Interval-Valued Probabilistic Hesitant Fuzzy Set Based Muirhead Mean for Multi-Attribute Group Decision-Making

Abstract
:1. Introduction
- Elicitation of occurrence probability in a precise manner is difficult and prone to inaccuracies.
- Following this, aggregation of preference information with better scope to capture the interrelationship between attributes is an open challenge in the IVPHFS context.
- Further, calculation of weights of attributes by making reasonable use of partial information from DMs is also an open challenge.
- Understanding the applicability, strengths and weaknesses of the proposed method are also substantial for effective use of the framework in uncertain situations.
- MM operator is extended in the IVPHFS context for capturing the interrelationship between attributes in a better way. Also, DMs’ preferences are aggregated in a rational manner by considering risk appetite along with the weight of each DM which addresses challenge (2).
- A new mathematical programming model is put forward in the IVPHFS context for calculation of weights of attributes with the help of partial information from the DMs. The idea is to use this partial information effectively for a reasonable calculation of weights.
- The applicability of the proposed method is validated by using a green supplier selection problem.
- Finally, the superiority and weakness of the proposed method are discussed in comparison with other methods.
2. Preliminaries
- Property 1: Commutativity
- Property 2: Associativity
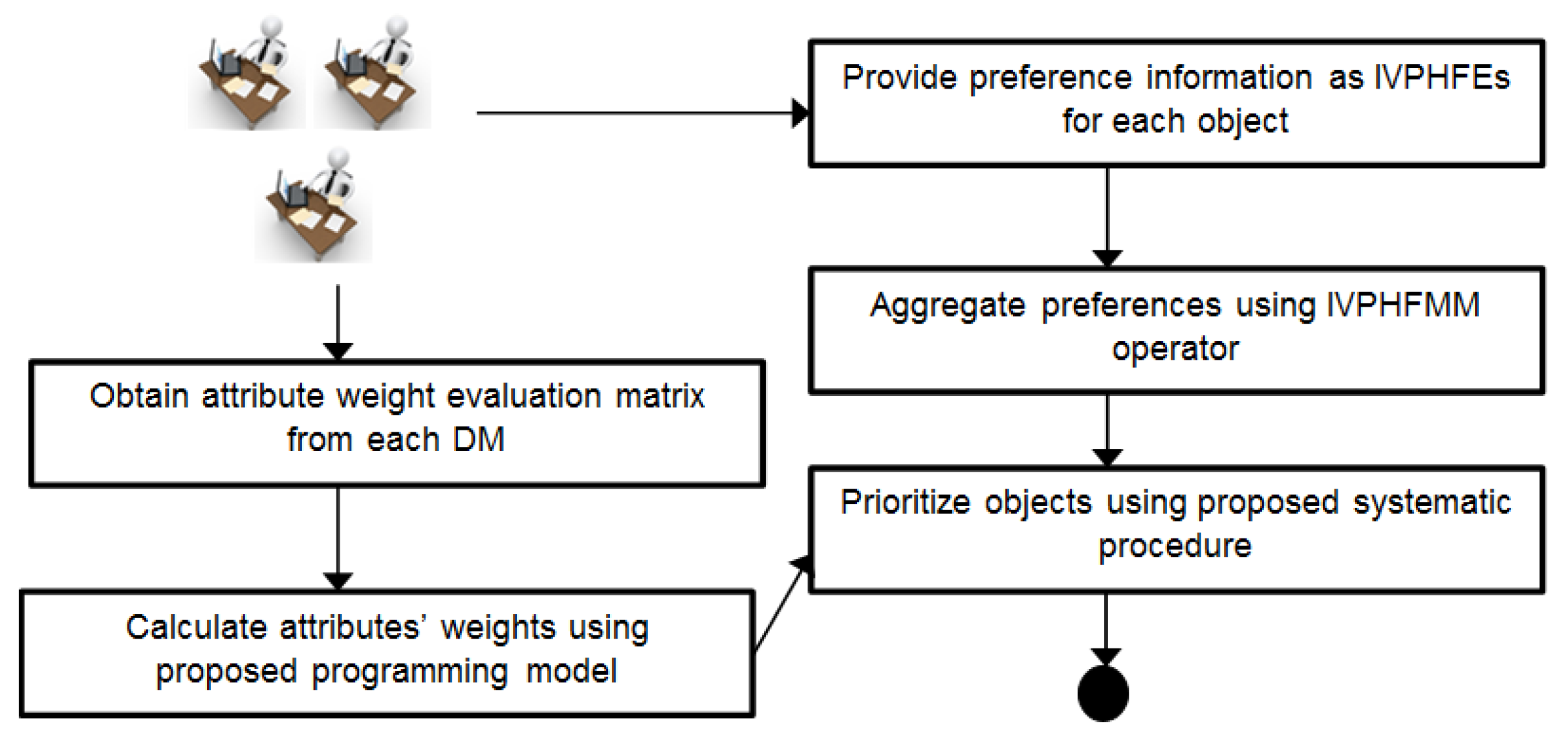
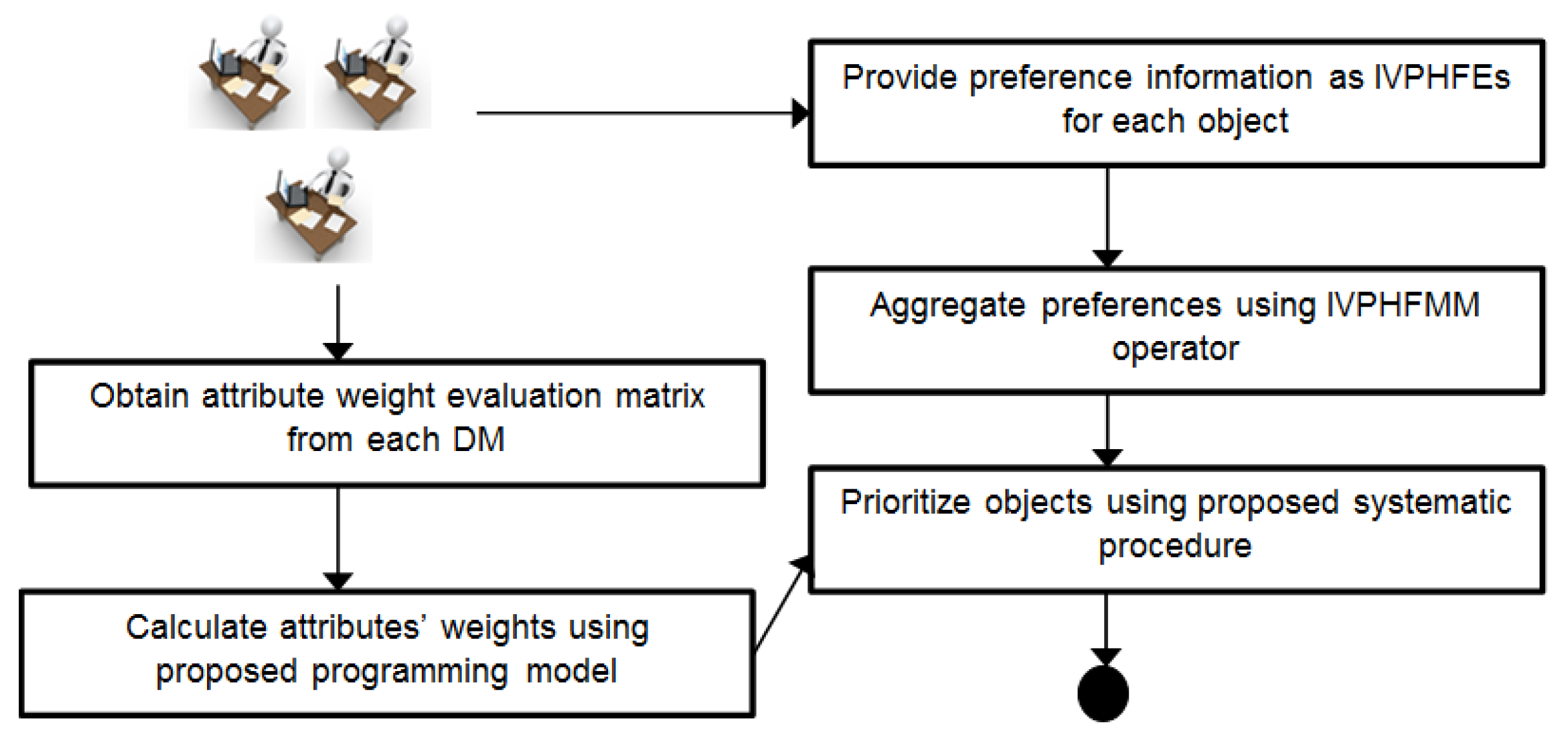
3. Proposed Methodology
3.1. IVPHFS Based MM Operator and Its Properties
3.2. Weight Calculation for Attributes Using the Proposed Programming Model
- Step 1:
- Construct an evaluation matrix of order with IVPHFS information. The order of the matrix is DMs by attributes.
- Step 2:
- Calculate the positive ideal solution (PIS) and negative ideal solution (NIS) for each attribute using Equations 9 and 10.where and are PIS and NIS values of the attribute respectively.The and are calculated for each attribute and they contain IVPHFS information of the corresponding value obtained from Equations 9 and 10.
- Step 3:
- Apply Model 1 to obtain the weights of attributes.Model 1:Subject to:The distance measure is calculated using Equation (11).where and are any two IVPHFEs.
3.3. Proposed MAGDM Method for Prioritization of Objects
- Step 1:
- Begin.
- Step 2:
- Construct decision matrices of order where is the number of objects and is the number of attributes.
- Step 3:
- Aggregate these matrices into a single matrix of order by using newly proposed IVPHFMM operator (see Section 3.1).
- Step 4:
