Combination of Ensembles of Regularized Regression Models with Resampling-Based Lasso Feature Selection in High Dimensional Data


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Setup
2.1.1. Simulation Data Setup
2.1.2. Experimental Data Setup
2.1.3. Data Notations
2.2. Rank Based Feature Selection Methods
2.2.1. Information Gain
2.2.2. Chi-Square Test
2.2.3. Minimum Redundancy Maximum Relevance
2.3. Classification Algorithms
2.3.1. Logistic Regression
2.3.2. Regularized Regression Models
2.3.3. Random Forests
2.3.4. Support Vector Machines
2.3.5. Adaboost
2.4. The Proposed Framework
2.4.1. The Resampling-Based Lasso Feature Selection
2.4.2. The Ensembles of Regularized Regression Models
| Algorithm 1 Proposed ERRM |
|
2.5. Evaluation Metrics
3. Results
3.1. Simulation Results
3.1.1. Simulation Scenario (S1): Low Correlation 0.2
3.1.2. Simulation Scenario (S2): Intermediate Correlation 0.5
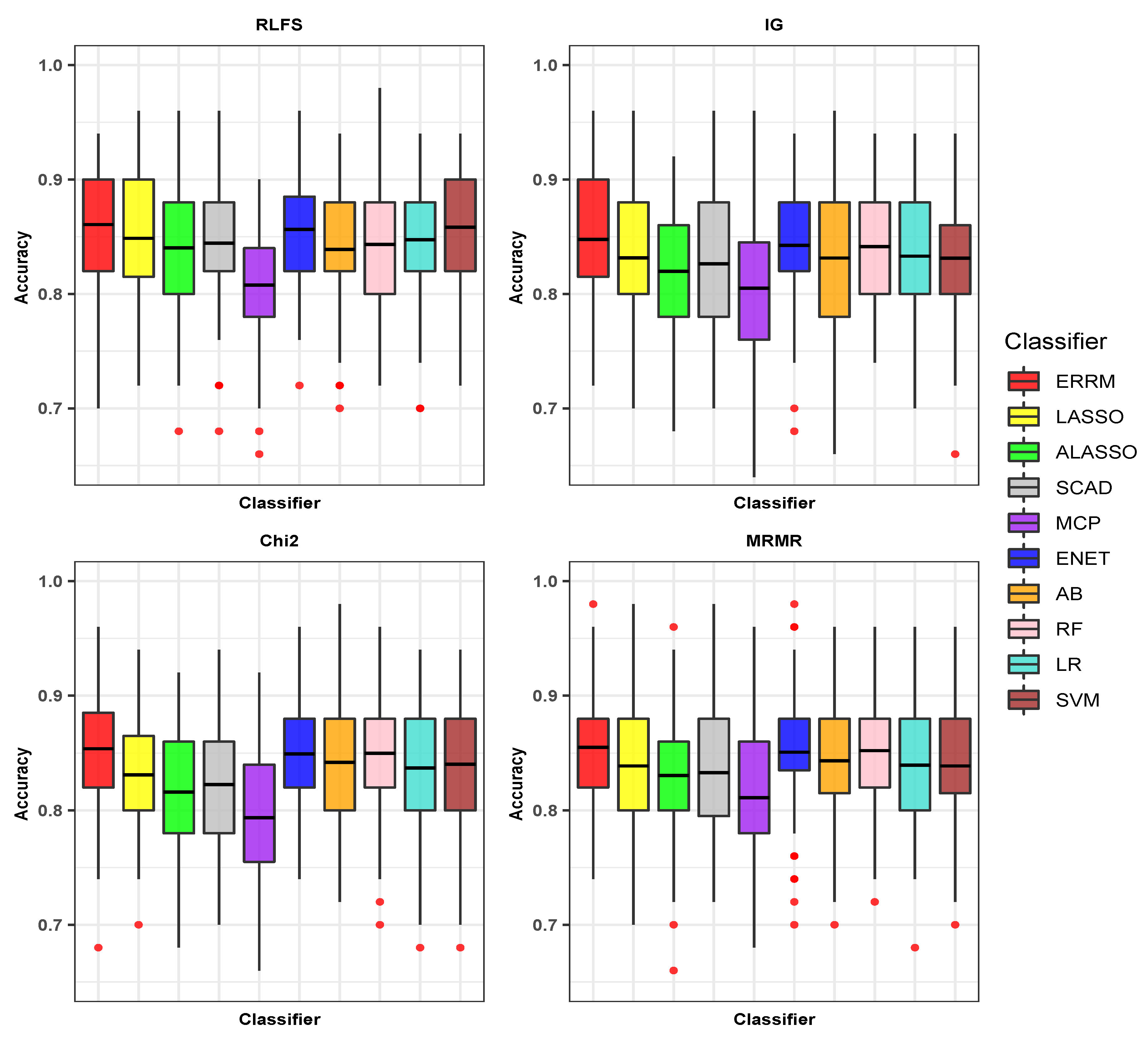
3.2. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FS | feature Selection |
| RLFS | resampling-based lasso feature selection |
| ERRM | ensemble regularized regression models |
| IG | information gain |
| Chi2 | chi-square |
| MRMR | minimum redundancy maximum relevance |
| ALASSO | adaptive lasso |
| AB | adaptive boosting |
| RF | random forests |
| LR | logistic regression |
| SVM | support vector machines |
| SD | standard deviation |
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed RLFS | IG | Chi2 | MRMR | |||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) |
| Proposed ERRM | 0.9586 (0.025) | 0.9596 (0.039) | 0.9556 (0.027) | 0.9565 (0.041) | 0.9530 (0.034) | 0.9544 (0.045) | 0.9560 (0.024) | 0.9558 (0.037) |
| LASSO | 0.9482 (0.033) | 0.9493 (0.050) | 0.9442 (0.030) | 0.9194 (0.045) | 0.9428 (0.037) | 0.9447 (0.051) | 0.9444 (0.032) | 0.9442 (0.042) |
| ALASSO | 0.9420 (0.031) | 0.9425 (0.051) | 0.9376 (0.030) | 0.9379 (0.045) | 0.9328 (0.041) | 0.942 (0.056) | 0.9388 (0.033) | 0.9389 (0.047) |
| ENET | 0.9576 (0.025) | 0.9587 (0.039) | 0.9538 (0.029) | 0.9546 (0.042) | 0.9532 (0.034) | 0.9546 (0.045) | 0.9566 (0.024) | 0.9562 (0.036) |
| SCAD | 0.9464 (0.031) | 0.9475 (0.049) | 0.9422 (0.030) | 0.9428 (0.045) | 0.9386 (0.043) | 0.9401 (0.055) | 0.9414 (0.031) | 0.9408 (0.043) |
| MCP | 0.9256 (0.040) | 0.9270 (0.062) | 0.9262 (0.038) | 0.9269 (0.055) | 0.9210 (0.041) | 0.9221 (0.058) | 0.9224 (0.034) | 0.9223 (0.048) |
| AB | 0.9454 (0.032) | 0.9469 (0.047) | 0.9494 (0.030) | 0.9501 (0.044) | 0.9470 (0.034) | 0.9482 (0.046) | 0.9480 (0.029) | 0.9481 (0.040) |
| RF | 0.9540 (0.030) | 0.9557 (0.043) | 0.9560 (0.029) | 0.9565 (0.043) | 0.9542 (0.032) | 0.9556 (0.044) | 0.9508 (0.027) | 0.9510 (0.039) |
| LR | 0.9478 (0.029) | 0.9482 (0.045) | 0.9462 (0.030) | 0.9469 (0.044) | 0.9418 (0.038) | 0.9432 (0.050) | 0.9438 (0.028) | 0.9437 (0.041) |
