Optimal Exploitation of a General Renewable Natural Resource under State and Delay Constraints

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Formulation
2.1. The Model
- is the time at which the manager gives the order to harvest. The harvest starts only at time , with ℓ a positive constant representing the delay.
- is the time when the harvest is stopped.

2.2. The Value Function
3. PDE Characterization
3.1. Extension of the Value Function
3.2. Dynamic Programming Principle
3.3. Growth Property
3.4. Viscosity Properties and Uniqueness
- If with , that means the manager has given the order to harvest, but this has not yet started, which implies:with for any function .
- If with , that means the manager harvests, and he/she can decide to stop this, which implies:with , and the operator is defined for any function by:
- If with , the manager must stop the harvest, so we have:
- If with , that means the manager has finished harvesting, but he/she has not yet sold his/her harvest, which implies:
- If with , that means the manager sells his/her harvest, which implies:
- If with , then the manager can do nothing, which implies:
- If with , then the manager can decide to start a harvest:The operator is defined for any function by:
- for any and such that:we have
- for any and
- for any with and such that:we have:
- for any , and :
- for any and such that:we have:
4. Numerical Results
4.1. The Discrete Problem
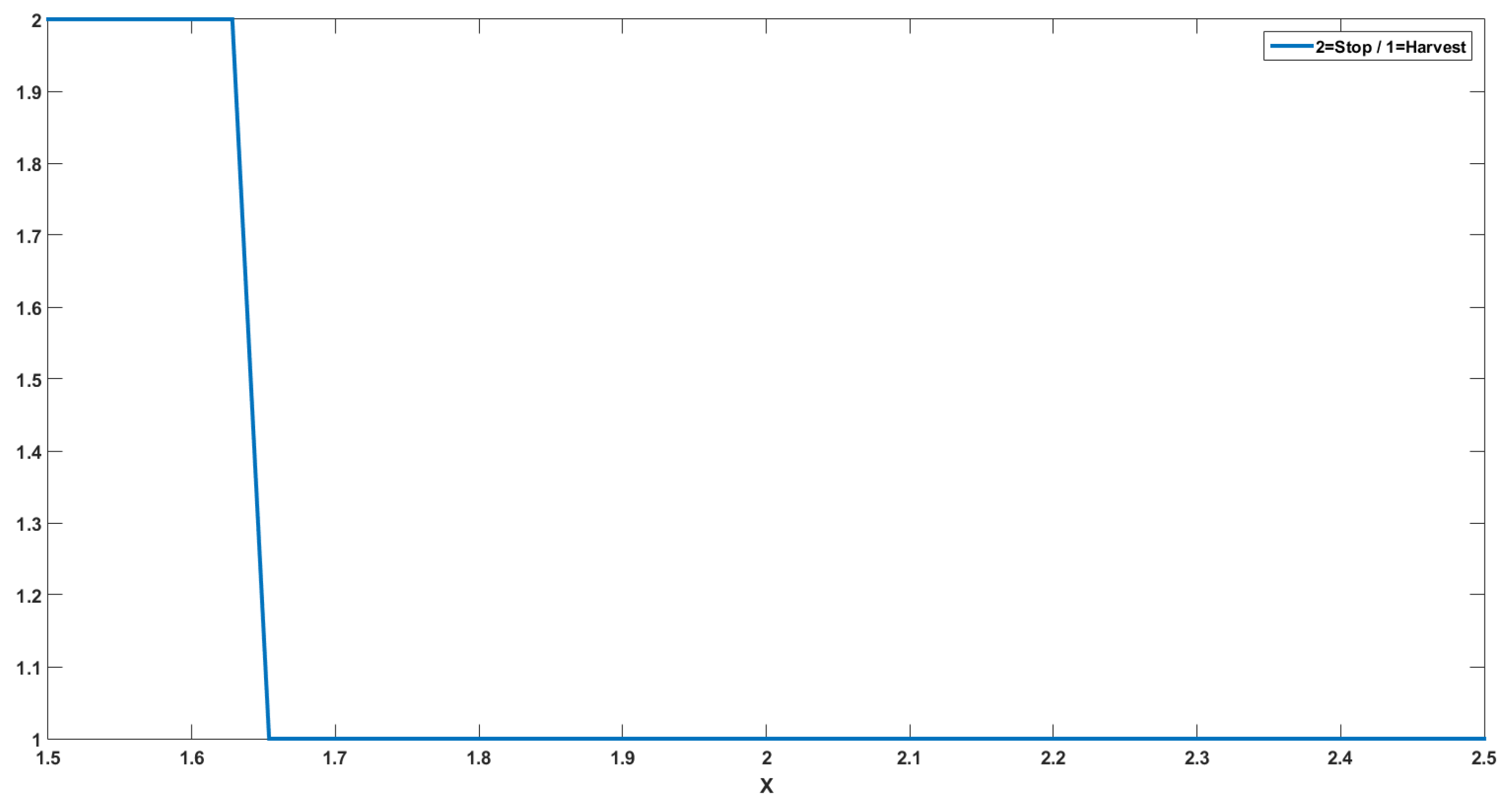
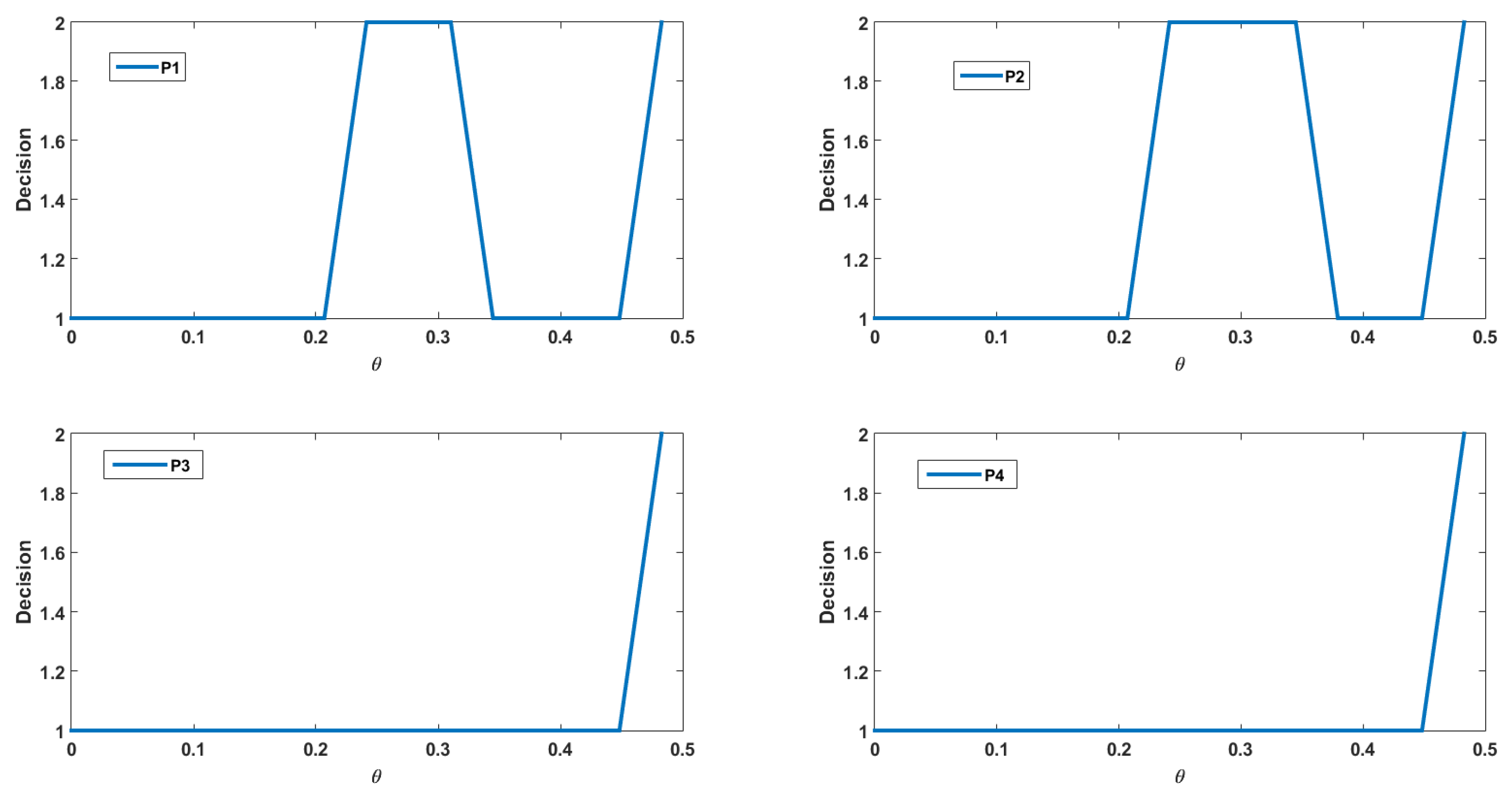
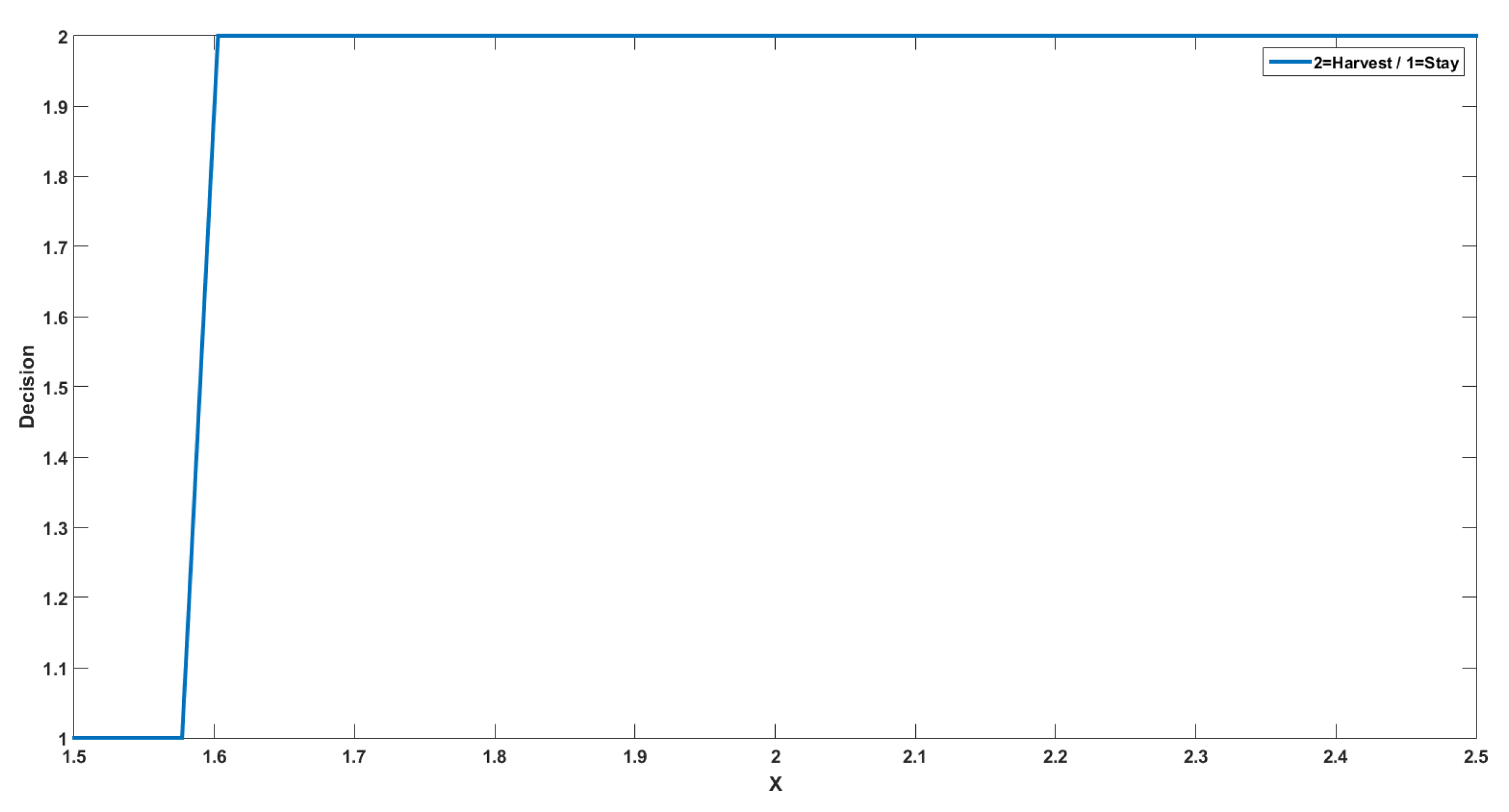
4.2. Numerical Interpretations
- .
