Automated Maintenance Data Classification Using Recurrent Neural Network: Enhancement by Spotted Hyena-Based Whale Optimization

 ,
,  ,
, 
Abstract
1. Introduction
- To address the challenges encountered by the machine learning algorithm for the data classification of mechanical maintenance data effectively and efficiently;
- To establish an automatic classification system using feature extraction and feature selection using different types of mechanical maintenance datasets;
- To develop and implement a hybrid meta-heuristic algorithm for the feature selection and classification of mechanical maintenance data;
- To analyze and validate the performance of the proposed model using diverse performance measures, demonstrating the reliability and effectiveness of the developed model.
2. Literature Review
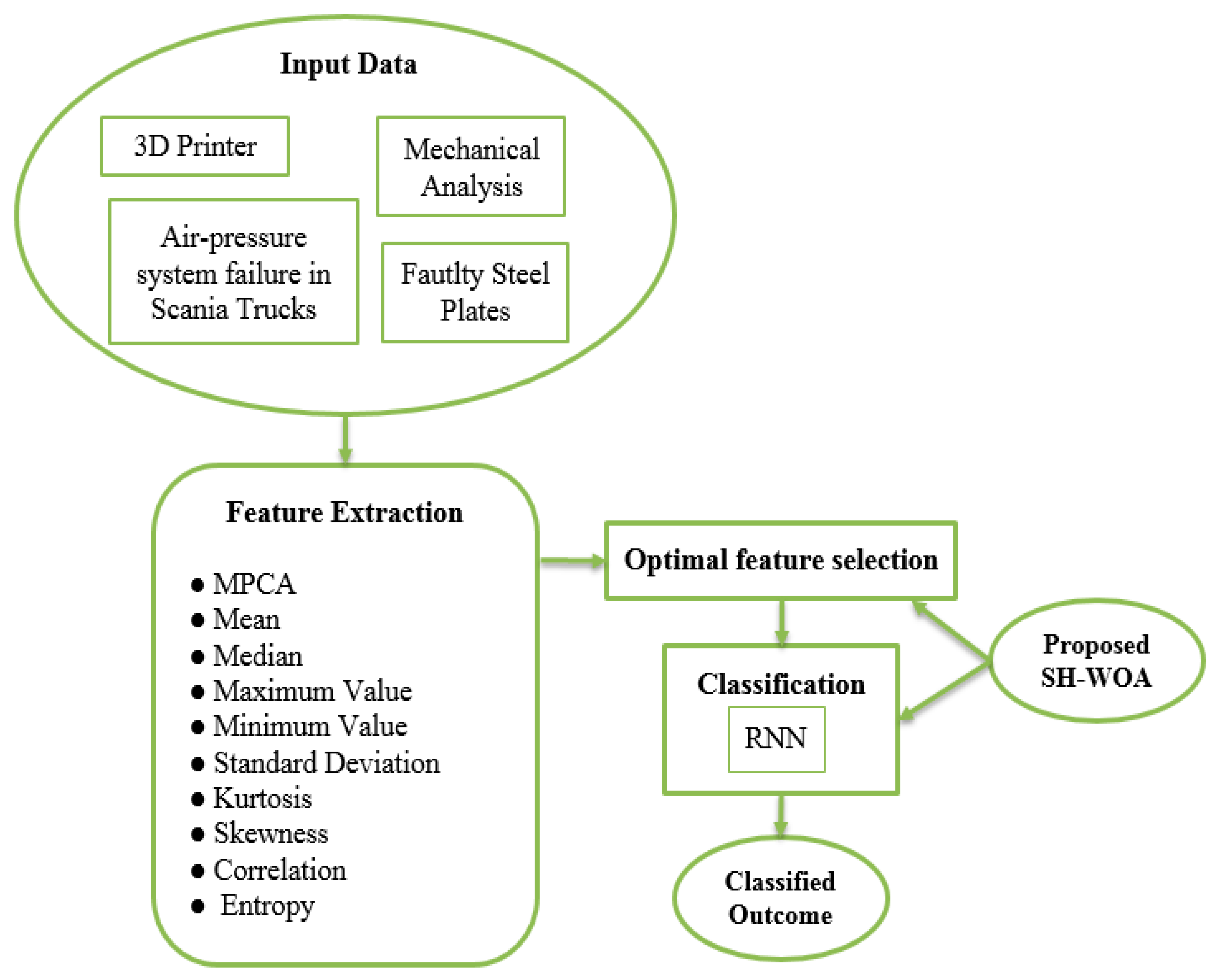
3. Developed Architecture for Mechanical Maintenance Data Classification
3.1. Proposed Architecture
3.2. Objective Model
4. Different Phases to Be Adopted for Data Classification in Mechanical Maintenance Field
4.1. Data Acquisition
4.2. Feature Extraction
5. Feature Selection and Deep Learning for Data Classification
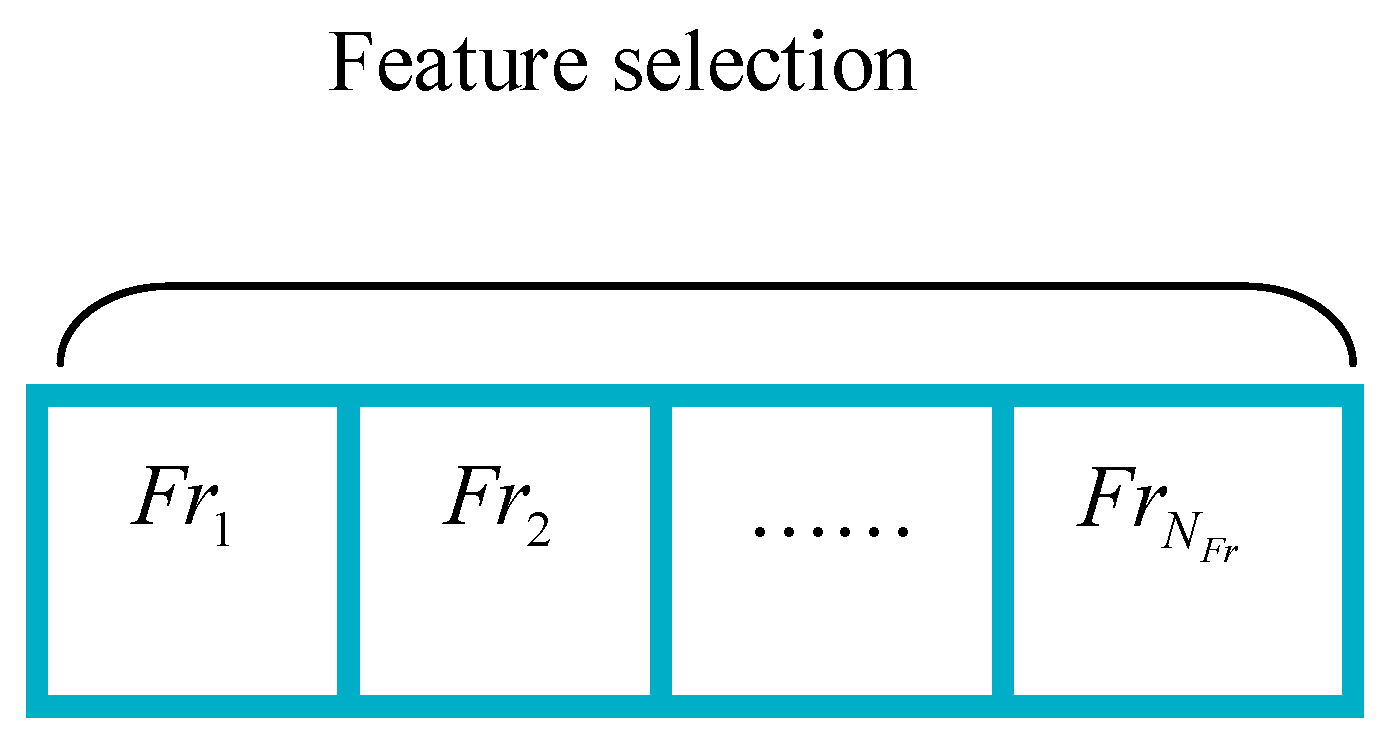
5.1. Feature Selection
5.2. RNN-Based Classification
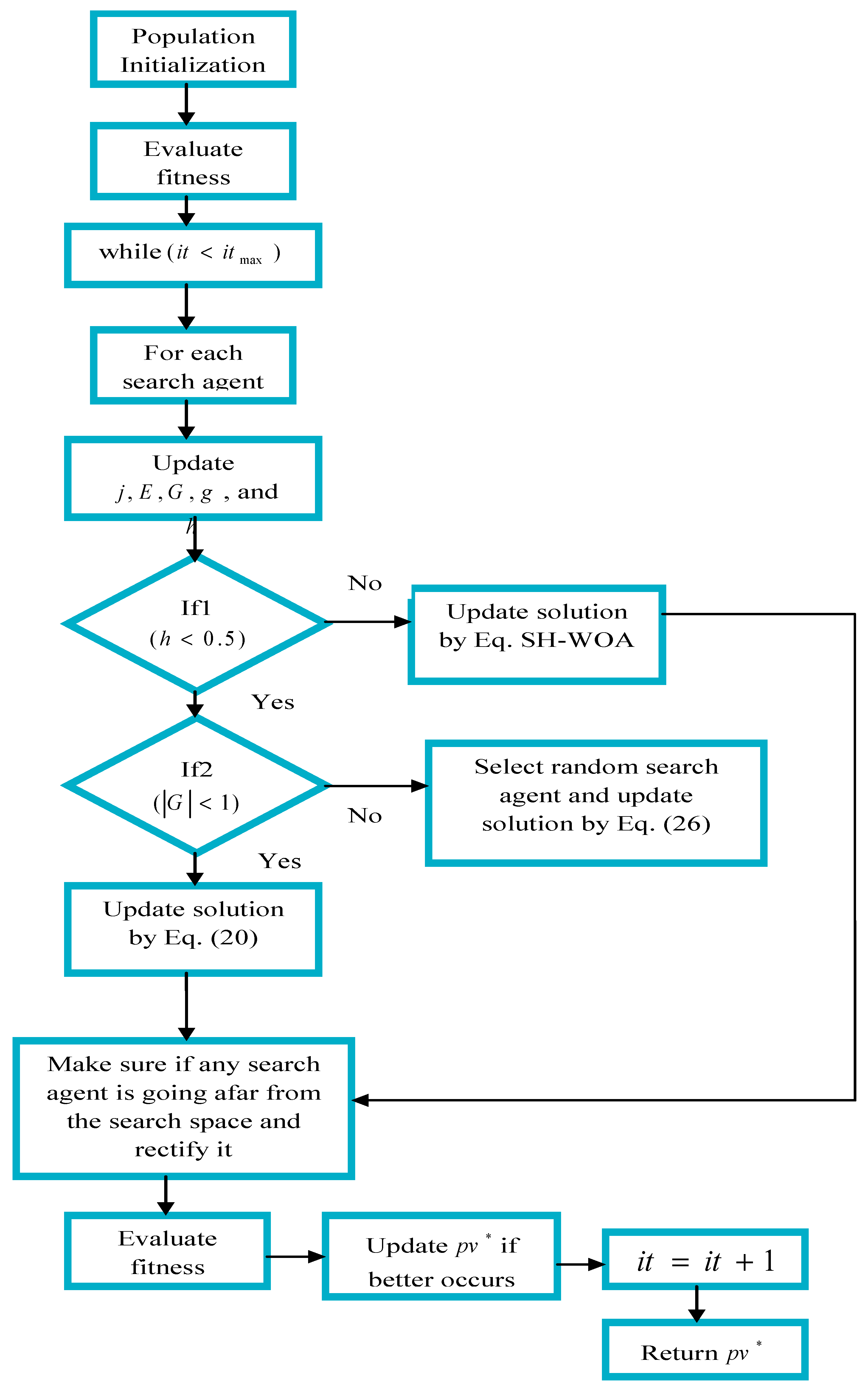
6. Proposed Spotted Hyena-Based Whale Optimization Algorithm for Optimal Feature Selection and Classification
6.1. Flow Diagram of Feature Selection and Classification
6.2. Solution Encoding
6.3. Conventional Whale Optimization Algorithm
| Algorithm 1. Pseudo code of Conventional Whale Optimization Algorithm [52]. | |
| 1: | Conduct the population initialization as , where . |
| 2: | Evaluate the fitness value of every search agent. |
| 3: | pv* is the best search agent. |
| 4: | itmax indicates maximum number of iterations. |
| 5: | while (it < itmax) |
| 6: | for each search agent |
| 7: | Update J, E, G, g, and h |
| 8: | if1 (h < 0.5) |
| 9: | if2 (|G| < 1) |
| 10: | Update the solution using Equation (20). |
| 11: | else if2 (|G| ≥ 1) |
| 12: | Select a random agent (pvrand) |
| 13: | Update the solution by Equation (26). |
| 14: | end if2 |
| 15: | else if1 (h ≥ 0.5) |
| 16: | Update the solution by Equation (23). |
| 17: | end if1 |
| 18: | end for |
| 19: | Make sure if any search agent is going afar from the search space and rectify it |
| 20: | Evaluate the fitness value of each search agent. |
| 21: | Update pv* if a better solution obtained. |
| 22: | it = it + 1 |
| 23: | end while |
| 24: | returnpv* |
6.4. Conventional Spotted Hyena Optimization
| Algorithm 2. Pseudocode of Conventional Spotted Hyena Optimization [53]. | |
| 1: | Input: Perform population initialization as , where . |
| 2: | Output: The best search agent. |
| 3: | Perform parameter initialization r, K, L, N. |
| 4: | Evaluate the objective function. |
| 5: | is the best solution or the best search agent. |
| 6: | indicates the group of all far optimal solutions. |
| 7: | while (it < itmax) |
| 8: | for each search agent |
| 9: | Update the solution by Equation (36). |
| 10: | end for |
| 11: | The variables r, K, L, N are updated. |
| 12: | Check if any solution goes beyond the given search space and manage it if it happens. |