| SVM | 0.9560 (0.027) | 0.9568 (0.041) | 0.9522 (0.030) | 0.9527 (0.043) | 0.9520 (0.031) | 0.9526 (0.042) | 0.9594 (0.026) | 0.9587 (0.037) |
References
- Tariq, H.; Eldridge, E.; Welch, I. An efficient approach for feature construction of high-dimensional microarray data by random projections. PLoS ONE 2018, 13, e0196385. [Google Scholar] [CrossRef] [PubMed]
- Bhola, A.; Singh, S. Gene Selection Using High Dimensional Gene Expression Data: An Appraisal. Curr. Bioinform. 2018, 13, 225–233. [Google Scholar] [CrossRef]
- Dai, J.J.; Lieu, L.H.; Rocke, D.M. Dimension reduction for classification with gene expression microarray data. Stat. Appl. Genet. Mol. Biol. 2006, 5, 6. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Kerns, R.T.; Peddada, S.D.; Bushel, P.R. Principal component analysis-based filtering improves detection for Affymetrix gene expression arrays. Nucleic Acids Res. 2011, 39, e86. [Google Scholar] [CrossRef]
- Bourgon, R.; Gentleman, R.; Huber, W. Reply to Talloen et al.: Independent filtering is a generic approach that needs domain specific adaptation. Proc. Natl. Acad. Sci. USA 2010, 107, E175. [Google Scholar] [CrossRef]
- Bourgon, R.; Gentleman, R.; Huber, W. Independent filtering increases detection power for high-throughput experiments. Proc. Natl. Acad. Sci. USA 2010, 107, 9546–9551. [Google Scholar] [CrossRef]
- Ramsköld, D.; Wang, E.T.; Burge, C.B.; Sandberg, R. An Abundance of Ubiquitously Expressed Genes Revealed by Tissue Transcriptome Sequence Data. PLoS Comput. Biol. 2009, 5, e1000598. [Google Scholar] [CrossRef]
- Li, L.; Kabesch, M.; Bouzigon, E.; Demenais, F.; Farrall, M.; Moffatt, M.; Lin, X.; Liang, L. Using eQTL weights to improve power for genome-wide association studies: A genetic study of childhood asthma. Front. Genet. 2013, 4, 103. [Google Scholar] [CrossRef]
- Calle, M.L.; Urrea, V.; Vellalta, G.; Malats, N.; Steen, K.V. Improving strategies for detecting genetic patterns of disease susceptibility in association studies. Stat. Med. 2008, 27, 6532–6546. [Google Scholar] [CrossRef]
- Bock, C. Analysing and interpreting DNA methylation data. Nat. Rev. Genet. 2012, 13, 705–719. [Google Scholar] [CrossRef]
- Sun, H.; Wang, S. Penalized logistic regression for high-dimensional DNA methylation data with case-control studies. Bioinformatics 2012, 28, 1368–1375. [Google Scholar] [CrossRef]
- Kim, S.; Halabi, S. High Dimensional Variable Selection with Error Control. BioMed Res. Int. 2016, 2016, 8209453. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Kim, J.M. Two-Stage Classification with SIS Using a New Filter Ranking Method in High Throughput Data. Mathematics 2019, 7, 493. [Google Scholar] [CrossRef]
