1. Introduction
In certain clinical studies, it is important to assess covariate effect types to indicate whether a covariate is predictive and/or prognostic in the context of treatment effectiveness. Clark et al. [
1] defined a predictive factor as a factor associated with the response or lack of response to a particular therapy, while a prognostic factor is a factor associated with the clinical outcome in the absence of therapy, or with the application of a standard therapy. To assess whether a covariate is predictive and/or prognostic, subgroup or regression analysis is often used [
2]. For a case with a binary outcome, on the difference scale, a binary covariate
is predictive if
is not zero, where
is the treatment arm (
for the experimental treatment and
for the control treatment) and
is the outcome (
for response and
for no response). If
is close to zero,
is prognostic if
is not zero.
Recently, for cases with a binary outcome, Chiba [
3] proposed assessing covariate effect types based on four response types [
4] defined in terms of the potential outcome of
if
is
,
, rather than
and
as above. The four response types are defined as follows:
Activated subjects, who would show a response regardless of the treatment they received; that is, ;
Causative subjects, who would show a response only if they received the experimental treatment; that is, ;
Preventive subjects, who would show a response only if they received the control treatment; that is, ;
Inert subjects, who would not show a response regardless of the treatment they received; that is, .
Based on the four response types, measures of the covariate effect types are defined as follows [
3]:
for
. Then,
can be used instead of a current common measure for predicting the effectiveness of the experimental treatment, i.e.,
in (1).
indicates that the proportion of subjects who would show a response only if they received the experimental treatment is higher in the subgroup where
than in the subgroup where
. In addition, we can consider predictability for the effectiveness of the control treatment (or the harm caused by the experimental treatment) by
. Instead of a current common measure for a prognostic factor, i.e.,
in (2),
can be used.
indicates that the proportion of subjects who would show a response regardless of the treatment they received is higher in the subgroup where
than in the subgroup where
.
Applying the potential outcome
to (1) under the assumption of
, which indicates that
is independent from
given
, the following relationship between (1) and (3) is obtained:
Similarly, the following relationship holds between (2) and (3):
Obviously, if
, the currently used definition of covariate effect types does not correspond to the new definition in (3). Except for the special case of
, under the current definition, the two characteristics of covariate effect cannot be separated from each other. In actual clinical studies, the aim is to assess covariate effect type on the basis of (3) rather than (1) and (2). However, (3) can be applied only when an outcome is binary and not when an outcome is continuous or time-to-event-based. In this article, we aim to generalize (3) to continuous and time-to-event outcomes. We provide a definition of measures of covariate effect types in
Section 2 and propose a simple method to estimate those measures in
Section 3. In
Section 4, our approach is illustrated using data from a clinical study with a time-to-event outcome. Finally, in
Section 5, the performance of the proposed approach and directions for future work in this area are discussed.
2. Definition of Measures of Covariate Effect Types
In the following, we mainly discuss a case with a time-to-event outcome
. However, this discussion can also be applied to a case with a continuous outcome as a special case without censored data in which a larger value represents a better response.
and
are the same as in
Section 1; i.e.,
is a binary treatment arm and
is a binary covariate.
is the potential outcome of
if
had been set to
. Unfortunately, it is not possible to observe the values of both
and
; i.e.,
[
5]. We use the stable unit treatment value assumption under which a single version of each treatment is available and there is no interference among subjects [
6,
7].
When an outcome is time-to-event, the response type
cannot be classified into four types unlike in the case of a binary outcome described in
Section 1. However, if we set a cut-off point
, the time-to-event outcome can be regarded as a binary variable; then, we can consider the following four response types.
Definition 1 (Response type).Using a cut-off point, the response type can be classified into the following four types:
Activated subjects (type 11 subjects), whose outcomes would be larger than or equal to, regardless of the treatment they received; that is,;
Causative subjects (type 10 subjects), whose outcomes would be larger than or equal toif they received the experimental treatment, but would be smaller thanif they received the control treatment; that is,;
Preventive subjects (type 01 subjects), whose outcomes would be smaller thanif they received the experimental treatment, but would be larger or equal toif they received the control treatment; that is,;
Inert subjects (type 00 subjects), whose outcomes would be smaller than, regardless of the treatment they received; that is,.
