Extending Fuzzy Cognitive Maps with Tensor-Based Distance Metrics





Abstract
1. Introduction
2. Previous Work
3. Myers-Briggs Type Indicator
- Approach to socialization: Introvert (I) vs Extrovert (E). As the name of this variable suggests, it denotes the degree a person is open to others. Introverts tend to work mentally in isolation and rely on indirect cues from others. On the contrary, extroverts share their thoughts frequently with others and ask for explicit feedback.
- Approach to information gathering: Sensing (S) vs Intuition (N). Persons who frequently resort to sensory related functions observe the outside world, whether the physical or social environment, in order to collect information about open problems or improve situational awareness belong to the S group. On the other hand, persons labeled as N rely on a less concrete form of information representation for reaching insight.
- Approach to decision making: Thinking (T) vs Feeling (F). This variable indicates the primary means by which an individual makes a decision. This may be rational thinking with clearly outlined processes, perhaps in the form of corporate policies of formal problem solving methods such as 5W or TRIZ, or a more abstract and empathy oriented way based on external influences and the emotional implications of past decisions.
- Approach to lifestyle: Judging (J) vs Perceiving (P). This psychological function pertains to how a lifestyle is led. Perceiving persons show more understanding to other lifestyles and may not object to open ended evolution processes over a long amount of time. On the contrary, judging persons tend to close open matters as soon as possible and are more likely to apply old solutions to new problems.
4. Cognitive Maps
- All neurons are eventually activated and assigned to clusters, leaving thus no gaps to the topological map. Thus all available neurons are utilized.
- Moreover, in the long run the number of neuron activations is roughly the same for each neuron. For sufficiently large number of epochs each neuron is activated with equal probability.
- Random order. In each epoch the data points are selected based on a random permutation of their original order.
- Reverse order. In each epoch the previous order is reversed.
4.1. Training
- The norm or Manhattan distance.
- The norm of Euclidean distance.
- Square.
- Hexagon.
- Cross.
- Constant rate: This is the simplest case as has a constant positive value of . This imples should be carefully chosen in order to avoid both a slow synaptic weight convergence and missing the convergence. In some cases a theoretical value of is given by (9), where is the maximum eigenvalue of the input autocorrelation matrix:
- Cosine rate: A common option for the learning rate is the cosine decay rate as shown in (10), which is in general considered flexible and efficient in the sense that the learning rate is initially large enough so that convergence is quickly achieved but also it becomes slow enough so that no overshoot will occur.In (10) the argument stays in the first quadrant, meaning that the is always positive. However, the maximum number of epochs should be known in advance. This specific learning rate has the advantage that initially it is relatively high but gradually drops with a quadratic rate as seen in Equation (11):To see what this means in practice, let us check when drops below :Thus, for only a third of the total available number of iterations the learning rate is above . Alternatively, for each iteration where the learning rate is above that threshold there are two where respectively it is below that, provided that the number of iterations is close to the limit . Another way to see this, the learning rate decays with a rate given by (13):
- Inverse linear: The learning rate scheme of Equation (14) is historically among the first. It has a slow decay which translates in the general case to a slow convergence rate, implying that more epochs are necessary in order for the SOM to achieve a truly satisfactory performance.Now the learning rate decays with a rate of:In order for the learning rate to drop below it suffices that:From the above equation it follows that determines convergence to a great extent.
- Inverse polynomial: Equation (17) generalizes the inverse linear learning rate to a higher dimension. In this case there is no simple way to predict its behavior, which may well fluctuate before the dominant term takes over. Also, the polynomial coefficients should be carefully selected in order to avoid negative values. Moreover, although the value at each iteration can be efficiently computed, numerical stability may be an issue especially for large values of p or when r is close to a root. If possible the polynomial should be given in the factor form. Also, ideally polynomials with roots of even moderate multiplicity should be avoided if r can reach their region as the lower order derivatives of the polynomial do not vanish locally. To this end algorithmic techniques such as Horner’s schema [82] should be employed. In this case:For this option the learning rate decay rate is more complicated compared to the other cases as:
- Inverse logarithmic: A more adaptive choice for the learning rate and an intermediate selection between the constant and the inverse linear options is the inverse logarithmic as described by Equation (19). The logarithm base can vary depending on the application and here the Neperian logarithms will be used. Although all logarithms have essentially the same order of magnitude, local differences between iterations may well be observed. In this case:As r grows, the logarithm tends to behave approximately like a increasing piecewise constant for increasingly large intervals of r. Thus, the learning rate adapts to the number of iterations and does not require a maximum value . Equation (20) gives the rate of this learning rate:In order for the learning rate to drop below it suffices that:Due to the nature of the exponential function all three parameters play their role in determining the number of epochs.
- Exponential decay: Finally the learning rate diminishes sharper when the scheme of Equation (22) is chosen, although that depends mainly on the parameter :The learning rate in this case decays according to:Therefore the learning rate decays with a rate proportional to its current value, a well known property of the exponential function, implying this decay is quickly accelerated. Additionally, in order for the learning rate to drop below it suffices that:
- Constant
- Rectangular with rectangle side
- Circular with radius
- Triangular with height and base .
- Gaussian with mean and variance
- Rectangular with rectangle size .
- Circular with radius .
- Gaussian with mean and variance
4.2. Error Metrics
| Algorithm 1 SOM training. |
|
5. Results
5.1. Dataset and Data Point Representation
- A point or even an entire class may be better represented by more than one vectors. Thus, these vectors may be concatenated to yield a matrix.
- Higher order relationships between vectors cannot be represented by other vectors.
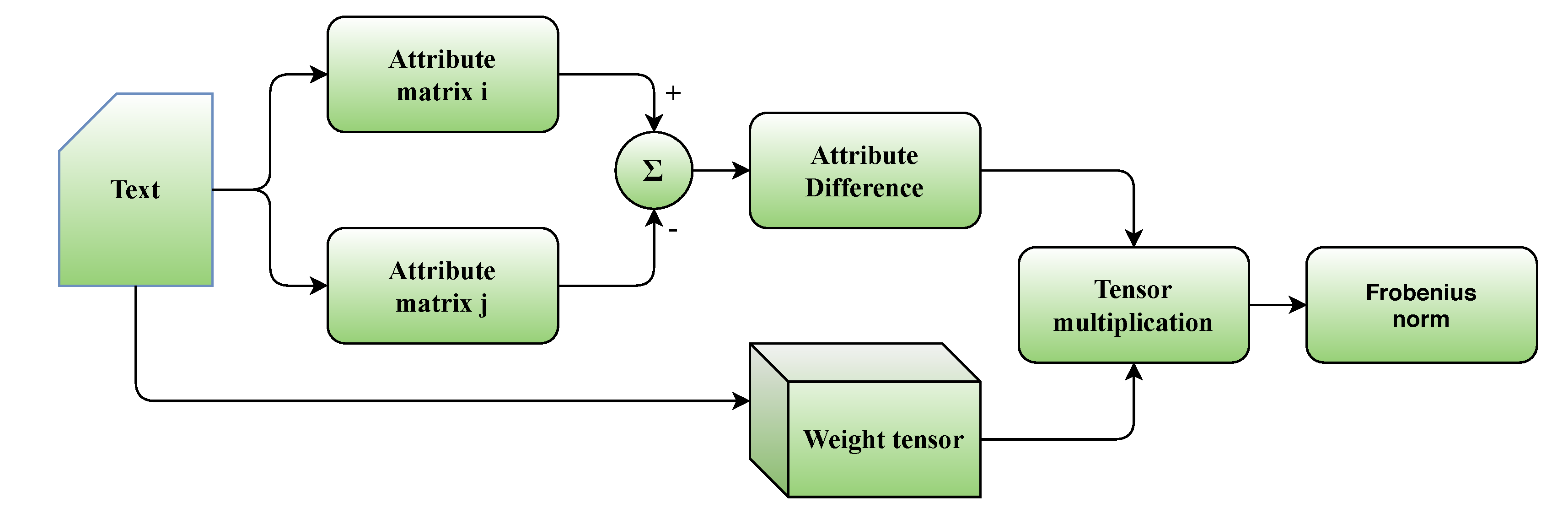
5.2. Proposed Metrics
5.3. Experimental Setup
- Clustering quality: As SOMs perform clustering general metrics can be used, especially since the dataset contains ground truth classes.