| 13: | Evaluate the fitness value of each search agent. |
| 14: | Update if a better solution occurs than the previous one. |
| 15: | Update the group with respect to . |
| 16: | it = it + 1 |
| 17: | end while |
| 18: | return |
6.5. Proposed SH-WOA
7. Results and Discussion
7.1. Experimental Procedure
7.2. Performance Metrics
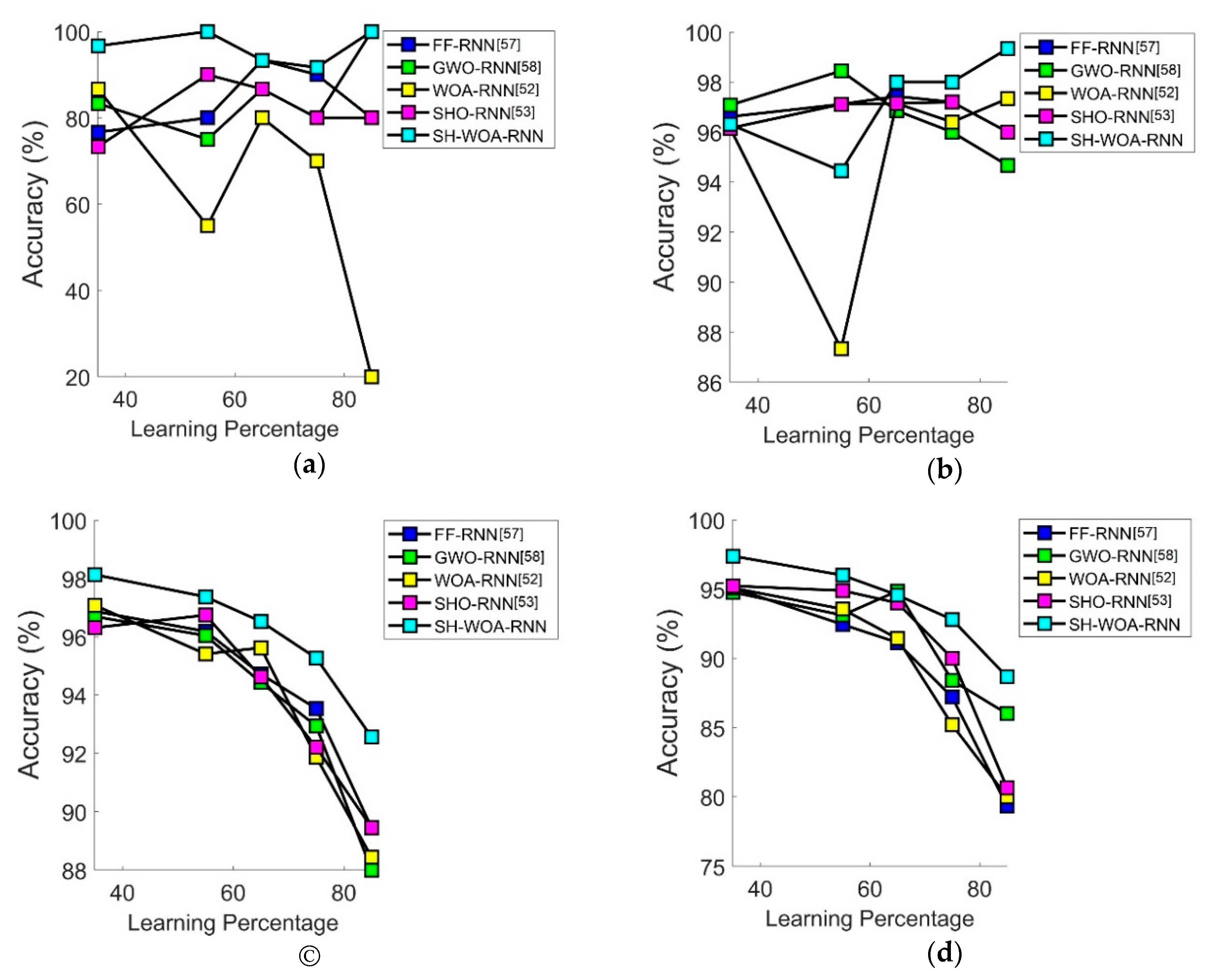
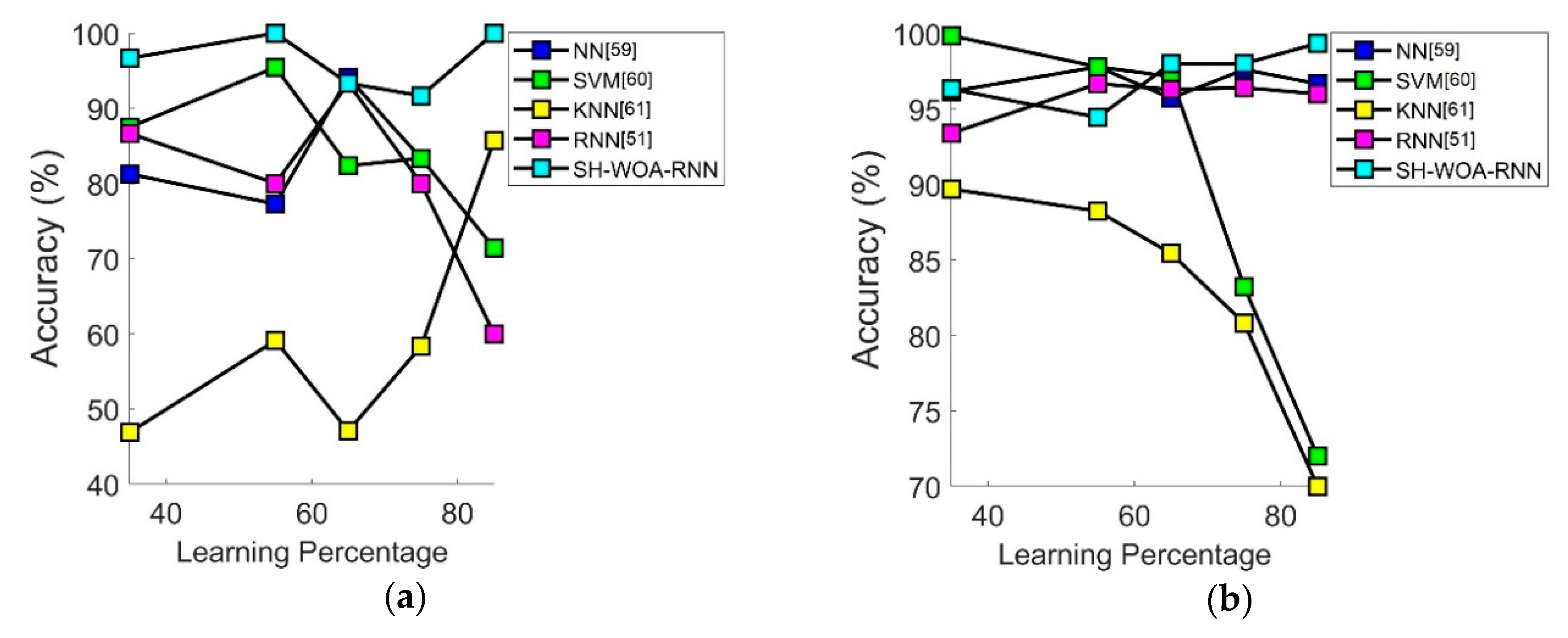
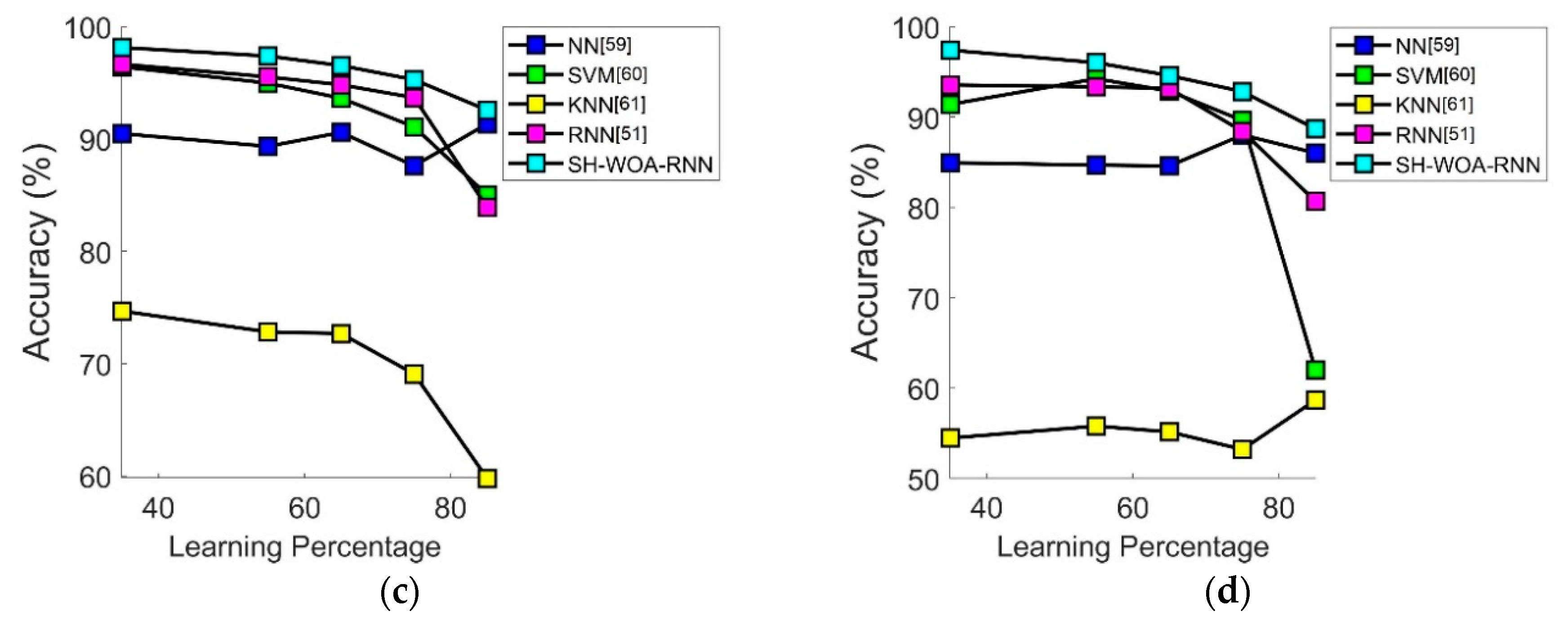
7.3. Performance Analysis in Terms of Accuracy
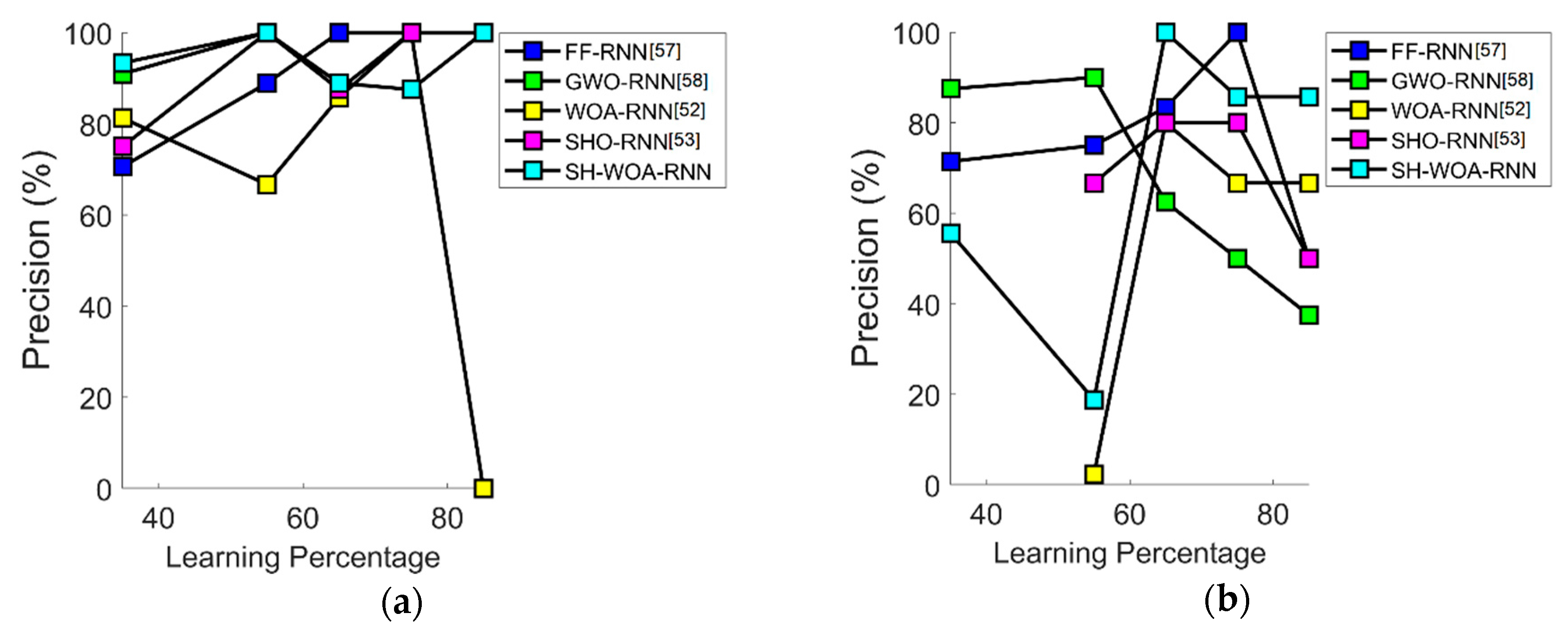
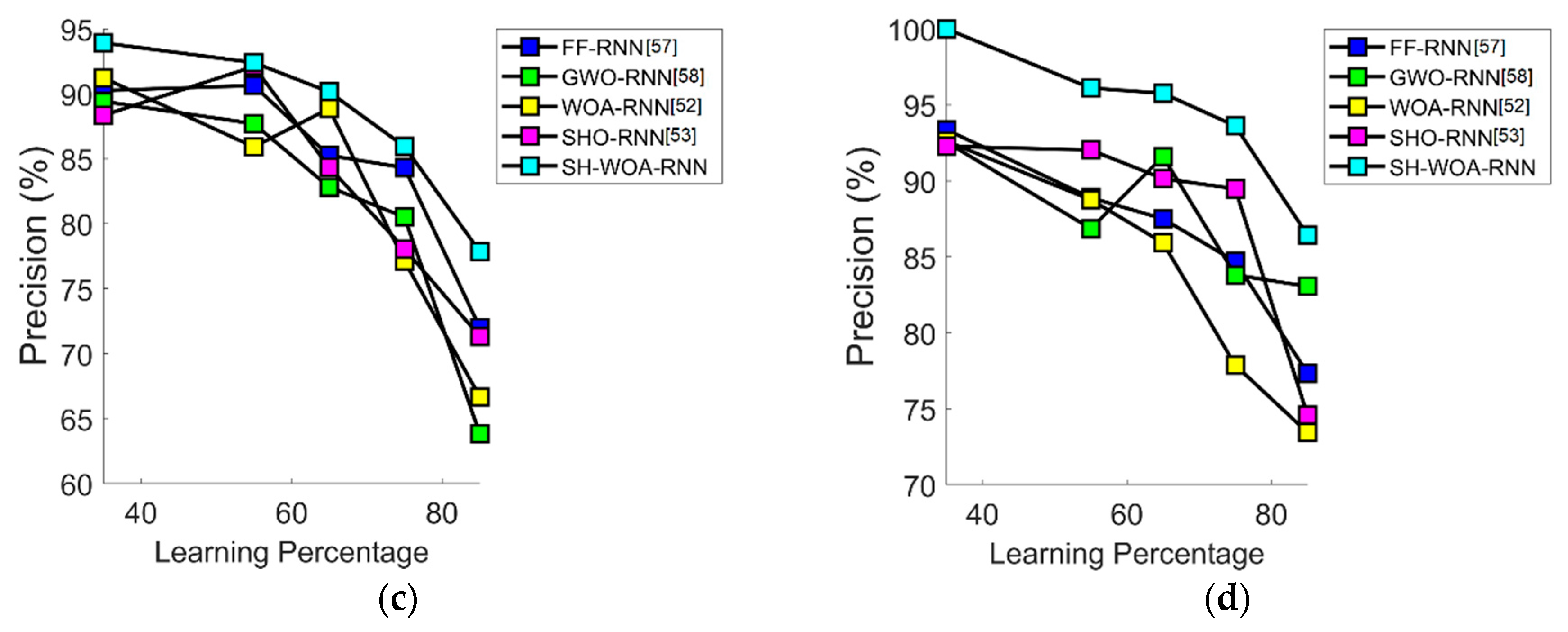
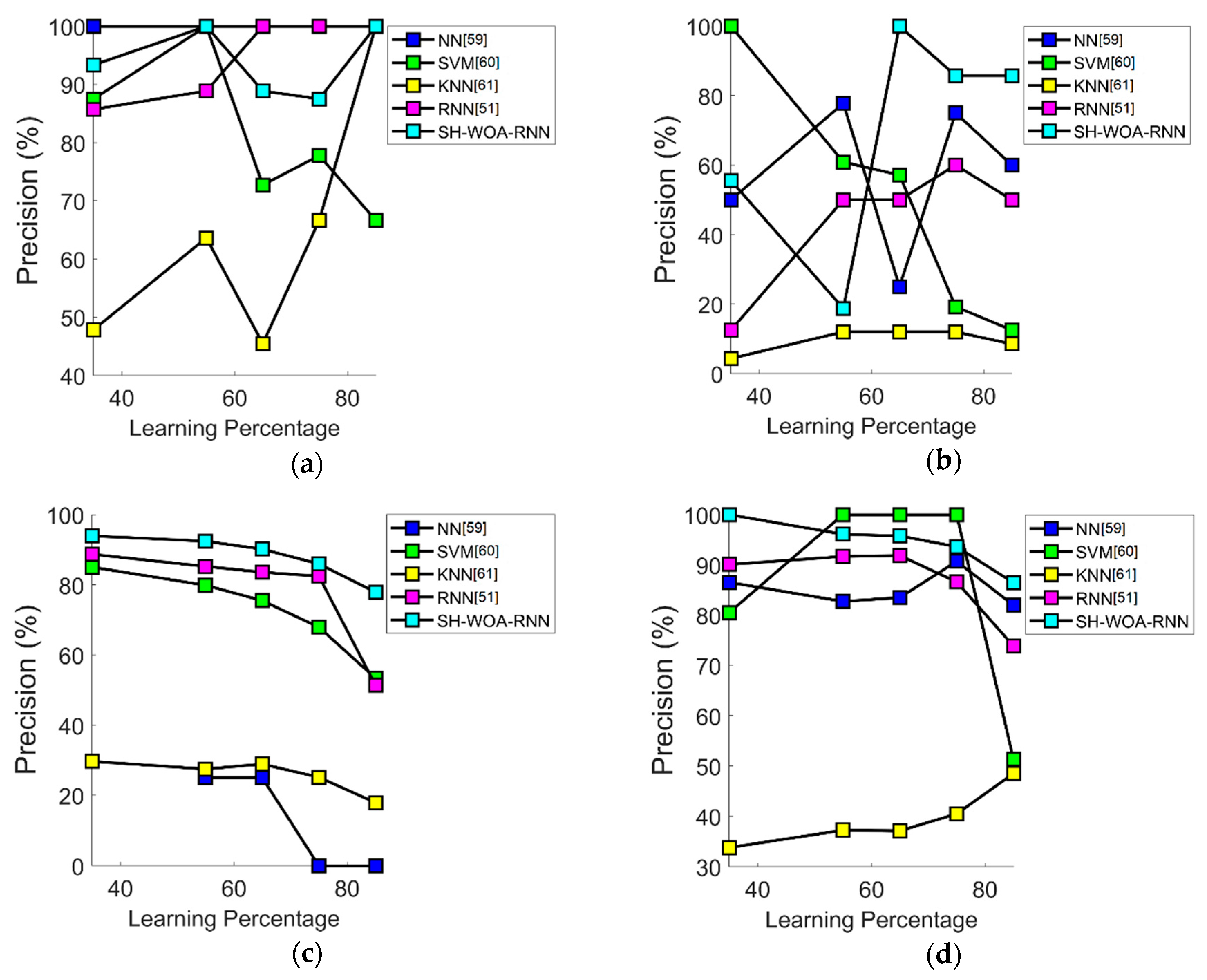
7.4. Performance Analysis in Terms of Precision
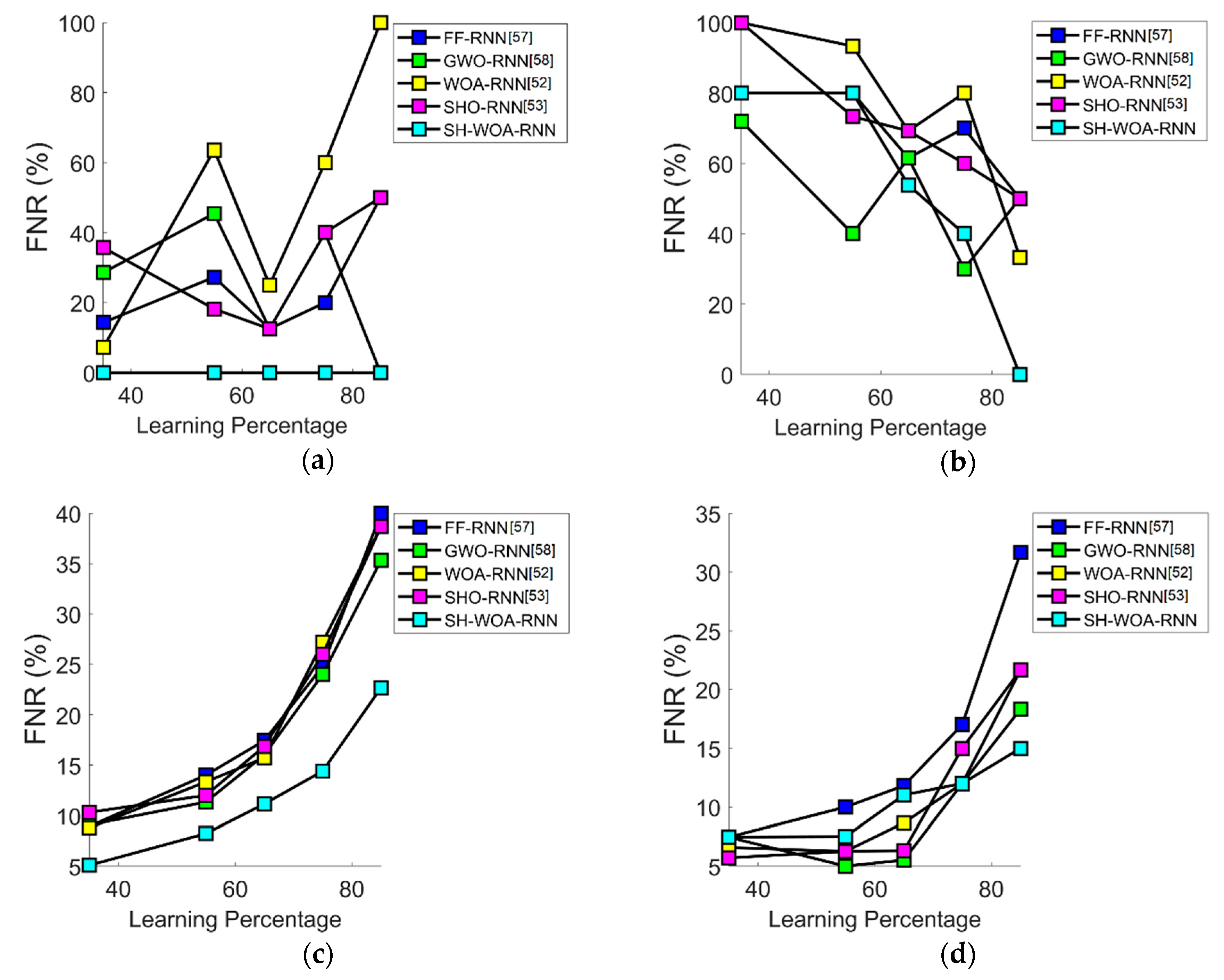
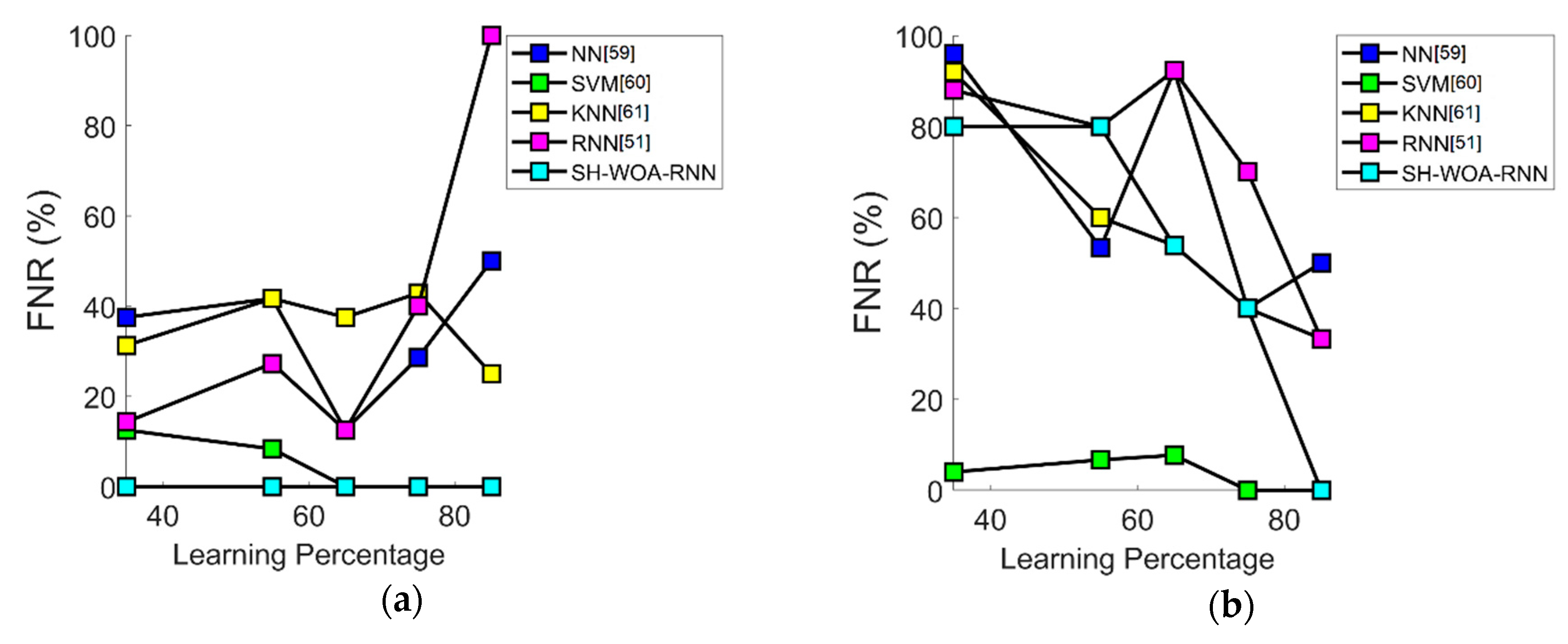
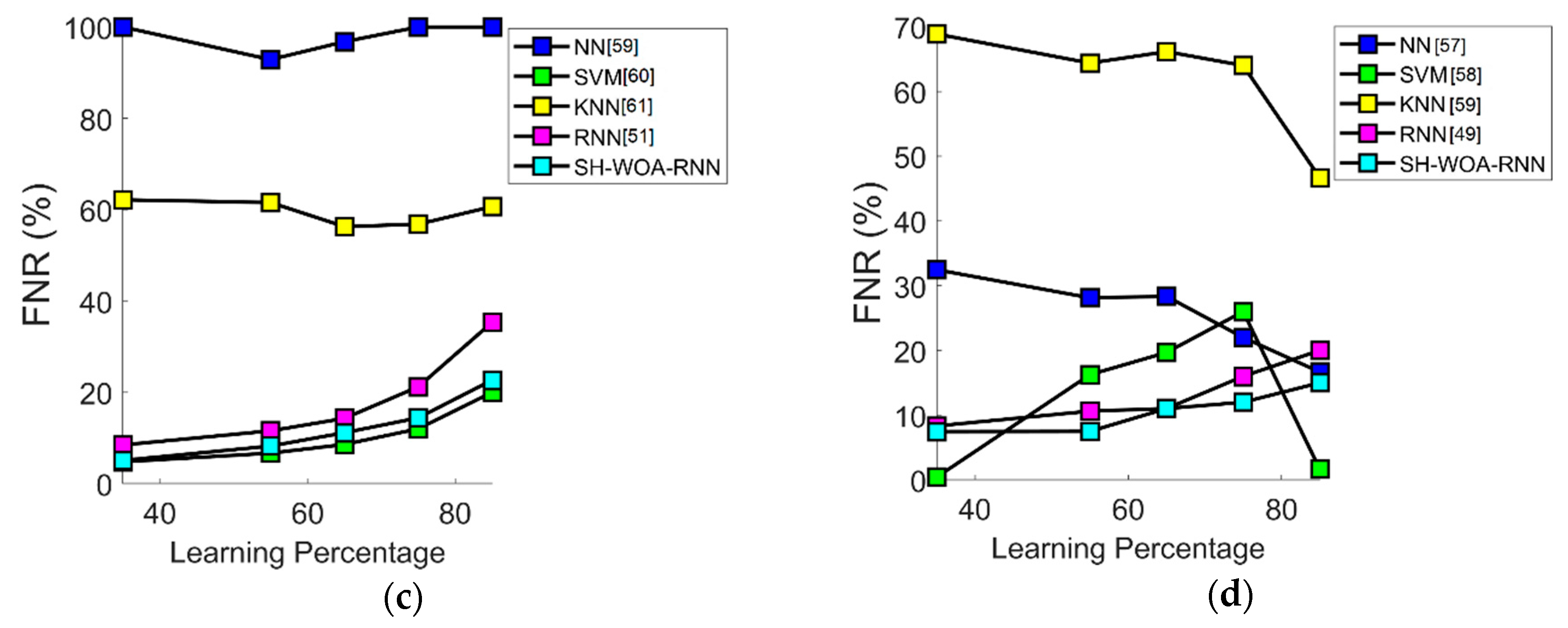
7.5. Performance Analysis in Terms of FNR
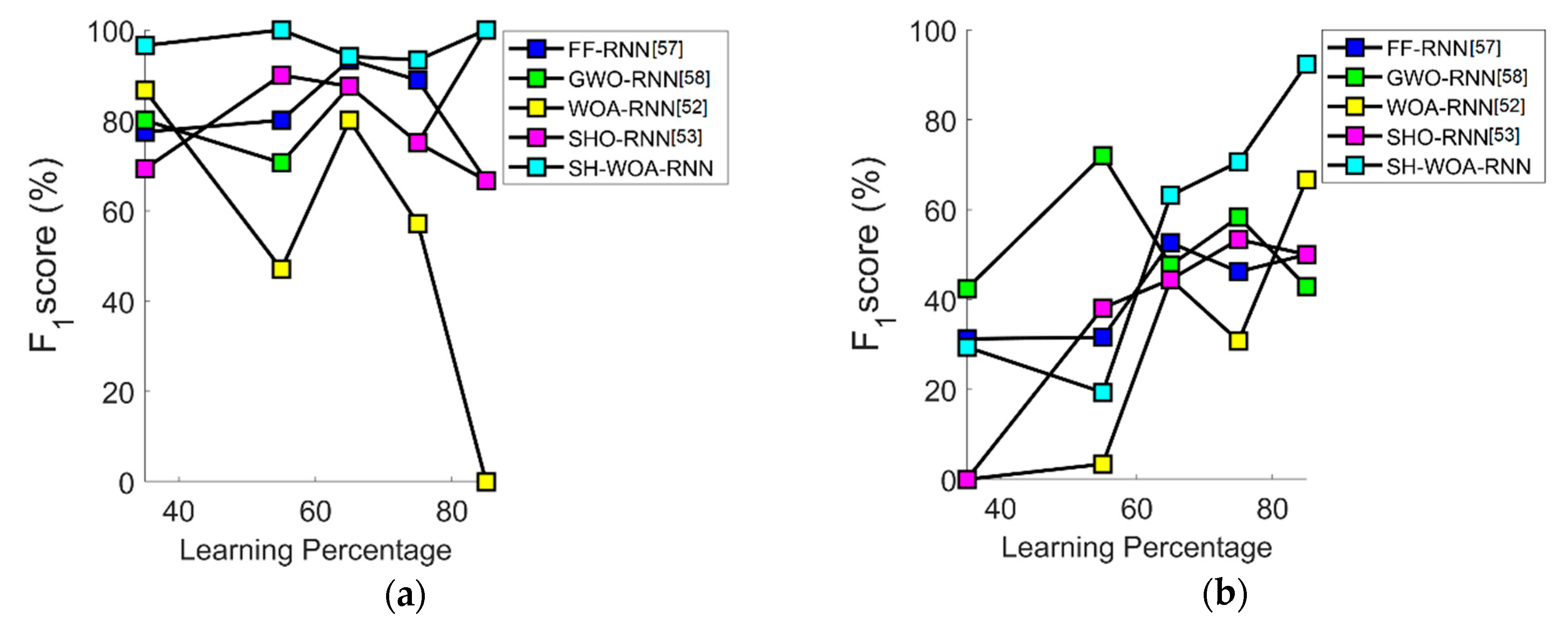
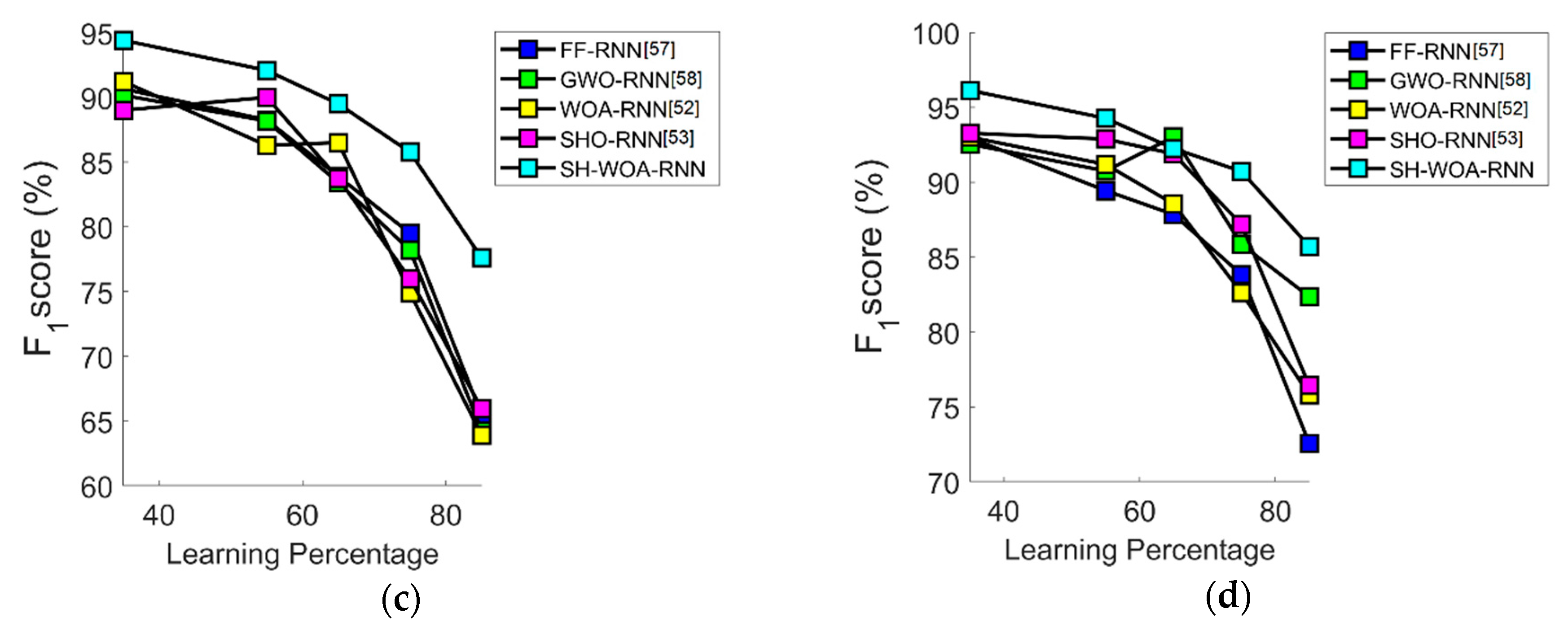
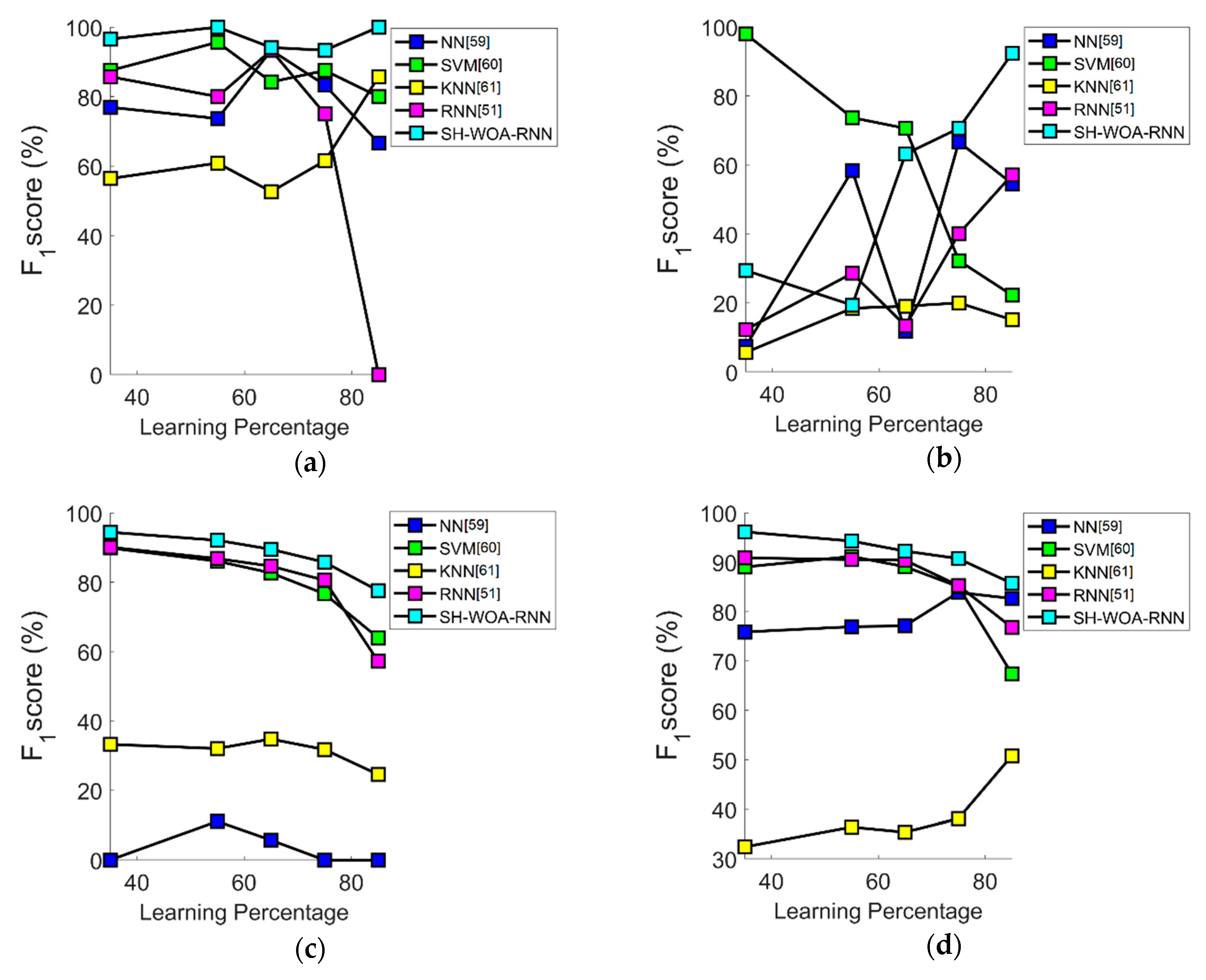
7.6. Performance Analysis in Terms of F1-Score
7.7. Overall Performance Analysis
7.8. Analysis Based on Computational Time
8. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PCA | Principal Component Analysis |
| WOA | Whale Optimization Algorithm |
| SHO | Spotted Hyena Optimization |
| SH-WOA | Spotted Hyena-based Whale Optimization Algorithm |
| RNN | Recurrent Neural Network |
| DNN | Deep Neural Network |
| SVM | Support Vector Machine |
| KNN | K-Nearest Neighbour |
| NB | Naive Bayes |
| CNN | Convolutional Neural Network |
| LDA | Linear Discriminant Analysis |
| QDA | Quadratic Discriminant Analysis |
| APS | Air Pressure System |
| ICA | Independent Component Analysis |
| NN | Neural Network |
| GRU | Gated Recurrent Unit |
| FPR | False Positive Rate |
| FF | FireFly algorithm |
| FNR | False Negative Rate |
| GWO | Grey Wolf Optimization |
| NPV | Negative Predictive Value |
| FDR | False Discovery Rate |
| MCC | Matthew’s Correlation Coefficient |
| ML | Machine Learning |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| SITO | Social Impact Theory-based Optimization |
| QWOA | Quantum Whale Optimization Algorithm |
| WOA-LFDE | Whale Optimization Algorithm-Levy Flight and Differential Evolution |
| MOSHO | Multi-Objective Spotted Hyena Optimizer |
| DE-CQPSO | Differential Evolution-Crossover Quantum Particle Swarm Optimization |
| FIOA | Firefly Integrated Optimization Algorithm |
| MHDOA | Memory based Hybrid Dragonfly Optimization Algorithm |
| BSOA | Brain Storm Optimization Algorithm |
| MLP | Multilayer Perceptron |
| DDAO | Dynamic Differential Annealed Optimization |
| FIMPSO | Firefly and Improved Multi-objective Particle Swarm Optimization |
| MIMO | Multiple Input Multiple Output |
References
- Lei, Y.; Lin, J.; He, Z.; Zuo, M.J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2013, 35, 108–126. [Google Scholar] [CrossRef]
- El Kadiri, S.; Grabot, B.; Thoben, K.-D.; Hribernik, K.; Emmanouilidis, C.; von Cieminski, G.; Kiritsis, D. Current trends on ICT technologies for enterprise information systems. Comput. Ind. 2016, 79, 14–33. [Google Scholar] [CrossRef]
- Precup, R.-E.; Angelov, P.; Costa, B.S.J.; Sayed-Mouchaweh, M. An overview on fault diagnosis and nature-inspired optimal control of industrial process applications. Comput. Ind. 2015, 74, 75–94. [Google Scholar] [CrossRef]