- .
- Penalty function: .
- Gain function: .
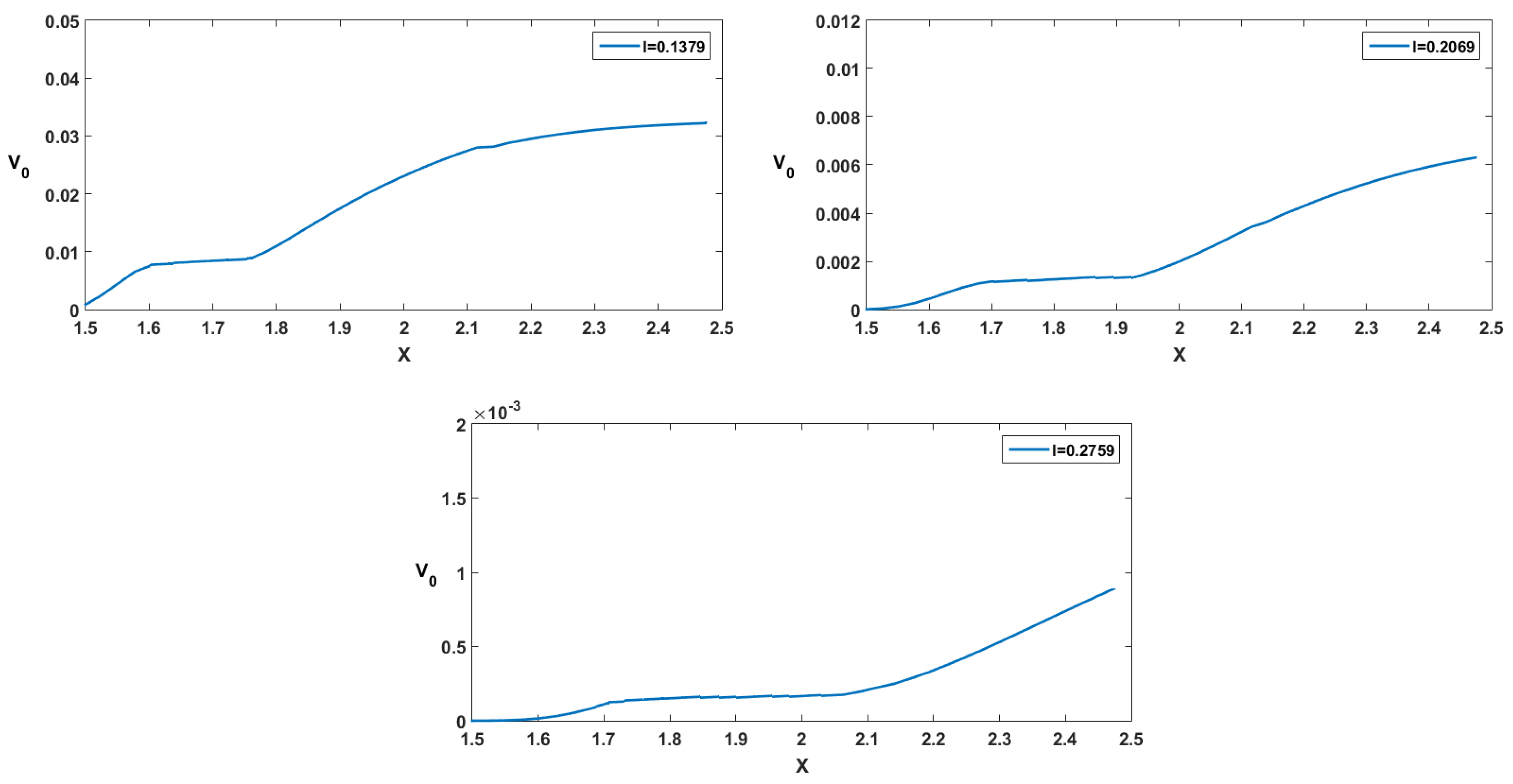
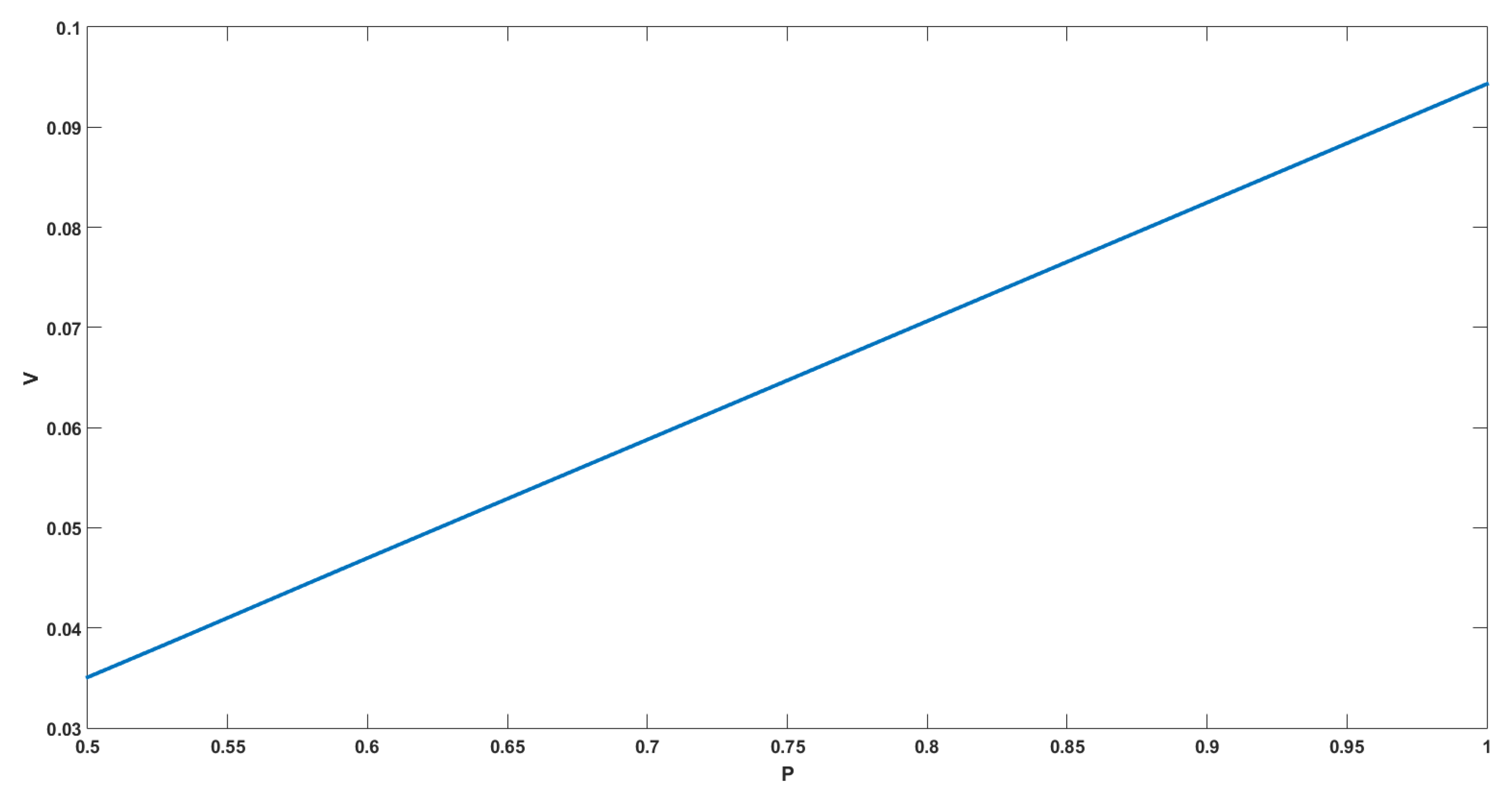
- : in this case the, value function is increasing since if we have at the initial time, then we will have a.s., and the bigger is the resource when we harvest, the more we can harvest since the function g is increasing;
- : in this case, the value function is constant since if we have at the initial time then we will have a.s., so we harvest exactly the same quantity in the two cases;
- : in this case, the value function is increasing since if we have at the initial time, then the resource decreases, but we will have a.s.
4.3. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Dynamic Programming Principle
- Consistency of the admissible strategies: and -a.s.
- Consistency of the gain function:
- If and , then we have:
- If and , then we have:
- If and , then we have:
Appendix B. Viscosity Properties