- Fan, J.; Lv, J. Sure independence screening for ultrahigh dimensional feature space. J. R. Stat. Soc. Ser. B 2008, 70, 849–911. [Google Scholar] [CrossRef] [PubMed]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Okeh, U.; Oyeka, I. Estimating the Fisher’s Scoring Matrix Formula from Logistic Model. Am. J. Theor. Appl. Stat. 2013, 2013, 221–227. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Ditzler, G.; Morrison, J.C.; Lan, Y.; Rosen, G.L. Fizzy: Feature subset selection for metagenomics. BMC Bioinform. 2015, 16, 358. [Google Scholar] [CrossRef]
- Su, C.T.; Yang, C.H. Feature selection for the SVM: An application to hypertension diagnosis. Expert Syst. Appl. 2008, 34, 754–763. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. 2010. [Google Scholar]
- Urbanowicz, R.J.; Meeker, M.; Cava, W.L.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 2017, 85, 189–203. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Freund, Y. An Adaptive Version of the Boost by Majority Algorithm. Mach. Learn. 2001, 43, 293–318. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Statnikov, A.R.; Wang, L.; Aliferis, C.F. A comprehensive comparison of random forests and support vector machines for microarray-based cancer classification. BMC Bioinform. 2008, 9, 319. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Marquardt, D.W.; Snee, R.D. Ridge Regression in Practice. Am. Stat. 1975, 29, 3–20. [Google Scholar]
- Yang, X.G.; Lu, Y. Informative Gene Selection for Microarray Classification via Adaptive Elastic Net with Conditional Mutual Information. arXiv 2018, arXiv:1806.01466. [Google Scholar]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference And Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In International Workshop on Multiple Classifier Systems; Springer: London, UK, 2000; pp. 1–15. [Google Scholar]
- Maclin, R.; Opitz, D.W. Popular Ensemble Methods: An Empirical Study. arXiv 2011, arXiv:1106.0257. [Google Scholar]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Datta, S.; Pihur, V.; Datta, S. An adaptive optimal ensemble classifier via bagging and rank aggregation with applications to high dimensional data. BMC Bioinform. 2010, 11, 427. [Google Scholar] [CrossRef] [PubMed]
- Ahn, H.; Moon, H.; Fazzari, M.J.; Lim, N.; Chen, J.J.; Kodell, R.L. Classification by ensembles from random partitions of high-dimensional data. Comput. Stat. Data Anal. 2007, 51, 6166–6179. [Google Scholar] [CrossRef]
- Lim, N.; Ahn, H.; Moon, H.; Chen, J.J. Classification of high-dimensional data with ensemble of logistic regression models. J. Biopharm. Stat. 2009, 20, 160–171. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2008; ISBN 3-900051-07-0. [Google Scholar]
- Kursa, M.B. Praznik: Collection of Information-Based Feature Selection Filters; R Package Version 5.0.0; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Novoselova, N.; Wang, J.; F.P.F.K. Biocomb: Feature Selection and Classification with the Embedded Validation Procedures for Biomedical Data Analysis, R package version 0.4; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef]