- Topological map: It is possible to construct figure of merits based on the SOM operating principles. Although they are by definition SOM-specific, they nonetheless provide insight on how the self-organization of the neurons takes place while adapting to the dataset topology.
- MBTI permuations: Finally, the dataset itself provides certain insight. Although no specific formulas can be derived, a qualitative analysis based on findings from the scientific literature.
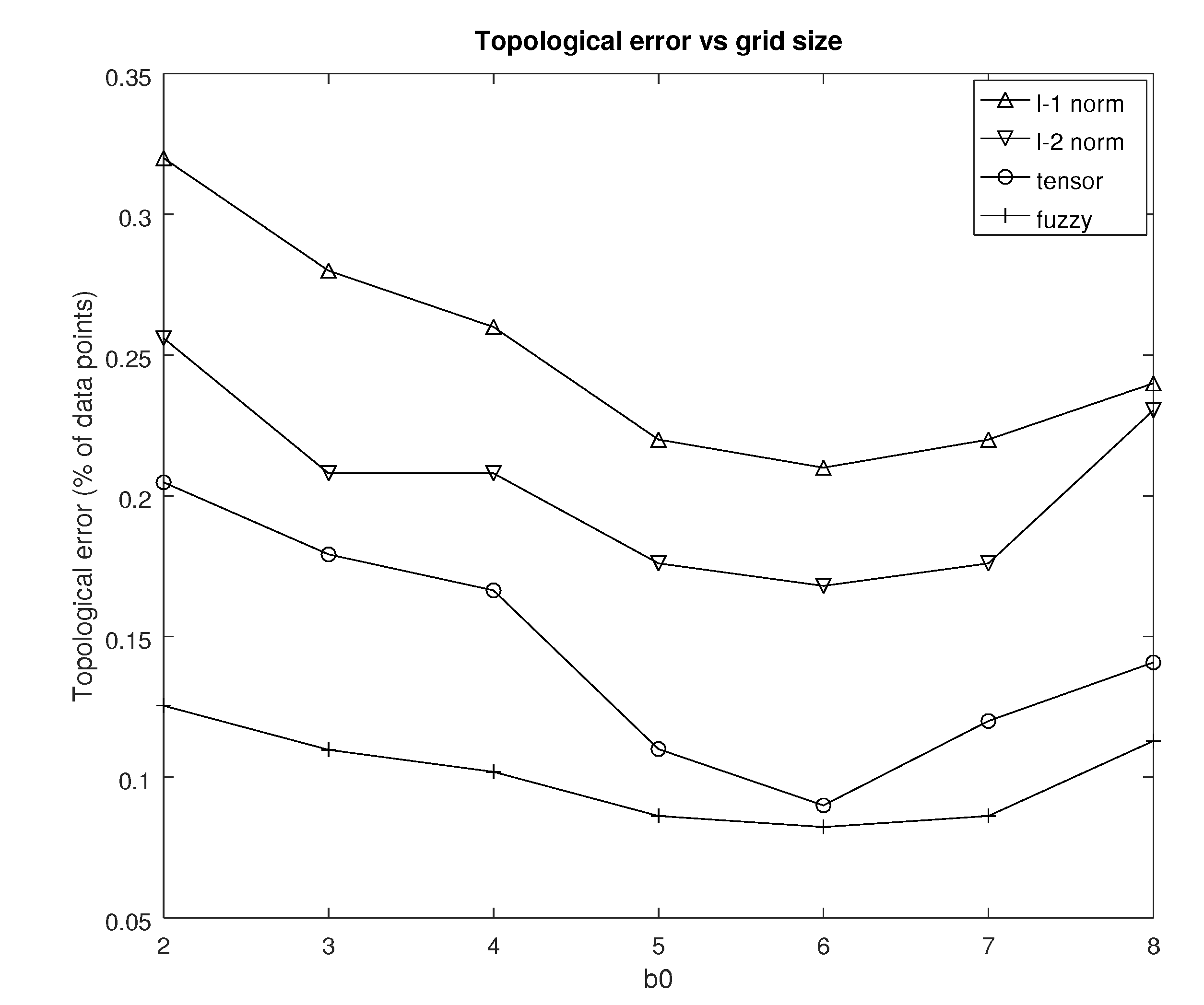
5.4. Topological Error
- In each case the variance is relatively small, implying that there is a strong concentration of the number of epochs around the respective mean value. In other words, is a reliable estimator of the true number of epochs of the respective combination of distance metric and learning rate.
- For the same learning rate the fuzzy version of the tensor distance metric consistently requires a lower number of epochs. It is followed closely by the tensor distance metric, whereas the and norms are way behind with the former being somewhat better than the latter.
- Conversely, for the same metric the cosine decay rate systematically outperforms the other two options. The inverse linear decay rate may be a viable alternative, although there is a significant gap in the number of epochs. The exponential decay rates results in very slow convergence requiring almost twice the number of epochs compared to the cosine decay rate.