- Multiply the weight of each attribute with the respective IVPHFE and use Equation (4) attribute-wise to calculate the net value for each object. The resultant value is also an IVPHFE.
- Step 5:
- Prioritize the objects by adopting transformation method given in Equation (12).where is the index for the object.Arrange in the descending order of values to obtain ranking order.
- Step 6:
- End.
4. Numerical Example: Renewable Energy Source Selection from the Indian Perspective
- Step 1:
- Construct a panel of three DMs viz., technical personnel , member of the ministry of energy and natural resource and senior financial personnel . Make an initial list of renewable energy sources and attributes. By systematic pre-screening, the panel finalizes four renewable energy sources and four attributes. These are adapted from Reference [35] and the panel decides to use IVPHFS information for rating energy sources against the attribute.
- Step 2:
- Form three matrices of order where the rows represent the energy sources and columns represent the attributes. Four renewable energy sources considered are geothermal , solar , tidal and hydro which are evaluated over four attributes viz., technical aspects , social aspects , financial aspects and environmental aspects IVPHFS information (refer Definition 3) is used for rating energy sources and it is depicted in Table 2.Table 2 presents the preference information by different DMs over renewable energy sources based on a set of attributes. IVPHFS based preference information is adopted.
- Step 3:
- Aggregate the IVPHFEs from Table 2 by using IVPHFMM operator (see Section 3.1 for details). There are three risk appetite values used viz., , and which are given by 2, 2 and 1. The weight of each DM is given by 0.3, 0.4 and 0.3.
- Step 4:
- Calculate the weights of the attributes by using the procedure given in Section 3.2. Table 4 shows an evaluation matrix with IVPHFS information which is used to calculate the PIS and NIS values for each attribute (see Table 4).By using Table 4 and Table 5 the objective function is constructed from Model 1. The constraints are obtained from the DMs and the model is solved using optimization toolbox of MATLAB®. From Model 1, we get the objective function as and the inequality constraints are given by , , and . By solving we get, and .
- Step 5:
- Prioritize the energy sources by using the procedure given in Section 3.3.The cumulative ring sum value for each renewable energy source is given by for unbiased attributes’ weights and for biased attributes’ weights. From Equation (12) we get, , , and for unbiased weight values and , , and for biased weight values. Thus, the ranking order is and the suitable renewable energy source for the process is solar energy .