- Breheny, P.; Huang, J. Coordinate descent algorithms for nonconvex penalized regression, with applications to biological feature selection. Ann. Appl. Stat. 2011, 5, 232–253. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien; R Package Version 1.7-1; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Pihur, V.; Datta, S.; Datta, S. RankAggreg: Weighted Rank Aggregation, R package version 0.6.5; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- The RLFS-ERRM Resources 2019. Available online: https://sites.google.com/site/abhijeetrpatil01/file-cabinet/blfs-errm-manuscript-files-2019 (accessed on 25 December 2019).
- Feature Selection Datasets. Available online: http://featureselection.asu.edu/old/datasets.php (accessed on 25 December 2019).
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A.; Benítez, J.M.; Herrera, F. A review of microarray datasets and applied feature selection methods. Inf. Sci. 2014, 282, 111–135. [Google Scholar] [CrossRef]
- Wang, M.; Barbu, A. Are screening methods useful in feature selection? An empirical study. PLoS ONE 2018, 14, e0220842. [Google Scholar] [CrossRef]
- Tsai, C.; Chen, J.J. Multivariate analysis of variance test for gene set analysis. Bioinformatics 2009, 25, 897–903. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2017, 50, 94:1–94:45. [Google Scholar] [CrossRef]
- Chen, X.D.; Ishwaran, H. Random forests for genomic data analysis. Genomics 2012, 99, 323–329. [Google Scholar] [CrossRef] [PubMed]
- Bielza, C.; Robles, V.; Larrañaga, P. Regularized logistic regression without a penalty term: An application to cancer classification with microarray data. Expert Syst. Appl. 2011, 38, 5110–5118. [Google Scholar] [CrossRef]
- Liao, J.G.; Chin, K.V. Logistic regression for disease classification using microarray data: model selection in a large p and small n case. Bioinformatics 2007, 23, 1945–1951. [Google Scholar] [CrossRef] [PubMed]
- Zou, H.; Hastie, T. Regularization and Variable Selection via the Elastic Net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Zhao, S. Gender Classification with Support Vector Machines Based on Non-tensor Pre-wavelets. In Proceedings of the 2010 Second International Conference on Computer Research and Development, Kuala Lumpur, Malaysia, 7–10 May 2010; pp. 770–774. [Google Scholar]





| Proposed RLFS | IG | Chi2 | MRMR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Correlation | Classifier | Acc (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) |
| 0.2 | Proposed ERRM | 0.8606 (0.049) | 0.8626 (0.073) | 0.8476 (0.052) | 0.8483 (0.079) | 0.8538 (0.053) | 0.8551 (0.071) | 0.8550 (0.049) | 0.8552 (0.075) |
| LASSO | 0.8486 (0.052) | 0.8504 (0.075) | 0.8316 (.054) | 0.8335 (0.083) | 0.8310 (0.052) | 0.8323 (0.071) | 0.8388 (0.051) | 0.8393 (0.077) | |
| ALASSO | 0.8402 (0.054) | 0.8416 (0.077) | 0.8198 (0.051) | 0.8217 (0.079) | 0.8160 (0.053) | 0.8171 (0.075) | 0.8304 (0.051) | 0.8313 (0.079) | |