- We first prove the viscosity supersolution property. Fix , and let and , such that:If and , we can take the immediate control so we obtain by Theorem 1:If and , we can take the immediate control so we obtain by Theorem 1:From the definition of , there exists a sequence of such that:We define . By continuity of , we get as .Applying Proposition A1 with . We have for n large enough:
- if :where is the strategy and then the manager follows the optimal strategy after this date,
- if :where is the strategy and then the manager follows the optimal strategy after this date,
- if :where is the strategy and then the manager follows the optimal strategy after this date.
We get for n large enough from (A3) and the three previous inequalities:Applying Itô’s formula, we get:- if and :
- if and :
- if and :
- if and :Sending n to ∞, we get the supersolution property from the mean value theorem.
- We turn to the viscosity subsolution. Fix , and let and , such that:If for with , and for with , then the subsolution inequality holds trivially. Consider now the case for with , and for with , and argue by contradiction by assuming on the contrary that:
- if , and :
- if , and :
- if , :
- if , :
By continuity of and its derivatives, there exists some s.t. for all , we have:- if , and :
- if , and :
- if , :
- if , :
From the definition of , there exists a sequence of with (resp. ) if (resp. ) such that:and there exists a sequence of (resp. ) if (resp. ) such that:By Theorem 1 we can find for each a control such that for all :and for all , we have:and for all , we have:We now choose where . Therefore, we get:Now, since and on , we get:Applying Itô’s formula to between 0 and , we then get:This implies:On the other hand, we have by (A6):From (A7), we then get sending n to infinity and to zero:Concerning the proof for and , we consider two cases: the case and the case .We start with the case . In this case we consider where . Therefore, we have:Now, since and on , we get:Applying Itô’s formula to between 0 and , we then get:This implies:On the other hand, we have by (A8):From (A9), we then get sending n to infinity and to zero:which is a contradiction.The case where , is analogous to the previous case and we also obtain a contradiction.