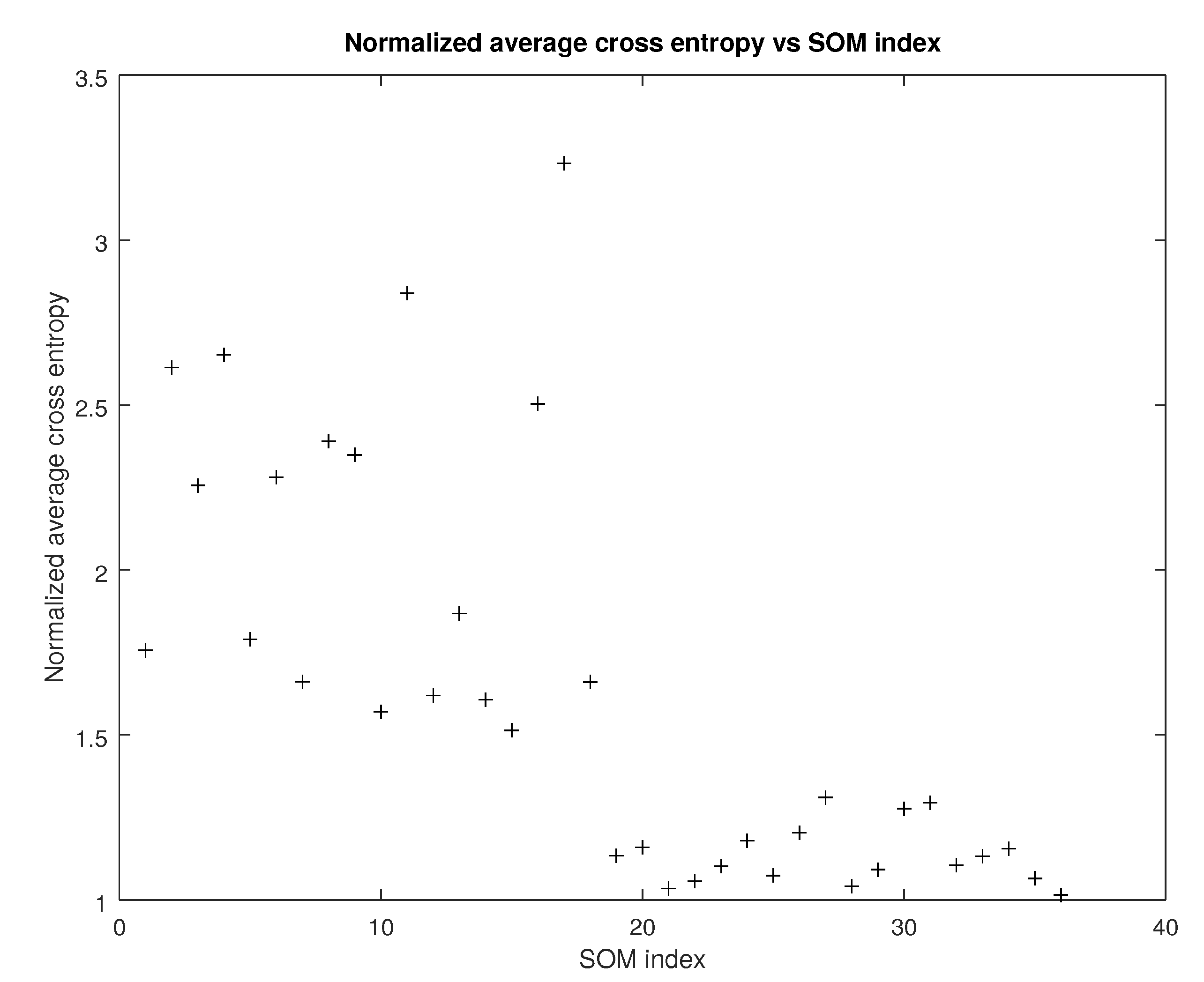
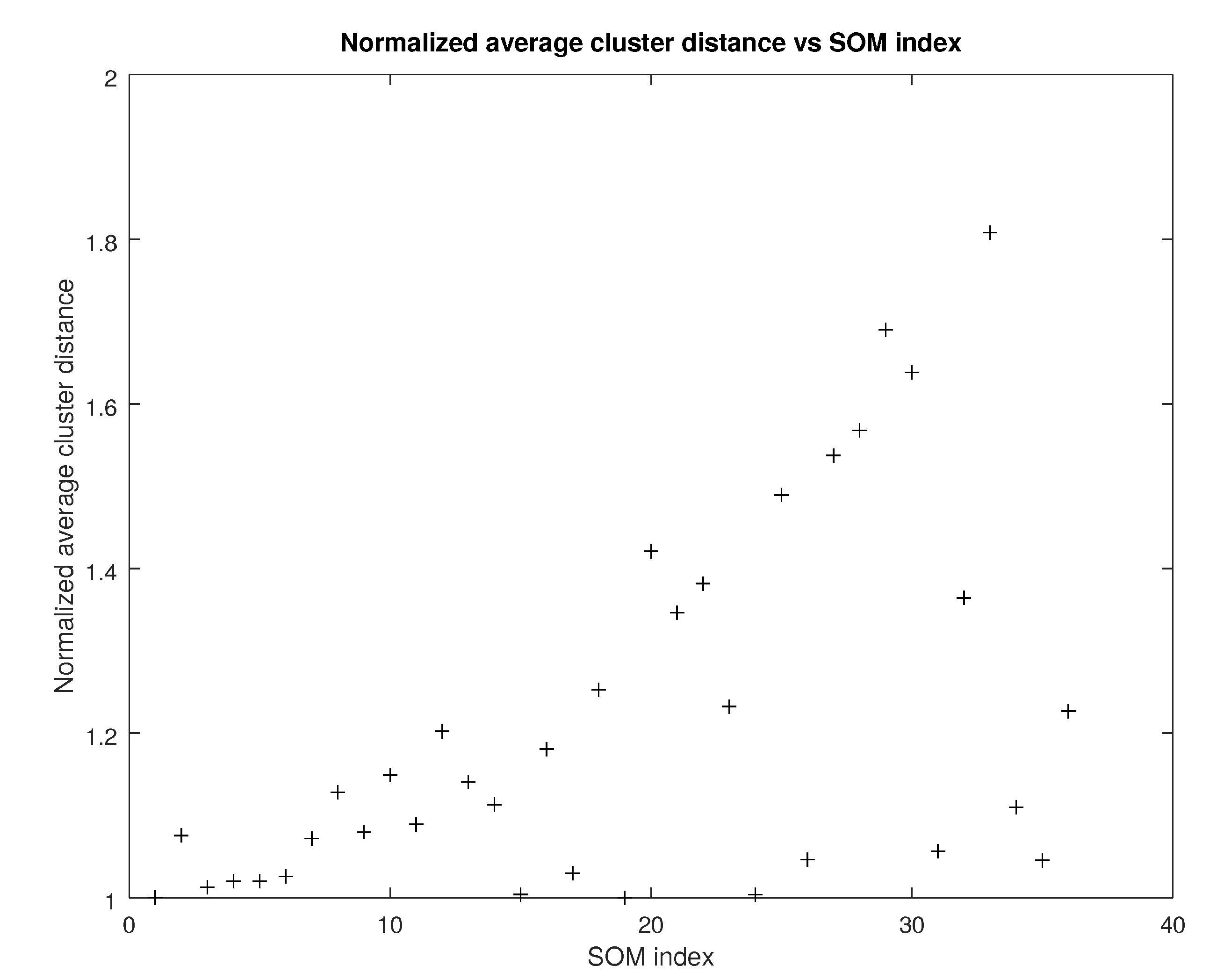
5.5. Clustering Quality
5.6. MBTI Permutations
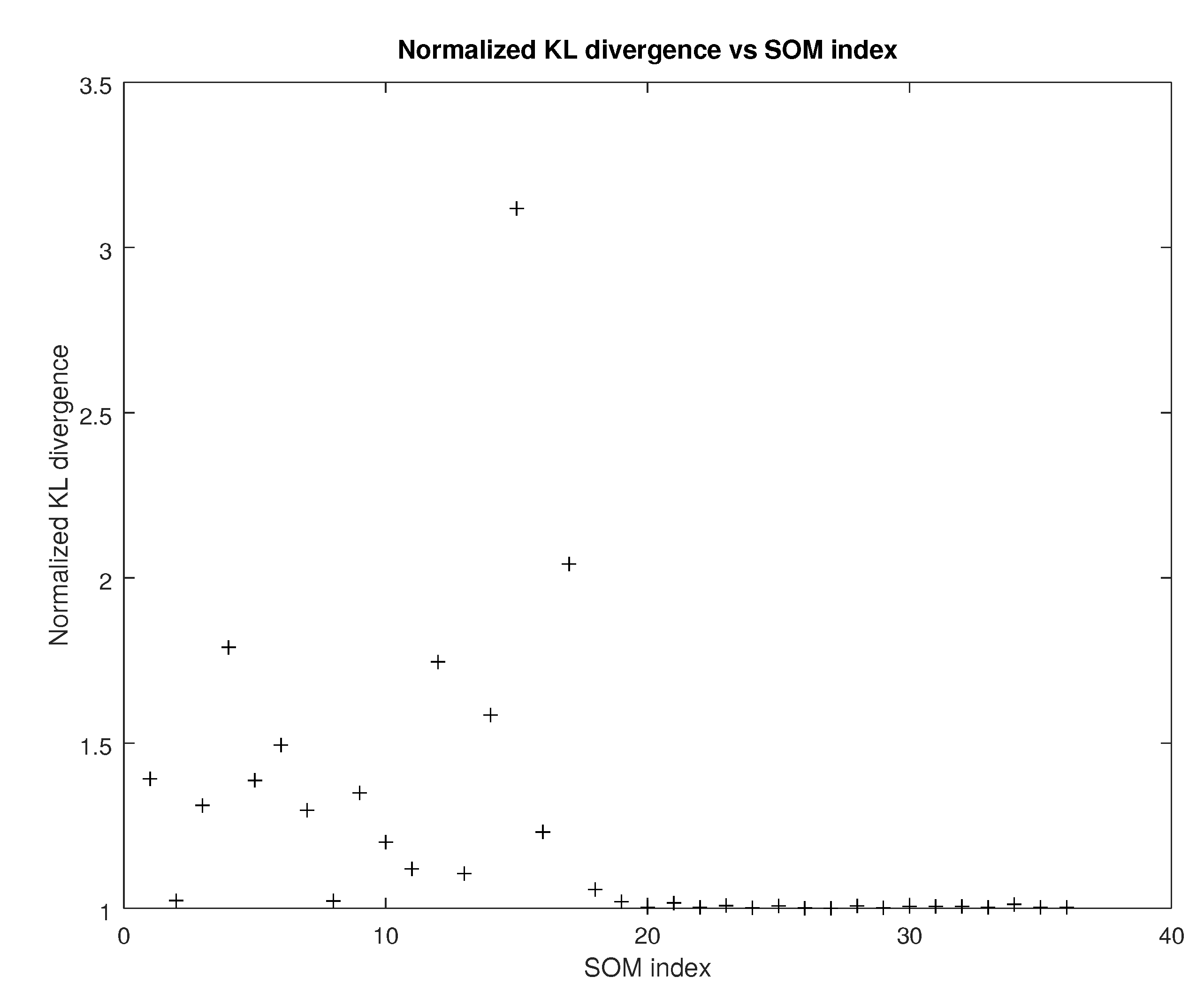
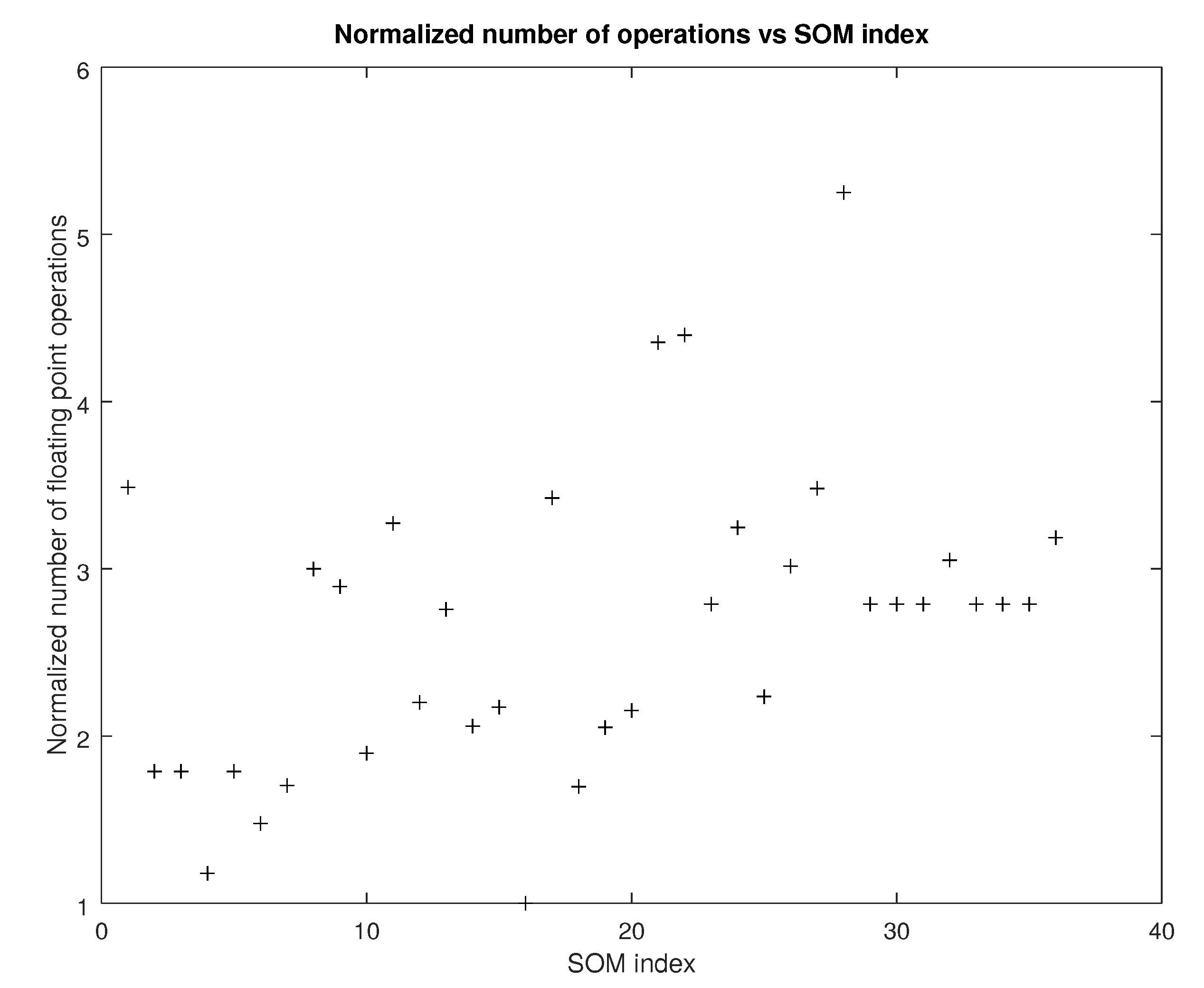
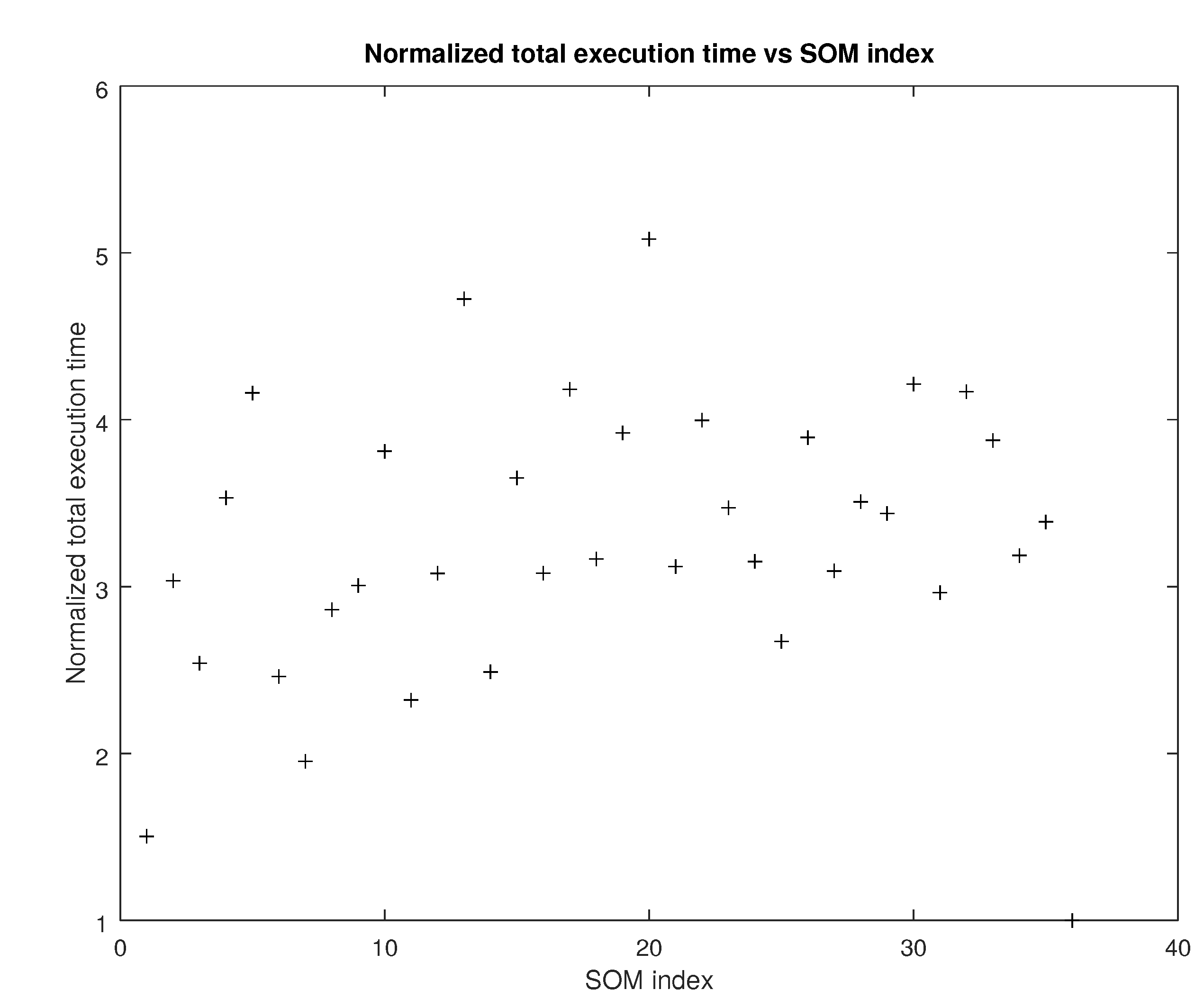
5.7. Complexity
5.8. Discussion
- The cosine decay rate outperforms the inverse linear and the exponential ones. This can be explained by the adaptive nature of the cosine as well as by the fact that the exponential function decays too fast and before convergence is truly achieved.
- Partitioning clusters in Gaussian regions results in lower error in every test case. This is explained by the less sharp shape of these regions compared to cubes or domes. Moreover, with the tensor distance metrics, which can in the general case approximate more smooth shapes, the cluster boundaries can better adapt to the topological properties of the dataset.
- The fuzzy version of the tensor distance metric results in better performance, even a slight one, in all cases. The reason for this may be the additional flexibility since personalities sharing traits from two categories can belong to both up to an extent. On the contrary, all the other distance metrics assign a particular personality to a single cluster.
- The complexity of the tensor metrics in terms of the number of floating point operations involved is clearly more than that of either the and the norm. However, because of the lower number of iterations that difference is not evident in the total execution time.
- The interpretability of the resulting cognitive map is limited by the texts of the original dataset, which in turn are answers to specific questions. Adding more cognitive dimensions to these texts would improve personality clustering quality.
- Although the MBTI map is small, for each cognitive map there is a large number of equivalent permutations. Finding them is a critical step before any subsequent analysis takes place.
- The curent version of the proposed methodology does not utilize neuron bias.
5.9. Recommendations
- Text, despite being an invaluable source of information about human traits, is not the only one. It is highly advisable that a cross check with other methods utilizing other modalities should take place.
- In case where the personalities of two or more group members are evaluated, it is advisable that their compatibility is checked against the group tasks in order to discover potential conflict points or communication points as early as possible.