| ENET | 0.8564 (0.048) | 0.8584 (0.072) | 0.8424 (0.054) | 0.8441 (0.081) | 0.8494 (0.046) | 0.8509 (0.067) | 0.8508 (0.052) | 0.8508 (0.077) | |
| SCAD | 0.8440 (0.054) | 0.8457 (0.080) | 0.8264 (0.057) | 0.8283 (0.086) | 0.8226 (0.061) | 0.8239 (0.077) | 0.8330 (0.056) | 0.8336 (0.081) | |
| MCP | 0.8078 (0.049) | 0.8095 (0.081) | 0.8050 (0.062) | 0.8074 (0.088) | 0.7936 (0.060) | 0.7952 (0.085) | 0.8110 (0.060) | 0.8126 (0.082) | |
| AB | 0.8390 (0.051) | 0.8224 (0.077) | 0.8314 (0.060) | 0.8328 (0.080) | 0.8422 (0.054) | 0.8435 (0.075) | 0.8432 (0.054) | 0.8437 (0.075) | |
| RF | 0.8432 (0.057) | 0.8467 (0.084) | 0.8414 (0.052) | 0.8435 (0.078) | 0.8498 (0.053) | 0.8520 (0.075) | 0.8522 (0.051) | 0.8534 (0.077) | |
| LR | 0.8474 (0.050) | 0.8489 (0.076) | 0.8330 (0.053) | 0.8346 (0.080) | 0.8370 (0.054) | 0.8380 (0.073) | 0.8394 (0.051) | 0.8394 (0.080) | |
| SVM | 0.8582 (0.049) | 0.8595 (0.070) | 0.8312 (0.052) | 0.8320 (0.083) | 0.8404 (0.054) | 0.8416 (0.074) | 0.8388 (0.049) | 0.8378 (0.084) | |
| 0.5 | Proposed ERRM | 0.9256 (0.037) | 0.9266 (0.053) | 0.9184 (0.039) | 0.9195 (0.059) | 0.9160 (0.038) | 0.9165 (0.056) | 0.9174 (0.042) | 0.9176 (0.056) |
| LASSO | 0.9146 (0.037) | 0.9155 (0.053) | 0.9034 (0.045) | 0.9046 (0.061) | 0.9020 (0.043) | 0.9029 (0.063) | 0.9066 (0.045) | 0.9065 (0.062) | |
| ALASSO | 0.9056 (0.039) | 0.9062 (0.056) | 0.8956 (0.044) | 0.8966 (0.065) | 0.8948 (0.046) | 0.8954 (0.065) | 0.8984 (0.046) | 0.8982 (0.062) | |
| ENET | 0.9244 (0.038) | 0.9253 (0.052) | 0.9150 (0.044) | 0.9163 (0.061) | 0.9122 (0.039) | 0.9130 (0.060) | 0.9158 (0.043) | 0.9155 (0.058) | |
| SCAD | 0.9102 (0.041) | 0.9110 (0.060) | 0.8974 (0.046) | 0.8986 (0.063) | 0.8964 (0.045) | 0.8972 (0.065) | 0.9090 (0.045) | 0.9090 (0.059) | |
| MCP | 0.8850 (0.047) | 0.8855 (0.066) | 0.8798 (0.050) | 0.8813 (0.068) | 0.8772 (0.045) | 0.8782 (0.065) | 0.8738 (0.049) | 0.8738 (0.070) | |
| AB | 0.9158 (0.035) | 0.9166 (0.050) | 0.9014 (0.046) | 0.9027 (0.065) | 0.9102 (0.040) | 0.9112 (0.060) | 0.9072 (0.047) | 0.9075 (0.062) | |
| RF | 0.9148 (0.039) | 0.9166 (0.055) | 0.9186 (0.041) | 0.9199 (0.059) | 0.9154 (0.042) | 0.9167 (0.060) | 0.9116 (0.043) | 0.9127 (0.060) | |
| LR | 0.9124 (0.037) | 0.9127 (0.054) | 0.9054 (0.043) | 0.9063 (0.061) | 0.9018 (0.045) | 0.9024 (0.063) | 0.9092 (0.043) | 0.9084 (0.060) | |
| SVM | 0.9256 (0.038) | 0.9261 (0.054) | 0.9128 (0.038) | 0.9135 (0.056) | 0.9080 (0.043) | 0.9099 (0.061) | 0.9126 (0.045) | 0.9120 (0.062) | |
| Proposed RLFS | IG | Chi2 | MRMR | |||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) | Accuracy (SD) | Gmean (SD) |
| Proposed ERRM | 0.7161 (0.053) | 0.7127 (0.082) | 0.6789 (0.056) | 0.6791 (0.091) | 0.6807 (0.056) | 0.6808 (0.091) | 0.7035 (0.056) | 0.7024 (0.087) |
| LASSO | 0.7073 (0.064) | 0.7058 (0.087) | 0.6726 (.060) | 0.6725 (0.095) | 0.6680 (0.057) | 0.6680 (0.090) | 06859 (0.061) | 0.6871 (0.097) |