- Step 6:
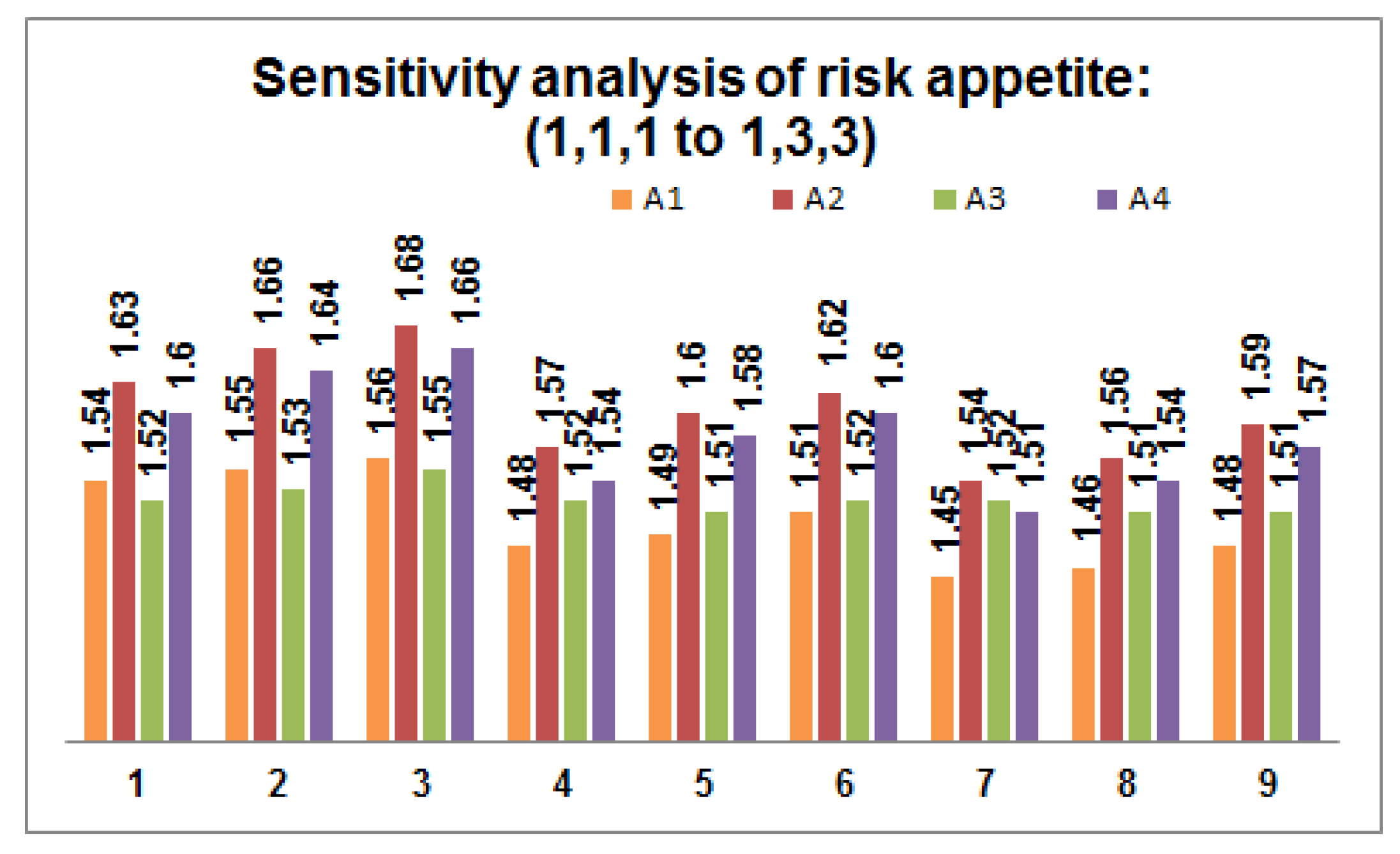
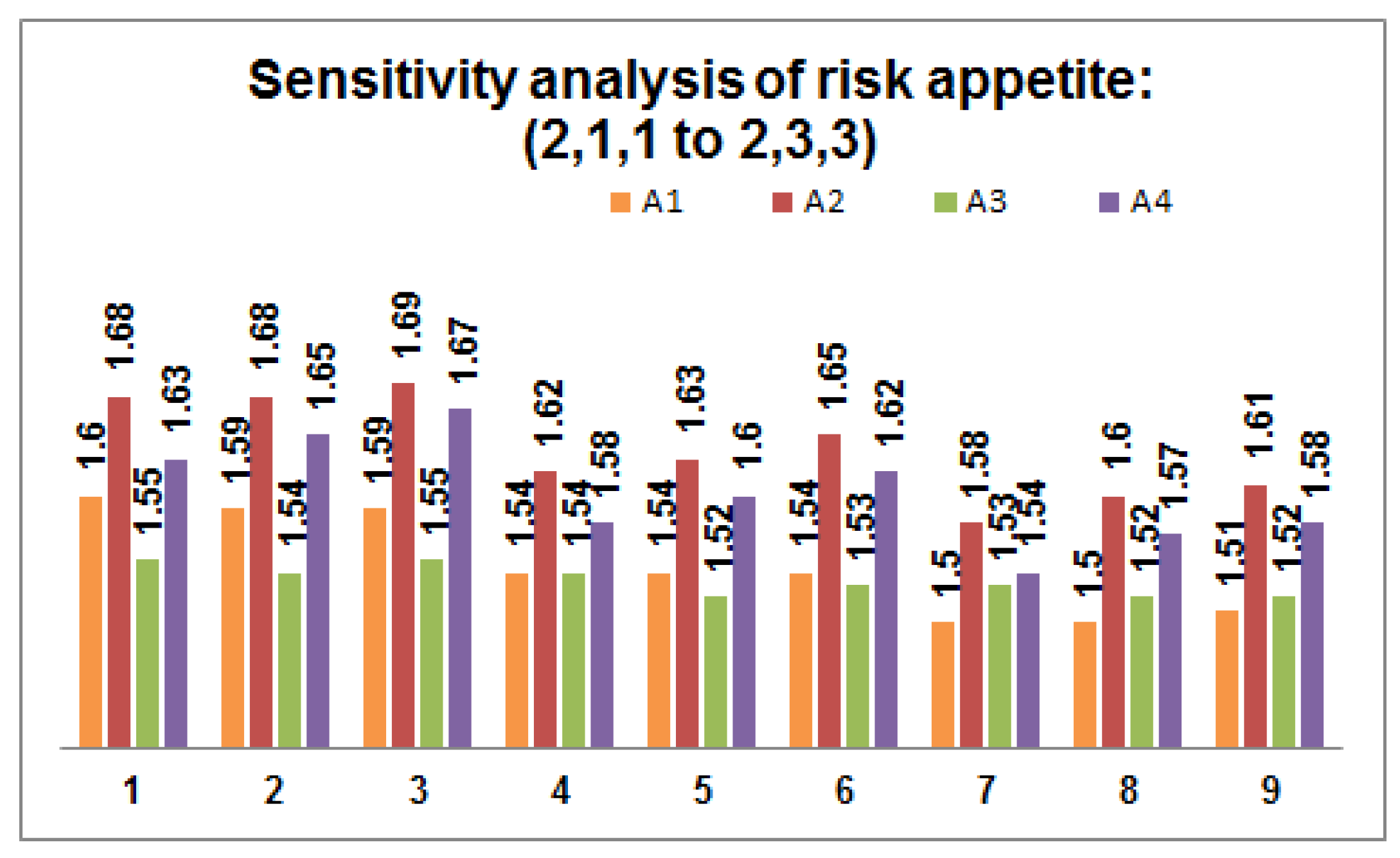
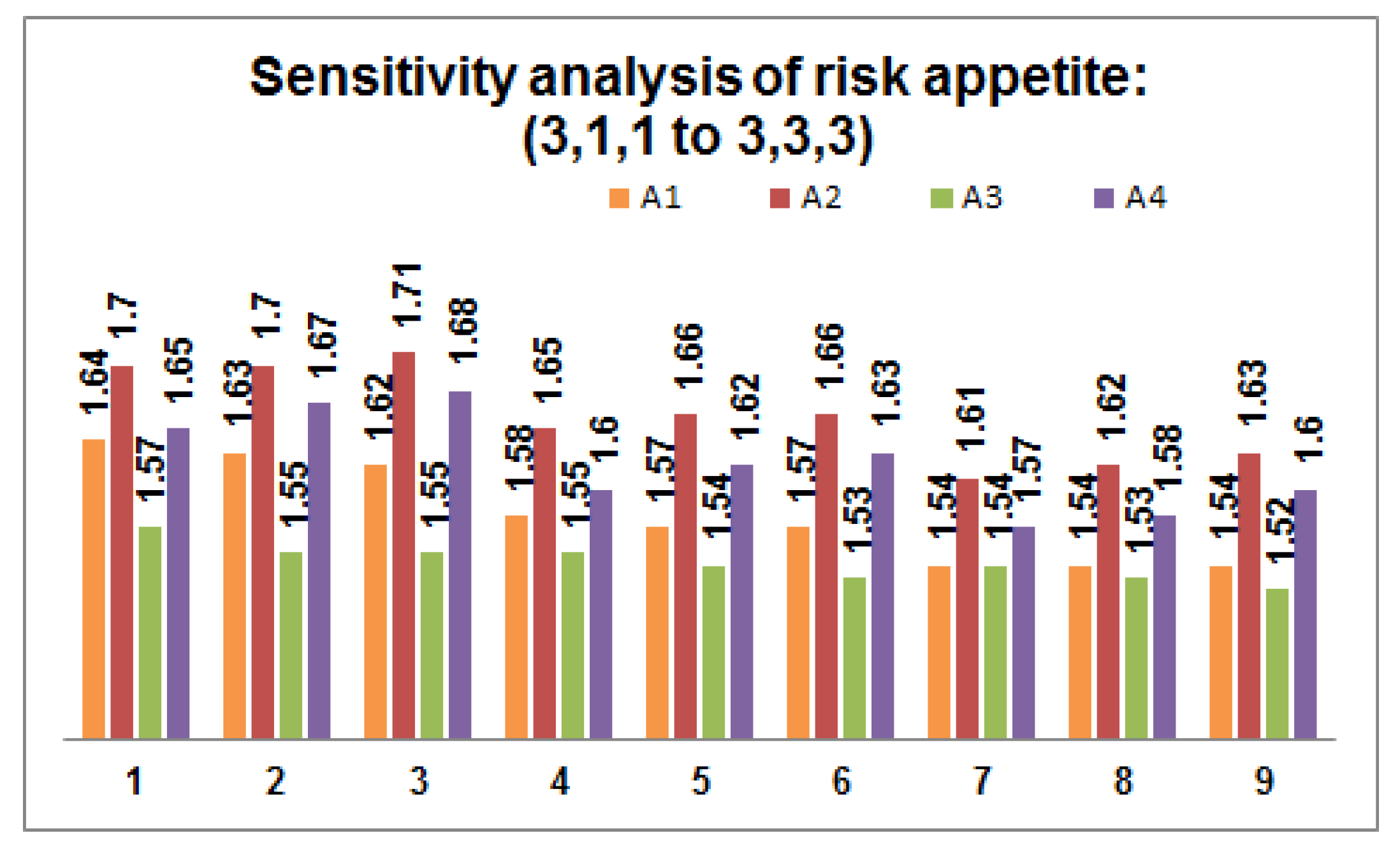
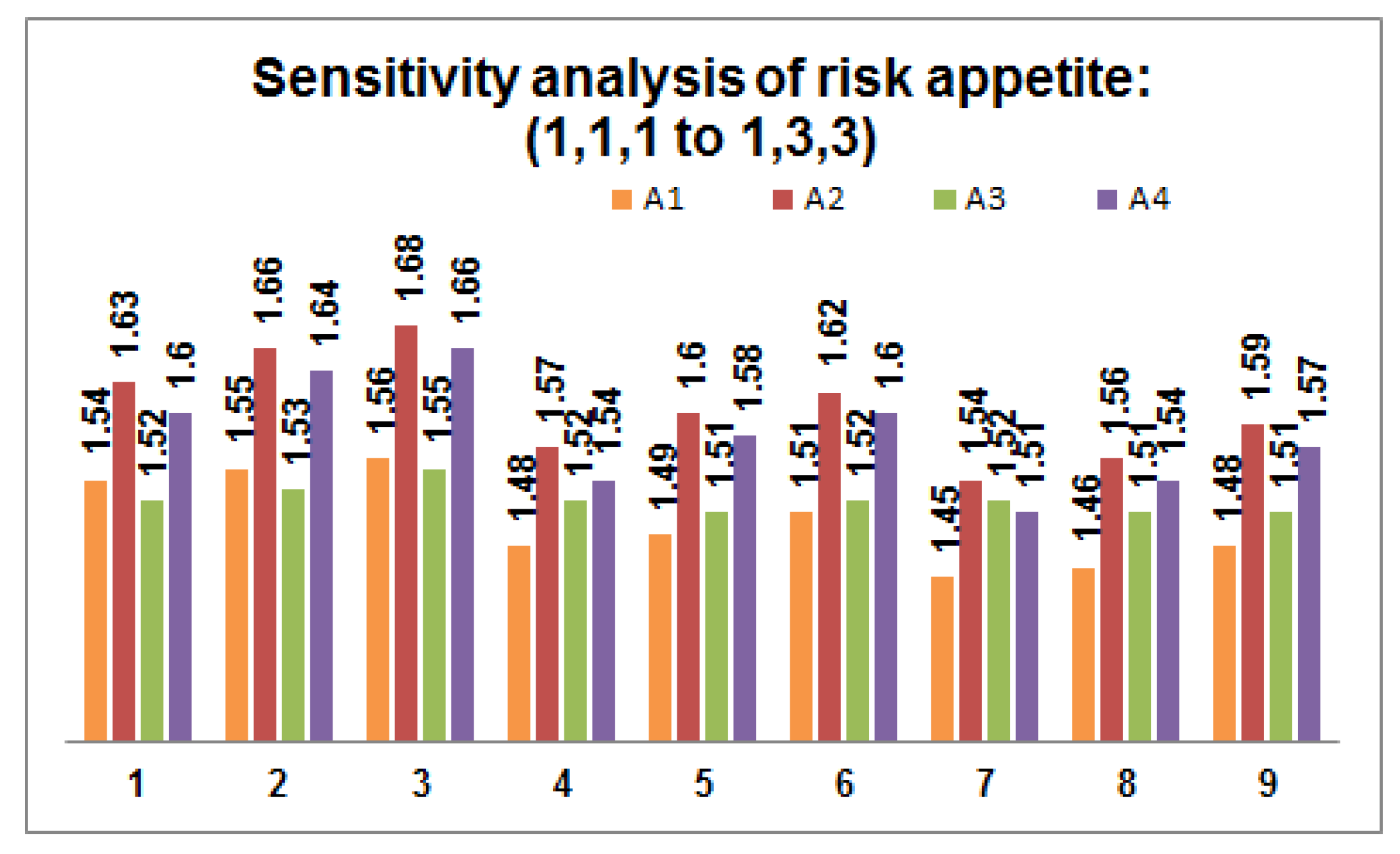
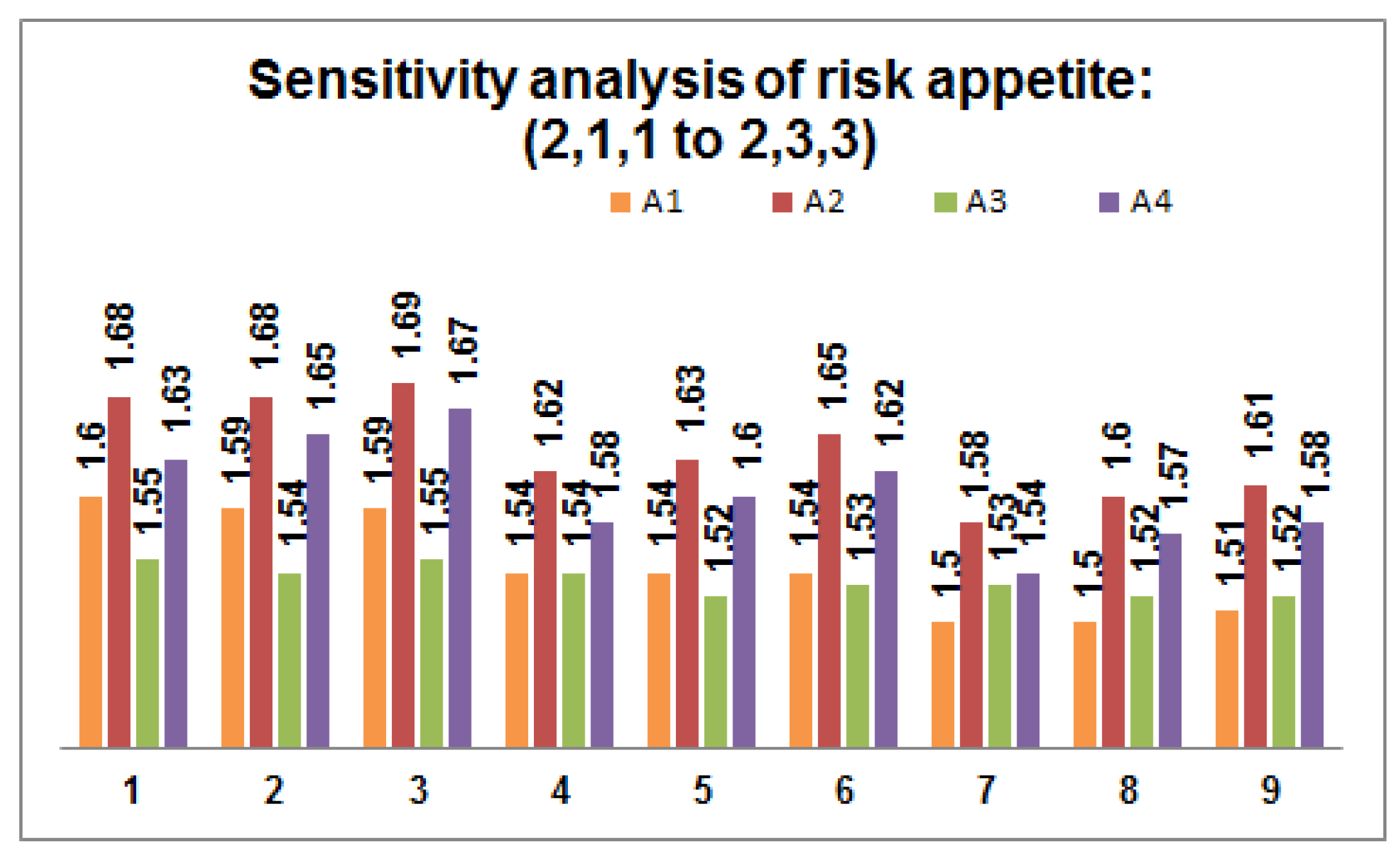
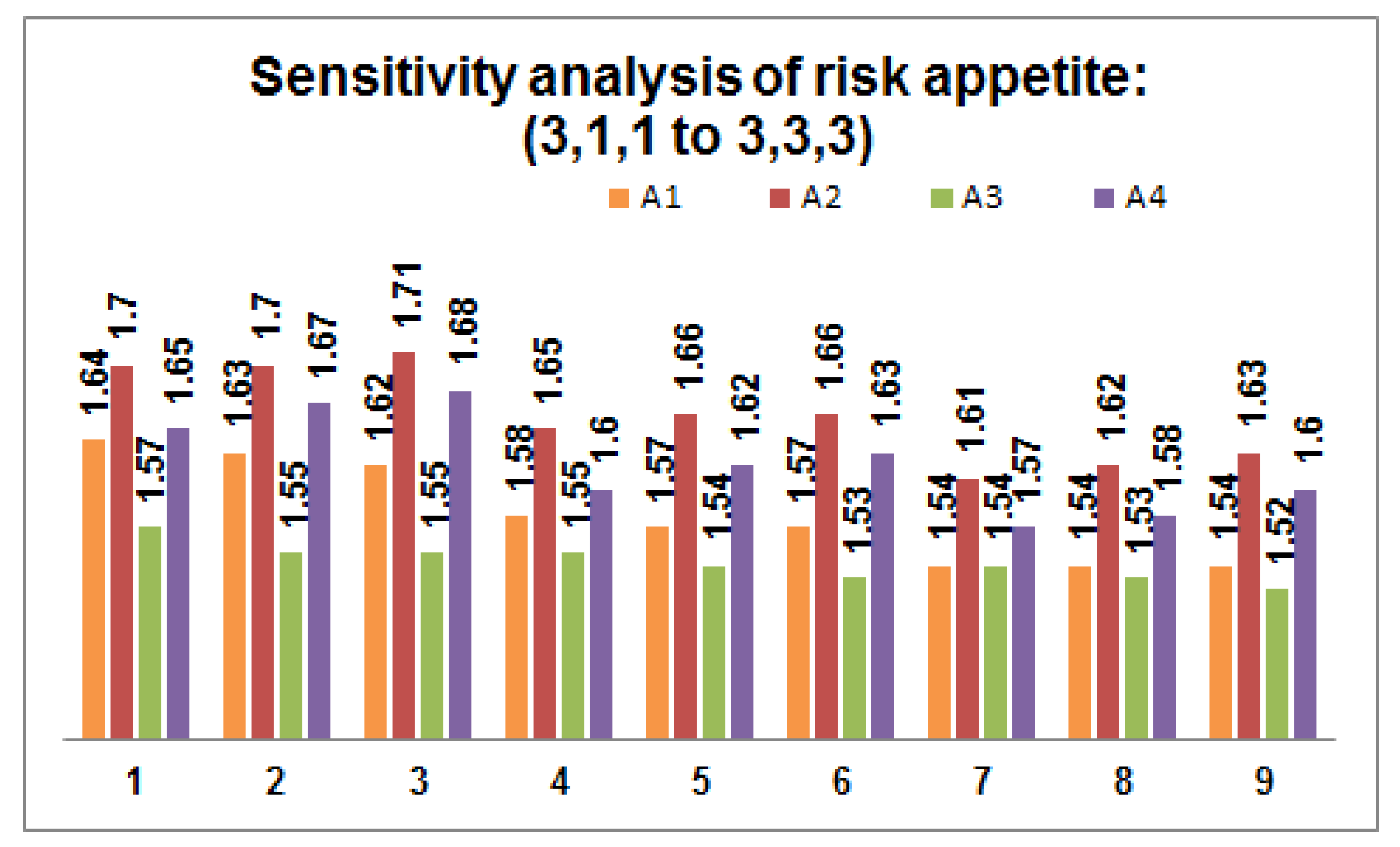