All subjects belong to one of these four types, although we cannot know which type a subject belongs to. We denote a proportion of the
subjects of the total subjects as
; i.e.,
and the proportion in the stratum with
as
. Then,
corresponds to the survival probability under the experimental condition and
is that under the control condition. For a continuous outcome, they correspond to one minus the cumulative density function.
Using
, we can simply define measures of covariate effect types at the cut-off point
by
This is essentially the same as in (3). Unfortunately, with a fixed cannot be applied as a general definition of measures of covariate types. If there is a medically meaningful cut-off point, the outcome is no longer time-to-event (continuous); rather, it is binary. If the cut-off point has no medical significance, it is not valuable to use a fixed cut-off point. and with a fixed cut-off point may also not be useful. Using these probabilities with changed on the interval, we define the restricted mean probability (RMP) as follows.
Definition 2 (Restricted mean probability).The restricted mean probability for response type on the interval,,
is defined by the following formula:for.
In this definition, and will usually be set to and , respectively, where is the truncation time; for a continuous outcome, these values will be set to the minimum and maximum values of the observed outcome, respectively. in the stratum with is defined in the same manner. is the restricted expectation of on the interval . Then, is interpreted as the mean proportion of type subjects when the cut-off point is changed from to .
It is important to note that is related to , which is the restricted expectation of the potential outcome on the interval .
Lemma 1. We have the following relationships betweenand:
The proof is given in
Appendix A. The difference between these two equations indicates that the restricted average causal effect on the interval
can be expressed as
. Notably, when
and
,
and
correspond to the restricted mean survival times (RMSTs) [
8,
9,
10], which are equal to the areas under the survival curves on the interval
under the experimental and control conditions, respectively. Similarly,
and
correspond to the restricted mean time lost [
9] under the experimental and control conditions, respectively.
We give a general definition of measures of covariate effect types using , which is the RMP of a given response type in the stratum with .
Proposition 1. We define a measure of covariate effect type asfor.
The interpretation of is similar to that of in (3) for a case with a binary outcome. As a prediction measure, we use and . implies the subgroup where contains a higher proportion of subjects who would survive longer by receiving the experimental treatment than the subgroup where . Then, predicts the effectiveness of the experimental treatment, and we say that is “augmented-causative”. If , we say that is “depleted-causative”. In a similar sense, is a prediction measure of the effectiveness of the control treatment (or for the harm associated with proceeding with the experimental treatment).
We note that for a case with a time-to-event (continuous) outcome, we can obtain results similar to (4) and (5) when the outcome is binary. Using Proposition 1 and Lemma 1, the prediction and prognosis measures based on conventional standard analysis, and , can be expressed as functions of on the difference scale.
Corollary 1. We have the following equations:where.
On the basis of this corollary, in Proposition 1 can be related to the prognosis under the current standard analysis. Similar to the currently used standard analysis, if is close to , which implies that is close to zero, is prognostic if is not zero. implies that the mean survival time is longer for subjects in the subgroup where than the subgroup where , regardless of the treatment they received. In this case, we say that is “augmented-activated”. In contrast, when , we say that is “depleted-activated”.
Finally, we emphasize that Corollary 1 indicates that the results of the current standard analysis can be properly interpreted when ; however, this may not be the case when . On the other hand, our measure of covariate effect type can assess whether a covariate is predictive and/or prognostic, even when .
3. Estimation of Measures of Covariate Effect Types
Unfortunately,
in Proposition 1 cannot be identified based on the observed data without making certain assumptions, because the joint probability of
and
cannot be estimated [
11,
12]. Therefore, we use two assumptions that are often applied in the context of the pairwise comparison based on
[
13,
14,
15].
Assumption 1 (Ignorable treatment assignment).The potential outcomeis independent of the treatment arm; i.e.,. It is also assumed that.