Appendix C. Uniqueness
References
- Lande, R.; Engen, S.; Sæther, B.-E. Optimal harvesting of fluctuating populations with a risk of extinction. Am. Nat. 1995, 145, 728–745. [Google Scholar] [CrossRef]
- Alvarez, L.; Keppo, J. The impact of delivery lags on irreversible investment under uncertainty. Eur. J. Oper. Res. 2002, 136, 173–180. [Google Scholar] [CrossRef]
- Bar-Ilan, A.; Strange, W. Investment lags. Am. Econ. Rev. 1996, 8, 610–622. [Google Scholar]
- Alvarez, L.; Shepp, L. Optimal harvesting of stochastically fluctuating populations. J. Math. Biol. 1998, 37, 155–177. [Google Scholar] [CrossRef]
- Bruder, B.; Pham, H. Impulse control problem on finite horizon with execution delay. Stoch. Process. Appl. 2009, 119, 1436–1469. [Google Scholar] [CrossRef] [Green Version]
- Oksendal, B.; Sulem, A. Optimal Stochastic Impulse Control with Delayed Reaction. Appl. Math. Optim. 2008, 58, 253–298. [Google Scholar] [CrossRef] [Green Version]
- Kharroubi, I.; Lim, T.; Vath, V.L. Optimal Exploitation of a Resource with Stochastic Population Dynamics and Delayed Renewal. J. Math. Anal. Appl. 2019, 477, 627–656. [Google Scholar] [CrossRef] [Green Version]
- Mnif, M.; Pham, H. A model of optimal portfolio selection under liquidity risk and price impact. Financ. Stochastics 2007, 11, 51–90. [Google Scholar]
- Soner, H.M. Optimal Control with State-Space Constraints I. SIAM J. Control. Optim. 1986, 24, 552–561. [Google Scholar] [CrossRef]
- Soner, H.M. Optimal Control with State-Space Constraints II. SIAM J. Control. Optim. 1986, 24, 1110–1122. [Google Scholar] [CrossRef]
- Skiadas, C.H. Exact Solutions of Stochastic Differential Equations: Gompertz, Generalized Logistic and Revised Exponential. Methodol. Comput. Appl. Probab. 2010, 12, 261–270. [Google Scholar] [CrossRef]
- Gaïgi, M.; Vath, V.L.; Mnif, M.; Toum, S. Numerical Approximation for a Portfolio Optimization Problem Under Liquidity Risk and Costs. Appl. Math. Optim. 2016, 74, 163–195. [Google Scholar] [CrossRef]
- Guilbaud, F.; Mnif, M.; Pham, H. Numerical methods for an optimal order execution problem. J. Comput. Financ. 2013, 16, 3–45. [Google Scholar] [CrossRef] [Green Version]
- Pagès, G.; Pham, H.; Printems, J. Optimal quantization methods and applications to numerical problems in finance. In Handbook on Numerical Methods in Finance; Rachev, S., Ed.; Birkhäuser: Boston, MA, USA, 2004; pp. 253–298. [Google Scholar]
- Bouchard, B.; Touzi, N. Weak dynamic programming principle for viscosity solutions. SIAM J. Control. Optim. 2011, 49, 948–962. [Google Scholar] [CrossRef] [Green Version]
- Dellacherie, C.; Meyer, P.A. Probabilités et Potentiel, I–IV; Hermann: Paris, France, 1975. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gaïgi, M.; Kharroubi, I.; Lim, T. Optimal Exploitation of a General Renewable Natural Resource under State and Delay Constraints. Mathematics 2020, 8, 2053. https://doi.org/10.3390/math8112053
Gaïgi M, Kharroubi I, Lim T. Optimal Exploitation of a General Renewable Natural Resource under State and Delay Constraints. Mathematics. 2020; 8(11):2053. https://doi.org/10.3390/math8112053
Chicago/Turabian StyleGaïgi, M’hamed, Idris Kharroubi, and Thomas Lim. 2020. "Optimal Exploitation of a General Renewable Natural Resource under State and Delay Constraints" Mathematics 8, no. 11: 2053. https://doi.org/10.3390/math8112053
APA StyleGaïgi, M., Kharroubi, I., & Lim, T. (2020). Optimal Exploitation of a General Renewable Natural Resource under State and Delay Constraints. Mathematics, 8(11), 2053. https://doi.org/10.3390/math8112053