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kangas, J.; Kohonen, T.; Laaksonen, J. Variants of self-organizing maps. IEEE Trans. Neural Netw. 1990, 1, 93–99. [Google Scholar] [PubMed]
- Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C.; Lagani, G. Hebbian learning meets deep convolutional neural networks. In Proceedings of the International Conference on Image Analysis and Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 324–334. [Google Scholar]
- Myers, S. Myers-Briggs typology and Jungian individuation. J. Anal. Psychol. 2016, 61, 289–308. [Google Scholar] [PubMed]
- Isaksen, S.G.; Lauer, K.J.; Wilson, G.V. An examination of the relationship between personality type and cognitive style. Creat. Res. J. 2003, 15, 343–354. [Google Scholar]
- Poria, S.; Majumder, N.; Mihalcea, R.; Hovy, E. Emotion recognition in conversation: Research challenges, datasets, and recent advances. IEEE Access 2019, 7, 100943–100953. [Google Scholar]
- Batbaatar, E.; Li, M.; Ryu, K.H. Semantic-emotion neural network for emotion recognition from text. IEEE Access 2019, 7, 111866–111878. [Google Scholar]
- Beliy, R.; Gaziv, G.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI. In Proceedings of the 2019 Conference on Neural Information Processing Systems NIPS, Vancouver, BC, Canada, 8–14 September 2019; pp. 6517–6527. [Google Scholar]
- Sidhu, G. Locally Linear Embedding and fMRI feature selection in psychiatric classification. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–11. [Google Scholar]
- Sun, X.; Pei, Z.; Zhang, C.; Li, G.; Tao, J. Design and Analysis of a Human-Machine Interaction System for Researching Human’s Dynamic Emotion. IEEE Trans. Syst. Man Cybern. Syst. 2019. [Google Scholar] [CrossRef]
- Vesanto, J.; Alhoniemi, E. Clustering of the self-organizing map. IEEE Trans. Neural Netw. 2000, 11, 586–600. [Google Scholar]
- Kohonen, T. Exploration of very large databases by self-organizing maps. In Proceedings of the International Conference on Neural Networks (ICNN’97), Houston, TX, USA, 12 June 1997; Volume 1, pp. PL1–PL6. [Google Scholar]
- Kosko, B. Fuzzy cognitive maps. Int. J. Man-Mach. Stud. 1986, 24, 65–75. [Google Scholar]
- Taber, R. Knowledge processing with fuzzy cognitive maps. Expert Syst. Appl. 1991, 2, 83–87. [Google Scholar]
- Stach, W.; Kurgan, L.; Pedrycz, W.; Reformat, M. Genetic learning of fuzzy cognitive maps. Fuzzy Sets Syst. 2005, 153, 371–401. [Google Scholar]
- Yang, Z.; Liu, J. Learning of fuzzy cognitive maps using a niching-based multi-modal multi-agent genetic algorithm. Appl. Soft Comput. 2019, 74, 356–367. [Google Scholar]
- Salmeron, J.L.; Mansouri, T.; Moghadam, M.R.S.; Mardani, A. Learning fuzzy cognitive maps with modified asexual reproduction optimisation algorithm. Knowl.-Based Syst. 2019, 163, 723–735. [Google Scholar]
- Wu, K.; Liu, J. Robust learning of large-scale fuzzy cognitive maps via the lasso from noisy time series. Knowl.-Based Syst. 2016, 113, 23–38. [Google Scholar]
- Wu, K.; Liu, J. Learning large-scale fuzzy cognitive maps based on compressed sensing and application in reconstructing gene regulatory networks. IEEE Trans. Fuzzy Syst. 2017, 25, 1546–1560. [Google Scholar]
- Liu, Y.c.; Wu, C.; Liu, M. Research of fast SOM clustering for text information. Expert Syst. Appl. 2011, 38, 9325–9333. [Google Scholar]
- Drakopoulos, G.; Giannoukou, I.; Mylonas, P.; Sioutas, S. On tensor distances for self organizing maps: Clustering cognitive tasks. In Proceedings of the International Conference on Database and Expert Systems Applications Part II; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12392, pp. 195–210. [Google Scholar] [CrossRef]
- Nam, T.M.; Phong, P.H.; Khoa, T.D.; Huong, T.T.; Nam, P.N.; Thanh, N.H.; Thang, L.X.; Tuan, P.A.; Dung, L.Q.; Loi, V.D. Self-organizing map-based approaches in DDoS flooding detection using SDN. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 249–254. [Google Scholar]
- Hawer, S.; Braun, N.; Reinhart, G. Analyzing interdependencies between factory change enablers applying fuzzy cognitive maps. Procedia CIRP 2016, 52, 151–156. [Google Scholar]
- Zhu, S.; Zhang, Y.; Gao, Y.; Wu, F. A Cooperative Task Assignment Method of Multi-UAV Based on Self Organizing Map. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 437–4375. [Google Scholar]
- Ladeira, M.J.; Ferreira, F.A.; Ferreira, J.J.; Fang, W.; Falcão, P.F.; Rosa, Á.A. Exploring the determinants of digital entrepreneurship using fuzzy cognitive maps. Int. Entrep. Manag. J. 2019, 15, 1077–1101. [Google Scholar]
- Herrero, J.; Dopazo, J. Combining hierarchical clustering and self-organizing maps for exploratory analysis of gene expression patterns. J. Proteome Res. 2002, 1, 467–470. [Google Scholar]
- Imani, M.; Ghoreishi, S.F. Optimal Finite-Horizon Perturbation Policy for Inference of Gene Regulatory Networks. IEEE Intell. Syst. 2020. [Google Scholar] [CrossRef]
- Drakopoulos, G.; Gourgaris, P.; Kanavos, A. Graph communities in Neo4j: Four algorithms at work. Evol. Syst. 2019. [Google Scholar] [CrossRef]
- Gutiérrez, I.; Gómez, D.; Castro, J.; Espínola, R. A new community detection algorithm based on fuzzy measures. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 23–25 July 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–140. [Google Scholar]
- Luo, W.; Yan, Z.; Bu, C.; Zhang, D. Community detection by fuzzy relations. IEEE Trans. Emerg. Top. Comput. 2017, 8, 478–492. [Google Scholar] [CrossRef]
- Drakopoulos, G.; Gourgaris, P.; Kanavos, A.; Makris, C. A fuzzy graph framework for initializing k-means. IJAIT 2016, 25, 1650031:1–1650031:21. [Google Scholar] [CrossRef]
- Yang, C.H.; Chuang, L.Y.; Lin, Y.D. Epistasis Analysis using an Improved Fuzzy C-means-based Entropy Approach. IEEE Trans. Fuzzy Syst. 2019, 28, 718–730. [Google Scholar] [CrossRef]
- Tang, Y.; Ren, F.; Pedrycz, W. Fuzzy C-means clustering through SSIM and patch for image segmentation. Appl. Soft Comput. 2020, 87, 105928. [Google Scholar] [CrossRef]
- Felix, G.; Nápoles, G.; Falcon, R.; Froelich, W.; Vanhoof, K.; Bello, R. A review on methods and software for fuzzy cognitive maps. Artif. Intell. Rev. 2019, 52, 1707–1737. [Google Scholar] [CrossRef]
- Etingof, P.; Gelaki, S.; Nikshych, D.; Ostrik, V. Tensor Categories; American Mathematical Soc.: Providence, RI, USA, 2016; Volume 205. [Google Scholar]
- Batselier, K.; Chen, Z.; Liu, H.; Wong, N. A tensor-based volterra series black-box nonlinear system identification and simulation framework. In Proceedings of the 2016 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 7–10 November 2016; pp. 1–7. [Google Scholar]