- Perform sensitivity analysis on the risk appetite of each DM by varying the values within the predefined threshold value. Figure 2, Figure 3 and Figure 4 depict 27 possible risk appetite values and the corresponding prioritized value for each renewable energy source. From the analysis, we can clearly observe that the prioritized order remains unchanged with the final order as with solar energy as a suitable renewable energy source for the process taken into consideration.
- Step 7:
- End.
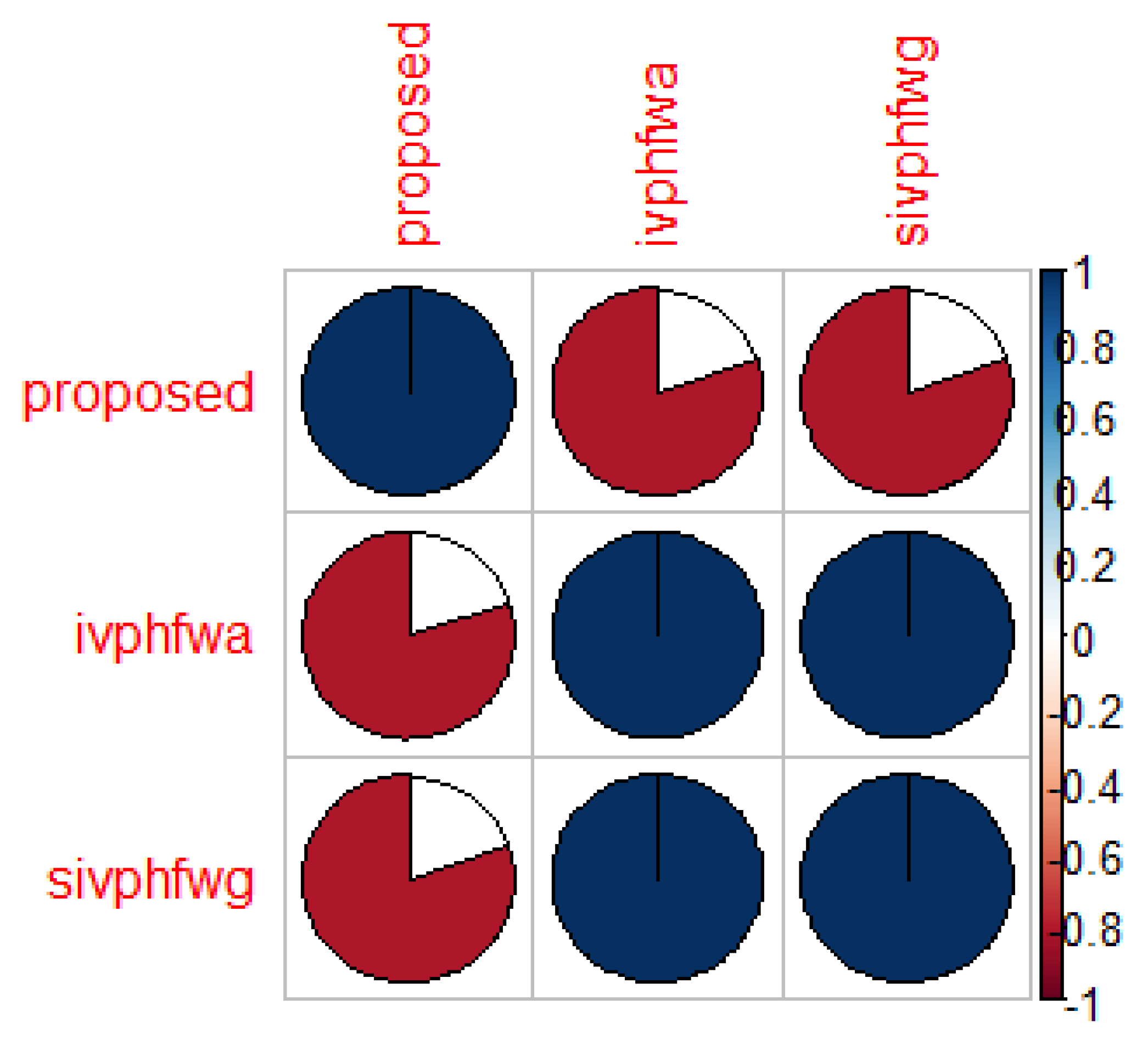
5. Comparative Analysis of Proposed Decision Framework
- The proposed aggregation operator uses the generalized data structure viz., IVPHFS as preference information. The interval number is associated as an occurrence probability value for each HFE.