- Miyajima, R. Deep Learning Triggers a New Era in Industrial Robotics. IEEE MultiMedia 2017, 24, 91–96. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Wang, K.-S. Intelligent predictive maintenance for fault diagnosis and prognosis in machine centers: Industry 4.0 scenario. Adv. Manuf. 2017, 5, 377–387. [Google Scholar] [CrossRef]
- Lu, C.; Wang, Z.-Y.; Qin, W.-L.; Ma, J. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification. Signal Process. 2017, 130, 377–388. [Google Scholar] [CrossRef]
- Lin, J.; Chen, Q. A novel method for feature extraction using crossover characteristics of nonlinear data and its application to fault diagnosis of rotary machinery. Mech. Syst. Signal Process. 2014, 48, 174–187. [Google Scholar] [CrossRef]
- Stimpson, A.J.; Cummings, M.L. Assessing Intervention Timing in Computer-Based Education Using Machine Learning Algorithms. IEEE Access 2014, 2, 78–87. [Google Scholar] [CrossRef]
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. Machine Learning an Artificial Intelligence Approach, 1st ed.; Springer: Berlin/Heidelberg, Germany, 1983; p. 572. [Google Scholar]
- Wang, Z.-Y.; Lu, C.; Zhou, B. Fault diagnosis for rotary machinery with selective ensemble neural networks. Mech. Syst. Signal. Process. 2018, 113, 112–130. [Google Scholar] [CrossRef]
- Lu, P.; Chen, S.; Zheng, Y. Artificial intelligence in civil engineering. Math. Probelms Eng. 2012, 2012, 1–22. [Google Scholar] [CrossRef]
- Krummenacher, G.; Ong, C.S.; Koller, S.; Kobayashi, S.; Buhmann, J.M. Wheel Defect Detection With Machine Learning. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1176–1187. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Yang, Y.; Dong, X.J.; Peng, Z.K.; Zhang, W.M.; Meng, G. Vibration signal analysis using parameterized time–frequency method for features extraction of varying-speed rotary machinery. J. Sound Vib. 2015, 335, 350–366. [Google Scholar] [CrossRef]
- Zhou, L.; Ma, L. Extreme Learning Machine-Based Heterogeneous Domain Adaptation for Classification of Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1781–1785. [Google Scholar] [CrossRef]
- Zhang, C.; Tan, K.C.; Li, H.; Hong, G.S. A Cost-Sensitive Deep Belief Network for Imbalanced Classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 109–122. [Google Scholar] [CrossRef]
- Shi, C.; Panoutsos, G.; Luo, B.; Liu, H.; Li, B.; Lin, X. Using Multiple-Feature-Spaces-Based Deep Learning for Tool Condition Monitoring in Ultraprecision Manufacturing. IEEE Trans. Ind. Electron. 2019, 66, 3794–3803. [Google Scholar] [CrossRef]
- Ruiz-Sarmiento, J.-R.; Monroy, J.; Moreno, F.-A.; Galindo, C.; Bonelo, J.-M.; Gonzalez-Jimenez, J. A predictive model for the maintenance of industrial machinery in the context of industry 4.0. Eng. Appl. Artif. Intell. 2020, 87, 103289. [Google Scholar] [CrossRef]
- Abidi, M.H.; Alkhalefah, H.; Mohammed, M.K.; Umer, U.; Qudeiri, J.E.A. Optimal Scheduling of Flexible Manufacturing System Using Improved Lion-Based Hybrid Machine Learning Approach. IEEE Access 2020, 8, 96088–96114. [Google Scholar] [CrossRef]
- Naik, D.L.; Kiran, R. Naïve Bayes classifier, multivariate linear regression and experimental testing for classification and characterization of wheat straw based on mechanical properties. Ind. Crops Prod. 2018, 112, 434–448. [Google Scholar] [CrossRef]