| ALASSO | 0.6878 (0.065) | 0.6869 (0.091) | 0.6715 (0.060) | 0.6714 (0.094) | 0.6696 (0.064) | 0.6698 (0.092) | 0.6800 (0.059) | 0.6803 (0.092) |
| ENET | 0.7138 (0.061) | 0.7116 (0.085) | 0.6733 (0.057) | 0.6722 (0.093) | 0.6733 (0.052) | 0.6726 (0.090) | 0.6998 (0.061) | 0.6992 (0.095) |
| SCAD | 0.7114 (0.054) | 0.7098 (0.083) | 0.6735 (0.056) | 0.6732 (0.090) | 0.6670 (0.058) | 0.6669 (0.091) | 0.6894 (0.059) | 0.6901 (0.091) |
| MCP | 0.6880 (0.010) | 0.6870 (0.082) | 0.6673 (0.057) | 0.6663 (0.089) | 0.6647 (0.059) | 0.6639 (0.092) | 0.6866 (0.057) | 0.6874 (0.089) |
| AB | 0.6991 (0.064) | 0.6958 (0.087) | 0.6673 (0.054) | 0.6634 (0.086) | 0.6605 (0.058) | 0.6583 (0.094) | 0.6929 (0.050) | 0.6897 (0.083) |
| RF | 0.6975 (0.056) | 0.6933 (0.089) | 0.6729 (0.045) | 0.6691 (0.078) | 0.6738 (0.054) | 0.6703 (0.090) | 0.6942 (0.055) | 0.6902 (0.088) |
| LR | 0.7001 (0.065) | 0.6987 (0.089) | 0.6761 (0.058) | 0.6662 (0.097) | 0.6770 (0.059) | 0.6769 (0.094) | 0.7008 (0.058) | 0.7000 (0.086) |
| SVM | 0.7026 (0.058) | 0.7014 (0.086) | 0.6422 (0.059) | 0.6430 (0.099) | 0.6459 (0.066) | 0.6477 (0.105) | 0.6668 (0.058) | 0.6658 (0.092) |
| Bootstrapping | Accuracy (SD) | Gmean (SD) | |
|---|---|---|---|
| ERRM without feature selection (FS) screening | Yes | 0.7129 (0.053) | 0.7093 (0.091) |
| ERRM without FS screening | No | 0.6947 (0.057) | 0.6944 (0.089) |
| FS Screening | Accuracy (SD) | Gmean (SD) | |
|---|---|---|---|
| LASSO | Yes | 0.7073 (0.064) | 0.7058 (0.087) |
| No | 0.6740 (0.061) | 0.6752 (0.125) | |
| ALASSO | Yes | 0.6878 (0.065) | 0.6869 (0.091) |
| No | 0.6740 (0.061) | 0.6752 (0.125) | |
| ENET | Yes | 0.7138 (0.061) | 0.7116 (0.085) |
| No | 0.6740 (0.061) | 0.6752 (0.125) | |
| SCAD | Yes | 0.7114 (0.054) | 0.7098 (0.083) |
| No | 0.6740 (0.061) | 0.6752 (0.125) | |
| MCP | Yes | 0.6880 (0.010) | 0.6870 (0.082) |
| No | 0.6740 (0.061) | 0.6752 (0.125) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, A.R.; Kim, S. Combination of Ensembles of Regularized Regression Models with Resampling-Based Lasso Feature Selection in High Dimensional Data. Mathematics 2020, 8, 110. https://doi.org/10.3390/math8010110
Patil AR, Kim S. Combination of Ensembles of Regularized Regression Models with Resampling-Based Lasso Feature Selection in High Dimensional Data. Mathematics. 2020; 8(1):110. https://doi.org/10.3390/math8010110
Chicago/Turabian StylePatil, Abhijeet R, and Sangjin Kim. 2020. "Combination of Ensembles of Regularized Regression Models with Resampling-Based Lasso Feature Selection in High Dimensional Data" Mathematics 8, no. 1: 110. https://doi.org/10.3390/math8010110
APA StylePatil, A. R., & Kim, S. (2020). Combination of Ensembles of Regularized Regression Models with Resampling-Based Lasso Feature Selection in High Dimensional Data. Mathematics, 8(1), 110. https://doi.org/10.3390/math8010110