- Batselier, K.; Chen, Z.; Wong, N. Tensor Network alternating linear scheme for MIMO Volterra system identification. Automatica 2017, 84, 26–35. [Google Scholar] [CrossRef]
- Batselier, K.; Ko, C.Y.; Wong, N. Tensor network subspace identification of polynomial state space models. Automatica 2018, 95, 187–196. [Google Scholar] [CrossRef]
- Battaglino, C.; Ballard, G.; Kolda, T.G. A practical randomized CP tensor decomposition. SIAM J. Matrix Anal. Appl. 2018, 39, 876–901. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Ragusa, E.; Gastaldo, P.; Zunino, R.; Cambria, E. Learning with similarity functions: A tensor-based framework. Cogn. Comput. 2019, 11, 31–49. [Google Scholar] [CrossRef]
- Lu, W.; Chung, F.L.; Jiang, W.; Ester, M.; Liu, W. A deep Bayesian tensor-based system for video recommendation. ACM Trans. Inf. Syst. 2018, 37, 1–22. [Google Scholar] [CrossRef]
- Drakopoulos, G.; Stathopoulou, F.; Kanavos, A.; Paraskevas, M.; Tzimas, G.; Mylonas, P.; Iliadis, L. A genetic algorithm for spatiosocial tensor clustering: Exploiting TensorFlow potential. Evol. Syst. 2020, 11, 491–501. [Google Scholar] [CrossRef]
- Bao, Y.T.; Chien, J.T. Tensor classification network. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Yu, D.; Deng, L.; Seide, F. The deep tensor neural network with applications to large vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 388–396. [Google Scholar] [CrossRef]
- Drakopoulos, G.; Mylonas, P. Evaluating graph resilience with tensor stack networks: A Keras implementation. Neural Comput. Appl. 2020, 32, 4161–4176. [Google Scholar] [CrossRef]
- Hore, V.; Viñuela, A.; Buil, A.; Knight, J.; McCarthy, M.I.; Small, K.; Marchini, J. Tensor decomposition for multiple-tissue gene expression experiments. Nat. Genet. 2016, 48, 1094. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Fu, H.; Liu, S.; Liu, G.; Cao, X. Low-rank tensor constrained multiview subspace clustering. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 1582–1590. [Google Scholar]
- Cao, X.; Wei, X.; Han, Y.; Lin, D. Robust face clustering via tensor decomposition. IEEE Trans. Cybern. 2014, 45, 2546–2557. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Alexopoulos, A.; Drakopoulos, G.; Kanavos, A.; Mylonas, P.; Vonitsanos, G. Two-step classification with SVD preprocessing of distributed massive datasets in Apache Spark. Algorithms 2020, 13, 71. [Google Scholar] [CrossRef]
- Yang, H.K.; Yong, H.S. S-PARAFAC: Distributed tensor decomposition using Apache Spark. J. KIISE 2018, 45, 280–287. [Google Scholar] [CrossRef]
- Bezanson, J.; Edelman, A.; Karpinski, S.; Shah, V.B. Julia: A fresh approach to numerical computing. SIAM Rev. 2017, 59, 65–98. [Google Scholar] [CrossRef]
- Bezanson, J.; Chen, J.; Chung, B.; Karpinski, S.; Shah, V.B.; Vitek, J.; Zoubritzky, L. Julia: Dynamism and performance reconciled by design. Proc. ACM Program. Lang. 2018, 2, 1–23. [Google Scholar] [CrossRef]
- Lee, J.; Kim, Y.; Song, Y.; Hur, C.K.; Das, S.; Majnemer, D.; Regehr, J.; Lopes, N.P. Taming undefined behavior in LLVM. ACM SIGPLAN Not. 2017, 52, 633–647. [Google Scholar] [CrossRef]
- Innes, M. Flux: Elegant machine learning with Julia. J. Open Source Softw. 2018, 3, 602. [Google Scholar] [CrossRef]
- Besard, T.; Foket, C.; De Sutter, B. Effective extensible programming: Unleashing Julia on GPUs. IEEE Trans. Parallel Distrib. Syst. 2018, 30, 827–841. [Google Scholar] [CrossRef]
- Mogensen, P.K.; Riseth, A.N. Optim: A mathematical optimization package for Julia. J. Open Source Softw. 2018, 3. [Google Scholar] [CrossRef]
- Ruthotto, L.; Treister, E.; Haber, E. jinv–A flexible Julia package for PDE parameter estimation. SIAM J. Sci. Comput. 2017, 39, S702–S722. [Google Scholar] [CrossRef]
- Krämer, S.; Plankensteiner, D.; Ostermann, L.; Ritsch, H. QuantumOptics.jl: A Julia framework for simulating open quantum systems. Comput. Phys. Commun. 2018, 227, 109–116. [Google Scholar] [CrossRef]
- Witte, P.A.; Louboutin, M.; Kukreja, N.; Luporini, F.; Lange, M.; Gorman, G.J.; Herrmann, F.J. A large-scale framework for symbolic implementations of seismic inversion algorithms in Julia. Geophysics 2019, 84, F57–F71. [Google Scholar] [CrossRef]
- Pittenger, D.J. The utility of the Myers-Briggs type indicator. Rev. Educ. Res. 1993, 63, 467–488. [Google Scholar] [CrossRef]
- Gordon, A.M.; Jackson, D. A Balanced Approach to ADHD and Personality Assessment: A Jungian Model. N. Am. J. Psychol. 2019, 21, 619–646. [Google Scholar]
- Lake, C.J.; Carlson, J.; Rose, A.; Chlevin-Thiele, C. Trust in name brand assessments: The case of the Myers-Briggs type indicator. Psychol.-Manag. J. 2019, 22, 91. [Google Scholar] [CrossRef]
- Stein, R.; Swan, A.B. Evaluating the validity of Myers-Briggs Type Indicator theory: A teaching tool and window into intuitive psychology. Soc. Personal. Psychol. Compass 2019, 13, e12434. [Google Scholar] [CrossRef]
- Plutchik, R.E.; Conte, H.R. Circumplex Models of Personality and Emotions; American Psychological Association: Washington, DC, USA, 1997. [Google Scholar]
- Ekman, P. Darwin, deception, and facial expression. Ann. N. Y. Acad. Sci. 2003, 1000, 205–221. [Google Scholar] [CrossRef] [PubMed]
- Furnham, A. Myers-Briggs type indicator (MBTI). In Encyclopedia of Personality and Individual Differences; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3059–3062. [Google Scholar]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech emotion classification using attention-based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Kim, Y.; Moon, J.; Sung, N.J.; Hong, M. Correlation between selected gait variables and emotion using virtual reality. J. Ambient. Intell. Humaniz. Comput. 2019, 1–8. [Google Scholar] [CrossRef]
- Zheng, W.; Yu, A.; Fang, P.; Peng, K. Exploring collective emotion transmission in face-to-face interactions. PLoS ONE 2020, 15, e0236953. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Kavuri, S.; Lee, M. A multimodal convolutional neuro-fuzzy network for emotion understanding of movie clips. Neural Netw. 2019, 118, 208–219. [Google Scholar] [CrossRef]
- Mishro, P.K.; Agrawal, S.; Panda, R.; Abraham, A. A novel type-2 fuzzy C-means clustering for brain MR image segmentation. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef]
- Sheldon, S.; El-Asmar, N. The cognitive tools that support mentally constructing event and scene representations. Memory 2018, 26, 858–868. [Google Scholar] [CrossRef]