- Xiong, S.; Fu, Y.; Ray, A. Bayesian Nonparametric Regression Modeling of Panel Data for Sequential Classification. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4128–4139. [Google Scholar] [CrossRef]
- McArthur, J.J.; Shahbazi, N.; Fok, R.; Raghubar, C.; Bortoluzzi, B.; An, A. Machine learning and BIM visualization for maintenance issue classification and enhanced data collection. Adv. Eng. Inform. 2018, 38, 101–112. [Google Scholar] [CrossRef]
- Konstantopoulos, G.; Koumoulos, E.P.; Charitidis, C.A. Classification of mechanism of reinforcement in the fiber-matrix interface: Application of Machine Learning on nanoindentation data. Mater. Des. 2020, 192, 108705. [Google Scholar] [CrossRef]
- Maxwell, K.; Rajabi, M.; Esterle, J. Automated classification of metamorphosed coal from geophysical log data using supervised machine learning techniques. Int. J. Coal Geol. 2019, 214, 103284. [Google Scholar] [CrossRef]
- Islam, M.M.; Rahman, M.J.; Chandra Roy, D.; Maniruzzaman, M. Automated detection and classification of diabetes disease based on Bangladesh demographic and health survey data, 2011 using machine learning approach. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 217–219. [Google Scholar] [CrossRef] [PubMed]
- Karandikar, J. Machine learning classification for tool life modeling using production shop-floor tool wear data. Procedia Manuf. 2019, 34, 446–454. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Wang, K. A deep learning driven method for fault classification and degradation assessment in mechanical equipment. Comput. Ind. 2019, 104, 1–10. [Google Scholar] [CrossRef]
- Siam, A.; Ezzeldin, M.; El-Dakhakhni, W. Machine learning algorithms for structural performance classifications and predictions: Application to reinforced masonry shear walls. Structures 2019, 22, 252–265. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, L.; Liu, T.; Kamruzzaman, M.M. Research on deep learning in the field of mechanical equipment fault diagnosis image quality. J. Vis. Commun. Image Represent. 2019, 62, 402–409. [Google Scholar] [CrossRef]
- Mahmodi, K.; Mostafaei, M.; Mirzaee-Ghaleh, E. Detection and classification of diesel-biodiesel blends by LDA, QDA and SVM approaches using an electronic nose. Fuel 2019, 258, 116114. [Google Scholar] [CrossRef]
- Zhu, X.; Cai, Z.; Wu, J.; Cheng, Y.; Huang, Q. Convolutional neural network based combustion mode classification for condition monitoring in the supersonic combustor. Acta Astronaut. 2019, 159, 349–357. [Google Scholar] [CrossRef]
- Akyol, S.; Alatas, B. Sentiment classification within online social media using whale optimization algorithm and social impact theory based optimization. Phys. A Stat. Mech. Appl. 2020, 540, 123094. [Google Scholar] [CrossRef]
- Agrawal, R.K.; Kaur, B.; Sharma, S. Quantum based Whale Optimization Algorithm for wrapper feature selection. Appl. Soft Comput. 2020, 89, 106092. [Google Scholar] [CrossRef]
- Devaraj, A.F.S.; Elhoseny, M.; Dhanasekaran, S.; Lydia, E.L.; Shankar, K. Hybridization of firefly and Improved Multi-Objective Particle Swarm Optimization algorithm for energy efficient load balancing in Cloud Computing environments. J. Parallel Distrib. Comput. 2020, 142, 36–45. [Google Scholar] [CrossRef]
