pontryagin, L.; Boltyanskii, V.; Gamkrelidze, R.; Mishchenko, E. The Mathematical Theory of Optimal Processes; Interscience: New York, NY, USA, 1962. [Google Scholar]
- Gromov, D.; Gromova, E. Differential games with random duration: A hybrid systems formulation. Contrib. Game Theory Manag. 2014, 7, 104–119. [Google Scholar]
- Tur, A.V.; Magnitskaya, N.G. Feedback and Open-Loop Nash Equilibria in a Class of Diferential Games with Random Duration. Contrib. Game Theory Manag. 2020, 13, 415–426. [Google Scholar] [CrossRef]
- Gromova, E.; Magnitskaya, N. Solution of the differential game with hybrid structure. Contrib. Game Theory Manag. 2019, 12, 159–176. [Google Scholar]
- Feichtinger, G.; Jørgensen, S. Differential game models in management science. Eur. J. Oper. Res. 1983, 14, 137–155. [Google Scholar] [CrossRef]
- Jørgensen, S.; Zaccour, G. Developments in differential game theory and numerical methods: Economic and management applications. Comput. Manag. Sci. 2007, 4, 159–181. [Google Scholar] [CrossRef]
- Malakhova, A.P.; Gromova, E.V. Strongly Time-Consistent Core in Differential Games with Discrete Distribution of Random Time Horizon. Math. Appl. 2018, 46, 197–209. [Google Scholar] [CrossRef]
- Abdel-Wahab, O.; Bentahar, J.; Otrok, H.; Mourad, A. Resource-Aware Detection and Defense System Against Multi-Type Attacks in the Cloud: Repeated Bayesian Stackelberg Game. IEEE Trans. Dependable Secur. Comput. 2019. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaremba, A.; Gromova, E.; Tur, A. A Differential Game with Random Time Horizon and Discontinuous Distribution. Mathematics 2020, 8, 2185. https://doi.org/10.3390/math8122185
Zaremba A, Gromova E, Tur A. A Differential Game with Random Time Horizon and Discontinuous Distribution. Mathematics. 2020; 8(12):2185. https://doi.org/10.3390/math8122185
Chicago/Turabian StyleZaremba, Anastasiia, Ekaterina Gromova, and Anna Tur. 2020. "A Differential Game with Random Time Horizon and Discontinuous Distribution" Mathematics 8, no. 12: 2185. https://doi.org/10.3390/math8122185
APA StyleZaremba, A., Gromova, E., & Tur, A. (2020). A Differential Game with Random Time Horizon and Discontinuous Distribution. Mathematics, 8(12), 2185. https://doi.org/10.3390/math8122185