Assumption 2 (Independent potential outcome).Two potential outcomes are independent of each other; i.e.,.
Assumption 1 is often made in randomized trials. Although some authors have discussed methods to infer
without Assumption 2 [
16,
17], the methods are impractical as they tend to be complex and/or require considerable computational effort.
Corollary 2. in (6) is identified under Assumptions 1 and 2 as follows:
in the stratum with
is also identified under Assumptions 1 and 2, thus allowing
in Definition 2 and
in Proposition 1 to be identified.
We propose a method to estimate in Definition 2 based on the formula in Corollary 2. Let us denote the observed event occurrence or censoring time as in which the time points in both arms are included. Then, we can use the cut-off point as a discrete value taking only the same value as ; that is, it is sufficient to consider as the cut-off points. We also set the interval to , where is the truncation time. These settings yield the following formula to estimate .
Proposition 2. For a time-to-event outcome, we estimatewith truncation timeunder Assumptions 1 and 2 as follows:whereand is the survival probability estimated using the Kaplan–Meier method. Then, we estimate
by
Censoring is considered when estimating by the Kaplan–Meier method. In a similar manner, and are estimated by applying Proposition 2 to the stratum with Z = z. Thus, , in (7) and in Proposition 1 can be estimated based on the observed data. It is obvious from Proposition 2 that and are consistent with the estimators of the RMST in the arm with X = x.
To derive the formulas to estimate and for a continuous outcome without censoring, let us suppose that t1 < ⋯ < tj < ⋯ tD are the observed values of the continuous outcome. The interval [ta,tb] is set to [t1,tD]. Here, we denote the number of subjects taking the value tj in the experimental arm as nj and that in the control arm as mj. Then, and are estimated by the following formulas.
Proposition 3. For a continuous outcome, we estimate under Assumptions 1 and 2 by
where
and
.
Let us denote the outcome values as () for subjects in the experimental arm and for those in the control arm. Then, in relation to Lemma 1, we have Lemma 2 below.
Lemma 2. When in Proposition 3 are used, the following equations hold:
The proof is given in
Appendix B. In this lemma, the right sides correspond to the arithmetic means in the arm with
. As the arithmetic mean is a plausible estimate of E{
T|
X =
x}, the left sides are plausible estimates of unrestricted rather than restricted expectation of
,
, under Assumption 1.
4. Illustration
We illustrate our measure of covariate effect type using the clinical data set of Ohashi and Hamada [
18]. The purpose of that study was to determine whether the survival time is longer with use of radiation during surgery (
) than without it (
) in subjects with pancreatic cancer. As it was an observational study, Assumption 1 would not hold. Nevertheless, we analyzed the data under this assumption, so the following analyses are for illustrative purposes only.
We explored the covariate effect type in the context of radiation effectiveness in the pancreatic cancer site, which was subclassified as pancreatic head (
) or “other” (
). In the pancreatic head subgroup, 51 subjects received radiation during surgery and 14 subjects did not. In the other subgroup, nine subjects (including one censored subject) received radiation and nine did not. The survival curves in both subgroups are shown in
Figure 1.
Table 1 summarizes the RMST estimates and differences between arms in both subgroups, with 95% confidence intervals (CIs). For the estimation, the truncation time was set to the maximum observed time, 21.6 (months), because the final survival probability was zero in both arms in both subgroups.
Before applying our approach, we first applied the current standard analysis given by
and
in Corollary 1. Using the RMST estimates in
Table 1,
(95% CI: –8.687, –0.011) and
(95% CI: –2.635, 2.422). As
, it was concluded that the cancer site would be a predictive factor, i.e., if the cancer site is not the pancreatic head, surgery is expected to be more effective with radiation than without it.
Next, we applied the approach proposed in this article.