- The extension of MM operator to IVPHFS context provides DMs with the ability to capture interrelationship between multiple attributes. This property resembles closely with the real-life decision-making problem.
- The proposed operator not only obtains weights of DMs but also considers the risk appetite of each DM.
- The proposed operator has parameters that are easily customizable for realizing different effects on prioritization of objects.
- The proposed operator can also realize certain operators as special cases which provide a generalized context for aggregation of preferences that helps DMs is effective management of uncertainty and vagueness.
- The attributes’ weight values are calculated in a rational manner by considering the partial information from each DM.
- It is difficult to fix the parameter value for different MAGDM application without a trial and error process.
- DMs need some training with the data structure for proper elicitation of preferences.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Triantaphyllou, E.; Shu, B. Multi-criteria decision making: An operations research approach. Encycl. Electr. Electron. Eng. 1998, 15, 175–186. [Google Scholar]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Chai, J.; Ngai, E.W.T. Multi-perspective strategic supplier selection in uncertain environments. Int. J. Prod. Econ. 2015, 166, 215–225. [Google Scholar] [CrossRef]
- Krishankumar, R.; Ravichandran, K.S.; Murthy, K.K.; Saeid, A.B. A scientific decision-making framework for supplier outsourcing using hesitant fuzzy information. Soft Comput. 2018, 22, 7445–7461. [Google Scholar] [CrossRef]
- Aktas, A.; Kabak, M. A hybrid hesitant fuzzy decision-making approach for evaluating solar power plant location sites. Arab. J. Sci. Eng. 2018, 1–13. [Google Scholar] [CrossRef]
- Senvar, O.; Otay, I.; Bolturk, E. Hospital site selection via hesitant fuzzy TOPSIS. IFAC-PapersOnLine 2016, 49, 1140–1145. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, J.; Zhu, Y.; Li, J.; Li, Q.; Zhuang, Z. A dual hesitant fuzzy rough pattern recognition approach based on deviation theories and its application in urban traffic modes recognition. Symmetry. 2017, 9, 262. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Torra, V.; Xu, Z.S.; Herrera, F. Hesitant fuzzy sets: State of the art and future directions. Int. J. Intell. Syst. 2014, 29, 495–524. [Google Scholar] [CrossRef]
- Xu, Z.S.; Zhou, W. Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment. Fuzzy Optim. Decis. Mak. 2016, 16, 1–23. [Google Scholar] [CrossRef]
- Yue, L.; Sun, M.; Shao, Z. The probabilistic hesitant fuzzy weighted average operators and their application in strategic decision making. J. Inf. Comput. Sci. 2013, 10, 3841–3848. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z. Multi-attribute decision making based on prioritized operators under probabilistic hesitant fuzzy environments. Soft Comput. 2018, 1–16. [Google Scholar] [CrossRef]
- Hao, Z.; Xu, Z.S.; Zhao, H.; Su, Z. Probabilistic dual hesitant fuzzy set and its application in risk evaluation. Knowledge-Based Syst. 2017, 127, 16–28. [Google Scholar] [CrossRef]
- Zhou, W.; Xu, Z.S. Group consistency and group decision making under uncertain probabilistic hesitant fuzzy preference environment. Inf. Sci. 2017, 414, 276–288. [Google Scholar] [CrossRef]
- Bashir, Z.; Rashid, T.; Watróbski, J.; Salabun, W.; Malik, A. Hesitant probabilistic multiplicative preference relations in group decision making. Appl. Sci. 2018, 8, 3998. [Google Scholar] [CrossRef]
- Gao, J.; Xu, Z.S.; Liao, H. A dynamic reference point method for emergency response under hesitant probabilistic fuzzy environment. Int. J. Fuzzy Syst. 2017, 19, 1261–1278. [Google Scholar] [CrossRef]
- Jiang, F.; Ma, Q. Multi-attribute group decision making under probabilistic hesitant fuzzy environment with application to evaluate the transformation efficiency. Appl. Intell. 2017, 48, 953–965. [Google Scholar] [CrossRef]
- Song, C.; Zhao, H.; Xu, Z.S.; Hao, Z. Interval-valued probabilistic hesitant fuzzy set and its application in the Arctic geopolitical risk evaluation. Int. J. Intell. Syst. 2018, 1–25. [Google Scholar] [CrossRef]
- Krishankumar, R.; Ravichandran, K.S.; Kar, S.; Gupta, P.; Mehlawat, M.K. Interval-valued probabilistic hesitant fuzzy set for multi-criteria group decision-making. Soft Comput. 2018, 1–27. [Google Scholar] [CrossRef]
- Moscovici, S.; Zavalloni, M. The group as a polarizer of attitudes. J. Pers. Soc. Psychol. 1969, 12, 125–135. [Google Scholar] [CrossRef]
- Mesiar, R.; Calvo, T. Fuzzy sets and their extensions: Representation, aggregation and models. Stud. Fuzziness Soft Comput. 2008, 220, 1–22. [Google Scholar]
- Muirhead, R.F. Some methods applicable to identities and inequalities of symmetric algebraic functions of n letters. Proc. Edinburgh Math. Soc. 1902, 21, 144–162. [Google Scholar] [CrossRef]
- Xia, M.; Xu, Z.S.; Zhu, B. Geometric Bonferroni means with their application in multi-criteria decision making. Knowledge-Based Syst. 2013, 40, 88–100. [Google Scholar] [CrossRef]
- Qin, J.; Liu, X.; Pedrycz, W. Hesitant fuzzy Maclaurin symmetric mean operators and its application to multiple-attribute decision making. Int. J. Fuzzy Syst. 2015, 17, 509–520. [Google Scholar] [CrossRef]
- Wang, R.; Wang, J.; Gao, H.; Wei, G. Methods for MADM with picture fuzzy Muirhead mean operators and their application for evaluating the financial investment risk. Symmetry 2019, 11, 6. [Google Scholar] [CrossRef]