- Zap, N.; Code, J. Virtual and augmented reality as cognitive tools for learning. In EdMedia+ Innovate Learning; Association for the Advancement of Computing in Education (AACE): Waynesville, NC, USA, 2016; pp. 1340–1347. [Google Scholar]
- Spevack, S.C. Cognitive Tools and Cognitive Styles: Windows into the Culture-Cognition System. Ph.D. Thesis, UC Merced, Merced, CA, USA, 2019. [Google Scholar]
- Lajoie, S.P. Computers As Cognitive Tools: Volume II, No More Walls; Routledge: London, UK, 2020. [Google Scholar]
- Abiri, R.; Borhani, S.; Sellers, E.W.; Jiang, Y.; Zhao, X. A comprehensive review of EEG-based brain–computer interface paradigms. J. Neural Eng. 2019, 16, 011001. [Google Scholar] [CrossRef]
- Ramadan, R.A.; Vasilakos, A.V. Brain computer interface: Control signals review. Neurocomputing 2017, 223, 26–44. [Google Scholar] [CrossRef]
- Sakhavi, S.; Guan, C.; Yan, S. Learning temporal information for brain-computer interface using convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5619–5629. [Google Scholar] [CrossRef] [PubMed]
- Kaur, B.; Singh, D.; Roy, P.P. Age and gender classification using brain–computer interface. Neural Comput. Appl. 2019, 31, 5887–5900. [Google Scholar] [CrossRef]
- Beale, M.H.; Hagan, M.T.; Demuth, H.B. Neural Network Toolbox User’s Guide; The Mathworks Inc.: Natick, MA, USA, 2010. [Google Scholar]
- Graillat, S.; Ibrahimy, Y.; Jeangoudoux, C.; Lauter, C. A Parallel Compensated Horner Scheme. In Proceedings of the SIAM Conference on Computational Science and Engineering (CSE), Atlanta, GA, USA, 3 March–27 February 2017. [Google Scholar]
- Amirhosseini, M.H.; Kazemian, H. Machine Learning Approach to Personality Type Prediction Based on the Myers–Briggs Type Indicator®. Multimodal Technol. Interact. 2020, 4, 9. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| Definition or equality by definition | |
| or | Set with elements |
| or | Set cardinality |
| Tensor multiplication along the k-th direction | |
| Vectorize operation for matrices and tensors | |
| Location function for data points | |
| Inverse location relationship for neurons | |
| Synaptic weights of neuron u | |
| Bias of neuron u | |
| Neighborhood of neuron u | |
| Cover of neuron u | |
| Kullback-Leibler divergence between discrete distributions and |
| Type | Attributes | Type | Attributes |
|---|---|---|---|
| ISTJ | Introversion, Sensing, Thinking, Judging | INFJ | Introversion, Intuition, Feeling, Judging |
| ISTP | Introversion, Sensing, Thinking, Perceiving | INFP | Introversion, Intuition, Feeling, Perceiving |
| ESTP | Extraversion, Sensing, Thinking, Perceiving | ENFP | Extraversion, Intuition, Feeling, Perceiving |
| ESTJ | Extraversion, Sensing, Thinking, Judging | ENFJ | Extraversion, Intuition, Feeling, Judging |
| ISFJ | Introversion, Sensing, Feeling, Judging | INTJ | Introversion, Intuition, Thinking, Judging |
| ISFP | Introversion, Sensing, Feeling, Perceiving | INTP | Introversion, Intuition, Thinking, Perceiving |
| ESFP | Extraversion, Sensing, Feeling, Perceiving | ENTP | Extraversion, Intuition, Thinking, Perceiving |
| ESFJ | Extraversion, Sensing, Feeling, Judging | ENTJ | Extraversion, Intuition, Thinking, Judging |
| Neighborhood | Weight | Shape | Neighborhood | Weight | Shape |
|---|---|---|---|---|---|
| Square | Square | Cube | Triangular | Triangular | Pyramid |
| Square | Triangular | Pyramid | Circular | Semicircular | Dome |
| Square | Semicircular | Dome | Gaussian | Gaussian | 3D Gaussian |
| Attribute | Position in (31) |
|---|---|
| Normalized number of words | |
| Normalized number of characters | |
| Normalized number of punctuation marks | |
| Normalized number of question marks | |
| Normalized number of exclamation points | |
| Normalized number of occurences of two or more ’.’ | |
| Normalized number of positive words | |
| Normalized number of negative words | |
| Normalized number of self-references | |
| Normalized number of references to others | |
| Normalized number of words pertaining to emotion | |
| Normalized number of words pertaining to reason |
| Parameter | Options |
|---|---|
| Synaptic weight initialization | Random |
| Bias mechanism | Not implemented |
| Neighborhood shape | Cross |
| Distance function | Tensor (T), Fuzzy tensor (F), norm (L1), norm (L2) |
| Proximity function | Gaussian (G), Circular (C), Rectangular (R) |
| Cover threshold - Equation (27) | |
| Weight function in | Gaussian, Circular, Rectangular (as above) |
| Gaussian | , |
| Circular | |
| Rectangular | |
| Learning rate parameter | Cosine (S), Inverse linear (L), Inverse quadratic (Q), Exponential (E) |
| Cosine | |
| Inverse linear | , , |
| Exponential | , |
| Grid size and - Equation (30) | , |
| Number of classes | 16 |
| Number of rows per class | 256 |
| Number of attributes | 2 |
| Number of runs | 100 |
| # | Configuration | # | Configuration | # | Configuration | # | Configuration |
|---|---|---|---|---|---|---|---|
| 1 | 10 | 19 | 28 | ||||
| 2 | 11 | 20 | 29 | ||||
| 3 | 12 | 21 | 30 | ||||
| 4 | 13 | 22 | 31 | ||||
| 5 | 14 | 23 | 32 | ||||
| 6 | 15 | 24 | 33 | ||||
| 7 | 16 | 25 | 34 | ||||
| 8 | 17 | 26 | 35 | ||||
| 9 | 18 | 27 | 36 |
| Cosine | Inv. linear | Exponential | |
|---|---|---|---|
| norm | / | / | / |
| norm | / | / | / |
| Tensor | / | / | / |
| Fuzzy | / | / | / |
| ISTJ | ISFJ | INFJ | INTJ |
| ISTP | ISFP | INFP | INTP |
| ESTP | ESFP | ENFP | ENTP |
| ESTJ | ESFJ | ENFJ | ENTJ |
| ENFJ | ISFP | ENFJ | ESFP |
| ISTJ | INTP | ESTJ | ISFJ |
| INTJ | INFJ | ENTP | ISTP |
| ESFJ | ENTJ | ESTP | ISFP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drakopoulos, G.; Kanavos, A.; Mylonas, P.; Pintelas, P. Extending Fuzzy Cognitive Maps with Tensor-Based Distance Metrics. Mathematics 2020, 8, 1898. https://doi.org/10.3390/math8111898
Drakopoulos G, Kanavos A, Mylonas P, Pintelas P. Extending Fuzzy Cognitive Maps with Tensor-Based Distance Metrics. Mathematics. 2020; 8(11):1898. https://doi.org/10.3390/math8111898
Chicago/Turabian StyleDrakopoulos, Georgios, Andreas Kanavos, Phivos Mylonas, and Panagiotis Pintelas. 2020. "Extending Fuzzy Cognitive Maps with Tensor-Based Distance Metrics" Mathematics 8, no. 11: 1898. https://doi.org/10.3390/math8111898
APA StyleDrakopoulos, G., Kanavos, A., Mylonas, P., & Pintelas, P. (2020). Extending Fuzzy Cognitive Maps with Tensor-Based Distance Metrics. Mathematics, 8(11), 1898. https://doi.org/10.3390/math8111898