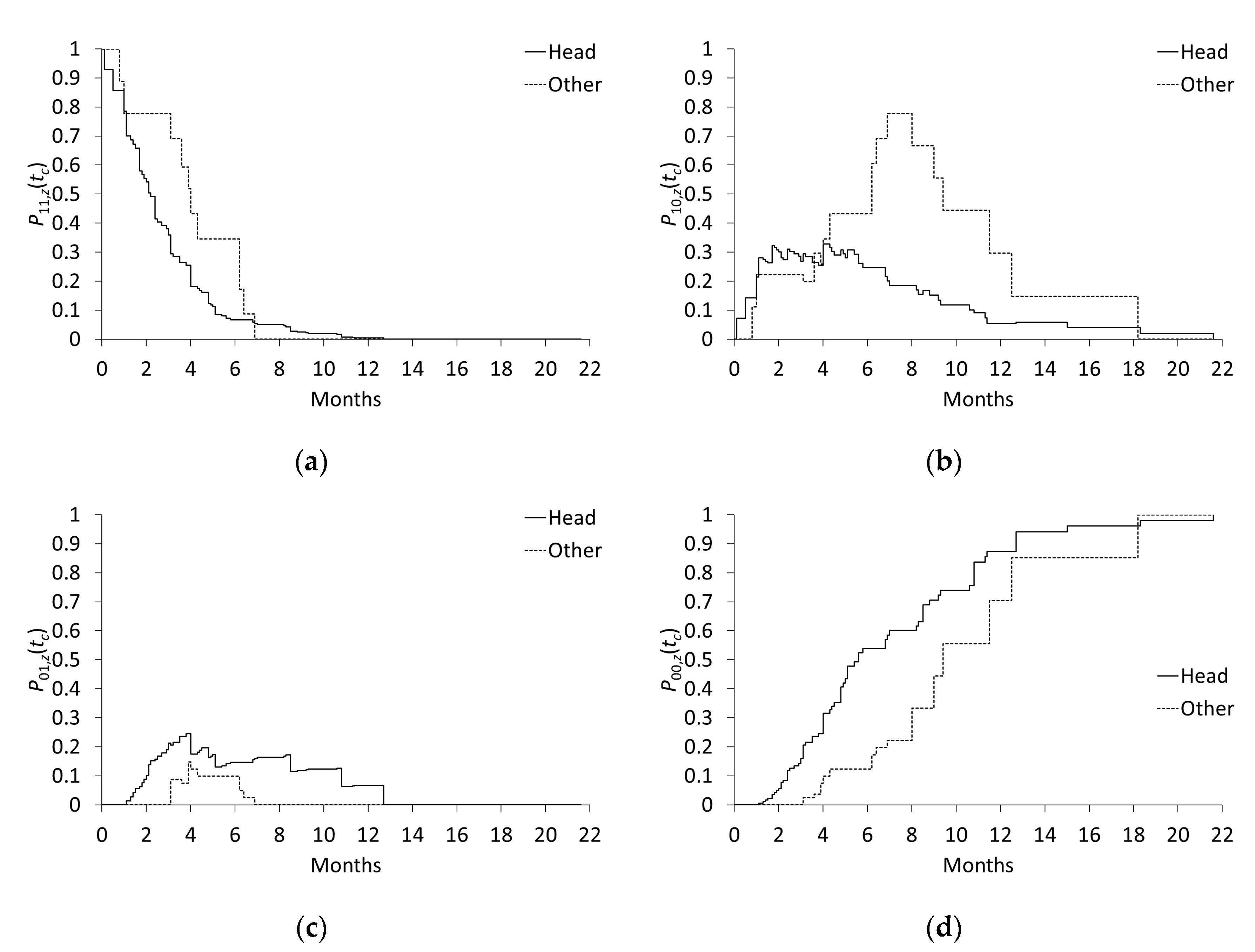
Figure 2 shows
in each subgroup when the cut-off point
was changed from 0 to 21.6 (months). The proportions of activated and inert subjects decreased and increased monotonically over time, respectively, as shown in
Figure 2a,d; this is to be expected given Proposition 2.
Figure 2b shows that the proportion of causative subjects is lower in the pancreatic head subgroup than in the other subgroup.
Figure 2c shows that the proportion of preventive subjects was small, especially in the other subgroup.