- Liu, P.; Khan, Q.; Mahmood, T.; Hassan, N. T-spherical fuzzy power Muirhead mean operator based on novel operational laws and their application in multi-attribute group decision making. IEEE Access 2019, 7, 22613–22632. [Google Scholar] [CrossRef]
- Liu, P.; Li, Y.; Zhang, M.; Zhang, L.; Zhao, J. Multiple-attribute decision-making method based on hesitant fuzzy linguistic Muirhead mean aggregation operators. Soft Comput. 2018, 22, 5513–5524. [Google Scholar] [CrossRef]
- Hong, Z.; Rong, Y.; Qin, Y.; Liu, Y. Hesitant fuzzy dual Muirhead mean operators and its application to multiple attribute decision making. J. Intell. Fuzzy Syst. 2018, 35, 2161–2172. [Google Scholar] [CrossRef]
- Khan, Q.; Hassan, N.; Mahmood, T. Neutrosophic cubic power Muirhead mean operators with uncertain data for multi-attribute decision-making. Symmetry 2018, 10, 444. [Google Scholar] [CrossRef]
- Xu, Y.; Shang, X.; Wang, J. Pythagorean fuzzy interaction Muirhead means with their application to multi-attribute group decision-making. Inf. 2018, 9, 157. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, R.; Zhu, X.; Zhou, Z.; Shang, X.; Li, W. Some q-rung orthopair fuzzy Muirhead means with their application to multi-attribute group decision-making. J. Intell. Fuzzy Syst. 2018, 36, 1–19. [Google Scholar] [CrossRef]
- Liu, P.; Teng, F. Some Muirhead mean operators for probabilistic linguistic term sets and their applications to multiple attribute decision-making. Appl. Soft Comput. 2018, 68, 396–431. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83. [Google Scholar] [CrossRef]
- Gupta, P.; Mehlawat, M.K.; Grover, N. Intuitionistic fuzzy multi-attribute group decision-making with an application to plant location selection based on a new extended VIKOR method. Inf. Sci. 2016, 370, 184–203. [Google Scholar] [CrossRef]
- Chatterjee, K.; Kar, S. A multi-criteria decision making for renewable energy selection using Z-numbers. Technol. Econ. Dev. Econ. 2018, 24, 739–764. [Google Scholar] [CrossRef]
- Mardani, A.; Zavadskas, E.K.; Khalifah, Z.; Zakuan, N.; Jusoh, A.; Nor, K.M.; Khoshnoudi, M. A review of multi-criteria decision-making applications to solve energy management problems: Two decades from 1995 to 2015. Renew. Sustain. Energy Rev. 2017, 71, 216–256. [Google Scholar] [CrossRef]
- Luthra, S.; Kumar, S.; Garg, D.; Haleem, A. Barriers to renewable/sustainable energy technologies adoption: Indian perspective. Renew. Sustain. Energy Rev. 2015, 41, 762–776. [Google Scholar] [CrossRef]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref.# | Aggregation Operator | Preference Style | Attributes’ Weights Calculation | Applications |
|---|---|---|---|---|
| [25] | MM | Picture fuzzy set | no | Investment risk |
| [26] | Power MM | T-spherical fuzzy set | no | Air quality evaluation |
| [27] | MM | The hesitant fuzzy linguistic term set | no | ERP system selection |
| [28] | MM | Hesitant fuzzy set | no | Evaluation of emergency responses |
| [29] | Power MM | Neutrosophic cubic fuzzy set | no | Van selection |
| [30] | MM | Pythagorean fuzzy set | no | Airline evaluation |
| [31] | MM | q-rung orthopair fuzzy set | no | Investor selection |
| [32] | MM | The probabilistic linguistic term set | no | Project selection |
| Energy | Evaluation Attribute | |||
|---|---|---|---|---|
| c1 | c2 | c3 | c4 | |
| Energy | Evaluation Attribute | |||
|---|---|---|---|---|
| DMs | Evaluation Attribute | |||
|---|---|---|---|---|
| Ideal Solution | Evaluation Attribute | |||
|---|---|---|---|---|
| Methods | Renewable Energy Source (s) | Order | |||
|---|---|---|---|---|---|
| a1 | a2 | a3 | a4 | ||
| [18] | 2 | 1 | 4 | 3 | |
| [19] | 2 | 1 | 4 | 3 | |
| Proposed | 3 | 1 | 4 | 2 | |
| Characteristics | Methods | ||
|---|---|---|---|
| Proposed | [18] | [19] | |
| Data | IVPHFS based preference information | ||
| Comprehensive data | yes | yes | yes |
| Interrelationship | yes | no | no |
| Customizable parameter(s) | yes | no | no |
| Total pre-order | yes | yes | yes |
| Generalizability | yes | no | no |
| The relative importance of DM | yes | yes | yes |
| Risk appetite of DM | yes | no | no |
| Information loss | Mitigated in an efficient manner | Mitigated in a moderate manner | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krishankumar, R.; Ravichandran, K.S.; Ahmed, M.I.; Kar, S.; Peng, X. Interval-Valued Probabilistic Hesitant Fuzzy Set Based Muirhead Mean for Multi-Attribute Group Decision-Making. Mathematics 2019, 7, 342. https://doi.org/10.3390/math7040342
Krishankumar R, Ravichandran KS, Ahmed MI, Kar S, Peng X. Interval-Valued Probabilistic Hesitant Fuzzy Set Based Muirhead Mean for Multi-Attribute Group Decision-Making. Mathematics. 2019; 7(4):342. https://doi.org/10.3390/math7040342
Chicago/Turabian StyleKrishankumar, R., K. S. Ravichandran, M. Ifjaz Ahmed, Samarjit Kar, and Xindong Peng. 2019. "Interval-Valued Probabilistic Hesitant Fuzzy Set Based Muirhead Mean for Multi-Attribute Group Decision-Making" Mathematics 7, no. 4: 342. https://doi.org/10.3390/math7040342
APA StyleKrishankumar, R., Ravichandran, K. S., Ahmed, M. I., Kar, S., & Peng, X. (2019). Interval-Valued Probabilistic Hesitant Fuzzy Set Based Muirhead Mean for Multi-Attribute Group Decision-Making. Mathematics, 7(4), 342. https://doi.org/10.3390/math7040342