- Gölcük, İ.; Ozsoydan, F.B. Evolutionary and adaptive inheritance enhanced Grey Wolf Optimization algorithm for binary domains. Knowl. Based Syst. 2020, 194, 105586. [Google Scholar] [CrossRef]
- Liu, M.; Yao, X.; Li, Y. Hybrid whale optimization algorithm enhanced with Lévy flight and differential evolution for job shop scheduling problems. Appl. Soft Comput. 2020, 87, 105954. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Multi-objective spotted hyena optimizer: A Multi-objective optimization algorithm for engineering problems. Knowl. Based Syst. 2018, 150, 175–197. [Google Scholar] [CrossRef]
- Xin-gang, Z.; Ji, L.; Jin, M.; Ying, Z. An improved quantum particle swarm optimization algorithm for environmental economic dispatch. Expert Syst. Appl. 2020, 152, 113370. [Google Scholar] [CrossRef]
- He, H.; Tan, Y.; Ying, J.; Zhang, W. Strengthen EEG-based emotion recognition using firefly integrated optimization algorithm. Appl. Soft Comput. 2020, 94, 106426. [Google Scholar] [CrossRef]
- Ranjini, K.S.S.; Murugan, S. Memory based Hybrid Dragonfly Algorithm for numerical optimization problems. Expert Syst. Appl. 2017, 83, 63–78. [Google Scholar] [CrossRef]
- Tuba, E.; Strumberger, I.; Bezdan, T.; Bacanin, N.; Tuba, M. Classification and Feature Selection Method for Medical Datasets by Brain Storm Optimization Algorithm and Support Vector Machine. Procedia Comput. Sci. 2019, 162, 307–315. [Google Scholar] [CrossRef]
- Orrù, P.F.; Zoccheddu, A.; Sassu, L.; Mattia, C.; Cozza, R.; Arena, S. Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability 2020, 12, 4776. [Google Scholar] [CrossRef]
- Ghafil, H.N.; Jármai, K. Dynamic differential annealed optimization: New metaheuristic optimization algorithm for engineering applications. Appl. Soft Comput. 2020, 93, 106392. [Google Scholar] [CrossRef]
- Mahjoubi, S.; Barhemat, R.; Bao, Y. Optimal placement of triaxial accelerometers using hypotrochoid spiral optimization algorithm for automated monitoring of high-rise buildings. Autom. Constr. 2020, 118, 103273. [Google Scholar] [CrossRef]
- Sahal, R.; Breslin, J.G.; Ali, M.I. Big data and stream processing platforms for Industry 4.0 requirements mapping for a predictive maintenance use case. J. Manuf. Syst. 2020, 54, 138–151. [Google Scholar] [CrossRef]
- Zhou, Q.; Jacobson, A. Thingi10K: A Dataset of 10,000 3D-Printing Models. arXiv. 2016. Available online: https://arxiv.org/abs/1605.04797 (accessed on 20 July 2020).
- Lindgren, T.; Biteus, J. APS Failure at Scania Trucks Data Set. Scania CV AB, S., Sweden. UCL Machine Learning Repository. Irvine, CA. 2017. Available online: https://archive.ics.uci.edu/ml/datasets/APS+Failure+at+Scania+Trucks (accessed on 20 July 2020).
- Semeion. Steel Plates Faults Data Set. Research Center of Sciences of Communication, R., Italy. UCL Machine Learning Repository. Irvine, CA. 2010. Available online: https://archive.ics.uci.edu/ml/datasets/Steel+Plates+Faults (accessed on 20 July 2020).
- Bergadano, F.; Giordana, A.; Saitta, L.; Bracadori, F.; Marchi, D. Mechanical Analysis Data Set. Repository, U.M.L.University of California, School of Information and Computer Science. Irvine, CA. 1990. Available online: https://archive.ics.uci.edu/ml/datasets/Mechanical+Analysis (accessed on 20 July 2020).