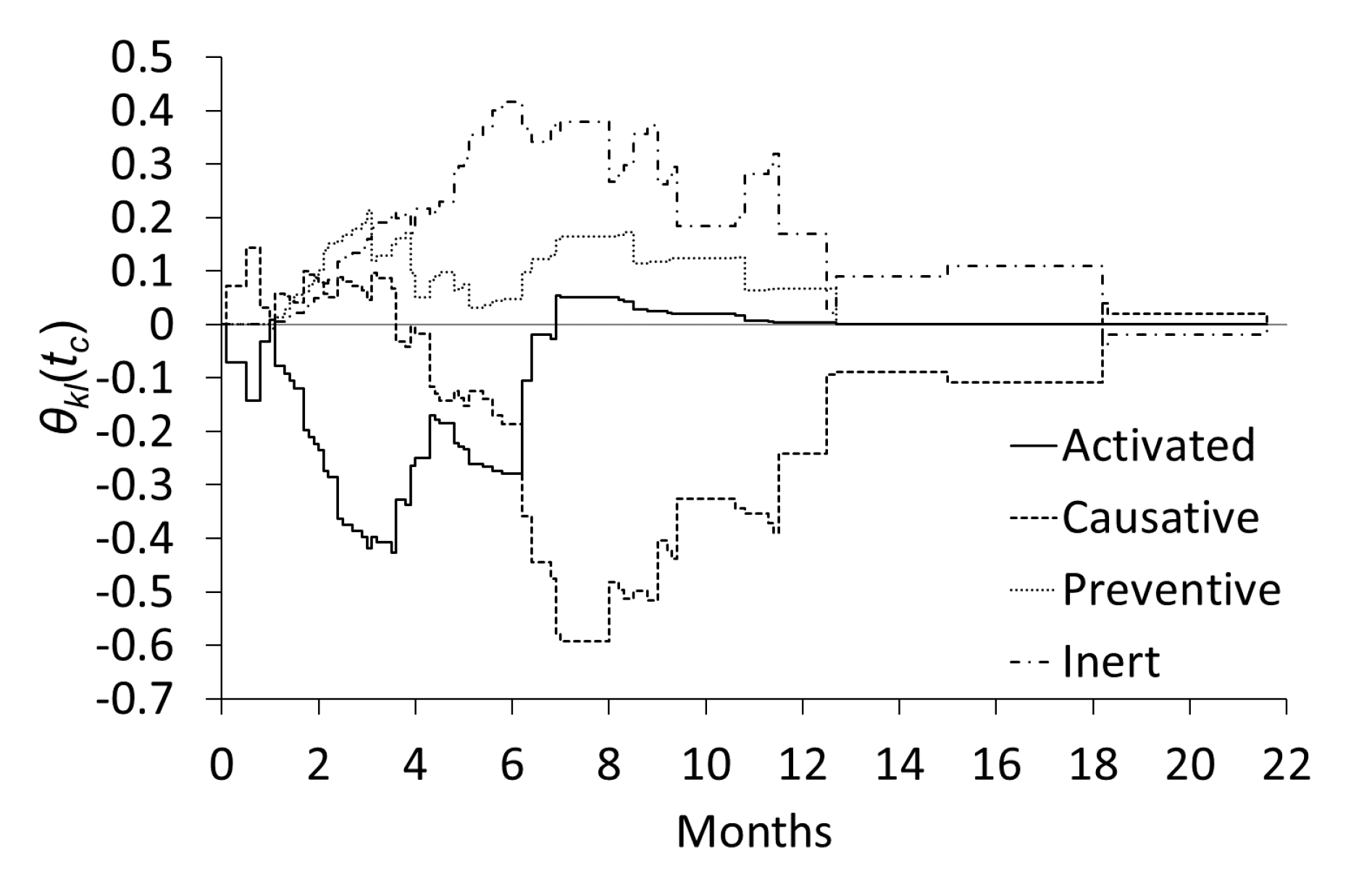
Figure 3 shows the differences in the estimated proportions between the two subgroups; i.e.,
in (7). In
Figure 3, we can clearly see that the cancer site is “depleted-activated” until approximately six months. Then, over the period from 6 to 12 months, the cancer site is “depleted-causative.”