- Xingfu, Z.; Xiangmin, R. Two Dimensional Principal Component Analysis based Independent Component Analysis for face recognition. In Proceedings of the 2011 International Conference on Multimedia Technology, Hangzhou, China, 26–28 July 2011; pp. 934–936. [Google Scholar]
- Li, F.; Liu, M. A hybrid Convolutional and Recurrent Neural Network for Hippocampus Analysis in Alzheimer’s Disease. J. Neurosci. Methods 2019, 323, 108–118. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Spotted hyena optimizer: A novel bio-inspired based metaheuristic technique for engineering applications. Adv. Eng. Softw. 2017, 114, 48–70. [Google Scholar] [CrossRef]
- Boothalingam, R. Optimization using lion algorithm: A biological inspiration from lion’s social behavior. Evol. Intell. 2018, 11, 31–52. [Google Scholar] [CrossRef]
- Rajakumar, B.R. Lion algorithm for standard and large scale bilinear system identification: A global optimization based on Lion’s social behavior. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 2116–2123. [Google Scholar]
- Beno, M.M.; Rajakumar, B.R. Threshold prediction for segmenting tumour from brain MRI scans. Int. J. Imaging Syst. Technol. 2014, 24, 129–137. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Yang, X.S.; Talatahari, S.; Alavi, A.H. Firefly algorithm with chaos. Commun. Nonlinear Sci. Numer. Simul. 2013, 18, 89–98. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Fernández-Navarro, F.; Carbonero-Ruz, M.; Alonso, D.B.; Torres-Jiménez, M. Global Sensitivity Estimates for Neural Network Classifiers. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2592–2604. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Tan, K.K.; Sng, B.L.; Li, S.; Sia, A.T.H. Lumbar Ultrasound Image Feature Extraction and Classification with Support Vector Machine. Ultrasound Med. Biol. 2015, 41, 2677–2689. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Hu, X.; Fan, W.; Shen, L.; Zhang, Z.; Liu, X.; Du, J.; Li, H.; Chen, Y.; Li, H. Fast density peak clustering for large scale data based on kNN. Knowl. Based Syst. 2020, 187, 104824. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Methodology | Features | Challenges |
|---|---|---|---|
| Li et al. [27] | DNN |
|
|
| Naik and Kiran [20] | NB |
|
|
| Siam et al. [28] | Machine Learning |
|
|
| Chen et al. [29] | CNN |
|
|
| Xiong et al. [21] | Bayesian nonparametric regression approach |
|
|
| Lei et al. [13] | Unsupervised two-layer NN |
|
|
| Mahmodi et al. [30] | SVM |
|
|
| Zhu et al. [31] | CNN |
|
|
| Akyol, and Alatas [32] | SITO |
|
|
| Agrawal et al. [33] | QWOA |
|
|
| Author | Methodology | Features | Challenges |
|---|---|---|---|
| Devaraj et al. [34] | FIMPSO |
|
|
| Golcuk and Ozsoydan [35] | GWO |
|
|
| Liu et al. [36] | WOA-LFDE |
|
|
| Dhiman and Kumar [37] | MOSHO |
|
|
| Xin-gang et al. [38] | DE-CQPSO |
|
|
| He et al. [39] | FIOA |
|
|
| Ranjini and Murugan [40] | MHDOA |
|
|
| Tuba et al. [41] | BSOA |
|
|
| Ghafil, and Jarmaia [43] | DDAO |
|
|
| Mahjoubi, and Bao [44] | Hypotrochoid spiral optimization algorithm |
|
|
| Performance Metrics | FF-RNN [57] | GWO-RNN [58] | WOA-RNN [52] | SHO-RNN [53] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.9 | 0.8 | 0.7 | 0.8 | 0.91667 |
| Sensitivity | 0.8 | 0.6 | 0.4 | 0.6 | 1 |
| Specificity | 1 | 1 | 1 | 1 | 0.8 |
| Precision | 1 | 1 | 1 | 1 | 0.875 |
| FPR | 0 | 0 | 0 | 0 | 0.2 |
| FNR | 0.2 | 0.4 | 0.6 | 0.4 | 0 |
| NPV | 1 | 1 | 1 | 1 | 0.8 |
| FDR | 0 | 0 | 0 | 0 | 0.125 |
| F1-Score | 0.88889 | 0.75 | 0.57143 | 0.75 | 0.93333 |
| MCC | 0.8165 | 0.65465 | 0.5 | 0.65465 | 0.83666 |
| Performance Metrics | NN [59] | SVM [60] | KNN [61] | RNN [29] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.83333 | 0.83333 | 0.58333 | 0.8 | 0.91667 |
| Sensitivity | 0.71429 | 1 | 0.57143 | 0.6 | 1 |
| Specificity | 1 | 0.6 | 0.6 | 1 | 0.8 |
| Precision | 1 | 0.77778 | 0.66667 | 1 | 0.875 |
| FPR | 0 | 0.4 | 0.4 | 0 | 0.2 |
| FNR | 0.28571 | 0 | 0.42857 | 0.4 | 0 |
| NPV | 1 | 0.6 | 0.6 | 1 | 0.8 |
| FDR | 0 | 0.22222 | 0.33333 | 0 | 0.125 |
| F1-Score | 0.83333 | 0.875 | 0.61538 | 0.75 | 0.93333 |
| MCC | 0.71429 | 0.68313 | 0.16903 | 0.65465 | 0.83666 |
| Performance Metrics | FF-RNN [57] | GWO-RNN [58] | WOA-RNN [52] | SHO-RNN [53] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.972 | 0.96 | 0.964 | 0.972 | 0.98 |
| Sensitivity | 0.3 | 0.7 | 0.2 | 0.4 | 0.6 |
| Specificity | 1 | 0.97083 | 0.99583 | 0.99583 | 0.99583 |
| Precision | 1 | 0.5 | 0.66667 | 0.8 | 0.85714 |
| FPR | 0 | 0.029167 | 0.004167 | 0.004167 | 0.004167 |
| FNR | 0.7 | 0.3 | 0.8 | 0.6 | 0.4 |
| NPV | 1 | 0.97083 | 0.99583 | 0.99583 | 0.99583 |
| FDR | 0 | 0.5 | 0.33333 | 0.2 | 0.14286 |
| F1-Score | 0.46154 | 0.58333 | 0.30769 | 0.53333 | 0.70588 |
| MCC | 0.53991 | 0.57174 | 0.35244 | 0.55405 | 0.70775 |
| Performance Metrics | NN [59] | SVM [60] | KNN [61] | RNN [29] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.976 | 0.832 | 0.808 | 0.964 | 0.98 |
| Sensitivity | 0.6 | 1 | 0.6 | 0.3 | 0.6 |
| Specificity | 0.99167 | 0.825 | 0.81667 | 0.99167 | 0.99583 |
| Precision | 0.75 | 0.19231 | 0.12 | 0.6 | 0.85714 |
| FPR | 0.008333 | 0.175 | 0.18333 | 0.008333 | 0.004167 |
| FNR | 0.4 | 0 | 0.4 | 0.7 | 0.4 |
| NPV | 0.99167 | 0.825 | 0.81667 | 0.99167 | 0.99583 |
| FDR | 0.25 | 0.80769 | 0.88 | 0.4 | 0.14286 |
| F1-Score | 0.66667 | 0.32258 | 0.2 | 0.4 | 0.70588 |
| MCC | 0.65876 | 0.39831 | 0.20412 | 0.40825 | 0.70775 |
| Performance Metrics | FF-RNN [57] | GWO-RNN [58] | WOA-RNN [52] | SHO-RNN [53] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.93533 | 0.92933 | 0.91867 | 0.922 | 0.95267 |
| Sensitivity | 0.752 | 0.76 | 0.728 | 0.74 | 0.856 |
| Specificity | 0.972 | 0.9632 | 0.9568 | 0.9584 | 0.972 |
| Precision | 0.84305 | 0.80508 | 0.77119 | 0.78059 | 0.85944 |
| FPR | 0.028 | 0.0368 | 0.0432 | 0.0416 | 0.028 |
| FNR | 0.248 | 0.24 | 0.272 | 0.26 | 0.144 |
| NPV | 0.972 | 0.9632 | 0.9568 | 0.9584 | 0.972 |
| FDR | 0.15695 | 0.19492 | 0.22881 | 0.21941 | 0.14056 |
| F1-Score | 0.79493 | 0.78189 | 0.74897 | 0.75975 | 0.85772 |
| MCC | 0.75843 | 0.74021 | 0.70091 | 0.7136 | 0.82933 |
| Performance Metrics | NN [59] | SVM [60] | KNN [61] | RNN [29] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.876 | 0.91067 | 0.69067 | 0.93667 | 0.95267 |
| Sensitivity | 0 | 0.88 | 0.432 | 0.788 | 0.856 |
| Specificity | 0.97333 | 0.9168 | 0.7424 | 0.9664 | 0.972 |
| Precision | 0 | 0.67901 | 0.25116 | 0.82427 | 0.85944 |