The estimates of
in Definition 2 and
in Proposition 1 are summarized in
Table 2. In the table,
implies that the mean proportion of causative subjects in the pancreatic head subgroup on the interval [0, 21.6] (12.9%) was 14.5% lower than that in the other subgroup (27.4%). This indicates that the cancer site is “depleted-causative”. However, for some subjects, the cancer site might be “activated-preventive” because
, although the absolute value is smaller than that of
(−0.145). The cancer site might also be considered as “depleted-activated” because
. In the context of prediction and prognosis, as
, it is concluded that the cancer site would be a predictive factor of the effectiveness of radiation, and possibly also of the harm caused by radiation, albeit to a lesser extent.
The results generated using our approach were similar to those obtained via the current standard analysis; however, the magnitude was different. The difference is attributed to , where our approach could not rule out, based on the data, a harmful effect of radiation in some subjects, especially in the pancreatic head subgroup. The value of estimated by the current standard analysis was −4.439, while it is converted to −0.201 (); this is 0.057 less than the value of (−0.145) derived by our approach, as seen in Corollary 1. Similarly, is converted to −0.005 (); this is 0.057 larger than the value of (−0.062). As a result, is closer to zero than .
5. Conclusion
In this article, we extended the concept of the covariate effect type proposed by Chiba [
3] from the case with a binary outcome to cases with time-to-event and continuous outcomes. This was achieved by using all cut-off points on the interval
, where the respective values of
and
are zero and the truncation time in a case with a time-to-event outcome and the minimum and maximum observed values in a case with a continuous outcome. A proportion of the
subjects for each cut-off point is
in (6), and the mean of
is the RMP,
, in Definition 2. As discussed in
Section 2 and
Section 3, the RMP is related to the arithmetic mean, which corresponds to the RMST for a case with a time-to-event outcome.
In some studies, a covariate of interest may be a continuous variable, rather than a binary variable discussed in this article. Unfortunately, our approach cannot be applied for a continuous covariate. However, a continuous covariate can be partitioned into two subgroups by finding the optimal threshold value to split it using a popular method such as receiver operating characteristic (ROC) curve analysis [
19]. Recently, partitioning methods based on a combination of multivariate covariates have also been discussed [
20]. These methods will facilitate the use of our approach.
Our measures of covariate effect types can easily be calculated by merging two data sets for the experimental and control arms including the rows of times and survival probabilities, which are automatically generated using commercial software such as SAS (SAS Institute, Cary, NC, USA) and R (R Foundation for Statistical Computing, Vienna, Austria). For example, to derive
, we can use a procedure to generate a Kaplan–Meier plot. Then, we obtain respective data sets including
and
.
is derived by merging these two data sets. The RMP estimate,
, is calculated by summing the areas of rectangles, which are calculated by applying a lag function. This process to estimate
can be applied to a case with a continuous outcome by setting the minimum value of the outcome to zero, i.e., by using
. It is also easy to extend the method to observational studies by using a weighted survival curve [
21] derived based on the propensity score [
22].
A limitation of our approach is the requirement that the assumption of independent potential outcomes (Assumption 2) is used when estimating the measures of covariate effect types. Unfortunately, we cannot verify whether this assumption holds in actual studies based on the observed data. Additional work is necessary to develop a simple method to estimate our measures of covariate effect types without using the assumption of independent potential outcomes.
Current standard analysis is suitable for assessing prediction and prognosis of a covariate when , which implies that a covariate is not predictable for the effectiveness of the control treatment (or for the harm caused by the experimental treatment). However, when , whether the current approach is appropriate is somewhat questionable unlike for our approach. Thus, our approach can supplement the current standard analysis, despite the limitation of requiring the assumption of independent potential outcomes.





{kind=link}
{kind=link}
{kind=link}