| FPR | 0.026667 | 0.0832 | 0.2576 | 0.0336 | 0.028 |
| FNR | 1 | 0.12 | 0.568 | 0.212 | 0.144 |
| NPV | 0.97333 | 0.9168 | 0.7424 | 0.9664 | 0.972 |
| FDR | 1 | 0.32099 | 0.74884 | 0.17573 | 0.14056 |
| F1-Score | 0 | 0.76655 | 0.31765 | 0.80573 | 0.85772 |
| MCC | −0.05227 | 0.7216 | 0.14373 | 0.76819 | 0.82933 |
| Performance Metrics | FF-RNN [57] | GWO-RNN [58] | WOA-RNN [52] | SHO-RNN [53] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.872 | 0.884 | 0.852 | 0.9 | 0.928 |
| Sensitivity | 0.83 | 0.88 | 0.88 | 0.85 | 0.88 |
| Specificity | 0.9 | 0.88667 | 0.83333 | 0.93333 | 0.96 |
| Precision | 0.84694 | 0.8381 | 0.77876 | 0.89474 | 0.93617 |
| FPR | 0.1 | 0.11333 | 0.16667 | 0.066667 | 0.04 |
| FNR | 0.17 | 0.12 | 0.12 | 0.15 | 0.12 |
| NPV | 0.9 | 0.88667 | 0.83333 | 0.93333 | 0.96 |
| FDR | 0.15306 | 0.1619 | 0.22124 | 0.10526 | 0.06383 |
| F1-Score | 0.83838 | 0.85854 | 0.82629 | 0.87179 | 0.90722 |
| MCC | 0.73254 | 0.76098 | 0.70216 | 0.79061 | 0.84957 |
| Performance Metrics | NN [59] | SVM [60] | KNN [61] | RNN [29] | SH-WOA-RNN |
|---|---|---|---|---|---|
| Accuracy | 0.88 | 0.896 | 0.532 | 0.884 | 0.928 |
| Sensitivity | 0.78 | 0.74 | 0.36 | 0.84 | 0.88 |
| Specificity | 0.94667 | 1 | 0.64667 | 0.91333 | 0.96 |
| Precision | 0.90698 | 1 | 0.40449 | 0.86598 | 0.93617 |
| FPR | 0.053333 | 0 | 0.35333 | 0.086667 | 0.04 |
| FNR | 0.22 | 0.26 | 0.64 | 0.16 | 0.12 |
| NPV | 0.94667 | 1 | 0.64667 | 0.91333 | 0.96 |
| FDR | 0.093023 | 0 | 0.59551 | 0.13402 | 0.06383 |
| F1-Score | 0.83871 | 0.85057 | 0.38095 | 0.85279 | 0.90722 |
| MCC | 0.74939 | 0.79415 | 0.006821 | 0.75736 | 0.84957 |
| Methods | Computational Time (sec.) | |||
|---|---|---|---|---|
| Three-Dimensional (3D) Printer (Test Case 1) | Air Pressure System Failure in Scania Trucks (Test Case 2) | Faulty Steel Plates (Test Case 3) | Mechanical Analysis Data (Test Case 4) | |
| FF [57] | 237.41 | 188.09 | 191.17 | 163.55 |
| GWO [58] | 169.58 | 118.5 | 131.27 | 102.56 |
| WOA [52] | 180.47 | 95.481 | 149.66 | 102.83 |
| SHO [53] | 393.53 | 302.82 | 303.94 | 320.8 |
| SH-WOA | 88.596 | 163.4 | 127.2 | 168.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abidi, M.H.; Umer, U.; Mohammed, M.K.; Aboudaif, M.K.; Alkhalefah, H. Automated Maintenance Data Classification Using Recurrent Neural Network: Enhancement by Spotted Hyena-Based Whale Optimization. Mathematics 2020, 8, 2008. https://doi.org/10.3390/math8112008
Abidi MH, Umer U, Mohammed MK, Aboudaif MK, Alkhalefah H. Automated Maintenance Data Classification Using Recurrent Neural Network: Enhancement by Spotted Hyena-Based Whale Optimization. Mathematics. 2020; 8(11):2008. https://doi.org/10.3390/math8112008
Chicago/Turabian StyleAbidi, Mustufa Haider, Usama Umer, Muneer Khan Mohammed, Mohamed K. Aboudaif, and Hisham Alkhalefah. 2020. "Automated Maintenance Data Classification Using Recurrent Neural Network: Enhancement by Spotted Hyena-Based Whale Optimization" Mathematics 8, no. 11: 2008. https://doi.org/10.3390/math8112008
APA StyleAbidi, M. H., Umer, U., Mohammed, M. K., Aboudaif, M. K., & Alkhalefah, H. (2020). Automated Maintenance Data Classification Using Recurrent Neural Network: Enhancement by Spotted Hyena-Based Whale Optimization. Mathematics, 8(11), 2008. https://doi.org/10.3390/math8112008